
Abstract
Background
Zoonotic diseases account for a substantial portion of infectious disease outbreaks and burden on public health programs to maintain surveillance and preventative measures. Taking advantage of new modeling approaches and data sources have become necessary in an interconnected global community. To facilitate data collection, analysis, and decision-making, the number of spatial decision support systems reported in the last 10 years has increased. This systematic review aims to describe characteristics of spatial decision support systems developed to assist public health officials in the management of zoonotic disease outbreaks.
Methods
A systematic search of the Google Scholar database was undertaken for published articles written between 2008 and 2018, with no language restriction. A manual search of titles and abstracts using Boolean logic and keyword search terms was undertaken using predefined inclusion and exclusion criteria. Data extraction included items such as spatial database management, visualizations, and report generation.
Results
For this review we screened 34 full text articles. Design and reporting quality were assessed, resulting in a final set of 12 articles which were evaluated on proposed interventions and identifying characteristics were described. Multisource data integration, and user centered design were inconsistently applied, though indicated diverse utilization of modeling techniques.
Conclusions
The characteristics, data sources, development and modeling techniques implemented in the design of recent SDSS that target zoonotic disease outbreak were described. There are still many challenges to address during the design process to effectively utilize the value of emerging data sources and modeling methods. In the future, development should adhere to comparable standards for functionality and system development such as user input for system requirements, and flexible interfaces to visualize data that exist on different scales.
PROSPERO registration number: CRD42018110466.
Similar content being viewed by others

Introduction
The current global population of 7.6 billion persons is expected to reach 9.8 billion by 2050 with an increasing number living in high density urban areas. The combination of high population density with increased global mobility of the human population potentially leads to growing exposure to dangerous zoonotic diseases. Technological advances, however, offer the opportunity to better understand patterns of disease spread, underlying conditions, and distribution of vulnerable populations. Spatial decision support tools can equip heath care officials with the data, analytics, information, modeling capacity, and visual tools to effectively make decisions and policy recommendations to improve public health outcomes. However, the literature shows that there have been missed opportunities, false starts, and gaps in the development of such tools. This paper identifies the strengths and challenges of spatial decision support system in public health informatics through a systematic literature review and offers insights on the significant advances, best practices, and gaps in knowledge.
Background
Zoonotic diseases are a prominent concern in public health, with the rise or reemergence of disease-causing pathogens such as Middle Eastern Respiratory Syndrome (MERS), Ebola virus, Zika virus, West Nile virus (WNV), and numerous influenza strains across the globe [1, 2]. Transference from animal reservoirs to the human population is a concern among populations of mingling and mobile species across various geographic scales [3, 4]. Approximately 60% of all human pathogens that negatively impact overall population health are derived from animals and a new emerging disease manifests approximately every 8 months [5, 6]. With each new introduction, it has been found that 60–80% of documented emerging infectious diseases originated in animals [7].
In the United States, the federal government and individual states conduct surveillance of infectious diseases but are limited in the scope of their analyses due to available data, resources and training, which is intensified by the growing development and application of informatics techniques. This development includes the introduction of digital disease surveillance systems such as HealthMap [8] which provides visualization of current disease outbreaks detected through data aggregation of online data sources such as ProMED [9], RSS feeds, Twitter and news reports using automated datamining [10]. Traditionally, surveillance of clusters of at risk areas has been passive, as agencies rely on case reporting by clinicians, laboratories, and the public. Reportable disease data constitutes a suspected or infected case and addresses: who, what, when, and where did the infection occur. Identification of high risk-areas or clusters of disease outbreak using digital data as a means of early warning and prevention is gaining traction as public health practitioners have compared local surveillance network performance with tools such as HealthMap in order to assess utility as a supplementary tool [11]. Other emerging sources of data by which outbreaks are assessed in this modern era are drawing on genetic data, primarily to identify viral strain types and to assess pathogenicity. These data enable public health practitioners such as epidemiologists to study the infectious agent itself, often using results from local laboratory strain typing and sequencing efforts [12]. Other fields such as molecular epidemiology, landscape epidemiology and phylogeography have demonstrated the value of incorporating infectious disease genetics and spatial analysis to address ad hoc population health research [13,14,15,16,17].
Recent literature indicates that public health officials have begun to address disease surveillance by incorporating spatial and temporal components of reportable disease data to model outbreaks and using geographic information systems (GIS) [18]. These methods include statistical and GIS software to produce disease maps using an array of data types such as clinical, the physical environment, or human mobility data to identify outbreaks or disease clustering. However, here has been little focus on employing these approaches by local health departments (LHDs) for differentiating strains of circulating zoonotic viruses, though the opportunity to do so is growing with the increasing amount of genetic data being generated via Next Generation Sequencing (NGS), and public sequence databases such as GenBank and the Influenza Research Database (IRD) [19, 20].
While the application of GIS and spatial statistics has advanced visualization and decision-making capabilities for disease detection, similar technological advances have been introduced and merged into integrated systems in other informatics related fields called a spatial decision support systems (SDSS). SDSS emerged from the more general decision support systems (DSSs), used widely across public health, governance, and environmental management fields. For example, electronic health records (EHRs) can incorporate DSS to assist medical staff with a variety of tasks such as treatment plans or alerts of contraindications in medications [21]. SDSS are computer-based systems that allow decision makers to take advantage of available data to solve spatially related problems in a more dynamic and integrated interface that allows for data organization, analysis and visualization [22]. Implementation of such systems have the potential to facilitate public health decision makers with many tasks from detecting high risk locations for influenza outbreaks, or distribution of medical facilities, vaccines and staff based on the affected population distribution [23, 24]. While technology and analytical software has become more sophisticated, a movement to enable decision makers to more fully explore available data to develop actionable and evidence based planning has grown [25].
The term spatial decision support system was first introduced in a series of conference proceedings from 1983 to 1985 by Jerome Dobson, in addition to Hopkins and Armstrong respectively [26, 27]. There are a few examples of prototype SDSS projects that predate the term, such as IBM’s GADS (Geodata analysis and display system) which allowed users to analyze and display geographic data [28]. However, for many years SDSS remained in a developmental phase in which decision support systems and GIS techniques were integrated into a more cohesive framework. The 1990’s saw the rise of SDSS that were frequently built using Esri’s ArcGIS software, often to demonstrate proposed architectural designs. The first implementations of modern SDSS occurred in the early 2000’s and continue today, which take advantage of advances in the world wide web that allows for web-services, data warehousing and advanced analytical processing [29].
Features that differentiate SDSS from other related systems, including clinical decision support tools, and GIS software are derived from the complex decision-making process all users engage in across multiple fields. Public health practitioners consider data such as reported cases, demographics, recent exposures, location and many other aspects while managing potential and current disease outbreaks. Due to scenarios of this complex nature, spatial problems have been referred to as “semi-structured” because they cannot be fully articulated, nor are the procedures carried out in a decision making process consistent from one investigation to the next [30]. Often decision-making software focuses on developing tools for a pre-defined decision-making process, which are often too constricting. Instead, early in the introduction of SDSS, Densham [30] emphasized that highly adaptive tools within a problem solving environment are needed. Since this time, the characteristics of modern SDSS have been defined by Sugumaran and DeGroote [29]. These characteristics, which include the ability to perform spatial analysis, visualization, and multiple scenario evaluation all within the same system have increased in popularity in the past decade as indicated by published literature using the term in PubMed (Fig. 1).

Number of papers that mention spatial decision support system by year in PubMed
Several example SDSS reported in the literature that are intended to aid public health decision makers in situations ranging from capacity analysis for local hospital beds to national preparedness for influenza outbreaks. Many recently developed systems web-based surveillance systems or platforms, though some are distributed as software packages. Functionality often includes geo-visualization of observed disease cases or outbreaks, to assisting in the actual decision to be made such as distribution of vaccination supplies [31, 32]. For example, Huang et al. [33] developed a SDSS for risk assessment of airline travel on global disease outbreaks. This tool was intended to aid the decision process, readily quantifying and comparing risk levels to assist end users with targeting priority routes in terms of prevention of spread, or mitigation efforts. In contrast, Bouden et al. [34] developed a system that provided users with a geosimulation functionality, allowing them to manipulate outbreak model parameters such as climate to aid decision makers in visualizing the progression of infectious disease distribution. However, the differences among recently developed systems is not well understood, including the use of development techniques, data sources and evaluation procedures.
A prominent complaint in literature reviews of SDSS is the inconsistency of end user involvement [35]. This is problematic in many respects because there are many considerations for software design, such as available technology and display capability, training, and knowledge of the decision-making process. While the potential and intention behind the design of many decision support systems is laudable, previous research has found these principles are inconsistently applied in the design of SDSS and related surveillance tools targeting public health users [36].
An attractive aspect of SDSS are their integrative capability to draw on many different sources of data, to relieve much of the organizational burden from the end user. However, inclusion of data sources for a given task are becoming increasingly difficult to address the full range of potential contributing factors using established methods. For surveillance tasks and analysis, common methods employ manually curated data that is processed using GIS and statistical software. As surveillance has become increasingly multidisciplinary, there is demand for access to more data and analytical tools [37]. As such, the online community has begun facilitating the acquisition of various types of data for analytical purposes by creating online repositories of data with various states of organization. Integrating these types of sources is imperative to fully explore all contributing factors to zoonotic disease. Additionally, recent SDSS have allowed for automated integration of data collection from multiple relevant sources such as hospitals, laboratories and physician reporting.
In this systematic review, we differentiate the characteristics of recently developed SDSS designed to aid public health practitioners in the identification of high risk areas for zoonotic disease outbreaks. While other literature has summarized the various forms of visualization and analytic tools targeting zoonotic disease, focusing on SDSS development allows for a better understanding of an emerging type of tool that has the potential to better integrate data for modeling and analytical processes to aid decision making. This is important as public health officials continue to rely on more sources with the rise of new online databases and newsfeeds for surveillance, thus increasing the complexity and cognitive load.
The objectives of this systematic review were to:
-
To identify and describe current spatial decision support systems developed for identifying zoonotic disease outbreaks in the public health sector.
-
To identify the underlying modeling techniques and predictors used in the development of the identified spatial decision support systems.
Methods
Selection of studies
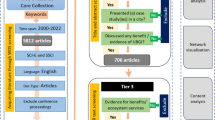
To identify articles covering the recent advances in SDSS, we chose to utilize the guidelines for systematic reviews provided by the PRISMA statement [38]. To identify potential articles, we searched the Google Scholar database using Boolean logic to combine key terms described in Table 1 and limited the years of observation from January 1, 2008 to August 31, 2018. The search was performed independently by two researchers, using the Endnote reference manager to document all citations. Once duplicates were removed, titles and abstracts were screened, and discrepancies were resolved through mutual agreement. A final screening of full manuscripts was carried out, whereby inclusion and exclusion criteria were used to identify the final set of articles by two reviewers.
Inclusion and exclusion criteria
For a prospective article to be considered, the subject of the title and abstract had to describe the development and implementation of an SDSS designed to aid the decision-making process to manage a zoonotic disease outbreaks capable of spatial modeling. However, we did consider the article if it described a tool that was developed to address reportable infectious disease generically and was inclusive of zoonotic diseases. The main intervention the SDSS had to address was the identification of high risk regions for disease transmission or outbreaks. As the primary concern of this article is to enhance the current understanding of tools available to support public health decision making, we only included those articles that studied human or animal populations. We excluded any summaries or reviews written about current SDSS, in addition to articles which proposed SDSS frameworks yet to be implemented. Any articles that did not develop an SDSS in which the intended users were professionals such as epidemiologists, veterinarians, wildlife biologists, or other similar positions were excluded. Any SDSS that were developed to manage other health conditions exclusively such as cardiac disease, diabetes, obesity, or emergency care were not considered. We also excluded the article if it described a system that did not include fully integrated spatial visualization and modeling capabilities through a user interface. Articles which described tools developed specifically for mathematical modeling of outbreaks or other events alone, and not in conjunction with decision-aid functionality for public health professionals were excluded. Systems which were developed to monitor and maintain a database of current zoonotic disease reports were also not considered. A full description of all criteria are summarized in Table 2.
Assessment
For each article that met our inclusion criteria, we reviewed the entire text in addition to tables, figures and supplementary material. For the review process, we first evaluated the quality of each publication using a scoring methodology (MMAT) approved for use in systematic reviews. This tool first applies screening criteria for any type of study to confirm whether there are clear objectives and whether the collected data allowed the researcher(s) to address the objective. Studies which passed the initial screening question were then further evaluated based on study type (quantitative, qualitative, or mixed methods) using a ranking system to answer specific questions (see Fig. 2), with either: yes, no, unable to tell, or not applicable similarly to Fournet et al. [39] (each response was ranked as 4, 3, 2, 1 respectively). The Template for intervention description and replication (TIDieR) checklist was then used to evaluate each of the full texts that passed the MMAT screening for completeness in addressing the intervention proposed as a means of qualitative synthesis [40]. The TIDieR was published in 2014 to extend the CONSORT and SPIRIT statements, and can be applied to all evaluation study designs [41]. This checklist covers topics including naming the specific intervention, why, what, who, how, where, and when.

Distribution of studies selected for full text evaluation by publication year
General descriptions of the final set of articles are documented in excel, including the target disease or diseases, the target population at risk, and the geographic coverage, and data sources and types used for identifying areas at risk for outbreak. To compare each SDSS in terms of modeling capability, we documented and described eight necessary characteristics of a SDSS as identified by Sugumaran et al. [29]. These include spatial data management/analysis, visualization, report generations, interactive problem solving, spatial modeling, semi structured problem solving, scenarios evaluation, and easy user interaction.
Results
Screening results
After duplicates were removed from search results and inclusion/exclusion criteria were applied to title and abstract screening, 75 articles were subject to full text review. We then screened each full article for inclusion/exclusion criteria and reduced the final set to 34 articles. Of those remaining, all articles selected described SDSS development intended for public health officials as end users which focused on identifying at risk areas of infectious disease outbreaks. The full screening process is summarized in Fig. 3. The final set of articles were published evenly throughout the selected time-period of 2008–2018, with a decreasing trend towards the end of the study period. See Additional file 1 for a basic description of all articles [8, 23, 24, 31,32,33,34, 42,43,44,45,46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69,70,71,72,73,74,75,76,77,78,79,80,81,82,83,84,85,86,87,88,89,90,91,92,93,94,95,96,97,98,99,100,101,102,103,104,105,106,107,108,109] that underwent full text review, with reasons for exclusion.

Qualitative assessment
Quality filtering
Of the final 34 articles identified after full text screening, 22 did not meet the MMAT screening criteria by addressing a specific objective or research question that could be readily quantitatively or qualitatively assessed (see Additional file 2 and Fig. 4). The articles which could not be fully evaluated using the MMAT generally reviewed the development and implementation of an SDSS, while a few also described a case study (n = 4), a simulation study (n = 3), and a pilot study (n = 1). Of those studies fully evaluated using the MMAT (n = 12), three were qualitative, seven were quantitative, and 2 were mixed methodologies. The average MMAT score for the final set of 12 articles was 87.5%.

Results of qualitative assessment using the MMAT tool. All papers included in the full text review were subject to the MMAT review, 22 of the 34 papers did not pass the initial screening questions and were not subject to further evaluation
Quality of interventions description
The papers that passed the MMAT screening questions were also assessed using the TIDieR checklist to determine if the proposed intervention was adequately described (see Fig. 5 and Additional file 3). All studies addressed most items on the checklist, all with a similar intervention to develop a spatial decision support system, though with some variations to address high risk areas for outbreaks and methodology. Rationales behind development varied from visualization of space time events, detection, monitoring or prediction of disease clusters or epicenters, or more specific tasks related to targeting regions for disease elimination or management. All but one [73] article described the intervention as effective, either through sensitivity (n = 3), significance (n = 3), or percentage (n = 2) evaluations on ability to identify at risk areas for outbreaks, in addition to user access traffic (n = 2), and user feedback on usability or usefulness (n = 5).

TIDieR checklist criteria results
Evaluation of selected SDSS
General descriptions
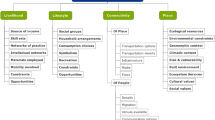
The selected SDSS are described briefly in Table 3 (also see Additional file 4). SDSS were developed predominantly as desktop applications, while four were web-based and one was undetermined. Half of the systems were capable of real or near real time surveillance data (n = 6) while the remaining systems were retrospective. Common practices described during development included data preprocessing, cleaning, or aggregation. Aggregation was often applied to climactic or environmental predictors for which finer geographic resolution was available, compared to other data sources. Other difficulties in combining data included differences in storage format, naming conventions, or data relationships from various sources and health organizations. Many studies described methods to address integration issues, though most did not give specifics.
Target disease, population, and geographic coverage
Further examination revealed an array of individual or groups of diseases targeted by the selected studies. Most commonly, a system was developed with the intent of being used for monitoring a single disease (n = 7), while those remaining were inclusive of several reportable infectious diseases (n = 5) for a given study area. Many of the reviewed SDSS were developed such that the international (n = 2) community could potentially utilize them, or a specific country (n = 7). A smaller proportion (n = 3) focused on a specific region, state or province. All but one of the reviewed systems focused on human centric health outcomes (Table 4).
Data types and sources
We found that most systems relied on case related data (n = 9) and most frequently was provided by National health departments (n = 7). Case reporting was sometimes combined with other data types (n = 4), though nearly half (n = 5) utilized case reporting data alone. Overall, combining multiple data sources was slightly more common (n = 7). In several instances we found that SDSS often integrated individual reporting, climactic, environmental, or remote sensing data. Less common data sources included drug sales [43], citizen reporting and social media data [57, 64]. A small subset allowed the user to upload data into the system (n = 2), and several SDSS allowed near real time automated data integration with local or national health agencies. One employed web crawling services to automatically update data in near real time from public online databases or resources [64] (Table 5).
Summary of core SDSS characteristics
Spatial database management
An overview of results for the review process in which each SDSS was evaluated based on the inclusion of the eight core functionalities are presented in Table 7. For the first core functionality, all systems described the inclusion of spatial database management, however the specific system could not be identified in four instances. ArcGIS and PostgreSQL were the most frequently used management system, open source GIS software such as QGIS while others utilized database management software such as MySQL in combination with map visualization tools such as OpenLayers and Google Maps.
Visualization
All systems were built as an application with integrated mapping capability that was developed for user interaction. All SDSS provided similar layouts that included a menu bar at the top, in addition to panels and or tabs that could be navigated to produce different displays including maps, analysis parameters, results, file management, analysis, or summaries. Most base maps were choropleth in nature and allowed overlays or color themes that identified areas of interest. These overlays were often points or circles to draw the user’s attention to georeferenced outbreak data. Other raster format layers representing demographic data, landuse, or climactic data were common. Less common overlays included simulations of networks of disease spread.
Report generation
While all SDSS were capable of displaying maps, most applications provided a means to generate tables or charts with summaries of the data or analyses being conducted. Often reports were available in a separate panel or tab within the user interface. A variety of graphs were used, ranging from pie charts for illustrating concepts such as proportions of case reports by region, tables summarizing analysis results, to bar or line graphs often used to present time-series data. Those SDSS which followed a web application format often took advantage of services such as HighCharts, which allow the developer to produce interactive charts within webpages.
Interactive problem solving
A variety of built in functions were noted for all SDSS related to mapping, analysis, and graphing. Often the interface allowed the user to adjust or remove layers to customize the spatial visualization in addition to zooming, color themes, legend display, select region etc. When the user performs an analysis, SDSS commonly allowed user selection of species or disease (if more than one available), timeframe, region of interest, model parameters, covariates to include, or graphical output format. In a few instances, an SDSS was capable of several different types of outbreak detection and prediction analysis [43, 48, 83], or allowed for simulations of disease outbreaks [34].
Spatial modeling capability
Most commonly choropleth maps were produced for model visualization, often identifying areas in which outbreaks of disease were identified or predicted. Risk maps were not always conceptualized in the same way ranging from clustering, disease activity levels, at-risk households to population density. Many SDSS were capable of also modeling disease distribution, identifying locations of individual cases, or zones of high risk. In one instance transmission routes or disease origins and destinations over a given time frame were modeled within a network to identify high risk nodes [33, 73]. Several spatial and non-spatial analytical techniques were used to develop the set of SDSS, often allowing the user to choose between multiple options including spatial scan statistics, data mining algorithms, susceptible, infected, recovered (SIR) models, Moran’s I, Knox test, and linear regression (see Table 6 for a summary).
Semi structured problem solving
Not all end users would necessarily utilize the same methods in designing a particular SDSS, apart from analyzing outbreaks, as such most SDSS allowed the user to control the analysis and modeling process in several ways. The user could often tune parameters used in the modeling process such as timeframe in which the model was constructed, search radius, predictors, or data sources. Furthermore, some studies allowed the user to query, add to, or modify the database [24, 80, 88]. Additionally, these SDSS often allowed the user to select from different map layers, or graphics to model an outbreak situation to their specifications and could be manipulated by zooming, panning, or feature section.
Scenario evaluation
A lot of the same features mentioned for semi structured problem solving also allow the user to iteratively model an outbreak situation to the users’ satisfaction. This is evident through iterative modeling for a given scenario using different data sources, parameters, or map specifications. A small set of studies incorporated methods to compare different models, as Ali et al. [43] allowed the user to compare two evaluations for a given outbreak side by side, which utilized different predictors or chart predicted versus observed outbreak data. Another study provided a feature to simulate the results of different mosquito spraying interventions to prevent diseases such as West Nile virus [34].
Easy user interface
All systems provided a graphical user interface that integrated mapping for spatial modeling visualization, and options to produce a variety of graphs or tables to aid the decision-making process either in a desktop or web application format. However, there were few studies that included a mechanism to assess user satisfaction to determine ease of use. A total of five studies included details of a usability evaluation and discussion. Evaluations were carried out by interviewing or surveying the user after performing set tasks. Surveys were either custom made or an industry standard such as the System Usability Scale [110]. Less direct methods of measuring ease of use included tracking user system accesses and usage, and percentage of target user utilization. Several studies indicated usability was addressed during the design process by consulting with potential users on needs and requirements, though follow up evaluation was inconsistent.
Table 7 describes the major characteristics of SDSS’ evaluated here, by summarizing the
most common method by which each characteristic is incorporated, and possible formats, or methods.
Discussion
General features
In our review, we found a large amount of diversity in design and scope regarding study areas targeted by recent SDSS. The systems observed here were developed by smaller research teams at individual institutions, as well as by government divisions throughout the world to address the concerning zoonotic disease developments and spread which have increased in recent years. Several SDSS built for smaller regions relied on local data sources and reporting, whereas those developed to be more generalizable used more public data sources. These findings highlight a common problem wherein systems are developed in isolation and rely on locally collected and curated data.
Fortunately, the trend in the data presented here indicates most systems are developed to address numerous diseases over large regions, entire countries, or the entire globe. Those systems that are more geographically inclusive have the potential to address a range of decision making needs of public health officials who are often faced with a variety of outbreak threats from surrounding environments. This universal approach reduces the necessity to have multiple tools that perform similar or redundant tasks.
Core SDSS functionalities
For each of the core functionalities, studies often provided enough detail to determine specific details regarding architectural design that allow visualization, reporting, problem solving etc. and implementation. Throughout the history of SDSS development, there has been a heavy reliance on proprietary, standalone GIS [111]. Beginning with open source GIS distributions such as GRASSGIS, the last 10–15 years have seen a remarkable expansion in the availability of open source software such as statistical packages, web mapping services, and others which have shifted the focus on client–server architecture to a web services model in newer SDSS [111]. The results here indicate that the availability of new tools to aid SDSS development are diversifying what software is used to produce the final product, ranging from desktop applications integrating one of many GIS with spatial database management to the implementation of web application frameworks that utilize open source database management systems (PostgreSQL, MySQL, etc.) with mapping services such as OpenLayers. Also reflected are a large variety of analytical tools or algorithms that can be packaged for use in a variety of systems for a similar purpose, or complementary analysis. For instance, Kulldorff’s spatial scan statistic software [112], k-nearest neighbor and support-vector machine learning models were implemented in just one SDSS reviewed here.
Many of the reviewed studies were less consistent in describing or performing model evaluations, obtaining stakeholder requirements, pilot studies, or usability testing. Several studies described their system as user friendly [23, 48, 49, 51, 64, 106, 107, 113], though not all performed an evaluation or even approached the topic in the same way. Most studies utilizing this term referred to usability testing, which was often followed with robust evaluation methods. However, other studies used the term in reference to ease of configuration with other software, or visual displays that were esthetically appealing without providing details of user participation to evaluate these claims. Despite this, it is noteworthy that usability metrics mentioned within the selected articles do not necessarily evaluate all aspects that potentially contribute to ease of use.
Current data sources and future developments
Integration of disparate data sources has been a common theme in surveillance systems and decision support systems for public health surveillance [114]. To accomplish this, collections from local health practitioners, state departments, or government agencies may be joined such that reportable disease data are housed within the same framework that integrates sources such as media, genetic sequencing, socio-economic data, or other environmental characteristics. However, integration of multiple data sources was not universal in recently developed SDSS reviewed here. Availability and utilization of social media, news, landscape, climactic, socio-economic data are reflected here, as several systems covered are inclusive of these increasingly readily available data types, providing even more data to better understand what contributes to disease spread and outbreaks. There are still many inequities in accessibility to resources globally that make collection and availability of data difficult, stratifying health status and potential interventions by socio-economic means and access to urban areas [115]. Limited resources to collect and organize data to develop effective surveillance systems is further impacted with difficulties in combining datasets recorded for varying formats, quality standards, and reporting requirements [116].
Genetic sequencing and related bioinformatics tools and resources are an emerging data source which are not well represented in recent SDSS development. Open source genetic data repositories are increasingly more common, such as GenBank [19] and the IRD [20] which contain an abundance of pathogen sequences and relevant metadata that present opportunities to enhance current practices. Utilization of sequencing to support epidemiological and disease prevention efforts have been demonstrated in recent epidemic events including the Ebola outbreak in west Africa from 2014 to 2015, in which genetic sequencing provided valuable information on the genetic diversity, to estimate how fast the disease spread and predict future transmission through phylogenetic analysis [117]. Likewise, Fraser et al. found that transmission potential estimates derived from genetic sequencing were comparable to traditional epidemiological estimates based clinical attack rates during the H1N1 pandemic of 2009 [118]. While these developments show great potential for the use of bioinformatic tools and resources in public health, the public sector has yet to take full advantage of genetic data driven tools. Despite a substantial amount of literature that documents the value of understanding the genetic variability of disease [119,120,121], only three potential articles included in the screening process were inclusive of sequencing data but did not pass the inclusion criteria or quality filtering process [53, 89, 95]. Complications for including sequencing data for zoonotic surveillance are largely due to limited resources or laboratory capacity to rapidly sequence emerging infections [121], and a unifying framework from which to integrate the phylogenetic patterns of an infectious agent and potential hosts [122], in addition to drivers of disease.
Understanding the phylogenetics of a disease in context with the spatial distribution, environmental characteristics, and potential hosts, assists in the identification of geographic areas that drive zoonotic disease spread and circulation. Ge et al. [123] compared methodologies for H5N1 avian influenza outbreak identification derived from three different fields including phylogenetics, spatial statistics, and epidemiological analysis of socio-ecological determinants of disease such as human and avian population density, migration routes, railways, and inland water, which found that integrating all three serves to better corroborate observed occurrence and estimate ability to spread. Changes in human population, industrialization, global trade, and travel also play a key role in facilitating the introduction or discovery of novel pathogens throughout the world [124], and phylogenetic analysis facilitates tracing the spread of disease through human interactions [125]. Health agencies are now better able to respond to emerging zoonotic diseases through understanding how changes in the genome of a pathogen impacts disease risk and spread by identifying transmission routes, mutation rates, in conjunction with other epidemiological parameters of interest [3]. Substantial concern for potential pandemics due to transmission of zoonotic disease from animal to human populations such as avian influenza [126] has also prompted integration of animal phylogenetic analysis to better understand interaction and transmission which can aid management and preventative measures [127,128,129]. The need to develop an integrative approach necessary to understand the emerging spatial patterns of zoonotic disease outbreak and spread has long been recognized, with the advent of movements such as “One Health” which call for a global strategy that is multidisciplinary to address the health of humans, animals, and the ecosystem [130]. Future development should focus on assisting in the ease of access and integration of multiple data sources to achieve this goal.
Future directions
Data integration and availability still pose several challenges in the development of SDSS for zoonotic disease outbreak management, including variability among available sources such as scale, completeness, and timeliness. Potential data sources range from the microscopic to the global scale, necessitating data transformation and projection for appropriate analysis and visualization. While georeferenced datasets describing environmental and climactic phenomena are more readily available, emerging genetic data sets present some challenges, as location of isolation are generally extracted manually from public records or publications. To address visualization of genetic sequence data, there have been efforts to extract geospatial metadata such as location and host from GenBank records, to ease automation of linking relevant sequence data for spatial modeling of disease [131]. Efforts to model outbreaks within a decision support environment which integrate data collected on different spatial scales need to address automated data extraction and transformation such as aggregation of case reports, host population densities, and locations from which isolates were sequenced for a region under study such that visualization of a multifaceted scenario is possible.
Sparsity in collected data across large geographic regions could also introduce uncertainty in results, leading to imputation or summarization methods to account for unobserved data. This is particularly a problem for genetic sequence data currently available, which does not cover regions comprehensively and geographic metadata may vary by location specificity, ranging from coordinates to country [132]. Machine learning algorithms have been utilized in clinical decision support systems to address missing patient data to aid medical professionals with decision making [133], and may also prove useful in spatial decision support systems to address this limitation. Other approaches to documenting disease case reporting that have been increasingly utilized are social media, new sources and various forms of citizen science. One SDSS reviewed here incorporated public reports of disease morbidity to enhance surveillance, provided through a hotline or online submission. The advent of the mobile phone in an increasingly interconnected digital age has given rise to a form of citizen science aptly described by the phrase ‘Wikification of GIS by the masses’ (WGM) coined by Kamel Boulos [134], and later described as volunteered geographic information (VGI) [135]. WGM is the specific embodiment of crowdsourcing approach in GIS [136]. WGM encompasses data contributions from citizens to bring local knowledge and spatial awareness on matters of interest into better focus. WGM is commonplace now in applications such as Google maps, and similar platforms have arisen to assist in disease surveillance such as Flu Near You [137, 138]. Recent literature has questioned the utility of WGM for surveillance purposes, suggesting that crowd sourced reporting at the local level does not correlate well with CDC records [138]. However, this citizen reporting through crowd sourcing can potentially complement traditional data sources.
Timeliness of emerging genetic data sources are currently primarily used for retrospective study due to inability to perform sequencing locally during epidemiological investigations, especially in regions of the world with limited resources and infrastructure. However, advances in near real time genetic sequencing may address this problem in the near future with the arrival of a portable sequencing instrument, which can produce sequencing results within a day of receiving a sample during on ongoing epidemic [139].
Future SDSS also need to better support existing public health surveillance practices, skills, resources and methodologies [140]. Previous work indicates that LHD’s utilize a wide variety of information systems for surveillance and identifying at risk areas in the United States alone, with little understanding of effectiveness [141]. Incorporating user centered design principles such as designing for the user tasks would allow more effective, efficient work within a user-friendly interface. Sutcliffe et al. has previously described a design framework for visualization decision support tools for epidemiology which incorporates user centered design [101]. They argue that to effectively translate data into actionable policy or prevention measures, the software designers and end-user analysts must collaborate extensively. This approach has been implemented more consistently in clinical informatics projects such as the design of electronic health records [142], though rarely in public health informatics [101]. The successful implementation of decision support tools is often limited to evaluations of the proposed system in which potential users provide valuable feedback, and frequently suffer from user dissatisfaction due to a mismatch in expectation, user knowledge of spatial analysis and other contributing factors [143]. While several SDSS here did evaluate usability after system design, often without prior user input, our finding here indicate that improvements can still be made to better include potential users throughout the design process.
Limitations
To limit the possible number of comparisons to more dated methods and technology, we focused on more recent work and thus excluded articles prior to 2008. We also did not search all available databases, opting for the breadth of Google scholar which might have resulted in unique publications that were not available in individual databases.
Conclusions
The characteristics, data sources, development and modeling techniques implemented in the design of recent SDSS that target zoonotic disease outbreak risk were highlighted. To take advantage of data collected on zoonotic diseases and their geographic distribution for public health decision making, it is necessary to integrate current organizational and analytical methods employed into the development of novel systems. These approaches need to be grounded in epidemiological practice, to better serve the end user’s objective. However, the systems described here often did not consistently or effectively address this important aspect. A focus on a cohesive methodology in the development of SDSS is needed to better address the needs of the user. As indicated here, there is a disconnect between many available systems and the end user as many of the recent designs and system evaluations did not include public health officials, or interaction was not limited. Inclusion and better communication with public health officials in the development process is necessary going forward, in addition to ongoing training, planning for full implementation and distribution.
Data integration with new complimentary fields of study are also needed, such as incorporating genetics into zoonotic spatiotemporal surveillance approaches. This enables health agencies to consider not only traditional epidemiological data such as location and timing of reported cases but also the genetics of the virus that influence the virus’s ability to adapt as it spreads and proliferates throughout an environment. Data quality and completeness will also need to be taken into consideration during this process. Going forward with inclusion of new data sources will necessitate an increase in complexity and connectivity between online resources and new public health SDSS in a streamlined manner, to reduce cognitive overload. Few of the SDSS described here have been widely distributed or consistently implemented by the greater public health community. Future systems that adopt these practices will potentially have better support from the target audience, resulting in continuing improvement of SDSS and prolonged use.
Change history
24 August 2021
A Correction to this paper has been published: https://doi.org/10.1186/s12942-021-00293-x
Abbreviations
- MERS:
-
Middle Eastern Respiratory Syndrome
- WNV:
-
West Nile virus
- OIE:
-
Institute for International Epizootics
- NGS:
-
Next Generation Sequencing
- IRD:
-
Influenza Research Database
- GIS:
-
geographic information systems
- ESRI:
-
Environmental Systems Research Institute
- SDSS:
-
spatial decision support system
- CDC:
-
The Centers for Disease Control and Prevention
- GADS:
-
geodata analysis and display system
- LHD:
-
local health departments
- SIR:
-
susceptible, infected, recovered
- WGM:
-
Wikification of GIS by the masses
- VGI:
-
volunteering geographic information
References
Lam TT, Hon CC, Tang JW. Use of phylogenetics in the molecular epidemiology and evolutionary studies of viral infections. Crit Rev Clin Lab Sci. 2010;47(1):5–49.
Duggal NK, D’Anton M, Xiang J, Seiferth R, Day J, Nasci R, Brault AC. Sequence analyses of 2012 West Nile virus isolates from Texas fail to associate viral genetic factors with outbreak magnitude. Am J Trop Med Hyg. 2013;89(2):205–10.
Morse SS, Mazet JAK, Woolhouse M, Parrish CR, Carroll D, Karesh WB, Zambrana-Torrelio C, Lipkin WI, Daszak P. Prediction and prevention of the next pandemic zoonosis. Lancet. 2012;380(9857):1956–65.
Woolhouse M, Gaunt E. Ecological origins of novel human pathogens. Crit Rev Microbiol. 2007;33(4):231–42.
Jones KE, Patel NG, Levy MA, Storeygard A, Balk D, Gittleman JL, Daszak P. Global trends in emerging infectious diseases. Nature. 2008;451(7181):990.
Gibbs EPJ, Anderson TC. One World - One Health and the global challenge of epidemic diseases of viral aetiology. Vet Ital. 2009;45(1):35–44.
Morens DM, Fauci AS. Emerging infectious diseases: threats to human health and global stability. PLoS Pathog. 2013;9(7):e1003467.
Brownstein JS, Freifeld CC, Reis BY, Mandl KD. Surveillance sans frontières: Internet-based emerging infectious disease intelligence and the HealthMap project. PLoS Med. 2008;5(7):1019–24.
Madoff LC, Woodall JP. The internet and the global monitoring of emerging diseases: lessons from the first 10 years of ProMED-mail. Arch Med Res. 2005;36(6):724–30.
Lyon A, Lyon L. Comparison of Webâ based biosecurity intelligence systems: BioCaster, EpiSPIDER and HealthMap. Transbound Emerg Dis. 2012;59(3):223–32.
Thomas MC, Kite-Powell A, Atrubin D, Hamilton JJ. Evaluating the utility of HealthMap as a supplementary surveillance tool. Online J Public Health Inform. 2015;7(1):e165.
Didelot X, Bowden R, Wilson DJ, Peto TEA, Crook DW. Transforming clinical microbiology with bacterial genome sequencing. Nat Rev Genet. 2012;13(9):601–12.
Culasso AC, Farias A, Di Lello FA, Golemba MD, Re V, Barbini L, Campos R. Spreading of hepatitis C virus subtypes 1a and 1b through the central region of Argentina. Infect Genet Evol. 2014;26c:32–40.
Ocwieja KE, Fernando AN, Sherrill-Mix S, Sundararaman SA, Tennekoon RN, Tippalagama R, Krishnananthasivam S, Premawansa G, Premawansa S, De Silva AD. Phylogeography and molecular epidemiology of an epidemic strain of dengue virus type 1 in Sri Lanka. Am J Trop Med Hyg. 2014;91:225–34.
Chiou HY, Hsieh CH, Jeng CR, Chan FT, Wang HY, Pang VF. Molecular characterization of cryptically circulating rabies virus from ferret badgers, Taiwan. Emerg Infect Dis. 2014;20(5):790–8.
Schuh AJ, Ward MJ, Leigh Brown AJ, Barrett AD. Dynamics of the emergence and establishment of a newly dominant genotype of Japanese encephalitis virus throughout Asia. J Virol. 2014;88(8):4522–32.
Velazquez-Salinas L, Pauszek SJ, Zarate S, Basurto-Alcantara FJ, Verdugo-Rodriguez A, Perez AM, Rodriguez LL. Phylogeographic characteristics of vesicular stomatitis New Jersey viruses circulating in Mexico from 2005 to 2011 and their relationship to epidemics in the United States. Virology. 2014;449:17–24.
Joyce K. “To me it’s just another tool to help understand the evidence”: public health decision-makers’ perceptions of the value of geographical information systems (GIS). Health Place. 2009;15(3):801–10.
Benson DA, Karsch-Mizrachi I, Clark K, Lipman DJ, Ostell J, Sayers EW. GenBank. Nucleic Acids Res. 2012;40(Database issue):D48–53.
Squires RB, Noronha J, Hunt V, Garcia-Sastre A, Macken C, Baumgarth N, Suarez D, Pickett BE, Zhang Y, Larsen CN, et al. Influenza research database: an integrated bioinformatics resource for influenza research and surveillance. Influenza Other Respir Viruses. 2012;6(6):404–16.
Fraccaro P, O’Sullivan D, Plastiras P, O’Sullivan H, Dentone C, Di Biagio A, Weller P. Behind the screens: clinical decision support methodologies—a review. Health Policy Technol. 2015;4(1):29–38.
Eisen L, Eisen RJ. Using geographic information systems and decision support systems for the prediction, prevention, and control of vector-borne diseases. Annu Rev Entomol. 2011;56:41–61.
Delmelle E, Delmelle EC, Casas I, Barto T. H.E.L.P: a GIS-based Health Exploratory AnaLysis Tool for Practitioners. Appl Spat Anal Policy. 2010;4(2):113–37.
Rees EE, Gendron B, Lelièvre F, Coté N, Bélanger D. Advancements in web-database applications for rabies surveillance. Int J Health Geogr. 2011;10(1):48.
Owens DK. Analytic tools for public health decision making. Med Decis Mak. 2002;22(5 suppl):S3–10.
Dobson MW. A high resolution microcomputer based color system for examining the human factors aspects of cartographic displays in a real-time user environment. In: Wellar BS, editor. Presented at the 6th international symposium on computer assisted cartography, vol. 1. Ottawa, CA; 1983. p. 352–361.
Hopkins LD, Armstrong MP. Analytic and cartographic data storage: a two-tiered approach to spatial decision support systems. In: Proceedings of seventh international symposium on computer-assisted cartography. Washington, DC: American Congress on Surveying and Mapping; 1985.
Mantey PE, Carlson ED. Integrated geographic data bases: the GADS experience. In: Blaser A, editor. Data base techniques for pictorial applications. Lecture notes in computer science, vol. 81. Berlin, Heidelberg: Springer; 1980. p. 173–198.
Sugumaran R, Degroote J. Spatial decision support systems: principles and practices. Boca Raton: CRC Press; 2011.
Densham P, Rushton G. A more efficient heuristic for solving large p-median problems. Pap Reg Sci. 1992;71(3):307–29.
Camitz M. StatFlu—a static modelling tool for pandemic influenza hospital load for decision makers. Eur surveill Bull Eur Mal Transm Eur commun Dis Bull. 2009;14(26):344–58.
Maciejewski R, Livengood P, Rudolph S, Collins TF, Ebert DS, Brigantic RT, Corley CD, Muller GA, Sanders SW. A pandemic influenza modeling and visualization tool. J Vis Lang Comput. 2011;22(4):268–78.
Huang Z, Das A, Qiu Y, Tatem AJ. Web-based GIS: the vector-borne disease airline importation risk (VBD-AIR) tool. Int J Health Geogr. 2012;11:33.
Bouden M, Moulin B, Gosselin P. The geosimulation of West Nile virus propagation: a multi-agent and climate sensitive tool for risk management in public health. Int J Health Geogr. 2008;7:35.
Sutcliffe A, Thew S, Jarvis P. Experience with user-centred requirements engineering. Requir Eng. 2011;16(4):267–80.
Carroll LN, Au AP, Detwiler LT, Fu T-C, Painter IS, Abernethy NF. Visualization and analytics tools for infectious disease epidemiology: a systematic review. J Biomed Inform. 2014;51:287–98.
Caprarelli G, Fletcher S. A brief review of spatial analysis concepts and tools used for mapping, containment and risk modelling of infectious diseases and other illnesses. Parasitology. 2014;141(5):581–601.
Liberati A, Altman DG, Tetzlaff J, Mulrow C, Gøtzsche PC, Ioannidis JPA, Clarke M, Devereaux PJ, Kleijnen J, Moher D. The PRISMA statement for reporting systematic reviews and meta-analyses of studies that evaluate health care interventions: explanation and elaboration. J Clin Epidemiol. 2009;62(10):e1–34.
Fournet F, Jourdain F, Bonnet E, Degroote S, Ridde V. Effective surveillance systems for vector-borne diseases in urban settings and translation of the data into action: a scoping review 11 Medical and Health Sciences 1117 Public Health and Health Services Frédéric Simard. Infect Dis Poverty. 2018;7(1):99.
Hoffmann TC, Glasziou PP, Boutron I, Milne R, Perera R, Moher D, Altman DG, Barbour V, Macdonald H, Johnston M, et al. Better reporting of interventions: template for intervention description and replication (TIDieR) checklist and guide. BMJ Br Med J. 2014;348(mar07 3):g1687.
Chan A-W, Tetzlaff JM, Gøtzsche PC, Altman DG, Mann H, Berlin JA, Dickersin K, Hróbjartsson A, Schulz KF, Parulekar WR, et al. SPIRIT 2013 explanation and elaboration: guidance for protocols of clinical trials. BMJ Br Med J. 2013;346(jan08 15):g1698.
Ahmed K, Dauod Altaf M, Dureab F. Electronic infectious disease surveillance system during humanitarian crises in Yemen. Online J Public Health Inform. 2014;6(1):e134.
Ali MA, Ahsan Z, Amin M, Latif S, Ayyaz A, Ayyaz MN. ID-Viewer: a visual analytics architecture for infectious diseases surveillance and response management in Pakistan. Public Health. 2016;134:72–85.
Arsevska E, Rabatel J, Falala S. Web monitoring of emerging animal infectious diseases integrated in the French Animal Health Epidemic Intelligence System. PLoS ONE. 2018;13(8):e0199960.
Bakr M, Nasr M, Hazman M. Cooperative spatial decision support system for controlling animal diseases outbreaks in Egypt. Int J Adv Netw Appl. 2015;6(6):2533–41.
Bui T, Pham HM. Web-based GIS for spatial pattern detection: application to malaria incidence in Vietnam. SpringerPlus. 2016;5(1):1014.
Burkom HS, Ramac-Thomas L, Babin S, Holtry R, Mnatsakanyan Z, Yund C. An integrated approach for fusion of environmental and human health data for disease surveillance. Stat Med. 2011;30(5):470–9.
Campbell TC, Hodanics CJ, Babin SM, Poku AM, Wojcik RA, Skora JF, Coberly JS, Mistry ZS, Lewis SH. Developing open source, self-contained disease surveillance software applications for use in resource-limited settings. BMC Med Inform Decis Mak. 2012;12(1):99.
Carney RM, Ahearn SC, McConchie A, Glasner C, Jean C, Barker C, Park B, Padgett K, Parker E, Aquino E, et al. Early warning system for West Nile virus risk areas, California, USA. Emerg Infect Dis. 2011;17(8):1445–54.
Chame M, Barbosa HJC, Gadelha LMR, Augusto DA, Krempser E, Abdalla L. SISS-geo: leveraging citizen science to monitor wildlife health risks in Brazil. bioRxiv 2018.
Chen C-C, Teng Y-C, Lin B-C, Fan IC, Chan T-C. Online platform for applying space–time scan statistics for prospectively detecting emerging hot spots of dengue fever. Int J Health Geogr. 2016;15(1):155–8.
Chester K. Overview of the BioSense 2.0 system architecture. Online J Public Health Inform. 2014;6(1):58.
Claes F, Kuznetsov D, Liechti R, Von Dobschuetz S, Truong BD, Gleizes A, Conversa D, Colonna A, Demaio E, Ramazzotto S, et al. The EMPRES-i genetic module: a novel tool linking epidemiological outbreak information and genetic characteristics of influenza viruses. Database J Biol Databases Curation. 2014;2014:bau008.
Cox J, Sovannaroth S, Dy Soley L, Ngor P, Mellor S, Roca-Feltrer A. Novel approaches to risk stratification to support malaria elimination: an example from Cambodia. Malar J. 2014;13(1):371.
Deodhar S. An interactive, web-based high performance modeling environment for computational epidemiology. ACM Trans Manag Inf Syst TMIS. 2014;5(2):1–28.
Dominkovics P, Granell C, Pérez-Navarro A, Casals M, Orcau À, Caylà Joan A. Development of spatial density maps based on geoprocessing web services: application to tuberculosis incidence in Barcelona, Spain. Int J Health Geogr. 2011;10(1):62.
Erraguntla M, Freeze J, Delen D, Madanagopal K, Mayer R, Khojasteh J. Data integration and predictive analysis system for disease prophylaxis. In: Proceedings of the 50th Hawaii international conference on system sciences. 2017. p. 1132–1141.
Evans B, Sabel CE. Open-source web-based geographical information system for health exposure assessment. Int J Health Geogr. 2012;11:2.
Fahnrich C, Denecke K, Adeoye O, Benzler J, Claus H, Kirchner G, Mall S, Richter R, Schapranow MP, Schwarz N, et al. Surveillance and Outbreak Response Management System (SORMAS) to support the control of the Ebola virus disease outbreak in West Africa. Eurosurveillance. 2015;20(12):21071.
Ferrè N, Mulatti P, Mazzucato M, Lorenzetto M, Trolese M, Pandolfo D, Vio P, Sitta G, Marangon S. GeoCREV: veterinary geographical information system and the development of a practical sub-national spatial data infrastructure. Geospat Health. 2011;5(2):275–83.
Foley DH, Wilkerson RC, Birney I, Harrison S, Christensen J, Rueda LM. MosquitoMap and the Mal-area calculator: new web tools to relate mosquito species distribution with vector borne disease. Int J Health Geogr. 2010;9(1):11.
Gao S, Mioc D, Anton F, Yi X, Coleman DJ. Online GIS services for mapping and sharing disease information. Int J Health Geogr. 2008;7(1):8.
Gesteland PH, Livnat Y, Galli N, Samore MH, Gundlapalli AV. The EpiCanvas infectious disease weather map: an interactive visual exploration of temporal and spatial correlations. J Am Med Inform Assoc JAMIA. 2012;19(6):954–9.
Guo D, Zhu Y, Yin W. OSCAR: a framework to integrate spatial computing ability and data aggregation for emergency management of public health. GeoInformatica. 2017;2017:1–28.
Hernández-Ávila JE, Rodriguez MH, Santos-Luna R, Sánchez-Castañeda V, Román-Pérez S, Ríos-Salgado VH, Salas-Sarmiento JA. Nation-wide, web-based, geographic information system for the integrated surveillance and control of dengue fever in Mexico. PLoS One. 2013;8(8):e70231.
Iannetti S, Savini L, Palma D, Calistri P, Natale F, Giovannini A. An integrated web system to support veterinary activities related to the management of information in epidemic emergencies. Epidemiol Sante Anim. 2011;60(59/60):49–51.
Ivorra B, Ngom D, Ramos Á. Be-CoDiS: a mathematical model to predict the risk of human diseases spread between countries—validation and application to the 2014–2015 Ebola virus disease epidemic. Bull Math Biol. 2015;77(9):1668–704.
Janies DA, Voronkin IO, Das M, Hardman J, Treseder TW, Studer J. Genome informatics of influenza A: from data sharing to shared analytical capabilities. Anim Health Res Rev Conf Res Workers Anim Dis. 2010;11(1):73–9.
Janies DA, Treseder T, Alexandrov B, Habib F, Chen JJ, Ferreira R, Çatalyürek Ü, Varón A, Wheeler WC. The Supramap project: linking pathogen genomes with geography to fight emergent infectious diseases. Cladistics. 2011;27(1):61–6.
Jardine A, Mullen N, Gudes O, Cosford J, Moncrieff S, West G, Xiao J, Yun G, Someford P. Web-based geo-visualisation of spatial information to support evidence-based health policy: a case study of the development process of HealthTracks. Health Inf Manag. 2014;43(2):7–16.
Jombart T, Aanensen DM, Baguelin M, Birrell P, Cauchemez S, Camacho A, Colijn C, Collins C, Cori A, Didelot X, et al. OutbreakTools: a new platform for disease outbreak analysis using the R software. Epidemics. 2014;7:28–34.
Joshi A, de Araujo Novaes M, Machiavelli J, Iyengar S, Vogler R, Johnson C, Zhang J, Hsu CE. A human centered GeoVisualization framework to facilitate visual exploration of telehealth data: a case study. Technol Health Care. 2012;20(6):457–71.
Kelly GC, Tanner M, Vallely A, Clements A. Malaria elimination: moving forward with spatial decision support systems. Trends Parasitol. 2012;28(7):297–304.
Kienberger S, Hagenlocher M, Delmelle E, Casas I. A WebGIS tool for visualizing and exploring socioeconomic vulnerability to dengue fever in Cali, Colombia. Geospat Health. 2013;8(1):313–6.
Kling A, Hebing K, Grünewald M, Hulth A. Two years of computer supported outbreak detection in Sweden: the user’s perspective. J Health Med Inform. 2012;3(1):108.
Kshirsagar D, Savalia C, Kalyani I, Kumar R, Nayak D. Disease alerts and forecasting of zoonotic diseases: an overview. Vet World. 2013;6(11):889.
Lal A, Marshall J, Benschop J, Brock A, Hales S, Baker MG, French NP. A Bayesian spatio-temporal framework to identify outbreaks and examine environmental and social risk factors for infectious diseases monitored by routine surveillance. Spat Spatio-temporal Epidemiol. 2018;25:39–48.
Li Y-P, Fang L-Q, Gao S-Q, Wang Z, Gao H-W, Liu P, Wang Z-R, Li Y-L, Zhu X-G, Li X-L. Decision support system for the response to infectious disease emergencies based on WebGIS and mobile services in China. PloS ONE. 2013;8(1):e54842.
Li L, Xu L, Jeng HA, Naik D, Allen T, Frontini M. Creation of environmental health information system for public health service: a pilot study. Inf Syst Front. 2008;10(5):531–42.
Di Lorenzo A, Di Sabatino D, Cioci D, Conte A, Bruno R, Sauro F, Calistri P, Savini L. The Arbo-zoonet information system. Vet Ital. 2016;52:161–8.
MacDonald N, Parks D, Beiko R. SeqMonitor: influenza analysis pipeline and visualization. PLoS Curr. 2009;1:RRN1040.
Martinez-Beneito MA, Botella-Rocamora P, Zurriaga O. A kernel-based spatio-temporal surveillance system for monitoring influenza-like illness incidence. Stat Methods Med Res. 2011;20(2):103–18.
Moraga P. SpatialEpiApp: a Shiny web application for the analysis of spatial and spatio-temporal disease data. Spat Spatio-Temporal Epidemiol. 2017;23:47–57.
Nieves E, Jones J. Epi Info™: now an open-source application that continues a long and productive “life” through CDC support and funding. Pan Afr Med J. 2009;2(6):6.
Nöremark M, Widgren S. EpiContactTrace: an R-package for contact tracing during livestock disease outbreaks and for risk-based surveillance. BMC Vet Res. 2014;10(1):71.
Paolotti D, Carnahan A, Colizza V, Eames K, Edmunds J, Gomes G, Koppeschaar C, Rehn M, Smallenburg R, Turbelin C. Web-based participatory surveillance of infectious diseases: the Influenzanet participatory surveillance experience. Clin Microbiol Infect. 2014;20(1):17–21.
Parks DH, Porter M, Churcher S, Wang S, Blouin C, Whalley J, Brooks S, Beiko RG. GenGIS: a geospatial information system for genomic data. Genome Res. 2009;19(10):1896–904.
Peng S, Yang K. Designing and developing an AIDS transmission management and spatial decision support system based on GIS. JSW. 2014;9(7):1969–75.
Perez AM, Zeng D, Tseng CJ, Chen H, Whedbee Z, Paton D, Thurmond MC. A web-based system for near real-time surveillance and space-time cluster analysis of foot-and-mouth disease and other animal diseases. Prev Vet Med. 2009;91(1):39–45.
Platz M, Rapp J, Groessler M, Niehaus E, Babu A, Soman B. Mathematical modeling of spatial disease variables by spatial fuzzy logic for spatial decision support systems. Int Arch Photogramm Remote Sens Spat Inf Sci. 2014;40(8):213.
Porcasi X, Rotela CH, Introini MV, Frutos N, Lanfri S, Peralta G, De Elia EA, Lanfri MA, Scavuzzo CM. An operative dengue risk stratification system in Argentina based on geospatial technology. Geospat Health. 2012;6(3):31–42.
Ramanathan A, Pullum LL, Hobson TC, Steed CA, Quinn SP, Chennubhotla CS, Valkova S. ORBiT: Oak Ridge biosurveillance toolkit for public health dynamics. BMC Bioinform. 2015;16(17):S4.
Ramirez-Ramirez LL, Gel YR, Thompson M, de Villa E, McPherson M. A new surveillance and spatio-temporal visualization tool SIMID: SIMulation of infectious diseases using random networks and GIS. Comput Methods Programs Biomed. 2013;110(3):455–70.
Rao DM, Chernyakhovsky A, Rao V. Modeling and analysis of global epidemiology of avian influenza. Environ Model Softw. 2009;24(1):124–34.
Savini L, Tora S, Di Lorenzo A, Cioci D, Monaco F, Polci A, Orsini M, Calistri P, Conte A. A Web Geographic Information System to share data and explorative analysis tools: the application to West Nile disease in the Mediterranean basin. PLoS ONE. 2018;13(6):e0196429.
Schriml LM, Arze C, Nadendla S, Ganapathy A, Felix V, Mahurkar A, Phillippy K, Gussman A, Angiuoli S, Ghedin E, et al. GeMInA, genomic metadata for Infectious Agents, a geospatial surveillance pathogen database. Nucleic Acids Res. 2010;38(Database issue):D754.
Sloot PMA, Coveney PV, Ertaylan G, Mueller V, Boucher CA, Bubak M. HIV decision support: from molecule to man. Philos Trans R Soc A Math Phys Eng Sci. 1898;2009(367):2691–703.
Sopan A, Noh AS-I, Karol S, Rosenfeld P, Lee G, Shneiderman B. Community Health Map: a geospatial and multivariate data visualization tool for public health datasets. Gov Inf Q. 2012;29(2):223–34.
Stein M, Rudge James W, Coker R, van Der Weijden C, Krumkamp R, Hanvoravongchai P, Chavez I, Putthasri W, Phommasack B, Adisasmito W, et al. Development of a resource modelling tool to support decision makers in pandemic influenza preparedness: the AsiaFluCap Simulator. BMC Public Health. 2012;12(1):870.
Studnicki J, Fisher JW. Determining community health status priorities in an online analytic processing (OLAP) environment. Online J Public Health Inform. 2013;5(2):210.
Sutcliffe A, de Bruijn O, Thew S, Buchan I, Jarvis P, McNaught J, Procter R. Developing visualization-based decision support tools for epidemiology. Inf Vis. 2014;13(1):3–17.
Thomas S, Tjaden N, van Den Bos S, Beierkuhnlein C. Implementing cargo movement into climate based risk assessment of vector-borne diseases. Int J Environ Res Public Health. 2014;11(3):3360–74.
Thomsen E, Deb R, Dunkley S, Coleman M, Foster G, Orlans M, Coleman M. Enhancing decision support for vector-borne disease control programs-the disease data management system. PLoS Negl Trop Dis. 2016;10(2):e0004342.
Tran A, Ippoliti C, Balenghien T, Conte A, Gely M, Calistri P, Goffredo M, Baldet T, Chevalier V. A geographical information system-based multicriteria evaluation to map areas at risk for Rift Valley fever vector-borne transmission in Italy. Transbound Emerg Dis. 2013;60(Suppl 2):14–23.
Trock SC, Burke SA, Cox NJ. Development of an influenza virologic risk assessment tool. Avian Dis. 2012;56(4s1):1058–61.
Vanmeulebrouk B, Rivett U, Ricketts A, Loudon M. Open source GIS for HIV/AIDS management. Int J Health Geogr. 2008;7(1):53.
Wangdi K, Banwell C, Gatton ML, Kelly GC, Namgay R, Clements AC. Development and evaluation of a spatial decision support system for malaria elimination in Bhutan. Malar J. 2016;15(1):180.
Yan W, Palm L, Lu X, Nie S, Xu B, Zhao Q, Tao T, Cheng L, Tan L, Dong H, et al. ISS-an electronic syndromic surveillance system for infectious disease in Rural China. PLoS ONE. 2013;8(4):e62749.
Yang W, Li Z, Lan Y, Wang J, Ma J, Jin L, Sun Q, Lv W, Lai S, Liao Y, et al. A nationwide web-based automated system for early outbreak detection and rapid response in China. West Pac Surveill Response J. 2011;2(1):10–5.
Brooke J. SUS-A quick and dirty usability scale. Usability Eval Ind. 1996;189(194):4–7.
Anderson G, Moreno-Sanchez R. Building web-based spatial information solutions around open specifications and open source software. Trans GIS. 2003;7(4):447–66.
Kulldorf M. A spatial scan statistic. Commun Stat Theory Methods. 1997;26:1481–96.
Gesteland PH, Livnat Y, Galli N, Samore MH, Gundlapalli AV. The EpiCanvas infectious disease weather map: an interactive visual exploration of temporal and spatial correlations. J Am Med Inform Assoc. 2012;19(6):954–9.
Clements AC, Pfeiffer DU. Emerging viral zoonoses: frameworks for spatial and spatiotemporal risk assessment and resource planning. Vet J. 2009;182(1):21–30.
Weiss DJ, Nelson A, Gibson HS, Temperley W, Peedell S, Lieber A, Hancher M, Poyart E, Belchior S, Fullman N, et al. A global map of travel time to cities to assess inequalities in accessibility in 2015. Nature. 2018;553(7688):333.
Buckee CO, Cardenas MIE, Corpuz J, Ghosh A, Haque F, Karim J, Mahmud AS, Maude RJ, Mensah K, Motaze NV, et al. Productive disruption: opportunities and challenges for innovation in infectious disease surveillance. BMJ Glob Health; 2018:3(1):e000538.
Gardy J, Loman N, Rambaut A. Real-time digital pathogen surveillance—the time is now. Genome Biol. 2015;16:155.
Fraser C, Donnelly CA, Cauchemez S, Hanage WP, Van Kerkhove MD, Hollingsworth TD, Griffin J, Baggaley RF, Jenkins HE, Lyons EJ, et al. Pandemic potential of a strain of influenza A (H1N1): early findings. Science (New York, NY). 2009;324(5934):1557–61.
Wiwanitkit V, Shi B, Xia S, Yang GJ, Zhou XN, Liu J. Research priorities in modeling the transmission risks of H7N9 bird flu. Infect Dis Poverty. 2013;2(1):17.
Li L, Grassly NC, Fraser C. Genomic analysis of emerging pathogens: methods, application and future trends. Genome Biol. 2014;15(11):541.
Gardy JL, Loman NJ. Towards a genomics-informed, real-time, global pathogen surveillance system. Nat Rev Genet. 2017;19:9.
Fountain-Jones NM, Pearse WD, Escobar LE, Alba-Casals A, Carver S, Davies TJ, Kraberger S, Papeş M, Vandegrift K, Worsley-Tonks K, et al. Towards an eco-phylogenetic framework for infectious disease ecology. Biol Rev. 2018;93(2):950–70.
Ge E, Haining R, Li CP, Yu Z, Waye MY, Chu KH, Leung Y. Using knowledge fusion to analyze avian influenza H5N1 in East and Southeast Asia. PloS ONE U6 - ctx_ver = Z3988-2004&ctx_enc = info%3Aofi%2Fenc%3AUTF-8&rfr_id = info:sid/summonserialssolutionscom&rft_val_fmt = info:ofi/fmt:kev:mtx:journal&rftgenre = article&rftatitle = Using + knowledge + fusion + to + analyze + avian + influenza + H5N1 + in + East + and + Southeast + Asia&rftjtitle = PloS + one&rftau = Ge%2C + Erjia&rftau = Haining%2C + Robert&rftau = Li%2C + Chi + Pang&rftau = Yu%2C + Zuguo&rftdate = 2012&rfteissn = 1932-6203&rftvolume = 7&rftissue = 5&rftspage = e29617&rft_id = info:pmid/22615729&rftexternalDocID = 22615729¶mdict = en-US U7 - Journal Article 2012, 7(5):e29617.
Destoumieux-Garzón D, Mavingui P, Boetsch G, Boissier J, Darriet F, Duboz P, Fritsch C, Giraudoux P, Le Roux F, Morand S et al: The One Health Concept: 10 Years Old and a Long Road Ahead. Frontiers in Veterinary Science 2018, 5.
Lipkin W. The changing face of pathogen discovery and surveillance. Nat Rev Microbiol. 2013;11(2):133–41.
Hill NJ, Runstadler JA. A bird’s eye view of influenza a virus transmission: challenges with characterizing both sides of a co-evolutionary dynamic. Integr Comp Biol. 2016;56(2):304–16.
Valdazo-Gonzalez B, Polihronova L, Alexandrov T, Normann P, Knowles NJ, Hammond JM, Georgiev GK, Ozyoruk F, Sumption KJ, Belsham GJ, et al. Reconstruction of the transmission history of RNA virus outbreaks using full genome sequences: foot-and-mouth disease virus in Bulgaria in 2011. PLoS ONE. 2012;7(11):e49650.
Guillot G, Mortier F, Estoup A. Geneland: a computer package for landscape genetics. Mol Ecol Notes. 2005;5(3):712–5.
Newman MEJ, Ferrario CR. Interacting epidemics and coinfection on contact networks. PLoS ONE. 2013;8(8):e71321.
Zinsstag J, Schelling E, Waltner-Toews D, Whittaker M, Tanner M: One Health: the theory and practice of integrated health approaches: CABI; 2015.
Tahsin T, Weissenbacher D, O’Connor K, Magge A, Scotch M, Gonzalez-Hernandez G. GeoBoost: Accelerating research involving the geospatial metadata of virus GenBank records. Bioinformatics. 2018;34(9):1606–8.
Tahsin T, Weissenbacher D, Rivera R, Beard R, Firago M, Wallstrom G, Scotch M, Gonzalez G. A high-precision rule-based extraction system for expanding geospatial metadata in GenBank records. J Am Med Inform Assoc JAMIA. 2016;23(5):934–41.
Taranath N, Patil SB, Patil P. Subbaraya CK: Medical decision support system for the missing data using data mining - A survey. In: 2014 International Conference on Contemporary Computing and Informatics (IC3I): 27-29 Nov. 2014 2014; 2014: 192–196.
Boulos MNK. Web GIS in practice III: creating a simple interactive map of England’s Strategic Health Authorities using Google Maps API, Google Earth KML, and MSN Virtual Earth Map Control. Int J Health Geogr. 2005;4:22–30.
Goodchild MF. Citizens as sensors: the world of volunteered geography. GeoJournal. 2007;69(4):211–21.
Kamel Boulos MN, Resch B, Crowley DN, Breslin JG, Sohn G, Burtner R, Pike WA, Jezierski E, Chuang KYS. Crowdsourcing, citizen sensing and sensor web technologies for public and environmental health surveillance and crisis management: trends, OGC standards and application examples. Int J Health Geogr. 2011;10:67.
Smolinski MS, Crawley AW, Baltrusaitis K, Chunara R, Olsen JM, Wójcik O, Santillana M, Nguyen A, Brownstein JS. Flu near you: crowdsourced symptom reporting spanning 2 influenza seasons. Am J Public Health. 2015;105(10):2124–30.
Santillana KB, John SB, Samuel VS, Eric B, Adam WC, Giuseppe C, Julia G, Josh G, Anna Z. Mauricio: comparison of crowd-sourced, electronic health records based, and traditional health-care based influenza-tracking systems at multiple spatial resolutions in the United States of America. BMC Infect Dis. 2018;18(1):403.
Joshua Q, Nicholas JL, Sophie D, Jared TS, Ettore S, Lauren C, Joseph Akoi B, Raymond K, Gytis D, Amy M et al: Real-time, portable genome sequencing for Ebola surveillance. Nature 2016, 530(7589).
Merrill J, Keeling J, Gebbie K. Toward standardized, comparable public health systems data: a taxonomic description of essential public health work. Health Serv Res. 2009;44(5):S1818.
Olsen J, Baisch MJ. An integrative review of information systems and terminologies used in local health departments. J Am Med Inform Assoc JAMIA. 2014;21(e1):e20–7.
Horsky J, Schiff GD, Johnston D, Mercincavage L, Bell D, Middleton B. Interface design principles for usable decision support: a targeted review of best practices for clinical prescribing interventions. J Biomed Inform. 2012;45(6):1202–16.
Dredger SM, Kothari A, Morrison J, Sawada M, Crighton EJ, Graham ID. Using participatory design to develop (public) health decision support systems through GIS. Int J Health Geogr. 2007;6:53.
Authors’ contributions
RB and MS have made substantial contributions to the conception and design of the study, in addition to interpretation and the editing process. EW provided valuable assistance in writing and editing the final manuscript. All authors read and approved the final manuscript.
Acknowledgements
We would like to Acknowledge Karen Jones for their help in the article identification and screening process.
Competing interests
The authors declare that they have no competing interests.
Availability of data and materials
The dataset(s) supporting the conclusions of this article is(are) included within the article (and its additional file(s)).
Consent for publication
Not applicable.
Ethical approval and consent to participate
Not applicable.
Funding
This research was supported by a fellowship from the National Library of Medicine of the National Institutes of Health under Award Number F31LM012176 to RB and R01LM012080 to MS. The content is solely the responsibility of the authors and does not necessarily represent the official views of the National Institutes of Health.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Author information
Authors and Affiliations
Corresponding author
Additional files
Additional file 1.
Full text screening summary: Full text articles reviewed for inclusion and exclusion criteria.
Additional file 2.
MMAT assessment: Articles assessed using the MMAT tool.
Additional file 3.
TIDieR assessment: Articles assessed using the TIDieR tool.
Additional file 4.
SDSS summarization: Characteristics of final SDSS selection.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Beard, R., Wentz, E. & Scotch, M. A systematic review of spatial decision support systems in public health informatics supporting the identification of high risk areas for zoonotic disease outbreaks. Int J Health Geogr 17, 38 (2018). https://doi.org/10.1186/s12942-018-0157-5
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12942-018-0157-5