
Abstract
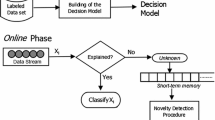
Data stream mining is an emergent research area that aims at extracting knowledge from large amounts of continuously generated data. Novelty detection (ND) is a classification task that assesses if one or a set of examples differ significantly from the previously seen examples. This is an important task for data stream, as new concepts may appear, disappear or evolve over time. Most of the works found in the ND literature presents it as a binary classification task. In several data stream real life problems, ND must be treated as a multiclass task, in which, the known concept is composed by one or more classes and different new classes may appear. This work proposes MINAS, an algorithm for ND in data streams. MINAS deals with ND as a multiclass task. In the initial training phase, MINAS builds a decision model based on a labeled data set. In the online phase, new examples are classified using this model, or marked as unknown. Groups of unknown examples can be used later to create valid novelty patterns (NP), which are added to the current model. The decision model is updated as new data come over the stream in order to reflect changes in the known classes and allow the addition of NP. This work also presents a set of experiments carried out comparing MINAS and the main novelty detection algorithms found in the literature, using artificial and real data sets. The experimental results show the potential of the proposed algorithm.

















Similar content being viewed by others


Notes
For details see (Faria et al. 2013a).
Available on http://dml.utdallas.edu/Mehedy/indexfiles/Page675.html.
We would like to thank to Eduardo Spinosa for providing the source codes.
The executable codes are available in http://dml.utdallas.edu/Mehedy/indexfiles/Page675.html.
We would like to thank the authors for providing the executable codes.
The source code is available in http://www.facom.ufu.br/~elaine/MINAS.
References
Aggarwal CC, Han J, Wang J, Yu PS (2003) A framework for clustering evolving data streams. In: Procedings of the 29th conference on very large data bases (VLDB’03), pp 81–92
Al-Khateeb T, Masud MM, Khan L, Aggarwal C, Han J, Thuraisingham B (2012a) Stream classification with recurring and novel class detection using class-based ensemble. In: Proceedings of the IEEE 12th international conference on data mining (ICDM ’12), pp 31–40
Al-Khateeb TM, Masud MM, Khan L, Thuraisingham B (2012b) Cloud guided stream classification using class-based ensemble. In: Proceedings of the 2012 IEEE 5th international conference on computing (CLOUD’12), pp 694–701
Bifet A, Holmes G, Pfahringer B, Kranen P, Kremer H, Jansen T, Seidl T (2010) MOA: massive online analysis, a framework for stream classification and clustering. J Mach Learn Res 11:44–50
Farid DM, Rahman CM (2012) Novel class detection in concept-drifting data stream mining employing decision tree. In: 7th international conference on electrical computer engineering (ICECE’ 2012), pp 630–633
Faria ER, Gama J, Carvalho ACPLF (2013) Novelty detection algorithm for data streams multi-class problems. In: Proceedings of the 28th symposium on applied computing (SAC’13), pp 795–800
Faria ER, Goncalves IJCR, Gama J, Carvalho ACPLF (2013) Evaluation methodology for multiclass novelty detection algorithms. In: 2nd Brazilian conference on intelligent systems (BRACIS’13), pp 19–25
Farid DM, Zhang L, Hossain A, Rahman CM, Strachan R, Sexton G, Dahal K (2013) An adaptive ensemble classifier for mining concept drifting data streams. Exp Syst Appl 40(15):5895–5906
Frank A, Asuncion A (2010) UCI machine learning repository. http://archive.ics.uci.edu/ml. Accessed 20 Aug 2015
Gama J (2010) Knowledge discovery from data streams, vol 1, 1st edn. CRC press chapman hall, Atlanta
Hayat MZ, Hashemi MR (2010) A DCT based approach for detecting novelty and concept drift in data streams. In: Proceedings of the international conference on soft computing and pattern recognition (SoCPaR), pp 373–378
Krawczyk B, Woźniak M (2013) Incremental learning and forgetting in one-class classifiers for data streams. In: Proceedings of the 8th international conference on computer recognition systems (CORES’ 13), advances in intelligent systems and computing vol 226, pp 319–328
Liu J, Xu G, Xiao D, Gu L, Niu X (2013) A semi-supervised ensemble approach for mining data streams. J Comput 8(11):2873–2879
Lloyd SP (1982) Least squares quantization in PCM. IEEE Trans Inf Theory 28(2):129–137
MacQueen JB (1967) Some methods of classification and analysis of multivariate observations. In: Proceedings of the 5th Berkeley symposium on mathematical statistics and probability, pp 281–297
Masud M, Gao J, Khan L, Han J, Thuraisingham BM (2011) Classification and novel class detection in concept-drifting data streams under time constraints. IEEE Trans Knowl Data Eng 23(6):859–874
Masud MM, Chen Q, Khan L, Aggarwal CC, Gao J, Han J, Thuraisingham BM (2010) Addressing concept-evolution in concept-drifting data streams. In: Proceedings of the 10th IEEE international conference on data mining (ICDM’10), pp 929–934
Naldi M, Campello R, Hruschka E, Carvalho A (2011) Efficiency issues of evolutionary k-means. Appl Soft Comput 11:1938–1952
Perner P (2008) Concepts for novelty detection and handling based on a case-based reasoning process scheme. Eng Appl Artif Intell 22:86–91
Rusiecki A (2012) Robust neural network for novelty detection on data streams. In: Proceedings of the 11th international conference on artificial intelligence and soft computing—volume part I (ICAISC’12), pp 178–186
Spinosa EJ, Carvalho ACPLF, Gama J (2009) Novelty detection with application to data streams. Intell Data Anal 13(3):405–422
Vendramin L, Campello R, Hruschka E (2010) Relative clustering validity criteria: a comparative overview. Stat Anal Data Min 3:209–235
Zhang T, Ramakrishnan R, Livny M (1996) BIRCH: an efficient data clustering method for very large databases. In: Proceedings of the ACM SIGMOD international conference on management of data, pp 103–114
Acknowledgments
This work was partially supported by Sibila and Smartgrids research projects (NORTE-07-0124-FEDER-000056/59), financed by North Portugal Regional Operational Programme (ON.2 O Novo Norte), under the National Strategic Reference Framework (NSRF), through the Development Fund (ERDF), and by national funds, through the Portuguese funding agency, Fundação para a Ciência e a Tecnologia (FCT), and by European Commission through the project MAESTRA (Grant number ICT-2013-612944). The authors acknowledge the support given by CAPES (Coordenação de Aperfeiçoamento de Pessoal de Nível Superior), CNPq (Conselho Nacional de Desenvolvimento Científico e Tecnológico) and FAPESP (Fundação de Amparo à Pesquisa do Estado de São Paulo), Brazilian funding agencies.
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible editor: Charu Aggarwal.
Appendix: Complexity analysis
Appendix: Complexity analysis
The computational cost is an important aspect to be considered in the development of ND algorithms for DSs. One of the requirements for ND algorithms is to execute only one scan in the data. This is very important because the memory is short when compared with the size of the DS.
In MINAS, the initial training phase is batch and run on a small portion of the data set. In this phase, a clustering algorithm is executed for each one of the c known classes, resulting in k micro-clusters per class.
MINAS can use two algorithms in the initial training phase, CluStream and K-Means. Using K-Means, the time complexity for each known class is \(O(k \times N \times d \times v)\), where k is the number of micro-clusters, N is the number of examples to be clustered, d is the data dimensionality and v is the maximum number of iterations of K-Means. Using the CluStream algorithm, the first step is to initialize the micro-clusters running K-Means on the first InitNumber examples. The next step associates each example to one micro-cluster. The time complexity for the execution of the K-Means for each class is \(O(k \times InitNumber \times d \times v)\). The complexity to include each example (of each class) in its closest micro-cluster is \(O(k \times d)\). If the micro-cluster can absorb the example, its statistic summary is updated. Otherwise, the two closest micro-clusters are identified, with complexity \(O(k^2 \times d)\), and merged, with time complexity O(1).
In the online phase, whenever a new example arrives, its closest micro-cluster is identified. For such, each one of the q micro-clusters that composes the decision model is consulted, with time complexity \(O(q \times d)\). The set of micro-cluster in the decision model, q, is composed by the micro-cluster learned in the initial training phase, k micro-clusters for each known class, plus micro-clusters learned online, the extensions and NPs. Regarding this sum, it is necessary to subtract the micro-clusters moved to the sleep memory over time. Although using a large number of micro-clusters allows separability between classes and representation of classes with different shapes, the classification of new examples has a higher computational cost. In addition, the maximal value of q is determined by the memory size.
For the continuous identification of NPs, examples from the short-term memory are clustered using the K-Means or CluStream algorithm, whose time complexity was previously discussed. To identify if a new micro-cluster is an extension or a new NP, its closer micro-cluster is identified, with time complexity \(O(q \times d)\). The complexity of the task of move the old micro-clusters to the sleep memory is \(O(q \times d)\).
Rights and permissions
About this article

Cite this article
de Faria, E.R., Ponce de Leon Ferreira Carvalho, A.C. & Gama, J. MINAS: multiclass learning algorithm for novelty detection in data streams. Data Min Knowl Disc 30, 640–680 (2016). https://doi.org/10.1007/s10618-015-0433-y
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10618-015-0433-y