
Abstract
Eye movements were recorded while participants discriminated upright and inverted faces that differed with respect to either configural or featural information. Two hypotheses were examined: (1) whether featural and configural information processing elicit different scanning patterns; (2) whether fixations on a specific region of the face dominate scanning patterns. Results from two experiments were compared to examine whether participants’ prior knowledge of the kind of information that would be relevant for the task (i.e., configural vs featural) influences eye movements. In Experiment 1, featural and configural discrimination trials were presented in random order such that participants were unaware of the information that would be relevant on any given trial. In Experiment 2, featural and configural discrimination trials were blocked and participants were informed of the nature of the discriminations. The results of both experiments suggest that faces elicit different scanning patterns depending on task demands. When participants were unaware of the nature of the information relevant for the task at hand, face processing was dominated by attention to the eyes. When participants were aware that relational information was relevant, scanning was dominated by fixations to the center of the face. We conclude that faces elicit scanning strategies that are driven by task demands.
Similar content being viewed by others
Introduction
Faces play an important role in human interactions and humans have a remarkable ability to recognize faces across a wide variety of conditions. While face perception has been a focus of psychological research for several decades, what information is most useful for discrimination and recognition of faces is still open to debate (for reviews see Richler, Palmeri & Gauthier, 2012, and Rossion, 2013). A popular account posits that face recognition relies more heavily on processing information derived from the relations between the features of the face than on information derived from individual features (e.g., eyes, nose, mouth) (Diamond & Carey, 1986; see reviews by Maurer et al., 2002; McKone & Robbins, 2012). Relational information is thought to be important for face recognition because faces are homogeneous and recognized at the individual level (Diamond & Carey, 1986). Different meanings and measures of relational information processing exist in the literature (reviewed by Richler et al., 2012). In this article, we adopt the term featural processing to refer to the analysis of individual features, configural to refer to the analysis of distances among individual features, (e.g., Freire, Lee, & Symons, 2000; Leder & Bruce, 2000; Rossion 2008, 2013; Taschereau-Dumouchel et al., 2010), and holistic to refer to the binding of the different face parts into an unparsed whole (e.g., Tanaka & Farah, 1993; Young, Hellawell, & Hay, 1987; see Richler et al., 2012, and Rossion, 2013, for alternative definitions). While configural information might be construed as referring to first-order relations—that is, categorizing a stimulus as a face because its features are arranged with two eyes above a nose, which is above a mouth (Maurer et al., 2002) —we use the term configural to refer exclusively to second-order relations.
Because eye location and covert attention are highly associated in complex tasks (Rayner, 2009), patterns of scanning can reveal the type of information that is critical for the viewer. Indeed, recognition performance is significantly impaired when participants are instructed to maintain fixation on a central point during encoding (between the eyes: Henderson, Williams, & Falk, 2005). One interpretation of this finding is that steady fixation impairs recognition performance because it prevents the deployment of transitional saccades between internal features. According to this interpretation, interfeatural saccades play a functional role in face processing by conveying information regarding interfeatural distances (Henderson et al., 2005). Expanding on this idea, Bombari et al. (2009) have proposed that faces elicit functionally different scanning patterns depending on the type of information that is relevant for the task at hand. They measured eye movements during matching of faces that were scrambled or blurred in order to encourage featural and configural processing, respectively (e.g., Collishaw & Hole 2000; Lobmaier & Mast, 2007). Discrimination of blurred faces elicited more interfeatural saccades than discrimination of scrambled features. In contrast, discrimination of scrambled features triggered more fixations on individual features than discrimination of blurred faces. The authors suggested that these scanning patterns reflect featural and configural processing, respectively. However, this interpretation is limited by the use of scrambled faces, where the first-order relations (Maurer et al., 2002) between face features are disrupted. As such, the differences in eye movements reported might be attributable to differences in processing first-order versus second-order relations rather than differences between featural and configural information per se.
Contrary to Bombari et al. (2009), a study by (Xu and Tanaka 2013) suggests that featural and configural processing elicit comparable scanning patterns. In their study, eye movements were recorded while participants discriminated featural and configural modifications in both upright and inverted faces. Featural and configural information processing was measured via discrimination of faces that differed with respect to small increments along a continuum for each dimension. Featural changes were made by changing the size of individual features (eyes or mouth) and configural changes were made by changing interocular distance or the position of the mouth. The authors did not find significant differences between scanning patterns elicited during featural and configural discriminations, for both upright and inverted faces. While these results appear to contradict Bombari et al. (2009), the manner in which featural and configural information was manipulated might not have adequately distinguished these two processes. Indeed, manipulating the size of individual features induced configural changes in Xu and Tanaka (2013). Furthermore, their results did not replicate the finding that inversion has a greater negative impact on performance for configural discriminations than featural discriminations (Boutet, Collin, & Faubert, 2003; Freire et al., 2000; Leder & Bruce, 2000, but see Yovel & Kanwisher, 2004). Hence, it remains to be determined whether faces elicit functionally different scanning patterns depending on whether featural or configuration information is task-relevant.
Since the seminal work by Yarbus (1967) on eye movements to faces in the 1960s, studies have reported a consistent pattern of results whereby fixations are predominantly directed to the eyes, followed by the nose, and mouth (e.g., Althoff & Cohen, 1999; Luria & Strauss, 1978; Mertens, Siegmund, & Grüsser, 1993; Stacey, Walker, & Underwood, 2005). This viewing pattern might reflect an automatic preference for the eye region because it conveys information diagnostic for identifying individual faces (e.g., Barton et al., 2006). Alternatively, focusing on the center of the face might provide diagnostic information for face identification. In Bombari et al. (2009), discrimination of intact faces elicited long fixations on the nose region, even though both featural and configural information were available. The authors proposed that this scanning pattern reflects holistic processing in that it facilitates the simultaneous capture of information across the entire face (Blais et al., 2008; Bombari et al., 2009; Miellet et al., 2011). Considering the importance of holistic information in face recognition (e.g., Boutet, Gentes-Hawn, & Chaudhuri, 2002; Richler & Gauthier, 2014; Todorov, Loehr, & Oosterhof, 2010), it is possible that faces tend to elicit fixations on the center of the stimulus irrespective of task demands.
In the present study, we investigated these hypotheses by directly manipulating the type of information relevant for the task at hand. Participants discriminated two sequentially presented faces that differed with respect to either featural information (by exchanging one feature with the corresponding feature of another face) or configural information (by moving the eyes, the nose, or the mouth of an original face) (Freire et al. 2000; Leder & Bruce, 2000). Featural and configural discriminations were made to faces presented in both upright and inverted orientation. Inverted faces are often included in studies on face processing because they offer a control condition wherein the images contain all of the same low-level information as upright faces while not being subject to the expertise that humans have developed for upright faces (see e.g., Gauthier & Bukach, 2007, for a discussion of expertise in other object categories). Furthermore, inversion has a greater negative impact on performance for configural discriminations than featural ones (e.g., Boutet et al., 2003; Freire et al., 2000; Leder & Bruce, 2000). As such, using inverted faces can provide information on whether disrupting the mechanisms that are primarily engaged during processing of upright faces influences scanning patterns (e.g., Farah et al., 1998; Gauthier and Logothetis, 2000; Rossion, 2008; Sekuler et al., 2004).
The first hypothesis we examined is whether faces elicit functionally different scanning patterns depending on the information that is relevant for the task being performed. In keeping with Bombari et al. (2009), this hypothesis would be supported if configural discriminations elicited more interfeatural saccades, and if featural discriminations elicited longer gaze duration on individual features. Moreover, if featural and configural discriminations yield different scanning patterns, then one would expect inversion to affect them differently. Indeed, because inversion disrupts performance on configural discriminations to a greater extent than featural discriminations, one would expect that inversion would diminish the number of interfeatural saccades recorded during configural discriminations. In contrast, inversion should have little impact on eye movements recorded during featural discriminations.
An alternative hypothesis is that faces will elicit fixations on a specific region of the face irrespective of task demands. While most research to date points to the eye region, fixations on the nose might instead dominate to allow the extraction of holistic information (Blais et al., 2008; Bombari et al., 2009; Miellet et al., 2011). This hypothesis would be supported if participants spent more time fixating on either the eye or nose region than on other areas of the face irrespective of whether the task-relevant information is featural or configural.
In Experiment 1, featural and configural modifications were randomly presented and participants were unaware of which type of modification was relevant on any given trial. In Experiment 2, featural and configural modifications were blocked and participants were informed of the type of modification to be discriminated. Whereas participants performed a discrimination task based on either featural or configural modifications in both experiments, in Experiment 1, the processing strategy is driven primarily by the information present in the stimuli. In Experiment 2, the processing strategy is driven both by the information present in the stimuli and by prior knowledge of which modification is relevant. To our knowledge, this is the first study to investigate whether prior knowledge of task demands influences eye movements elicited during configural and featural face processing tasks. In light of behavioral evidence suggesting that cognitive set can influence the manner in which faces are processed (Richler, Bukach, & Gauthier, 2009; Wegner & Ingvalson, 2002), we predicted that differences between configural and featural conditions, if any, would be more pronounced in Experiment 2.
Experiment 1
In Experiment 1, eye movements were recorded while participants discriminated faces that were either the same or different with respect to their individual features or their configuration. The order of presentation of the modified faces was randomized such that participants were naive regarding the nature of the relevant modification.
Method
Participants
Twenty-two participants (6 male, 16 female), aged 18-30, were recruited from the University of Ottawa undergraduate subject pool and compensated with class credits for their participation. All participants were either Caucasian or had been residing in Canada for at least 10 years. All participants had normal or corrected-to-normal vision. The University of Ottawa’s Research Ethics Board approved the study.
Stimuli and materials
Figure 1 illustrates examples of the stimuli used in this experiment. Computer-generated faces taken from the Max-Planck Institute for Biological Cybernetics face database (http://faces.kyb.tuevingen.mpg.de/) were converted to an eight-bit grayscale image using MATLAB (Version 2010a; www.mathworks.com). The faces represent young Caucasian individuals. Face stimuli were standardized for luminance and root-mean-square (RMS) contrast. Stimuli were created in the following fashion using the Adobe Photoshop software. Ten faces were cropped so that the eyes, noses, and mouths were removed from their external features. The size of the external features was averaged across the faces such that all faces subtended a viewing angle of 11° × 16. 75° at a viewing distance of 57 cm. Using this set of external features, ten different baseline faces were created using internal features from different original faces to ensure that the baseline faces and the faces that had undergone featural or configural modifications were equally realistic. Nine modified versions of each of the ten baseline faces were then created: six for the interfeatural distance (configural) modifications (three for moving the feature up and three for moving the feature down) and three for the featural modifications. Featural modifications were made by swapping the eyes, nose, and mouth of the baseline face with that of a new face. Again, the resulting faces contained sets of features that all came from different original faces. Interfeatural distance modifications were made by moving the eyes, nose, or mouth up or down by 3 mm.

An example of a baseline face (left) and the configural (upper row) and featural (bottom row) modifications applied to the eyes, nose and mouth (left to right). For the configural modifications (top row), the eyes are moved down in the left panel, the nose is moved up in the middle panel, and the mouth is moved up in the right panel. Not all possible modifications are shown here since the features could be displaced either upwards or downwards
The experiment was programmed in Experiment Builder and run on a PC comprising part of an EyeLink I000 head-mounted video-based eye tracking system (SR Research, Ottawa, ON; www.sr-research.com). This was used to record participants’ eye movements at a frequency of 500 Hz, with 0.5° spatial accuracy. Participants viewed stimuli on a 21.5-in. LCD monitor. Viewing distance was enforced at 57cm with a chin rest.
Procedure
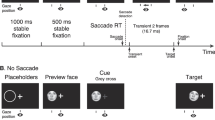
A sequential 2AFC discrimination paradigm was used. To initiate a trial, the participant had to press the spacebar. A fixation point then appeared on one side (left or right) of the screen. This remained until the participant fixed her/his gaze on it, after which the first face appeared and remained on screen for 3 s, followed by another fixation point on the same side as the previous one. The participant had to fixate on this second fixation point in order for the second face to appear. Participants responded, as quickly and as accurately as possible, by pressing a key to indicate whether the two stimuli were “same” or “different”. The second face remained on the screen until a response was made. Both faces were presented in the middle of the screen. The participants were told to complete the experiment at their own speed.
Participants were tested on two counterbalanced blocks: one block of 120 trials where the faces were upright and one block of 120 trials where the faces were inverted. Out of these 120 trials, 12 trials were randomly presented for each of the ten baseline faces. Of these 12 trials, six were same trials and six were different trials. The six same trials consisted of the sequential presentation of the same two faces. The face presented was one of the six modified versions of the baseline face: three trials presented the featural modification of the baseline face (eyes, nose, mouth) and three presented the configural modification of the baseline face (eyes moved, nose moved, mouth moved; either up or down, randomly chosen). The six different trials consisted of the presentation of the baseline face, followed by one of the six modified versions as described in the same trials. Therefore, a total of 240 trials were shown in the experiment: 2 orientations × 10 faces × 12 trials per face.
A calibration procedure preceded the experiment, wherein the participant had to fixate targets at each edge and corner of the screen. Once the eye-tracking device was calibrated, the participant began the experiment. Participants were asked to keep their heads as still as possible during the experiment. During the experiment, the eye-tracker was recalibrated as required. Prior to the practice session, participants were instructed that they would be shown two faces, one after another, and that they would have to determine whether the faces were same or different. No information regarding the nature of the change was given. This was followed by a single practice session of eight trials (four for upright faces and four for inverted faces), after which the experimenter answered any question the participant might have. This was followed by the 240 trials for the main experiment. The face used during practice was not presented in the main experiment. The entire testing session lasted about 90 min, including the calibration of the eye-tracking device.
Data analysis
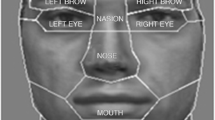
Discrimination performance was measured using both d' (Macmillan & Creelman, 2004) and response times (RTs). Only the d' data is reported here because none of the effects involving RTs were significant. Data recorded for same trials were omitted from the analysis of the eye movement data because these trials do not require participants to make a judgment based on either featural or configural information. Hence, eye movements recorded during same trials might not reflect potential differences between these two cognitive processes. Eye movements were analyzed according to three dependent variables: interfeatural saccades, gaze duration, and proportion of time spent on a given area of interest (AOI). The threshold velocity, distance, and amplitude parameters for defining saccades and fixations were based on the default parameters of the Eyelink 1000 software. An interfeatural saccade was defined as a ballistic movement between two consecutive fixations on different AOIs. Three AOIs were manually and individually defined for each face to reflect the regions of the face that had been modified: eyes (including both eyes and the nasion, or bridge of the noseFootnote 1), nose, and mouth. Interfeatural saccade counts were normalized by total exposure duration in seconds because trial duration varied based on RT. Gaze duration was defined as the sum of the durations of consecutive fixations on the same AOI, that is, the time spend on an AOI before leaving it. The data were normalized by dividing by the total fixation time for a given trial. Proportion time was defined as the percentage of a trial’s duration spent on a given AOI, regardless of whether fixations were performed consecutively in the same AOI or not. It can be regarded as a measure of the relative amount of visual attention granted to each AOI.
To reduce the effect of outliers, a procedure was applied to all dependent variables on the basis of the single-pass method of VanSelst and Jolicoeur (1994). Outliers were replaced by the corresponding winsorized score (replaced by the next highest/lowest inlying value) (Erceg-Hurn & Mirosevich, 2008). Altogether, fewer than 4% of cells were winsorized for each DV.
We analyzed behavioral and eye movement data using planned contrasts because we had defined two hypotheses to test at the onset of the experiment (Rosenthal & Rosnow, 1985). Prior to calculating contrasts, the data for the three eye movement dependent variables were analyzed using a 2 × 2 × 3 × 3 repeated-measures ANOVA with Orientation (upright, inverted), Modification Type (configural, featural), Modified Feature (eyes, nose, mouth), and AOI (eyes, nose, mouth) as variables. d' was analyzed using a 2 × 2 repeated-measures ANOVA with Orientation (upright, inverted) and Modification Type (configural, featural) as variables. The error term for the relevant interaction was then used for the contrast analyses. Considering the small number of contrasts conducted relative to the total number of possible comparisons, the alpha level was not adjusted and α = 0.05 was used as significance threshold (Rosenthal & Rosnow, 1985, p. 45). Only the results of the contrast analyses are reported here. ANOVA tables are provided in the “Appendix.” Effect sizes were measured as r (Rosenthal & Rosnow, 1985, p. 62).
While there is no convention for calculating power with a factorial repeated-measures design, we nonetheless attempted to determine whether our sample size was appropriate by using the “Repeated-Measures” function in G-power. Sample size calculated for one group, four measurements, a power of 0.8 and an effect size of 0.25 was 29. Considering that this estimate is likely to be too conservative, we feel that our sample size is adequate for the interpretation of a non-significant finding.
Results
Behavioral performance: d'
Figure 2A shows the mean d' values for discriminating configural and featural modifications in upright and inverted faces. As reported elsewhere (Freire et al., 2000; Leder & Bruce, 2000), inversion significantly impaired performance for configural [F(1, 21) = 30.82, p < 0.01, r = 0.77] and featural discriminations [F(1, 21) = 8.42, p = 0.01, r = 0.54], but the effect was stronger in the configural condition.

Performance (d') for configural and featural discriminations in upright and inverted faces for Experiment 1 (a) and Experiment 2 (b). Error bars represent ±1 SEM
Eye movements
Hypothesis 1: Do configural versus featural discriminations elicit different scanning patterns?
We tested whether featural discriminations elicited longer gaze durations on individual features than configural discriminations by contrasting the average gaze duration recorded during configural versus featural discriminations for upright and inverted faces separately (see Fig. 3). For both upright and inverted faces, featural discriminations did not elicit more mean gaze duration than configural discriminations [upright faces: F(1, 21) = 1.1, p > 0.05, r = 0.23; inverted faces: F(1, 21) < 1, p > 0.05, r = 0.17].

Experiment 1: a Mean gaze duration and b mean interfeatural saccades during featural and configural discriminations. Error bars represent ±1 SEM
We tested whether configural discriminations elicited more interfeatural saccades than featural discriminations by contrasting interfeatural saccades elicited during configural versus featural discriminations for upright and inverted faces separately. For both upright and inverted faces, configural discriminations did not elicit more interfeatural saccades than featural discriminations [upright faces: F(1, 21) < 1, r = 0.18; inverted faces: F(1, 21) < 1, r = 0.05].
Hypothesis 2: Do fixations on a specific region of the face dominate scanning patterns?
Figure 4 illustrates the mean proportion of time spent on each AOI. The figure shows that participants spent a greater proportion of time fixating on the eye region than on other areas of the face. Contrast analyses comparing the eyes to either the mouth or the nose were significant for all conditions [upright configural: eyes vs. mouth: F(1, 21) = 47.94, p < 0.01, r = 0.83; eyes vs nose: F(1, 21) = 9.49, p = 0.01, r = 0.56; upright featural: eyes vs mouth: F(1, 21) = 104.95, p < 0.01, r = 0.91; eyes vs nose F(1, 21) = 43.73, p < 0.01, r = 0.82; inverted configural: eyes vs mouth F(1, 21) = 14.23, p < 0.01, r = 0.64; eyes vs nose F(1, 21) = 5.33, p = 0.03, r = 0.45; inverted featural: eyes vs mouth: F(1, 21) = 3.02, p > 0.05; r = 0.35; eyes vs nose: F(1, 21) = 33.34, p < 0.01, r = 0.78].

Experiment 1: Mean proportion time (%) for upright and inverted test faces for the eyes, nose, mouth and other area of the face. Other is shown in the graph for informative purposes only, this AOI was not included in the analysis. Error bars represent ±1 SEM
Discussion
The behavioral data replicate previous findings on the featural/configural paradigm (Freire et al., 2000; Leder & Bruce, 2000), with inversion having a slightly greater impact on configural than featural discriminations. This finding provides evidence that our behavioral manipulation was effective in triggering different processing strategies that are specific to upright faces. The eye movement data does not support the hypothesis that configural and featural processing elicit different scanning patterns: configural discriminations were not associated with more interfeatural saccades, nor were featural discriminations associated with longer mean gaze duration. This finding is in contradiction to Bombari et al. (2009). However, in their study, featural processing was measured by scambling face parts. Their results might therefore reflect differences between processing first-order relations and second-order relations rather than differences between featural and configural information as was measured herein. In contrast, our results are consistent with Xu and Tanaka (2013), where similar scanning patterns were found irrespective of whether featural or configural information was task-relevant.
Our results support the hypothesis that fixations on one region of the face dominate scanning patterns. Participants looked at the eye region for longer periods of time than the other regions in all four experimental conditions, even if modifications to the nose and mouth were relevant in two-thirds of the trials. Furthermore, spending most time on the eyes did not prevent participants from accurately making featural and configural discriminations regarding the nose and the mouth. This result supports the importance of the eyes in face scanning (e.g., Althoff & Cohen, 1999; Walker-Smith, Gale, & Findlay, 1977; Xu & Tanaka, 2013; Yarbus, 1967) and face recognition (e.g., McKelvie, 1976; Fraser, Craig, & Parker, 1990; Haig, 1985, 1986; Tanaka & Farah, 1993; Walker-Smith, 1978).
Finally, the scanning patterns we observed with upright faces were replicated with inverted faces. Whether inversion leads to qualitative or quantitative changes in face processing is controversial (e.g., Farah et al., 1998; Gauthier & Logothetis, 2000; Rossion, 2008; Sekuler et al., 2004) and studies that have examined this issue using eye movements have yielded inconsistent results (Barton et al. 2006; Hills, Sullivan, & Pake, 2012; Hills, Cooper, & Pake, 2013; Williams & Henderson, 2007; Schwaninger, Lobmaier, & Fischer, 2005a, b; Xu & Tanaka, 2013). We focus here on Xu and Tanaka (2013) because the manipulation they used is comparable to ours. Consistent with our findings, Xu and Tanaka (2013) found that inversion does not affect eye movements made during featural versus configural discriminations differently. However, inversion diminished the number of fixations on the eyes, while increasing the number of fixations on the mouth and nose. Because the focus of this study is not on inversion, we had not planned to test this pattern of results at the onset of the study. Nonetheless, we conducted a posteriori contrasts comparing proportion of time spent on each AOI in upright vs. inverted faces. None of the analyses reached, or were close to significance. Two differences between our study and that by Xu and Tanaka (2013) might explain this discrepancy. First, in Xu and Tanaka (2013), configural changes to the eyes were made by changing the distance between the eyes; here, configural changes were made by moving the eyes up or down. This discrepancy may have lead to processing differences because focusing on the eyes only would be sufficient for detecting a change in distance between the eyes, but not for detecting a change in the position of the eyes relative to the rest of the features. Moreover, in Xu and Tanaka (2013), the predicted effect of inversion on configural versus featural discriminations was not replicated (Freire et al., 2000; Leder & Bruce, 2000), suggesting that their manipulation may have differed in some important way from that used here and in these previous studies. In the current study, inversion had a greater negative impact on discrimination of configural modifications than featural modifications, yet we did not find differences in eye movements between the two conditions. This finding further supports the notion that featural and configural discriminations do not elicit distinct scanning patterns.
Experiment 2
In Experiment 1, participants were unaware of whether featural or configural information would be relevant for the task prior to presentation of the test stimulus. It is possible that this uncertainty drove participants to adopt a scanning strategy based on information that is diagnostic in natural viewing conditions, irrespective of the information relevant for the task at hand. To test this hypothesis, we replicated Experiment 1 while presenting featural and configural discriminations in separate blocks. Participants were informed regarding the nature of the task at the onset of each block, removing uncertainty regarding which kind of information would be relevant.
Method
Participants
Twenty participants (6 male, 14 female), aged 18-30 were recruited from the University of Ottawa undergraduate subject pool and compensated with class credits for their participation. All participants were either Caucasian or had been residing in Canada for at least 10 years. All participants had normal or corrected-to-normal vision. The University of Ottawa’s Research Ethics Board approved the study.
Stimuli, materials, procedure and data analysis
The same stimuli and materials as in Experiment 1 were used in Experiment 2. The same sequential matching procedure as in Experiment 1 was used in Experiment 2 with the following exceptions. In Experiment 2, featural and configural modifications were blocked. Faces with either featural or configural modifications were presented together in a series of 120 trials: 60 trials for upright faces and 60 trials for inverted faces. As in Experiment 1, Orientation was blocked and counterbalanced. The 60 trials were divided as follows: three same trials and three different trials for each of the ten baseline faces. The experiment began with a set of verbal instructions where the participants were told that they would be shown two faces one after another and the faces might be same or different. Prior to each block, participants completed 12 practice trials where only the modification relevant for the following block (e.g., featural or configural) was shown. Participants were informed of the nature of the modification before the practice trials. After the practice trials, the experimenter answered any question the participant might have and reminded them of the relevant modification for the following experimental block.
Results
As with Experiment 1, we report focused planned contrast analyses here; complete ANOVA tables are provided in the “Appendix.”
Behavioral performance: d'
As reported in Experiment 1 and elsewhere (Freire et al., 2000; Leder & Bruce, 2000), the results of Experiment 2 are consistent with what is typically observed during featural and configural discriminations. Inversion significantly impaired performance for both configural [F(1, 19) = 102.68, p < 0.01, r = 0.92] and featural modifications [F(1, 19) = 49.90, p < 0.01, r = 0.85), and the effect was stronger in the configural condition.
Eye movements
Hypothesis 1: Do configural versus featural discriminations elicit different scanning patterns?
Figure 5 illustrates mean gaze duration and mean interfeatural saccade counts for featural and configural discriminations. For both upright and inverted faces, featural discriminations did not elicit longer gaze durations than configural discriminations [upright faces: F(1, 19) < 1, p > 0.05, r = 0.01; inverted faces: F(1, 19) < 1, p > 0.05, r = 0.04]. Moreover, configural discriminations did not elicit more interfeatural saccades than featural discriminations for both upright and inverted faces [upright faces: F(1, 19) = 1.05, p > 0.05, r = 0.22; inverted faces: F(1, 19) < 1, p > 0.05, r = 0.17].

Experiment 2: a Mean gaze duration and b mean interfeatural saccades during featural and configural discriminations. Error bars represent ±1 SEM
Hypothesis 2: Do fixations on a specific region of the face dominate scanning patterns?
Figure 6 illustrates the mean proportion of time spent on each AOI. Unlike in Experiment 1, the nose region dominated scanning patterns during configural discriminations. Contrast analyses revealed that more attention was devoted to the nose than the other features during configural discriminations of both upright faces [nose vs eyes: F(1, 19) = 5.67, p = 0.03, r = 0.48; nose vs mouth: F(1, 19) = 6.03, p = 0.02, r = 0.49] and inverted faces [nose vs eyes: F(1, 19) = 6.38, p = 0.02, r = 0.50; nose vs mouth: F(1, 19) = 10.36, p < 0.01, r = 0.60]. For featural discriminations, the results were not significant for either upright [nose vs eyes: F(1, 19) < 1, r = 0.21] nor inverted faces [nose vs eyes: F(1, 19) = 1.51, p > 0.05, r = 0.27; nose vs mouth: F(1, 19) = 1.26, p > 0.05, r = 0.25], with the exception that the nose received more attention than the mouth during upright featural discriminations [F(1, 19) = 6.43, p = 0.02, r = 0.50).

Experiment 2: Mean proportion time (%) for upright and inverted test faces for the eyes, nose, mouth and other area of the face. Other is shown in the graph for informative purposes only, this AOI was not included in the analysis. Error bars represent ±1 SEM
Discussion
In Experiment 2, we again measured eye movements while participants performed configural and featural discriminations, but the two tasks were blocked to provide prior knowledge to the participants regarding the information relevant for the task. Not surprisingly, performance in the blocked experiment was slightly superior to that in the unblocked experiment, illustrating the advantage conferred by prior knowledge of which information was task-relevant. The behavioral data yielded the expected pattern of results with inversion having a greater impact on configural than featural discriminations.
As in Experiment 1, configural and featural discriminations yielded comparable interfeatural saccades and gaze duration, even though there was no uncertainty regarding the type of information relevant for the task. This finding was consistent across upright and inverted faces. The results of Experiment 1 and 2 therefore suggest that eye movements are not functional in characterizing spatial relations between features, as suggested elsewhere (Bombari et al., 2009; Henderson et al., 2005). Nonetheless, our results do support the notion that configural and featural discriminations can yield different patterns of eye movements. In Experiment 2, fixations on the nose dominated scanning patterns for configural but not featural discriminations. Whether these different scanning patterns facilitate the processing of information diagnostic for face identification remains to be determined. One possibility is that focusing on the center of the face permits the extraction of holistic information because such a scanning pattern would allow participants to rapidly capture all of the information present in the face (Blais et al., 2008; Bombari et al., 2009; Miellet et al., 2011). While judging variations in spatial relations is generally referred to as configural processing, holistic and configural processing are closely linked in the sense that both rely more heavily on information derived from the relations between the features of the face than on information derived from individual features (see Richler & Gauthier, 2014, for a review of different mechanisms implicated in face processing; see Burton et al., 2015 for a criticism of configural processing). If fixations on the center of the face do indeed facilitate holistic processing, then our results suggest that a close link exists between these two types of information, which might explain some of the contradiction that exists in the literature regarding these two mechanisms and their behavioral manifestations (e.g., Kimchi & Amishav, 2010; McKone & Yovel, 2016; Richler, Palmeri, & Gauthier, 2015). Alternatively, focusing on the center of the face might support the processing of other types of information implicated in face recognition such as texture (e.g., Burton et al., 2015) or symmetry (Locher & Nodine, 1989). Additional studies are required to elucidate these mechanisms.
While some have suggested that holistic processing is automatic (Boutet et al., 2002; Richler & Gauthier, 2014; but see Palermo & Rhodes, 2002), our results suggest that focusing on the center of the face is not driven by the presence of a face per se but rather is contingent on task demands. Indeed, fixations on the nose did not dominate configural discriminations in Experiment 1, where participants were unaware of whether featural or configural information was relevant. Instead, fixations on the eyes dominated. Interestingly, fixations on the eyes dominated scanning patterns during featural discriminations of inverted faces in Experiment 2 as well, suggesting that when relational information disrupted, eye movements are automatically drawn to the eyes. While the scanning patterns recorded in Experiment 1 are consistent with evidence that the eyes play a dominant role in face identification (e.g., McKelvie, 1976; Fraser, Craig, & Parker, 1990; Haig, 1985, 1986; Tanaka & Farah, 1993; Walker-Smith, 1978), those recorded in Experiment 2 indicate that this is not the only route by which faces can be efficiently processed. This finding is consistent with behavioral studies demonstrating that task requirements can influence the manner in which faces are analyzed (Gao et al., 2011; Meinhardt-Injac, Persike, & Meinhardt, 2014).
General discussion
Taken together, the results of our study suggest that faces do not elicit a single pattern of eye movements but rather that different scanning strategies can be deployed depending on task demands. When the information relevant for the task was unknown (Experiment 1), attention to the eye region dominated scanning patterns. The importance of the eye region during face processing is well documented (Althoff & Cohen, 1999; Davies, Ellis, & Shepherd, 1977; McKelvie, 1976; Fraser et al., 1990; Haig, 1985, 1986; Tanaka & Farah, 1993; Walker-Smith, 1978, Xu & Tanaka, 2013; Yarbus, 1967), perhaps because this region provides diagnostic information for identification. However, the exact manner in which the eyes might facilitate recognition remains to be determined. One interpretation is that the eyes are essential for the capture of relational face information (Blais et al., 2008; Hills et al., 2013). Our findings shed doubt on this hypothesis because fixations on the nose, rather than the eyes, were linked to relational information processing. It is interesting to note that the importance of the eye region is influenced by familiarity (Barton et al., 2006), viewpoint (Bindeman, Scheepers & Burton, 2009; Royer et al., 2016), and culture (Blais et al., 2008; Brielman, Bülthoff, & Armann, 2014; Rodger et al., 2010), suggesting that which information is diagnostic for recognition might depend on either the perceptual attributes of the face or internal tendencies.
When participants were aware of the nature of the task (Experiment 2), fixations on the nose dominated during configural, but not featural, discriminations. This strategy might be adaptive in that it allows the extraction of relational information via simultaneous sampling of all the features of the face (Blais et al., 2008; Bombari et al., 2009, 2013; Miellet et al., 2011). In agreement with this interpretation, Weber et al. (2000) showed that fewer saccades are made when participants attend to the global letter than to the local letters in Navon figures. The authors suggested that fixation induces an expansion of the focus of attention to the global properties of the figure. Whether this scanning pattern is associated with other measures of relational information processing remains to be determined. In a study by Bombari et al. (2009), configural processing was associated with interfeatural saccades, presumably to extract precise information on the spatial distance between features. In the study by de Heering et al. (2008; see also Turati et al., 2010), eye movements were measured during delayed matching of composite faces that trigger holistic processing. Holistic processing was not associated with a different pattern of eye movements than feature-based processing. However, eye movements were not analyzed as a function of the different regions present in the face, making it impossible to determine whether holistic processing was linked to fixation on the nose area. In light of these contradictory findings, one cannot specify which scanning pattern, if any, affords the most effective strategy for processing relational information. Measuring eye movements while participants are viewing faces that tap into other types of information, such as composite faces for holistic encoding (Richler & Gauthier, 2014), or faces that contain only information derived from texture (Liu et al., 2005; Hancock, Burton, & Bruce, 1996), could shed light on some of these issues.
One general conclusion that can be drawn from our findings is that one must take into account task set in interpreting previous eye-tracking studies. As we have shown, providing participants prior knowledge of which information is task-relevant by blocking trials can influence scanning patterns. It has long been known that the organization of trials can affect participants’ overt response behaviors in at least two related ways. First, as already alluded to, blocking allows participants to know what kind of information will be relevant to an upcoming trial, whereas intermixing creates uncertainty. Second, blocking can induce a cognitive set in participants that focuses their attention on a subset of available information. To our knowledge, ours is the first study to find that these effects apply to eye movements during face processing. This finding implies that previous studies may have been examining different mechanisms depending on whether trials are blocked or not. Specifically, those that have used intermixed trials are likely measuring more stimulus-driven automatic processes, while those that have used blocked trials are indexing a more strategy-driven voluntary process.
One limitation of the present study rests in the use of changes in interfeatural distances to investigate relational processing. Some have questioned the ecological validity of this manipulation (Taschereau-Dumouchel et al., 2010) as well as the importance of configural information in real life face recognition (Burton et al., 2015). However, we contend that modifying interfeatural distances provides the best method for examining the suggestion that eye movements are functional in determining distances among features (Bombari et al., 2009; Henderson et al., 2005).
To conclude, our findings suggest that eye movements elicited by faces are determined by task demands and participants’ knowledge of those demands. In natural viewing conditions, when the information relevant for the task is unknown, face processing appears to be dominated by attention to eyes. In conditions where viewers are aware that relational information is relevant, scanning is dominated by fixations on the center of the face. Future studies should investigate whether these different scanning strategies can be generalized to other types of relational information, faces and viewers of other cultures, faces in different viewpoints, and faces with varying degrees of familiarity.
Notes
The eye AOI includes relational information in the sense that the horizontal spacing between the eyes is conveyed in that AOI. However, because the configural modification made to the eyes involved a vertical displacement, the information conveyed by horizontal spacing was irrelevant to the task at hand.
References
Althoff, R. R., & Cohen, N. J. (1999). Eye-movement-based memory effect: A reprocessing effect in face perception. Journal of Experimental Psychology. Learning, Memory, and Cognition, 25(4), 997–1010.
Barton, J. J. S., Radcliffe, N., Cherkasova, M. V., Edelman, J., & Intriligator, J. M. (2006). Information processing during face recognition: The effects of familiarity, inversion, and morphing on scanning fixations. Perception, 35(8), 1089–1105. doi:10.1068/p5547
Bindemann, M., Scheepers, C., & Burton, A. M. (2009). Viewpoint and center of gravity affect eye movements to human faces. Journal of Vision, 9(2), 7.1–16. doi:10.1167/9.2.7
Blais, C., Jack, R. E., Scheepers, C., Fiset, D., & Caldara, R. (2008). Culture shapes how we look at faces. PLOS ONE, 3(8), e3022. doi:10.1371/journal.pone.0003022
Bombari, D., Mast, F. W., & Lobmaier, J. S. (2009). Featural, Configural, and Holistic Face-Processing Strategies Evoke Different Scan Patterns. Perception, 38(10), 1508–1521. https://doi.org/10.1068/p6117
Bombari, D., Schmid, P. C., Schmid Mast, M., Birri, S., Mast, F. W., & Lobmaier, J. S. (2013). Emotion recognition: The role of featural and configural face information. The Quarterly Journal of Experimental Psychology, 66(12), 2426–2442. doi:10.1080/17470218.2013.789065
Boutet, I., Collin, C., & Faubert, J. (2003). Configural face encoding and spatial frequency information. Perception & Psychophysics, 65(7), 1078–1093.
Boutet, I., Gentes-Hawn, A., & Chaudhuri, A. (2002). The influence of attention on holistic face encoding. Cognition, 84(3), 321–341.
Brielmann, A. A., Bülthoff, I., & Armann, R. (2014). Looking at faces from different angles: Europeans fixate different features in Asian and Caucasian faces. Vision Research, 100, 105–112. doi:10.1016/j.visres.2014.04.011
Burton, A. M., Schweinberger, S. R., Jenkins, R., & Kaufmann, J. M. (2015). Arguments against a configural processing account of familiar face recognition. Perspectives on Psychological Science, 10(4), 482–496. doi:10.1177/1745691615583129
Collishaw, S. M., & Hole, G. J. (2000). Featural and configurational processes in the recognition of faces of different familiarity. Perception, 29(8), 893–909. doi:10.1068/p2949
Davies, G., Ellis, H., & Shepherd, J. (1977). Cue saliency in faces as assessed by the “Photofit” technique. Perception, 6(3), 263–269.
de Heering, A., Rossion, B., Turati, C., & Simion, F. (2008). Holistic face processing can be independent of gaze behaviour: Evidence from the composite face illusion. Journal of Neuropsychology, 2(1), 183–195. doi:10.1348/174866407X251694
Diamond, R., & Carey, S. (1986). Why faces are and are not special: An effect of expertise. Journal of Experimental Psychology. General, 115(2), 107–117.
Erceg-Hurn, D. M. & Mirosevich, V. M. (2008). Modern robust statistical methods: An easy way to maximize the accuracy and power of your research. American Psychologist, 63, 591-601
Farah, M. J., Wilson, K., Drain, H. M., & Tanaka, J. R., (1998). What is “special” about face perception? Psychological Review, 105, 482-498
Fraser, I. H., Craig, G. L., & Parker, D. M. (1990). Reaction time measures of feature saliency in schematic faces. Perception, 19(5), 661–673. doi:10.1068/p190661
Freire, A., Lee, K., & Symons, L. A. (2000). The face-inversion effect as a deficit in the encoding of configural information: Direct evidence. Perception, 29(2), 159–170. doi:10.1068/p3012
Gao, Z., Flevaris, A. V., Robertson, L. C., & Bentin, S. (2011). Priming global and local processing of composite faces: Revisiting the processing-bias effect on face perception. Attention, Perception, & Psychophysics, 73(5), 1477–1486. doi:10.3758/s13414-011-0109-7
Gauthier, I., & Bukach, C. (2007). Should we reject the expertise hypothesis? Cognition, 103(2), 322–330. doi:10.1016/j.cognition.2006.05.003
Gauthier, I., & Logothetis, N. K. (2000). Is face recognition not so unique after all? Cognitive Neuropsychology, 17(1), 125–142. doi:10.1080/026432900380535
Haig, N. D. (1985). How faces differ--a new comparative technique. Perception, 14(5), 601–615.
Haig, N. D. (1986). High-resolution facial feature saliency mapping. Perception, 15(4), 373–386.
Hancock, P. J. B., Burton, A. M., & Bruce, V. (1996). Face processing: Human perception and principal components analysis. Memory & Cognition, 24(1), 26–40. doi:10.3758/BF03197270
Henderson, J. M., Williams, C. C., & Falk, R. J. (2005). Eye movements are functional during face learning. Memory & Cognition, 33(1), 98–106.
Hills, P. J., Cooper, R. E., & Pake, J. M. (2013). First fixations in face processing: The more diagnostic they are the smaller the face-inversion effect. Acta Psychologica, 142(2), 211–219. doi:10.1016/j.actpsy.2012.11.013
Hills, P. J., Sullivan, A. J., & Pake, J. M. (2012). Aberrant first fixations when looking at inverted faces in various poses: The result of the centre-of-gravity effect? British Journal of Psychology (London, England: 1953), 103(4), 520–538. doi:10.1111/j.2044-8295.2011.02091.x
Kimchi, R., & Amishav, R. (2010). Faces as perceptual wholes: The interplay between component and configural properties in face processing. Visual Cognition, 18(7), 1034–1062. doi:10.1080/13506281003619986
Leder, H., & Bruce, V. (2000). When inverted faces are recognized: The role of configural information in face recognition. The Quarterly Journal of Experimental Psychology. A, Human Experimental Psychology, 53(2), 513–536. doi:10.1080/713755889.
Liu, C. H., Collin, C. A., Farivar, R., & Chaudhuri, A. (2005). Recognizing faces defined by texture gradients. Attention, Perception, & Psychophysics, 67(1), 158–167
Lobmaier, J. S., & Mast, F. W. (2007). Perception of novel faces: The parts have it! Perception, 36(11), 1660–1673. doi:10.1068/p5642
Locher, P., & Nodine, C. (1989). The perceptual value of symmetry. Computers & Mathematics with Applications, 17(4), 475–484. doi:10.1016/0898-1221(89)90246-0
Luria, S. M., & Strauss, M. S. (1978). Comparison of eye movements over faces in photographic positives and negatives. Perception, 7(3), 349–358.
Macmillan, N. A., & Creelman, C. D. (2004). Detection theory: A user’s guide. New York: Psychology Press-Routledge.
Maurer, D., Le Grand, R., & Mondloch, C. J. (2002). The many faces of configural processing. Trends in Cognitive Sciences, 6(6), 255–260.
McKelvie, S. J. (1976). The role of eyes and mouth in the memory of a face. The American Journal of Psychology, 89(2), 311–323. doi:10.2307/1421414
McKone, E., & Robbins, R. (2012). Are Faces Special. In G. Rhodes, A. Calder, M. Johnson, & J. V. Haxby (Eds.), Oxford Handbook of Face Perception (pp. 149–179). Oxford, UK: Oxford University Press
McKone, E., & Yovel, G. (2016). Why does picture-plane inversion sometimes dissociate perception of features and spacing in faces, and sometimes not? Toward a new theory of holistic processing. Psychonomic Bulletin & Review, 16(5), 778–797. doi:10.3758/PBR.16.5.778
Meinhardt-Injac, B., Persike, M., & Meinhardt, G. (2014). Holistic face perception in young and older adults: Effects of feedback and attentional demand. Frontiers in Aging Neuroscience, 6, 291. doi:10.3389/fnagi.2014.00291
Mertens, I., Siegmund, H., & Grüsser, O. J. (1993). Gaze motor asymmetries in the perception of faces during a memory task. Neuropsychologia, 31(9), 989–998.
Miellet, S., Caldara, R., & Schyns, P. G. (2011). Local Jekyll and global Hyde: The dual identity of face identification. Psychological Science, 22(12), 1518–1526. doi:10.1177/0956797611424290
Palermo, R., & Rhodes, G. (2002). The influence of divided attention on holistic face perception. Cognition, 82(3), 225–257
Rayner, K. (2009). Eye movements and attention in reading, scene perception, and visual search. The Quarterly Journal of Experimental Psychology, 62(8), 1457–1506. doi:10.1080/17470210902816461
Richler, J.J., Bukach, C.M., & Gauthier, I. (2009). Context influences holistic processing of non-face objects in the composite task. Attention, Perception & Psychophysics, 71, 530-540
Richler, J. J., Bukach, C. M., & Gauthier, I. (2016). Context influences holistic processing of non-face objects in the composite task. Attention, Perception & Psychophysics, 71, 530–540. doi:10.3758/APP.71.3.530
Richler, J. J., & Gauthier, I. (2014). A meta-analysis and review of holistic face processing. Psychological Bulletin, 140(5), 1281–1302. doi:10.1037/a0037004
Richler, J. J., Palmeri, T. J., & Gauthier, I. (2012). Meanings, mechanisms, and measures of holistic processing. Frontiers in Psychology, 3, 553. doi:10.3389/fpsyg.2012.00553
Richler, J. J., Palmeri, T. J., & Gauthier, I. (2015). Holistic processing does not require configural variability. Psychonomic Bulletin & Review, 22(4), 974–979. doi:10.3758/s13423-014-0756-5
Rodger, H., Kelly, D. J., Blais, C., & Caldara, R. (2010). Inverting faces does not abolish cultural diversity in eye movements. Perception, 39(11), 1491–1503. doi:10.1068/p6750
Rosenthal, R., & Rosnow, R. L. (1985). Contrast analysis: Focused comparisons in the analysis of variance. Cambridge: Cambridge University Press.
Rossion, B. (2008). Picture-plane inversion leads to qualitative changes of face perception. Acta Psychologica, 128, 274–289
Rossion, B. (2013). The composite face illusion: A whole window into our understanding of holistic face perception. Visual Cognition, 21(2), 139–253. doi:10.1080/13506285.2013.772929
Royer, J., Blais, C., Barnabé-Lortie, V., Carré, M., Leclerc, J., & Fiset, D. (2016). Efficient visual information for unfamiliar face matching despite viewpoint variations: it’s not in the eyes! Vision Research, 123, 33–40. doi:10.1016/j.visres.2016.04.004
Sekuler, A. B., Gaspar, C. M., Gold, J. M., & Bennett, P. J. (2004). Inversion leads to quantitative, not qualitative, changes in face processing. Current Biology, 14(5), 391–396
Schwaninger, A., Lobmaier, J. S., & Fischer, M. H. (2005a). The inversion effect on gaze perception reflects processing of component information. Experimental Brain Research, 167(1), 49–55. doi:10.1007/s00221-005-2367-x
Schwaninger, A., Lobmaier, J. S., & Fischer, M. H. (2005b). The inversion effect on gaze perception reflects processing of component information. Experimental Brain Research, 167(1), 49–55. doi:10.1007/s00221-005-2367-x
Stacey, P. C., Walker, S., & Underwood, J. D. M. (2005). Face processing and familiarity: Evidence from eye-movement data. British Journal of Psychology (London, England: 1953), 96(Pt 4), 407–422. doi:10.1348/000712605X47422
Tanaka, J. W., & Farah, M. J. (1993). Parts and wholes in face recognition. The Quarterly Journal of Experimental Psychology. A, Human Experimental Psychology, 46(2), 225–245.
Taschereau-Dumouchel, V., Rossion, B., Schyns, P. G., & Gosselin, F. (2010). Interattribute distances do not represent the identity of real world faces. Frontiers in Psychology, 1. doi:10.3389/fpsyg.2010.00159
Todorov, A., Loehr, V., & Oosterhof, N. N. (2010). The obligatory nature of holistic processing of faces in social judgments. Perception, 39(4), 514–532. doi:10.1068/p6501
Turati, C., Di Giorgio, E., Bardi, L., & Simion, F. (2010). Holistic face processing in newborns, 3-month-old infants, and adults: Evidence from the composite face effect. Child Development, 81(6), 1894–1905. doi:10.1111/j.1467-8624.2010.01520.x
Van Selst, M. & Jolicoeur, P. (1994). A solution to the effect of sample size on outlier elimination. The .Quaterly Journal of Experimental Psychology, 47, 631-650
Walker-Smith, G. J. (1978). The effects of delay and exposure duration in a face recognition task. Perception, 6, 63–70.
Walker-Smith, G. J., Gale, A. G., & Findlay, J. M. (1977). Eye movement strategies involved in face perception. Perception, 6(3), 313–326.
Weber, B., Schwarz, U., Kneifel, S., Treyer, V., & Buck, A. (2000). Hierarchical visual processing is dependent on the oculomotor system. Neuroreport, 11(2), 241–247.
Wegner, M. J., & Ingvalson, E. M. (2002). A decisional component of holistic encoding. Journal of Experimental Psychology: Learning, Memory, and Cognition, 28(5), 872–892. doi:10.1037/0278-7393.28.5.872
Williams, C. C., & Henderson, J. M. (2007). The face inversion effect is not a consequence of aberrant eye movements. Memory & Cognition, 35(8), 1977–1985.
Xu, B. & Tanaka, J. (2013). Does face inversion qualitatively change face processing: an eye movement study using a face change detection task. Journal of Vision, 13, 1-16
Yarbus, A. L. (1967). Eye movements and vision. 1967. New York.
Young, A. W., Hellawell, D., & Hay, D. C. (1987). Configurational information in face perception. Perception, 16(6), 747–759.
Yovel, G., & Kanwisher, N. (2004). Face perception: Domain specific, not process specific. Neuron, 44(5), 889–898.
Acknowledgements
This study was supported by grant from the Canadian Natural Sciences and Engineering Research Council to C.C. (no. 2015-05067). We thank Patrick Gauvreau for data collection and Dwayne Schindler for statistical consultation.
Author information
Authors and Affiliations
Corresponding author
Appendix ANOVA tables for all analyses
Appendix ANOVA tables for all analyses
Rights and permissions
About this article

Cite this article
Boutet, I., Lemieux, C., Goulet, MA. et al. Faces elicit different scanning patterns depending on task demands. Atten Percept Psychophys 79, 1050–1063 (2017). https://doi.org/10.3758/s13414-017-1284-y
Published:
Issue Date:
DOI: https://doi.org/10.3758/s13414-017-1284-y