
Abstract
Background
In Photoacoustic imaging (PAI), the most prevalent beamforming algorithm is delay-and-sum (DAS) due to its simple implementation. However, it results in a low quality image affected by the high level of sidelobes. Coherence factor (CF) can be used to address the sidelobes in the reconstructed images by DAS, but the resolution improvement is not good enough, compared to the high resolution beamformers such as minimum variance (MV). In this paper, it is proposed to use high-resolution-CF (HRCF) weighting technique in which MV is used instead of the existing DAS in the formula of the conventional CF.
Results
The higher performance of HRCF is proved numerically and experimentally. The quantitative results obtained with the simulations show that at the depth of 40 mm, in comparison with DAS+CF and MV+CF, HRCF improves the full-width-half-maximum of about 91% and 15% and the signal-to-noise ratio about 40% and 14%, respectively.
Conclusion
Proposed method provides a high resolution along with a low level of sidelobes for PAI.
Similar content being viewed by others
Background
In photoacoustic imaging (PAI), a short electromagnetic pulse, i.e. laser or radio frequency (RF), illuminates the target of imaging, and Ultrasound (US) waves are generated based on the thermoelastic effect [1, 2]. In comparison with other imaging modalities, PAI has multiple advantages leading to many investigations [3, 4]. The main incentive in PAI is having the merits of the US imaging spatial resolution and the optical imaging contrast in one imaging modality [5]. PAI can be used in different fields of study such as tumor detection [6, 7], ocular imaging [8] and functional imaging [9, 10]. Moreover, contrast agents and nanoparticles play a significant role in PAI [11, 12]. PAI can be separated into two fields: photoacoustic tomography (PAT) and photoacoustic microscopy (PAM) [13, 14]. PAT, for the first time, was successfully used as in vivo functional and structural brain imaging modality in small animals [15]. In PAT, an array of elements may be formed in linear, arc or circular shape, and mathematical reconstruction algorithms are used to obtain the optical absorption distribution map of the tissue [16–18]. Most of the used reconstruction algorithms for image formation in PAI are based on some assumptions leading to artifacts and disturbing effects on the formed photoacoustic (PA) images. One of the challenges in PA image formation is related to reduction of these effects for different number of transducers and properties of imaging media [19–21].
Some modifications should be considered if an algorithm in US imaging is going to be used in PAI. These modifications have led using different hardware to implement an integrated US-PA imaging device [22, 23]. DAS is the most commonly used beamforming algorithm in PAI. However, it leads to a low quality image, having a wide mainlobe and high level of sidelobes [24]. Adaptive beamformers, commonly employed in radar, have the ability of weighting the aperture based on the characteristics of detected signals, providing a high quality image with a wide range of off-axis signals rejection. MV can be treated as one of the commonly used adaptive methods in medical US imaging [25, 26]. Vast variety of modifications have been investigated on MV such as complexity reduction [27, 28], shadowing suppression [29], using eigenstructure to enhance MV performance [30, 31], and combination of MV and multi-line transmission (MLT) technique [32]. Matrone et al.proposed a new algorithm namely delay-multiply-and-sum (DMAS), as a beamforming technique for medical US imaging [33]. Double stage DMAS (DS-DMAS), outperforming DMAS in the terms of contrast and sidelobes, was introduced for the linear-array US and PAI [34–36]. Minimum variance-based DMAS has been proposed for resolution improvement in DMAS while the level of sidelobes would be retained [37, 38]. Coherence factor (CF) can be mentioned as one of the prevalent weighting methods in beamforming field [39]. The performance of CF has been investigated for US imaging and PAI in [40] and [41], respectively. Short-lag spatial coherence beamforming was also used to enhance the visualization of prostate brachytherapy seeds [42, 43]. Moreover, a high resolution CF (HRCF) has been investigated for high-frame rate US imaging [44]. Recently, a modified version of the CF has been reported by the authors where the aim was to achieve a higher contrast compared to the conventional CF [45].
In this paper, the performance of HRCF is investigated for linear-array PAI. The concept of this technique indicates that a high resolution image, obtained with an algorithm such as MV, can be used to weight the calculated samples instead of the formed image by DAS. It is shown that the proposed weighting algorithm (used with DAS) outperforms the DAS and MV (with/without CF) in the terms of resolution, sidelobes and contrast.
Numerical results and performance assessment
In this section, numerical results are presented to illustrate the performance of the proposed technique for PA image formation in comparison with DAS, DAS+CF, MV and MV+CF.
Simulated point targets
Simulation setup
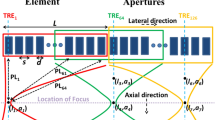
The K-wave Matlab toolbox was used to simulate the numerical study [46]. Imaging region was 20 mm in the lateral axis and 80 mm in the vertical axis. A linear-array having M=128 elements operating at 7 MHz central frequency and 77% fractional bandwidth was used to detect the PA signals generated from the defined initial pressures. The schematic of the designed simulation is shown in Fig. 1. The speed of sound was assumed to be 1540 m/s during the simulations. The sampling frequency was 50 MHz, subarray length L=M/2, K=3 and Δ=1/100L for all the simulations.

Schematic of the simulation study
Qualitative and quantitative evaluation
The reconstructed images are shown in Fig. 2, along with a zoomed version at the depth of 40 mm (shown in Fig. 3) for a better evaluation. As can be seen, the reconstructed image using DAS have a low quality along with high sidelobes. MV improves the resolution significantly, but the sidelobes still affect the image. Using CF combined with DAS or MV results in sidelobes reduction and image quality enhancement. Even though the image reconstructed by MV+CF, shown in Fig. 2d, has a high resolution, but the negative effects of the sidelobes still degrade the image quality. In Fig. 2e, it can be seen that the sidelobes are reduced compared to Fig. 2d while the resolution is retained. To assess in more details, the lateral variations of the reconstructed images shown in Fig. 2 are shown at four imaging depths in Fig. 4. As can be seen, DAS+HRCF results in lower level of sidelobes and narrower width of mainlobe compared to other beamformers. Moreover, the lateral valleys between the targets have the lowest levels using the proposed method. Consider, for instance, the depth of 50 mm where the level of sidelobes are of about -36 dB, -69 dB, -45 dB, -79 dB and -88 dB for DAS, DAS+CF, MV, MV+CF and DAS+HRCF, respectively. Thus, the proposed method leads to lowest sidelobes in comparison with other beamformers. Moreover, the levels of the lateral valleys for DAS, DAS+CF, MV, MV+CF and DAS+HRCF are about -29 dB, -61 dB, -37 dB, -70 dB and -80 dB, respectively. It indicates the higher separability of the proposed method. To evaluate the proposed method quantitatively, the full-width-half-maximum (FWHM) in -6 dB and signal-to-noise ratio (SNR) metrics are calculated and presented in Table 1 and Table 2, respectively. SNRs are calculated using the formula explained in [35]. For the axial FWHM, at the depth of 25 mm, DAS, DAS+CF, MV, MV+CF and DAS+HRCF leads to 442.7 μm, 441.0 μm, 433.2 μm, 431.7 μm and 425.1 μm, respectively.

Reconstructed images using the simulated data. a DAS, b DAS+CF, c MV, d MV+CF and e DAS+HRCF. A linear-array and point phantom were used for the numerical design. All images are shown with a dynamic range of 60 dB. Noise was added to the detected signals having a SNR of 40 dB

A close view of the reconstructed images shown in Fig. 1

Lateral variations of the reconstructed images shown in Fig. 2 at the depths of a 20 mm, b 40 mm, c 55 mm and d 70 mm
As demonstrated in Table 1, the proposed method for PA image reconstruction results in a narrower width of mainlobe in -6 dB compared to other beamformers in the all depth of imaging. Of note, there is no significant improvement compared to MV and MV+CF. Consider, in particular, the depth of 45 mm where DAS, DAS+CF, MV, MV+CF and DAS+HRCF leads to a FWHM of 2284 μm, 1388 μm, 131 μm, 131 μm and 103 μm, respectively. In comparison with a high resolution method such as MV, the proposed method leads to 28 μm FWHM improvement. As shown in Table 2, the proposed method results in a higher SNR in comparison with other reconstruction methods at the all depths of imaging. Consider, for instance, the depth of 55 mm where DAS, DAS+CF, MV, MV+CF and DAS+HRCF results in a SNR of 37.8 dB, 55.4 dB, 47.8 dB, 68.3 dB and 77.7 dB, respectively. In other words, DAS+HRCF improves the SNR for about 9 dB and 22 dB compared to MV+CF and DAS+CF, respectively, proving its superiority for linear-array PAI.
The proposed method is evaluated at the presence of high level of imaging noise. Eleven 0.1 mm radius spherical absorbers as initial pressure were positioned along the vertical axis every 5 mm beginning 25 mm from transducer surface. Noise was added to the detected signals having a SNR of 0 dB. The reconstructed images are shown in Fig. 5. As can be seen, the presence of the noise in the reconstructed images using DAS and MV degrade the images. CF results in the higher noise suppression and higher image quality, as shown in Fig. 5b and Fig. 5d. As shown in Fig. 5e, the sidelobes are better reduced using DAS+HRCF. The lateral variations for images shown in Fig. 5, at two depths of imaging, are shown in Fig. 6. As can be seen, the proposed method results in lower level of sidelobes and narrower width of mainlobe.

Reconstructed images using the simulated data. a DAS, b DAS+CF, c MV, d MV+CF and e DAS+HRCF. A linear-array and point phantom were used for the numerical design. All images are shown with a dynamic range of 60 dB. Noise was added to the detected signals having a SNR of 0 dB

Lateral variations of the reconstructed images shown in Fig. 5 at the depths of (a) 45 mm and b 55 mm
Experimental results
Experimental setup
To further evaluate the proposed weighting method and its effects on enhancing the PA images, phantom experiments were performed in which a phantom consists of 2 light absorbing wires with diameter of 150 μm were placed 1 mm apart from each other, as seen in Fig. 7. In this experiment, we utilized a Nd:YAG pulsed laser (Phocus core system, OPOTEK Inc, Carlsbad, CA, USA), with the pulse repletion rate of 30 Hz at wavelengths of 532 nm. A programmable digital ultrasound scanner (System Vantage 128,Verasonics, Inc., Kirkland, WA, USA), equipped with a linear array transducer (L11-4v, Verasonics, Inc., Kirkland, WA, USA) operating at frequency range between 4 to 9 MHz was utilized to acquire the PA RF data. A high speed FPGA was used to synchronize the light excitation and PA signal acquisition.

The schematic of the setup used for the experimental PAI
Qualitative and quantitative evaluation
The reconstructed images are shown in Fig. 8. As can be seen, the artifact and noise affect the reconstructed image by DAS while the CF improves the image quality by suppressing them. As shown in Fig. 8c, MV results in an image having a high resolution, but the presence of the noise highly affects the image. As can be seen in Fig. 8e, HRCF results in a high resolution while the sidelobes are degraded, and the presence of the noise is clearly lower than other methods, comparing the background of the Fig. 8e with other images shown in Fig. 8. To assess the images in details, the lateral variations of the two wire targets are shown in Fig. 9. As can be seen, the HRCF outperforms the conventional CF combined with DAS and MV and results in a narrower width of mainlobe and lower level of sidelobes. Consider, for instance, the depth of 24 mm where DAS+CF, MV+CF and DAS+HRCF result in -36 dB, -47 dB and -60 dB sidelobes, respectively. In other words, DAS+HRCF improves the sidelobes for about 24 dB and 13 dB compared to DAS+CF and MV+CF, respectively. To compare the experimental images quantitatively, SNRs for all the methods are calculated and presented in Table 3 where the proposed weighting method leads to a higher SNR, for both imaging targets, compared to other methods, indicating the superiority of HRCF weighting method.

Reconstructed images using the experimental detected data. a DAS, b DAS+CF, c MV, d MV+CF and e DAS+HRCF. A linear-array and wire target phantom were used for the experimental design. All images are shown with a dynamic range of 60 dB

Lateral variations of the reconstructed images obtained with DAS+CF, MV+CF and DAS+HRCF, shown in Fig 8, at the depths of a 22 mm and b 24 mm
Discussion
The main improvement gained by HRCF is having a high resolution and low sidelobes at the same time. DAS is the most commonly used beamformer in PA and US imaging which is mainly as a result of its simple implementation. Moreover, it provides a real-time imaging. However, it results in a low quality image having a low resolution and high sidelobes due to its blindness and non-adaptiveness. To put it more simply, DAS considers all the calculated samples the same as each other, and there is just a summation process. On the other hand, adaptive beamformers, such as MV, provides a higher image quality compared to DAS, especially in the term of resolution. However, in MV, sidelobes affect the reconstructed image and degrade the image quality. CF is a weighting method that can be used with beamformers, such as DAS or MV, for sidelobes reduction. However, conventional CF weighting does not improve the resolution and the width of mainlobe significantly, compared to beamformers such as MV. It can be seen that in (2), the numerator of the formula of CF is the output of DAS. While CF reduces the sidelobes, the performance of CF is not high in the term of resolution, which is mainly due to the existence of DAS on the numerator of the formula of CF. Using MV instead of the exiting DAS in the (2) can improve the resolution gained by the conventional CF (15). The proposed method, HRCF, is a weighting method which can be applied on any beamforming algorithm (DAS was used in this paper). The reconstructed images (Fig. 2 and Fig. 3) show that the HRCF outperforms CF combined with DAS and MV. As shown in Fig. 2 and Fig. 3, the point targets are better distinguished and detectable using HRCF weighting procedure, and the sidelobes are better reduced. The proposed method was evaluated in the term of the presence of high level of noise, and the reconstructed images were shown in Fig. 5. As can be seen, the HRCF reduces the negative effects of the added noise, and it provides a higher robustness compared to other methods. The images have been evaluated using the lateral variations shown in Fig. 4 and Fig. 6, and all the results indicate the superiority of HRCF in the terms of sidelobes, lateral valley and the width of mainlobe. Tables 1, 2 and 3 show the quantitative evaluation of the proposed weighting method. They indicate that the HRCF reduces the presence of the noise and results in the narrower width of mainlobe. Despite all the evaluation with the simulations, the algorithm should be evaluated using experimental data. The generated experimental images are shown in Fig. 7, and the superiority of HRCF can be clearly seen. The lateral variations of the experimental images are shown in Fig. 9, proving the higher performance of HRCF. Compared to similar method proposed in [45], modified CF (MCF), it should be noticed that the proposed method in this paper focuses on a high resolution (better than MV), providing a contrast slightly better than CF. However, MCF provides almost 50 dB lower sidelobes compared to CF, with a slightly improved resolution. It should be mentioned that the higher performance of the HRCF is obtained at the expense of the higher computational burden where replacing DAS by MV on the numerator of the formula of CF would result the order of complexity change from O(M) to O(L3). The computational time to generate images shown in Fig. 7a-e was 0.96 s, 1.09 s, 144.16 s, 145.05 s and 145.11 s, respectively. All the results indicate that the HRCF can be an effective weighting method for image formation in linear-array PAI, and it provides a higher contrast and resolution compared to DAS and MV combined with conventional CF.
Conclusions
In this paper, the HRCF was proposed as a weighting method in linear-array PAI. It was shown that there is a DAS on the numerator of the formula of CF, and it can be replaced with MV beamformer. The proposed method (HRCF) was evaluated numerically and experimentally, and it was shown that it leads to a higher image quality compared to MV and DAS (with/without CF). The quantitative results show that at the depth of 55 mm, compared to DAS+CF and MV+CF, HRCF improves the SNR of about 9 dB and 22 dB, respectively, and reduces the FWHM of about 1752 μm and 44 μm, respectively.
Methods
In this section, the concept of image reconstruction in linear-array PAI, along with the concerned algorithms in this paper, are discussed.
Beamforming In linear-array PAI, a laser illuminates the target of imaging. Then, PA signals are recorded using an US transducer. The detected signals can be used for the image formation using a beamforming algorithm. The most common beamforming algorithm in linear-array PAI is DAS. Its formula is as follows:
where yDAS(k) is the output of the beamformer, k is the time index, M is the number of elements of array, and xi(k) and Δi are the detected signals and the corresponding time delay for the detector i, respectively. To have a more efficient beamformer and improve the reconstructed image, CF can be combined with DAS [40]. The combination of DAS and CF results in sidelobes reduction and contrast enhancement. CF, as an effective weighting process, is given by:
As can be seen in (2), the argument inside the squared absolute value is the output of DAS algorithm. (1) can be simply implemented and provides a real-time PAI. However, due to the low range of the off-axis signals rejection, it leads to low quality images. The combination of DAS and CF can be written as follows:
MV can be chosen as an algorithm which provides a high resolution in PAI [47]. However, sidelobes caused by MV highly affect the image quality and degrade the contrast of the reconstructed image. The output of MV adaptive beamformer is given by:
where Xd(k) is the time-delayed array detected signals Xd(k)=[x1(k), x2(k),...,xM(k)]T, W(k)=[w1(k),w2(k),...,wM(k)]T is the beamformer weights, and (.)T and (.)H represent the transpose and the conjugate transpose, respectively. The detected array signals can be written as follows:
where s(k),i(k) and n(k) are the desired signal, interference and noise components received by the transducer, respectively. Parameters s(k) and a are the signal waveform and the related steering vector, respectively. MV bemaformer can be used to adaptively weight the calculated samples. Its goal is to achieve the optimal weights in order to estimate the desired signal as accurately as possible. The superiority of MV algorithm has been evaluated in comparison with static windows, such as Hamming window [26]. To acquire the optimal weights, signal-to-interference-plus-noise ratio (SINR) needs to be maximized:
where Ri+n and \(\sigma _{s}^{2}\) are the M×M interference-plus-noise covariance matrix and the signal power, respectively. The maximization of SINR can be gained by minimizing the output interference-plus-noise power while maintaining a distortionless response to the desired signal using following equation:
The solution of (7) is given by [48]:
In practice, the interference-plus-noise covariance matrix is unavailable. Consequently, the sample covariance matrix is used instead of the unavailable covariance matrix using N recently received samples and is given by:
Using MV in medical US imaging encounters some problems which are addressed and discussed in reference [40]. The subarray-averaging or the spatial-smoothing method can be used to achieve a better estimation of the covariance matrix using decorrelation of the coherent signals received by the array. The covariance matrix estimation using the spatial-smoothing can be written as:
where L is the subarray length, and \(\boldsymbol X_{d}^{l}(k)~=~\left [x_{d}^{l}(k),x_{d}^{l+1} (k),...,x_{d}^{l+L-1}(k)\right ]\) is the delayed input signal for the lth subarray. Due to the limited statistical information, only a few temporal samples are used to estimate the covariance matrix. Therefore, to obtain a stable covariance matrix, the diagonal loading (DL) technique is used. This method leads to replacing \(\hat {\boldsymbol R}\) by the loaded sample covariance matrix, \(\hat {\boldsymbol R_{l}}=\hat {\boldsymbol R}+\gamma \boldsymbol I\), where γ is the loading factor:
where Δ is a constant related to the subarray length. Also, the temporal averaging method can be applied along with the spatial averaging to gain resolution enhancement while the contrast is retained. The estimation of the covariance matrix using both temporal averaging and spatial smoothing in given by:
where the temporal averaging is performed over (2K+1) samples. After estimation of the covariance matrix, the optimal weights are calculated by (8) and (12). Finally, the output of MV beamformer is given by:
where W∗(k)=[w1(k),w2(k),...,wL(k)]T. Considering (2), it can be seen that the numerator of the fraction is the output of DAS beamformer, and this is why the output of the combination of DAS and CF does not have a high resolution. To put it more simply, the combination of DAS and CF does not provide a high resolution because DAS is weighted using a procedure in which DAS plays a significant role. On the other hand, using MV combined with CF weighting is a good alternative. However, as will be shown in the next section, the output of the combination of DAS and MV can be further improved using HRCF weighting procedure combined with DAS. Its formula is as follows [44, 49]:
where
In the next section, the results of the proposed method (the combination of DAS and HRCF) for PA image reconstruction is evaluated.
Abbreviations
- CF:
-
Coherence factor
- DAS:
-
Delay and sum
- DL:
-
Diagonal loading
- DMAS:
-
Delay-multiply-and-sum
- DS-DMAS:
-
Double stage delay multiply and sum
- HRCF:
-
High resolution coherence factor
- MLT:
-
Multi-line-transmission
- MV:
-
Minimum variance
- PA:
-
Photoacoustic
- PAI:
-
Photoacoustic imaging
- PAM:
-
Photoacoustic microscopy
- PAT:
-
Photoacoustic tomography
- RF:
-
Radio frequency
- SINR:
-
Signal-to-interference-plus-noise ratio
- SNR:
-
Signal to noise ratio
- US:
-
Ultrasound
References
Jeon M, Kim C. Multimodal photoacoustic tomography. IEEE Trans Multimed. 2013; 15(5):975–82.
Mehrmohammadi M, Joon Yoon S, Yeager D, Y Emelianov S. Photoacoustic imaging for cancer detection and staging. Curr Mole Imaging. 2013; 2(1):89–105.
Yao J, Wang LV. Breakthroughs in photonics 2013: Photoacoustic tomography in biomedicine. IEEE Photon J. 2014; 6(2):1–6.
Beard P. Biomedical photoacoustic imaging. Interf Focus. 2011; 1(4):602–31.
Xia J, Wang LV. Small-animal whole-body photoacoustic tomography: a review. IEEE Trans Biomed Eng. 2014; 61(5):1380–9.
Guo B, Li J, Zmuda H, Sheplak M. Multifrequency microwave-induced thermal acoustic imaging for breast cancer detection. IEEE Trans Biomed Eng. 2007; 54(11):2000–10.
Heijblom M, Steenbergen W, Manohar S. Clinical photoacoustic breast imaging: the twente experience. IEEE Pulse. 2015; 6(3):42–46.
de La Zerda A, Paulus YM, Teed R, Bodapati S, Dollberg Y, Khuri-Yakub BT, Blumenkranz MS, Moshfeghi DM, Gambhir SS. Photoacoustic ocular imaging. Opt Lett. 2010; 35(3):270–2.
Yao J, Xia J, Maslov KI, Nasiriavanaki M, Tsytsarev V, Demchenko AV, Wang LV. Noninvasive photoacoustic computed tomography of mouse brain metabolism in vivo. Neuroimage. 2013; 64:257–66.
Nasiriavanaki M., Xia J, Wan H, Bauer AQ, Culver JP, Wang LV. High-resolution photoacoustic tomography of resting-state functional connectivity in the mouse brain. Proc Natl Acad Sci. 2014; 111(1):21–6.
Qu M, Mallidi S, Mehrmohammadi M, Truby R, Homan K, Joshi P, Chen Y-S, Sokolov K, Emelianov S.Magneto-photo-acoustic imaging. Biomed Opt Express. 2011; 2(2):385–96.
Mehrmohammadi M, Oh J, Mallidi S, Emelianov SY. Pulsed magneto-motive ultrasound imaging using ultrasmall magnetic nanoprobes. Mol Imaging. 2011; 10(2):7290–2010.
Zhou Y, Yao J, Wang LV. Tutorial on photoacoustic tomography. J Biomed Opt. 2016; 21(6):061007.
Yao J, Wang LV. Photoacoustic microscopy. Laser & Photon Rev. 2013; 7(5):758–778.
Wang X, Pang Y, Ku G, Xie X, Stoica G, Wang LV. Noninvasive laser-induced photoacoustic tomography for structural and functional in vivo imaging of the brain. Nat Biotechnol. 2003; 21(7):803–6.
Xu M, Wang LV. Time-domain reconstruction for thermoacoustic tomography in a spherical geometry. IEEE Trans Med Imaging. 2002; 21(7):814–22.
Xu Y, Feng D, Wang LV. Exact frequency-domain reconstruction for thermoacoustic tomography. i. planar geometry. IEEE Trans Med Imaging. 2002; 21(7):823–8.
Xu Y, Xu M, Wang LV. Exact frequency-domain reconstruction for thermoacoustic tomography. ii. cylindrical geometry. IEEE Trans Med Imaging. 2002; 21(7):829–33.
Sheng Q, Wang K, Matthews TP, Xia J, Zhu L, Wang LV, Anastasio MA. A constrained variable projection reconstruction method for photoacoustic computed tomography without accurate knowledge of transducer responses. IEEE Trans Med Imaging. 2015; 34(12):2443–58.
Zhang C., Wang Y., Wang J.Efficient block-sparse model-based algorithm for photoacoustic image reconstruction. Biomed Sig Process Control. 2016; 26:11–22.
Omidi P, Zafar M, Mozaffarzadeh M, Hariri A, Haung X, Orooji M, Nasiriavanaki M. A novel dictionary-based image reconstruction for photoacoustic computed tomography. Appl Sci. 2018; 8(9):1570.
Mercep E, Jeng G, Morscher S, Li P-C, Razansky D. Hybrid optoacoustic tomography and pulse-echo ultrasonography using concave arrays. IEEE Trans Ultrason Ferroelectr Freq Control. 2015; 62(9):1651–61.
Harrison T, Zemp RJ. The applicability of ultrasound dynamic receive beamformers to photoacoustic imaging. IEEE Trans Ultrason Ferroelectr Freq Control. 2011; 58(10):2259–63.
Karaman M, Li P-C, O’Donnell M. Synthetic aperture imaging for small scale systems. IEEE Trans Ultrason Ferroelectr Freq Control. 1995; 42(3):429–42.
Synnevag J, Austeng A, Holm S. Adaptive beamforming applied to medical ultrasound imaging. IEEE Trans Ultrason Ferroelectr Freq Control. 2007; 54(8):1606.
Synnevag J-F, Austeng A, Holm S. Benefits of minimum-variance beamforming in medical ultrasound imaging. IEEE Trans Ultrason Ferroelectr Freq Control. 2009; 56(9):1868–79.
Asl BM, Mahloojifar A. IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control. 2012; 59(4):660–7.
Deylami AM, Asl BM. Low complex subspace minimum variance beamformer for medical ultrasound imaging. Ultrasonics. 2016; 66:43–53.
Mehdizadeh S, Austeng A, Johansen TF, Holm S. IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control. 2012; 59(4):683–93.
Asl BM, Mahloojifar A. IEEE Transactions on Ultrasonics, Ferroelectrics, and Frequency Control. 2010; 57(11):2381–90.
Mehdizadeh S, Austeng A, Johansen TF, Holm S. Eigenspace based minimum variance beamforming applied to ultrasound imaging of acoustically hard tissues. IEEE Trans Med Imaging. 2012; 31(10):1912–21.
Rabinovich A, Feuer A, Friedman Z. Multi-line transmission combined with minimum variance beamforming in medical ultrasound imaging. IEEE Trans Ultrason Ferroelectr Freq Control. 2015; 62(5):814–27.
Matrone G, Savoia AS, Caliano G, Magenes G. The delay multiply and sum beamforming algorithm in ultrasound b-mode medical imaging. IEEE Trans Med Imaging. 2015; 34(4):940–9.
Mozaffarzadeh M, Sadeghi M, Mahloojifar A, Orooji M. Double-stage delay multiply and sum beamforming algorithm applied to ultrasound medical imaging. Ultrasound Med Biol. 2018; 44(3):677–86.
Mozaffarzadeh M, Mahloojifar A, Orooji M, Adabi S, Nasiriavanaki M. Double-stage delay multiply and sum beamforming algorithm: Application to linear-array photoacoustic imaging. IEEE Trans Biomed Eng. 2018; 65(1):31–42.
Mozaffarzadeh M, Hariri A, Moore C, Jokerst JV. The double-stage delay-multiply-and-sum image reconstruction method improves imaging quality in a led-based photoacoustic array scanner. Photoacoustics. 2018; 12:22–9.
Mozaffarzadeh M, Mahloojifar A, Orooji M, Kratkiewicz K, Adabi S, Nasiriavanaki M. Linear-array photoacoustic imaging using minimum variance-based delay multiply and sum adaptive beamforming algorithm. J Biomed Opt. 2018; 23(2):026002.
Mozaffarzadeh M, Mahloojifar A, Periyasamy V, Pramanik M, Orooji M. Eigenspace-based minimum variance combined with delay multiply and sum beamformer: Application to linear-array photoacoustic imaging. IEEE J Sel Top Quantum Electron. 2019; 25(1):1–8.
Nilsen C-IC, Holm S. Wiener beamforming and the coherence factor in ultrasound imaging. IEEE Trans Ultrason Ferroelectr Freq Control. 2010; 57(6).
Asl BM, Mahloojifar A. Minimum variance beamforming combined with adaptive coherence weighting applied to medical ultrasound imaging. IEEE Trans Ultrason Ferroelectr Freq Control. 2009; 56(9):1923–31.
Paridar R, Mozaffarzadeh M, Periyasamy V, Basij M, Mehrmodammadi M, Pramanik M, Orooji M. Validation of delay-multiply-and-standard-deviation weighting factor for improved photoacoustic imaging of sentinel lymph node. J Biophoton. 2018:201800292.
Bell MAL, Kuo N, Song DY, Boctor EM. Short-lag spatial coherence beamforming of photoacoustic images for enhanced visualization of prostate brachytherapy seeds. Biomed Opt Express. 2013; 4(10):1964–77.
Pourebrahimi B, Yoon S, Dopsa D, Kolios MC. Improving the quality of photoacoustic images using the short-lag spatial coherence imaging technique. In: Photons Plus Ultrasound: Imaging and Sensing 2013: 2013. p. 85813. International Society for Optics and Photonics.
Wang S-L, Li P-C. Mvdr-based coherence weighting for high-frame-rate adaptive imaging. IEEE Trans Ultrason Ferroelectr Freq Control. 2009; 56(10).
Mozaffarzadeh M, Yan Y, Mehrmohammadi M, Makkiabadi B. Enhanced linear-array photoacoustic beamforming using modified coherence factor. J Biomed Opt. 2018; 23(2):026005.
Treeby BE, Cox BT. k-wave: Matlab toolbox for the simulation and reconstruction of photoacoustic wave fields. J Biomed Opt. 2010; 15(2):021314.
Mozaffarzadeh M, Mahloojifar A, Orooji M. Medical photoacoustic beamforming using minimum variance-based delay multiply and sum. In: SPIE Digital Optical Technologies: 2017. p. 1033522. International Society for Optics and Photonics.
Capon J. High-resolution frequency-wavenumber spectrum analysis. Proc IEEE. 1969; 57(8):1408–18.
Wang S-L, Li P-C. High frame rate adaptive imaging using coherence factor weighting and the mvdr method. In: Ultrasonics Symposium, 2008. IUS 2008. IEEE: 2008. p. 1175–8. IEEE.
Acknowledgements
Not applicable.
Funding
This study was part of a M.S. thesis supported by Tehran University of Medical Sciences; Grant NO. 97-01-30-37890.
Availability of data and materials
The datasets used and/or analysed during the current study are available from the corresponding author on reasonable request.
Author information
Authors and Affiliations
Contributions
MM has developed and evaluated the proposed algorithm, under the supervision of BM. MB has conducted the experimental studies, under the supervision of MM. In addition, all the authors has contributed to write the paper.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
Not applicable.
Consent for publication
Not applicable.
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The Creative Commons Public Domain Dedication waiver(http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated.
About this article

Cite this article
Mozaffarzadeh, M., Makkiabadi, B., Basij, M. et al. Image improvement in linear-array photoacoustic imaging using high resolution coherence factor weighting technique. BMC biomed eng 1, 10 (2019). https://doi.org/10.1186/s42490-019-0009-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s42490-019-0009-9