
Abstract
Background
Predicting survival of recipients after liver transplantation is regarded as one of the most important challenges in contemporary medicine. Hence, improving on current prediction models is of great interest.Nowadays, there is a strong discussion in the medical field about machine learning (ML) and whether it has greater potential than traditional regression models when dealing with complex data. Criticism to ML is related to unsuitable performance measures and lack of interpretability which is important for clinicians.
Methods
In this paper, ML techniques such as random forests and neural networks are applied to large data of 62294 patients from the United States with 97 predictors selected on clinical/statistical grounds, over more than 600, to predict survival from transplantation. Of particular interest is also the identification of potential risk factors. A comparison is performed between 3 different Cox models (with all variables, backward selection and LASSO) and 3 machine learning techniques: a random survival forest and 2 partial logistic artificial neural networks (PLANNs). For PLANNs, novel extensions to their original specification are tested. Emphasis is given on the advantages and pitfalls of each method and on the interpretability of the ML techniques.
Results
Well-established predictive measures are employed from the survival field (C-index, Brier score and Integrated Brier Score) and the strongest prognostic factors are identified for each model. Clinical endpoint is overall graft-survival defined as the time between transplantation and the date of graft-failure or death. The random survival forest shows slightly better predictive performance than Cox models based on the C-index. Neural networks show better performance than both Cox models and random survival forest based on the Integrated Brier Score at 10 years.
Conclusion
In this work, it is shown that machine learning techniques can be a useful tool for both prediction and interpretation in the survival context. From the ML techniques examined here, PLANN with 1 hidden layer predicts survival probabilities the most accurately, being as calibrated as the Cox model with all variables.
Trial registration
Retrospective data were provided by the Scientific Registry of Transplant Recipients under Data Use Agreement number 9477 for analysis of risk factors after liver transplantation.
Similar content being viewed by others


Background
Liver transplantation (LT) is the second most common type of transplant surgery in the United States after kidney [1]. Over the last decades, the success of liver transplants has improved survival outcome for a large number of patients suffering from chronic liver disease everywhere on earth [2]. Availability of donor organs is a major limitation especially when compared with the growing demand of liver candidates due to the enlargement of age limits. Therefore, improvement on current prediction models for survival since LT is important.
There is an open discussion about the value of machine learning (ML) versus statistical models (SM) within clinical and healthcare practice [3–7]. For survival data, the most commonly applied statistical model is the Cox proportional hazards regression model [8]. This model allows a straightforward interpretation, but is at the same time restricted to the proportional hazards assumption. On the other hand, ML techniques are assumption-free and data adaptive which means that they can be effectively employed for modelling complex data. In this article, the results between SM and ML techniques are assessed based on a 3-stage comparison: predictive performance for large sample size/large number of covariates, calibration (absolute accuracy) which is often neglected, and interpretability in terms of the most prognostic factors identified. Advantages and disadvantages for each method are detailed.
ML techniques need a precise set of operating conditions to perform well. It is important that a) the data have been adequately processed so that the inputs allow for good learning, b) modern method is applied using state-of-the-art programming software and c) proper tuning of the parameters is performed to avoid sub-optimal or default choices for parameters which downgrade the algorithm’s performance. Danger of overfitting is associated with ML approaches (as they employ complex algorithms). A note of caution is required during model training to prevent from overfitting, e.g. the selection of suitable hyper-parameters. Needless to say, overfitting might also occur with a traditional model if it is too complex (estimation of too many parameters) thus limiting generalizability outside training instances.
Neural networks have been commonly applied in healthcare. Consequently, different approaches for time-to-event endpoints are present in the literature. Biganzoli et al. proposed a partial logistic regression approach of feed forward neural networks (PLANN) for flexible modelling of survival data [9]. By using the time interval as an input in a longitudinally transformed feed forward network with logistic activation and entropy error function, they estimated smoothed discrete hazards at each time interval in the output layer. This is a well known approach for modelling survival neural networks [10]. In 2000, Xiang et al. [11] compared the performance of 3 existing neural network methods for right censored data (the Faraggi-Simon [12], the Liestol-Andersen-Andersen [13] and a modification of the Buckley-James method [14]) with Cox models in a Monte Carlo simulation study. None of the networks outperformed the Cox models and they only performed as good as Cox for some scenarios. Lisboa et al. extended the PLANN approach introducing a Bayesian framework which can perform Automatic Relevance Determination for survival data (PLANN-ARD) [15]. Several applications of the PLANN and the PLANN-ARD methods can be found in the literature [16–19]. They show potential for neural networks in systems with non-linearity and complex interactions between factors. Here extensions of the PLANN approach for big LT data are examined.
The clinical endpoint of interest for this study is overall graft-survival defined as the time between LT and graft-failure or death. Predicting survival after LT is hard as it depends on many factors and is associated with donor, transplant and recipient characteristics whose importance changes over time and per outcome measure [20]. Models that combine donor and recipient characteristics have usually better performance for predicting overall graft-survival and particularly those that include sufficient donor risk factors have better performance for long-term graft survival [21]. The aims of this manuscript can be summarised as: i) potential role of ML as a competitor of traditional methods when complexity of the data is high (large sample size, high dimensional setting), ii) identification of potential risk factors using 2 ML methods (random survival forest, survival neural networks) complementary to the Cox model, iii) use of variable selection methods to compare their predictive ability with the models including the non-reduced set of variables, iv) evaluation of predictions and goodness of fit, and v) clinical relevance of the findings (potential for medical applications).
The paper is organized as follows. “Methods” section presents details about data collection and the imputation technique, SMs and ML. Further sections discuss model training, predictive performance assessment on test data, and details about interpretability of the models. Comparisons between models based on global performance measures, prediction error curves, variable importance and calibration plots are discussed in the “Results” section. The article is concluded by the “Discussion” section about findings, limitations of this work and future perspectives. All analyses were performed in R programming language version 3.5.3 [22]. Preliminary results were presented at 40th Annual Conference of the International Society for Clinical Biostatistics [23].
Methods
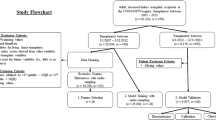
An analysis is presented on survival data after LT based on 62294 patients from the United States. Information was collected from the United Network of Organ Sharing (UNOS)Footnote 1. After extensive pre-processing from a set of more than 600 covariates, 97 variables were included in the final dataset based on clinical and statistical considerations (see Additional file 1); 52 donor and 45 liver recipient characteristics (missing values were imputed). As the UNOS data is large in both number of observations and covariates, it is of interest to see how ML algorithms - which are able to capture naturally multi-way interactions between variables and can deal with big datasets - will perform compared to Cox models. The clinical endpoint is overall graft-survival (OGS) the time between LT and graft-failure or death. The choice for this endpoint was made for two reasons 1) it is of primary interest for clinicians and 2) it is the most appropriate outcome measure to evaluate the efficacy of LT, because it incorporates both patient mortality and survival of the graft [21].
This section is divided into different subsections including the necessary components of analyses for OGS (provided in “Results” section). We discuss in detail both Cox models and ML techniques (Random Survival Forest, Survival Neural Networks). Elements of how the models were trained and how the predictive performance was assessed on the test data are presented. More technical details are provided in the supplementary material. We conclude this extensive section with a focus on methods to extract interpretation for the ML approaches.
Data collection and imputation technique
UNOS manages the Organ Procurement and Transplantation Network (OPTN) and together they collect, organise and maintain data of statistical information regarding organ transplants in the Scientific Registry of Transplant Recipients (SRTR) databaseFootnote 2. SRTR gathers data from local Organ Procurement Organisations (OPO) and from OPTN (primary source). It includes data from transplantations performed in the United States from 1988 onwards. This information is used to set priorities and seek improvements in the organ donation process.
The data provided by UNOS included 62294 patients who underwent LT surgery from 2005 to 2015 (project under DUA number 9477). Standard analysis files contained 657 variables for both donors and patients (candidates and recipients). Among these, 97 candidate risk factors - 52 donor and 45 patient characteristics - were pre-selected before carrying out analysis. This resulted in a final dataset with 76 categorical and 21 continuous variables amounting to 2.2% missing data overall. The percentage of missing values for each covariate varied from 0 to 26.61% (no missing values for 26 covariates, up to 1% missingness for 51 covariates, 1 to 10% for 11 variables, 10 to 25% for 7 variables and 25 to 26.61% for only 2 variables). Analysis on the complete case would reduce the available sample size from 62294 to 33394 patients leading to a huge waste of data. Furthermore, this could lead to invalid results (underestimation or overestimation of survival) if the excluded group of patients represents a subgroup from the entire sample [24]. To reconstruct the missing values the missForest algorithm [25] was applied for both continuous and categorical variables. This is a non-parametric imputation method that does not make explicit assumptions about the functional form of the data and builds a random forest model for each variable (500 trees were used). It specifies the model to predict missing values by using information based on the observed values. It is the most exhaustive and accurate of all random forests algorithms used for missing data imputation, because all possible variable combinations are checked as responses.
Cox proportional Hazard regression models
In survival analysis, the focus is on the time till the occurrence of the event of interest (here graft-failure or death). The Cox proportional hazards model is usually employed to estimate the effect of risk factors on the outcome of interest [8].
Data with sample size n consist of the independent observations from the triple (T,D,X) i.e. (t1,d1,x1),⋯,(tn,dn,xn). For the ith individual, ti is the survival time, di the indicator (di=1 if the event occurred and di=0 if the observation is right censored) and xi is the vector of predictors (x1,⋯,xp). The hazard function of the Cox model with time-fixed covariates is as follows:
where h(t|X) is the hazard at time t given predictor values X, h0(t) is an arbitrary baseline hazard and β=(β1,⋯,βp) is a parameter vector.
The corresponding partial likelihood can be written as:
where D is the set of failures, and R(ti) is the risk set at time ti of all individuals who are still in the study at the time just before time ti. This function is then maximised over β to estimate the model parameters.
Two other Cox models were employed 1) a Cox model with a backward elimination and 2) a penalised Cox regression with the Least Angle and Selection Operator (LASSO). Both models have been widely used for variable selection. We aim to compare these more parsimonious models versus a Cox model with all variables in terms of predictive performance. For the first, a numerically stable version of the backward elimination on factors was applied using a method based on Lawless and Singhal (1978) [26]. This method estimates the full model and computes approximate Wald statistics by computing conditional maximum likelihood estimates - assuming multivariate normality of estimates. Factors that require multiple degrees of freedom are dropped or retained as a group.
The latter approach uses a combination of selection and regularisation [27]. Denote the log-partial likelihood by ℓ(β)=logL(β). The vector β is estimated via the criterion:
with s a user specified positive parameter.
Equation (3) can also be rewritten as
The quantity \(\sum _{j = 1}^{p} |\beta _{j}| \) is also known as the L1-norm and performs regularisation to the log-partial likelihood. The term λLASSO is a non-negative constant that assigns the amount of penalisation. Larger values for the parameter mean larger penalty to the βj coefficients and enlarged shrinkage towards zero.
The tuning parameter s in Eq. (3) or equivalently parameter λLasso in Eq. (4) is the controlling mechanism for the variance of the model. Higher values reduce further the variance but introduce at the same time more bias (variance-bias trade off). To find a suitable value for this parameter 5-fold cross-validation was performed to minimise the prediction error; here in terms of the cross-validated log-partial likelihood (CVPL) [28]
where ℓ(−i)(β) is the partial log-likelihood of Eq. (2) when individual i is excluded. Therefore, the term \(\ell (\hat {\beta }_{(-i)}) - \ell _{{(-i)}}\left (\hat {\beta }_{(-i)}\right)\) represents the contribution of observation i. The value that maximizes ℓ(−i)(β(−i)) is denoted by \(\hat {\beta }_{(-i)}\).
Random forests for survival analysis
Random Survival Forests (RSFs) are an ensemble tree method for survival analysis of right censored data [29] adapted from random forests [30]. The main idea of random forests is to get a series of decision trees - which can capture complex interactions but are notorious for their high variance - and obtain a collection averaging their characteristics. In this way weak learners (the individual trees) are turned into strong learners (the ensemble) [31].
For RSFs, randomness is introduced in two ways: bootstrapping a number of patients at each tree \(\mathcal {B}\) times and selecting a subset of variables for growing each node. During growing each survival tree, a recursive application of binary splitting is performed per region (called node) on a specific predictor in such a way that survival difference between daughter nodes is maximised and difference within them is minimised. Splitting is terminated when a certain criterion is reached (these nodes are called terminal). The most commonly used splitting criteria are the log-rank test by Segal [32] and the log-rank score test by Hothorn and Lausen [33]. Each terminal node should have at least a pre-specified number of unique events. Combining information from the \(\mathcal {B}\) trees, survival probabilities and ensemble cumulative hazard estimate can be calculated using the Kaplan-Meier and Nelson-Aalen methodology, respectively.
The fundamental principle behind each survival tree is the conservation of events. It is used to define ensemble mortality, a new type of predicted outcome for survival data derived from the ensemble cumulative hazard function (comparable to the prognostic index based on the Cox model). This principle asserts that the sum of estimated cumulative hazard estimate over time is equal to the total number of deaths, therefore the total number of deaths is conserved within each terminal node \(\mathcal {H}\) [29]. RSFs can handle both data with large sample size and vast number of predictors. Moreover, they can reach remarkable stability combining the results of many trees. However, combining an ensemble of trees downgrades significantly the intuitive interpretation of a single tree.
Survival neural networks
Artificial neural networks (ANNs) are a machine learning method able to model non-linear relationships between prognostic factors with great flexibility. These systems are inspired from biological neural networks that aimed at imitating the human brain activity [34]. A ANN has a layered structure and is based on a collection of connected units called nodes or neurons which comprise a layer. The input layer picks up the signals and passes them through transformation functions to the next layer which is called “hidden”. A network may have more than one hidden layer that connects with the previous and transmit signals towards the output layer. Connections between artificial neurons are called edges. Artificial neurons and edges have a weight (connection strength) which adjusts as learning proceeds. It increases or decreases the strength of the signal of each connection according to its sign. For the purpose of training, a target is defined, which is the observed outcome. The simplest form of a NN is the single layer feed-forward perceptron with the input layer, one hidden layer and the output layer [35].
The application of NNs has been extended to survival analysis over the years [13]. Different approaches have been considered; some model the survival probability \(\mathcal {S}(t)\) directly or the unconditional probability of death \(\mathcal {F}(t)\) whereas other approaches estimate the conditional hazard h(t) [10]. They can be distinguished according to the method used to deal with the censoring mechanism. Some networks have k output nodes [36] - where k denotes k separate time intervals - while others have a single output node.
In this research, the method of Biganzoli was applied, which specifies a partial logistic feed-forward artificial neural network (PLANN) with a single output node [9]. This method uses as inputs the prognostic factors and the survival times to increase the predictive ability of the model. Data have to be transformed into a longitudinal format with the survival times being divided into a set of k non-overlapping intervals (months or years) Ik=(τk−1,τk], with 0=τo<τ1<⋯<τk a set of pre-defined time points. In this way, the time component of survival data is taken into consideration. On the training data, each individual is repeated for the number of intervals he/she was observed in the study and on the test data for all time intervals. PLANN provides the discrete conditional probability of dying \(\mathcal {P}\left (T \in I_{k} \mid T>\tau _{k-1}\right)\) using as transformation function of both input and output layers the logistic (sigmoid) function:
where \(\eta = \sum _{i = 1}^{p}w_{i} X_{i}\) is the summed linear combination of the weights wi of input-hidden layer and the input variables Xi (i=1,2,⋯,p).
The contribution to the log-likelihood for each individual is calculated all over the intervals one is at risk. The output node is a large target vector with 0 if the event did not occur and 1 if the event occurred in a specific time interval. Therefore, such a network first estimates the hazard for each interval hk=P(τk−1<T≤τk|T>τk−1) and then \(S(t) = \prod _{k: t_{k} \leq t} (1 - h_{k})\).
In this work, novel extensions in the specification of the PLANN are tested. Two new transformation functions were investigated for the input-hidden layer the rectified linear unit (ReLU)
which is the most used activation function for NNs and the hyperbolic tangent (tanh)
These functions can be seen as different modulators of the degree of non-linearity implied by the input and the hidden layer.
The PLANN was expanded in 2 hidden layers with same node size and identical activation functions for input-hidden 1 and hidden 1 - hidden 2 layers. The k non-overlapping intervals of the survival times were treated as k separate variables. In this way, the contribution of each interval to the predictions of the model using the relative importance method by Garson [37] and its extension for 2 hidden layers can be obtained (see “Interpretability of the models” section below and Additional file 1).
Model training
The split sample approach was employed; data was split randomly into two complementary parts, a training set (2/3) and a test set (1/3) under the same event/censoring proportions. To tune a model, 5-fold cross validation was performed in the training set for the machine learning techniques (and for Cox LASSO). Training data was divided into 5 folds. Each time 4 folds were used to train a model and the remaining fold was used to validate its performance and the procedure was repeated for all combination of folds. Tuning of the hyper-parameters was done using grid search and performance of final models was assessed on the test set. Analyses were performed in R programming language version 3.5.3 [22]. Package of implementation for RSFs and NNs as well as technical details regarding the choice of tuning parameters and the cross-validation procedure for each method are provided in Additional File 2.
Assessing predictive performance on test data
To assess the final predictive performance of the models the concordance index, the Brier score, and the Integrated Brier Score (IBS) were applied.
The most popular measure of model performance in a survival context is the concordance index [38] which computes the proportion of pairs of observations for which the survival times and model predictions order are concordant taking into account censoring. It takes values typically in the range 0.5 - 1 with higher values denoting higher ability of the model to discriminate and 0.5 indicating no discrimination. The C-index cannot be defined for neural network models since it relies on the ordering of individuals according to prognosis and there is no unique ordering between the subjects. At one year individual i may have better survival probability than individual j, but this could be reversed for a different time point.
The C-index provides a rank statistic between the observations that is not time-dependent. Following van Houwelingen and le Cessie [39] a time-dependent prediction error is defined as
where \(\hat {S}(t_{0}|x)\) is the model-based probabilistic prediction for the survival of an individual beyond t0 given the predictor x, and y=1{t>t0} is the actual observation ignoring censoring. The expected value with respect to a new observation Ynew under the true model S(t0|x) can be written as:
The Brier Score consists of two components: the “true variation” S(t0|x)(1−S(t0|x)) and the error due to the model \((S(t_{0}|x) - \hat {S}(t_{0}|x))^{2}\). A perfect prediction is only possible if S(t0|x)=0 or S(t0|x)=1. In practice the two components cannot be separated since the true S(t0|x) is unknown.
To assess the performance of a prediction rule in actual data, censored observations before time t0 must be considered. To calculate Brier Score when censored observations are present, Graf proposed the use of inverse probability of censoring weighting [40]. Then an estimate of the average prediction error of the prediction model \(\hat {S}(t|x)\) at time t=t0 is
In (11), \(\frac {1}{\hat {C}(\min (t_{i}-, t_{0}) | x_{i})} \) is a weighting scheme known as inverse probability of censoring weighting (IPCW) and Score is the Brier Score for the prediction model. It ranges typically from 0 to 0.25 with a lower value meaning smaller prediction error.
Brier score is calculated at different time-points. An overall measure of prediction error is the Integrated Brier Score (IBS) which can be used to summarise the prediction error over the whole range up to the time horizon \(\int _{0}^{t_{hor}}Err_{Score}(\hat {S}, t_{0})dt_{0}\) (here thor = 10 years) [41]. IBS provides the cumulative prediction error up to thor at all available times (t∗= 1, 2, ⋯, 10 years) and takes values in the same range as the Brier score. In this study, we use IBS as the main criterion to evaluate the predictive ability of all models up to 10 years.
Interpretability of the models
Interpretation of models is of great importance for the medical community. It is well known that Cox models offer a straightforward interpretation through hazard ratios.
For neural networks with one hidden layer the connection weights algorithm by Garson [37] – later modified by Goh [42] – can provide information about the mechanism of the weights. The idea behind this algorithm is that inputs with larger connection weights produce greater intensities of signal transfer. As a result, these inputs will be more important for the model. Garson’s algorithm can be used to determine relative importance of each input variable, partitioning the weights in the network. Their absolute values are used to specify percentage of importance. Note that the algorithm does not provide the direction of relationships, so it remains uncertain whether the relative importance indicates a positive or a negative effect. For details about the algorithm see [43]. During this work, the algorithm was extended for 2 hidden layers to obtain the relative importance of each variable (for the implementation see algorithm 1 in Additional file 1).
Random survival forest relies on two methods which can provide interpretability: variable importance (VIMP) and minimal depth [44]. The former is associated with the prediction error before and after the permutation of a prognostic factor. Large importance values indicate variables with strong predictive ability. The latter is related to the forest topology as it assesses the predictive value of a variable by computing its depth compared to the root node of a tree. VIMP is more frequently reported than minimal depth in the literature [45]. For both methods interpretation is available only for variable entities and not for each variable level.
Results
Administrative censoring was applied to the UNOS data at 10 years. Median follow-up is equal to 5.36 years (95% CI: 5.19 - 5.59 years) and it was estimated with reverse Kaplan-Meier [46]. Clinical endpoint is overall graft-survival (OGS). From the total number of patients, 69.1% was alive/censored and 30.9% experienced the event of interest (graft-failure or death). 3 models were used from the Cox family to predict survival outcome: a) a model with all 97 prognostic factors, b) a model with backward selection and c) a model based on the LASSO method for variable selection. Furthermore, 3 machine learning methods were employed: a) a random survival forest, b) a NN with one hidden layer and c) a NN with two hidden layers.
Comparisons between models
In this section a direct comparison of the 6 models is illustrated in terms of variable importance on the training set and predictive performance on the test set. Specification of the variables with dummy coding included 119 variable levels from the 97 potentially prognostic factors. For NNs - to apply and extend the methodology of Biganzoli - follow-up time was divided into 10 time intervals (0,1],(1,2],⋯, (9,10] denoting years since transplantation. For Cox models and RSF exact time points were used.
Cox model assumes that each covariate has a multiplicative effect in the hazard function (which is constant over time). Estimating a model with 97 prognostic factors leads inevitably to a violation of the proportional hazards assumption for some covariates (17 out of 97 here). This means that hazard ratios for those risk factors are the mean effects on the outcome which is still a valuable information for the clinicians. To consider all possible non-linear effects on interactions leads to a complex model where too many parameters need to be estimated and the interpretability becomes very difficult. On the other hand, ML techniques do not make any assumptions about the data structure and therefore their performance is not affected by the violation of PH. The backward and the LASSO methods selected 28 (out of 97) and 45 predictors (out of 119 dummy coded), respectively. Selection of a smaller set of variables by Cox backward was expected, since it is a greedier (heuristic) method than LASSO penalized regression. The 12 most influential variables for the Cox model with all variables were selected by both methods (see Table 2). 5 of these variables: re-transplantation, donor type, log(Total cold ischemic time), diabetes and pre-treatment status violated the PH assumption.
5-fold cross-validation in the training data resulted in the following optimal hyper-parameters combinations for the machine learning techniques:
-
For the Random Survival Forest nodesize = 50, mtry = 12, nsplit = 5 and ntree = 300. Stratified bootstrap sub-sampling of half the patients was used per tree (due to the large training time required).
-
For the neural network with 1 hidden layer activation function = “sigmoid” (for the input-hidden layer), node size = 85, dropout rate = 0.2, learning rate = 0.2, momentum = 0.9 and weak class weight = 1.
-
For the neural network with 2 hidden layers activation function = “sigmoid” (for the input-hidden 1 and the hidden 1-hidden 2 layers), node size = 110, dropout rate = 0.1, learning rate = 0.2, momentum = 0.9 and weak class weight = 1.
Global performance measures
The global performance measures on test data are provided in Table 1. Examining the Integrated Brier Score (IBS), the NNs with 1 and with 2 hidden layers have the lowest (IBS = 0.180) followed by the RSF (IBS = 0.182). Cox models have a comparable performance (IBS = 0.183). Therefore, the predictive ability of Cox backward and Cox LASSO is the same as the less parsimonious Cox model with all variables in terms of IBS. The best model in terms of C-index is the Random Survival Forest (0.622) while the Cox models with all variables has slightly worse performance. C-index for Cox backward and Cox LASSO are respectively 0.615 and 0.614.
Stability of the networks was investigated by rerunning the same models on the test data, and showed that the NN with 1 hidden layer had stable predictive performance and variable importance. In contrast, the NN with 2 hidden layers was quite unstable regarding variable importance. This behavior might be related to the vast amount of weights that had to be trained for this model which can lead to overfitting (in total 26621 connection weights were estimated for a sample size of 41530 patients in long format; whereas for the NN with 1 hidden layer 11136 connection weights). For the RSF, model obtained remarkable stability in terms of performance error after a particular number of trees (ntree = 300 was selected).
Prediction error curves
Figure 1 shows the average prediction Brier error over time for all models. Small differences can be observed between Cox models and RSF. The NNs with 1 hidden and with 2 hidden layers have almost identical evolution over time achieving better performance than the Cox models and the RSF.

Prediction error curves for all models
Variable importance
In this section, the models are compared based on the most prognostic variables identified from the set of 97 predictors - 52 donor and 45 recipient characteristics. Hazard ratios of the 12 most prognostic variables for the Cox models are shown in Table 2, based on the absolute z-score values for the Cox model with all variables. The strongest predictor is re-transplantation. Having been transplanted before increases the hazard of graft-failure or death by more than 55%. The other most detrimental variables are donor age and donor type circulatory dead. One unit increase for donor age rises the hazard by around 1% while having received the graft from a donor circulatory versus brain-dead increases the hazard by more than 29% for all models. The rest of the factors which have an adverse effect are: cold ischemic time, diabetes, race, life-support, recipient age, incidental tumour, spontaneous hypertensive bleeding, serology status of HCV and intense care unit before the operation.
In Table 3 the most prognostic factors for the machine learning techniques are presented. The top predictors are provided in terms of relative importance (Rel-Imp) for the PLANN models and in terms of variable importance (VIMP) for the RSF. For the NNs, the strongest predictor is re-transplantation (Rel-Imp 0.035 for 1 hidden and 0.028 for 2 hidden layers), which is the second strongest for the RSF (VIMP 0.009). According to the tuned RSF, the most prognostic factor for the overall graft-survival of the patient is donor age (VIMP 0.010).
Other strong prognostic variables for the NN with 1 hidden layer are life support (Rel-Imp 0.025), intense care unit before the operation (Rel-Imp 0.023) and donor type circulatory dead versus brain-dead (Rel-Imp 0.023). For the NN with 2 hidden layers other very prognostic variables are serology status for HCV (Rel-Imp 0.025), life support (Rel-Imp 0.024) and donor age (Rel-Imp 0.023).
For the RSF life support (VIMP 0.007), serology status for HCV (VIMP 0.007) and intense care unit before the operation (VIMP 0.006). Note that variable total cold ischemic time which was identified as the 4th most prognostic for the Cox model with all variables and the 10th most prognostic for random survival forest is not in the list of the 12 most prognostic for both NNs.
Individual predictions
In this section, the predicted survival probabilities are compared for 3 new hypothetical patients and 3 patients from the test data.
In Fig. 2a the patient with reference characteristics shows the best survival. The highest probabilities are predicted by the RSF and the lowest by the Cox model. The same pattern occurs for the patient that suffers from diabetes (orange lines). The patient with diabetes who has been transplanted before has the worst survival predictions. In this case the NN predicts the highest survival probabilities and the Cox model built using all the prognostic factors the lowest.

a Predicted survival probabilities for 3 new hypothetical patients using the Cox model with all variables (solid lines), the tuned RSF (short dashed lines) and the tuned NN with 1 hidden layer (long dashed lines). The green lines correspond to a reference patient with the median values for the continuous and the mode value for categorical variables. The patient in the orange line has diabetes (the other covariates as in reference patient). The patient in the red line has been transplanted before and has diabetes simultaneously (the other covariates as in reference patient). Values for 10 prognostic variables for the reference patient are provided in Table 2 of Additional file 1. b Predicted survival probabilities for 3 patients selected from the test data based on the Cox model with all variables (solid lines), the tuned RSF (short dashed lines) and the tuned NN with 1 hidden layer (long dashed lines). Green lines correspond to a patient censored at 1.12 years. Patient in the orange line was censored at 6.86 years. Patient in the red line died at 0.12 years. Values for 10 prognostic variables for the patients are provided in Tables 3-5 of Additional file 1
In Fig. 2b the estimated survival probabilities are showed by the Cox model with all variables, the tuned RSF and the tuned PLANN with 1 hidden layer for 3 patients from the test set. The first patient shows the highest survival predictions by the 3 models. The RSF provides the highest survival probabilities and the NN the lowest. The second patient experiences lower survival probabilities (orange lines) whereas the third patient shows the lowest survival probabilities overall. For the second patient the NN predicts the lowest survival probabilities over time and for the third the Cox model.
In general, the random survival forest provides the most optimistic survival probabilities whereas the most pessimistic survival probabilities are predicted by either the Cox model or the NN (more often by the Cox model). This may be related to the characteristics of the methods as RSF relies on recursive binary partitioning of predictors, whereas Cox models imply linearity, and NNs fit non-linear relationships.
Calibration
Here 4 methods are compared: Cox model with all variables, RSF, PLANN 1 hidden and 2 hidden layers based on the calibration on the test data. For each method, the predicted survival probabilities at each year are estimated and the patient data are split into 10 equally sized groups based on the deciles of the probabilities. Then the survival probabilities along with their 95% confidence intervals are calculated using the Kaplan-Meier methodology [47].
In Fig. 3 the results are showed at 2 years since LT. The Cox model with all variables and the PLANN with 1 hidden layer are both well calibrated. The RSF and the PLANN with 2 hidden layers tend to overestimate the survival probabilities for the patients at higher risk. Survival neural network with 1 hidden layer seems to be the most reliable for predictions between the ML techniques. Calibration plots at 5 and 10 years can be found in Additional file 3.

Calibration plots at 2 years on the test data: a Cox model with all variables, b Random Survival Forest, c Partial Logistic Artificial Neural Network with 1 hidden layer, d Partial Logistic Artificial Neural Network with 2 hidden layers
Discussion
With the rise of computational power and technology on the 21 st century, more and more data have been collected in the medical field to identify trends and patterns which will allow building better allocation systems for patients, provide more accurate prognosis and diagnosis as well as more accurate identification of risk factors. During the past few years, machine learning (ML) has received increased attention in the medical area. For instance, in the area of LTs graft failure or primary non-function might be predicted at decision time with ML methodology [48]. Briceño et al. created a NN process for donor-recipient matching specifying a binary classification survival output (recipient or graft survival) to predict 3-month graft mortality [49].
In this study statistical and ML models were estimated for patients from the US post-transplantation. Random survival forest performed better than Cox models with respect to the C-index. This shows the ability of the model to discriminate between low and high risk groups of patients. The C-index was not estimated for NN because a natural ordering of subjects is not feasible. Therefore, the Brier score was measured each year for all methods. The RSF showed similar results to the Cox models having slightly smaller total prediction error (in terms of IBS). The NNs performed in general better than the Cox models or the RSF and had very similar performance over time. RSF and survival NN are ML techniques which have a different learning method and model non-linear relationships between variables automatically. Both methods may be used in medical application but should be applied at present as additional analysis for comparison.
Special emphasis was given on the interpretation of the models. An indirect comparison was performed to examine which are the most prognostic variables for a Cox model with all variables, a RSF and NNs. Results showed that Cox model with all variables (via absolute z-score values) and the NNs with one/two hidden layer(s) (via relative importance) identified similar predictors. Both methods identified re-transplantation as the strongest predictor and donor age, diabetes, life support and race as relatively strong predictors. According to RSF, the most prognostic variables were donor age, re-transplantation, life support and serology status of HCV. Aetiology and last serum creatinine were selected as the 7th and the 8th most prognostic. This raises a known concern about the RSF bias towards continuous variables and categorical variables with multiple levels [50] (aetiology has 9 levels: metabolic, acute, alcoholic, cholestatic, HBV, HCV, malignant, other cirrhosis, other unknown). As continuous and multilevel variables incorporate larger amount of information than categorical, they tend to be favoured by the splitting rule of the forest during binary partitioning. Such bias was reflected in the variable importance results.
When comparing statistical models with machine learning techniques with respect to interpretability, Cox models offer a straightforward interpretation through the hazard ratios. On the contrary, for both neural networks and random survival forests the sign of the prediction is not provided (if the effect is positive or negative). Additionally, for NNs interpretation is possible for different variable levels (with the method of Garson and its extension), whereas for RSF only the total effect of a variable is shown. There is no common metric to directly compare Cox models with ML techniques in terms of interpretation. Future research in this direction is needed.
ML techniques are inherently based on mechanisms introducing randomisation and therefore very small changes are expected between different iterations of the same algorithm. To evaluate stability of performance, ML models were run several times under the same parametrisation. RSF were consistently stable after a certain number of trees (300 were selected). This was not the case for the NNs where instability is a common problem. It is challenging to tune a NN due to many hyper-parameter combinations available and the lack of a consistent global performance measure for survival data. IBS was used to tune the novel NNs, which may be the reason of instability for the NN with 2 hidden layers together with the large number of weights. Note also that the NN with 1 hidden layer is well calibrated whereas the NN with 2 hidden layers is less calibrated on the test data.
This is the first study where ML techniques are applied to transplant data where a comparison with the traditional Cox model was investigated. To construct the survival NN, the original problem had to be converted into a classification problem where exact survival times were transformed into (maximum) 10 time intervals denoting years since transplantation. On the other hand, for the Cox models and the RSF exact time to event was used. Recently, a new feed forward NN has been proposed for omics data which calculates directly a proportional hazards model as part of the output node using exact time information [51]. A survival NN with exact times may lead to better predictive performance. For UNOS data, 69.1% of the recipients were alive/censored and 30.9% had the event of interest. Results above were based on these particular percentages for censoring and events (for the NNs the percentages varied because of the reformulation of the problem).
It might be useful to investigate how the number of variables affects the performance of the models. Here 97 variables were pre-selected supported by clinical and statistical reasons (e.g. variables available before or during LT). It might be interesting to repeat the analyses on a smaller group of predictors, implementation time can be drastically reduced as the calculation complexity depends on sample size and predictors multiplicity. Alongside, predictive accuracy might be increased as some noisy factors will be removed from the dataset increasing the signal of potentially prognostic variables.
Both traditional Cox models and PLANNs allow for the inclusion of time-dependent covariates. For PLANNs, each patient is replicated multiple times during the transformation of exact times into a set of k non-overlapping intervals in long format. Thus, different values of a covariate can be naturally incorporated to increase the predictive ability of the networks. It would be interesting to apply and compare the predictive ability of time-dependent Cox models and PLANNs to liver transplantation data including explanatory variables whose values change over time. Such extension to more dynamic methods may increase predictive performance and help in decision making.
Conclusions
There is an increased attention to ML techniques beyond SM in the medical field with methods and applications being more necessary than ever. Utilization of these algorithmic approaches can lead to pattern discovery in the data promoting fast and accurate decision making. For time-to-event data, more ML techniques may be applied for prediction such as Support Vector Machines and Bayesian Networks. Moreover, deep learning with NN is gaining more and more attention and will likely be another trend in the future for these complex data.
In this work two alternatives to the Cox model from machine learning for medical data with large total sample size (62294 patients) and many predictors (97 in total) were discussed. RSF showed better performance than the Cox models with respect to C-index so it can be a useful tool for prioritisation of particular high risk patients. NNs showed better prediction performance in terms of Integrated Brier score. However, both ML techniques required a non-trivial implementation time. Cox models are preferable in terms of straightforward interpretation and fast implementation. Our study suggests that some caution is required when ML methods are applied to survival data. Both approaches can be used for exploratory and analysis purposes as long as the advantages and the disadvantages of the methods are presented.
Availability of data and materials
The research data for this project is private. Unauthorized use is a violation of the terms of the Data Use Agreement with the U.S. Department of Health and Human Services. More information and instructions for researchers to request UNOS data can be found at https://unos.org/data/. R-code developed to perform the analysis is available in Additional file 4.
Notes
UNOS is a non-profit and scientific organisation in the United States which arranges organ donation and transplantation. For more information visit its website https://unos.org.
Dictionary for variables details is provided at: https://www.srtr.org/requesting-srtr-data/saf-data-dictionary/.
Abbreviations
- BS:
-
Brier score
- CVPL:
-
cross-validated log-partial likelihood
- DCD:
-
Donor Circulatory Dead
- HBV:
-
Chronic hepatitis B virus
- HCV:
-
Chronic hepatitis C virus
- IBS:
-
Integrated Brier score
- IPCW:
-
Inverse Probability of Censoring Weighting
- LASSO:
-
least angle and selection operator
- LT:
-
liver transplantation
- LUMC:
-
Leiden University Medical Center
- ML:
-
machine learning
- NN(s):
-
artificial neural network(s)
- OGS:
-
overall graft-survival
- OPO:
-
Organ Procurement Organisations
- OPTN:
-
Organ Procurement and Transplantation Network
- PLANN:
-
partial logistic artificial neural network
- PLANN-ARD:
-
partial logistic artificial neural network - automatic relevance determination
- PH:
-
proportional hazards
- Rel-Imp:
-
relative importance
- RSF:
-
random survival forest
- SM:
-
statistical model
- SRTR:
-
Scientific Registry of Transplant Recipients
- UNOS:
-
United Network of Organ Sharing
- VIMP:
-
variable importance.
References
Grinyó JM. Why is organ transplantation clinically important?Cold Spring Harb Perspect Med. 2013; 3(6). https://doi.org/10.1101/cshperspect.a014985.
Merion RM, Schaubel DE, Dykstra DM, Freeman RB, Port FK, Wolfe RA. The survival benefit of liver transplantation. Am J Transplant. 2005; 5(2):307–13. https://doi.org/10.1111/j.1600-6143.2004.00703.x.
Song X, Mitnitski A, Cox J, Rockwood K. Comparison of machine learning techniques with classical statistical models in predicting health outcomes. Stud Health Technol Inform. 2004; 107(Pt 1):736–40.
Deo RC. Machine learning in medicine. Circulation. 2015; 132(20):1920–30. https://doi.org/10.1161/CIRCULATIONAHA.115.001593.
Shailaja K, Seetharamulu B, Jabbar MA. Machine learning in healthcare: A review. In: Second International Conference on Electronics, Communication and Aerospace Technology (ICECA). Coimbatore: 2018. p. 910–4. https://doi.org/10.1109/ICECA.2018.8474918.
Scott IA, Cook D, Coiera EW, Richards B. Machine learning in clinical practice: prospects and pitfalls. Med J Aust. 2019; 211:203–5. https://doi.org/10.5694/mja2.50294.
Desai RJ, Wang SV, Vaduganathan M, Evers T, Schneeweiss S. Comparison of machine learning methods with traditional models for use of administrative claims with electronic medical records to predict heart failure outcomes. JAMA Netw open. 2020; 3(1):1918962. https://doi.org/10.1001/jamanetworkopen.2019.18962.
Cox DR. Regression models and life-tables. J Roy Stat Soc Ser B Methodol. 1972; 34(2):187–220.
Biganzoli E, Boracchi P, Mariani L, Marubini E. Feed forward neural networks for the analysis of censored survival data: a partial logistic regression approach. Stat Med. 1998; 17(10):1169–86. https://doi.org/10.1002/(sici)1097-0258(19980530)17:10<1169::aid-sim796>3.0.co;2-d
Wang P, Li Y, Reddy CK. Machine learning for survival analysis: A survey. ACM Comput Surv. 2019; 51(6). https://doi.org/10.1145/3214306.
Xiang A, Lapuerta P, Ryutov A, Buckley J, Azen S. Comparison of the performance of neural network methods and cox regression for censored survival data. Comput Stat Data Anal. 2000; 34(2):243–57. https://doi.org/10.1016/S0167-9473(99)00098-5.
Faraggi D, Simon R. A neural network model for survival data. Stat Med. 1995; 14(1):73–82. https://doi.org/10.1002/sim.4780140108.
Liestøl K, Andersen PK, Andersen U. Survival analysis and neural nets. Stat Med. 1994; 13(12):1189–200. https://doi.org/10.1002/sim.4780131202.
Buckley J, James I. Linear regression with censored data. Biometrika. 1979; 66(3):429–36. https://doi.org/10.1093/biomet/66.3.429.
Lisboa PJG, Wong H, Harris P, Swindell R. A bayesian neural network approach for modelling censored data with an application to prognosis after surgery for breast cancer. Artif Intell Med. 2003; 28(1):1–25. https://doi.org/10.1016/S0933-3657(03)00033-2.
Biganzoli E, Boracchi P, Marubini E. A general framework for neural network models on censored survival data. Neural Netw. 2002; 15(2):209–18. https://doi.org/10.1016/s0893-6080(01)00131-9.
Biglarian A, Bakhshi E, Baghestani AR, Gohari MR, Rahgozar M, Karimloo M. Nonlinear survival regression using artificial neural network. J Probab Stat. 2013; 2013. https://doi.org/10.1155/2013/753930.
Jones AS, Taktak AGF, Helliwell TR, Fenton JE, Birchall MA, Husband DJ, Fisher AC. An artificial neural network improves prediction of observed survival in patients with laryngeal squamous carcinoma. Eur Arch Otorhinolaryngol. 2006; 263(6):541–7. https://doi.org/10.1007/s00405-006-0021-2.
Taktak A, Antolini L, Aung M, Boracchi P, Campbell I, Damato B, Ifeachor E, Lama N, Lisboa P, Setzkorn C, Stalbovskaya V, Biganzoli E. Double-blind evaluation and benchmarking of survival models in a multi-centre study. Comput Biol Med. 2007; 37(8):1108–20. https://doi.org/10.1016/j.compbiomed.2006.10.001.
Blok JJ, Putter H, Metselaar HJ, Porte RJ, Gonella F, De Jonge J, Van den Berg AP, Van Der Zande J, De Boer JD, Van Hoek B, Braat AE. Identification and validation of the predictive capacity of risk factors and models in liver transplantation over time. Transplantation Direct. 2018; 4(9). https://doi.org/10.1097/TXD.0000000000000822.
de Boer JD, Putter H, Blok JJ, Alwayn IPJ, van Hoek B, Braat AE. Predictive capacity of risk models in liver transplantation. Transplantation Direct. 2019; 5(6):457. https://doi.org/10.1097/TXD.0000000000000896.
R: A Language and Environment for Statistical Computing. http://www.R-project.org/.
Kantidakis G, Lancia C, Fiocco M. Prediction Models for Liver Transplantation - Comparisons Between Cox Models and Machine Learning Techniques [abstract OC30-4]: 40th Annual Conference of the International Society for Clinical Biostatistics; 2019, pp. 343–4. https://kuleuvencongres.be/iscb40/images/iscb40-2019-e-versie.pdf.
Van Buuren S, Boshuizen HC, Knook DL. Multiple imputation of missing blood pressure covariates in survival analysis. Stat Med. 1999; 18(6):681–94. https://doi.org/10.1002/(SICI)1097-0258(19990330)18:6<681::AID-SIM71>3.0.CO;2-R.
Stekhoven DJ, Bühlmann P. Missforest-non-parametric missing value imputation for mixed-type data. Bioinformatics. 2012; 28(1):112–8. https://doi.org/10.1093/bioinformatics/btr597.
Lawless JF, Singhal K. Efficient screening of nonnormal regression models. Biometrics. 1978; 34(2):318–27. https://doi.org/10.2307/2530022.
Tibshirani R. The lasso method for variable selection in the cox model. Stat Med. 1997; 16(4):385–95.
Verweij PJM, Van Houwelingen HC. Cross-validation in survival analysis. Stat Med. 1993; 12(24):2305–14. https://doi.org/10.1002/sim.4780122407.
Ishwaran H, Kogalur UB, Blackstone EH, Lauer MS. Random survival forests. Ann Appl Stat. 2008; 2(3):841–60. https://doi.org/10.1214/08-AOAS169.
Breiman L. Random forests. Mach Learn. 2001; 45(1):5–32. https://doi.org/10.1023/A:1010933404324.
Hastie T, Tibshirani R, Friedman J. The Elements of Statistical Learning: Springer; 2009. https://doi.org/10.1007/978-0-387-84858-7.
Segal MR. Regression trees for censored data. Biometrics. 1988; 44(1):35–47.
Hothorn T, Lausen B. On the exact distribution of maximally selected rank statistics. Comput Stat Data Anal. 2003; 43(2):121–37. https://doi.org/10.1016/S0167-9473(02)00225-6.
van Gerven M, Bohte S. Editorial: Artificial neural networks as models of neural information processing. Front Comput Neurosci. 2017; 11:114. https://doi.org/10.3389/fncom.2017.00114.
Minsky M, Papert S. Perceptrons; an Introduction to Computational Geometry. (Book edition 1). Cambridge: MIT Press; 1969.
Lapuerta ASbsuffixP, L L. Use of neural networks in predicting the risk of coronary artery disease. Comput Biomed Res. 1995; 28(1):38–52. https://doi.org/10.1006/cbmr.1995.1004.
Garson GD. Interpreting neural network connection weights. AI Expert. 1991; 6(4):46–51.
Harrell FE, Lee KL, Mark DB. Multivariable prognostic models: issues in developing models, evaluating assumptions and adequacy, and measuring and reducing errors. Stat Med. 1996; 15(4):361–87. https://doi.org/10.1002/(SICI)1097-0258(19960229)15:4<361::AID-SIM168>3.0.CO;2-4.
Van Houwelingen JC, Le Cessie S. Predictive value of statistical models. Stat Med. 1990; 9(11):1303–25. https://doi.org/10.1002/sim.4780091109.
Graf E, Schmoor C, Sauerbrei W, Schumacher M. Assessment and comparison of prognostic classification schemes for survival data. Stat Med. 1999; 18(17-18):2529–45. https://doi.org/10.1002/(sici)1097-0258(19990915/30)18:17/18<2529::aid-sim274>3.0.co;2-5.
Houwelingen JCv, Putter H. Dynamic Prediction in Clinical Survival Analysis. (Book edition 1). Boca, Raton: CRC Press; 2012, p. 234.
Goh ATC. Back-propagation neural networks for modeling complex systems. Artif Intell Eng. 1995; 9(3):143–51. https://doi.org/10.1016/0954-1810(94)00011-S.
Olden JD, Jackson DA. Illuminating the “black box”: a randomization approach for understanding variable contributions in artificial neural networks. Ecol Model. 2002; 154(1-2):135–50.
Ishwaran H, Kogalur UB, Gorodeski EZ, Minn AJ, Lauer MS. High-dimensional variable selection for survival data. J Am Stat Assoc. 2010; 105(489):205–17. https://doi.org/10.1198/jasa.2009.tm08622.
Ishwaran H, Lu M. Standard errors and confidence intervals for variable importance in random forest regression, classification, and survival. Stat Med. 2019; 38(4):558–82. https://doi.org/10.1002/sim.7803.
Schemper M, Smith TL. A note on quantifying follow-up in studies of failure time. Control Clin Trials. 1996; 17(4):343–6. https://doi.org/10.1016/0197-2456(96)00075-x.
Kaplan EL, Meier P. Nonparametric estimation from incomplete observations. J Am Stat Assoc. 1958; 53(282):457–81. https://doi.org/10.2307/2281868.
Lau L, Kankanige Y, Rubinstein B, Jones R, Christophi C, Muralidharan V, Bailey J. Machine-learning algorithms predict graft failure after liver transplantation. Transplant. 2017; 101(4):125–32. https://doi.org/10.1097/TP.0000000000001600.
Briceño J, Cruz-Ramírez M, Prieto M, Navasa M, De Urbina JO, Orti R, Gómez-Bravo MN, Otero A, Varo E, Tomé S, Clemente G, Bañares R, Bárcena R, Cuervas-Mons V, Solórzano G, Vinaixa C, Rubín N, Colmenero J, Valdivieso A, Ciria R, Hervás-Martínez C, De La Mata M. Use of artificial intelligence as an innovative donor-recipient matching model for liver transplantation: Results from a multicenter spanish study. J Hepatol. 2014; 61(5):1020–8. https://doi.org/10.1016/j.jhep.2014.05.039.
Loh W-Y, Shih Y-S. Split selection methods for classification trees. Stat Sin. 1997; 7:815–40.
Ching T, Zhu X, Garmire LX. Cox-nnet: An artificial neural network method for prognosis prediction of high-throughput omics data. PLoS Comput Biol. 2018; 14(4). https://doi.org/10.1371/journal.pcbi.1006076.
Acknowledgements
The authors would like to thank the United Network of Organ Sharing (UNOS) and Scientific Registry of Transplant Recipients (SRTR) for providing the data about liver transplantation to Leiden University Medical Center (LUMC) under DUA number 9477.
Funding
Georgios Kantidakis’s work as a Fellow at EORTC Headquarters was supported by a grant from the EORTC Soft Tissue and Bone Sarcoma Group and Leiden University as well as from the EORTC Cancer Research Fund (ECRF). The funding sources had no role in the design of the study and collection, analysis, and interpretation of data or preparation of the manuscript.
Author information
Authors and Affiliations
Contributions
JDB and AEB requested the data to the Scientific Registry of Transplant Recipients (SRTR) and provided clinical input. GK, HP, CL and MF designed the models. GK carried out the statistical analysis. GK wrote the manuscript and HP, MF critically revised it. All authors read and approved the final version.
Corresponding author
Ethics declarations
Ethics approval and consent to participate
The ethics committee of Leiden University Medical Center (LUMC) approved the study by sending a letter to JDB. For all patients written informed consent was provided to use the data for scientific research.
Consent for publication
The study was submitted to a functioning Institutional Review Board (IRB) for review and approval. Consent was provided for publication.
Competing interests
The authors declare that they have no competing interests. The data reported here have been supplied by the Minneapolis Medical Research Foundation (MMRF) as the contractor for the Scientific Registry of Transplant Recipients (SRTR). The interpretation and reporting of these data are the responsibility of the author(s) and in no way should be seen as an official policy of or interpretation by the SRTR or the U.S. Government.
This study used data from the Scientific Registry of Transplant Recipients (SRTR). The SRTR data system includes data on all donor, wait-listed candidates, and transplant recipients in the US, submitted by the members of the Organ Procurement and Transplantation Network (OPTN). The Health Resources and Services Administration (HRSA), U.S. Department of Health and Human Services provides oversight to the activities of the OPTN and SRTR contractors.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The majority of this work was done at Leiden University
Supplementary Information
Additional file 1
Includes the Garson’s algorithm for 2 hidden layers, a table with the relative importance of the time intervals for the neural networks with 1 and 2 hidden layes, detailed criteria for variable pre-selection, a plot of survival and censoring distributions and 4 tables with individual patient characteristics.
Additional file 2
Provides information about the package to implement RSFs and NNs as well as technical parts regarding the choice of tuning parameters and the cross-validation procedure for each method. A figure illustrates the cross-validation procedure for RSF on a 3D space. References are provided for further reading.
Additional file 3
Contains calibration plots at 5 and 10 years for a) a Cox model with all prognostic factors, b) a Random Survival Forest with all prognostic factors, c) a Partial Logistic Artificial Neural Network with 1 hidden layer with all prognostic factors and d) a Partial Logistic Artificial Neural Network with 2 hidden layers with all prognostic factors.
Additional file 4
Provides the R code developed for the analyses of this project.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/. The Creative Commons Public Domain Dedication waiver (http://creativecommons.org/publicdomain/zero/1.0/) applies to the data made available in this article, unless otherwise stated in a credit line to the data.
About this article

Cite this article
Kantidakis, G., Putter, H., Lancia, C. et al. Survival prediction models since liver transplantation - comparisons between Cox models and machine learning techniques. BMC Med Res Methodol 20, 277 (2020). https://doi.org/10.1186/s12874-020-01153-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s12874-020-01153-1