
Abstract
Availability of large amounts of raw unlabeled data has sparked the recent surge in semi-supervised learning research. In most works, however, it is assumed that labeled and unlabeled data come from the same distribution. This restriction is removed in the self-taught learning algorithm where unlabeled data can be different, but nevertheless have similar structure. First, a representation is learned from the unlabeled samples by decomposing their data matrix into two matrices called bases and activations matrix respectively. This procedure is justified by the assumption that each sample is a linear combination of the columns in the bases matrix which can be viewed as high level features representing the knowledge learned from the unlabeled data in an unsupervised way. Next, activations of the labeled data are obtained using the bases which are kept fixed. Finally, a classifier is built using these activations instead of the original labeled data. In this work, we investigated the performance of three popular methods for matrix decomposition: Principal Component Analysis (PCA), Non-negative Matrix Factorization (NMF) and Sparse Coding (SC) as unsupervised high level feature extractors for the self-taught learning algorithm. We implemented this algorithm for the music genre classification task using two different databases: one as unlabeled data pool and the other as data for supervised classifier training. Music pieces come from 10 and 6 genres for each database respectively, while only one genre is common for the both of them. Results from wide variety of experimental settings show that the self-taught learning method improves the classification rate when the amount of labeled data is small and, more interestingly, that consistent improvement can be achieved for a wide range of unlabeled data sizes. The best performance among the matrix decomposition approaches was shown by the Sparse Coding method.
Similar content being viewed by others


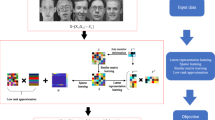
Introduction
A tremendous amount of music-related data has recently become available either locally or remotely over networks, and technology for searching this content and retrieving music-related information efficiently is demanded. This consists of several elemental tasks such as genre classification, artist identification, music mood classification, cover song identification, fundamental frequency estimation, and melody extraction. Essential for each task is the feature extraction as well as the model or classifier selection. Audio signals are conventionally analyzed frame-by-frame using Fourier or Wavelet transform, and coded as spectral feature vectors or chroma features extracted for several tens or hundreds of milliseconds. However, it is an open question how precisely music audio should be coded depending on the task kind and the succeeding classifier.
For the classification, classical supervised pattern recognition approaches require large amount of labeled data which is difficult and expensive to obtain. On the other hand, in the real world, a massive amount of musical data is created day by day and various musical databases are newly composed. There may be no labels for some databases and musical genres may be very specific. Thus, recent music information retrieval research has been increasingly adopting semi-supervised learning methods where unlabeled data are utilized to help the classification task. Common assumption, in this case, is that both labeled and unlabeled data come from the same distribution [1] which, however, may not be easily achieved during the data collection. This restriction is alleviated in the transfer learning framework [2] which allows the domains, tasks, and distributions used in training and testing to be different. Utilizing this framework and the semi-supervised learning ideas, the recently proposed self-taught learning algorithm [3] appears to be a good candidate for the kind of music genre classification task described above. According to this algorithm, first, a high-level representation of the unlabeled data is found in an unsupervised manner. This representation is assumed to hold some common structures appearing in the data such as curves, edges, or shapes for images or particular spectrum changes for music. In other words, we try to learn some basic “building blocks” or high-level features representing the knowledge extracted from the unlabeled data. In practice, this is accomplished by decomposing the unlabeled data matrix into a matrix of basis vectors representing those “building blocks” and matrix of combination coefficients such that each data sample can be approximated by a linear combination of the basis vectors. The basis vectors matrix is often called a dictionary while the coefficients matrix is called an activations matrix. There are various methods for this kind of matrix decomposition but most of them are based on the minimization of the approximation error, so the main difference between those methods lays in the used optimization algorithms. In this study, we investigated the performance of two recently proposed methods: the Non-negative Matrix Factorization (NMF) [4] and Sparse Coding (SC) [5], as well as the classical Principal Component Analysis (PCA) [6] as approaches for learning the dictionary of basis vectors. Each method has its own advantages and drawbacks and some researchers have investigated their combinations by essentially adjusting the objective function to accommodate some constraints. Thus, the sparse PCA [7], the non-negative sparse PCA [8], and sparse NMF [4, 9] have been introduced lately. However, in order to be able to do a fair comparison, we decided to use the original PCA and NMF rather than their sparse derivatives.
The next step of the self-taught learning algorithm involves transformation of the labeled data into new feature vectors using the dictionary learned at the previous step. This is done using the same matrix factorization procedure as before with the only difference that the basis vectors matrix is kept fixed and only the activation matrix is calculated. This way, each of the labeled data vectors is approximated by a linear combination of bases learned from a large amount of data. It is expected that the activation vectors will capture more information than the original labeled data they correspond to, since additional knowledge encapsulated in the bases is being used. Finally, using labeled activation vectors as regular features, classical supervised classifier is trained for the task at hand. In this work, we used the standard Support Vector Machine (SVM) classifier.
In our experiments, we utilized two music databases: one as unlabeled music data and the other for the actual supervised classification task. We have published some preliminary experimental results on these databases [10, 11], but this study provides a thorough investigation and comparison of the three matrix decomposition methods mentioned above.
Related studies
There are several studies where the semi-continuous learning framework has been used for music analysis and music information retrieval tasks. Based on a manifold regularization method, it has been shown that adding unlabeled data can improve the music genre classification accuracy rate [12]. This approach is later extended to include fusion of several music similarity measures which achieved further gains in the performance [13]. The so called “semi-supervised canonical density estimation” method was proposed for the task of automatic audio tag classification [14]. In this study, using the semi-supervised variants of the canonical correlation analysis and the kernel density estimation methods, authors have built a system for automatic music annotation with tags such as genre, instrumentation, emotion, style, rhythm, etc. According to the published results, adding unlabeled sound samples can improve both the precision and recall rates. In all these studies, although not explicitly stated, both the labeled and unlabeled data come from the same classes and have the same distribution. This is evident from the fact that the unlabeled data have been obtained by removing the labels from part of the data corpus used in the experiments. In the self-taught learning case, however, the unlabeled data, though being of the same type, i.e., music, come from different classes (genres).
On the other hand, the non-negative matrix factorization and the sparse representation methods have been applied in various music processing tasks, but in a standard supervised learning scenario. An NMF based on Itakura-Saito divergence has been used for notes pitch estimation as well as decomposition of music into individual instrumental sounds [15]. In another study [16], a polyphonic music transcription is achieved by estimating the spectral profile and temporal information for every note using NMF decomposition. Recent review of the sparse representations in audio and music [17] describes successful applications in such tasks as audio coding, denoising, blind source separation as well as automatic music transcription. In an experimental setup similar to our baseline, i.e., with no unlabeled data, high genre classification performance has been reported using the so called Predictive Sparse Decomposition method [18].
As an instance of the transfer learning, the self-taught learning approach can be particularly useful when the amount of target data is too small, but other raw data from the same “type” or “modality” are sufficiently available. Using the self-taught idea, clustering performance can be improved by simultaneous clustering of both the target and auxiliary raw data through a common set of features [19]. When the number of bases learned from the other unlabeled data is less than the feature vectors dimension, the representation of the target data using these bases essentially becomes a dimensionality reduction. This observation is the basis of the self-taught dimensionality reduction method [20], where special care is taken for the preservation of the target data structures in the original space in order to improve the k-means performance. In our system, labeled data dimension is also reduced, but the goal is to improve the supervised classification accuracy.
The self-taught learning algorithm
A classification task is considered with small labeled training data set drawn i.i.d. from an unknown distribution . Each is an input feature vector which is assigned a class label . In addition, a larger unlabeled training data set is available, which is assumed only to be of the “same type” as and may not be associated with the class labels and distribution . Obviously, in order to help the classification of the labeled data, it should not be totally different or unrelated.
The main idea of the self-taught learning approach is to use the unlabeled samples to learn in an unsupervised way slightly higher level representation of the data [3]. In other words, to discover some hidden structures in the data which can be considered as basic building blocks. For example, if the data represent images, the algorithm would find simple elements such as edges, curves, etc., so that the image can be represented in terms of these more abstract, higher level features. Once learned, this representation is applied to the labeled data resulting in a new set of features which lighten the supervised learning task.
This idea is formalized as follows: each unlabeled data vector is assumed to be generated as a linear combination of some basis functions:
where are the linear combination coefficients specific to and are the basis functions. In the self-taught learning framework, these basis functions are considered as the data building blocks or the higher level features. Taking into account all the unlabeled training data, Equation (1) can be conveniently rewritten in the following matrix form:
where is a product of two matrices Bu= and . Each column of Au represents the coefficient vector for data vector . It is easy to see that Equation (2) essentially decomposes the training data matrix Xu into two unknown matrices Au and Bu which are also often called activation matrix and dictionary (of bases) respectively. All the methods for finding Au and Bu discussed in the next section produce an approximative solution and thus, in practice, Equations (1) and (2) become:
where is a Gaussian noise representing the approximation error. After the dictionary Bu has been learned from the unlabeled training data , according to the self-taught learning algorithm, this dictionary is used to obtain activations for the labeled data . In other words, it is assumed that the labeled vectors can also be represented as a linear combination of some basis functions and particularly the basis vectors :
where is the activation matrix corresponding to the labeled data. We can consider these activations as a new representation of and the whole procedure as a non-linear mapping or transformation of vectors into vectors . Note that in the case when d>K, this transformation involves dimension reduction as well. Next, we can assign original class labels y i to each and thus obtain new labeled training data which we can use to build any appropriate classifier in the traditional supervised manner. In other words, instead of the original training data , we use the set of activations as feature vectors for our classification task. This exchange is justified when the amount of original labeled training data is too small for reliable model estimation. Although the size of the new training set is the same, the new feature vectors may contain more information about the underlying classes because they are obtained using the higher level features, i.e., the basis functions, learned from a much bigger pool of data. This can be considered as a transfer of structural information or knowledge from one set of data to another under the reasonable assumption that both the data sets share the same or similar higher level features.
The whole self-taught learning algorithm can be summarized into the following steps: Step 1. Compute a dictionary Bu of basis vectors from the unlabeled data using any appropriate matrix decomposition method. Step 2. Obtain activation vectors for each labeled training vector using the dictionary learned at Step 1. Step 3. Use activation vectors as new labeled features to train standard supervised classifier. Step 4. Transform each test vector into an activation vector in the same way as the training data at Step 2 and apply the classifier to obtain its label.
Data matrix decomposition and feature transformation methods
The general approach for finding the solution, i.e., Au and Bu, for the Equations (3) or (4) is the minimization of the squared approximation error:
which in the matrix form can be expressed by the Frobenius norm:
Since there is no unique solution to the above optimization problem, the different minimization approaches described in this section result in solutions with different properties and, consequently, different performance.
For the labeled data transformation into activation vectors, similar optimization objective is used:
where is the activation vector corresponding to . It is easy to see that this is a sub-task of the optimization of Equation (7) and can be solved using the same or even simpler method.
Principal Component Analysis (PCA)
The PCA [6] is a popular data-processing and dimension-reduction technique, with numerous applications in engineering, biology, and social science. It identifies a low dimensional subspace of maximal variation within the data in an unsupervised manner. It is not difficult to show that the following function [21]:
where m is the data mean, is minimized when the vectors e k are the K eigenvectors of the data covariance matrix having largest eigenvalues, and the coefficients a i are called principal components. Assuming that our unlabeled data are mean normalized, i.e., m=0, and comparing this equation with Equation (7) we see that the eigenvectors and the principal components correspond to the basis functions and activations respectively.
The standard way of performing PCA is to do a singular value decomposition (SVD) of the data matrix:
where Wu is the eigenvectors matrix, i.e., the dictionary, and Pu=Σu[Vu]T is the matrix of principal components, i.e., the activations matrix.
In this case, the labeled data transformation, i.e., Equation (9), is simplified to:
which together with the SVD procedure required for finding the matrix Wu makes the PCA approach very easy to implement and computationally inexpensive way of calculating the high level features for the self-taught learning algorithm. However, compared to the other matrix decomposition methods, the PCA has several limitations. First, as can be seen from the above equation, the PCA results in linear feature extraction, i.e., activations are just linearly transformed input data. Other methods, such as sparse coding, can produce features which are inherently a non-linear function of the input. Second, the dictionary size cannot be bigger than the data dimension because the eigenvectors are assumed to be orthogonal. Finally, it is difficult to think of the eigenvectors as building blocks or higher level structures of the data.
Non-negative Matrix Factorization (NMF)
In this case, to learn the higher level representation, we use the non-negative matrix factorization method. It decomposes the unlabeled data matrix Xu into a product of two matrices Wu= and having only non-negative elements. The decomposition is approximative in nature, so:
or equivalently in a vector form:
where Hu is the mixing matrix corresponding to the activations matrix Au and Wu corresponds to the bases matrix Bu of Equation (4). Since only additive combinations of these bases are allowed, the non-zero elements of Wu and Hu are all positive. Thus, in such decomposition no subtractions can occur. For these reasons, the non-negativity constraints are compatible with the intuitive notion of combining components to form a whole signal, which is how the NMF learns the high level (parts-based) representations.
In contrast to the sparse coding method, the NMF does not assume explicitly or implicitly sparseness or mutual statistical independence of components. However, sometimes it can produce sparse decompositions [22].
For finding W and H, the most frequently used cost functions are the Square Euclidean distance expressed by the Frobenius norm:
which is optimal for Gaussian distributed approximation error, and the generalized Kullback-Leibler divergence:
Although both functions are convex in W and H only, they are not convex in both variables together. Thus, we can only expect the maximization algorithm to find a local minimum. A good compromise between speed and ease of implementation have been proposed in [23] and is known as the multiplicative updates algorithm. It consists of iterative application of the following update rules:
when Frobenius norm (Equation (15)) is chosen as objective function. Another popular optimization method is the alternating least squares (ALS) algorithm where simpler objective is solved by fixing one of the unknown matrices and then solving again with the other matrix held fixed. The ALS algorithm, however, does not guarantee convergence to a global minimum or even to a stationary point. Some other approaches such as the Projected Gradient or Quasi-Newton method have been shown to give better results. An excellent and deep description of the NMF and its optimization methods is given in [4].
After learning the basis vectors from the unlabeled training data we use them to obtain activations for the labeled data . The new labeled features are computed by solving Equation (9) which in the case of NMF is:
This is a convex least squares task which is the same as the optimization of (15) with fixed bases w k and can be solved in the by using the update rule just for h i j , i.e., Equation (17).
Sparse Coding (SC)
To learn the higher level representation with a sparse coding method, we can add a sparsity constraint to the objective function of Equation (7). Given the unlabeled data set , the following optimization procedure is defined:
where basis vectors and activations are subject to optimization. The parameter β controls the sparsity level and is usually tuned on a development data set. The first term of the above objective tries to represent each data vector as a linear combination of the bases b k with weights given by the corresponding activations. The second term, on the other hand, tries to reduce the L1 norm of the activation vectors, thus making them sparse. The optimization problem is convex only in terms of basis vectors or activations alone and these sub-problems are solved iteratively by alternatingly holing a i or b k fixed. For learning the bases, the problem is a least squares optimization with quadratic constraints which in general is solved using gradient descent or convex optimization approaches such as the quadratically constrained quadratic programming (QCQP). For the activations, the optimization problem is a convex L1-norm regularized least squares problem and the possible solutions include generic QP solvers, least angle regression (LARS) [24] or grafting [25]. In our experiments, however, we used the more efficient feature-sign search algorithm [26]. It is based on the fact that if the sign of ai,k is known, then the optimization problem is reduced to a standard, unconstrained QP problem, which can be solved analytically.
After learning the basis vectors from the unlabeled training data as described above, we use them to obtain activations for the labeled data by solving the following optimization problem:
This is the same as the optimization problem of Equation (20) with fixed bases b k and can be solved using the same feature-sign search algorithm. Vectors are sparse and approximate labeled data as a linear combination of the bases which, however, are learned using the unlabeled data .
Experiments
In this section, we provide details about the databases we used, the experimental conditions and obtained results. All data sets, signal processing and classification methods are common to all the matrix decomposition methods described in the previous section.
Databases
As unlabeled database we used the GTZAN collection of music [27]. It consists of 1000 30 s audio clips, each belonging to one of the following ten genres: Classical, Country, Disco, Hip-Hop, Jazz, Rock, Blues, Reggae, Pop and Metal. There are 100 clips per genre and all of them have been down-sampled to 22050 Hz. The other database which we used as labeled data is the corpus used in the ISMIR 2004 audio contest [28]. It contains of 729 whole tracks for training, but since the number of tracks per genre is non-uniform, the original nine genres are usually mapped into the following six classes: Classical, Electronic, Jazz-Blues, Metal-Punk, Rock-Pop and World. Another 729 tracks are used for testing. Note that the only common genre between the two databases is the “Classical” genre.
Audio data from both databases are divided into 5 s pieces which were further randomly selected in order to make several training sets with different amount of data, keeping the same number of such pieces per genre. Table 1 summarizes the contents of the training data sets we used in our experiments. For example, set GT-50 has 50 randomly selected 5 s pieces per genre, 500 pieces in total or 0.69 h of music from the GTZAN database. In contrast, IS-20 is a data set from the training part of the ISMIR 2004 corpus consisting of 20 pieces per genre or 120 pieces in total. All sets are constructed in such way that each larger set contains all the pieces from the smaller set. There is only one test set and it consists of 250 pieces per genre randomly selected from the ISMIR 2004 test tracks.
Audio signal preprocessing
When it comes to feature extraction for music information processing, in contrast to the case of speech where the MFCC is dominant, there exists wide variety of approaches—from carefully crafted multiple music specific tonal, chroma, etc. features to single and simple “don’t care about the content” spectrum. In our experiments, we used spectral representation tailored for music signals, such as the Constant-Q transformed (CQT) FFT spectrum. The CQT can be thought of as a series of logarithmically spaced filters having constant center frequency to bandwidth ratio, i.e.,
where Q is known as the transform’s “quality factor”. The main property of this transform is the log-like frequency scale where the consecutive musical notes are linearly spaced [29].
The CQT transform is applied to the FFT spectrum vectors computed from 23.2 ms (512 samples) frames with 50 % overlap in a way that there are 12 Constant-Q filters per octave resulting in a filter-bank of 89 filters which covers the whole bandwidth of 11025 Hz. The filter-bank outputs of 20 consecutive frames are further stacked into a 1780 (89 × 20) dimensional super-vector which is used in the experiments. This is the same as to have a 20 frame time-frequency spectrum image. There is a overlap of 10 frames between such two consecutive spectrum images. This way, each 5 s music piece is represented by 41 spectrum images or super-vectors.
Bases learning
For each data set given in Table 1 we learned several basis vector sets or dictionaries. The sets sizes K are: 100, 200, 300 and 500. Contrary to the conventional sparse coding scheme, where the dictionary size is much bigger than the vectors dimension (for over-complete representation), in our case we in fact do dimension reduction. This is motivated by the fact that our super-vectors are highly redundant and that the basis vectors actually represent higher level spectral image features, not just arbitrary projection directions.
Before bases learning, all the feature vectors from the corresponding GTZAN data set are pooled together and randomly shuffled. Then, each of the matrix decomposition method is applied and the respective dictionaries learned.
Supervised classification
After all labeled training data, i.e. sets IS-20, IS-50, IS-100 and IS-250, have been transformed into activation vectors for each dictionary learned from each unlabeled data set, we obtained in total 64 (4 labeled data sets × 4 dictionary sizes × 4 unlabeled data sets) labeled training data sets. Then, using the LIBSVM tool, we learned 64 SVM classifiers each consisting of 6 SVMs trained in one-versus-all mode. The SVM input vectors were linearly scaled to fit the [0,1] range. For the sparse coding method, this significantly reduces vectors sparsity, but it is tolerable since our goal is not the sparse representation itself. Linear kernel was used as distance measure and the SVMs were trained to produce probabilistic outputs.
During testing, each 5 s musical piece represented by 41 feature (activation) vectors is considered as a sample for classification. Outputs of all genre specific SVMs are aggregated (summed in the log domain) and the label of the maximum output is taken as the classification result.
In order to assess the effect of the self-taught learning, we need performance comparison with a system build under the same conditions but without unlabeled data. We will refer to this system as baseline. In this case, the basis vectors are learned using labeled training data instead of the unlabeled . Then, the activations are obtained in the same way as if the bases were learned from the unlabeled data.
Results using PCA
Table 2 shows the baseline results in terms of genre classification accuracy for each data set IS-20, IS-50, IS-100 and IS-250 with respect to the number of eigenvectors used, i.e., dictionary size K. As can be seen, performance improves with the data set size, but doesn’t change much with respect to the activation features dimension. This suggests that the input data are highly redundant and that the information captured by the eigenvectors is proportional to the data set size.
Using larger amount of data to obtain the eigenvectors through the self-taught learning algorithm significantly improves the results for the poorly performing data sets IS-20 and IS-50 as evident from the Table 3. In this table, the absolute improvement with respect to the baseline accuracy is shown in four sub-tables, one for each of the unlabeled data sets GT-50, GT-100, GT-250 and GT-500. It is interesting to notice that the improvement due to the unlabeled data doesn’t change with the data set size.
Results using NMF
The same set of experiments was done with the non-negative matrix factorization method. Results summarized in Tables 4 and 5 correspond to those for PCA which we described in the previous section.
We can see that the baseline performance is much better than the PCA baseline, especially for the small data sets IS-20 and IS-50. Application of the self-taught learning, however, did not result in such definite improvement as in the case of PCA. In average, the unlabeled data helped for the middle range data sets, IS-50 and IS-100 when the dictionary size was 200 or 300.
Results using sparse coding
The last two tables, Tables 6 and 7, show the corresponding results for the sparse coding method. As in the NMF, the baseline performance is much better than the PCA, and in some cases even better. The SC approach achieved the best baseline accuracy of 64 %.
As for the self-taught learning effect, we can see clear performance improvement for the small data sets IS-20 and IS-50, though not as big as in the PCA case.
Discussion
To some extend, the results presented in the previous section highlight the strengths and drawbacks of each of the matrix decomposition methods we used in our experiments. The PCA is easy to implement and computationally not expensive, but it fails to capture enough structural information from the data and shows the lowest absolute classification rate. The drawbacks of the PCA are well known and include the lack of sparseness, i.e., activations are linear combinations of the input data, difficulty to interpret the results in terms of high level data shapes, and the upper limit on the number of achievable basis vectors.
On the other hand, the NMF and sparse coding methods have iterative solutions which may become computationally challenging for big data sets, but they provide non-linear labeled data transformation albeit with different degree of sparsity. In the standard NMF method it is not possible to control the sparseness and depending on the data it can be quite low. In contrast, the sparse coding approach allows the sparseness to be adjusted (to some degree of course, since if set too high it may lead to stability and numerical issues) and optimized with respect to the data. It is expected that higher degree of sparseness forces more information to be captured by the basis vectors which is essential for the success of the self-taught learning algorithm. This is also evident from the visual inspection of the learned basis vectors using NMF and sparse coding shown in Figures 1 and 2, respectively. It is apparent that the bases learned by the SC exhibit clearer spectrum shapes with higher diversity than the NMF bases. Some of the main differences and similarities of all the three methods are summarized in Table 8.

Example of learned basis vectors using NMF (shown as spectrum images).

Example of learned basis vectors using Sparse Coding (shown as spectrum images).
In order to evaluate the self-taught learning algorithm itself, we obtained genre classification accuracy using the initial set of 1780 dimensional feature vectors, i.e., without any matrix decomposition and transformation, and a SVM classifier. The results of this evaluation are shown in Figures 3, 4, 5, and 6 for each training set IS-20, IS-50, IS-100, and ID-250, respectively, compared with the corresponding results obtained using each of the PCA, NMF, and SC data matrix decomposition methods for their best conditions. The improvement from the self-taught learning with unlabeled data is added to each of the bars in different color. Clearly, even in the regular supervised setup, NMF and SC can produce some gain in the classification performance. In total, including the effect of the unlabeled data usage, the improvement especially for small target data sizes, is quite substantial.

Genre classification results using the IS-20 data set for training in both the supervised and self-taught learning scenarios.

Genre classification results using the IS-50 data set for training in both the supervised and self-taught learning scenarios.

Genre classification results using the IS-100 data set for training in both the supervised and self-taught learning scenarios.

Genre classification results using the IS-250 data set for training in both the supervised and self-taught learning scenarios.
Conclusion
In this study, we investigated the performance of several matrix decomposition methods, such as PCA, NMF and sparse coding when applied for high level feature extraction in the self-taught learning algorithm with respect to the music genre classification task. Results of the experiments conducted under various conditions showed that the sparse coding method outperforms the PCA in absolute recognition accuracy and the NMF in terms of relative improvement due to the knowledge extracted from the unlabeled data.
As for the self-taught learning algorithm itself, the results show that it achieves its purpose, i.e., to improve the performance when the amount of labeled data is small. Experiments also suggested that this improvement in not sensitive to the size of unlabeled data set.
References
Nigam K, McCallum A, Thrun S, Mitchell T: Text classification from labeled and unlabeled documents using EM. Machine Learning 2000, 39(2–3):103-134.
Pan S, Yang Q: A survey on transfer learning. IEEE Trans. Knowledge Data Eng 2010, 22(10):1349-1359.
Raina R, Battle A, Lee H, Packer B, Ng A: Self-taught learning: transfer learning from unlabeled data. In Proceedings of International Conference on Machine Learning. NY: New York; 2007:759-766.
Cichocki A, Zdunek R, Phan Huy A, Amari S: Nonnegative Matrix and Tensor Factorizations. UK: John Wiley & Sons; 2009.
Olshausen B, Field D: Field, Emergence of simple-cell receptive field properties by learning a sparse code for natural images. Nature 1996, 381(13):607-609.
Jolliffe I: Principal Component Analysis. New York: Springer Verlag; 1986.
Zou H, Hastie T, Tibshirani R: Sparse principal component analysis. Journal of Computational and Graphical Statistics 2006, 15(2):265-286. 10.1198/106186006X113430
Zass R, Shashua A: Nonnegative sparse PCA. In Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems. British Columbia: Vancouver; 2006:1561-1568.
Virtanen T: Monaural sound source separation by non-negative matrix factorization with temporal continuity and sparseness criteria. IEEE Trans. Audio Speech Lang. Process 2007, 15(3):1066-1074.
Markov K, Matsui T: Music genre classification using self-taught learning via sparse coding. In Proceedings of IEEE International Conference on Acoustics, Speech, Signal Processing. Kyoto; 2012:1929-1932.
Markov K, Matsui T: Nonnegative matrix factorization based self-taught learning with application to music genre classification. In Proceedings of IEEE International Workshop on Machine Learning for Signal Processing. Spain: Santander; 2012:1-5.
Song Y, Zhang C, Xiang S: Semi-supervised music genre classification. In Proceedings of IEEE International Conference on Acoustics, Speech, Signal Processing. Hawaii: Honolulu; 2007:729-732.
Song Y, Zhang C: Content-based information fusion for semi-supervised music genre classification. IEEE Trans. Multimedia 2008, 10(1):145-152.
Takagi J, Ohishi Y, Kimura A, Sugiyama M, Yamada M, Kameoka H: Automatic audio tag classification via semi-supervised canonical density estimation. In Proceedings of IEEE International Conference on Acoustics, Speech, Signal Processing. Prague; 2011:2232-2235.
Fevotte C, Bertin N, Durrieu J: Nonnegative matrix factorization with the Itakura-Saito divergence: with application to music analysis. Neural Computation 2009, 21(3):793-830. 10.1162/neco.2008.04-08-771
Smaragdis P, Brown J: Non-negative matrix factorization for polyphonic music transcription. In Proceedings of IEEE Workshop on Applications of Signal Processing to Audio and Acoustics. USA: New Paltz; 2003:177-180.
Plumbley M, Blumensath T, Daudet L, Gribonval R, Davies M: Sparse representations in audio and music: from coding to source separation. Proc. IEEE 2010, 98(6):995-1005.
Henaff M, Jarrett K, Kavukcuoglu K, LeCun Y: Unsupervised learning of sparse features for scalable audio classification. In Proceedings of the 12th International Society for Music Information Retrieval Conference. FL: Miami; 2011.
Dai W, Yang Q, Xue GR, Yu Y: Self-taught clustering. In Proceedings of International Conference on Machine Learning. Helsinki; 2008:200-207.
Zhu X, Huang Z, Yang Y, Shen HT, Xu C, Luo J: Self-taught dimensionality reduction on the high-dimensional small-sized data. Pattern Recognition 2013, 46(1):215-229. 10.1016/j.patcog.2012.07.018
Duda R, Hart P, Stork D: Pattern Classification. USA: John Wiley & Sons; 2001.
Lee D, Seung H: Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401(6755):788-791. 10.1038/44565
Lee D, Seung H: Algorithms for non-negative matrix factorization. In Proceedings of Conference on Neural Information Processing Systems. CO: Denver; 2000:556-562.
Efron B, Hastie T, Johnstone I, Tibshirani R: Least angle regression. The Annals of Statistics 2004, 32(2):407-499. 10.1214/009053604000000067
Perkins S, Theiler J: Online feature selection using grafting. In Proceedings of International Conference on Machine Learning. DC: Washington; 2003:592-599.
Lee H, Battle A, Raina R, Ng A: Efficient sparse coding algorithms. In Proceedings of the Twentieth Annual Conference on Neural Information Processing Systems. British Columbia: Vancouver; 2006:801-808.
Tzanetakis G, Cook P: Musical genre classification of audio signals. IEEE Trans. Acoustics, Speech and Language Processing 2002, 10(5):293-302. 10.1109/TSA.2002.800560
Cano P, Gomes E, Gouyon F, Herrera P, Koppenberger M, Ong B, Serra X, Streich S, Wack N: ISMIR 2004 Audio Description Contest. Tech. Rep. MTG-TR-2006-02, Universitat Pompeu Fabra 2006.
Schoerkhuber C, Klapuri A: Constant-Q transform toolbox for music processing. In Proceedings of the 7th. Sound and Music Computing Conference. Barcelona; 2010.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Markov, K., Matsui, T. High level feature extraction for the self-taught learning algorithm. J AUDIO SPEECH MUSIC PROC. 2013, 6 (2013). https://doi.org/10.1186/1687-4722-2013-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-4722-2013-6