
Abstract
Background
Transfection in mammalian cells based on liposome presents great challenge for biological professionals. To protect themselves from exogenous insults, mammalian cells tend to manifest poor transfection efficiency. In order to gain high efficiency, we have to optimize several conditions of transfection, such as amount of liposome, amount of plasmid, and cell density at transfection. However, this process may be time-consuming and energy-consuming. Fortunately, several mathematical methods, developed in the past decades, may facilitate the resolution of this issue. This study investigates the possibility of optimizing transfection efficiency by using a method referred to as least-squares support vector machine, which requires only a few experiments and maintains fairly high accuracy.
Results
A protocol consists of 15 experiments was performed according to the principle of uniform design. In this protocol, amount of liposome, amount of plasmid, and the number of seeded cells 24 h before transfection were set as independent variables and transfection efficiency was set as dependent variable. A model was deduced from independent variables and their respective dependent variable. Another protocol made up by 10 experiments was performed to test the accuracy of the model. The model manifested a high accuracy. Compared to traditional method, the integrated application of uniform design and least-squares support vector machine greatly reduced the number of required experiments. What's more, higher transfection efficiency was achieved.
Conclusion
The integrated application of uniform design and least-squares support vector machine is a simple technique for obtaining high transfection efficiency. Using this novel method, the number of required experiments would be greatly cut down while higher efficiency would be gained. Least-squares support vector machine may be applicable to many other problems that need to be optimized.
Similar content being viewed by others

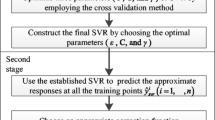

Background
Central to life functions, protein expression in normal and diseased states is essential for quantifying altered patterns of gene expression. This is especially true in the era that the sequencing of human genome has been finished. To gain insights into protein expression, we have to transfect cells with kinds of expression vectors, based on plasmid, viral vector, or transposon, etc. Transfection may be one of the commonest but indispensable procedures for cellular biology. However, in the process of evolution, eukaryotic cells tend to have low transfection efficiency in order to protect their genomes from exogenous insults. Transfection difficulty manifests itself, especially in the cotransfection of mammalian cells. Theoretically, if the transfection efficiency of single kind of plasmid is E, which ranges from 0 to 1, the efficiency of double and triple cotransfection may decline to E2 and E3, respectively. Therefore, it is of great importance to improve efficiency.
In order to enhance the transfection, several kinds of strategies are developed, which are categorized into two types: viral gene delivery carriers and non-viral gene delivery carriers. In non-viral gene delivery carriers, cationic liposomes has the widest application. Cationic liposomes are positively charged liposomes which interact with the negatively charged DNA molecules to form a stable complex. Cationic liposomes consist of a positively charged lipid and a co-lipid. A variety of positively charged lipid formulations are commercially available and many other are under development. Lipofection, one of the most frequently cited cationic lipids, was first reported by Felgner in 1987 to deliver genes to cells in culture [1]. Lipofection has been used to deliver linear DNA, plasmid DNA, and RNA to a variety of cells in culture. Liposomes offer several advantages in delivering genes to cells. (1) Liposomes have the ability to combine both with negatively and positively charged molecules. (2) Liposomes offer a degree of protection to the DNA from degradative processes. (3) Liposomes carry large pieces of DNA, potentially as large as a chromosome. (4) Liposomes can be targeted to specific cells or tissues. In addition, liposomes overcome problems inherent with viral vectors – specific concerns over immunogenicity and replication competent virus contamination. Liposomes resulted in a highly adaptable and flexible system capable of gene delivery both in vitro and in vivo. Current limitations regarding in vivo application of liposomes revolve around the low transfection efficiencies and transient gene expression. Also, liposomes display a small degree of cellular toxicity and appear to be inhibited by serum components. The ability to overcome these problems should greatly facilitate their application to a variety of gene delivery mechanisms.
Several factors have significant effects on the transfection efficiency of cationic liposomes, such as vigor of the host cells, the amount of plasmid, the amount of transfection agent, and the density of cells. However, it is hard to control vigor of host cells which has not a quantitative index. The other three factors are controllable in transfection, which can be adjusted according to the host cells and transfection agents. However, the adjustment of these three factors is a time and energy-consuming work. For most researchers, they may spend two to three months on optimizing transfection. Fortunately, several mathematical methods offer promising avenues to the resolution of this issue.
There are several ways to perform computer experiments, such as Latin Hypercube Sampling (LHS) and Uniform Design (UD). LHS was brought up by three scholars in the North American [2]. Uniform design, abbreviated as UD, was first developed by Fang et al in nineteen eighty [3]. UD seeks design points that are scattered uniformly on the domain. It has been popular since 1980. The main advantages of UD may be generalized as the following: first, it has the ability to greatly reduce the number of experiments while not to alter the representativeness; second, it generates a regression model based on the results and it's able to predict at what independent variables the dependent variable may gain the maximum.
As a relatively new algorithm used for classification and regression, support vector machine (SVM) was developed in the 1990s [4, 5]. It is a desired method for estimation based on finite-sample and therefore is able to solve a lot of practical problems in case of limited samples. Their practical successes may be attributed to solid theoretical foundations based on Vapnik Chervonenkis theory, and to the minimization of structural risk [6]. In order to implement the SVM into our transfection optimization, the least squares support vector machines (LS-SVM) was used, which has a growing popularity for regression problems [7]. It can be argued that LS-SVM would yield better generalization for regression problems on finite samples [8].
Results and discussion
As was shown in Table 1 and Figure 1, transfection efficiency varied greatly with the changes of the amount of plasmid, LipofectAMINE, and the number of seeded cells. If these three independent varies did not match, transfection efficiency would decline sharply. In Table 1 and Figure 1, experiment L has the lowest efficiency (13.49%) for the ration of plasmid to transfection agent is too low, while experiment K has the highest efficiency owing to the designed ratios between the three independent factors. According to the established model, transfection efficiency would gain the maximum if 2.1×105 of cells, 0.66 μg of plasmid and 1.32 μg of LipofectAMINE were used. And this was accord with the observed data (Table 2 and Figure 2). More than that, there was a high degree of coincidence between calculated transfection efficiency and the deduced date from the model (Figure 3). Thus, by virtue of UD and LS-SVM, only 15 experiments, which can be performed in two 24-well plates, are needed to get the optimal transfection conditions whereas more than 153 experiments are needed to attain the expected purpose by using traditional method. What's more, if more accurate conditions were demanded, the number of experiments would greatly exceed 153.

Varied expression of green fluorescent protein under different transfection conditions.

Varied expression of green fluorescent protein under the conditions centering to the predicted optimal transfection conditions. G1, G2, G3 showed the same visual field observed under the green, yellow and red light, respectively.

Coincidence between observed values and predicted values based on LS-SVM.
The proper setting of LS-SVM model training parameters was tuned by grid search. The most common performance assessment method is probably the k-fold cross-validation [9] and the leave-one-out procedure. In the k-fold cross-validation, the training data are randomly split into k mutually exclusive subsets (the folds) with approximately equal sizes. The resulting LS-SVM model is obtained by training on k-1 subsets and then the model is tested on the remaining one subset. This procedure is repeated for k times and in this fashion each subset is used for testing only once. By averaging the test errors over the k trials it gives an estimate of the expected generalization error. The leave-one-out procedure can be viewed as an extreme form of the k-fold cross-validation with k equal to the number of examples. Leave-one-out is known as an unbiased estimation method for small-samples problems, such as our application. Therefore, fifteen times of training and test repeated on a pair of parameters and each MSE value for a pair of parameters were reported by the leave-one-out procedure. Part of results was listed in Table 3. As was shown in Table 3, the minimum MSE is found at a pair of parameters (γ = 42, C = 1500), and then the LS-SVM model obtains a peak estimated performance. After the optimal parameters for model construction are known, the according model (final model) is validated by predicting the validation data and comparing these predictions with the real observations.
The discrepancy between the predicted value and their respective observed data was listed in Table 4. From Table 4, it could be find that the maximum of observed data was N7 (92.32%) and the maximum of predicted values based on LS-SVM was also N7 (84.04%). The error ratio between observed data and predicted value of LS-SVM was less than 10%. Thus, LS-SVM has an excellent predicted ability (generalization ability) on our problem. The mutual influence between the predicted value and two of all the three variables was shown in Figure 4, 5 and 6. In a three dimensional surface, each mesh point in the (x, y)-plane stood for a variable combination and the z-axis stood the predicted value. Figure 4, 5 and 6 showed that the change of LS-SVM predicted value on ten test samples was consistent with observed data.

Response surface showing the effect of plasmid and cell on transfection efficiency. Pink response surface representing the real efficiency and blue response surface representing the predicted efficiency.

Response surface showing the effect of LipofectAMINE and cell on transfection efficiency. Pink response surface representing the real efficiency and blue response surface representing the predicted efficiency.

Response surface showing the effect of LipofectAMINE and plasmid on transfection efficiency. Pink response surface representing the real efficiency and blue response surface representing the predicted efficiency.
The contribution of a specific independent variable was also evaluated. Table 5 showed the average MSE when one specific variable was ignored. As is indicated by Table 5 and Figure 7, 8 and 9, amount of plasmid has the most significant effect on transfection efficiency, followed by amount of LipofectAMINE, while the density of seeded cells has the least effect on transfection efficiency. And this result coincided with our experience.

Response surface showing the effect of random alteration of the seeded cells density on transfection efficiency.

Response surface showing the effect of random alteration of the amount of plasmid on transfection efficiency.

Response surface showing the effect of random alteration of LipofectAMINE on transfection efficiency.
Owing to UD, the amount of test points required can be enormously reduced, especially when the experimental region has many factors and multiple levels, while the results that reflect the major characteristics of the experimental system are ensured. As an efficient fractional factorial design, UD has been widely applied in manufacturing, system engineering, pharmaceutics, and natural sciences in the past decades [10–12]. The UD was used in this research to describe factors that significantly influence transfection efficiency to obtain a smaller, more manageable set. To perform a computer experiment, in order to have a wide coverage of the entire design region with a limited number of runs, UD is a good recommendation.
The SVM is a machine learning technique with a strong theoretical foundation that has been used to improve classification accuracy in biological applications [13–19]. The SVM is a maximum margin classifier that can solve non-linear classification problems by learning an optimal separating hyperplane in a higher-dimensional feature space. By use of non-linear kernel functions such as a Gaussian kernel, complex and non-linear decision functions can be learned by the SVM. LS-SVM is a reformulation to standard SVM. It is closely related to regularization networks and Gaussian processes but it additionally emphasizes and exploits primal-dual interpretations from optimization theory. In our experiment, LS-SVM mapped the original input space into a high dimension feature space by a Gaussian kernel and then learns a smoothest hyperplane to fit the training data. From statistical learning theory, it can be expected that this hyperplane would have excellent generalization ability and has minor local extreme value. Together, UD has the ability to greatly reduce the number of experiments while not to alter the representativeness and LS-SVM would yield better generalization for regression problems on finite samples. Thereupon, the integrated application of UD and LS-SVM would have high prediction accuracy and would contribute to transfection optimization.
Conclusion
This paper investigates the integrated application of UD and LS-SVM to transfection, for obtaining precise information on the optimal conditions. Based on our experiments, UD and LS-SVM appear to have high efficiency and perform well even when undergone experiments are extremely scarce. With the established model, we are able to gain the optimal transfection conditions and the highest transfection efficiency that can be reached. Thus, the required time and experiments to improve transfection efficiency can be greatly reduced while the achieved efficiency may even be higher than traditional methods. It seems that LS-SVM has higher accuracy in the prediction of optimal transfection conditions than it does in the prediction of highest transfection efficiency; nevertheless, we usually have higher stringency of the information on optimal transfection conditions. It should be pointed out that the vigor of host cells and the purity of plasmid have crucial effect on the transfection efficiency too. However, these factors are uncontrollable in most settings. Further interpretation of the results obtained from other host cell lines is required. These issues are part of our ongoing research.
Methods
Cell Culture
The 293FT cell line was maintained in DMEM supplemented with 100 mL/L fetal calf serum, 2 mmol/mL L-glutamine, 100 μg/mL penicillin and 100 units/mL streptomycin. The cells were incubated in a humidified incubator at 37°C containing 50 mL/L CO2. Cell viability was estimated by the trypan blue dye exclusion method. The 293FT cells were seeded into 24-well plates 24 h prior to transfection. Three wells of cells were transfected for every experiment. The cells were transfected using LipofectAMINE 2000 (abbreviated as LipofectAMINE) cationic liposome (Invitrogen, Carlsbad, California, USA) and the cells were harvested 36 h after transfection. Transfection efficiency was evaluated by calculating the ratio of cells that express green fluorescent protein (GFP) by using flow cytometer (COULTER EPICS XL, Beckman, USA). The experiments were performed in duplicate.
Uniform Design
On the basis of orthogonal design, UD as a new experimental design method was proposed by Fang et al in 1980s. The characteristics of UD are taking no account of regular comparability, completely ensuring the uniformity, and distributing the test points in the experimental scope adequately and uniformly. UD finds good representative points uniformly scattered over the sample space for a much more efficient parameter search. It is one kind of space filling designs that can be used for computer techniques. Suppose there are s samples of interest over a domain CS. The goal here is to choose a set of m points p m = {θ1, ..., θ m } ⊂ CSsuch that these points are uniformly scattered on CS.
Experimentations
In a protocol consists of 15 experiments, amount of liposome, plasmid, and the number of seeded cells were set as independent variables while transfection efficiency was set as dependent variable. Each independent variable had 15 levels. The ranges of independent variables were set according to the instruction of manufacturer. The protocol was performed according to the principle of UD (Table 1). Each transfection efficiency (dependent variable) was calculated by flow cytometer. The expression of GFP in each experiment was also observed by fluorescence microscope (Eclipse 80I, Nikon, Tokyo, Japan). A model was constructed by using LS-SVM. The respective fitted value to each measured transfection efficiency was also deduced from the established model. Another protocol consisting of 10 experiments was designed centering on the predicted optimal conditions at which the dependent variable would reach the maximum (Table 2). And the observed GFP expression was shown in Figure 1 and Figure 2. All the observed data in Table 1 and Table 2 were the mean values of three independent experiments.
Development of the LS-SVM based models for prediction of transfection efficiency
In regression formulation, the goal is to estimate an unknown continuous-valued function based on a finite number set of noisy samples (x i , y i ), (i = 1, ..., n), where d-dimensional input is x ∈ Rdand the output is y ∈ R. In SVM regression formulations, the input X is first mapped into a m-dimensional feature space using some fixed (nonlinear) mapping, and then a linear model is constructed in this feature space [8]. Using mathematical notation, the linear model (in the feature space) f(x, ω) is given by Equation (1), where g j (x), j = 1, ..., m denotes a set of nonlinear transformations, and b is the "bias" term.

The quality of estimation is measured by the loss function L(y, f(x, ω)). SVM regression uses a new type of loss function called ε-insensitive loss function proposed by Vapnik [6]:

SVM regression tries to reduce model complexity by minimizing ||ω||2. In addition, it introduces (non-negative) slack variables ξ
i
,  i = 1, ... n to measure the deviation of training samples outside the ε-insensitive zone. Thus, SVM regression is formulated as minimization of the following function:
i = 1, ... n to measure the deviation of training samples outside the ε-insensitive zone. Thus, SVM regression is formulated as minimization of the following function:

Compared with simple SVM, LS-SVM computes the solution by solving a linear system instead of quadratic programming. This is due to the use of equality instead of inequality constraints in the above problem formulation. It is well known that LS-SVM generalization performance (estimation accuracy) depends on a good setting of meta-parameters parameters C and the kernel parameters. The main performance metric of LS-SVM is the prediction risk (Equation (4)), defined as mean square error (MSE), between estimated values derived from LS-SVM and true values for testing inputs.

Therefore, for ensuring good generalization performance, the main issue on LS-SVM application depends on the proper setting of these parameters for a given data set. Selecting a particular kernel type and kernel function parameters is usually based on application-domain knowledge and should also reflect distribution of inputted values of the training data [20]. Here, we showed example of SVM regression using radial basis function (RBF) kernels (Equation (5)), where the RBF width parameter γ should reflect the distribution/range of x-values of the training data.

The LS-SVM based model building processes were carried out by using the software package named LS-SVMlab1.5 available at http://www.esat.kuleuven.ac.be/sista/lssvmlab/. This toolbox provides in-depth functionality of SVM. Functions include tuning, optimizing, validating, and training SVMs. Significantly, it provides a good visual representation of the trained LS-SVMlab. The meta-parameters of the LS-SVM model with a Gaussian kernel function are γ (the width of the Gaussian kernels) and C (regularization factor). The model construction process consisted consecutively of: i) selection of the inputted variables, ii) selection of the training parameters (C and γ), iii) construction of the model, iv) performance evaluation by validation data.
Contribution analysis of independent variables
The contribution of specific variable was evaluated by using a method based on LS-SVM. Random alteration of the value of a specific variable has a similar effect to take out of this variable. However, the feature space keeps unchanged when it undergoes this process. There are only three variables, so that we can analyze them one by one. The analysis process was described as follows: i) select a variable, such as the density of cells; ii) random exchange the 15 training samples value of cell density and keep other two variables (the amount of plasmid and the amount of LipofectAMINE) unchanged; iii) train another LS-SVM using the same parameters (γ = 42, C = 1500); iv) test the trained LS-SVM on 10 testing samples, get the predicated value and MSE; v) repeat step ii to step iv for 10 times, get the average predicated value and average MSE; vi) repeat step i to step v on other two variables. The variable with the biggest MSE has the most important effect on the depend variable.
References
Felgner PL, Gadek TR, Holm M, Roman R, Chan HW, Wenz M, Northrop JP, Ringold GM, Danielsen M: Lipofection: a highly efficient, lipid-mediated DNA-transfection procedure. Proc Natl Acad Sci USA. 1987, 84 (21): 7413-7417. 10.1073/pnas.84.21.7413.
McKay MD, Beckman RJ, Conover WJ: A Comparison of Three Methods for Selecting Values of Input Variables in the Analysis of Output From a Computer Code. Technometrics. 1979, 21: 239-245. 10.2307/1268522.
Fang KT: The uniform design: application of number-theoretic methods in experimental design. Acta Mathematicae Applagatae Sinica. 1980, 3: 363-372.
Vapnik VN: The Nature of Statistical Learning Theory [M]. 2000, New York: Springer-Verlag
Burges CJC: A Tutorial on Support Vector Machines for Pattern Recognition. Data Mining and Knowledge Discovery. 1998, 2 (2): 121-167. 10.1023/A:1009715923555.
Vapnik VN: An overview of statistical learning theory. IEEE TRANSACTIONS ON NEURAL NETWORKS. 1999, 10 (5): 988-999. 10.1109/72.788640.
Collobert R, Bengio S: SVMTorch: support vector machines for large-scale regression problems. J Mach Learn Res. 2001, 1: 143-160. 10.1162/15324430152733142.
Suykens JAK, Vandewalle J: Least Squares Support Vector Machine Classifiers. Neural Processing Letters. 1999, 9 (3): 293-300. 10.1023/A:1018628609742.
Stone M: Cross-validatory choice and assessment of statistical predictions. Journal of the Royal Statistical Society. 1974, 36 (1): 111-147.
Ji YB, Alaerts G, Xu CJ, Hu YZ, Heyden Vander Y: Sequential uniform designs for fingerprints development of Ginkgo biloba extracts by capillary electrophoresis. J Chromatogr A. 2006, 1128 (1–2): 273-281. 10.1016/j.chroma.2006.06.053.
Liu D, Wang P, Li F, Li J: Application of uniform design in L-isoleucine fermentation. Chinese journal of biotechnology. 1991, 7 (3): 207-212.
Xu CP, Yun JW: Optimization of submerged-culture conditions for mycelial growth and exo-biopolymer production by Auricularia polytricha (wood ears fungus) using the methods of uniform design and regression analysis. Biotechnology and applied biochemistry. 2003, 38 (Pt 2): 193-199. 10.1042/BA20030020.
Baten AK, Halgamuge SK, Chang BC: Fast splice site detection using information content and feature reduction. BMC bioinformatics. 2008, 9 (Suppl 12): S8-10.1186/1471-2105-9-S12-S8.
Cheng CW, Su EC, Hwang JK, Sung TY, Hsu WL: Predicting RNA-binding sites of proteins using support vector machines and evolutionary information. BMC bioinformatics. 2008, 9 (Suppl 12): S6-10.1186/1471-2105-9-S12-S6.
Guo Y, Yu L, Wen Z, Li M: Using support vector machine combined with auto covariance to predict protein-protein interactions from protein sequences. Nucleic acids research. 2008, 36 (9): 3025-3030. 10.1093/nar/gkn159.
Han P, Zhang X, Norton RS, Feng ZP: Large-scale prediction of long disordered regions in proteins using random forests. BMC bioinformatics. 2009, 10 (1): 8-10.1186/1471-2105-10-8.
Kong L, Zhang Y, Ye ZQ, Liu XQ, Zhao SQ, Wei L, Gao G: CPC: assess the protein-coding potential of transcripts using sequence features and support vector machine. Nucleic acids research. 2007, W345-349. 10.1093/nar/gkm391. 35 Web Server
Krause L, McHardy AC, Nattkemper TW, Puhler A, Stoye J, Meyer F: GISMO – gene identification using a support vector machine for ORF classification. Nucleic acids research. 2007, 35 (2): 540-549. 10.1093/nar/gkl1083.
Verikas A, Gelzinis A, Bacauskiene M, Uloza V, Kaseta M: Using the patient's questionnaire data to screen laryngeal disorders. Computers in biology and medicine Comput Biol Med. 2009 Feb;39(2):148-55. 2009, 39 (2): 148-155.
Cherkassky V, Ma Y: Practical selection of SVM parameters and noise estimation for SVM regression. Neural Networks. 2004, 17 (1): 113-126. 10.1016/S0893-6080(03)00169-2.
Acknowledgements
We thank professor Tian-Hui Hu and associate professor Hong-Bin Dai for discussion and comments on the manuscript. The authors wish to thank anonymous referees for comments/suggestions that helped in improving the manuscript.
This research was supported by National Natural Science Foundation of China (No. 30750013) and Key Science Research Project Natural Science Foundation of Xiamen (No. WKZ0501).
Author information
Authors and Affiliations
Corresponding author
Additional information
Authors' contributions
JSP and MZH generated the idea. JSP, MZH and JLR designed the study. JSP, MZH, JYC, JD and HXS performed the experiments. QFZ and HZW performed the analysis of the transfection data and generated the model. LKL and DQY tested the model. JSP, MZH, QFZ and HZW wrote the draft manuscript. JSP, MZH and JLR proofread the manuscript. All authors participated in production of the final version of the manuscript, read it and approved it.
Jin-Shui Pan, Mei-Zhu Hong contributed equally to this work.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Pan, JS., Hong, MZ., Zhou, QF. et al. Integrated application of uniform design and least-squares support vector machines to transfection optimization. BMC Biotechnol 9, 52 (2009). https://doi.org/10.1186/1472-6750-9-52
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1472-6750-9-52