
Abstract
The rapid advancement of remote sensing and availability of polarimetric SAR (PolSAR) data have facilitated to monitor the land use land cover (LULC) dynamics. In the recent past, polarimetric decomposition theorems are applied widely to perform LULC classification with the help of machine learning techniques. In this study, we utilized ALOS PALSAR-1 L-band quad polarimetric data for performing polarimetric decomposition, textural information extraction, and to generate LULC maps over the western part of Mizoram state, northeast India. The study area comprises three districts, namely Mamit, Lunglei, and Lawngtlai. We adopted two representative full-polarimetric decomposition models: classical model-based Freeman–Durden and Yamaguchi decomposition. These methods decompose the coherency matrix of PolSAR images into surface, double-bounce, and volume scattering. Textural measures, such as variance, contrast, entropy, homogeneity, dissimilarity, and uniformity are also retrieved using grey-level co-occurrence matrix (GLCM) for LULC classification. For LULC classification, we employed a support vector machine classifier and calculated the area statistics of LULC. The outcomes were checked with the help of confusion matrix derived for six classes, such as built-up, deciduous forest, evergreen forest, scrubland, bareland, and waterbody. Each LULC class is separated using the scattering properties of PolSAR images. Results exhibited that Yamaguchi four-component decomposition (overall accuracy 90% and kappa coefficient 0.88) gives relatively better LULC classification results than the Freeman–Durden three-component decomposition (overall accuracy 87% and kappa coefficient 0.84). Use of textural images of GLCM has supported the classification accuracy at par with the Yamaguchi model. Integration of polarimetric information offers a new dimension in LULC classification and produces high accuracy maps. This approach overcomes the limitations of optical data in cloud covering areas, and furthermore, it provides better classification accuracy.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
The alteration of terrestrial surface by human activities is typically known for Land use land cover (LULC) change. Over the last few decades, the LULC is changing rapidly around the globe [1]. It is widely documented that the alterations of LULC have caused severe environmental problems, such as floods, landslides, deforestation, loss of biodiversity, and urbanization, among others [2,3,4,5,6,7] due to mismanagement of agriculture, forest, urban, wetland, and forest. So, LULC maps are very essential for understanding any unprecedented changes in agriculture [8,9,10], forest ecosystems [7, 11], biodiversity/ecological process [6], environmental process, and hazard assessment [4]. LULC change information is essential for providing vital input to decision-making bodies of natural resources management including town planning.
LULC maps can be created through field surveys or remote sensing techniques. As field surveys are comprehensive, costly and cumbersome, typically remote sensing techniques were preferred in the recent years. In the case of remote sensing, digital image processing techniques play an important role in LULC classification due to availability of various multi-spectral satellite images (Landsat, SPOT (Satellite Pour l’Observation de la Terre), IRS (Indian Remote Sensing satellites), ASTER (Advanced Spaceborne Thermal Emission and Reflection Radiometer), Sentinel-2A) including the synthetic Aperture Radar (SAR) images, such as ENVISAT (Environmental Satellite), ALOS (Advanced Land Observing Satellite) PALSAR (Phased Array type L-band Synthetic Aperture Radar), RADARSAT (Radar Satellite), TSX, (TerraSAR-X), and TDX (TanDEM-X). Classification of remotely sensed data produces thematic maps; however, it is very challenging to achieve accuracy of classified LULC map. The precision and accuracy of an imagery classification depends upon many factors, such as complexity of the landscape, selected remote sensing data, spatial resolution, atmospheric condition, adopted image processing techniques, and classification approaches. All these factors can affect the effectiveness and accuracy of a LULC map [12]. Furthermore, the classification methods employed in mapping LULC are perhaps the most important one [12] and pose a challenge to the research community.
Numerous techniques have been developed over the years to produce LULC maps using the satellite images. The commonly used techniques are image classification [13, 14], principal component analysis [15], fuzzy classification [16], artificial neural network [17], machine/deep learning [18, 19], and object-based classification [20]. Most of these supervised classification methods involve training and human supervision. Further, most of these techniques are employed with optical satellite images that have inherent limitations of clouds, but these techniques are rarely used with the full-polarimetric SAR data. With the recent advancement of availability of full-polarimetric SAR data with multi-bands (X, C, S, L bands), there are approaches, namely polarimetric decomposition theorems which applied widely to perform LULC classification by using the machine learning classification methods [21,22,23]. Polarimetric decomposition theorems are developed either based on eigenvalue decomposition or physical model-based decomposition. Most common statistics and physical model-based decomposition methods developed for PolSAR data are Cloude–Pottier (H/A/α), Huynen, Cameron, Freeman–Durden, and Yamaguchi decompositions, which are being utilized to retrieve various maps, such as LULC maps, forest density maps, and crop type’s maps, among others. [22,23,24]. Based on the coherency and covariance matrix, Moriyama decomposition, Krogager decomposition, Van Zyl decomposition, and Touzi decomposition were also developed. Polarimetric SAR (PolSAR) images were analysed using decomposition theorems [21], which also increase the accuracy of LULC. PolSAR was intensively used as a monitoring tool for crops that grew during the rainy season [25]. Studies have also suggested that a combined approach of using optical and radar images improves the LULC maps [26, 27].
In radar polarimetry, the utilization of complete electromagnetic vector wave information has gained momentum over the years. Using radar polarimetry, Cloude and Pottier [21], had made important contribution in the field of target decomposition by the help of entropy/anisotropy/alpha (H/A/α) decomposition method, which is also known as eigenvector–eigenvalue decomposition. These parameters/attributes have become the standard tool for target characterization and image classification. Freeman–Durden and Yamaguchi [22, 23] introduced the concept of three/four scattering properties, such as surface scattering, double-bounce scattering, volume scattering, and helix scattering from objects. So the targets’ structure information can be deduced as the sum of all four scattering components. Typically, surface scattering relates to rough surfaces, such as water bodies, bare soil (non-vegetated), while double-bounce scattering corresponds to dihedral corners, namely wetland vegetation, artificial targets related to ground-wall corners. Volume scattering relates to random oriented dipoles, namely the tree canopy, whereas helix scattering is associated with man-made structures in urban areas, but it disappears in all natural distributed scattering. Thereby, the PolSAR can differentiate different LULC classes, such as bare land, buildings, water bodies, vegetation, agriculture, and shrubland, among others by the help of scattering mechanism-based PolSAR land cover classification methods [28,29,30]. However, there are some misclassifications using the attributes of scattering mechanism (i.e. the surface scattering-Ps, double-bounce-Pd and volumetric-Pv)-based PolSAR LULC classification. This is because some different classes can have the identical scattering mechanism and the same classes can have different scattering mechanisms particularly for the urban areas and the vegetation [31, 32]. To improve LULC classification using polarimetric information, studies have explored PolSAR image classification methods, the image texture-based classification methods (like GLCM texture features), and the interferometry information [33, 34]. In addition, wide variety of polarimetric features like backscattering coefficients of different polarizations, such as linear (HH, HV, VV), circular (LL, RR, RL), and their ratios, were used to play up the differences between the radar bands and polarizations which can be more sensitive in certain field conditions. Despite these attempts, there are some deficiencies in LULC classification accuracy. Typically there are some information redundancies like the entropy/anisotropy/alpha (H/A/α) attributes that represent volume scattering (Pv), which is also part of the Freeman–Durden and Yamaguchi models. The attributes derived from Cloude–Pottier decomposition technique exhibited good potential to discriminate forest classes having more or less canopy, but it cannot distinguish accurately the ecological succession classes especially by utilizing H/α attributes [35]. However, attributes like anisotropy (A) and Pv exhibited a higher separability for forest classes than bare land, shrubland, and oriented urban classes. Most of the classification methods are pixel-based, which results in the sensitivity to speckle noise and tonal information in SAR pixels. However, region-based classification can increase the classification accuracy by segmenting PolSAR images. In image segmentation analysis, a variety of spatial and textural information like shape, texture, area, and context can be obtained, which is important for improving the LULC classification [36].
In principle, polarimetric model decompositions are quite similar to feature extraction or visual interpretation [37]. Several algorithms such as machine learning classifier (neural network, support vector machine, random forest) [38,39,40], grey-level co-occurrence matrix (GLCM) [41,42,43], and Wishart classifier [44, 45] are developed to perform PolSAR image classification and to retrieve LULC maps. The Wishart classifier is a statistics-based method that applies perfectly if the ground target is either homogeneous or has only one scattering. Several studies accomplished classification of fully PolSAR data using decision tree, neural network, object-based, and contextual algorithms [28, 46,47,48]. Among the aforesaid algorithms, support vector machine (SVM) is widely used for LULC classification using the PolSAR data [27, 40, 49, 50]. The overreaching objectives of this study are: (1) to decompose the L-band full-polarimetric ALOS PALSAR data using the physical-based model Freeman–Durden and Yamaguchi decomposition methods, (2) to explore decomposition scattering components and GLCM-based texture features to classify LULC by using the SVM classifier, and (3) to compare classified LULC maps among Freeman–Durden, Yamaguchi decomposition, and GLCM methods.
2 Study area
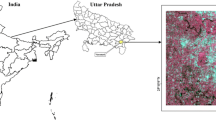
The study area is a part of Mamit, Lunglei, and Lawngtlai districts in Mizoram state, Northeast India. The state is situated between 21°58′ N to 24°35′ N Latitude and 92°15′ E to 93°29′ E Longitude (Fig. 1). Total geographical area of the state is 21,087 km2. There are eight districts in the state, and the study area covers parts of three districts, namely Mamit in North, Lunglei in the middle, and Lawngtlai in the South part of Mizoram state. The study area is known for the tropical evergreen forest that comprises several hill ranges with prominent relief. The height of hill ranges varied from 1179 to 2157 m (above msl). The hills are extremely steep with rugged terrain and separated by rivers. Major rivers flow either to north or south are Tuirial River in Mamit district, Mat and Tuichang Rivers in Lunglei district, Kawnpui and Kaladan Rivers in Lawngtlai district, and these rivers create usually deep gorges. The climate is characterized by a tropical humid climate with cold winters and cool summers. The temperature varies from 11 °C in winter to 30 °C in summer, and the annual rainfall received between 2000 and 2850 mm. There are three major types of soils, such as hill soil (colluvial soil along steep side slopes), valley soil (mixture of colluvial and alluvial), and terrace soil (deposits of cobbles and pebbles).

Study area shown in colour composite image using the HH, HV, and VV polarization of L-band ALOS. The subset map a is a part of Mamit district, b is a part of Lunglei district, and c is a part of Lawngtlai district situated in western part of Mizoram state, Northeast India
3 Materials and methods
The Phased Array type L-band Synthetic Aperture Radar (PALSAR)-1 is a microwave sensor developed by JAXA with available data from 2006 to 2011 [51]. The Advanced Land Observing Satellite (ALOS) PALSAR-1 L-band (15–30 cm) is available in the form of quad polarization (HH + HV + VH + VV), which are sent and receive horizontally (H) and vertically (V) polarized waves by radar antenna. It has a swath width of 30 km and temporal resolution of 46 days. For this study, we used level 1.1 quad polarized data having single look complex (SLC) format, which contains the amplitude and phase information. Due to unavailability of quad polarized data in the recent years, we only acquired one ALOS L-band scene that corresponds to 28th May 2009. The L-band data have been processed using the PolSARpro and SNAP software, developed by ESA [52]. The sensor characteristics are provided in Table 1. In the present study, the thematic classes, such as built-up, deciduous forest, evergreen forest, scrubland, bareland, and waterbody, are discriminated by using the PolSAR images with the help of PolSAR decomposition methods.
3.1 Pre-processing of PALSAR data (L-band)
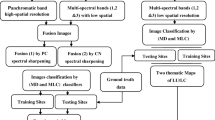
The flowchart of the methodology has been given Fig. 2, where we described satellite data pre-processing steps. The methodology employed is based on the use of polarization coherency matrix (T3). Prior to extraction of coherency matrix elements, the SLC data in slant range were converted to ground range using the multi-looking process (window size 5 × 5) that reduces coherent noise in the radar image. Then, a boxcar filter with 5 × 5 window size was applied to 3 × 3 coherency matrix (T3) to get the filtered image. The coherency matrix elements contain the complex information related to different physical scatters present in the PolSAR image. The physical scattering mechanisms are based on their geophysical parameters, such as surface roughness, dielectric constant, geometrical structure, shape, orientation, and reflectivity. Furthermore, the two decomposition algorithms, Freeman–Durden and Yamaguchi, were applied to separate physical scattering properties of ground target [22, 23]. Finally, orthorectification was applied to images of Freeman–Durden and Yamaguchi decomposition as it eliminates the height-induced azimuth and range shifts over this mountainous area. Training samples for the LULC classes, namely built-up, deciduous forest, evergreen forest, scrubland, bareland, and waterbody, were collected from the orthorectified images with the help of Google earth optical imageries. The orthorectified Freeman–Durden and Yamaguchi decomposition images were furthermore used through SVM classifier. Validation and accuracy assessment of LULC map were undertaken by using training sample points from the Google earth optical imagery and treated it as a reference data source.

The detailed flowchart of the methodology adopted to map LULC in parts of three districts in Mizoram state
To compare the LULC statistics under each LULC class, the available LULC data at 1:50,000 scale were used and these data were from National Remote Sensing Centre (NRSC) [54], Department of Space (DoS), Government of India. The LULC of NRSC was prepared based on the Resourcesat‐2 terrain corrected Linear Imaging Self-scanning Sensor (LISS)‐III data of year 2011–12. Due to lack of data on LULC statistics of NRSC for the year 2009, we compared with the closest period data period 2011–12 by assuming slow response of LULC at demi-decadal period.
3.2 Polarimetric decomposition methods and image texture analysis using GLCM
The major advantage of PolSAR data is the utilization of backscatter coefficients that strongly depends on the scattering properties of ground target. For full-polarimetric data analysis, we attempted a three-component polarimetric decomposition model called Freeman–Durden Decomposition (henceforth called FDD) as a large area was covered by natural forest in the study area. This model describes the scattering contributions from surface, double-bounce, and volume by phase and intensity information. The detailed mathematical equations related to scattering coefficients were provided in [22], wherein scattering attributes were obtained directly from a scattering coherent matrix. The backscattering matrix of volume scattering is modelled as a thin infinite dipole, the double-bounce is modelled by a dielectric dihedral corner reflector, and the surface (single-bounce) scattering is modelled by a first-order Bragg scattering. The surface scattering component is associated with water bodies, bare or ground soil (i.e. non-vegetated surface), a dihedral scattering component is associated with oriented urban areas and wetland vegetation, and a volume scattering component is associated with vegetation.
A four-component polarimetric decomposition model called Yamaguchi decomposition (henceforth called YD) was also attempted [23]. This model describes the scattering contributions from surface, double-bounce, volume, and helix by phase and intensity information. This scheme basically includes a three-component introduced by Freeman and Durden, which deals with the reflection symmetry that the co-pol and the cross-pol correlation were close to zero. Helix scattering power is added as a fourth component, which generally appears in complex urban areas describing man-made targets in urban area scattering [23].
Image texture analysis has been broadly used to characterize diverse land features and useful for generating accurate LULC classification [56, 57]. The widely used texture method is grey-level co-occurrence matrix (GLCM), wherein wavelets, Gabor filters, and local binary patterns (LBPs) were also used for extracting the texture features. Initially, Haralick et al. [41] proposed 14 texture measures from the probability matrix, and in the present study, we used six texture measures, i.e. variance, contrast, entropy, homogeneity, dissimilarity, and uniformity. Texture features extracted from radar images provide useful information. Texture measures were extracted from HH, HV, VV, and SPAN amplitude images. The SPAN image is an average of HH, HV, VV, and, consequently, has a lower speckle noise than individual HH, HV, VV images. We have set the quantization level at 64, window size 7 × 7, and angle 90 degree. A total of 24 GLCM texture features were extracted as input layers for SVM classification.
3.3 Support vector machine (SVM) classifier
The SVM classifier has been used often for LULC mapping using PolSAR satellite images [38]. This classifier is developed based on machine learning theory [39], which provides higher accuracies in LULC classification as compared to other classifiers. SVM classifier discriminates the classes by fitting an optimal separating hyperplane to the training samples in a multi-dimensional feature space [58]. It uses kernel function to make nonlinear decision boundaries into linear ones in a high-dimensional space [58, 59]. In this study, the SVM classification was performed using PolSARpro 5.0 software, wherein two decomposition images (FDD and YD) were used as an input data to classifier. Furthermore, the GLCM texture images were used as an input data for SVM classification.
3.4 Training samples collection and accuracy assessment
The training samples selected for LULC classes are given in Table 2, and furthermore, these samples were used for classification and validation. There is no overlap between the training and testing data, wherein about 70% of pixels were used for training purposes. The remaining 30% pixels were used for validation. In addition, some points were also obtained from the Google earth high-resolution optical imageries and considered as reference data for accuracy assessment of LULC map.
The typically an error or confusion matrix is commonly used for accuracy assessment of LULC classified maps. The confusion matrix contains class types obtained from the classified map in rows, whereas class types obtained from the reference data in columns. The correctly classified pixels were allocated in diagonals, while misclassified pixels were represented in the off-diagonal one. To evaluate LULC classification map, four metrics, such as producer accuracy, user accuracy, overall accuracy, and kappa coefficient, were derived based on confusion matrix [60].
4 Results
4.1 Freeman–Durden and Yamaguchi decomposition scattering images
The orthorectified decomposed scattering properties of a target using FDD are shown in Fig. 3. In the FDD image, double-bounce scattering is shown in red and scattering relates to artificial targets like ground-wall corners, and building blocks. Volume scattering is shown in green and scattering represents forests. The surface scattering is shown in blue and scattering represents bare soil, fallowland, and rivers. It can be noted that volume scattering is dominant within the extensive areas of hill ranges with forest and scrubland coverage across the three districts. Strong surface scattering also appeared over the Lawngtlai district representing the agriculture fields, flat terrain, and urban scattering.

Orthorectified Freeman–Durden decomposition images with the double-bounce in red, volume scattering in green, and surface scattering in blue. The zoomed subset represents a volume, b double-bounce, and c surface scattering over the three districts, namely Mamit, Lunglei, and Lawngtlai
The scattering properties of targets produced by Yamaguchi decomposition were quite similar to the three-component-based FDD across the three districts (Fig. 4). However, the helix scattering is stronger especially over the Lawngtlai district, which generally appears in complex urban areas. These areas can appear as red colour which reflect from the urban scatters.

Orthorectified Yamaguchi decomposition images with the double-bounce in red, volume scattering in green, and surface scattering in blue. The zoomed subset represents a volume, b double-bounce, c surface scattering and d Helix scattering over the three districts, namely Mamit, Lunglei, and Lawngtlai
4.2 SVM-based LULC classification using FDD image
The LULC classification map derived from SVM classifier is presented in Fig. 5 over the parts of three districts in the state. This classification was performed based on six LULC classes, namely built-up, deciduous forest, evergreen forest, scrubland, bareland, and waterbody, and each LULC class was separated using the scattering properties of images. The results indicated that the predominant classes are evergreen and deciduous forest and they were marked by green colours in the map of Mamit, Lunglei, and Lawngtlai district. The scrubland is presented in yellow, while rivers or water bodies were presented in blue colour. The built-up and fallowland classes were prominent especially in Lawngtlai district. The detailed area statistics of each class are presented in Table 3.

LULC classification map using SVM algorithm based on FDD scattering image. The three subset represents a part of a Mamit, b Lunglei, and c Lawngtlai districts
The classified LULC map as per SVM using FDD image showed that the forest accounted for 76%, 77%, and 73% of area, in Mamit, Lunglei, and Lawngtlai districts, respectively. Across these three districts, forest cover is a dominant class followed by scrubland (about 17–18%). This class mostly comprised a series of hills range throughout the district. The hilly regions have dominantly covered with evergreen, deciduous, and mixed forests. The major vegetation types are (1) Cachar tropical semi-evergreen forest, (2) secondary moist Bamboo, (3) pioneer Euphorbiaceous scrub (appeared over steep slopes), 4) moist mixed deciduous forest (Albizia spp, Artocarpus spp) (5) subtropical wet hill forest (Litsea spp, Quercus spp), and (6) subtropical pine forest (Quercus spp, Schima wallichii, Rhododendron spp). The area occupied by bareland is about 3–6%, and most of this area is a part of forest clearance used for jhum cultivation (also known as shifting cultivation). The hilly range of these districts is occupied by < 1% area for urban/built-up, whereas rivers and water bodies account for about 1–3% of area. In the case of Lunglei district, the built-up land is also relatively higher compared to other two districts.
4.3 SVM-based LULC classification using YD image
The LULC classification map derived from SVM classifier using YD image is presented in Fig. 6. The classification map showing built-up, deciduous forest, evergreen forest, scrubland, bareland, and waterbody is similar to SVM classifier based on FDD image. The detailed area statistics of each class are presented in Table 4. The LULC statistics were comparable to SVM classifier based on FDD image; however, relatively higher area under the urban scatters was obtained in SVM classification map obtained from YD image. It was observed that in case of volume scattering, comparatively good separation is shown for forest class. Furthermore, a constant value is exhibited in the water body and scrubland, where volume scattering tends to be negligible. In the case of urban scatters, the helix scattering based on YD provides higher area classified under the urban class.

LULC classification map using SVM algorithm based on YD scattering image. The three subset represents a part of a Mamit, b Lunglei, and c Lawngtlai districts
As per the National Remote Sensing Centre report [54] and LULC map (scale: 1:50,000) of 2011–12, the forest cover occupied 75%, 70.6%, and 66.2% of area in the Mamit, Lunglei, and Lawngtlai districts, respectively (Table 3). These reported statistics were very close to our estimates based on decomposition models (FDD and YD) assessed by SVM classifier. As per the NRSC [54], the scrubland occupied 20%, 23.6%, and 22.5% of area in the Mamit, Lunglei, and Lawngtlai districts, respectively. As compared to NRSC LULC statistics, we estimated 17–18% of the area is classified as scrubland. As per the NRSC, bareland occupied 0.9%, 0.39%, and 4.56% of area in the Mamit, Lunglei, and Lawngtlai districts, respectively (Table 3). Our estimated statistics are underestimated by 2–3% as compared to NRSC LULC statistics for scrubland and bareland. As per the NRSC [54], built-up area accounts for 0.55%, 0.62%, and 0.93% in the Mamit, Lunglei, and Lawngtlai districts, respectively, and these statistics are quite close to the results obtained from two decomposition models as assessed by SVM classifier. In the case of water bodies, it accounts for 0.64%, 0.86%, and 0.98% of area in the Mamit, Lunglei, and Lawngtlai districts, respectively. As per the decomposition models, water bodies areal statistics varied from 1.2 to 2.8%. There are some discrepancies in area statistics of LULC between NRSC and SVM-based classifier, which could be attributed to the extent of the study area. In other words, area statistics of NRSC represented whole districts, whereas the satellite L-band ALOS scenes did not cover the whole district. Furthermore, there is a difference in resolution used by NRSC and L-band PolSAR data. Nevertheless, the estimated LULC statistics by SVM classifier are well representative of statistics given by NRSC and the spatial distributions are also quite similar.
4.4 SVM-based LULC classification using GLCM texture images
The LULC classification map derived from SVM classifier using GLCM texture images is presented in Fig. 7. The spatial distribution of LULC map showing built-up, deciduous forest, evergreen forest, scrubland, bareland, and waterbody was quite similar to SVM classifier based on decomposition models. The detailed area statistics and confusion matrix of each class are presented in Table 5. The LULC area statistics were also comparable to decomposition models.

LULC classification map using SVM algorithm based on GLCM texture images. The three subset represents a part of a Mamit, b Lunglei, and c Lawngtlai districts
4.5 Accuracy assessment of LULC map
The performance of FDD and YD output in relation to LULC classification by using the SVM classifier is presented in Tables 6 and 7. The confusion matrix and accuracy assessment showed that the overall classification accuracy was 87.1–89.9% with a kappa coefficient 0.84–88 as per the FDD and YD, respectively. The producer and user accuracy are shown in Tables 6 and 7. The overall classification accuracy was improved to 90.3% with a kappa coefficient 0.88 by using SVM classification based on GLCM-based texture images (Table 8).
Using Freeman–Durden-based volume scattering attributes, the forest types, such as deciduous and evergreen forest, were not having good classification accuracy due to the presence of dense vegetation along the hilly terrain with prominent relief that ranged from 1179 to 2157 m (above msl). This can be assessed using the commission error (misclassification pixels) from Tables 6 and 7. However, misclassification of forest pixels decreased in case of Yamaguchi scattering attributes leading to improvement of classification accuracy. The forest class was misclassified as a bareland in all the two decomposition techniques due to double-bounce scattering from the forests along the high reliefs, and most of the bareland are predominantly formed due to shifting cultivation practices. The evergreen forest was misclassified as a built-up in all the two decomposition techniques due to double-bounce scattering from the forest classes. The scrubland was misclassified as forest in all the two decomposition techniques due to similarity of volume scattering attributes from the forest classes, but misclassification of scrubland pixels decreased in case of Yamaguchi-based volume scattering that has led to improvement of classification accuracy using Yamaguchi decomposition model. The bareland associated with surface scattering exhibited lowest classification accuracy in both the decomposition models. However, bareland is also misclassified as water bodies owing to confusion of surface scattering between bareland and water bodies in both the decomposition models. YD model performed better results, mainly in oriented urban areas (built-up) due to the helix scattering component, followed by FDD. Nevertheless, the comparisons of two decomposition theorems assessed by SVM classifications revealed that the classification based on Yamaguchi decomposition provides relatively higher accuracy of LULC map as deduced from the kappa coefficient. The texture analysis of the GLCM-based model resulted in some improvement of classification accuracy in the built-up class, whereas the accuracy levels for the remaining classes are quite similar to SVM classification using Yamaguchi decomposition model.
5 Discussion and conclusions
Rapid advancement of SAR-based sensors has provided large volumes of full-PolSAR data, but these polarimetric are also complex to interpret objects unlike optical sensors data. Thereby, the polarimetric target decomposition turned out to be a useful tool for understanding the PolSAR images by separating the radar backscatter into basic scattering mechanisms [61, 62]. The scattering matrix comprises magnitude and phase information at four polarizations (HH + HV + VH + VV), which are sent and received horizontally (H) and vertically (V) polarized waves by radar antenna. Thereby in recent years, use of PolSAR has become widespread because it supports a higher amount of information on scattering objects than in single/double polarization data. PolSAR data usually characterized by changes of microwave polarization, which is mainly influenced by the dielectric properties and terrain features, so LULC classification is the most important application of PolSAR data [63]. Cloude and Pottier [21] developed an eigenvector decomposition of a covariance matrix, which plays a vital role for capturing scattering properties of each pixel and for LULC classification. Other physical-based model decompositions, namely FDD and YD, have been also widely used to classify ground objects using the three-component and four-component scattering mechanism model, respectively. By using aforementioned decomposition methods, several studies performed the LULC and crop classification by employing mostly the machine learning-based classifiers [64, 65]. As such, PolSAR has the potential to differentiate forest, agriculture, scrubland, fallowland, bareland, buildings, and water bodies, among others, with the help of surface scattering, double-bounce scattering, and volume scattering [66]. The estimated area statistics of LULC classes are well comparable to the report of NRSC [54] as provided by the Department of Space (DoS), Government of India.
Here, we explored two classical model-based decomposition models, namely FDD and YD for ALOS full-pol L-band data for performing LULC classification. A machine learning SVM classifier is adopted for LULC classification. The key findings revealed that the four-component decomposition scheme (YD) outperformed the three-component decomposition scheme (FDD) for classifying LULC in three districts of the Mizoram state as evaluated by kappa coefficient. The study region is mostly dominated by a series of hill ranges with forest coverage up to 75%. This is in line with the other previous studies which suggested that the four-component decomposition scheme comprising the scattering contributions from surface (single-bounce), double-bounce, volume, and helix performed better than the three-component decomposition scheme [23, 59]. Notably, Varghese et al. [21] adopted six decomposition methods (i.e. Huynen, Freeman–Durden, Yamaguchi, Cloude, Van zyl, and H/A/α) and the performance of each decomposition was assessed using a SVM classifier and concluded that Yamaguchi four-component scheme had a better accuracy in forest canopy mapping followed by Van Zyl and Freeman–Durden decomposition. Our results suggested that the helix scattering as a fourth component of Yamaguchi decomposition assisted to discriminate man-made targets in urban area scattering especially in Lawngtlai district of Mizoram state. There is a confusion between forest and bareland in both decomposition models, which are associated with double-bounce scattering from the forests along the high reliefs. There is a confusion especially between evergreen forest and built-up due to double-bounce scattering from the evergreen forest. There is also a confusion between forest and scrubland associated with similar volume scattering attributes from both classes. There is a confusion between bareland and water bodies in both the decomposition models associated with surface scattering characteristics from both classes. Nevertheless, misclassification of forest and scrubland decreased in Yamaguchi-based scattering attributes leading to improvement of classification accuracy. Yamaguchi decomposition performed better especially in built-up areas associated with helix scattering components. By using only six texture measures of GLCM, the SVM classifier exhibited classification accuracy at par with the Yamaguchi-based model. In particular, the GLCM model delivered a better accuracy for built-up class compared to Yamaguchi scattering model. This displays that texture information is appropriate for urban land cover classification and similar conclusions were also drawn in several studies that have used texture measures from PolSAR data [67, 68]. Nevertheless, textural images have improved the accuracy of LULC classification, but there are some limitations related to appropriate texture features, high amount of features and computation time, window size, and noise in some features [69].
The six LULC classes were separated using the scattering properties of PolSAR images. The LULC classification accuracy was confirmed using the confusion matrix. The accuracy varied from 87 to 90% as evaluated by the SVM classifier. The kappa coefficient (0.88) is higher for YD image as compared to FDD image (0.84). The accuracy of LULC was also improved especially when texture features are utilized from GLCM. These results highlight the significance of PolSAR data and polarimetric decomposition for LULC mapping with reasonably high accuracy.
References
Manakos I, Braun M (2014) Land use and land cover mapping in Europe: Practices and Trends. Springer, Dordrecht
Tripathi G, Pandey AC, Parida BR, Kumar A (2020) Flood inundation mapping and impact assessment using multi-temporal optical and SAR satellite data: a case study of 2017 Flood in Darbhanga district, Bihar, India. Water Resour Manag 34 (In press). https://doi.org/10.1007/s11269-020-02534-3
Kupková L, Červená L, Suchá R et al (2017) Classification of tundra vegetation in the Krkonoše Mts. National Park using APEX, AISA dual and Sentinel-2A data. Eur J Remote Sens 50:29–46. https://doi.org/10.1080/22797254.2017.1274573
van der Sande CJ, de Jong SM, de Roo APJ (2003) A segmentation and classification approach of IKONOS-2 imagery for land cover mapping to assist flood risk and flood damage assessment. Int J Appl Earth Obs Geoinform 4:217–229. https://doi.org/10.1016/S0303-2434(03)00003-5
Geymen A, Baz I (2007) Monitoring urban growth and detecting land-cover changes on the Istanbul metropolitan area. Environ Monit Assess 136:449–459. https://doi.org/10.1007/s10661-007-9699-x
Falcucci A, Maiorano L, Boitani L (2007) Changes in land-use/land-cover patterns in Italy and their implications for biodiversity conservation. Landsc Ecol 22:617–631. https://doi.org/10.1007/s10980-006-9056-4
Bargiel D, Herrmann S (2011) Multi-temporal land-cover classification of agricultural areas in two European regions with high resolution spotlight TerraSAR-X Data. Remote Sens 3:859–877. https://doi.org/10.3390/rs3050859
Roy A, Inamdar AB (2019) Multi-temporal land use land cover (LULC) change analysis of a dry semi-arid river basin in western India following a robust multi-sensor satellite image calibration strategy. Heliyon 5:e01478. https://doi.org/10.1016/j.heliyon.2019.e01478
Roy PS, Behera MD, Murthy MSR et al (2015) New vegetation type map of India prepared using satellite remote sensing: comparison with global vegetation maps and utilities. Int J Appl Earth Obs Geoinform 39:142–159. https://doi.org/10.1016/j.jag.2015.03.003
Bajocco S, De Angelis A, Perini L et al (2012) The impact of land use/land cover changes on land degradation dynamics: a mediterranean case study. Environ Manag 49:980–989. https://doi.org/10.1007/s00267-012-9831-8
Barksdale WF, Anderson CJ (2015) The influence of land use on forest structure, species composition, and soil conditions in headwater-slope wetlands of coastal Alabama, USA. Int J Biodivers Sci Ecosyst Serv Manag 11:61–70. https://doi.org/10.1080/21513732.2013.876449
Lam NS (2008) Methodologies for mapping land cover/land use and its change. In: Liang S (ed) Advances in land remote sensing. Springer, Dordrecht, pp 341–367
Jensen J (2005) Introductory digital image processing: a remote sensing perspective, 3rd edn. Prentice-Hall, New Jersey
Lillesand TM, Kiefer RW (2009) Remote sensing and image interpretation. Wiley, New York
Lu D, Mausel P, Brondízio E, Moran E (2004) Change detection techniques. Int J Remote Sens 25:2365–2401. https://doi.org/10.1080/0143116031000139863
Peddle DR, Foody GM, Zhang A et al (1994) Multi-source image classification II: an empirical comparison of evidential reasoning and neural network approaches. Can J Remote Sens 20:396–407. https://doi.org/10.1080/07038992.1994.10874582
Foody GM (1997) Fully fuzzy supervised classification of land cover from remotely sensed imagery with an artificial neural network. Neural Comput Appl 5:238–247. https://doi.org/10.1007/BF01424229
Hinton GE, Osindero S, Teh Y-W (2006) A fast learning algorithm for deep belief nets. Neural Comput 18:1527–1554. https://doi.org/10.1162/neco.2006.18.7.1527
Kotsiantis SB (2007) Unspervised machine learning: a review of classification techniques. Appl Comput Eng Real Word 31:249–268
Benz UC, Hofmann P, Willhauck G et al (2004) Multi-resolution, object-oriented fuzzy analysis of remote sensing data for GIS-ready information. ISPRS J Photogramm Remote Sens 58:239–258. https://doi.org/10.1016/j.isprsjprs.2003.10.002
Cloude SR, Pottier E (1996) A review of target decomposition theorems in radar polarimetry. IEEE Trans Geosci Remote Sens 34:498–518. https://doi.org/10.1109/36.485127
Freeman A, Durden SL (1998) A three-component scattering model for polarimetric SAR data. IEEE Trans Geosci Remote Sens 36:963–973. https://doi.org/10.1109/36.673687
Yamaguchi Y, Moriyama T, Ishido M, Yamada H (2005) Four-component scattering model for polarimetric SAR image decomposition. IEEE Trans Geosci Remote Sens 43:1699–1706. https://doi.org/10.1109/TGRS.2005.852084
Cameron WL, Rais H (2006) Conservative polarimetric scatterers and their role in incorrect extensions of the cameron decomposition. IEEE Trans Geosci Remote Sens 44:3506–3516. https://doi.org/10.1109/TGRS.2006.879115
Brisco B, Li K, Tedford B et al (2013) Compact polarimetry assessment for rice and wetland mapping. Int J Remote Sens 34:1949–1964. https://doi.org/10.1080/01431161.2012.730156
Ranjan AK, Parida BR (2019) Paddy acreage mapping and yield prediction using sentinel-based optical and SAR data in Sahibganj district, Jharkhand (India). Spat Inf Res 27:399–410. https://doi.org/10.1007/s41324-019-00246-4
McNairn H, Champagne C, Shang J et al (2009) Integration of optical and Synthetic Aperture Radar (SAR) imagery for delivering operational annual crop inventories. ISPRS J Photogramm Remote Sens 64:434–449. https://doi.org/10.1016/j.isprsjprs.2008.07.006
Lee JS, Grunes MR, Kwok R (1994) Classification of multi-look polarimetric SAR imagery based on complex Wishart distribution. Int J Remote Sens 15:2299–2311. https://doi.org/10.1080/01431169408954244
Wang S, Liu K, Pei J et al (2013) Unsupervised classification of fully polarimetric SAR images based on scattering power entropy and copolarized ratio. IEEE Geosci Remote Sens Lett 10:622–626. https://doi.org/10.1109/LGRS.2012.2216249
Pottier E, Saillard J (1993) Classification of earth terrain in polarimetric SAR images using neural nets modelization. In: Proc. SPIE 1748, Radar Polarimetry, San Diego, CA, United States. https://doi.org/10.1117/12.140624
Kajimoto M, Susaki J (2013) Urban-area extraction from polarimetric SAR images using polarization orientation angle. IEEE Geosci Remote Sens Lett 10:337–341. https://doi.org/10.1109/LGRS.2012.2207085
Deng L, Wang C (2014) Improved building extraction with integrated decomposition of time-frequency and entropy-alpha using polarimetric SAR data. IEEE J Sel Top Appl Earth Obs Remote Sens 7:4058–4068. https://doi.org/10.1109/JSTARS.2013.2281594
Qi Z, Yeh AG-O, Li X, Lin Z (2012) A novel algorithm for land use and land cover classification using RADARSAT-2 polarimetric SAR data. Remote Sens Environ 118:21–39. https://doi.org/10.1016/j.rse.2011.11.001
Zhang L, Zou B, Zhang J, Zhang Y (2009) Classification of polarimetric SAR image based on support vector machine using multiple-component scattering model and texture features. EURASIP J Adv Signal Process 2010:960831. https://doi.org/10.1155/2010/960831
Wiederkehr NC, Gama FF, Mura JC et al (2019) Analysis of the target decomposition technique attributes and polarimetric ratios to discriminate land use and land cover classes of the Tapajós Region. Bull Geod Sci 25:e2019002. https://doi.org/10.1590/s1982-21702019000100002
Laliberte A, Koppa J, Fredrickson E, Rango A (2006) Comparison of nearest neighbor and rule-based decision tree classification in an object-oriented environment. In: 2006 IEEE international symposium on geoscience and remote sensing, IEEE, Denver, USA, pp 3923–3926
Fang Y, Zhang H, Mao Q, Li Z (2018) Land cover classification with GF-3 polarimetric synthetic aperture radar data by random forest classifier and fast super-pixel segmentation. Sensors 18:2014. https://doi.org/10.3390/s18072014
Fukuda S, Hirosawa H (2001) Support vector machine classification of land cover: application to polarimetric SAR data. In: Proceedings of the IEEE 2001 international geoscience and remote sensing symposium (IGARSS’01). Sydney, Australia, pp 187–189
Cortes C, Vapnik V (1995) Support-vector networks. Mach Learn 20:273–297. https://doi.org/10.1007/BF00994018
Du P, Samat A, Waske B et al (2015) Random forest and rotation forest for fully polarized SAR image classification using polarimetric and spatial features. ISPRS J Photogramm Remote Sens 105:38–53. https://doi.org/10.1016/j.isprsjprs.2015.03.002
Haralick RM, Shanmugam K, Dinstein I (1973) Textural features for image classification. IEEE Trans Syst Man Cybern SMC 3:610–621. https://doi.org/10.1109/TSMC.1973.4309314
Franklin SE, Hall RJ, Moskal LM et al (2000) Incorporating texture into classification of forest species composition from airborne multispectral images. Int J Remote Sens 21:61–79. https://doi.org/10.1080/014311600210993
Ghimire B, Rogan J, Miller J (2010) Contextual land-cover classification: incorporating spatial dependence in land-cover classification models using random forests and the Getis statistic. Remote Sens Lett 1:45–54. https://doi.org/10.1080/01431160903252327
Conradsen K, Nielsen AA, Schou J, Skriver H (2003) A test statistic in the complex wishart distribution and its application to change detection in polarimetric SAR data. IEEE Trans Geosci Remote Sens 41:4–19. https://doi.org/10.1109/TGRS.2002.808066
Lee Jong-Sen, Grunes MR, Ainsworth TL et al (1999) Unsupervised classification using polarimetric decomposition and the complex Wishart classifier. IEEE Trans Geosci Remote Sens 37:2249–2258. https://doi.org/10.1109/36.789621
Frery AC, Correia AH, da Freitas CC (2007) Classifying multifrequency fully polarimetric imagery with multiple sources of statistical evidence and contextual information. IEEE Trans Geosci Remote Sens 45:3098–3109. https://doi.org/10.1109/TGRS.2007.903828
Franklin SE, Wulder MA (2002) Remote sensing methods in medium spatial resolution satellite data land cover classification of large areas. Prog Phys Geogr Earth Environ 26:173–205. https://doi.org/10.1191/0309133302pp332ra
Blaschke T (2010) Object based image analysis for remote sensing. ISPRS J Photogramm Remote Sens 65:2–16. https://doi.org/10.1016/j.isprsjprs.2009.06.004
Lardeux C, Frison P-L, Tison C et al (2009) Support vector machine for multifrequency SAR polarimetric data classification. IEEE Trans Geosci Remote Sens 47:4143–4152. https://doi.org/10.1109/TGRS.2009.2023908
Longepe N, Rakwatin P, Isoguchi O et al (2011) Assessment of ALOS PALSAR 50 m Orthorectified FBD data for regional land cover classification by support vector machines. IEEE Trans Geosci Remote Sens 49:2135–2150. https://doi.org/10.1109/TGRS.2010.2102041
JAXA (2020) ALOS PALSAR products. Available: https://earth.esa.int/web/guest/data-access/view-data-product/-/article/alos-palsar-fbs-fbd-and-plr-products
ESA (2020) Sentinel Application Platform (SNAP). Available: https://step.esa.int/main/toolboxes
ASF (2020) Alaska Satellite Facility. Available: https://asf.alaska.edu/
NRSC (2014) Land use/land cover database on 1:50,000 scale, Natural Resources Census Project, LUCMD, LRUMG, RSAA, National Remote Sensing Centre, ISRO, Hyderabad
IMD (2020) India Meteorological Department. Ministry of Earth Sciences. Government of India. Available: http://dsp.imdpune.gov.in
Nyoungui AN, Tonye E, Akono A (2002) Evaluation of speckle filtering and texture analysis methods for land cover classification from SAR images. Int J Remote Sens 23:1895–1925. https://doi.org/10.1080/01431160110036157
Herold ND, Haack BN, Solomon E (2005) Radar spatial considerations for land cover extraction. Int J Remote Sens 26:1383–1401. https://doi.org/10.1080/01431160512331337998
Katmoko AS, Novie I (2013) Land cover classification of ALOS PALSAR data using support vector machine. Int J Remote Sens Earth Sci 10:9–18
Varghese AO, Suryavanshi A, Joshi AK (2016) Analysis of different polarimetric target decomposition methods in forest density classification using C band SAR data. Int J Remote Sens 37:694–709. https://doi.org/10.1080/01431161.2015.1136448
Cohen J (1960) A coefficient of agreement for nominal scales. Educ Psychol Meas 20:37–46. https://doi.org/10.1177/001316446002000104
Chen H, Cloude SR, Goodenough DG (2016) Forest canopy height estimation using Tandem-X coherence data. IEEE J Sel Top Appl Earth Obs Remote Sens 9:3177–3188. https://doi.org/10.1109/JSTARS.2016.2582722
Ouchi K (2013) Recent trend and advance of synthetic aperture radar with selected topics. Remote Sens 5:716–807. https://doi.org/10.3390/rs5020716
Mott H (2006) Remote sensing with polarimetric radar. Wiley, Hoboken
Alberga V, Satalino G, Staykova DK (2008) Comparison of polarimetric SAR observables in terms of classification performance. Int J Remote Sens 29:4129–4150. https://doi.org/10.1080/01431160701840182
Piazza GA, Vibrans AC, Liesenberg V, Refosco JC (2016) Object-oriented and pixel-based classification approaches to classify tropical successional stages using airborne high–spatial resolution images. GISci Remote Sens 53:206–226. https://doi.org/10.1080/15481603.2015.1130589
Mishra VN, Kumar P, Gupta DK, Prasad R (2014) Classification of various land features using RISAT-I dual polarimetric data,. 2014 XL-8. ISPRS:833–837
Zhou Tao, Li Zhaofu, Pan Jianjun (2018) Multi-feature classification of multi-sensor satellite imagery based on dual-polarimetric Sentinel-1A, Landsat-8 OLI, and hyperion images for urban land-cover classification. Sensors 18:373. https://doi.org/10.3390/s18020373
Mishra VN, Prasad R, Kumar P et al (2017) Dual-polarimetric C-band SAR data for land use/land cover classification by incorporating textural information. Environ Earth Sci 76:26. https://doi.org/10.1007/s12665-016-6341-7
Chen D, Stow DA, Gong P (2004) Examining the effect of spatial resolution and texture window size on classification accuracy: an urban environment case. Int J Remote Sens 25:2177–2192. https://doi.org/10.1080/01431160310001618464
Acknowledgements
This research was supported by the University Grants Commission (UGC) under the start-up Grant (F. 4-5(209-FRP)/2015/BSR). Authors thanks to JAXA and Alaska Satellite facility (ASF) team for providing the ALOS PALSAR-1 sensor data. Authors also thank ESA/PolSARpro project team for providing the analysis software.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Parida, B.R., Mandal, S.P. Polarimetric decomposition methods for LULC mapping using ALOS L-band PolSAR data in Western parts of Mizoram, Northeast India. SN Appl. Sci. 2, 1049 (2020). https://doi.org/10.1007/s42452-020-2866-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-020-2866-1