
Abstract
The soil attributes of spatially structured data were often measured in Central plateau, of Karnataka, but often poorly defined spatial variability of soil attributes important for land management under hot semiarid agroecological environment. The Kaligaudanahalli microwatershed (612 ha) divided into 250 m × 250 m square grids using ArcGIS and collected surface soils (0–15 cm) at 89 locations. The results of cluster analysis with average linkage method revealed four soil typologies viz., slightly alkaline, sandy clay loam texture showing high coefficient of variation for all soil variables in cluster-I, but neutral, sandy clay loam with high variability for DTPA-extractable Cu in cluster-II, moderately alkaline sandy clay loam to clay texture with high variability for EC, OC, available K2O, B and Cu for cluster-III and IV. The study concluded that the measured soil properties in regular gird sampling at given scale were enough to capture spatial dependence using ordinary and cokriging techniques and in deriving thematic maps for efficient soil management strategies at watershed level. The results of spatial dependence of each soil property, using ordinary kriging showed that there is strong spatial dependence of pH, EC, K2O, B, Cu, Fe and Mn with nugget-to-sill ratio [(C0/C0 + C)] less than 0.25 showing strong spatial distribution where DTPA-extractable Zn had a nugget/sill more than 0.75, displaying a weak spatial autocorrelation. The results showed that cokriging is the best fit and strongly correlated with EC, P2O5, K2O, Fe and Mn using pH as ancillary variable over ordinary kriging to derive thematic maps.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
The spatial variability of soil properties can be measured and quantified at a given scale with regular sampling technique for designing sustainable land management practices [19, 43]. Most of the studies on spatial variability of soil attributes using geospatial techniques have been carried out in diverse temperate countries [5, 7, 10, 12, 15, 47]. In the past three decades, the application of geostatistical methods by soil researchers primarily focused on predicting spatial variability along a transect [40] or at field-scale [8, 43]. Using geostatistics, GIS and remote sensing techniques for large area in Australia, McBratney et al. [26] provided the comprehensive maps for physical, chemical and biological soil properties. In India, majority of soil maps were prepared by conventional methods on smaller scale. Due to initiation of detailed microwatershed surveys in drought prone areas of Karnataka along with grid survey, the modern spatial prediction techniques were employed in spatial variability of soil properties [25, 28, 37]. It was reported that soil pH, electrical conductivity, organic carbon and exchangeable bases have been varied highly in acid soils of India [2], the spatial variability of organic carbon, available N, P and K of Karlawad village in Dharwad district of Karnataka [30] and in lateritic soils of West Bengal [4].
Several workers reported that cokriging employs spatial information on the primary variables along with the spatial correlation between primary and auxiliary variables [16, 45, 48, 54]. A recent study [44] made a comparative study of interpolation techniques and confirmed that cokriging is performed well over ordinary kriging. Considering the review of the literature, we hypothesized to answer, what statistical tools are useful in explaining the variability of soil properties and their use in designing crop specific nutrient management plans? The research herein is a part of Sujala-III project in semiarid tracts of Karnataka State for reducing fertilizer recommendation and enhancing crop productivity of small-scale farmers. Hence, the objectives of this study were to (i) evaluate the efficacy of grid survey method in addressing top soil properties and (ii) analyze the variability of physicochemical properties of top soil by means of cluster analysis, and their spatial dependence by ordinary kriging and cokriging comparison through cross-validation.
2 Materials and methods
2.1 Study area
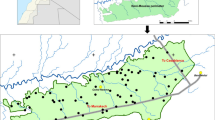
The Kaligaudanahalli microwatershed lies between 11°41′–11°43′N and 76°37′–76°41′E covering 612 ha. It is bounded by Karle, Siddapura, Siddainapura and Maguvinahalli villages in Gundlupet taluk, Chamarajanagar district, Karnataka State, India (Fig. 1). The study area is a part of hot moist semiarid subregion of Central Karnataka Plateau, with medium to deep red loamy soils, low AWC (available water holding capacity) and LGP (length of growing period) of 120–150 days [46]. The elevation is 450–900 m above mean sea level with mean annual rainfall of 670–890 mm of which about 55–75% is received during the south west monsoon. Geological formations in the study area show the occurrence of Archean-age granite gneiss and schistose rocks with quartzite and banded iron formations and Dolerite dykes of Proterozoic age with variable strike directions and width [3]. It was reported that Typic/Lithic Rhodustalfs/Haplustalfs are dominant but in association with Typic/Vertic Haplustepts under isohyperthermic soil temperature regime and ustic soil moisture regime [32].

Location map of Kaligaudanahalli microwatershed
2.2 Grid soil survey
The grid survey at an interval of by 250 × 250 m was carried out to collect soil samples of plow layer (0–15 cm). A total of 89 grid points in Kaligaudanahalli microwatershed were taken. At each grid point, 8–10 cores samples within 10 m radius were taken and georeferenced using GPS system (GARMIN etrex-30x model) (Fig. 2).

Map showing grid points in the Kaligaudanahalli microwatershed
2.3 Laboratory methods
The collected surface soil samples were air-dried, grinded and passed through 2-mm sieve for fine earth fraction and used fine earth fraction (< 2 mm) for laboratory analysis. Soil reaction was determined in 1:2.5 soil/water suspension using standard pH meter (Hanna instrument) and electrical conductivity (EC) using conductivity meter (Toshniwal insts. Mfg. Pvt. Ltd, TC 17). Soil organic carbon (OC) was estimated using the wet digestion method as described by Walkley and Black (1934) [50] and expressed its value in percentage. The available potassium (K+) in 1N ammonium acetate (NH4OAc) at (pH 7.0) was determined by Flame photometer [17]. DTPA-extractable micronutrients viz., Fe, Mn, Zn and Cu were extracted by 0.005 M DTPA at pH 7.3 according to the method of [23], and the concentration of micronutrients was estimated using atomic absorption spectrophotometer (Agilent Technologies, 200 series AA model). Available phosphorus was determined by Olsen method [27] and available S by CaCl2 extraction method [53]. The available Boron was estimated by azomethine-H method by using Lab India (analytical) UV/VIS spectrophotometer [14]. Fertility status of N, P, K and S were categorized as low, medium and high and that of DTPA-extractable zinc, iron, copper and manganese interpreted as deficient, sufficient and excess as per the criteria of Arora [1].
2.4 Statistical analysis
2.4.1 Hierarchical cluster analysis and descriptive statistics
Hierarchical cluster analysis was used to categorize the 11 soil properties at 89 locations with similar characteristics into a group using average. CA was performed to identify analogous behavior among the different soil properties and also among the samples. It was performed on the normalized data set by means of Ward’s method using squared Euclidean distances as a measure of similarity (SPSS 15 version). The clusterwise descriptive analysis was made and classified on the basis of coefficient of variation as low: < 15%, moderate: from 15 to 50% and high as > 50% [51]. Correlations and KS test was performed by XLSTAT 20191.1.
2.4.2 Geostatistical analysis
The soil properties were analyzed using geostatistical tool and calculated semivariogram [16, 19] for each soil property using the equation as given below:
where γ (h) is the experimental semivariogram value at distance interval h; N (h) is the number of sample value pairs within the distance interval h; z (xi), z (xi + h) is sample values at two points separated by the distance interval h.
Exponential,
The parameters of the model: nugget semivariance, range and sill or total semivariance were determined. To define different classes of spatial dependence for the soil variables, the ratio between the nugget and the sill was used [8] to classify as: ≤ 25%-strongly spatially dependent, between 26 and 75%-moderately spatially dependent, > 75%-weakly spatially dependent and 100% considered as non-spatially correlated (pure nugget). We employed ordinary [13] and cokriging techniques, and used the procedures as given under:
2.4.2.1 Ordinary kriging (OK)
Ordinary kriging is an univariate linear regression model which was used to estimate variance and confidence interval assuming a normal distribution of errors is the spatial prediction of the unmeasured point s0 is given by predicting the value \(\hat{z}(s_{0}),\) which equals the line sum of the known measured values (i.e., observed values). The formula was used to workout spatial variability as given under:
where \(\hat{z}(s_{0} )\) is the value at location s0 to be interpolated, \(z\left( {s_{i} } \right)\) are the sampled values, and λi, determined by the semivariogram modeling and are the weights to be assigned to each unsampled location.
2.4.2.2 Cokriging (CoK)
Cokriging was worked out based on spatial structure of co-variables and their covariance (autocorrelation). The cokriging (CoK) estimator ds at the unsampled location x0, Zw cross-correlated with the main variable Zv, was given as [16]:
where \(\alpha_{i}\), \(\beta_{j}\)—weights assigned to the known values of the primary and secondary variables Zv and Zw, respectively, n, m—numbers of primary and secondary observations.
2.4.3 Cross-validation technique
Cross-validation technique was used to examine the difference between the known data and the predicted data using the mean error [ME, Eq. (5)], the root-mean-squared error [RMSE, Eq. (6)], the average kriging standard error [AKSE, Eq. (7)], the root-mean-square standardized prediction error [RMSP, Eq. (8)] and the mean standardized prediction error [MSPE, Eq. (9)]. Equations (7) and (9) are only applicable to kriging as they require the kriging variance. Equations (5) and (6) are applicable to all of the interpolation techniques applied in this research.
where \(\hat{Z}(s_{i} )\) is the predicted value, \(z(s_{i} )\) is the observed (known) value, N is the number of values in the dataset, and σ2 is the kriging variance for location \(s_{i}\) [18, 21, 49, 52].
3 Results
3.1 Cluster analysis and sample grouping
The cluster analysis shows that cluster-II (45% of total samples) has neutral reaction followed by slightly alkaline under cluster-I and III (55.2% of total sample) and moderately alkaline with 9.1% of grids under cluster-IV. The mean pH is 7.78 ± 0.61 with CV of 7.81% for cluster-I and 7.9 ± 0.59 with CV of 7.5% for cluster-III. The cluster-II has mean pH of 6.75 ± 0.90 with CV of 13.4% but for cluster-IV having mean of 8.21 ± 0.26 with CV of 3.2% (Table 1).
These soils are nonsaline with electrical conductivity less than 0.37 dS m−1 and high coefficient of variation in cluster-I and II (CV > 35%). Considering the trends of soil test values [29], these soils have high soil organic carbon with mean of 0.81 ± 0.39 for cluster-I, 0.77 ± 0.25 for cluster-II and 0.83 ± 0.51 for cluster-IV, but medium in case of cluster-III with mean organic carbon content of 0.63 ± 0.28. The high variability of soil organic carbon is recorded in cluster-I (CV of 48.4%), cluster-II (CV of 43.99%) and cluster-IV (CV of 61.15%), but medium in case of cluster-III with CV of 32.6%. The available P2O5 in top soils is categorized as high in cluster-IV (mean of 90.23 ± 43.02 kg ha−1), whereas medium in cluster-I and III and low in cluster-II (mean of 14.06 ± 11.72 kg ha−1). Similarly, the status of available K2O is high in all clusters with high variability in cluster-II (CV of 35.35%). The sulfur status is medium for cluster-III and IV but low in cluster-I and II. The coefficient of variation is high for all clusters regarding available P2O5 and S status (Table 1). The available boron status is more than 0.5 mg kg−1 in all clusters with high CV except in cluster-II where B is medium (0.44 ± 0.3 mg kg−1). Among DTPA-extractable micronutrients, Cu, Mn and Fe contents shows sufficient in all clusters with high coefficient of variation. It is interesting to note that DTPA-extractable Zn is below critical limit in cluster-II (mean of 0.51 ± 0.37 mg kg−1) and cluster-III (0.56 ± 0.28 mg kg−1). These clusters have CV of 71.86% (cluster-II) and 49.18% (cluster-III).
The Kolmogorov–Smirnov statistic quantifies a distance between the empirical distribution function of the sample and the cumulative distribution function of the reference distribution, or between the empirical distribution functions of two samples and calculates a P value from that and the sample sizes. If the P value is small, conclude that the two groups were sampled from populations with different distributions. The populations may differ in median, variability or the shape of the distribution.
(KS) normality test indicates that all soil variables are very significant (< 0.001) to extremely significant (< 0.0001) in all clusters except two variables. As a result of using software to test for normality, small p values in the output generally indicate the data is not from a normal distribution [36]. Kolmogorov–Smirnov (KS) normality test indicates that P2O5 is almost normally distributed with a non-significant (high) p value of 0.388 in cluster-I, 0.076 in cluster-III, 0.022 in cluster-IV and Mn with high p value of 0.007 in cluster-II and cluster-IV. Except above two variables, all soil variables are very significant (< 0.001) to extremely significant (< 0.0001) in all clusters (Table 1).
3.2 Correlation matrix
The correlation analysis shows that pH has significant (1% level) positive correlation with EC (0.707**), P2O5 (0.382**), K2O (0.591**) and negatively correlated with Fe (− 0.744**) and Mn (− 0.707**). The results further show that OC has a positive correlation of with S, Cu and Fe, respectively (Table 2).
3.3 Geostatistical analysis
3.3.1 Ordinary kriging
In ordinary kriging, semivariogram models of exponential method were used and presented in Table 3. The data shows that spatial dependence of soil variable is varied from 487.66 m for B to 5198.85 m for available K2O. In agreement with findings of [39], soil OC, P2O5 and S are spatially correlated to distance of 603.06 m, 750.01 m and 755.70 m; however, it showed a small/zero nugget variance. It is observed that the nugget semivariance of OC and P2O5 is very small and approached to zero. In the study site, relative nugget effect of pH, EC, K2O, B, Cu, Fe, Zn and DTPA-extractable Mn is less than 25% showing a strongly spatial dependence. Relative nugget effect for the pH was 17%, Cu-22%, and Fe-18%, indicating a random structured variability and for DTPA-extractable Zn with nugget-to-sill ratio of 84%, indicating weakly structured variability.
3.3.2 Cokriging
Soil pH is affected by land use and management, vegetation type impacts soil pH, a loss of organic matter removal of soil minerals when crops are harvested, erosion of the surface layer, climate, mineral content, but soil texture cannot be changed. In cokriging, the exponential semivariogram models are worked out using pH as ancillary variable and have strong relation with EC, P2O5, K2O, Fe and Mn. The nugget-to-sill ratio is varied from 0.07 for Mn and 0.16 for P2O5 (Table 4) with RMSP of 0.9–1 except for Fe.
3.4 Cross-validation
3.4.1 Ordinary kriging
The cross-validation of results with the calculation of ME, RMSE, AKSE, RMSP, MSPE, R2 and goodness of fit is presented in Table 5. The lowest root-mean-square error (RMSE) is reported for EC (0.070, 20 neighbors), for B (0.289, 12 neighbors) and for organic carbon (0.318, 19 neighbors). The root-mean-square standardized prediction error (RMSP) suggests the same since it is less than 1 for pH and DTPA-extractable Zn except EC and DTPA-extractable Mn which shows underestimating the variability predictions. The ME and MSPE are negative for EC, OC, K2O and Mn with AKSE greater than the RMSE, indicating larger kriging variance.
3.4.2 Cokriging
The result revealed that the ME and MSPE are negative with AKSE greater than the RMSE (Table 6). The R2 value is varied from 0.55 for Mn, P2O5 and 0.65 for EC with goodness of fit is 1. Figure 4 shows the scatter plot of estimated versus measured of pH versus EC, P2O5, K2O and DTPA-extractable Fe and Mn data using cokriging methods. Generally, scatter plot is appropriate for quality assurance and accuracy of predictions. It is also useful when there are large numbers of sample points and can provide information about the strength of a relationship between two variables. Based on Fig. 4, all the scatter plots confirm the results of RMSE (Table 6).
4 Discussions
The Kaligaudanahalli microwatershed have crest/summits, back slopes and then foot slopes of granitic terrain supporting medium to deep red soils with five surface textures such as clay (13.1% of total area), sandy clay (23.46%), sandy clay loam (37.54%), sandy loam (13.1%) and loamy sand (4.03%) out of total area [34]. The mean annual rainfall is 670–890 mm, of which about 55–75% is received during kharif season. Descriptive statistical summary (Table 1) shows that these soils are slightly acid to strongly alkaline with low coefficient of variation (< 15%), but have high coefficient of variation for electrical conductivity (> 35%) and for organic carbon, available phosphorus and potassium. This observation is in agreement with the findings of earlier researchers [6, 9, 11]. Considering the critical level of S (10 mg kg−1) and B (0.5 mg kg−1), the high variability of S and B is observed. There is a significant positive relation of organic carbon with available sulfur (mg kg−1) (R2) = 0.142**, significant at 1% level. The available S is the function of organic carbon as reported by Kour and Jalali [20].
It was reported that there is wide spread deficiencies of S, B and Zn in drylands of Karnataka [31, 38, 41], but the soils in the microwatershed are having medium status of S and above critical limit of B status. Similar kinds of observations were reported in various parts of Karnataka [24, 33, 35, 42]. Among all micronutrients, Zn is deficient with high variability. Classical statistics did not show the strongly patchy distribution of some soil parameters and provided mean values that produced medium and large CV for all the soil properties except pH. These findings are in agreement with the results of Cambardella and Karlen [8] and Geypens et al. (1999) [15].
The cluster analysis was done to find out affinity among the 11 soil properties under study and brought out four clusters (Fig. 3). The cluster analysis clearly shows distinct variations in soil properties both within cluster and between the clusters. It is pointed here that the neutral soils grouped under cluster-II showed high variability of organic carbon (CV of 43.99%) with low status of available P2O5, below critical limit of DTPA-extractable Zn and Boron (Table 2). It is further observed that soil properties under study have high mean ± SD for cluster-IV as compared to cluster-II. In case of DTPA-extractable Fe and Mn, the trend is opposite to that of cluster-II and IV. Most of the grid points in cluster-II are near to the depressional zones and subjected to seasonal water stagnation, favoring the high concentration of redox sensitive elements such as Fe and Mn. The concentration of Fe and Mn in top soils is negatively related with pH and expressed its exponential relation as:

Dendrogram using a hierarchical agglomerative method of complete linkage grouping derived from a Gower’s similarity coefficient
-
Eq 10. DTPA-extractable Iron (mg kg−1) = 8.568 e−0.02x, (R2) = 0.5547**
-
Eq 11. DTPA-extractable Manganese (mg kg−1) = 8.460 e−0.008x, (R2) = 0.4999**
This equation is significant at 1% level with coefficient of determination (R2) of 0.56** and 0.49** for Mn. The performance of semivariogram are depended dividing of variogram that computed by the function of the distance and characterizes the spatial continuity between points. Five main factors relate to the quality of the data are: distribution, isotropism and anisotropism, variance and range, accuracy, spatial correlation and other factors, and secondary variables [22]. The changing of variogram could be a variable of some parameters such as nugget, partial sill or range, and anisotropy of the data that is also correlated with the distance of the location and the soil properties at a point. In ordinary kriging, exponential semivariograms shows a range of 487 m for B and 5198 m for K2O (Table 3). Thus, EC and K2O had a range of more than 5000 m, indicating that both values influenced by neighboring values of soil over greater distances. The number of closest samples chosen varied from 12 for Boron and Zn. The cross-validation of results showed that the lowest root-mean-square error (RMSE) is reported for EC (0.0708, 20 neighbors), for B (0.288, 12 neighbors) and for organic carbon (0.324, 19 neighbors). The root-mean-square standardized prediction error (RMSP) suggests the same since it is less than 1 for pH and DTPA-extractable Zn, but for underestimating in case of EC and DTPA-extractable Mn as RMSP > 1. The predictions are relatively unbiased for pH, EC, DTPA-extractable Zn and Mn. Since the average kriging standard error (AKSE greater than the RMSE) indicates that the kriging variance is larger than the true estimation variance and indicates that the variogram model is overestimating the variability of the predictions.
Geostatistical-variogram analysis and spatial interpolation (Ordinary kriging and Co-kriging) methods using the threshold limits of each nutrient as per Arora [1] under study. RMSE and QQ-plots (Fig. 4) together with the sum and average errors were considered to be the best estimation methods (Tables 6). The thematic maps show the nutrient zoning of pH versus available phosphorus (P2O5), K2O, DTPA-extractable Fe and Mn under cokriging as best fit model (Fig. 5). The results showed that the area under low status of available phosphorus using cokriging is estimated as 434 ha area (70.86%) with moderately acidic (pH 5.5) to strongly alkaline (pH 9.0) and concentrated in the maximum part of the microwatershed, whereas 178 ha (29.14%) area covered by medium available P2O5 with neutral (pH 6.5) to strongly alkaline (pH 9.0) in the microwatershed. Similar exercise was done for deriving thematic maps using cokriging on available K2O, DTPA-extractable Fe and Mn (Fig. 5). The map shows that 6.75% of moderately acid to neutral soils have medium K2O, whereas the remaining 93% of moderately acid to strongly alkaline soils have high available K2O; 26.56% of total area under neutral to strongly alkaline conditions are deficient and 73.44% are sufficient (pH moderately acid to strongly alkaline) in DTPA-extractable Fe. Irrespective of soil pH, the DTPA-extractable Mn status is sufficient in these soils. The results are more encouraging for cokriging over ordinary kriging. In practice, identifying the different nutrient zones with respect to soil reaction class is useful for effective soil test-based recommendations and to improve productivity of crops grown in the watershed.

Scatter plot of estimated versus measured and normal QQ-plot of standardized estimation errors with cokriging interpolation of pH versus EC, P2O5, K2O, Fe and Mn

Thematic maps on available P2O5, K2O, DTPA-extractable Fe and Mn (cokriging)
5 Conclusions
The systematic grid survey at 89 locations in Kaligaudanahalli microwatershed was carried out with the aim of deriving maps and spatial variability of soil nutrients for soil-test-based fertilizer recommendations. We employed cluster technique and derived four clusters. The normality test was performed using Kolmogorov–Smirnov test and found that available P2O5 is normally distributed with p value of 0.348 and positively correlated with pH (r = 0.382**). The ordinary and cokriging techniques used to derive thematic maps of available P2O5, K2O, DTPA-extractable Fe and Mn. The results showed that the maps derived from cokriging is good for practical recommendations based on soil test values for locally grown crops in the microwatershed. The study further stated that the applications of cokriging technique for deriving nutrient zones are quick and useful for optimizing nutrient plans at watershed level.
References
Arora CL (2002) Analysis of soil, plant and fertilizer. In: Fundamentals of soil science Published by Indian Soc of Soil Sci, pp 548
Behera SK, Shukla AK (2015) Spatial distribution of surface soil acidity electrical conductivity, soil organic carbon content and exchangeable potassium, calcium and magnesium in some cropped acid soils of India. Land Degrad Dev 26:71–79
Bhaskar Rao YJ, Naha K, Srinivasan R, Gopalan K (1991) Geology, geochemistry and geochronology of the Archaean Peninsular Gneiss around Gorur, Hassan District, Karnataka, India. Proc Indian Acad Sci Earth Planet Sci 100(4):399–412
Bhunia GS, Shit PK, Chattopadhyay R (2018) Assessment of spatial variability of soil properties using geostatistical approach of lateritic soil (West Bengal, India). Ann Agrarian Sci 16:436–443. https://doi.org/10.1016/j.aasci.2018.06.003
Blackmore S, Godwin RJ, Taylor JC, Cosser ND, Wood GA, Earl R, Knight S (1998) Understanding variability in four fields in the United Kingdom. In: Robert PC, Rust RH, Larson W (eds) Proceedings of the 4th international conference on precision agriculture. ASA, CSSA, SSSA, Madison, WI, pp 3–18
Bouma J, Hole FD (1971) Soil structure and hydraulic conductivity of adjacent virgin and cultivated pedons at two sites: a Typic Argiudoll (silt loam) and a Typic Eutrochrept (clay). Soil Sci Soc Am J Proc 35:314–318
Cambardella CA, Karlen DK (1999) Spatial analysis of soil fertility parameters. Precis Agric 1:5–14
Cambardella CA, Moorman TB, Novak JM, Parkin TB, Karlen DK, Turco RF, Konopka AE (1994) Field-scale variability of soil properties in central Iowa soils. Soil Sci Soc Am J 58:1501–1511
Cattle SR, Koppi AJ, McBratney AB (1994) The effect of cultivation on the properties of a Rhodoxeralf from the wheat/sheep belt of New South Wales. Geoderma 63:215–225
Domsch H, Wendroth O (1997) On-site diagnosis of soil structure for site specific management. In: Stafford JV (ed) Proceedings of the 1st European conference on precision agriculture. BIOS Scientific Publishers Ltd, Warwick, pp 95–102
Fabrizzi KP, Moron A, Garcia FO (2003) Soil carbon and nitrogen organic fractions in degraded vs. nondegraded mollisols in Argentina. Soil Sci Soc Am J 67:1831–1841
Geypens M, Vanongeval L, Vogels N, Meykens J (1999) Spatial variability of agricultural soil fertility parameters in a Gleyic Podzol of Belgium. Precis Agric 1:319–326
Goovaerts P (1997) Geostatistics for natural resources evaluation. Oxford University Press, New York
Gupta VC (1967) A simplified method for determining hot water soluble boron in podzol soils. Soil Sci 103:111–112
Heisel T, Ersboll AK, Andersen C (1999) Weed mapping with co-kriging using soil properties. Precis Agric 1:39–52
Isaaks EH, Srivastava RM (1989) An introduction to applied geostatistics. Oxford University Press, New York
Jackson ML (1973) Soil chemical analysis. Prentice Hall of India Pvt. Ltd., New Delhi
Johnston K, Ver Hoef JM, Krivoruchko K, Lucas N (2001) Using ArcGIS geostatistical analyst. Environ Syst Res, Redlands, USA
Journel AG, Huijbregts CJ (1978) Mining geostatistics. Academic Press, London
Kour S, Jalali VK (2006) Characteristics of hilly tract soils in relation to its sulphur status. In: Arora S, Sharma V (eds) Resource management for Sustainable Agriculture, pp 67–71
Kravchenko AN, Bullock DG (1999) A comparative study of interpolation methods for mapping soil properties. J Agron 91:393–400
Li J, Heap AD (2008) A review of spatial interpolation methods for environmental scientists. Geosci Aust Rec 23:137
Lindsay WL, Norvell WA (1978) Development of a DTPA soil test for zinc, iron, manganese and copper. Soil Sci Soc Am J 42:421–448
Mahantesh Karajanagi S, Patil PL, Dundur SS (2016) GIS Mapping of available nutrients status of village under Malaprabha command area in Karnataka. J Farm Sci 29:37–40
Mali SS, Naik SK, Bhatt BP (2016) Spatial variability in soil properties of Mango Orchards in Eastern Plateau and Hill Region of India. Vegetos 29(3):1–6. https://doi.org/10.5958/2229-4473.2016.00070.7
McBratney AB, Mendonca ML, Minansy B (2003) On digital soil mapping. Geoderma 117:3–52
Olsen SR, Cole CV, Watanabe FS, Dean LA (1954) Estimation of available phosphorus in soils by extraction with sodium bicarbonate. U. S. Department of Agriculture Circular No. 939. Banderis, A. D., D. H. Barter and K. Anderson. Agricultural and Advisor
Pal S, Manna S, Aich A, Chattopadhyay B, Mukhopadhyay SK (2014) Assessment of the spatio-temporal distribution of soil properties in East Kolkata wetland ecosystem (A Ramsar site: 1208). J Earth Syst Sci 123(4):729–740
Pathak H (2010) Trend of soil fertility status of Indian soils. Curr Adv Agric Sci 2:10–12
Patil SS, Patil VC, Al-Gaadi KA (2011) Spatial variability in fertility status of surface soils. World Appl Sci J 14(7):1020–1024
Patil PL, Kuligod VB, Gundlur SS, Jahnavi Katti, Nagaral IN, Shikrashetti P, Geetanjali HM, Dasog GS (2016) Soil fertility mapping in Dindur sub-watershed of Karnataka for site specific recommendations. J Indian Soc of Soil Sci 64:381–390. https://doi.org/10.5958/0974-0228.2016.00050.5
Seth Pinki, Chikkaramappa T, Das Rajeswari, Navya NC (2017) Characterisation and classification of soil resources of Kumachahalli micro-watershed in Chamarajanagar, Karnataka, India. Int J Curr Microbiol Appl Sci 6(12):319–329
Pulakeshi HBP, Patil PL, Dasog GS, Radder BM, Mansur CP (2012) Mapping nutrients status by geographic information system (GIS) in Amara et al. 53 Mantagani village under northern transition zone of Karnataka. Karnataka J Agric Sci 25:232–235
Rajendra H, Niranjana KV, Srinivas S, Nair KM, Dhanorkar BA, Reddy RS, Singh SK (2017) Land resource inventory for watershed planning and development of Kaligaudanahalli microwatershed, Gundlupet Taluk, Chamarajanagara District, Karnataka, Sujala MWS Publ. 28, ICAR – NBSS & LUP, RC, Bangalore, p 109
Ravi Kumar MA, Patil PL, Dasog GS (2007) Mapping of nutrients status of 48A Distributary of Malaprabha Right Bank Command of Karnataka by GIS technique. I—major nutrients. Karnataka J Agric Sci 20:735–737
Ruppert D (2004) Statistics and finance: an introduction. Springer, Berlin
Saha D, Kukal SS, Bawa SS (2012) Soil organic carbon stock and fractions in relation to land use and soil depth in the degraded Shiwaliks hills of lower Himalayas. Land Degrad Dev 22:407–416. https://doi.org/10.1002/ldr.2151
Sahrawat KL, Wani SP, Rego TJ, Pardhasaradhi G, Murthy KVS (2007) Widespread deficiencies of sulphur, boron and zinc in dryland soils of the Indian semi-arid tropics. Curr Sci 93:1428–1432
Samper-Calvete FJ, Carrera-Ramírez J (1996) Geostadística. Aplicaciones a la hidrologíasubterránea. Centro Internacional de Métodos Numéricosen Ingeniería, Universitat Politècnica de Catalunya, España, pp 484
Schloeder CA, Zimmerman NE, Jacobs MJ (2001) Comparison of methods for interpolating soil properties using limited data. Soil Sci Soc Am J 65:470–479
Singh SK, Dey P, Surendra Singh, Sharma PK, Singh YV, Latare AM, Singh CM, Dileep Kumar, Omkar Kumar, Yadav SN, Verma SS (2015) Emergence of boron and sulphur deficiency in soils of Chandauli, Mirzapur, Sant Ravidas Nagar and Varanasi Districts of Eastern Uttar Pradesh. J Indian Soc of Soil Sci 63:200–208. https://doi.org/10.5958/0974-0228.2015.00026.2
Srikant KS, Patil PL, Dasog GS, Gali SK (2008) Mapping of available major nutrients in Black and Red soils of a microwatershed in Northern Dry Zone of Karnataka. Karnataka J Agric Sci 21:391–395
Stenger R, Priesack E, Beese F (2002) Spatial variation of nitrate-N and related soil properties at the plot-scale. Geoderma 105:259–275
Tziachris P, Metaxa E, Papadopoulos F, Papadopoulou M (2017) Spatial modelling and prediction assessment of soil iron using kriging interpolation with pH as auxiliary information. Int J Geo-inform 6:283. https://doi.org/10.3390/ijgi6090283
Vauclin M, Vieira S, Vachaud G, Nielsen D (1983) The use of cokriging with limited field soil observations. Soil Sci Soc Am J 47:175–184
Velayutham C, Shoemaker D, Dromani A (2004) A standard methodology for embedding security functionally with in formal specifications of requirements. In: American conference on information systems, New York
Verhagen J (1997) Modeling soil and crop responses in a spatially variable field. In: Stafford JV (ed) Proceedings of the 1st European conference on precision agriculture. BIOS Scientific Publishers Ltd, Warwick, pp 197–204
Vieira SR, Nielsen DR, Biggar JW (1981) Spatial variability of field-measured infiltration rate. Soil Sci Soc Am J 47:175–184
Voltz M, Webster R (1990) A comparison of kriging, cubic splines and classification for predicting soil properties from sample information. J Soil Sci 41:473–490
Walkley A, Black IA (1934) An examination of the Degtjareff method for determining soil organic matter, and a proposed modification of the chromic acid titration method. Soil Sci 37:29–38
Warrick AW (1998) Spatial variability. In: Hillel D (ed) Environmental soil physics. Academic Press, New York, pp 655–675
Webster R, Oliver MA (2001) Geostatistics for environmental scientists. Wiley, Brisbane
Williams CH, Steinberg A (1959) Soil sulphur fractions as chemical indices of available sulphur in some Australian soils. Aust J Agric Res 10:340–352
Yates SR, Warrick AW (1987) Estimating soil water content using cokriging. Soil Sci Soc Am J 51:23
Acknowledgements
Authors gratefully acknowledge the funding received from Sujala-III project of Karnataka Watershed Development Department for carrying out this study. Authors express their thanks to Sri R.S. Reddy, Principal Scientist (retd.) in correcting the manuscript and for useful discussions made during this study.
Funding
This study was funded by World Bank (SUJALA-III Project, Grant No. NRMANBSSLUPol201405400404).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors express that there are no conflict of interest with the work contained in this manuscript.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hegde, R., Bardhan, G., Niranjana, K.V. et al. Spatial variability and mapping of selected soil properties in Kaligaudanahalli Microwatershed, Gundlupet Taluk, Chamarajanagar District, under hot semi arid agrosubregion of Central Karnataka Plateau, India. SN Appl. Sci. 1, 518 (2019). https://doi.org/10.1007/s42452-019-0486-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-019-0486-4