
Abstract
Traditionally, investigations in the area of stimulus equivalence have employed humans as experimental participants. Recently, however, artificial neural network models (often referred to as connectionist models [CMs]) have been developed to simulate performances seen among human participants when training various types of stimulus relations. Two types of neural network models have shown particular promise in recent years. RELNET has demonstrated its capacity to approximate human acquisition of stimulus relations using simulated matching-to-sample (MTS) procedures (e.g., Lyddy & Barnes-Holmes Journal of Speech and Language Pathology and Applied Behavior Analysis, 2, 14–24, 2007). Other newly developed connectionist algorithms train stimulus relations by way of compound stimuli (e.g., Tovar & Chavez The Psychological Record, 62, 747–762, 2012; Vernucio & Debert The Psychological Record, 66, 439–449, 2016). What makes all of these CMs interesting to many behavioral researchers is their apparent ability to simulate the acquisition of diversified stimulus relations as an analogue to human learning; that is, neural networks learn over a series of training epochs such that these models become capable of deriving novel or untrained stimulus relations. With the goal of explaining these quickly evolving approaches to practical and experimental endeavors in behavior analysis, we offer an overview of existing CMs as they apply to behavior–analytic theory and practice. We provide a brief overview of derived stimulus relations as applied to human academic remediation, and we argue that human and simulated human investigations have symbiotic experimental potential. Additionally, we provide a working example of a neural network referred to as emergent virtual analytics (EVA). This model demonstrates a process by which artificial neural networks can be employed by behavior–analytic researchers to understand, simulate, and predict derived stimulus relations made by human participants.




Similar content being viewed by others
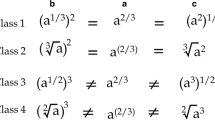

Notes
Thus, as will be explained shortly, “feedforward” means that experience with stimuli is passed sequentially through the network’s input, hidden, and output layers. “Backpropagation” means that these layers, in turn, are altered by the experience so that they accommodate future experience differently. In broad strokes, the process is similar to feedback loops that are familiar in discussions of human learning.
Note that we also conducted tests for symmetry; however, these outcomes are not described herein, as the outcomes were entirely consistent with those of our tests for equivalence.
References
Abbass, H. A. (2002). An evolutionary artificial neural networks approach for breast cancer diagnosis. Artificial Intelligence in Medicine, 25, 265–281. doi:10.1016/s0933-3657(02)00028-3.
Aleven, V. (2013). Help seeking and intelligent tutoring systems: theoretical perspectives and a step towards theoretical integration. In R. Azevedo & V. Aleven (Eds.), International handbook of metacognition and learning technologies (pp. 311–335). New York, NY: Springer. doi:10.1007/978-1-4419-5546-3_21.
Allamehzadeh, M., & Mokhtari, M. (2003). Prediction of aftershocks distribution using self-organizing feature maps (SOFM) and its application on the Birjand-Ghaen and Izmit earthquakes. Journal of Seismology and Earthquake Engineering, 5, 1–15. doi:10.1016/j.quaint.2012.07.059.
Arciniegas, I., Daniel, B., & Embrechts, M. J. (2001). Exploring financial crises data with self-organizing maps (SOM). In N. Allinson, L. Allinson, H. Yin, & J. Slack (Eds.), Advances in self-organizing maps (pp. 30–39). London, England: Springer-Verlag.
Arntzen, E., & Holth, P. (1997). Probability of stimulus equivalence as a function of training design. The Psychological Record, 47, 309–320.
Barnes, D., & Hampson, P. J. (1993). Stimulus equivalence and connectionism: implications for behavior analysis and cognitive science. Psychological Record, 43, 617–638.
Bullinaria, J. A. (1997). Modeling reading, spelling, and past tense learning with artificial neural networks. Brain and Language, 59, 236–266. doi:10.1006/brln.1997.1818.
Burgos, J. E. (2007). Autoshaping and automaintenance: a neural-network approach. Journal of the Experimental Analysis of Behavior, 88, 115–130. doi:10.1901/jeab.2007.75-04.
Cohen, A., & Sackrowitz, H. B. (2002). Inference for the model of several treatments and a control. Journal of Statistical Planning and Inference, 107, 89–101. doi:10.1016/s0378-3758(02)00245-8.
Connell, J. E., & Witt, J. C. (2004). Applications of computer-based instruction: using specialized software to aid letter-name and letter-sound recognition. Journal of Applied Behavior Analysis, 37, 67–71. doi:10.1901/jaba.2004.37-67.
Critchfield, T. S., & Fienup, D. M. (2008). Stimulus equivalence. In S. F. Davis & W. F. Buskist (Eds.), 21st century psychology: a reference handbook (pp. 360–372). Thousand Oaks, CA: Sage.
Critchfield, T. S., & Fienup, D. M. (2010). Using stimulus equivalence technology to teach about statistical inference in a group setting. Journal of Applied Behavior Analysis, 43, 437–462. doi:10.1901/jaba.2010.43-763.
Critchfield, T. S., & Fienup, D. M. (2013). A “happy hour” effect in translational stimulus relations research. Experimental Analysis of Human Behavior Bulletin, 29, 2–7.
Cullinan, V., Barnes, D., Hampson, P. J., & Lyddy, F. (1994). A transfer of explicitly and nonexplicitly trained sequence responses through equivalence relations: an experimental demonstration and connectionist model. The Psychological Record, 44, 559–585.
De Rose, J. C., De Souza, D. G., & Hanna, E. S. (1996). Teaching reading and spelling: exclusion and stimulus equivalence. Journal of Applied Behavior Analysis, 29, 451–469. doi:10.1901/jaba.1996.29-451.
Desmarais, M. C., Meshkinfam, P., & Gagnon, M. (2006). Learned student models with item to item knowledge structures. User Modeling and User-Adapted Interaction, 16, 403–434. doi:10.1007/s11257-006-9016-3.
Desmarais, M. C., & Pu, X. (2005). A Bayesian inference adaptive testing framework and its comparison with item response theory. International Journal of Artificial Intelligence in Education, 15, 291–323. doi:10.1007/11527886_51.
Donahoe, J. W., & Burgos, J. E. (2000). Behavior analysis and revaluation. Journal of the Experimental Analysis of Behavior, 74, 331–346. doi:10.1901/jeab.2000.74-331.
Erdal, H. I., & Ekinci, A. (2013). A comparison of various artificial intelligence methods in the prediction of bank failures. Computational Economics, 42, 199–215. doi:10.1007/s10614-012-9332-0.
Feng, M., Heffernan, N. T., & Koedinger, K. R. (2009). Addressing the assessment challenge in an intelligent tutoring system that tutors as it assesses. User Modeling and User-Adapted Interaction, 19, 243–266. doi:10.1007/s11257-009-9063-7.
Fienup, D. M., Covey, D. P., & Critchfield, T. S. (2010). Teaching brain–behavior relations economically with stimulus equivalence technology. Journal of Applied Behavior Analysis, 43, 19–33. doi:10.1901/jaba.2010.43-19.
Fienup, D. M., & Critchfield, T. S. (2010). Efficiently establishing concepts of inferential statistics and hypothesis decision making through contextually controlled equivalence classes. Journal of Applied Behavior Analysis, 43, 19–33. doi:10.1901/jaba.2010.43-437.
Fienup, D. M., & Critchfield, T. S. (2011). Transportability of equivalence-based programmed instruction: efficacy and efficiency in a college classroom. Journal of Applied Behavior Analysis, 43, 763–768. doi:10.1901/jaba.2011.44-435.
Fienup, D. M., Critchfield, T. S., & Covey, D. P. (2009). Building contextually-controlled equivalence classes to teach about inferential statistics: a preliminary demonstration. Experimental Analysis of Human Behavior Bulletin, 27, 1–10.
Fodor, J. A., & Pylyshyn, Z. W. (1988). Connectionism and cognitive architecture: a critical analysis. Cognition, 28, 3–71. doi:10.1016/0010-0277(88)90031-5.
Guo, D., Liao, K., & Morgan, M. (2007). Visualizing patterns in a global terrorism incident database. Environment and Planning B: Planning and Design, 34, 767–784. doi:10.1068/b3305.
Hagan, M., Demuth, H., & Beale, M. (2002). Neural network design. Boston, MA: PWS.
Hamilton, B. E., & Silberberg, A. (1978). Contrast and autoshaping in multiple schedules varying reinforcer rate and duration. Journal of the Experimental Analysis of Behavior, 30, 107–122. doi:10.1901/jeab.1978.30-107.
Hayes, S. C., Fox, E., Gifford, E. V., Wilson, K. G., Barnes-Holmes, D., & Healy, O. (2001). Derived relational responding as learned behavior. In S. C. Hayes, D. Barnes-Holmes, & B. Roche (Eds.), Relational frame theory: a post-Skinnerian account of human language and cognition (pp. 21–50). New York, NY: Plenum.
Haykin, S. O. (2008). Neural networks and learning machines (3rd ed.). Upper Saddle River, NJ: Pearson Education.
Heller, J., Steiner, C., Hockemeyer, C., & Albert, D. (2006). Competence-based knowledge structures for personalised learning. International Journal on E-Learning, 5, 75–88.
Huang, Y., Chen, J., Chang, Y., Huang, C., Moon, W. K., Kuo, W., et al. (2013). Diagnosis of solid breast tumors using vessel analysis in three-dimensional power Doppler ultrasound images. Journal of Digital Imaging, 26, 731–739. doi:10.1007/s10278-012-9556-5.
Kemp, S. N., & Eckerman, D. A. (2001). Situational descriptions of behavioral procedures: the in situ testbed. Journal of the Experimental Analysis of Behavior, 75, 135–164. doi:10.1901/jeab.2001.75-135.
Khan, M. R., & Ondrusek, C. (2000). Short-term electric demand prognosis using artificial neural networks. Electrical Engineering, 51, 296–300.
Knutti, R., Stocker, T. F., Joos, F., & Plattner, G. K. (2003). Probabilistic climate change projections using neural networks. Climate Dynamics, 21, 257–272. doi:10.1007/s00382-003-0345-1.
Koedinger, K. R., Corbett, A. T., & Perfetti, C. (2012). The knowledge-learning-instruction framework: bridging the science-practice chasm to enhance robust student learning. Cognitive Science, 36, 757–798. doi:10.1111/j.1551-6709.2012.01245.x.
LeBlanc, L. A., Miguel, C. F., Cummings, A. R., Goldsmith, T. R., & Carr, J. E. (2003). The effects of three stimulus-equivalence testing conditions on emergent US geography relations of children diagnosed with autism. Behavioral Interventions, 18, 279–289. doi:10.1002/bin.144.
Lovett, S., Rehfeldt, R. A., Garcia, Y., & Dunning, J. (2011). Comparison of a stimulus equivalence protocol and traditional lecture for teaching single-subject designs. Journal of Applied Behavior Analysis, 44, 819–833. doi:10.1901/jaba.2011.44-819.
Lyddy, F., & Barnes-Holmes, D. (2007). Stimulus equivalence as a function of training protocol in a connectionist network. Journal of Speech and Language Pathology and Applied Behavior Analysis, 2, 14–24. doi:10.1037/h0100204.
Lyddy, F., Barnes-Holmes, D., & Hampson, P. J. (2001). A transfer of sequence function via equivalence in a connectionist network. The Psychological Record, 51, 409–428. doi:10.1037/h0100204.
Maqsood, I., Khan, M. R., & Abraham, A. (2004). An ensemble of neural networks for weather forecasting. Neural Computing and Applications, 13, 112–122. doi:10.1007/s00521-004-0413-4.
McCaffrey, J. (2014). Neural networks using C# succinctly [Blog post]. Retrieved from https://jamesmccaffrey.wordpress.com/2014/06/03/neural-networks-using-c-succinctly
McCaffrey, J. (2015). Coding neural network back-propagation using C#. Visual Studio Magazine. Retrieved from https://visualstudiomagazine.com/articles/2015/04/01/back-propagation-using-c.aspx
McClelland, J. L., & Rumelhart, D. E. (1986). Parallel distributed processing, vol. 2: psychological and biological models. Cambridge, MA: MIT Press.
Nason, S., & Zabrucky, K. (1988). A program for comprehension monitoring of text using HyperCard for the Macintosh. Behavior Research Methods, Instruments, & Computers, 20, 499–502.
Ninness, C., Henderson, R., Ninness, C., & Halle, S. (2015). Probability pyramiding revisited: univariate, multivariate, and neural networking analyses of complex data. Behavior and Social Issues, 24, 164–186. doi:10.5210/bsi.v24i0.6048.
Ninness, C., Lauter, J., Coffee, M., Clary, L., Kelly, E., Rumph, M., et al. (2012). Behavioral and biological neural network analyses: a common pathway toward pattern recognition and prediction. The Psychological Record, 62, 579–598. doi:10.5210/bsi.v22i0.4450.
Ninness, C., Rumph, M., Clary, L., Lawson, D., Lacy, J. T., Halle, S., et al. (2013). Neural network and multivariate analysis: pattern recognition in academic and social research. Behavior and Social Issues, 22, 49–63. doi:10.5210/bsi.v22i0.4450.
Ninness, C., Rumph, R., McCuller, G., Harrison, C., Vasquez, E., Ford, A., et al. (2005). A relational frame and artificial neural network approach to computer-interactive mathematics. The Psychological Record, 55, 561–570. doi:10.1007/bf03395503.
Oğcu, G., Demirel, O. F., & Zaim, S. (2012). Forecasting electrical consumption with neural networks and support vector regression. Procedia – Social and Behavioral Sciences, 58, 1576–1585. doi:10.1016/j.sbspro.2012.09.1144.
Rumelhart, D. E., Hinton, G. E., & Williams, D. C. (1986). Learning representations by back-propagating errors. Nature, 323, 533–536. doi:10.1038/323533a0.
Sidman, M., & Cresson, O. (1973). Reading and crossmodal transfer of stimulus equivalences in severe retardation. American Journal of Mental Deficiency, 77, 515–523.
Sidman, M., & Tailby, W. (1982). Conditional discrimination vs. matching to sample: an expansion of the testing paradigm. Journal of the Experimental Analysis of Behavior, 37, 5–22.
Steele, D. M., & Hayes, S. C. (1991). Stimulus equivalence and arbitrarily applicable relational responding. Journal of the Experimental Analysis of Behavior, 56, 519–555. doi:10.1901/jeab.1991.56-519.
Stromer, R., Mackay, H. A., & Stoddard, L. T. (1992). Classroom applications of stimulus equivalence technology. Journal of Behavioral Education, 2, 225–256. doi:10.1007/bf00948817.
Tovar, A. E., & Chavez, A. T. (2012). A connectionist model of stimulus class formation with a yes/no procedure and compound stimuli. The Psychological Record, 62, 747–762. doi:10.1007/s40732-016-0184-1.
Vernucio, R. R., & Debert, P. (2016). Computational simulation of equivalence class formation using the go/no-go procedure with compound stimuli. The Psychological Record, 66, 439–449. doi:10.1007/s40732-016-0184-1.
Walker, D., Rehfeldt, R. A., & Ninness, C. (2010). Using the stimulus equivalence paradigm to teach course material in an undergraduate rehabilitation course. Journal of Applied Behavior Analysis, 43, 615–633. doi:10.1901/jaba.2010.43-615.
Wolberg, W. (1992). Breast cancer Wisconsin (diagnostic) data set [UCI Machine Learning Repository]. Retrieved from http://archive.ics.uci.edu/ml/
You, H., & Rumbe, G. (2010). Comparative study of classification techniques on breast cancer FNA biopsy data. International Journal of Artificial Intelligence and Interactive Multimedia, 3, 5–12. doi:10.9781/ijimai.2010.131.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
No animals or humans were involved in the development of this study. All data were acquired by way of artificial intelligence systems.
Conflict of Interest
All authors declare “No conflicts of interest.”
Electronic Supplementary Material
ESM 1
(CSV 140 bytes)
Appendix
Appendix
Conducting a CM Analysis with Training and Test Stimuli
As mentioned earlier in this article, the idea of converting abstract stimuli (e.g., pictorial symbols, mathematical expressions, or verbal concepts) into binary values may seem like an unusual way to simulate stimuli for use in training stimulus equivalence procedures. The binary encoding issue involves the following feature: Rather than using pictorial symbols or conceptual stimuli, which are often employed when training stimulus relations to human participants, stimuli are presented to neural networks as a series of binary activation units that can be either on (1) or off (0). So, rather than pictorial or conceptual stimuli that are related or not related to one another in the training of human participants, each row or vector of activation units is composed of 1s and 0s that are related or not related to one another. During most traditional equivalence-based studies, human participants derive stimulus relations by learning the mutually shared patterns among stimuli. Analogously, in order for a neural network to derive stimulus relations, it must learn the mutually shared patterns of binary activation units. As a practical matter, virtually any set of input patterns of stimuli that can be employed in the training and testing of human participants can be parsed into binary activation units for training and testing by way of a computer model.
Trained Stimuli
Figure 5 displays rows within the exemplar trained stimuli wherein each row contains six unique stimulus arrangements followed by two target variables. The first row—A1B1—displays the digit 1 in columns A1 and B1; the other columns in this row are set to 0. In binary activation format, this row indicates that the A1 and B1 stimulus units are on (1), whereas B2, C1, C2, and A2 are off (0).

The top panel displays the trained and tested stimulus relations presented to emergent virtual analytics (EVA) as an analogue to human–computer interactive learning. In the bottom panel, selected abstract stimuli, as might be seen by human participants during interactive training, are superimposed on the binary training stimuli
We identify the target variables in the last two columns (within-class stimuli or between-class stimuli) as YES (1) and NO (0), respectively (cf. Tovar & Chavez, 2012). To make the group membership patterns somewhat more salient (as might be seen by humans), we have shaded all stimulus units that share within-class membership. However, unlike the Tovar and Chavez data set, no extraexperimental pretraining input values (i.e., XY, YZ, and XZ) are included within the trained stimuli.
In the bottom panel of Fig. 5, selected abstract stimuli, as might be seen by human participants during interactive training, are superimposed on the binary training stimuli. On particular trials, A1B1 are displayed adjacent to one another on the computer screen. Likewise, on various trials, B1C1 are displayed side by side on the screen. Throughout training, contingent reinforcement is provided for correctly identifying A1B1 and B1C1 stimuli as being members of the same class (i.e., within-class stimuli). During testing, the emergence of A1C1 as being members of the same class indicates the formation of the equivalence class A1B1C1.
Tested Stimuli
With regard to the tested values displayed in the top panel of Fig. 5, there are four rows, and each row contains six unique stimulus units followed by the target variables. For example, the first row—A1C1—displays the digit 1 in columns A1 and C1; the other columns in this row are set to 0. In binary activation format, this row shows that the A1 and C1 stimulus units are on (1), whereas B2, C2, B1, and A2 are off (0). The first row stands in contrast to all other rows within the tested stimuli. All of the YES column variables display 1s or 0s in order to allow the researcher to visually identify the desired or target values. Note, however, that the last column labeled NO contains only 0 values. Subsequent to training, this last column will display the simulated participants’ percentage of correct task performances.
Because comma-separated values (CSV) files can be used with any spreadsheet program, we use this format as an exemplar for the current training data (see the CSV files identified as “Train_8_rows_8_cols” and “Test_4_rows_8_cols” in the supplemental materials). As described within the main text, we also provide two additional data sets (identified as “Train_Opposites_8_rows_8_cols” and “Test_Opposites_4_rows_8_cols” in the supplemental materials) that the user can access and run by way of the EVA network. Figure 6 shows the same training input values displayed in Fig. 5 after being converted to CSV format. Note that all row and column descriptors have been deleted when saving the data to this format. Eliminating descriptors is essential for inputting training and test values.

Training input values (as displayed in the top panel of Fig. 5) converted to comma-separated values (CSV) format
Running the EVA Application
In Fig. 7, we provide an illustration of the EVA Windows form where all input parameters are prepared to receive the training and test files. As described within the text, the total number of columns and rows for the training values is set to 8 because these values correspond to the number of units within the training file. The number of input neurons is 6 because the first 6 out of 8 column variables in each row represent stimulus units. We set the momentum option to 0.10 in this example. Moving to the left side of this Windows form, we have set the number of hidden neurons at 2. The number of rows for the test data is set at 4 because this represents the total number of rows employed in the test data, and the learning rate is set at 0.50. The simulation number, displayed as 1, is the program’s current randomization seed. Advancing the simulation number randomizes all previous training weight and bias values. This is analogous to initiating training and testing for a new human participant; that is, each time the simulation number is advanced, all previous learning is deleted and the input values are randomized (resequenced) by the Fisher–Yates shuffle algorithm. Thus, with each of the 10 possible simulation numbers, EVA initiates the training of a completely new simulated participant.

Emergent virtual analytics (EVA) Windows form employed in the training and testing of simulated participants
Sensitive Settings
Virtually all CMs that employ feedforward backpropagation algorithms have several sensitive settings to which the researcher must be attentive. Two of the most sensitive are the learning rate and the momentum. When conducting a series of simulations, the learning rate and momentum settings must remain constant when comparing the task performances across simulated participants. Likewise, the number of hidden neurons employed during training is a parameter that should not be changed when comparing performances across simulated participants.
CM Training
Clicking the Train button in the center of Fig. 8 opens a new window that allows the user to select the training data. Upon selecting the training file, the CM immediately initiates 5000 training epochs. When training is finished, the number of epochs completed in the training of a simulated participant appears on the left side of the simulation number under the “Epochs Conducted” heading. At this point, this number should match the number displayed under the “Epochs Target” heading.

Emergent virtual analytics (EVA) Windows form showing the settings employed during the training and testing of a simulated participant
As shown in Fig. 9, training accuracy is identified at 100%, and the MSE is 0.0000804 in this particular example. Training accuracy and the MSE are important, but these are preliminary metrics of how well the network will perform on test data. These preliminary outcomes suggest that the researcher is well positioned to conduct a CM analysis of the test data.

Emergent virtual analytics (EVA) Windows form displaying training outcomes
Training Outcomes
Under the “Randomized Training Data Results” heading, the leftmost number indicates the correct (target) value, and the adjacent number indicates EVA’s percentage of correct task performances for matching this target (i.e., EVA’s predicted value appears immediately to the right of each target value). For example, the first target value in this listing is 1, and the adjacent correct task performance is 0.992878. The second target value is 0, and the adjacent task performance value is 0.0053285. Inspecting all of the outcomes under this heading, it becomes apparent that all of the predicted values are very good approximations of their respective targets. Thus, the researcher is well positioned to conduct an analysis of the test values. Because EVA saves a copy of all weight and bias values calculated during training, the researcher can move directly toward conducting an analysis of the test values.
Conducting an Analysis of the Test Values
Figure 10 displays the test data set after being converted to CSV format. Again, the last column includes only 0s because these task performance values have yet to be calculated by the neural network (see the “Test_4_rows_8_cols.csv” file in the supplemental materials).

Illustration of the test data set displayed in Fig. 5 after being converted to comma-separated values (CSV) format
As shown in Fig. 11, clicking the Test button located directly below the Train button opens a new window, allowing the user to select the test values file. When the user clicks the test file name, EVA immediately runs an analysis of the selected test values.

Illustration of the emergent virtual analytics (EVA) Windows form allowing the selection of the test file
Test Findings
On the far right side of Fig. 12, the test data findings appear under the “EVA Test Data Outcomes” heading. Within each row, there are two values. The target values of 1 or 0 appear to the left of their corresponding percentages of correct task performances. For example, the first target value in this listing is 1, and the adjacent task performance value is 0.9942561.The second target value is 0, and the adjacent task performance value is 0.0269981. Clicking the Save Evaluation Values as CSV button, the user is able to save a copy of the test outcomes to any computer location.

Test data findings appear under the “EVA Test Data Outcomes” heading. EVA emergent virtual analytics
Opening the saved CSV file, the network analysis of the test outcomes appears as shown in Fig. 13. The target values, YES (1) and NO (0), fall under column A, and the network’s calculated percentages of correct task performances appear immediately adjacent to each target value under column B. The results can be converted into a bar graph by highlighting the column B data and inserting a column chart.

Spreadsheet illustration of the network’s test findings
Based on the results displayed in Fig. 13, Fig. 14 shows a bar graph of the network’s test findings. Each bar depicts how well the network performed with respect to deriving stimulus relations for each of the four possible classifications. A1C1 and A2C2 refer to the emergent stimulus relations for within-class membership, whereas A1C2 and A2C1 refer to stimuli that do not form class membership (between-class stimuli).

A1C1 and A2C2 represent connectionist model (CM) task performance levels for within-class relations, and A1C2 and A2C1 represent the network’s identification of stimuli that fall between classes. MSE mean square error
As shown in Fig. 14, setting the maximum number of epochs at 5000 allows the model to identify stimuli that are members of the same class. Training the network with this fairly large number of epochs, the MSE falls to 0.0000804, and the within-class and between-class stimuli are well differentiated where the task performance levels are 0.9942561 for A1C1 and 0.9942381 for A2C2. As might be expected, Fig. 14 shows the between-class stimuli outcomes at extremely low task performance levels; that is, the stimuli in these classes did not form group membership.
Computational Processes
As described earlier, for all input values presented to the CM, the algorithm generates a series of randomized weights (between −1 and 1 or much smaller) that function as multipliers between neurons. Subsequent to multiplying these input values by these randomized weights, the values are summed and passed to neurons located within the hidden layer. Within the hidden layer, the algorithm transforms all weighted inputs and bias values using an activation function (e.g., the hyperbolic tangent function) and then passes these values along to the output layer for comparison with the known target values.
As a practical matter, bias values are constants (usually values of 1) that act to shift all inputs away from the center (origin) of the coordinate axis. Oftentimes, bias nodes are not discussed or illustrated in streamlined descriptions of neural network algorithms; however, they are essential components of the feedforward backpropagation algorithm. As stated by McCaffrey (2014):
Training a neural network is the process of finding a set of good weights and bias values so that the known outputs of some training data match the outputs computed using the weights and bias values. The resulting weights and bias values for a particular problem are often collectively called a model. The model can then be used to predict the output for previously unseen inputs that do not have known output values. (p. 95)
Figure 15 provides a didactic illustration of the multifaceted feedforward backpropagation algorithm in the form of a flowchart. In this illustration, the input and bias values enter at the top of the chart and are passed downward and then recycled during backpropagation; that is, the weight and bias values are continually reprocessed to gradually improving levels of accuracy over a series of forward and backward passes.

Illustration of the feedforward backpropagation algorithm. During the forward pass (solid arrow lines), input and bias values enter at the top and are passed downward and then recycled during backpropagation (dashed arrow lines)
To revisit the flow of learning originally shown in Fig. 1 (but with inputs positioned at the top of this illustration), the weight and bias values are summed and fed forward (solid arrow lines) to the activation function in the hidden layer (the hyperbolic tangent function). Then, new weight and bias values are calculated and forwarded to the output layer, where the values are compared with the target values (the Softmax function).
Upon completing the forward pass to the output layer, the backpropagation process begins. Each backward pass (dashed arrow lines) from the output layer recalculates the weight and bias values in accordance with the current level of error that a neuron has produced and returns these values to the hidden layer for processing. The hidden layer applies the activation function and returns the updated values to the input layer. The feedforward and backpropagation processes continue until a specified number of epochs are completed. When the required number of epochs has been accomplished, the training process is stopped, and the researcher can run his or her test data based on a trained CM (see Haykin, 2008, for comprehensive mathematical details).
Number of Hidden Neurons
The researcher determines the number of neurons (processing units) that exist within the hidden layer. It should be understood, however, that if an insufficient number of neurons is employed, the network may not be able to identify the intricacies of a potentially complex training data set. This type of problem is often referred to as “underfitting the data.” On the other hand, if too many neurons are employed within the hidden layer, the network attempts to model all of the random noise that usually exists within any complex training data set. In doing so, the idiosyncratic distribution of output values tends to become overly explicit, and the random noise may become incorporated within the network’s overall modeling of the training data, resulting in the network’s inability to formulate a generalized model of the training data. Such an outcome is frequently described as “overfitting” (see Haykin, 2008, for a discussion of these and other related issues).
Learning Rate and Momentum
As noted within Table 1, the learning rate controls the size and speed of the weight and bias values that are updated during each training epoch. Similar to the learning rate, the momentum modulates the size of the updated values and also helps the network avoid inaccurate updates (often referred to as local minima). Combining high learning rates and momentum terms (e.g., both values at or near 1) increases the likelihood that the CM may overestimate the best weight and bias values needed to produce an accurate model (see Hagan et al., 2002, for an in-depth discussion).
Software and Input Values
This article illustrates the application of a neural network using the Windows version of C#. The training and test values employed as exemplars within this article were obtained from a study originally conducted by Tovar and Chavez (2012) and replicated by Vernucio and Debert (2016). The feedforward backpropagation algorithm that operates within the EVA application was originally developed and described by McCaffrey (2015; refer to Haykin, 2008, for a related discussion). A functional beta Windows version of EVA (with training and test values) is downloadable for academic researchers from www.chris-ninness.com.
The EVA software is enclosed within a zipped or compressed folder in conjunction with the training data and test data files. The current beta version of EVA runs on most Windows operating systems; however, before running the current Windows version of EVA, some Windows machines may require the installation of a freely available and downloadable Microsoft program (http://go.microsoft.com/fwlink/?LinkID=145727&clcid=0x894). The user must right-click and extract all files prior to beginning the installation process. Subsequent to extraction, the user opens the EVA folder and clicks the EVA icon. If a Microsoft or other antivirus warning appears (and it will), researchers are advised to read the following information prior to installing and running the program.
The current beta version of the EVA application was designed to run on Windows 7–10 operating systems (a Mac OS version is in progress). All versions of the EVA CM neural network system are and will remain freely accessible to interested academic users; however, the current beta version of EVA is designed for academic research and demonstration purposes only. The authors and the journal (The Behavior Analyst) assume no liability for any damages associated with using, modifying, or distributing this program. The program has not been extensively field tested with input values (data sets) beyond those described in this article. This program is made available to interested educators or researchers without cost and without any warranties or provision for support. The authors and the journal assume no responsibility or liability for the use of the program and do not provide any certifications, licenses, or titles under any patent, copyright, or government grant. The authors and the journal make no representations or assurances with regard to the security, functionality, or other components of the program. There are unidentifiable hazards associated with installing and running any software application, and users and researchers are responsible for determining the extent to which this program is compatible with the computer and other software currently installed on the user’s computer.
Rights and permissions
About this article

Cite this article
Ninness, C., Ninness, S.K., Rumph, M. et al. The Emergence of Stimulus Relations: Human and Computer Learning. Perspect Behav Sci 41, 121–154 (2018). https://doi.org/10.1007/s40614-017-0125-6
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40614-017-0125-6