
Abstract
Introduction
As novel therapies for chronic kidney disease (CKD) in type 2 diabetes mellitus (T2DM) become available, their long-term benefits should be evaluated using CKD progression models. Existing models offer different modeling approaches that could be reused, but it may be challenging for modelers to assess commonalities and differences between the many available models. Additionally, the data and underlying population characteristics informing model parameters may not always be evident. Therefore, this study reviewed and summarized existing modeling approaches and data sources for CKD in T2DM, as a reference for future model development.
Methods
This systematic literature review included computer simulation models of CKD in T2DM populations. Searches were implemented in PubMed (including MEDLINE), Embase, and the Cochrane Library, up to October 2021. Models were classified as cohort state-transition models (cSTM) or individual patient simulation (IPS) models. Information was extracted on modeled kidney disease states, risk equations for CKD, data sources, and baseline characteristics of derivation cohorts in primary data sources.
Results
The review identified 49 models (21 IPS, 28 cSTM). A five-state structure was standard among state-transition models, comprising one kidney disease-free state, three kidney disease states [frequently including albuminuria and end-stage kidney disease (ESKD)], and one death state. Five models captured CKD regression and three included cardiovascular disease (CVD). Risk equations most commonly predicted albuminuria and ESKD incidence, while the most predicted CKD sequelae were mortality and CVD. Most data sources were well-established registries, cohort studies, and clinical trials often initiated decades ago in predominantly White populations in high-income countries. Some recent models were developed from country-specific data, particularly for Asian countries, or from clinical outcomes trials.
Conclusion
Modeling CKD in T2DM is an active research area, with a trend towards IPS models developed from non-Western data and single data sources, primarily recent outcomes trials of novel renoprotective treatments.
Plain Language Summary
The clinical effects of new treatments and their costs are often evaluated over a longer time frame than is possible in clinical trials by using computer simulation models. As new treatments are becoming available to treat chronic kidney disease, including in patients with type 2 diabetes, chronic kidney disease models may be used to inform clinical and economic decisions regarding these new treatment options. In the present study, we identified 49 published simulation models of chronic kidney disease used in populations with type 2 diabetes, and reviewed their structures and the data sources they used. The models focused mostly on disease states and outcomes associated with albuminuria (a condition in which the protein albumin is found in the urine) and end-stage kidney disease. Model structures with five disease states, including a kidney disease-free state, three kidney disease states, and death, were the most common. Relatively few models used glomerular filtration rates (a common measure of kidney function) or captured the possibility of an improvement in chronic kidney disease. Important data sources for many models were patient registries, cohort studies, and clinical trials, most conducted several decades ago in high-income countries with a high proportion of White participants. Several models developed in the past 5 years, particularly for Asian countries, instead relied largely or exclusively on country-specific data. In parallel, several individual patient simulations were recently developed from large outcomes trials for new treatments, including from trial subgroups covering specific geographical settings or ethnicities, shortly after trial publication.
Similar content being viewed by others
Why carry out this study? |
Chronic kidney disease (CKD) in type 2 diabetes mellitus (T2DM) is associated with a substantial clinical and economic burden globally |
Evaluating new treatment options, including renoprotective drugs, requires accurate computer simulation models of CKD in T2DM, which were reviewed systematically in this study to identify model structures and approaches and data sources used, to inform future model development |
What was learned from the study? |
Computer simulation models of CKD in T2DM focused on albuminuria and end-stage kidney disease, with relatively few models capturing CKD regression or remission, or employing glomerular filtration rate (GFR) for modeling |
Central data sources informing models were predominantly from high-income countries and White populations, but several recent models were developed from country-specific data for Asian countries or from large outcomes trials |
The models and data sources identified in this review can be used as a starting point to develop new or update existing CKD models for T2DM, especially when combined with recent clinical findings on albuminuria and GFR trajectories and new data sources on CKD treatments |
Introduction
Chronic kidney disease (CKD) affects nearly one in ten people globally—approximately 700 million people—and was responsible for an estimated 1.2 million deaths in 2017 [1]. By 2040, CKD is projected to rank among the five leading causes of years of life lost [2]. Healthcare spending related to CKD is already substantial: US Medicare costs for CKD and end-stage kidney disease (ESKD) in 2017 exceeded US dollars (USD) 120 billion or one in every three fee-for-service dollars spent by Medicare [3]. Among commercially insured US patients with newly recognized CKD and type 2 diabetes mellitus (T2DM), total costs were USD 24,029 per person per year, while mean total healthcare-related CKD costs in Spain were euros (EUR) 14,533 in 2019 [4, 5].
More severe CKD increases the risk of adverse clinical outcomes, in particular cardiovascular disease (CVD) and mortality [6, 7], and necessitates more intensive and more expensive therapy, including renal replacement therapy (RRT) such as dialysis or kidney transplant [8]. For example, among commercially insured US patients with CKD, microalbuminuria, and T2DM, per-person per-year costs were USD 18,529 in patients with CKD stage 1, compared with USD 110,210 in patients with CKD stage 5 [4]. Similar findings were reported for Germany, where mean per-person annual costs for were EUR 8030 for patients in CKD stage 3 relative to EUR 44,374 for dialysis-treated patients [9], and for Italy, where mean direct healthcare costs per patient in the first year of treatment with erythropoiesis-stimulating agents were EUR 8917 for patients in CKD stages 1–3 compared with EUR 31,985 for dialysis-treated patients [10]. In China, the mean annual costs for hemodialysis and peritoneal dialysis were Chinese yuan (CNY) 94,761 and CNY 80,763 per patient, compared with CNY 132,253 and CNY 93,155 per patient with a kidney transplant in the first and second year, respectively [11].
Clinically, CKD is defined as kidney structure or kidney function abnormalities present for more than 3 months and classified using glomerular filtration rate (GFR) and albuminuria [12]. As part of this classification, GFR is conventionally grouped into five stages that, together with albuminuria, inform patient prognosis [12, 13]. The classical phenotype of CKD, both with and without T2DM, has been a linear decline in estimated GFR (eGFR) in the presence of persistent albuminuria [14]. Alternative disease trajectories have recently been described, including eGFR declines in diabetes in the absence of albuminuria [15] as well as non-linear, non-progressive, and variable eGFR trajectories [16, 17], with the latter being linked to outcomes such as ESKD, initiation of RRT, and mortality [18, 19]. While CKD remains a progressive disease in most patients, CKD is not irreversible and may regress, to the extent that CKD regression and death are more probable with advancing age than CKD progression and kidney failure [20, 21].
Metabolic conditions such as obesity and diabetes are among the main risk factors for CKD and increase the risk of non-CKD sequelae in patients with CKD [22,23,24]. Diabetes, in particular, is an independent risk factor for kidney damage, prevalent in almost two-thirds of patients with CKD, and will contribute substantially to the projected increase in worldwide CKD cases [23, 25, 26].
The treatment of CKD in T2DM has recently advanced, after a prolonged period with limited progress in therapeutic options, by the availability of novel drug classes including sodium-glucose cotransporter 2 (SGLT2) inhibitors, such as canagliflozin and dapagliflozin, and mineralocorticoid receptor agonists, such as finerenone [22, 27, 28].
SGLT2 inhibitors have been shown to have cardio- and renoprotective effects, as evaluated by improvements in eGFR and albuminuria and in clinically relevant endpoints, and they reduce mortality in patients with T2DM and at different stages of CKD [27, 29,30,31]. A systematic review and meta-analysis of trials for empagliflozin, canagliflozin, and dapagliflozin in patients with T2DM showed that the risk of dialysis, transplant, and death due to kidney disease was reduced by 33%, and risk of ESKD was reduced by 35% with SGLT2 inhibitors relative to placebo, with benefits observed across eGFR subgroups and albuminuria levels at baseline [32]. A similar analysis of cardiovascular outcomes trials in T2DM showed that use of SGLT2 inhibitors was associated with reductions in worsening eGFR, ESKD, or renal death risk of between 36% and 52% [33]. Similarly, an additional meta-analysis of six placebo-controlled trials of SGLT2 inhibitors, including five trials conducted in populations with T2DM, showed that SGLT2 inhibitors were associated with reduced risk of worsening kidney function, ESKD, or kidney death as well as reduced all-cause mortality, irrespective of metformin use [30].
Clinical trials and reviews building on them can establish the efficacy and safety of a novel therapy only over a limited time horizon. Long-term assessments of benefits and costs instead often rely on computer simulation models. Such modeling is challenging given the complexity of CKD and diabetes and the considerable number of risk factors and adverse clinical outcomes that could be considered in a model, subject to the availability of appropriate data.
Given the increasing need for modeling CKD in T2DM to inform clinical and economic decision-making around novel treatment options, the present study aimed to provide a comprehensive and current reference on modeling CKD in T2DM based on a systematic literature review of existing models. The work was motivated by a 2019 review [34] of CKD models in general, relative to which the present study provides an updated focus of CKD modeling specifically in T2DM and adds a review of modeling data sources, including their clinical and geographical representativeness.
Methods
A systematic literature review was conducted and reported in line with the Preferred Reporting Items for Systematic Reviews and Meta-Analyses 2020 (Table S1 in the Supplementary Material) [35]. The review protocol was not registered but is available from the corresponding author. This article is based on previously conducted studies and does not contain any new studies with human participants or animals performed by any of the authors.
Eligibility Criteria
The Population, Intervention, Comparator, Outcomes, Study Design approach was used to define study eligibility, albeit with no restrictions on interventions or comparators. Studies were eligible for inclusion if they were computer simulation models (study design) of kidney disease or kidney markers (outcomes) in patients with T2DM (population), regardless of the intervention and comparators used (Table S2 in the Supplementary Material).
In line with a 2008 definition by Stahl, a model was considered as a “simplified representation of reality that captures some of that reality’s essential properties and relationships” [36]. Specifically, computer simulation models of CKD were considered, including cohort state-transition models (cSTM)—or models that could be evaluated as such—and risk equation-based individual patient simulations (IPS), designed to project disease outcomes over time. Models were not required to report health economic outcomes, but studies that developed only risk predictions or nomograms were not eligible.
Studies were not eligible if they did not assess the progression of renal disease (but instead employed only a single renal-related state/event) or if they were cases using models already included in the review (published updates to existing models were considered to inform data extraction but were not counted as separate or new models). The latter criterion was used to avoid the inclusion of studies that used existing models such as the CORE Diabetes Model [37] to investigate a specific intervention in a particular setting, without making or reporting changes to the model.
Studies were also excluded if they provided no or insufficient detail on the renal model, e.g., if a model was only briefly described in a conference abstract (searches were conducted on the basis of model name, if any, as well as on first and last author names to identify if full publications were available and eligible for inclusion). As the focus of the review was on modeling CKD, not on the clinical efficacy of specific interventions, clinical studies were also not eligible.
Information Sources and Search Strategies
Searches were conducted in PubMed (including MEDLINE), Embase, and the Cochrane Library, using the respective search interfaces, on February 12, 2021, with incremental identical searches for newly added studies conducted on March 6 and October 8, 2021, as data extraction progressed on the models identified in the initial search.
Search strategies were adapted from those published by Sugrue et al. [34] by limiting the search to T2DM and by widening the focus from health economic models to modeling studies in general. Search strategies combined terms from the Medical Subject Heading and Emtree controlled vocabularies with free-text terms for renal complications, T2DM, and modeling studies. Initially developed for PubMed (Table S3 in the Supplementary Material), search strategies were subsequently mapped to Embase (Table S4 in the Supplementary Material) and the Cochrane Library (Table S5 in the Supplementary Material). Reference lists of eligible articles were also searched for relevant publications.
For searches in PubMed and the Cochrane Library, no limits were imposed on dates of coverage. For Embase, search results also available from MEDLINE were excluded to avoid duplicates, and abstracts identified in Embase were excluded if published before 2019 as it was assumed that a full peer-reviewed paper would have been published by the time of final search implementation in late 2021.
Study Selection and Data Collection
Results from literature searches were retrieved and stored using the literature review platform Sourcerer (Covalence Research Ltd, London, UK) [38]. After the removal of duplicate hits, the titles and abstracts of the remaining unique hits were screened against inclusion criteria by a single researcher. Subsequently, full texts of articles retained after title-abstract screening were screened, again by a single researcher, to determine final inclusion or exclusion. Ten percent of hits were screened by a second researcher, with any discrepancies resolved through consensus.
Data were extracted by a single researcher into a Google Sheets (Google LLC, Mountain View, CA, US) workbook. The extracted data included information on model design, structure, and setting, including, for example, year of publication, country setting, research goals, model type, and number of kidney disease-related states/events; risk equation parameters; data on possible transitions and transition probabilities in state-transition models; data sources used by models (where possible, by specific data point in the model); and baseline clinical and demographic characteristics of derivation cohorts in the primary clinical sources. A detailed list of variables is provided in Table S6 in the Supplementary Material. For models of both type 1 and 2 diabetes mellitus, data were extracted from the T2DM component of the model if sufficient detail was available.
The risk of bias within and across studies as well as the certainty and heterogeneity of results were not assessed as they were not considered relevant for the current review given the focus on model structures rather than outcomes. Similarly, specific model results, e.g., on the long-term benefits or economic characteristics of specific interventions, were not extracted.
Synthesis Methods
All statistical summaries were descriptive, including means, standard errors, and proportions to summarize model characteristics across the pool of models under consideration. All statistical analyses were based on complete cases, i.e., using all data available for a specific analysis. Data preparation and analyses [39,40,41,42,43] and plotting [44,45,46,47,48,49,50,51,52,53] were conducted using version 4.1.1 of the R statistical programming language [54, 55].
Models and primary sources were conceived of and plotted as a co-occurrence network [56,57,58]. Two simple measures of centrality were calculated to evaluate the importance of specific datasets to the CKD modeling in T2DM: degree centrality (the number of edges a node has) as a measure of “popularity”, and eigenvector centrality (accounting, for each node, for the centrality of the other nodes it is connected to) as a measure of “prestige” [59]. A core set of sources was identified by ranking sources on both measures of centrality; core sources were defined as any source ranked within the ten most central sources on at least one of the two centrality measures. For the analysis of model–data source relationships, only primary sources—sources that reported original data, such as clinical trials, observational studies, or CKD registers—were considered. If a source was a synthesis of previous sources, e.g., a meta-analysis, the underlying primary sources were identified and included.
For primary sources, the time “lag” between the source data cutoff and model publication was analyzed. The source data cutoff was established as follows: where reported, the end of the study or follow-up period was used. Otherwise, if the end of study or follow-up could be estimated from latest year of baseline enrolment and the reported follow-up time, this estimate was used. If the year so calculated was later than the year of publication or if no year could be calculated, the date of submission to the journal was used. If neither was reported, the year of publication was assigned.
For the analysis of baseline data from derivation cohorts, the publication with the largest sample size was chosen if more than one publication was available reporting on a single clinical data source; publications with smaller sample sizes were deemed more likely to be subgroup analyses. If a study reported baseline data separated across groups, e.g., by sex or by treatment arm, mean values weighted by the sample size in each group/arm were calculated. Biomarkers reported in different units, e.g., as mg/dL and mmol/L for lipids, were converted to a common unit for each biomarker (Table S7 in the Supplementary Material).
Baseline data were combined across studies using arithmetic means, weighted by the logarithm of sample sizes (except for ethnicity proportions, which were calculated from untransformed sample sizes). Values reported as medians were converted to arithmetic means using the Box–Cox method proposed by McGrath et al. [60], while values reported as geometric means were converted using the methods outlined by Higgins et al. [61].
Results
Study Selection and Characteristics
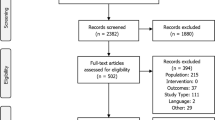
The literature and reference list searches identified 2995 records, of which 435 were duplicates (Fig. S1 in the Supplementary Material). Titles and abstracts of the remaining 2560 unique records were screened, leading to exclusion of 2478 records. Full texts of the remaining 82 studies were reviewed, leaving 49 computer simulation models of CKD in T2DM for inclusion in the review (Table 1 and Table S8 in the Supplementary Material).
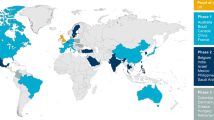
Of the 49 models, most had been developed for the USA (n = 14) or the UK (n = 6), nine had been developed for Asian countries (Japan, n = 3; Thailand, n = 3; China, n = 2; Taiwan, n = 1), and one for a Latin American country, Columbia (Fig. S2 in the Supplementary Material). Two models were developed explicitly for a multinational setting while six were not reported as being specific to any geographical setting. Twenty models had been developed for multiple use in different settings and for different research questions, while the others were tailored to a specific setting and research question. Most CKD models (n = 31) formed part of larger diabetes models, while the remainder were standalone models. Models had been published over a period of 25 years, from 1996 to 2021, and included 28 cSTM and 21 IPS models (Fig. S3 in the Supplementary Material).
Conceptualization of CKD in Computer Simulation Models of T2DM
State-Transition Models
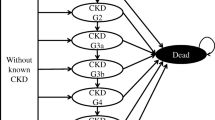
In state-transition models, a structure including five states—one kidney disease-free state, three states with kidney disease, and one death state—was the mostly frequently used, with 16 models adopting this structure from seminal models such as the Eastman et al. [92] and United Kingdom Prospective Diabetes Study (UKPDS) 64 models [103] (Fig. 1).

State-transition diagrams for CKD models in T2DM. CKD, chronic kidney disease; ESKD, end-stage kidney disease; T2DM, type 2 diabetes mellitus. States with borders do not allow loops (patients cannot remain state). Models marked with an asterisk allow regression of renal disease. Plots are ordered by (1) number of states, (2) mean transitions per state (not counting death states and loops), (3) model publication year, and (4) model name in alphabetical order
The description of the kidney disease-free state was most often described as normoalbuminuria, “free of renal disease”, or “free of nephropathy”, or as “complication-free diabetes” in larger diabetes models, which included a kidney disease model as a submodel. Some variation was observed in which kidney disease states were modeled. Dating back to the model developed by Eastman et al. [92] (Fig. S4 in the Supplementary Material), microalbuminuria, macroalbuminuria or proteinuria, and ESKD were considered by several models, including by Adarkwah et al. [62], Bagust et al. [76], Golan et al. [80], Wu et al. [110], and the MICADO model [90]. Other models followed the same structure but used different kidney disease states, including the PROSIT ShannonB model [96], which used micro- and macroalbuminuria and a “renal disease” state defined by plasma creatinine ≥ 175 μmol/L; and González et al. [81], which used two ESKD states distinguished by the type of RRT.
In contrast, models such as the UKPDS 64 nephropathy model [103] used the same number of similarly defined states but allowed more transitions, including from the kidney disease-free state directly to more advanced kidney disease states such as macroalbuminuria or elevated plasma creatinine (Fig. S5 in the Supplementary Material). This structure was also used by Palmer et al. [93] and in the Swedish Institute for Health Economics model [85]. An exceptional five-state structure of linear progression from normal renal function through microalbuminuria, clinical nephropathy, and ESKD to death from ESKD was used in the Centers for Disease Control and Prevention cost-effectiveness kidney disease submodel [68], which modeled other diabetes-related outcomes and non-ESKD-related death in its larger diabetes model.
While a five-state model structure was most common, models with as few as three states—modeling pre-ESKD and ESKD states in addition to death [82, 83]—and as many as eight states were identified. Models with more states either modeled CKD in greater detail, e.g., by distinguishing between early and advanced overt nephropathy and different types of RRT [95] or between detected and undetected kidney disease states [102], or by modeling individual CKD stages [12, 78], and/or modeled CKD sequelae such as CVD [65, 100].
Overall, 40 distinct kidney disease states were included by the 28 models, with only five states (microalbuminuria [n = 28], macroalbuminuria [n = 14], ESKD [n = 18], ESKD with transplant [n = 16], and ESKD with dialysis [n = 13]) used by more than ten models. Twenty-five states were used by only one model each, indicating some heterogeneity in how the CKD continuum was modeled in state-transition models.
The three models that explicitly modeled CKD sequelae as part of the CKD model all focused on CVD sequelae [65, 69, 100]. The models by Chen et al. [69] and Smith et al. [100] included a single CVD state, while the model by Campbell et al. [65] included, for each of its four kidney disease states, an additional state combining kidney disease with a CVD event (Fig. S6 in the Supplementary Material).
Regression of renal disease was included in five state-transition models (Fig. 1). The PROSIT ShannonB model [96] allowed regression from macroalbuminuria and microalbuminuria to microalbuminuria and normoalbuminuria, respectively, as did the model developed by Deerochanawong et al. [74] based on the DECLARE-TIME 58 trial for dapagliflozin [111]. The models by Smith et al. [100] and Srisubat et al. [101] allowed for regression from micro- to normoalbuminuria. In the model developed by Delea et al. [75] based on the AVOID Study [112], regression from early overt nephropathy to microalbuminuria and from advanced overt nephropathy to early overt nephropathy and microalbuminuria was modeled during the first 6-month cycle of each overt nephropathy state.
Risk Equations for Kidney Disease Outcomes in IPS Models
Across the 21 IPS models, 20 risk equations were used to predict seven types of kidney disease outcomes, most frequently ESKD/kidney failure (n = 11), albuminuria (n = 5), and eGFR (n = 2).
ESKD/kidney failure occurrence was predicted from 20 different risk factors, most frequently from blood pressure (n = 6), cholesterol, CVD, glycemia (measured using glycated hemoglobin [HbA1c]), and retinopathy (n = 4 each) and from sex (n = 5), age (n = 4), as well as ethnicity and smoking (n = 2) (Fig. S7 in the Supplementary Material). Albuminuria was predicted from 22 different risk factors, most frequently from glycemia (n = 6), blood pressure (n = 4), and cholesterol (n = 3), as well as from sex (n = 5), age (n = 3), and smoking (n = 3). Albuminuria was also predicted on the basis in part of treatment-related factors such as receiving antidiabetic or anticoagulant treatment or SGLT2 inhibitors, but each treatment-related factor was used in at most one risk equation.
Risk Equations Predicting CKD Sequelae in State-Transition and IPS Models
Twenty-two of the 49 models used kidney disease outcomes and markers to predict sequelae and mortality (Fig. S8 in the Supplementary Material). The outcomes most frequently predicted from kidney disease were mortality (n = 21 models), CVD (n = 11), and cerebrovascular disease (n = 6), while ESKD/renal failure (n = 19) and albumin, including albuminuria (n = 10), were the most frequent types of kidney disease outcomes used as predictors. eGFR was used as a predictor by only six models, for CVD (n = 5), mortality (n = 5), and cerebrovascular disease (n = 4).
Primary Data Sources for Modeling CKD in T2DM
Across the 49 models, 158 publications covering 112 primary data sources were identified, including 52 cohort studies, 30 randomized controlled trials (RCT), and 20 registry-based studies (Table S9 in the Supplementary Material). As for models, most primary data sources were from the USA (n = 31) and the UK (n = 11) or were multinational studies (n = 18) (Fig. S9 in the Supplementary Material). A single data source from an African country, Morocco, was identified, while five and seven studies were from China and Japan, respectively.
Network of Models and Primary Sources
The co-occurrence network of models and primary sources revealed a densely connected core of models and sources centered on the US Renal Data System (USRDS) and the UKPDS [113, 114] for clinical and mortality data, and, for clinical data only, the Wisconsin Epidemiological Study of Diabetic Retinopathy (WESDR) [115], and the Rochester Diabetes Project [116] as well as seminal RCTs in diabetic kidney disease including the Irbesartan Diabetic Nephropathy Trial (IDNT) [117], the Irbesartan in Type 2 Diabetes With Microalbuminuria 2 (IRMA-2) trial [118], and the RENAAL trial [119] (Fig. 2 and Fig. S10 in the Supplementary Material).

Model-source co-occurrence network for clinical effects. CKD, chronic kidney disease; ESKD, end-stage kidney disease; T2DM, type 2 diabetes mellitus. Node size is proportional to the indegree (normalized by the number of nodes in the network) so larger nodes indicate higher centrality. Sakthong et al.’s work [99] is classified as both a model and a primary data source as elicited data from experts for development of this model were subsequently used by other models
Both centrality indices ranked UKPDS and USRDS among the most central data sources to the kidney disease modeling literature in T2DM for clinical and mortality data, followed by Lewis et al. [120] for clinical data and the Steno-2 study [121] for mortality data (Fig. S11 in the Supplementary Material). Only 13 of the 49 models did not use either UKPDS or USRDS data.
There were five models [70, 72, 83, 88, 109] not connected to the main model-source network component for clinical data and four models [64, 87, 89, 110] that were only loosely connected (Fig. 2). This set of models included the state-transition models by Hayashino et al. [83], for Japan, and by Wu et al. [110], for China, which relied exclusively (in the case of Hayashino et al.) or almost exclusively (in the case of Wu et al.) on country- or Asian-specific data sources instead of sources from American or European countries. The remainder of this set of models included risk equation-based IPS models, which relied on at most two sources for their clinical effectiveness data, either from large clinical management systems (as in the CHIME model [70]) or from large clinical trials (e.g., ACCORD [122] in the BRAVO model [64]) or clinical outcomes trial such as CREDENCE [29] in CREDEM-DKD [72]. With the only exception of the model by Hayashino et al., all risk equation-based IPS models either not connected or loosely connected to the main model-source network had been published since 2018.
Primary Data Sources: Age, Duration of Follow-Up, and Sample Sizes
At the point of model publication, the newest data from the primary sources used in the model were, on average, 13.1 years old (standard deviation [SD] 6.7 years), with minimum and maximum ages ranging from 1.5 years [72] to 28 years [90] (Fig. S12 in the Supplementary Material). The mean calculated follow-up across primary sources was 10.3 years (SD 9.5 years), ranging from less than a year for some observational studies to more than 40 years [123,124,125].
Some of the most central sources identified above were among the older sources but also provided some of the longest follow-up, including the Rochester Diabetes Project, UKPDS, and WESDR studies (Fig. 3).

Age, length of follow-up, and sample size for primary data sources. Each row indicates, for a primary data source, the study start (bubble) and data cuts used in publications for this primary data source (crosses). The bubbles indicating sample sizes are scaled by the logarithm of the baseline sample size of the study. For source abbreviations and citations, see Table S9 in the Supplementary Material
There was also a broad trend towards larger sample sizes in more recent primary data sources. The largest sample sizes were from analyses of registry data, including more than 1.1 million adults from the Kaiser Permanente Renal Registry [126], used in the ECHO-T2DM model, and 228,552 adults from the USRDS [127], used in the Syreon Diabetes Control Model [102] and the CORE Diabetes Model [37], as well as the 57,594 patients from the Taiwanese Chronic Disease Management Registry [128], used for modeling by Wu et al. [110], and the 42,495 patients with T2DM from the Hong Kong Health Authority Clinical Management System used by the CHIME simulation model [70]. Other large primary data sources used for modeling were a screening study from Okinawa with 78,529 patients [129], used in the Howard et al. model [84], and large clinical outcomes trials such as DECLARE-TIMI 58 with 17,160 participants [111].
Baseline Characteristics of Derivation Cohorts
Baseline data were available for 1,853,362 participants from 97 primary data sources (Table 2). At baseline, the median age of participants was 58.9 years, while 53% of participants were men. White participants accounted for more than half (50.8%) of all participants, relative to Black and Asian participants, who accounted for 11.5% and 10.1% of all participants, respectively. Half of the participants had never smoked, while 23% were current and 27% were former smokers.
The median reported urinary albumin creatinine ratio was 139.2 mg/g, indicating moderately increased albuminuria (microalbuminuria) (Fig. S13 in the Supplementary Material), while the median eGFR was 84.9 mL/min/1.73 m2, indicating mildly decreased kidney function (Fig. 4) [12].

Estimated glomerular filtration rate at baseline across participants in primary derivation cohorts. Estimated glomerular filtration rate values were weighted by the logarithm of the study sample size (mapped to the size of grey bubbles for individual studies, with a total of 116,636 participants available for analysis) and then summarized. Shading refers to glomerular filtration categories as defined in the KDIGO 2012 Clinical Practice Guideline [12]
Median HbA1c was 8.3%, while median systolic and diastolic blood pressure were 135.6 and 79.7 mmHg, respectively (Table 2). The most common comorbidities, as reported in publications at baseline, were hypertension (66%), CVD (41%), and microalbuminuria (29%) (Fig. S14 in the Supplementary Material).
Discussion
To the existing clinical reviews investigating the renoprotective effects of specific compounds or drug classes [28, 30, 32, 33, 130, 131] the present review adds a comprehensive and current overview of computer simulation models of CKD in T2DM and of the data sources and derivation cohorts informing these models.
Regarding model structures and conceptualization of CKD progression, state-transition models of CKD in T2DM were found to frequently employ a five-state structure, for modeling progression from a kidney disease-free state through states with kidney disease to death. While there was some heterogeneity between models in which kidney disease states were chosen, CKD progression in T2DM was modeled almost exclusively on the basis of albuminuria; the one model to use eGFR-based CKD stages as states used a CKD model originally developed for a general, not necessarily diabetic, population [78, 132]. The reliance on albuminuria confirms the observation by Sugrue et al. [34] for a larger set of T2DM models. It is consistent with the classical understanding of kidney disease in diabetes as a sequence of albuminuria states leading to an eventual decline in eGFR and subsequent ESKD [14, 133,134,135].
The other biomarker to define CKD, eGFR, has only more recently been used in CKD models in T2DM. While widely used in general population CKD models that model declining kidney function based on CKD stages defined by eGFR [12, 34, 132], eGFR has only recently received increased attention in CKD models in T2DM as the understanding of eGFR trajectories and their link with albuminuria in patients with diabetes has improved. This understanding includes the non-linear and potentially non-progressive shape of eGFR trajectories, the link between speed of eGFR decline and clinical outcomes, and the possibility for both eGFR and albuminuria to worsen independently of each other [14,15,16,17,18,19,20,21, 136].
Regarding eGFR, renoprotective treatments including SGLT2 inhibitors and glucagon-like peptide 1 (GLP-1) receptor agonists were found to be associated with a transient dip in eGFR upon treatment initiation before eventually slowing eGFR decline [29, 31, 111, 137, 138]. This dip likely reflects intrarenal hemodynamic changes in microcirculation [31, 139] and has also been observed with renin–angiotensin–aldosterone system inhibition [140, 141]. The clinical importance of this transient eGFR dip is not fully understood, but current evidence suggests that it is unlikely to be associated with adverse clinical events [141,142,143].
While the clinical importance of this transient eGFR decline remains to be established and even though an acute phase dip may have little impact over a lifetime modeling horizon, modelers may still wish to allow for this dip when building a model. If models then also consider non-linear eGFR trajectories, their effect on clinical outcomes, and the possibility of CKD regression, modeling CKD in T2DM would quickly reach a complexity that favors risk equation-based IPS over state-transition models as the former can more easily account for non-linear relationships between patient characteristics and model outcomes as well as for heterogeneity between patients [144].
As complex models are not always feasible or preferable to build [145], there may be some interest in reducing complexity when modeling CKD in T2DM, e.g., if sufficient data on clinical outcomes are not available early in a trial or if the model is designed to facilitate communication with wider audiences. One approach adopted in the literature to reduce complexity is to focus on the CKD outcomes associated with the largest clinical—and economic—burden, usually ESKD [8]. Examples include prediction of ESKD from four readily available, not kidney-related clinical characteristics as in the BRAVO risk engine [64], or a simple linear projection of eGFR slopes using a threshold for dialysis initiation as assumed by Durkin and Blais [146]. The latter approach in particular is straightforward to implement and communicate and may suffice to provide an early approximation of intervention effects on the incidence of high-burden events such as ESKD. Alternatively, this could be achieved by developing simple cSTMs that focus on key CKD outcomes and in which robust data for these outcomes compensates for the lack of modeled clinical complexity.
In addition to model structures and CKD disease progression modeling, the review also investigated the data sources and derivation cohorts used by CKD models in T2DM, and potential concerns arising from these findings are discussed here. Several well-established data sources, such as the USRDS, UKPDS, and WESDR, contributed substantially to the clinical effects used in modeling CKD. However, many of these central data sources reported on predominantly White participants from high-income countries in North America and Europe, calling into question their suitability for modeling in underserved populations and in different country settings given differences in the epidemiology, treatment, and prognosis of diabetes and CKD.
In the USA, for example, racial and ethnic minorities are more likely to suffer from diabetes and prediabetes, at lower BMI, than Whites [147, 148]. Minorities were found to be at higher risk of diabetes-related mortality and adverse clinical events, including ESKD, relative to White people in multinational [149] and national studies [150, 151]. Race and ethnicity may also influence whether appropriate care is received for kidney disease; in the UK, for example, adjustment for ethnicity was found to overestimate GFR in self-reported Black participants, thereby potentially delaying the time to treatment initiation [152]. Although note that, in the USA, a National Kidney Foundation and American Society for Nephrology Task Force recently recommended that creatinine equations be refit without a variable for race and that research into GFR estimation aims to eliminate race and ethnic disparities [153]. For people of Asian ethnicity, kidney disease was shown to be a more likely consequence of T2DM than for European and US populations [154], while SGTL2 inhibitors, as an add-on to metformin, were shown to be more efficacious in East Asian patients relative to non-Asian patients with T2DM [155].
These epidemiological and physiological differences in populations with diabetes and/or CKD have led to calls for modeling that is more sensitive to these differences [156], which have recently been heeded as a number of models have been developed specifically for Asian settings using data not derived from US or European populations. In Fig. 2, they can be seen on the edge of (or entirely disconnected from) the model-source co-occurrence network, and include the CHIME model, based on data from Hong Kong [70], the JJCEM, based on data from Japan [87], the model by Watada et al. [109], based on Asian patients from the CARMELINA trial [157], and the models by Hayashino et al. [83] and Wu et al. [110].
Some established data sources may be questioned regarding not only their racial and ethnical representativeness but also their relevance for current clinical practice, as a result of their age. The UKPDS, for example, was initiated in 1977, while key trials such as IDNT, IRMA-2, and RENAAL were begun in the 1990s and completed by the early 2000s. Concerns about the age of the UKPDS data, for example, motivated the development of the BRAVO risk engine from ACCORD data [64]. These concerns may be less urgent than they may initially seem, however, as studies with long and comprehensive follow-up necessarily need to have started longer ago. Provided that the models based on these studies can discriminate well between patients and/or cohorts, there is nothing to preclude their use in modern patient populations, particularly after appropriate calibration [158]. This review also identified several models developed from clinical outcomes trials soon after trial completion, including the CREDEM-DKD model [72] and the models by Kansal et al. [88] and Watada et al. [109], which may represent a beginning trend to develop disease models quickly from outcomes trials. Such trials may provide not only recent but also comprehensive data on a wide range of biomarkers that would allow to build CKD and indeed full diabetes models from a single consistent data source. As findings from clinical trials may not readily be generalizable to non-trial populations, using only trial data to develop models could limit a model’s scope and usefulness although trials could be specifically designed to include participants from previously understudied populations [159].
The present review has some limitations. Searches in literature databases were limited to PubMed (including MEDLINE), Embase, and the Cochrane Library, which are recommended for consideration in systematic reviews but may have missed computer simulation models published in non-English language or non-indexed journals, possibly biasing the set of models available for inclusion [160]. The review also relied exclusively on published and publicly available information, meaning that models that are already fully operational but not (yet) described in a published paper or technical report and unpublished model updates were missed. A further limitation of the review was that 90% of titles and abstracts were screened and all full texts reviewed by a single researcher, potentially increasing the risk of inadvertently excluding relevant studies relative to two reviewers screening all studies independently.
Grouping models for analyses and synthesizing study results was also limited by inconsistent terminology and modeling approaches (which, as previously observed by Sugrue et al. [34], were rarely justified), and differences in the level of detail provided. A limitation in the assessment of baseline characteristics of derivation cohorts was that all primary data sources with baseline data available were treated equally (after weighting by sample size) so data from a source informing a single data point in a single model received the same weight as data from a source informing dozens of data points across several models. While also weighting by network centrality was considered, this would have required redrawing networks and recalculating indices for each outcome as not all outcomes were reported by all studies. Different summary measures would then have been based on different networks with limited comparability of either networks or summary measures. Data sources were therefore treated equally, and readers should bear this in mind when considering results for baseline characteristics.
Conclusion
As novel renoprotective treatments for CKD in patients with T2DM become available, the modeling of CKD progression in T2DM has become ever more important to inform clinical and economic decision-making. The accuracy of such modeling will likely increase through recent and future improvements in the understanding of CKD and T2DM and through larger and more robust data. As increasingly detailed data are gathered, modelers may consider developing complex models that allow one to track CKD progression and outcomes in increasing detail. Modelers should not lose sight, however, of using these data to populate or develop simpler models, e.g., those focusing on the clinically and economically most relevant endpoints, or to inform the link between surrogate endpoints and clinical outcomes [161]. Simpler models may not capture as many details but may still be sufficient to model outcomes reliably (in some cases even more accurately than complex models [145]), may be more familiar to clinical and health technology assessment audiences, and may be easier to communicate and interpret. The present review provides a comprehensive and contemporary overview of modeling approaches and data sources that modelers can use to explore different modeling options and to inform the development of any future models of CKD in patients with T2DM.
References
Bikbov B, Purcell CA, Levey AS, et al. Global, regional, and national burden of chronic kidney disease, 1990–2017: a systematic analysis for the Global Burden of Disease Study 2017. Lancet. 2020;395:709–33.
Foreman KJ, Marquez N, Dolgert A, et al. Forecasting life expectancy, years of life lost, and all-cause and cause-specific mortality for 250 causes of death: reference and alternative scenarios for 2016–40 for 195 countries and territories. Lancet. 2018;392:2052–90.
United States Renal Data System. 2019 USRDS Annual Data Report: epidemiology of kidney disease in the United States. Bethesda, MD: National Institutes of Health, National Institute of Diabetes and Digestive and Kidney Diseases; 2019. https://www.usrds.org/media/2371/2019-executive-summary.pdf. Accessed 13 Oct 2021.
Folkerts K, Petruski-Ivleva N, Kelly A, et al. Annual health care resource utilization and cost among type 2 diabetes patients with newly recognized chronic kidney disease within a large U.S. administrative claims database. J Manag Care Spec Pharm. 2020;26:1506–16.
Escobar C, Palacios B, Aranda U, et al. Costs and healthcare utilisation of patients with chronic kidney disease in Spain. BMC Health Serv Res. 2021;21:536.
Cabrera CS, Lee AS, Olsson M, et al. Impact of CKD progression on cardiovascular disease risk in a contemporary UK cohort of individuals with diabetes. Kidney Int Rep. 2020;5:1651–60.
Huang Y-J, Hsu Y-L, Chuang Y-H, Lin HY-H, Chen Y-H, Chan T-C. Association between renal function and cardiovascular mortality: a retrospective cohort study of elderly from health check-up. BMJ Open. 2021;11:e049307.
Darlington O, Dickerson C, Evans M, et al. Costs and healthcare resource use associated with risk of cardiovascular morbidity in patients with chronic kidney disease: evidence from a systematic literature review. Adv Ther. 2021;38:994–1010.
Gandjour A, Armsen W, Wehmeyer W, Multmeier J, Tschulena U. Costs of patients with chronic kidney disease in Germany. PLoS ONE. 2020;15:e0231375.
Ingrasciotta Y, Sultana J, Formica D, et al. Direct healthcare costs of chronic kidney disease management in Italy: what cost-savings can be achieved with higher biosimilar uptake and more appropriate use of erythropoiesis-stimulating agents? Pharmacoepidemiol Drug Saf. 2021;30:65–77.
Zhang H, Zhang C, Zhu S, Ye H, Zhang D. Direct medical costs of end-stage kidney disease and renal replacement therapy: a cohort study in Guangzhou City, southern China. BMC Health Serv Res. 2020;20:122.
National Kidney Foundation. KDIGO 2012 clinical practice guideline for the evaluation and management of chronic kidney disease. Kidney Int Suppl. 2013;3:91–111.
Murton M, Goff-Leggett D, Bobrowska A, et al. Burden of chronic kidney disease by KDIGO categories of glomerular filtration rate and albuminuria: a systematic review. Adv Ther. 2021;38:180–200.
Oshima M, Shimizu M, Yamanouchi M, et al. Trajectories of kidney function in diabetes: a clinicopathological update. Nat Rev Nephrol. 2021;17:740–50.
Vistisen D, Andersen GS, Hulman A, Persson F, Rossing P, Jørgensen ME. Progressive decline in estimated glomerular filtration rate in patients with diabetes after moderate loss in kidney function-even without albuminuria. Diabetes Care. 2019;42:1886–94.
Weldegiorgis M, de Zeeuw D, Li L, et al. Longitudinal estimated GFR trajectories in patients with and without type 2 diabetes and nephropathy. Am J Kidney Dis. 2018;71:91–101.
Jun M, Harris K, Heerspink HJL, et al. Variability in estimated glomerular filtration rate and the risk of major clinical outcomes in diabetes: post hoc analysis from the ADVANCE trial. Diabetes Obes Metab. 2021;23:1420–5.
Ali I, Chinnadurai R, Ibrahim ST, Kalra PA. Adverse outcomes associated with rapid linear and non-linear patterns of chronic kidney disease progression. BMC Nephrol. 2021;22:82.
Kovesdy CP, Naseer A, Sumida K, et al. Abrupt decline in kidney function precipitating initiation of chronic renal replacement therapy. Kidney Int Rep. 2018;3:602–9.
Liu P, Quinn RR, Lam NN, et al. Progression and regression of chronic kidney disease by age among adults in a population-based cohort in Alberta, Canada. JAMA Netw Open. 2021;4:e2112828.
Yang L, Chu TK, Lian J, et al. Individualised risk prediction model for new-onset, progression and regression of chronic kidney disease in a retrospective cohort of patients with type 2 diabetes under primary care in Hong Kong. BMJ Open. 2020;10:e035308.
Kalantar-Zadeh K, Jafar TH, Nitsch D, Neuen BL, Perkovic V. Chronic kidney disease. Lancet. 2021;398:786–802.
Afkarian M, Katz R, Bansal N, et al. Diabetes, kidney disease, and cardiovascular outcomes in the Jackson Heart Study. Clin J Am Soc Nephrol. 2016;11:1384–91.
Tuttle KR, Alicic RZ, Duru OK, et al. Clinical characteristics of and risk factors for chronic kidney disease among adults and children: an analysis of the CURE-CKD registry. JAMA Netw Open. 2019;2:e1918169.
Deng Y, Li N, Wu Y, et al. Global, regional, and national burden of diabetes-related chronic kidney disease from 1990 to 2019. Front Endocrinol. 2021;12:809.
Duan J, Wang C, Liu D, et al. Prevalence and risk factors of chronic kidney disease and diabetic kidney disease in Chinese rural residents: a cross-sectional survey. Sci Rep. 2019;9:10408.
Muskiet MHA, Wheeler DC, Heerspink HJL. New pharmacological strategies for protecting kidney function in type 2 diabetes. Lancet Diabetes Endocrinol. 2019;7:397–412.
Garcia Sanchez JJ, Thompson J, Scott DA, et al. Treatments for chronic kidney disease: a systematic literature review of randomized controlled trials. Adv Ther. 2022;39(1):193–220.
Perkovic V, Jardine MJ, Neal B, et al. Canagliflozin and renal outcomes in type 2 diabetes and nephropathy. N Engl J Med. 2019;380:2295–306.
Neuen BL, Arnott C, Perkovic V, et al. Sodium-glucose co-transporter-2 inhibitors with and without metformin: a meta-analysis of cardiovascular, kidney and mortality outcomes. Diabetes Obes Metab. 2021;23:382–90.
Cherney DZI, Heerspink HJL, Frederich R, et al. Effects of ertugliflozin on renal function over 104 weeks of treatment: a post hoc analysis of two randomised controlled trials. Diabetologia. 2020;63:1128–40.
Neuen BL, Young T, Heerspink HJL, et al. SGLT2 inhibitors for the prevention of kidney failure in patients with type 2 diabetes: a systematic review and meta-analysis. Lancet Diabetes Endocrinol. 2019;7(11):845–54.
Zelniker TA, Wiviott SD, Raz I, et al. Comparison of the effects of glucagon-like peptide receptor agonists and sodium-glucose cotransporter 2 inhibitors for prevention of major adverse cardiovascular and renal outcomes in type 2 diabetes mellitus. Circulation. 2019;139(17):2022–31.
Sugrue DM, Ward T, Rai S, McEwan P, van Haalen HGM. Economic modelling of chronic kidney disease: a systematic literature review to inform conceptual model design. Pharmacoeconomics. 2019;37:1451–68.
Page MJ, McKenzie JE, Bossuyt PM, et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. PLOS Med. 2021;18:e1003583.
Stahl JE. Modelling methods for pharmacoeconomics and health technology assessment: an overview and guide. Pharmacoeconomics. 2008;26:131–48.
Palmer AJ, Roze S, Valentine WJ, et al. The CORE Diabetes Model: projecting long-term clinical outcomes, costs and cost-effectiveness of interventions in diabetes mellitus (types 1 and 2) to support clinical and reimbursement decision-making. Curr Med Res Opin. 2004;20(Suppl 1):S5-26.
Covalence Research Ltd. Sourcerer.pro. 2021. https://sourcerer.pro. Accessed 10 Jan 2022.
Wickham H. ggplot2: elegant graphics for data analysis. Springer: New York; 2016. https://ggplot2.tidyverse.org.
Wickham H, Averick M, Bryan J, et al. Welcome to the Tidyverse. J Open Source Softw. 2019;4:1686.
Hester J. glue: interpreted string literals. 2020. https://CRAN.R-project.org/package=glue. Accessed 15 Oct 2021.
Bryan J, RStudio. googlesheets4: access Google Sheets using the Sheets API V4. 2021. https://CRAN.R-project.org/package=googlesheets4. Accessed 15 Oct 2021.
Pebesma E. Simple features for R: standardized support for spatial vector data. R J. 2018;10:439.
Iannone R, Cheng J, Schloerke B, RStudio. gt: easily create presentation-ready display tables. 2021. https://CRAN.R-project.org/package=gt. Accessed 15 Oct 2021.
Pedersen TL. Patchwork: the composer of plots. 2020. https://CRAN.R-project.org/package=patchwork. Accessed 9 Sep 2021.
Arnold JB, Daroczi G, Werth B, et al. ggthemes: extra themes, scales and geoms for “ggplot2”. 2021. https://CRAN.R-project.org/package=ggthemes. Accessed 15 Oct 2021.
Wilke CO. ggtext: improved text rendering support for “ggplot2”. 2020. https://CRAN.R-project.org/package=ggtext. Accessed 15 Oct 2021.
Brunson JC, Read QD. ggalluvial: alluvial plots in “ggplot2”. 2020. https://CRAN.R-project.org/package=ggalluvial. Accessed 15 Oct 2021.
Jeworutzki S, Giraud T, Lambert N, Bivand R, Pebesma E, Nowosad J. cartogram: create cartograms with R. 2020. https://CRAN.R-project.org/package=cartogram. Accessed 15 Oct 2021.
Zeileis A, Fisher JC, Hornik K, et al. colorspace: a toolbox for manipulating and assessing colors and palettes. J Stat Softw. 2020;96:1–49.
Zeileis A, Hornik K, Murrell P. Escaping RGBland: selecting colors for statistical graphics. Comput Stat Data Anal. 2009;53:3259–70.
Wickham H, Seidel D, RStudio. scales: scale functions for visualization. 2020. https://CRAN.R-project.org/package=scales. Accessed 15 Oct 2021.
South A. rnaturalearth: world map data from Natural Earth. 2017. https://CRAN.R-project.org/package=rnaturalearth. Accessed 15 Oct 2021.
R Core Team. R: a language and environment for statistical computing. Vienna, Austria: R Foundation for Statistical Computing; 2021. https://www.R-project.org/. Accessed 13 Oct 2021.
Pedersen TL, Shemanarev M, Juricic T, Marusinec M, Garret S, RStudio. ragg: graphic devices based on AGG. 2021. https://CRAN.R-project.org/package=ragg. Accessed 15 Oct 2021.
Pedersen TL. Tidygraph: a tidy API for graph manipulation. 2020. https://CRAN.R-project.org/package=tidygraph. Accessed 23 Sep 2021.
Pedersen TL, RStudio. ggraph: an implementation of grammar of graphics for graphs and networks. 2021. https://CRAN.R-project.org/package=ggraph. Accessed 23 Sep 2021.
Csardi G, Nepusz T. The igraph software package for complex network research. Int J. 2006;Complex Syst:1695.
Borgatti SP. Centrality and network flow. Soc Netw. 2005;27:55–71.
McGrath S, Zhao X, Steele R, Thombs BD, Benedetti A. Estimating the sample mean and standard deviation from commonly reported quantiles in meta-analysis. Stat Methods Med Res. 2020;29:2520–37.
Higgins JPT, White IR, Anzures-Cabrera J. Meta-analysis of skewed data: combining results reported on log-transformed or raw scales. Stat Med. 2008;27:6072–92.
Adarkwah CC, Gandjour A, Akkerman M, Evers SM. Cost-effectiveness of angiotensin-converting enzyme inhibitors for the prevention of diabetic nephropathy in the Netherlands: a Markov model. PLoS ONE. 2011;6:e26139.
Schlessinger L, Eddy DM. Archimedes: a new model for simulating health care systems-the mathematical formulation. J Biomed Inform. 2002;35:37–50.
Shao H, Fonseca V, Stoecker C, Liu S, Shi L. Novel risk engine for diabetes progression and mortality in USA: Building, Relating, Assessing, and Validating Outcomes (BRAVO). Pharmacoeconomics. 2018;36:1125–34.
Campbell HM, Boardman KD, Dodd MA, Raisch DW. Pharmacoeconomic analysis of angiotensin-converting enzyme inhibitors in type 2 diabetes: a Markov model. Ann Pharmacother. 2007;41:1101–10.
McEwan P, Peters JR, Bergenheim K, Currie CJ. Evaluation of the costs and outcomes from changes in risk factors in type 2 diabetes using the Cardiff stochastic simulation cost-utility model (DiabForecaster). Curr Med Res Opin. 2006;22:121–9.
Caro JJ, Klittich WS, Raggio G, et al. Economic assessment of troglitazone as an adjunct to sulfonylurea therapy in the treatment of type 2 diabetes. Clin Ther. 2000;22:116–27.
CDC Diabetes Cost-effectiveness Group. Cost-effectiveness of intensive glycemic control, intensified hypertension control, and serum cholesterol level reduction for type 2 diabetes. JAMA. 2002;287:2542–51.
Chen THH, Yen MF, Tung TH. A computer simulation model for cost–effectiveness analysis of mass screening for type 2 diabetes mellitus. Diabetes Res Clin Pract. 2001;54:37–42.
Quan J, Ng CS, Kwok HHY, et al. Development and validation of the CHIME simulation model to assess lifetime health outcomes of prediabetes and type 2 diabetes in Chinese populations: a modeling study. PLOS Med. 2021;18:e1003692.
Coyle D, Palmer AJ, Tam R. Economic evaluation of pioglitazone hydrochloride in the management of type 2 diabetes mellitus in Canada. Pharmacoeconomics. 2002;20(Suppl 1):31–42.
Willis M, Asseburg C, Slee A, Nilsson A, Neslusan C. Development and internal validation of a discrete event simulation model of diabetic kidney disease using CREDENCE trial data. Diabetes Ther. 2020;11:2657–76.
Critselis E, Vlahou A, Stel VS, Morton RL. Cost-effectiveness of screening type 2 diabetes patients for chronic kidney disease progression with the CKD273 urinary peptide classifier as compared to urinary albumin excretion. Nephrol Dial Transpl. 2018;33:441–9.
Deerochanawong C, Vareesangthip K, Piyayotai D, Thongsuk D, Pojchaijongdee N, Permsuwan U. Cost-utility analysis of dapagliflozin as an add-on to standard treatment for patients with type 2 diabetes and high risk of cardiovascular disease in Thailand. Diabetes Ther. 2021;12:1947–63.
Delea TE, Sofrygin O, Palmer JL, et al. Cost-effectiveness of aliskiren in type 2 diabetes, hypertension, and albuminuria. J Am Soc Nephrol. 2009;20:2205–13.
Bagust A, Hopkinson PK, Maier W, Currie CJ. An economic model of the long-term health care burden of type II diabetes. Diabetologia. 2001;44:2140–55.
Mueller E, Maxion-Bergemann S, Gultyaev D, et al. Development and validation of the economic assessment of glycemic control and long-term effects of diabetes (EAGLE) model. Diabetes Technol Ther. 2006;8:219–36.
Willis M, Johansen P, Nilsson A, Asseburg C. Validation of the economic and health outcomes model of type 2 diabetes mellitus (ECHO-T2DM). Pharmacoeconomics. 2017;35:375–96.
Brown JB, Russell A, Chan W, Pedula K, Aickin M. The global diabetes model: user friendly version 3.0. Diabetes Res Clin Pract. 2000;50:S15–46.
Golan L, Birkmeyer JD, Welch HG. The cost-effectiveness of treating all patients with type 2 diabetes with angiotensin-converting enzyme inhibitors. Ann Intern Med. 1999;131:660–7.
González JC, Walker JH, Einarson TR. Cost-of-illness study of type 2 diabetes mellitus in Colombia. Rev Panam Salud Publica. 2009;26:55–63.
Guinan K, Beauchemin C, Tremblay J, et al. Economic evaluation of a new polygenic risk score to predict nephropathy in adult patients with type 2 diabetes. Can J Diabetes. 2021;45:129–36.
Hayashino Y, Fukuhara S, Akizawa T, et al. Cost-effectiveness of administering oral adsorbent AST-120 to patients with diabetes and advance-stage chronic kidney disease. Diabetes Res Clin Pract. 2010;90:154–9.
Howard K, White S, Salkeld G, et al. Cost-effectiveness of screening and optimal management for diabetes, hypertension, and chronic kidney disease: a modeled analysis. Value Health. 2010;13:196–208.
Steen Carlsson K, Persson U. Cost-effectiveness of add-on treatments to metformin in a Swedish setting: liraglutide vs sulphonylurea or sitagplitin. J Med Econ. 2014;17:658–69.
Gozzoli V, Palmer AJ, Brandt A, Spinas GA. Economic and clinical impact of alternative disease management strategies for secondary prevention in type 2 diabetes in the Swiss setting. Swiss Med Wkly. 2001;131:303–10.
Tanaka S, Langer J, Morton T, et al. Developing a health economic model for Asians with type 2 diabetes based on the Japan Diabetes Complications Study and the Japanese Elderly Diabetes Intervention Trial. BMJ Open Diabetes Res Care. 2021;9:e002177.
Kansal A, Reifsnider OS, Proskorovsky I, et al. Cost-effectiveness analysis of empagliflozin treatment in people with type 2 diabetes and established cardiovascular disease in the EMPA-REG OUTCOME trial. Diabet Med. 2019;36:1494–502.
Kazemian P, Wexler DJ, Fields NF, Parker RA, Zheng A, Walensky RP. Development and validation of PREDICT-DM: a new microsimulation model to project and evaluate complications and treatments of type 2 diabetes mellitus. Diabetes Technol Ther. 2019;21:344–55.
van der Heijden AAWA, Feenstra TL, Hoogenveen RT, et al. Policy evaluation in diabetes prevention and treatment using a population-based macro simulation model: the MICADO model. Diabet Med. 2015;32:1580–7.
Zhou H, Isaman DJM, Messinger S, et al. A computer simulation model of diabetes progression, quality of life, and cost. Diabetes Care. 2005;28:2856–63.
Eastman RC, Javitt JC, Herman WH, et al. Model of complications of NIDDM. I. Model construction and assumptions. Diabetes Care. 1997;20:725–34.
Palmer AJ, Annemans L, Roze S, Lamotte M, Rodby RA, Cordonnier DJ. An economic evaluation of irbesartan in the treatment of patients with type 2 diabetes, hypertension and nephropathy: cost-effectiveness of Irbesartan in Diabetic Nephropathy Trial (IDNT) in the Belgian and French settings. Nephrol Dial Transpl. 2003;18:2059–66.
Palmer AJ, Annemans L, Roze S, et al. Cost-effectiveness of early irbesartan treatment versus control (standard antihypertensive medications excluding ACE inhibitors, other angiotensin-2 receptor antagonists, and dihydropyridine calcium channel blockers) or late irbesartan treatment in patients with type 2 diabetes, hypertension, and renal disease. Diabetes Care. 2004;27:1897–903.
Palmer AJ, Chen R, Valentine WJ, et al. Cost-consequence analysis in a French setting of screening and optimal treatment of nephropathy in hypertensive patients with type 2 diabetes. Diabetes Metab. 2006;32:69–76.
Schramm W, Sailer F, Pobiruchin M, Weiss C. PROSIT Open Source Disease Models for diabetes mellitus. Stud Health Technol Inform. 2016;226:115–8.
Rodby RA, Firth LM, Lewis EJ. An economic analysis of captopril in the treatment of diabetic nephropathy. Diabetes Care. 1996;19:1051–61.
Rodby RA, Chiou CF, Borenstein J, et al. The cost-effectiveness of irbesartan in the treatment of hypertensive patients with type 2 diabetic nephropathy. Clin Ther. 2003;25:2102–19.
Sakthong P, Tangphao O, Eiam-Ong S, et al. Cost-effectiveness of using angiotensin-converting enzyme inhibitors to slow nephropathy in normotensive patients with diabetes type II and microalbuminuria. Nephrology. 2001;6:71–7.
Smith DG, Nguyen AB, Peak CN, Frech FH. Markov modeling analysis of health and economic outcomes of therapy with valsartan versus amlodipine in patients with type 2 diabetes and microalbuminuria. J Manag Care Pharm. 2004;10:26–32.
Srisubat A, Sriratanaban J, Ngamkiatphaisan S, Tungsanga K. Cost-effectiveness of annual microalbuminuria screening in Thai diabetics. Asian Biomed. 2014;8:371–9.
Nagy B, Zsólyom A, Nagyjánosi L, et al. Cost-effectiveness of a risk-based secondary screening programme of type 2 diabetes. Diabetes Metab Res Rev. 2016;32:710–29.
Adler AI, Stevens RJ, Manley SE, et al. Development and progression of nephropathy in type 2 diabetes: the United Kingdom Prospective Diabetes Study (UKPDS 64). Kidney Int. 2003;63:225–32.
Clarke PM, Gray AM, Briggs A, et al. A model to estimate the lifetime health outcomes of patients with type 2 diabetes: the United Kingdom Prospective Diabetes Study (UKPDS) Outcomes Model (UKPDS no. 68). Diabetologia. 2004;47:1747–59.
Hayes AJ, Leal J, Gray AM, Holman RR, Clarke PM. UKPDS Outcomes Model 2: a new version of a model to simulate lifetime health outcomes of patients with type 2 diabetes mellitus using data from the 30 year United Kingdom Prospective Diabetes Study: UKPDS 82. Diabetologia. 2013;56:1925–33.
Leal J, Alva M, Gregory V, et al. Estimating risk factor progression equations for the UKPDS Outcomes Model 2 (UKPDS 90). Diabet Med. 2021;38:e14656.
van Os N, Niessen LW, Bilo HJ, Casparie AF, van Hout BA. Diabetes nephropathy in the Netherlands: a cost effectiveness analysis of national clinical guidelines. Health Policy. 2000;51:135–47.
Vijan S, Hofer TP, Hayward RA. Estimated benefits of glycemic control in microvascular complications in type 2 diabetes. Ann Intern Med. 1997;127:788–95.
Watada H, Sakamaki H, Yabe D, et al. Cost-effectiveness analysis of linagliptin in Japan based on results from the Asian subpopulation in the CARMELINA® trial. Diabetes Ther. 2020;11:1721–34.
Wu B, Zhang S, Lin H, Mou S. Prevention of renal failure in Chinese patients with newly diagnosed type 2 diabetes: a cost-effectiveness analysis. J Diabetes Invest. 2018;9:152–61.
Mosenzon O, Wiviott SD, Cahn A, et al. Effects of dapagliflozin on development and progression of kidney disease in patients with type 2 diabetes: an analysis from the DECLARE-TIMI 58 randomised trial. Lancet Diabetes Endocrinol. 2019;7:606–17.
Parving H-H, Persson F, Lewis JB, Lewis EJ, Hollenberg NK, AVOID Study Investigators. Aliskiren combined with losartan in type 2 diabetes and nephropathy. N Engl J Med. 2008;358:2433–46.
UK Prospective Diabetes Study Group. Intensive blood-glucose control with sulphonylureas or insulin compared with conventional treatment and risk of complications in patients with type 2 diabetes (UKPDS 33). Lancet. 1998;352:837–53.
UK Prospective Diabetes Study Group. Effect of intensive blood-glucose control with metformin on complications in overweight patients with type 2 diabetes (UKPDS 34). Lancet. 1998;352:854–65.
Klein R, Klein BE, Moss SE, Davis MD, DeMets DL. The Wisconsin Epidemiologic Study of Diabetic Retinopathy. II. Prevalence and risk of diabetic retinopathy when age at diagnosis is less than 30 years. Arch Ophthalmol. 1984;102:520–6.
Humphrey LL, Ballard DJ, Frohnert PP, Chu CP, O’Fallon WM, Palumbo PJ. Chronic renal failure in non-insulin-dependent diabetes mellitus: a population-based study in Rochester. Minnesota Ann Intern Med. 1989;111:788–96.
Lewis EJ, Hunsicker LG, Clarke WR, et al. Renoprotective effect of the angiotensin-receptor antagonist irbesartan in patients with nephropathy due to type 2 diabetes. N Engl J Med. 2001;345:851–60.
Parving HH, Lehnert H, Bröchner-Mortensen J, Gomis R, Andersen S, Arner P. The effect of irbesartan on the development of diabetic nephropathy in patients with type 2 diabetes. N Engl J Med. 2001;345:870–8.
Brenner BM, Cooper ME, de Zeeuw D, et al. Effects of losartan on renal and cardiovascular outcomes in patients with type 2 diabetes and nephropathy. N Engl J Med. 2001;345:861–9.
Lewis EJ, Hunsicker LG, Bain RP, Rohde RD. The effect of angiotensin-converting-enzyme inhibition on diabetic nephropathy. N Engl J Med. 1993;329:1456–62.
Gaede P, Vedel P, Parving HH, Pedersen O. Intensified multifactorial intervention in patients with type 2 diabetes mellitus and microalbuminuria: the Steno type 2 randomised study. Lancet. 1999;353:617–22.
ACCORD Study Group, Gerstein HC, Miller ME, et al. Effects of intensive glucose lowering in type 2 diabetes. N Engl J Med. 2008;358:2545–59.
Leibson CL, O’Brien PC, Atkinson E, Palumbo PJ, Melton LJ. Relative contributions of incidence and survival to increasing prevalence of adult-onset diabetes mellitus: a population-based study. Am J Epidemiol. 1997;146:12–22.
Borch-Johnsen K, Kreiner S. Proteinuria: value as predictor of cardiovascular mortality in insulin dependent diabetes mellitus. BMJ. 1987;294:1651–4.
Krolewski AS, Warram JH, Christlieb AR, Busick EJ, Kahn CR. The changing natural history of nephropathy in type I diabetes. Am J Med. 1985;78:785–94.
Go AS, Chertow GM, Fan D, McCulloch CE, Hsu C. Chronic kidney disease and the risks of death, cardiovascular events, and hospitalization. N Engl J Med. 2004;351:1296–305.
Wolfe RA, Ashby VB, Milford EL, et al. Comparison of mortality in all patients on dialysis, patients on dialysis awaiting transplantation, and recipients of a first cadaveric transplant. N Engl J Med. 1999;341:1725–30.
Loh PT, Toh MPHS, Molina JA, Vathsala A. Ethnic disparity in prevalence of diabetic kidney disease in an Asian primary healthcare cluster. Nephrology. 2015;20:216–23.
Iseki K, Ikemiya Y, Kinjo K, Iseki C, Takishita S. Prevalence of high fasting plasma glucose and risk of developing end-stage renal disease in screened subjects in Okinawa. Japan Clin Exp Nephrol. 2004;8:250–6.
Kelly MS, Lewis J, Huntsberry AM, Dea L, Portillo I. Efficacy and renal outcomes of SGLT2 inhibitors in patients with type 2 diabetes and chronic kidney disease. Postgrad Med. 2019;131(1):31–42.
Lo KB, Gul F, Ram P, et al. The effects of SGLT2 inhibitors on cardiovascular and renal outcomes in diabetic patients: a systematic review and meta-analysis. Cardiorenal Med. 2020;10(1):1–10.
Hoerger TJ, Wittenborn JS, Segel JE, et al. A health policy model of CKD: 1. Model construction, assumptions, and validation of health consequences. Am J Kidney Dis. 2010;55:452–62.
Mogensen CE, Christensen CK, Vittinghus E. The stages in diabetic renal disease. With emphasis on the stage of incipient diabetic nephropathy. Diabetes. 1983;32(Suppl 2):64–78.
Porrini E, Ruggenenti P, Mogensen CE, et al. Non-proteinuric pathways in loss of renal function in patients with type 2 diabetes. Lancet Diabetes Endocrinol. 2015;3:382–91.
MacIsaac RJ, Ekinci EI. Progression of diabetic kidney disease in the absence of albuminuria. Diabetes Care. 2019;42:1842–4.
Li L, Astor BC, Lewis J, et al. Longitudinal progression trajectory of GFR among patients with CKD. Am J Kidney Dis. 2012;59:504–12.
Mann JFE, Hansen T, Idorn T, et al. Effects of once-weekly subcutaneous semaglutide on kidney function and safety in patients with type 2 diabetes: a post-hoc analysis of the SUSTAIN 1–7 randomised controlled trials. Lancet Diabetes Endocrinol. 2020;8:880–93.
Wanner C, Inzucchi SE, Lachin JM, et al. Empagliflozin and progression of kidney disease in type 2 diabetes. N Engl J Med. 2016;375:323–34.
Škrtić M, Cherney DZI. Sodium-glucose cotransporter-2 inhibition and the potential for renal protection in diabetic nephropathy. Curr Opin Nephrol Hypertens. 2015;24:96–103.
Collard D, Brouwer TF, Olde Engberink RHG, Zwinderman AH, Vogt L, van den Born B-JH. Initial estimated glomerular filtration rate decline and long-term renal function during intensive antihypertensive therapy: a post hoc analysis of the SPRINT and ACCORD-BP randomized controlled trials. Hypertension. 2020;75:1205–12.
Chen DC, McCallum W, Sarnak MJ, Ku E. Intensive BP control and eGFR declines: are these events due to hemodynamic effects and are changes reversible? Curr Cardiol Rep. 2020;22:117.
Beddhu S, Shen J, Cheung AK, et al. Implications of early decline in eGFR due to intensive BP control for cardiovascular outcomes in SPRINT. J Am Soc Nephrol. 2019;30:1523–33.
Clase CM, Barzilay J, Gao P, et al. Acute change in glomerular filtration rate with inhibition of the renin-angiotensin system does not predict subsequent renal and cardiovascular outcomes. Kidney Int. 2017;91:683–90.
Davis S, Stevenson M, Tappenden P, Wailoo A. NICE DSU technical support document 15: cost-effectiveness modelling using patient-level simulation. Sheffield: Decision Support Unit, ScHARR, University of Sheffield; 2014. p. 62. http://nicedsu.org.uk/wp-content/uploads/2016/03/TSD15_Patient-level_simulation.pdf. Accessed 17 Oct 2021.
Katsikopoulos KV, Şimşek Ö, Buckmann M, Gigerenzer G. Transparent modeling of influenza incidence: big data or a single data point from psychological theory? Int J Forecast. 2021. https://doi.org/10.1016/j.ijforecast.2020.12.006.
Durkin M, Blais J. Linear projection of estimated glomerular filtration rate decline with canagliflozin and implications for dialysis utilization and cost in diabetic nephropathy. Diabetes Ther. 2021;12:499–508.
Zhu Y, Sidell MA, Arterburn D, et al. Racial/ethnic disparities in the prevalence of diabetes and prediabetes by BMI: Patient Outcomes Research To Advance Learning (PORTAL) multisite cohort of adults in the U.S. Diabetes Care. 2019;42:2211–2219.
Cheng YJ, Kanaya AM, Araneta MRG, et al. Prevalence of diabetes by race and ethnicity in the United States, 2011–2016. JAMA. 2019;322:2389–98.
Ezzatvar Y, Ramírez-Vélez R, Izquierdo M, García-Hermoso A. Racial differences in all-cause mortality and future complications among people with diabetes: a systematic review and meta-analysis of data from more than 2.4 million individuals. Diabetologia. 2021;64:2389–2401.
Yu D, Zhao Z, Osuagwu UL, et al. Ethnic differences in mortality and hospital admission rates between Māori, Pacific, and European New Zealanders with type 2 diabetes between 1994 and 2018: a retrospective, population-based, longitudinal cohort study. Lancet Global Health. 2021;9:e209–17.
Patzer RE, McClellan WM. Influence of race, ethnicity and socioeconomic status on kidney disease. Nat Rev Nephrol. 2012;8:533–41.
Gama RM, Clery A, Griffiths K, et al. Estimated glomerular filtration rate equations in people of self-reported black ethnicity in the United Kingdom: inappropriate adjustment for ethnicity may lead to reduced access to care. PLoS ONE. 2021;16:e0255869.
Delgado C, Baweja M, Crews DC, et al. A unifying approach for GFR estimation: recommendations of the NKF-ASN Task Force on reassessing the inclusion of race in diagnosing kidney disease. Am J Kidney Dis. 2022;79(2):268–288.e1.
Ma RCW, Chan JCN. Type 2 diabetes in East Asians: similarities and differences with populations in Europe and the United States. Ann N Y Acad Sci. 2013;1281:64–91.
Li X, Zhang Q, Zhou X, et al. The different hypoglycemic effects between East Asian and non-Asian type 2 diabetes patients when treated with SGLT-2 inhibitors as an add-on treatment for metformin: a systematic review and meta-analysis of randomized controlled trials. Aging. 2021;13:12748–65.
Dadwani RS, Laiteerapong N. Economic simulation modeling in type 2 diabetes. Curr Diab Rep. 2020;20:24.
Inagaki N, Yang W, Watada H, et al. Linagliptin and cardiorenal outcomes in Asians with type 2 diabetes mellitus and established cardiovascular and/or kidney disease: subgroup analysis of the randomized CARMELINA® trial. Diabetol Int. 2020;11:129–41.
Vanni T, Karnon J, Madan J, et al. Calibrating models in economic evaluation: a seven-step approach. Pharmacoeconomics. 2011;29:35–49.
Woodcock J, Araojo R, Thompson T, Puckrein GA. Integrating research into community practice — toward increased diversity in clinical trials. N Engl J Med. 2021;385:1351–3.
Cohen JF, Korevaar DA, Wang J, Spijker R, Bossuyt PM. Should we search Chinese biomedical databases when performing systematic reviews? Syst Rev. 2015;4:23.
Levey AS, Gansevoort RT, Coresh J, et al. Change in albuminuria and GFR as end points for clinical trials in early stages of CKD: a scientific workshop sponsored by the National Kidney Foundation in collaboration with the US Food and Drug Administration and European Medicines Agency. Am J Kidney Dis. 2020;75:84–104.
Acknowledgements
Funding
Sponsorship for this study and the journal’s Rapid Service Fee were funded by AstraZeneca.
Authorship
All named authors meet the International Committee of Medical Journal Editors (ICMJE) criteria for authorship for this article, take responsibility for the integrity of the work as a whole, and have given their approval for this version to be published.
Author Contributions
JP, KB, and RFP contributed to the study conception and design. Material preparation, data collection and data analyses were performed by JP and RFP. The first draft of the manuscript was written by JP and RFP. All authors commented on the previous versions of the manuscript. All authors read and approved the final manuscript.
Prior Presentation
This manuscript is based on work that has been previously presented as posters POSB312, POSB313, and POSC306 at Virtual ISPOR Europe 2021 (November 30 to December 3, 2021).
Disclosures
Johannes Pöhlmann and Richard F. Pollock are employees of Covalence Research Ltd., which received consulting fees from AstraZeneca UK Ltd. for the implementation of the literature review and preparation of the manuscript as well as consulting fees for projects outside the submitted work. Andrew Briggs received consulting fees from AstraZeneca for the present work and for work outside the submitted work. Klas Bergenheim, Juan Jose Garcia Sanchez, and Naveen Rao are employees of and Klas Bergenheim owns stock in AstraZeneca.
Compliance with Ethics Guidelines
This article is based on previously conducted studies and does not contain any new studies with human participants or animals performed by any of the authors.
Data Availability
All data generated or analyzed during this study are included in this published article and the supplementary information files.
Author information
Authors and Affiliations
Corresponding author
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution-NonCommercial 4.0 International License, which permits any non-commercial use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by-nc/4.0/.
About this article

Cite this article
Pöhlmann, J., Bergenheim, K., Garcia Sanchez, JJ. et al. Modeling Chronic Kidney Disease in Type 2 Diabetes Mellitus: A Systematic Literature Review of Models, Data Sources, and Derivation Cohorts. Diabetes Ther 13, 651–677 (2022). https://doi.org/10.1007/s13300-022-01208-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13300-022-01208-0