
Abstract
We analyse the Publication and Research data set of University of Bristol collected between 2008 and 2013. Using the existing co-authorship network and academic information thereof, we propose a new link prediction methodology, with the specific aim of identifying potential interdisciplinary collaboration in a university-wide collaboration network.
Similar content being viewed by others

1 Introduction
Interdisciplinarity has come to be celebrated in recent years with many arguments made in support of interdisciplinary research. Rylance (2015) noted that:
-
complex modern problems, such as climate change and resource security, require many types of expertise across multiple disciplines;
-
scientific discoveries are more likely to be made on the boundaries between fields, with the influence of big data science on many disciplines as an example; and
-
encounters with others fields benefit single disciplines and broaden their horizons.
In 2015, UK higher education funding bodies and Medical Research Council commissioned a quantitative review of interdisciplinary research (Elsevier 2015), as part of the effort to assess the quality of research produced by UK higher education institutions and design the UK’s future research policy and funding allocations. Around the same time, Nature published a special issue (Nature 2015), reflecting the increasing trend of interdisciplinarity. One such example is observed in publication data, where more than one-third of the references in scientific papers point to other disciplines, also, an increasing number of research centres and institutes established globally, bringing together members of different fields, in order to tackle scientific and societal questions that go beyond the boundary of a single discipline (Ledford 2015).
As a way of promoting interdisciplinary research, Brown et al. (2015) suggested ‘the institutions to identify research strengths that show potential for interdisciplinary collaboration and incentivise it through seed grants’. Faced with the problem of utilising limited resources, decision makers in academic organisations may focus on promoting existing collaborations between different disciplines. However, it could also be of interest to identify the disciplines that have not yet collaborated to this date but have the potential to develop and benefit from collaborative research given the nurturing environment.
Thus motivated, the current paper has a twofold goal: from the perspective of methodological development, we introduce new methods for predicting edges in a network; from the policy making perspective, we provide decision makers a systematic way of introducing or evaluating calls for interdisciplinary research, based on the potential for interdisciplinary collaboration detected from the existing co-authorship network. In doing so, we analyse the University of Bristol’s research output data set, which contains the co-authorship network among the academic staff and information on their academic membership, including the (main) disciplines where their research lies in.
Link prediction is a fundamental problem in network statistics. Besides the applications to co-authorship networks, link prediction problems are of increasing interests for friendship recommendation in social networks (e.g. Liben-Nowell and Kleinberg 2007), exploring collaboration in academic contexts (e.g. Kuzmin et al. 2016; Wang and Sukthankar 2013), discovering unobserved relationships in food webs (e.g. Wang et al. 2014), understanding the protein–protein interactions (e.g. Martńez et al. 2014) and gene regulatory networks (e.g. Turki and Wang 2015), to name but a few. Due to the popularity of link prediction in a wide range of applications, many efforts have been made in developing statistical methods for link prediction problems. Liben-Nowell and Kleinberg (2007), Lü and Zhou (2011) and Martínez et al. (2016), among others, are some recent survey papers on this topic. The methods developed can be roughly categorised into model-free and model-based methods.
Among the model-free methods, some are based on information from neighbours (e.g. Liben-Nowell and Kleinberg 2007; Adamic and Adar 2003; Zhou et al. 2009) to form similarity measures and predict linkage; some are based on geodesic path information (e.g. Katz 1953; Leicht et al. 2006); some use the spectral properties of adjacency matrices (e.g. Fouss et al. 2007). Among the model-based methods, some exploit random walks on the graphs to predict future linkage (e.g. Page et al. 1999; Jeh and Widom 2002; Liu and Lü 2010); some predict links based on probabilistic models (e.g. Geyer 1992); some estimate the network structure via maximum likelihood estimation (e.g. Guimerá and Sales-Pardo 2009); others utilise the community detection methods (e.g. Clauset et al. 2008).
The link prediction problem in this paper shares similarity with the above-mentioned ones. However, we also note on the fundamental difference that we collect the data at the level of individual researchers for the large-size network thereof, but the conclusion we seek is for the small-size network with nodes representing the individuals’ academic disciplines, which are given in the data set. Nodes of the small-size network are different from communities: memberships to the communities are typically unknown and the detection of community structure is often itself of separate interest, whereas academic affiliations, which we use as a proxy for academic disciplines, are easily accessible and treated as known in our study.
The rest of the paper is organised as follows. Section 2 provides a detailed description of the Publication and Research data set collected at the University of Bristol, as well as the networks arising from the data. In Sect. 3, we propose a link prediction algorithm, compare its performance in combination with varying similarity measures for predicting the potential interdisciplinary research links via thorough study of the co-authorship network, and demonstrate the good performance of our proposed method. Section 4 concludes the paper. Appendix provides additional information about the data set.
2 Data description and experiment setup
2.1 Data set
Publication and Research (PURE) is an online system provided by a Danish company Atira. It collects, organises and integrates data about research activity and performance. Adopting the PURE data set of research outputs collected between 2008 and 2013 from the University of Bristol (simply referred to as the ‘University’), we focus on journal outputs made by academic staff. Each of research outputs and members of academic staff has a unique ID. The data set also includes the following information:
-
Outputs’ titles and publication dates;
-
Authors’ publication names, job titles, affiliations within the University;
-
University organisation structures: there are 6 Faculties, and each Faculty has a few Schools and/or Centres (see Tables 1 and 3 in Appendix). We will refer to the Schools and Centres as the School-level organisations, or simply Schools, in the rest of the paper.
Journal information is not provided in the data set, but we obtained this information using rcrossref (Chamberlain et al. 2014).
In summary, we have
-
2926 staff, 20 of which have multiple Faculty affiliations, and 36 of which have multiple School-level affiliations;
-
20740 outputs, including 3002 outputs in Year 2008, 3084 in 2009, 3371 in 2010, 3619 in 2011, 3797 in 2012, and 3867 in 2013.
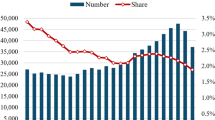
See Fig. 1 for the breakdown of the academic staff and their publications with respect to the Schools.

Barplot of the number of staff (magnitudes given in the left y-axis) and publications (right y-axis) from the academic organisations listed in Table 1
Note that this data set only includes all the authors within the University, i.e. if a paper has authors outside the University, (disciplines of) these authors are not reflected in the data set nor the analysis conducted in this paper. Also, we omit from our analysis any contribution to books and anthologies, conference proceedings and software. In Summer 2017, the University has re-named the Schools in the Faculty of Engineering and Faculty of Health Sciences and merged SOCS and SSCM as Bristol Medical School (see Table 3). In this paper, we keep the structure and names used for the data period.
2.2 Experiment setup and notation
In order to investigate the prediction performance of the proposed methods, we split the whole data set into training and test sets, which contain the research outputs published in Years 2008–2010 and Years 2011–2013, respectively.
Denote by \(\mathcal {I}\) and \(\mathcal {O}\) the collections of all the staff (researchers) and all the School-level organisations appearing in Years 2008–2013, respectively. Also, let \(\mathcal J\) denote the collection of all the journals in which the researchers in \(\mathcal I\) have published during the same period. Three types of networks arise from the PURE data set.
-
Co-authorship network: the nodes are individual researchers (\(\mathcal I\)), and the edges connecting pairs of researchers indicate that they have joint publications.
-
Researcher-journal network: in this bipartite network, the nodes are researchers (\(\mathcal I\)) and journals (\(\mathcal J\)), and there is an edge connecting a researcher and a journal if the researcher has published in the journal.
-
School network: the nodes are School-level organisations (\(\mathcal O\)), and the edges connecting pairs of organisations indicate that they have collaboration in ways which are to be specified; we wish to predict links in this network.
The co-authorship adjacency matrices for the training and test sets are denoted by \(A^{\mathrm {train}}, A^{\mathrm {test}} \in \mathbb {N}^{|\mathcal {I}| \times |\mathcal {I}|}\), both of which are based on the same cohort of researchers. To be specific, for \(i, j \in \mathcal {I}\),
Similarly, we define the incidence matrices corresponding to the research-journal bipartite networks for the training and test sets \(I^{\mathrm {train}}, I^{\mathrm {test}} \in \mathbb {N}^{|\mathcal {I}| \times |\mathcal {J}|}\), as
for \(i \in \mathcal {I}\) and \(j \in \mathcal {J}\).
For a researcher \(i \in \mathcal {I}\), let \(\mathcal {S}(i)\) be the School-level affiliation of researcher i. At the School-level, we create collections of edges (collaboration) \(E^{\mathrm {train}}\) and \(E^{\mathrm {test}}\) for the training and test sets, respectively, with
i.e. we suppose that there is an edge connecting a pair of organisations if they have joint publications in the corresponding data sets. Note that since \(A^{\text {train(test)}}\) are symmetric, the edges in \(E^{\text {train(test)}}\) are undirected ones.
Then, \(E^{\mathrm {new}} = E^{\mathrm {train}} {\setminus } E^{\mathrm {test}}\) denotes the collection of new School-level collaborative links appearing in the test set only. In this data set, there are 260 pairs of Schools which have no collaborations in the training set, and \(|E^{\mathrm {new}}| = m_{\mathrm {new}} = 37\) new pairs of Schools which have developed collaborations in the test set. Our aim is to predict as many edges in \(E^{\mathrm {new}}\) as possible using the training set, without incurring too many false positives. We would like to point out that false positives can also be interpreted as potential collaboration which has not be materialised in the whole data set.
3 Link prediction
3.1 Methodology
We formulate the problem of predicting potential interdisciplinary collaboration in the University as School network link prediction problem, by regarding the academic affiliations as a proxy for disciplines. We may approach the problem.
-
(i)
By observing the potential for future collaboration among the individuals and then aggregating the scores according to their affiliations for link prediction in the School network, or
-
(ii)
by forming the School network based on the existing co-authorship network (namely, \((\mathcal O, E^{\text{ train }})\)) and predicting the links thereof.
Noting that interdisciplinary research is often led by individuals of strong collaborative potential, we adopt the approach in (i) and propose the following algorithm.
Link prediction algorithm
- Step 1 :
-
Obtain the similarity scores for the pairs of individuals as \(\{w^0_{ij}; \, i, j \in \mathcal {I}\}\) using the training data.
- Step 2 :
-
Assign weights \(w_{kl}\) to the edges in the School network by aggregating \(w^0_{ij}\) for i with \(\mathcal {S}(i) = k\) and j with \(\mathcal {S}(j) = l\).
- Step 3 :
-
Select the set of predicted edges as
$$\begin{aligned} E^{\mathrm {pred}} = \{(k, l):\, w_{kl} > \pi \hbox { and } (k, l) \notin E^{\mathrm {train}}\}, \end{aligned}$$for a given threshold \(\pi\).
Note that although we can compute the edge weights for the pairs of individuals (and hence for the pairs of Schools) with existing collaborative links in Steps 1–2, they are excluded in the prediction performed in Step 3.
We propose two different methods for assigning the similarity scores \(w^0_{ij}\) to the pairs of individual researchers in Step 1, and aggregating them into the School network edge weights \(w_{kl}\) in Step 2. We first compute \(w^0_{ij}\) using the co-authorship network only (Sect. 3.1.1), and explore ways of further integrating the additional layer of information by adopting the bipartite network between the individuals and journals (Sect. 3.1.2).
3.1.1 Similarity scores based on the co-authorship network
As noted in Clauset et al. (2008), neighbour- or path-based methods have been known to work well in link prediction for strongly assortative networks such as collaboration and citation networks. If researchers A and B have both collaborated with researcher C in the past, it is reasonable to expect the collaboration between A and B if they have not done so yet. In the same spirit, one can also predict linkage based on other functions of neighbourhood.
Motivated by this observation, we propose different methods for calculating the similarity scores in Step 1. In all cases, \(w_{ij}^0 = 0\) if and only if (i, j) does not have a length-2 geodesic path based on \(A^{\mathrm {train}}\).
-
(a)
Length-2 geodesic path. Set \(w^0_{ij} = 1\) if there is a length-2 geodesic path connecting i and j based on \(A^{\mathrm {train}}\).
-
(b)
Number of common direct neighbours. Let \(w^0_{ij}\) be the number of distinct length-2 geodesic paths linking i and j based on \(A^{\mathrm {train}}\), i.e.
$$\begin{aligned} w^0_{ij} = \mid \mathcal {N}^{\mathrm {train}}(i) \cap \mathcal {N}^{\mathrm {train}}(j)\mid , \end{aligned}$$where \(\mathcal {N}^{\mathrm {train}}(i) = \{k: A^{\mathrm {train}}_{ik} > 0\}\).
-
(c)
Number of common order-2 neighbourhood. Let \(w^0_{ij}\) be the number of common order-2 neighbours of i and j; in other words,
$$\begin{aligned} w^0_{ij} =&\mid \left( \mathcal {N}^{\mathrm {train}}(i) \cup \{k: \, k\in \mathcal {N}^{\mathrm {train}}(l), \, l \in \mathcal {N}^{\mathrm {train}} (i)\}\right) \\ \cap&\left( \mathcal {N}^{\mathrm {train}}(j) \cup \{k: \, k\in \mathcal {N}^{\mathrm {train}}(l), \, l \in \mathcal {N}^{\mathrm {train}}(j)\}\right) \mid . \end{aligned}$$ -
(d)
Sum of weights of path edges. Let \(w^0_{ij}\) be the sum of the \(A^{\mathrm {train}}\) weights of all the length-2 geodesic paths linking i and j, i.e. listing all length-2 geodesic paths connecting i and j as \(\{i, k_1, j\}, \{i, k_2, j\}, \ldots , \{i, k_m, j\}\), \(m \ge 1\), we set
$$\begin{aligned} w^0_{ij} = \sum _{s = 1}^m (A^{\mathrm {train}}_{i, k_s} + A^{\mathrm {train}}_{k_s, j}). \end{aligned}$$
All (a)–(d) assign positive weights to the pairs of individuals who do not have direct collaboration in the training data set, but have at least one common co-author. Compared to (a), the other three scores integrate more information and take into consideration the number of common publications or the number of common co-authors; however, all (a)–(d) assign nonzero weights to the same set of edges. Then, with the thus-chosen edge weights between the researchers, we obtain the edge weights for the School network in Step 2, as
which in turn is used for link prediction in Step 3. In combination with (a)–(d), we propose to select the threshold \(\pi\) in Step 3 as the \(100(1-p)\)th percentile of \(\{w_{kl} > 0, k, l \in \mathcal {O}\}\) for a given \(p \in [0, 1]\).
3.1.2 Similarity scores based on the bipartite network
In the research output data set, we have additional information, namely the journals in which the research outputs have been published, which can augment the co-authorship network for School network link prediction. Our motivation comes from the observation that when researchers from different organisations publish their research outputs in the same (or similar) journals but have not collaborated yet to this date, it indicates that they have the potential to form interdisciplinary collaboration with each other. A similar idea has been adopted in e.g. Kuzmin et al. (2016) for identifying the potential for scientific collaboration among molecular researchers, by adding the layer of the paths of molecular interactions to the co-authorship network.
Recall the incidence matrix for the researcher-journal bipartite network in the training set, \(I^{\text{ train }}\). In the bipartite network, we define the neighbours of the researcher i as the journals in which i has published, and denote the set of neighbours by \(\mathcal J^{\text{ train }}(i) = \{j \in \mathcal {J}: \, I^{\text{ train }}_{ij} \ne 0\}\). Analogously, for journal j, its neighbours are those researchers who have published in the journal, and its set of neighbours is denoted by \(\mathcal I^{\text{ train }}(j) = \{i \in \mathcal {I}: \, I^{\text{ train }}_{ij} \ne 0\}\).
Then, we propose the following scores to be used in Step 1 for measuring the similarity between two researchers i and \(i'\). Where there is no confusion, we omit ‘train’ from the superscripts of \(\mathcal J^{\text{ train }}(\cdot )\), \(\mathcal I^{\text{ train }}(\cdot )\) and \(I^{\text{ train }}\).
-
Jaccard’s coefficient The Jaccard coefficient that measures the similarity between finite sets, is extended to compare the neighbours of two individual researchers as
$$\begin{aligned} \sigma _{\text{ Jaccard }}^1(i, i') = \frac{\vert \mathcal J(i) \cap \mathcal J(i') \vert }{\vert \mathcal J(i) \cup \mathcal J(i') \vert }. \end{aligned}$$This definition simply counts the number of journals shared by i and \(i'\), and hence gives more weights to a pair of researchers who, for example, each published one paper in two common journals, than those who published multiple papers in a single common journal, given that \(\vert \mathcal J(i) \cup \mathcal J(i') \vert\) remains the same. Therefore, we propose a slightly modified definition which takes into account the number of publications:
$$\begin{aligned} \sigma _{\text{ Jaccard }}^2(i, i') = \frac{\sum _{j \in \mathcal J(i) \cap \mathcal J(i')} (I_{ij} + I_{i'j})}{\sum _{j \in \mathcal J(i) \cup \mathcal J(i')} (I_{ij} + I_{i'j})}. \end{aligned}$$ -
Adamic and Adar (2003) The rarer a journal is (in terms of total publications made in the journal), two researchers that share the journal may be deemed more similar. Hence, we adopt the similarity measure originally proposed in Adamic and Adar (2003) for measuring the similarity between two personal home pages based on the common features, which refines the simple counting of common features by weighting rarer features more heavily:
$$\begin{aligned} \sigma _{\text{ AA }}(i, i') = \sum _{j \in \mathcal J(i) \cap \mathcal J(i')} \frac{1}{\log (\sum _{l \in \mathcal I(j)} I_{lj})} \end{aligned}$$ -
Co-occurrence We note the resemblance between the problem of edge prediction in a co-authorship network and that of stochastic language modelling for unseen bigrams (pairs of words that co-occur in a test corpus but not in the training corpus), and adapt the ‘smoothing’ approach of Essen and Steinbiss (1992). We first compute the similarity between journals using \(\sigma ^k_{\text{ Jaccard }}, \, k = 1, 2\) and augment the similarity score between a pair of researchers by taking into account not only those journals directly shared by the two, but also those which are close to those journals:
$$\begin{aligned} \sigma ^k_{\text{ cooc }}(i, i')= & {} \sum _{j \in \mathcal J(i)}\sum _{j' \in \mathcal J(i')} \frac{I_{ij}}{\sum _l I_{il}} \cdot \frac{I_{i'j'}}{\sum _l I_{i'l}} \cdot \sigma ^k_{\text{ Jaccard }}(j, j'), \quad k = 1, 2. \end{aligned}$$
The use of above similarity measures and others has been investigated by Liben-Nowell and Kleinberg (2007) for link prediction problems in social networks. Here, we accommodate the availability of additional information beside the direct co-authorship network and re-define the similarity measures accordingly.
Since the above similarity measures do not account for the path-based information in the co-authorship network, we propose to aggregate the similarity scores and produce the School network edge weights (Step 2) as
for a given \(d > 0\), where \(g_{ii'}\) denotes the geodesic distance between researchers i and \(i'\) in \(A^{\text{train }}\). As an extra parameter d is introduced in computing \(w_{kl}\), we propose to select the threshold \(\pi\) in Step 3 such that only those \((k, l) \notin E^{\text{train }}\), whose edge weights \(w_{kl}\) exceed the median of the weights for the collaborative links that already exist in the training set, are selected in \(E^{\text{pred }}\).
3.2 Results
In Table 2, we perform link prediction following Steps 1–3 of the link prediction algorithm on the PURE data set, using different combinations of the weights (a)–(d) and the threshold chosen with \(p \in \{1, 0.4, 0.3, 0.2\}\) as described in Sect. 3.1.1, and similarity scores introduced in Sect. 3.1.1 together with \(d \in \{\hbox {NA}, \infty , 10, 4\}\) for (1), where NA refers to the omission of thresholding on the geodesic distance \(g_{ii'}\). For evaluating the quality of the predicted links, we report the total number of predicted edges, their prediction accuracy and recall, which are defined as
following the practice in the link prediction literature (see Liben-Nowell and Kleinberg (2007)). Each method is compared to random guessing, the prediction accuracy of which is defined as the expectation of prediction accuracy of randomly picking \(m_{\mathrm {new}}\) pairs from all non-collaborated pairs in the training data.
In Fig. 2, we present the edges predicted with the similarity scores based on the co-authorship network with \(p = 0.4\), and in Fig. 3 those predicted with the similarity scores based on the bipartite network and \(d = 10\), in addition to the one returned with \(\sigma ^1_{\text{ cooc }}\) and \(d = \infty\). Different node colours represent different Faculties to which Schools belong, and edge width is proportional to the edge weights \(w_{kl}\) obtained in Step 2 of the proposed algorithm.

Edges predicted indicating possible collaboration among School-level organisations using various weights a–d described in Sect. 3.1.1 and threshold \(p = 0.4\). Each node represents a School, and each Faculty has a unique colour. Each plot reports the prediction accuracy and the number of total edges returned. The edge width is proportional to the edge weights \(w_{kl}\) in Step 1

Table 2 shows that the performance of the link prediction algorithm, combined with the similarity scores based on the co-authorship network, is not sensitive to the choice of the weights (a)–(d) nor the threshold (p): all 16 combinations outperform the random choice, and do not differ too much among themselves. Only counting the length-2 geodesic path pairs, the score (a) predicts the most edges among them, and when no thresholding is applied (\(p = 1\)), all (a)–(d) select the same cohort of edges. From Fig. 2, it is observable that the four similarity scores still differ by preferring different edges. For instance, with (b) and (c), the edge between SSCM and GEOG is assigned a relatively larger weight than when (a) is used.
It is evident that by taking into account the additional layer of information on journals enhances the prediction accuracy considerably, returning a larger proportion of true positives among a fewer number of predicted edges in general (thus fewer false positives). In particular, combining the similarity measure \(\sigma ^1_{\text{ cooc }}\), which takes into account the similarity among the journals as well, with the choice \(d \in \{\infty , 10\}\) returns a set of predicted edges that is comparable to the set of edges predicted with the scores from Sect. 3.1.1 in terms of its size, while achieving higher prediction accuracy and recall. Among possible values for d, most scores perform the best with \(d =10\), which aggregates the similarities between two individuals in forming School network edge weights, provided that their geodesic distance in the co-authorship network is less than 10; an exception is \(\sigma ^1_{\text{ cooc }}\), where slight improvement is observed with \(d = \infty\).
For comparison, Table 2 also reports the results from applying a modularity-maximising hierarchical community detection method to the School network constructed from \(A^{\mathrm {train}}\). Here, we assign an edge between Schools k and l, \(k, l \in \mathcal {O}\) with the number of publications between the researchers from the two Schools as its weight, and the prediction is made by linking all the members (Schools) in the same communities. Modularity optimisation algorithms are known to suffer from the resolution limit, and strong connections among a small number of nodes in large networks are not well detected by such methods (Fortunato and Barthelemy 2007; Alzahrani and Horadam 2016). Noting the nature of interdisciplinary research collaboration, which is often driven by a small number of individuals, we choose to apply the community detection method to the School network of smaller size rather than to the co-authorship network, following the approach described in (ii) at the beginning of Sect. 3.1.
The optimal cut results in 21 different communities at the School level, which leads to too few predicted edges. We therefore trace back in the dendrogram and show the results corresponding to the cases in which there are 5–8 communities. It is clearly seen from the outcome that our proposed method outperforms the community detection method regardless of the choice of similarity scores or other parameters. In fact, community detection often performs worse than random guessing in link prediction. This may be attributed to modularity maximisation assuming all communities in a network to be statistically similar Newman 2016, whereas the PURE data set is highly unbalanced with regard to both the numbers of academic staff and publications at different Schools, see Fig. 1. On the other hand, our proposed method observes the potential for collaborative research at the individual level and then aggregates the resulting scores to infer the interdisciplinary collaboration potential, and hence can predict the links between, e.g., a relatively small organisation (BIOC) and a large one (SSCM) as well as that between BIOC and another organisation of similar size (PSYC), see the bottom right panel of Fig. 3.
Our proposed method predicts edges which do not appear in the test data set. On one hand, this can be interpreted as false positive prediction, but on the other, it may be due to the time scale limitation, i.e. these edges may appear after Year 2013, or the Schools connected still have the potential to form collaborative links which are yet to be realised.
Figure 4 shows both the predicted edges (solid) and those which are in \(E^{\mathrm {new}}\) but not among the predicted ones (false negatives, dashed). Edge width is proportional to the corresponding weight for \((k, l) \in E^{\mathrm {pred}}\). For the false negative edges, we assign a very small value (0.2) as their edge weights and add 0.2 to all other edge weights to make the visualisation possible. In addition, we use weights computed in the same manner but with the test data to colour the edges: the bluer an edge is, the greater the association is between the pairs of Schools connected in the test set, while the red edges indicate weaker association; grey ones are falsely predicted ones (\(E^{\mathrm {pred}} {\setminus } E^{\mathrm {new}}\)). In the figure, many of the predicted edges are more towards blue on the colour spectrum, while the majority of missing edges are in red, implying that the methodology is able to identify the pairs of Schools that develop significant collaboration in the test period.

Edges in \(E^{\mathrm {pred}} \cup E^{\mathrm {new}}\). Blue and red edges are in \(E^{\mathrm {new}}\), and the bluer an edge is, the larger the corresponding weight that is computed using the test set; the redder an edge is, its test set weight is smaller. The edges in \(E^{\mathrm {pred}} {\setminus } E^{\mathrm {new}}\) are in grey. The edges in \(E^{\mathrm {pred}}\) are solid lines and their widths are proportional to \(w_{kl}\), and the ones in \(E^{\mathrm {new}} {\setminus } E^{\mathrm {pred}}\) are dashed lines. The left panel is based on the similarity score (c) with \(p = 0.4\) described in Sect. 3.1.1, and the right panel is based on \(\sigma ^1_{\text{ cooc }}\) with \(d = \infty\) as described in Sect. 3.1.2
4 Discussion
In this paper, we tackle the problem of predicting potential interdisciplinary research by transforming it to a membership network link prediction problem. Two types of similarity scores have been proposed in this paper, one employing only the co-authorship network and the other integrating additional information which is naturally available for the research output data. As expected, when we have more information in hand, the prediction accuracy improves. Within each type of scores, different choices of scores or parameters do not differ by much in their performance when applied to the PURE data set. However, this does not guarantee that the same robustness can be expected when different data sets are used.
We would like to suggest that the practitioners make their own choice according to the aim of the analysis, and different behaviours of different metrics used may reflect the underlying properties of specific data set. For example, when using the co-author relationship only, if we also care about the amount of joint publications, then the similarity score (b) is more suitable. When additional information is available, \(\sigma ^1_{\text{ cooc }}\) returns the best prediction accuracy by taking into account not only those journals directly shared by two individuals, but also the journals which are similar to them. Also, the scores proposed in Sect. 3.1.2 tend to return fewer edges and, consequently, fewer false positives which, for some applications, may be a more important criterion than the measure of prediction accuracy used in this paper.
We would also like to point out one main limitation of this paper. The problem here is to predict linkage between disciplines within a university. However, due to the lack of information, it is not possible to map all individuals to disciplines, and therefore, we equate disciplines with academic organisations within the university. In most situations, this remedy works well, especially in traditional disciplines such as civil engineering, pure mathematics and languages, among others, which are all categorised well within the School framework. Relatively newer disciplines, however, do not have clear School boundaries, e.g., there are statisticians working in the School of Mathematics, School of Social and Community Medicine and School of Engineering. This situation, on the other hand, also means mathematics, public health and engineering have shared interests in the modern world.
Finally, the paper focuses on predicting academic collaboration links from the co-authorship network, but we would like to point out that the proposed method and similarity scores per se are not limited to a single organisation or, indeed, an application area. For example, we may suggest interaction between different communities based on their members’ Facebook networks, using both Facebook friend lists and additional information such as their taste in music or films.
References
Adamic LA, Adar E (2003) Friends and neighbors on the web. Soc. Netw 25:211–230
Alzahrani T, Horadam KJ (2016) Community detection in bipartite networks: algorithms and case studies. Complex systems and networks. Springer, Berlin, Heidelberg, pp 25–50
Brown RR, Deletic A, Wong THF (2015) How to catalyse collaboration. Nature 525:315–317
Chamberlain S, Boettiger C, Hart T, Ram K (2014) rcrossref: R Client for Various CrossRef APIs. R package version 0.3.0 https://github.com/ropensci/rcrossref
Clauset A, Moore C, Newman ME (2008) Hierarchical structure and the prediction of missing links in networks. Nature 453:98
Elsevier (2015) A review of the UK’s interdisciplinary research using a citation-based approach. http://www.hefce.ac.uk/pubs/rereports/year/2015/interdisc/
Essen U, Steinbiss V (1992) Cooccurrence smoothing for stochastic language modeling. Proc IEEE Int Conf Acoust Speech Signal Process 1:161–164
Fortunato S, Barthelemy M (2007) Resolution limit in community detection. Proc Natl Acad Sci USA 104:36–41
Fouss F, Pirotte A, Renders J-M, Saerens M (2007) Random-walk computation of similarities between nodes of a graph with application to collaborative recommendation. IEEE Trans Knowl Data Eng 19:355–369
Geyer CJ (1992) Practical Markov chain Monte Carlo. Stat Sci 7:473–483
Guimerá R, Sales-Pardo M (2009) Missing and spurious interactions and the reconstruction of complex networks. Proc Natil Acad Sci 106:22073–22078
Jeh G, Widom J (2002) SimRank: a measure of structural-context similarity. In: Proceedings of the 8th ACM SIGKDD international conference on knowledge discovery and data mining (KDD02), ACM, pp 538–543
Katz L (1953) A new status index derived from sociometric analysis. Psychometrika 18:39–43
Kuzmin K, Lu X, Mukherjee PS, Zhuang J, Gaiteri C, Szymanski BK (2016) Supporting novel biomedical research via multilayer collaboration networks. Appl Netw Sci 1:11
Ledford H (2015) Tean science. Nature 525:308–311
Leicht EA, Holme P, Newman MEJ (2006) Vertex similarity in networks. Phys Rev E 73:026120
Liben-Nowell D, Kleinberg J (2007) The link-prediction problem for social networks. J Assoc Inf Sci Technol 58:1019–31
Liu W, Lü L (2010) Link prediction based on local random walk. EPL (Europhysics Letters) 89:58007
Lü L, Zhou T (2011) Link prediction in complex networks: a survey. Phys A Stat Mech Appl 390:1150–70
Martínez V, Berzal F, Cubero JC (2016) A survey of link prediction in complex networks. ACM Comput Surv (CSUR) 49:69
Martńez V, Cano C, Blanco A (2014) ProphNet: a generic prioritization method through propagation of information. BMC Bioinform 15:S5
Nature (2015) A special issue on interdisciplinary research. https://www.nature.com/news/interdisciplinarity-1.18295
Newman M E J (2016) Community detection in networks: Modularity optimization and maximum likelihood are equivalent. arXiv preprint arXiv:1606.02319
Page L, Brin S, Motwani R, Winograd T (1999) The PageRank citation ranking: bringing order to the web. Technical Report 1999–66. Stanford InfoLab
Rylance R (2015) Global funders to focus on interdisciplinarity. Nature 525:313–315
Turki T, Wang J T L (2015). A new approach to link prediction in gene regulatory networks. In: International conference on intelligent data engineering and automated learning. Springer International Publishing, pp 404–415
Wang L, Hu K, Tang Y (2014) Robustness of link-prediction algorithm based on similarity and application to biological networks. Curr Bioinform 9:246–252
Wang X, Sukthankar G (2013) Link prediction in multi-relational collaboration networks. In Proceedings of the 2013 IEEE/ACM international conference on advances in social networks analysis and mining, ACM, pp 1445–1447
Woelert P, Millar V (2013) The ‘paradox of interdisciplinarity’ in Australian research governance. High Educ 66:755–767
Zhou T, Lü L, Zhang YC (2009) Predicting missing links via local information. Eur Phys J B 71:623–630
Acknowledgements
We thank the PURE team and the Jean Golding Institute at the University of Bristol for providing the data set. We thank Professor Jonathan C. Rougier for all the constructive discussions, comments and his input in the data analysis. We also thank the Editor and the two referees for their constructive suggestions.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Cho, H., Yu, Y. Link prediction for interdisciplinary collaboration via co-authorship network. Soc. Netw. Anal. Min. 8, 25 (2018). https://doi.org/10.1007/s13278-018-0501-6
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13278-018-0501-6