
Abstract
Recently, vision transformer (ViT) based multimodal learning methods have been proposed to improve the robustness of face anti-spoofing (FAS) systems. However, there are still no works to explore the fundamental natures (e.g., modality-aware inputs, suitable multimodal pre-training, and efficient finetuning) in vanilla ViT for multimodal FAS. In this paper, we investigate three key factors (i.e., inputs, pre-training, and finetuning) in ViT for multimodal FAS with RGB, Infrared (IR), and Depth. First, in terms of the ViT inputs, we find that leveraging local feature descriptors (such as histograms of oriented gradients) benefits the ViT on IR modality but not RGB or Depth modalities. Second, in consideration of the task (FAS vs. generic object classification) and modality (multimodal vs. unimodal) gaps, ImageNet pre-trained models might be sub-optimal for the multimodal FAS task. Finally, in observation of the inefficiency on direct finetuning the whole or partial ViT, we design an adaptive multimodal adapter (AMA), which can efficiently aggregate local multimodal features while freezing majority of ViT parameters. To bridge these gaps, we propose the modality-asymmetric masked autoencoder (M\(^{2}\)A\(^{2}\)E) for multimodal FAS self-supervised pre-training without costly annotated labels. Compared with the previous modality-symmetric autoencoder, the proposed M\(^{2}\)A\(^{2}\)E is able to learn more intrinsic task-aware representation and compatible with modality-agnostic (e.g., unimodal, bimodal, and trimodal) downstream settings. Extensive experiments with both unimodal (RGB, Depth, IR) and multimodal (RGB+Depth, RGB+IR, Depth+IR, RGB+Depth+IR) settings conducted on multimodal FAS benchmarks demonstrate the superior performance of the proposed methods. One highlight is that the proposed method is robust under various missing-modality cases where previous multimodal FAS models suffer serious performance drops. We hope these findings and solutions can facilitate the future research for ViT-based multimodal FAS.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Face recognition technology has widely used in many intelligent systems due to their convenience and remarkable accuracy. However, face recognition systems are still vulnerable to presentation attacks (PAs) ranging from print, replay and 3D-mask attacks. Therefore, both the academia and industry have recognized the critical role of face anti-spoofing (FAS) for securing the face recognition system.
In the past decade, plenty of hand-crafted features based (Boulkenafet et al., 2015, 2017; Komulainen et al., 2013; Patel et al., 2016) and deep learning based (Qin et al., 2020; Liu et al., 2018; Yang et al., 2019; Atoum et al., 2017; Gan et al., 2017; George & Marcel, 2019) methods have been proposed for unimodal FAS. Despite satisfactory performance in seen attacks and environments, unimodal methods generalize poorly on emerging novel attacks and unseen deployment conditions. Thanks to the advanced sensors with various modalities (e.g., RGB, Infrared (IR), Depth, Thermal) (George et al., 2019), multimodal methods facilitate the FAS applications under some high-security scenarios with low false acceptance errors (e.g., face payment and vault entrance guard).
Recently, due to the strong long-range and cross-modal representation capacity, vision transformer (ViT) (Dosovitskiy et al., 2021) based methods (Liu &, 2022; George & Marcel, 2020b) have been proposed to improve the robustness of FAS systems. However, these methods focus on directly finetuning ViTs (George & Marcel, 2020b) or modifying ViTs with complex and powerful modules (Liu &, 2022), which cannot provide enough insights on bridging the fundamental natures (e.g., modality-aware inputs, suitable multimodal pre-training, and efficient finetuning) of ViT in multimodal FAS. Despite mature exploration and finds (He et al., 2022; Bachmann et al., 2022; Xiao et al., 2021) of ViT on other computer vision communities [e.g., generic object classification (Chen et al., 2022a)], these knowledge might not be fully aligned for the multimodal FAS due to the task and modality gaps.
Compared with CNN, ViT usually aggregates the coarse intra-patch info at the very early stage and then propagates the inter-patch global attentional features. On other words, it neglects the local detailed clues for each modality. According to the prior evidence from MM-CDCN (Yu et al., 2020b), local fine-grained features from multiples levels benefits the live/spoof clue representation in convolutional neural networks (CNN) from different modalities. Whether local descriptors/features can improve the ViT-based multimodal FAS systems is worth exploring.
In comparison with CNNs, ViTs usually have huger parameters to train, which easily overfit on the FAS task with limited data amount and diversity. Existing works show that direct finetuning the last classification head (George & Marcel, 2020b) or training extra lightweight adapters (Huang et al., 2022) can achieve better performance than fully finetuning. However, all these observations are based on the unimodal RGB inputs, it is unclear how different ViT-based transfer learning techniques perform on (1) other unimodal scenario (IR or Depth modality); and (2) multimodal scenario (e.g., RGB+IR+Depth). Moreover, to design more efficient transfer learning modules for ViT-based multimodal FAS should be considered.
Existing multimodal FAS works usually finetune the ImageNet pre-trained models, which might be sub-optimal due to the huge task (FAS vs. generic object classification) and modality (multimodal vs. unimodal) gaps. Meanwhile, in consideration of costly collection of large-scale annotated live/spoof data, self-supervised pre-training without labels (Muhammad et al., 2022) is potential for model initialization in multimodal FAS. Although a few self-supervised pre-training methods [e.g., masked image modeling (MIM) (Bachmann et al., 2022; Chen et al., 2022b) and contrastive learning (Akbari et al., 2021)] are developed for multimodal (e.g., vision-language) applications, there are still no self-supervised pre-trained models specially for multimodal FAS. To investigate the discrimination and generalization capacity of pre-trained models and design advanced self-supervision strategies are crucial for ViT-based multimodal FAS.
Motivated by the discussions above, in this paper we rethink the ViT-based multimodal FAS into three aspects, i.e., modality-aware inputs, suitable multimodal pre-training, and efficient finetuning. Besides the elaborate investigations, we also provide corresponding elegant solutions to (1) establish powerful inputs with local descriptors (Bhattacharjee & Roy, 2019; Dalal & Triggs, 2005) for IR modality; (2) efficiently finetune multimodal ViTs via adaptive multimodal adapters; and (3) pre-train generalized multimodal model via modality-asymmetric masked autoencoder. Our contributions include:
-
We are the first to investigate three key factors (i.e., inputs, pretraining, and finetuning) for ViT-based multimodal FAS. We find that (1) leveraging local feature descriptors benefits the ViT on IR modality; (2) partially finetuning or using adapters can achieve reasonable performance for ViT-based multimodal FAS but still far from satisfaction; and (3) mask autoencoder (He et al., 2022; Bachmann et al., 2022) pre-training cannot provide better finetuning performance compared with ImageNet pre-trained models.
-
We design the adaptive multimodal adapter (AMA) for ViT-based multimodal FAS, which can efficiently aggregate local multimodal features while freezing majority of ViT parameters.
-
We propose the modality-asymmetric masked autoencoder (M\(^{2}\)A\(^{2}\)E) for multimodal FAS self-supervised pre-training. Compared with modality-symmetric autoencoders (He et al., 2022; Bachmann et al., 2022), the proposed M\(^{2}\)A\(^{2}\)E is able to learn more intrinsic task-aware representation and compatible with modality-agnostic downstream settings. To our best knowledge, this is the first attempt to design the MIM framework for generalized multimodal FAS.
-
Our proposed methods achieve state-of-the-art performance with most of the modality settings on both intra- as well as cross-dataset testings on WMCA (George et al., 2019) and CASIA-SURF (Zhang et al., 2019b) datasets. Moreover, the proposed method achieves the robustest performance under various missing-modality settings.
2 Related Work
Multimodal face anti-spoofing With multimodal inputs (e.g., RGB, IR, Depth, and Thermal), there are a few multimodal FAS works that consider input-level (Nikisins et al., 2019; Liu et al., 2021; George & Marcel, 2020; Nikisins et al., 2019) and decision-level (Zhang et al., 2019a) fusions. Besides, mainstream FAS methods extract complementary multi-modal features using feature-level fusion (Yu et al., 2020b; Zhang et al., 2019b; Liu et al., 2021; Wang et al., 2022a; Liu &, 2022; Li et al., 2021) strategies. As there are redundancy across multi-modal features, direct feature concatenation (Yu et al., 2020b) easily results in high-dimensional features and overiftting. To alleviate this issue, Zhang et al. (2019b, 2020) propose a feature re-weighting mechanism to select the informative and discard the redundant channel features among RGB, IR, and Depth modalities. shen et al. (2019) design a Modal Feature Erasing operation to randomly dropout partial-modal features to prevent modality-aware overftting.
Despite performance improvement via fusion, multimodal FAS models suffer from vulnerability when missing partial modalities. George and Marcel (2021) present a cross-modal focal loss to modulate the loss contribution of each modality, which benefits the model to learn complementary information among modalities to alleviate modality-missing issues. Furthermore, to fairly evaluate models’ performance against modality-missing scenarios, two flexible-modal FAS benchmarks (Yu et al., 2023b, a) are established while few robust flexible-modal learning algorithms (Yu et al., 2023b, a; Liu et al., 2023; Liu &, 2022) are presented.

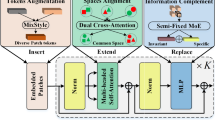
Framework of the ViT finetuning with adaptive multimodal adapters (AMA). The AMA and classification head are trainable while the linear projection and vanilla transformer blocks are fixed with the pre-trained parameters. ‘MHSA’, ‘FFN’, and ‘GAP’ are short for the multihead self-attention, feed-forword network, and global average pooling, respectively
Transformer for vision tasks Transformer is proposed in Vaswani et al. (2017) to model sequential data in the field of NLP. Then ViT (Dosovitskiy et al., 2021) is proposed recently by feeding transformer with sequences of image patches for image classification. In consideration of the data hungry characteristic of ViT, direct training ViTs from scratch would result in severe overfitting. On the one hand, fast transferring [e.g., adapter ( Houlsby et al., 2019; Chen et al., 2022a; Jie &, 2022) and prompt (Zhou et al., 2022) tuning] while fixed most of pre-trained models’ parameters is usually efficient for downstream tasks. On the other hand, self-supervised masked image modeling (MIM) methods [(e.g., BEiT (Bao et al., 2021) and MAE (He et al., 2022; Bachmann et al., 2022)] benefit the excellent representation learning, which improve the finetuning performance in downstream tasks.
Meanwhile, a few works introduce vision transformer for FAS (Liu &, 2022; Ming et al., 2022; George & Marcel, 2020b; Wang et al., 2022b, c; Yu et al., 2021). On the one hand, ViT is adopted in the spatial domain (Ming et al., 2022; George & Marcel, 2020b; Wang et al., 2022b) to explore live/spoof relations among local patches. On the other hand, global features temporal abnormity (Wang et al., 2022c) or physiological periodicity (Yu et al., 2021) are extracted applying ViT in the temporal domain. Recently, Liu and (2022) develop the modality-agnostic transformer blocks to supplement liveness features for multimodal FAS. Despite convincing performance via modified ViT with complex customized modal-disentangled and cross-modal attention modules (Liu &, 2022), there are still no works to explore the fundamental natures (e.g., modality-aware inputs, suitable multimodal pre-training, and efficient finetuning) in vanilla ViT for multimodal FAS.
Masked Image Modeling A few works have explored the potential of masked image modeling (MIM). The BEiT (Bao et al., 2021) proposes a pre-training task called MIM, and also introduces the definition of MIM firstly. In BEiT, the image is represented as discrete tokens, and these tokens will be treated as the construct target of masked patches. Most recently, MAE (He et al., 2022) and SimMIM (Xie et al., 2022) almost simultaneously obtain state-of-the-art on computer vision tasks. They propose a pre-training paradigm based on MIM. Specifically, the patches of images are randomly masked with a high probability, then the self-attention mechanism is used in the encoder to learn the relationship between patches. Finally, the masked patches are reconstructed in the decoder. Recently, Ma et al. (2022) apply MAE to pretrain unimodal FAS models, and show their excellent generalization capacities. Meanwhile, Bachmann et al. (2022) propose the first multimodal MAE for pretraining generic semantic models in a multimodal and multitask manner. Different from previous works (Ma et al., 2022; Bachmann et al., 2022), we are the first to explore MAE for the multimodal FAS task, and find that modality-symmetric masked inputs are one of the keys for effective multimodal live/spoof clue modeling.
3 Methodology
To benefit the exploration of fundamental natures of ViT for multimodal FAS, here we adopt the simple, elegant, and unified ViT framework as baselines. As illustrated in the left part (without ‘AMA’) of Fig. 1, the vanilla ViT consists of a patch tokenizer \(\textbf{E}_{\text {patch}}\) via linear projection, N transformer blocks \(\textbf{E}^{i}_{\text {trans}}\) (\( i=1,...,N\)) and a classification head \(\textbf{E}_{\text {head}}\). The unimodal (\(X_{\text {RGB}}\), \(X_{\text {IR}}\), \(X_{\text {Depth}}\)) or multimodal (\(X_{\text {RGB+IR}}\), \(X_{\text {RGB+Depth}}\), \(X_{\text {IR+Depth}}\), \(X_{\text {RGB+IR+Depth}}\)) inputs are passed over \(\textbf{E}_{\text {patch}}\) to generate the visual tokens \(T^\text {Vis}\), which is concatenated with learnable class token \(T^\text {Cls}\), and added with position embeddings. Then all patch tokens \(T^\text {All}=[T^\text {Vis},T^\text {Cls}]\) will be forwarded with \(\textbf{E}_{\text {trans}}\). Finally, \(T^{\text {Cls}}\) is sent to \(\textbf{E}_{\text {head}}\) for binary live/spoof classification.
We will first briefly introduce different local descriptor based inputs in Sect. 3.1, then introduce the efficient ViT finetuning with AMA in Sect. 3.2, and at last present the generalized multimodal pre-training via M\(^{2}\)A\(^{2}\)E in Sect. 3.3.
3.1 Local Descriptors for Multimodal ViT
Besides the raw multimodal inputs, we consider three local features and their compositions for multimodal ViT. The motivations behind are that the vanilla ViT with raw inputs is able to model rich cross-patch semantic contexts but sensitive to illumination and neglecting the local fine-grained spoof clues (Yu et al., 2023b). Explicitly leveraging local descriptors as inputs of different modalities might benefit multimodal ViT mining more discriminative fine-grained spoof clues (Yu et al., 2020b, c, 2021b, 2020a) as well as illumination-robust live/spoof features (Li et al., 2021).

Local Binary Pattern (LBP) LBP (Ojala et al., 2002) computes a binary pattern via thresholding central difference among neighborhood pixels. Fine-grained textures and illumination invariance make LBP robust for generalized FAS (Li &, 2019). For a center pixel \(I_{c}\) and a neighboring pixel \(I_{i}(i=1,2,...,p)\), LBP can be formalized as follows:
Typical LBP maps are shown in second column of Fig. 2.
Histograms of oriented gradients (HOG) HOG (Dalal & Triggs, 2005) describes the distribution of gradient orientations or edge directions within a local subregion. It is implemented via firstly computing magnitudes and orientations of gradients at each pixel, and then the gradients within each small local subregion are accumulated into orientation histogram vectors of several bins, voted by gradient magnitudes. Due to the partial invariance to geometric and photometric changes, HOG features might be robust for the illumination-sensitive modalities like RGB and IR. The visualization results are shown in third column of Fig. 2.
Pattern of local gravitational force (PLGF) Inspired by Law of Universal Gravitation, PLGF (Bhattacharjee & Roy, 2019) describes the image interest regions via local gravitational force magnitude, which is useful to reduce the impact of illumination/noise variation while preserving edge-based low-level clues. It can be formulated as:
where I is the raw image. \(M_{x}\) and \(M_{y}\) are two filter masks for gravitational force calculation. m and n are indexes denoting the relative position to the center. \(*\) is convolution operation sliding along all pixels. The visualization of PLGF maps are shown in fourth column of Fig. 2.
Composition In consideration of the complementary characteristics from raw image and local descriptors, we also study the compositions among these features via input-level concatenation. For example, ‘GRAY_HOG_PLFG’ denotes three-channel inputs (raw gray-scale channel + HOG + PLFG), which is visualized in last column of Fig. 2.
3.2 Adaptive Multimodal Adapter
Recent studies have verified that introducing adapters (Huang et al., 2022) with fully connected (FC) layers can improve the FAS performance when training data is not adequate. However, FC-based adapter focuses on the intra-token feature refinement but neglects (1) contextual features from local neighbor tokens; and (2) multimodal features from cross-modal tokens. To tackle these issues, we extend the convolutional adapter (ConvAdapter) (Jie &, 2022) into a multimodal version for multimodal FAS.
As illustrated in Fig. 1, instead of directly finetuning the transformer blocks \(\textbf{E}_{\text {trans}}\), we fix all the pre-trained parameters from \(\textbf{E}_{\text {patch}}\) and \(\textbf{E}_{\text {trans}}\) while training only adaptive multimodal adapters (AMA) and \(\textbf{E}_{\text {head}}\). An AMA module consists of four parts: (1) an 1 \(\times \)1 convolution with GELU \(\Theta _{\downarrow }\) for dimension reduction from the original channels D to a hidden dimension \(D'\); (2) a 3\(\times \)3 2D convolution \(\Theta _{\text {2D}}\) mapping channels \(D'\times K\) to \(D'\) for multimodal local feature aggregation, where K means the modality numbers; (3) an adaptive modality weight (\(w_{1},...,w_{K}\)) generator via cascading global averaging pooling (GAP), 1\(\times \)1 convolution \(\Theta _{\text {Ada}}\) to project channels from \(D' \times K\) to K, and the Sigmoid function \(\sigma \); and (4) an 1\(\times \)1 convolution with GELU \(\Theta _{\uparrow }\) for dimension expansion to D. As features from different modalities are already spatially aligned, we restore the 2D structure for each modality after the channel squeezing. Similarly, the 2D structure will be flatten into 1D tokens before the channel expanding. The AMA can be formulated as
Here we show an example when K=3 (i.e., RGB+ IR+Depth) in Eq. (3), and AMA is flexible for arbitrary modalities (e.g., RGB+IR). Note that AMA is equivalent to vanilla ConvAdapter (Jie &, 2022) in unimodal setting when K=1.
3.3 Modality-Asymmetric Masked Autoencoder
Existing multimodal FAS works usually finetune the ImageNet pre-trained models, which might be sub-optimal due to the huge task and modality gaps. Meanwhile, in consideration of costly collection of large-scale annotated live/spoof data, self-supervised pre-training without labels (Muhammad et al., 2022) is potential for model initialization in multimodal FAS. Here we propose the modality-asymmetric masked autoencoder (M\(^{2}\)A\(^{2}\)E) for multimodal FAS self-supervised pre-training.
As shown in Fig. 15, given a multimodal face sample (\(X_{\text {RGB}},X_{\text {IR}},X_{\text {Depth}}\)), M\(^{2}\)A\(^{2}\)E randomly selects unimodal input \(X_{i}\) (\(i\in {\text {RGB},\text {IR},\text {Depth}}\)) among all modalities. Then random sampling strategy (He et al., 2022) is used to mask out p percentage of the visual tokens in \(X_{i}\). Only the unmasked visible tokens are forwarded the ViT encoder and both visible and masked tokens are fed in unshared ViT decoders. In terms of the reconstruction target, given a masked input \(X_{i}\) with the i-th modality, M\(^{2}\)A\(^{2}\)E aims to predict the pixel values with mean squared error (MSE) loss for 1) each masked patch of \(X_{i}\), and 2) the whole input images of other modalities \(X_{j}\) (\(j\ne i; j\in {\text {RGB},\text {IR},\text {Depth}}\)). The motivation behind M\(^{2}\)A\(^{2}\)E is that with the multimodal reconstruction target, the self-supervised pre-trained ViTs are able to model (1) task-aware contextual semantics (e.g., moiré patterns and color distortion) via masked patch prediction; and (2) intrinsic physical features (e.g., 2D attacks without facial depth) via cross modality translation.
Relation to modality-symmetric autoencoders (He et al., 2022; Bachmann et al., 2022) Compared with the vanilla MAE (He et al., 2022), M\(^{2}\)A\(^{2}\)E adopts the same masked strategy in unimodal ViT encoder but targeting at multimodal reconstruction with multiple unshared ViT decoders. Besides, M\(^{2}\)A\(^{2}\)E is similar to the multimodal MAE (Bachmann et al., 2022) only when partial tokens from a single modality are visible while masking all tokens from other modalities (Fig. 3).

The framework of the modality-asymmetric masked autoencoder (M\(^{2}\)A\(^{2}\)E). Different from previous multimodal MAE (Bachmann et al., 2022) masking all modalities as inputs, our M\(^{2}\)A\(^{2}\)E randomly selects unimodal masked input for multimodal reconstruction
4 Experimental Evaluation
4.1 Datasets and Performance Metrics
Three commonly used multimodal FAS datasets are used for experiments, including WMCA (George et al., 2019), CASIA-SURF (Zhang et al., 2019b) and CASIA-SURF CeFA (CeFA) (Liu et al., 2021a). WMCA contains a wide variety of 2D and 3D PAs with four modalities, which introduces 2 protocols: ‘seen’ protocol which emulates the seen attack scenario and the ‘unseen’ attack protocol that evaluates the generalization on an unseen attack. CASIA-SURF consists of 1000 subjects with 21,000 videos, and each sample has 3 modalities, which has an official intra-testing protocol. CeFA is the largest multimodal FAS dataset, covering 3 ethnicities, 3 modalities, 1607 subjects, and 34,200 videos. We conduct intra- and cross-dataset testings on WMCA and CASIA-SURF datasets, and leave large-scale CeFA for self-supervised pre-training.

The training and inference pipeline of M\(^{2}\)A\(^{2}\)E and AMA modules. At Stage 1, M\(^{2}\)A\(^{2}\)E is used for multimodal self-supervised pre-training, and the ViT-based encoder and decoders are trainable. At Stage 2, the pre-trained encoder is fixed while only the AMA modules and the classification head are trainable when finetuning
In terms of evaluation metrics, Attack Presentation Classification Error Rate (APCER), Bonafide Presentation Classification Error Rate (BPCER), and ACER (international organization for standardization, 2016) are used for the metrics. The ACER on testing set is determined by the Equal Error Rate (EER) threshold on dev sets for CASIA-SURF, and the BPCER = 1% threshold for WMCA. True Positive Rate (TPR)@False Positive Rate (FPR) = 10\(^{-4}\) (Zhang et al., 2019b) is also provided for CASIA-SURF. For cross-testing experiments, Half Total Error Rate (HTER) is adopted.
4.2 Implementation Details
We crop the face frames using MTCNN (Zhang et al., 2016) face detector. The local descriptors are extracted from gray-scale images with: (1) \(3\times 3\) neighbors for LBP (Ojala et al., 2002; 2) 9 orientations, \(8\times 8\) pixels per cell, and \(2\times 2\) cells per block for HOG (Dalal & Triggs, 2005); and (3) the size of masks are set to 5 for PLGF (Bhattacharjee & Roy, 2019). Composition inputs ‘GRAY_HOG_PLGF’ are adopted on unimodal and multimodal experiments for IR modality, while the raw inputs are utilized for RGB and Depth modalities. ViT-Base (Dosovitskiy et al., 2021) supervised by binary cross-entropy loss is used as the defaulted architecture. For the direct finetuning, only the last transformer block and classification head are trainable. For AMA and ConvAdapter (Jie &, 2022) finetuning, the original and hidden channels are D=768 and \(D'\)=64, respectively. For M\(^{2}\)A\(^{2}\)E, the mask ratio p=40% is used while the decoder depth and width is 4 and 512, respectively. The training and inference pipeline of self-supervised pretraining with M\(^{2}\)A\(^{2}\)E pretraining and fine-tuning/inference with AMA modules are illustrated in Fig. 4.
The experiments are implemented with Pytorch on one NVIDIA A100 GPU. For the self-supervised pre-training on CeFA with RGB+IR+Depth modalities, we use the AdamW (Loshchilov &, 2017) optimizer with learning rate (lr) 1.5e−4, weight decay (wd) 0.05 and batch size 64 at the training stage. ImageNet pre-trained weights are used for our encoder. We train the M\(^{2}\)A\(^{2}\)E for 400 epochs while warming up the first 40 epochs, and then performing cosine decay. For supervised unimodal and multimodal experiments on WMCA and CASIA-SURF, we use the Adam optimizer with the fixed lr = 2e−4, wd = 5e−3 and batch size 16 at the training stage. We finetune models with maximum 30 epochs based on the ImageNet or M\(^{2}\)A\(^{2}\)E pre-trained weights.
4.3 Results of Unimodal and Multimodal FAS
Intra testing on WMCA The unimodal and multimodal results of protocols ‘seen’ and ‘unseen’ on WMCA (George et al., 2019) are shown in Table 1. On the one hand, compared with the direct finetuning results from ‘ViT’, the ViT+AMA/ConvAdapter can achieve significantly lower ACER in all modalities settings and both ‘seen’ and ‘unseen’ protocols. This indicates the proposed AMA efficiently leverages the unimodal/multimodal local inductive cues to boost original ViT’s global contextual features. On the other hand, when replaced the ImageNet pre-trained ViT with self-supervised M\(^{2}\)A\(^{2}\)E from CeFA, the generalization for unseen attack detection improves obviously with modalities ‘IR’, ‘Depth’, ‘RGB+IR’, ‘IR+Depth’, and ‘RGB+IR+Depth’, indicating its excellent transferability for downstream modality-agnostic tasks. It is surprising to find in the last block that the proposed methods with RGB+IR+Depth modalities perform even better than ‘MC-CNN’ (George et al., 2019) with four modalities in both ‘seen’ and ‘unseen’ protocols. With complex and specialized modules, although ‘MA-ViT’ (Liu &, 2022) outperforms the proposed methods with RGB+Depth modalities in ‘unseen’ protocol by \(-\)2.01% ACER, the proposed AMA and M\(^{2}\)A\(^{2}\)E might be potential to plug-and-play in ‘MA-ViT’ for further performance improvement.
Intra testing on CASIA-SURF For CASIA-SURF, we compare with three famous multimodal methods ‘SEF’ (Zhang et al., 2019b), ‘MS-SEF’ (Zhang et al., 2020), and ‘MA-ViT’ (Liu &, 2022). From Table 2, we can observe that the performance of ‘ViT’ is usually worse than ‘MS-SEF’ with multimodal settings due to the limited modality fusion ability. When equipped with AMA and M\(^{2}\)A\(^{2}\)E-based self-supervised pre-training, ‘ViT+AMA+M\(^{2}\)A\(^{2}\)E’ outperforms MS-SEF by a large margin in most modality settings (‘RGB’, ‘Depth’, ‘RGB+IR’, ‘RGB+Depth’, ‘RGB+IR+Depth’) in terms of ACER metrics. Thanks to the powerful multimodal representation capacity from the M\(^{2}\)A\(^{2}\)E pre-trained model, the proposed method surpasses the dedicated ‘MA-ViT’ with ‘RGB+IR+Depth’ modalities.
Cross-dataset testings To evaluate the unimodal and multimodal generalization, we conduct cross-testing experiments between models trained on CASIA-SURF and WMCA with Protocol ‘seen’. We also introduce the ‘MM-CDCN’ (Yu et al., 2020b) and ‘MA-ViT’ (Liu &, 2022) as baselines. Table 3 lists the HTER of all methods trained on one dataset and tested on another dataset. From these results, the proposed ‘ViT+AMA+M\(^{2}\)A\(^{2}\)E’ outperforms ‘MM-CDCN’ in most modality settings and ‘MA-ViT’ with ‘RGB+IR+Depth’ on both two cross-testing protocols, indicating that the learned multimodal features are robust to the sensors, resolutions, and attack types. Specifically, directly finetuning ImageNet pre-trained ViTs (see results of ‘ViT’) usually generalize worse than ‘MM-CDCN’ in multimodal settings. When assembling with AMA and M\(^{2}\)A\(^{2}\)E, the HTER can be further reduced 9.25%/5.38%/10.41%/10.59% and 4.96% / 4.13% / 8.64% / 4.38% for ‘RGB + IR’/‘RGB+Depth’/‘IR+Depth’/‘RGB+IR+Depth’ when tested on CASIA-SURF and WMCA, respectively.

Quantitative intra-testing results on WMCA with different modality-missing ratios under four flexible-modal settings

Quantitative intra-testing results on CASIA-SURF with different modality-missing ratios under four flexible-modal settings
4.4 Results of Flexible-Modal FAS
Following four flexible-modal sub-protocols (i.e., (1) RGB-D when missing depth; (2) RGB-IR when missing IR; (3) RGB-D-IR when missing overlapped depth and IR; and (4) RGB-D-IR when missing Depth and IR with limited complete RGB-DIR data or limited overlapped D-IR data.) in Yu et al. (2023a), we show results of missing modality ratio \(\alpha \)=70% on WMCA and CASIA-SURF datasets with our proposed methods and five baseline methods including vanilla multimodal ViT (ViT) (Dosovitskiy et al., 2021), visual prompt tuning (Prompt) (Jia et al., 2022), cross-modal focal loss (CMFL) (George & Marcel, 2021), cross attention (CrossAtten) (Yu et al., 2023b), and VP-FAS (Yu et al., 2023a).
Intra testing on WMCA As shown in Table 4, we find that the proposed ‘ViT+AMA’ consistently improves the state-of-the-art ‘VP-FAS’ by a convincing margin (at least 0.8% ACER decrease) in all the scenarios, indicating that using the adaptive multimodal adapter, without entire model finetuning, is able to represent rich modality-aware live/spoof cues while the adaptive modality weighting mechanism benefits modality-complementary relation modeling thus alleviating missing-modality issues. Besides, we also find from the results ‘ViT+AMA+M\(^{2}\)A\(^{2}\)E’ that pretraining with M\(^{2}\)A\(^{2}\)E further reduces at least 0.6% ACER in all missing-modality scenarios. It indicates that the modality-asymmetric masked modeling from large-scale unlabeled task-related data enhances cross-modal live/spoof intrinsic representation thus mitigating severe missing-modality degradation.

Results of direct finetuning on different transformer blocks

Impacts of inputs with local feature descriptors (e.g., LBP, HOG, PLGF) for ViT using direct finetuning and ConvAdapter strategies on a RGB, b IR, and c depth modalities
Intra testing on CASIA-SURF Similar to the results in WMCA, it can be seen from Table 5 that the proposed AMA outperforms ‘Prompt’, ‘CMFL’, ‘CrossAtten’ and ‘VP-FAS’ by large margins on the CASIA-SURF dataset under all flexible-modal settings, showing the effectiveness of adaptive multimodal parameter-efficient tuning. Different from other advanced multimodal learning strategies (i.e., ‘Prompt’, ‘CMFL’, ‘CrossAtten’, and ‘VP-FAS’) suffering poor performance under the flexible RGB-IR setting due to noisy IR imaging data in CASIA-SURF, the proposed AMA is robust even in this challenging scenario because of its reliable adaptive modality reweighting mechanism. Furthermore, it can be seen clearly from the results ‘ViT+AMA+M\(^{2}\)A\(^{2}\)E’ that pretraining with M\(^{2}\)A\(^{2}\)E enhances the robustness of multimodal feature representation especially on two flexible RGB-D-IR settings (more than 2% ACER decrease).
Robustness to different \(\alpha \) We also evaluate models’ robustness against missing modalities on WMCA and CASIA-SURF in four flexible-modal settings with different modality-missing ratios \(\alpha \). As shown in Fig. 5, we find that on WMCA, the proposed ‘ViT+AMA’ and ‘ViT+AMA+M\(^{2}\)A\(^{2}\)E’ are more robust to larger \(\alpha \), compared with the other baseline methods. Meanwhile, the performance gaps of the proposed and previous methods are clear on two flexible RGB-D-IR settings, indicating the efficacy of AMA and M\(^{2}\)A\(^{2}\)E for robust multimodal FAS feature representation. Moreover, we can find similar conclusions on CASIA-SURF from Fig. 6 that the proposed ‘ViT+AMA’ and ‘ViT+AMA+M\(^{2}\)A\(^{2}\)E’ are less sensitive to missing-modality scenarios. One highlight can be found from Fig. 6c, d that on CASIA-SURF, performance gaps among previous methods on two flexible RGB-D-IR settings are usually close due to the issue of low-quality complete-modality data in CASIA-SURF while the proposed ‘ViT+AMA+M\(^{2}\)A\(^{2}\)E’ outperform them by convincing margins.

Impacts of bimodal inputs with local feature descriptors (e.g., LBP, HOG, PLGF) for ViT using direct finetuning and adaptive multimodal adapter (AMA) strategies on a RGB+IR; b RGB+Depth; and c IR+Depth modalities. ‘Raw+HOG’ indicates ‘Raw’ input and ‘HOG’ input are used for the first and second modalities, respectively

Impacts of trimodal inputs with local feature descriptors for ViT using direct finetuning and AMA strategies on RGB+IR+Depth modalities. ‘Raw+HOG+Raw’ indicates ‘Raw’ input, ‘HOG’ input and ‘Raw’ input are respectively used for three modalities
4.5 Ablation Study
We provide the results of ablation studies for inputs with local descriptors and AMA on ‘seen’ protocol of WMCA to verify models’ discrimination. We then study M\(^{2}\)A\(^{2}\)E on ‘unseen’ protocol of WMCA and cross testing from WMCA to CASIA-SURF to verify models’ generalization capacity.
Ablation on direct finetuning Here we discuss five finetuning strategies for ImageNet pretrained ViT-Base including finetuning (1) all transformer blocks and classification head; (2) last 8 transformer blocks and classification head; (3) last 4 transformer blocks and classification head; (4) last transformer block and classification head; and (5) only classification head. The results on WMCA with Protocol ‘seen’ are shown in Fig. 7. The composition input ‘GRAY_HOG_PLGF’ is used for IR modality. It is clear that finetuning all transformer blocks perform the worst due to the overfitting issues in huge trainable parameters. In contrast, finetuning the last transformer block or last 8 transformer blocks can achieve stable and reasonable performance. We adopt the strategy of finetuning last transformer block and classification head as the defaulted direct finetuning setting due to its efficiency.
Impact of unimodal inputs with local descriptors In the default setting of ViT inputs, composition input ‘GRAY_HOG_PLGF’ is adopted on for IR modality, while the raw inputs are utilized for RGB and Depth modalities. In this ablation, we consider three local descriptors (‘LBP’ (Ojala et al., 2002), ‘HOG’ (Dalal & Triggs, 2005), ‘PLGF’ (Bhattacharjee & Roy, 2019)) and their compositions (‘HOG_PLGF’, ‘LBP_HOG_PLGF’, ‘GRAY_HOG_PLGF’). It can be seen from Fig. 8 that the ‘LBP’ input usually performs worse than other features for all three modalities. In contrast, the ‘PLGF’ input achieves reasonable performance (even better performance than raw input for IR modality via direct finetuning). It is clear that raw inputs are good enough for all modalities via ConvAdapter. One highlight is that composition input ‘GRAY_HOG_PLGF’ performs the best for IR modality via both direct finetuning and ConvAdapter, indicating the importance of local detailed and illumination invariant cues in IR feature representation.
Impact of multimodal inputs with local descriptors. In the default setting of ViT inputs, composition input ‘GRAY_HOG_PLGF’ is adopted on for IR modality, while the raw inputs are utilized for RGB and Depth modalities. Besides the unimodal input results with local descriptors in the main manuscript, we also demonstrate elaborate bimodal and trimodal results with local descriptors on WMCA with Protocol ‘seen’ in Figs. 9 and 10, respectively. Some observations can be found: (1) in the multimodal settings (RGB+IR, IR+Depth, and RGB+IR+Depth), the composition input ‘GRAY_HOG_PLGF’ for IR modality with raw inputs for other modalities performs the best via both direct finetuning and AMA; and (2) leveraging the local descriptor inputs for IR modality via direct finetuing, the performance on ‘IR+Depth’ and ‘RGB+IR+Depth’ are significantly improved compared with using all raw inputs. They all indicate the importance of local detailed and illumination invariant cues in IR feature representation (Fig. 11).

Ablation of the adapter types in transformer blocks

Detailed architectures of five possible adapter types for efficient multimodal learning, including a FC-based ‘vanilla adapter’ (Huang et al., 2022); b independent-modal ‘ConvAdapter’ (Jie &, 2022); c ‘multimodal ConvAdapter’ with \(\Theta _{\text {2D}}\) mapping channels \(D' \times K\) to \(D'\); d ‘multimodal ConvAdapter (huge)’ with \(\Theta _{\text {2D}}\) mapping channels \(D'\times K\) to \(D'\times K\); and e adaptive multimodal ConvAdapter (‘AMA’)
Impact of adapter types Here we discuss five possible adapter types for efficient multimodal learning, including FC-based ‘vanilla adapter’ (Huang et al., 2022), independent-modal ‘ConvAdapter’ (Jie &, 2022), ‘multimodal ConvAdapter’ with \(\Theta _{\text {2D}}\) mapping channels \(D'\times K\) to \(D'\), ‘multimodal ConvAdapter (huge)’ with \(\Theta _{\text {2D}}\) mapping channels \(D'\times K\) to \(D'\times K\), and adaptive multimodal ConvAdapter (‘AMA’). As shown in Fig. 12a, the FC-based ‘vanilla adapter’ (Huang et al., 2022) is the most efficient one but ignores the modality interaction as well as the local spatial context. In contrast, the independent-modal ‘ConvAdapter’ (Jie &, 2022) in Fig. 12b can benefit from the local spatial context. The ‘multimodal ConvAdapter’ with \(\Theta _{\text {2D}}\) mapping channels \(D'\times K\) to \(D'\) and ‘multimodal ConvAdapter (huge)’ with \(\Theta _{\text {2D}}\) mapping channels \(D'\times K\) to \(D'\times K\) are illustrated in Fig. 12c, d, respectively. They both can capture the multimodal spatial context. The former captures the modality-shared features and then copy & expand back to all modalities, which is more efficient. The latter directly generates interacted features for each modality. Compared with ‘multimodal ConvAdapter’, the proposed adaptive multimodal ConvAdapter (‘AMA’) can dynamically adjust the modality-shared features for each modality with negligible parameter increases.
As shown in Fig. 11, the ConvAdapter based modules perform significantly better than vanilla adapter in multimodal settings, indicating the local inductive biases benefit the ViT-based FAS. Moreover, compared with ‘ConvAdapter’, ‘multimodal ConvAdapter’ reduces more than 0.5% ACER in all multimodal settings via aggregating multimodal local features. In contrast, we cannot see any performance improvement from ‘multimodal ConvAdapter (huge)’. In other words, directly learning high-dimensional (\(D'\times K\)) convolutional features for all K modalities results in serious overfitting. Compared with ‘multimodal ConvAdapter’, AMA enhances the diversity of features for different modalities via adaptively weighting the shared low-dimensional (\(D'\)) convolutional features, which decreases 0.52, 0.31, 1.07, 0.07% ACER for ‘RGB+Depth’, ‘RGB+IR’, ‘IR+Depth’, ‘RGB+IR+Depth’, respectively.

Ablation of the hidden dimensions in AMA

Ablation of the AMA positions in transformer blocks
Impact of dimension and position of AMA Here we study the hidden dimensions \(D'\) in AMA and the impact of AMA positions in transformer blocks. It can be seen from Fig. 13 that despite more lightweight, lower dimensions (16 and 32) cannot achieve satisfactory performance due to weak representation capacity. The best performance can be achieved when \(D'=64\) in all multimodal settings. In terms of AMA positions, it is interesting to find from Fig. 14 that plugging AMA along FFN performs better than along MHSA in multimodal settings. This might be because the multimodal local features complement the limitation of point-wise receptive field in FFN. Besides, it is reasonable that applying AMA on MHSA+FFN performs the best.
Impact of mask ratio in M\(^{2}\)A\(^{2}\)E Fig. 15a illustrates the generalization of the M\(^{2}\)A\(^{2}\)E pre-trained ViT when finetuning on ‘unseen’ protocol of WMCA and cross testing from CASIA-SURF to WMCA. Different from the conclusions from (He et al., 2022; Bachmann et al., 2022) using very large mask ratio (e.g., 75 and 83%), we find that mask ratio ranges from 30 to 50% are suitable for multimodal FAS, and the best generalization performance on two testing protocols are achieved when mask ratio equals to 40%. In other words, extreme high mask ratios (e.g., 70–90%) might force the model to learn too semantic features but ignoring some useful low-/mid-level live/spoof cues.

Ablation of the a mask ratio; b self-supervision training epochs; and c decoder depth in M\(^{2}\)A\(^{2}\)E
Impact of training epochs and decoder depth in M\(^{2}\)A\(^{2}\)E We also investigate how the training epochs and decoder depth influence the M\(^{2}\)A\(^{2}\)E. As shown in Figs. 15b, c, training M\(^{2}\)A\(^{2}\)E with 400 epochs and decoder of 4 transformer blocks generalizes the best. More training iterations and deeper decoder are not always helpful due to the severe overfits on reconstruction targets.
Comparison between multimodal MAE (Bachmann et al., 2022) and M\(^{2}\)A\(^{2}\)E We also compare M\(^{2}\)A\(^{2}\)E with the symmetric multimodal MAE (Bachmann et al., 2022) when finetuning on all downstream modality settings. It can be seen from Fig. 16 that with more challenging reconstruction target (from masked unimodal inputs to multimodal prediction), M\(^{2}\)A\(^{2}\)E is outperforms the best settings of multimodal MAE (Bachmann et al., 2022) on most modalities (‘RGB’, ‘IR’, ‘RGB+IR’, ‘RGB+Depth’, ‘RGB+IR+Depth’), indicating its excellent downstream modality-agnostic capacity.

Results of the multimodal MAE (Bachmann et al., 2022) and our M\(^{2}\)A\(^{2}\)E

Visualization of the reconstructed multimodal faces from M\(^{2}\)A\(^{2}\)E with unimodal masked inputs on CeFA
4.6 Visualization and Discussion
Parameter efficiency of AMA. The proposed AMA is parameter-efficient, which respectively requires only 7.25 and 8.8% parameters to adapt pretrained ViT-Base models in two- and three-modality settings, thus avoiding finetuning heavy transformers.
Visualization of M\(^{2}\)A\(^{2}\)E We also conduct experiments to visualize the reconstruction results of the proposed M\(^{2}\)A\(^{2}\)E. As illustrated in Fig. 17, we find that even though with unimodal (40%) masked input, the reconstruction of all three modalities still keep some important live/spoof clues (e.g., convincing facial geometric depth predicted from masked RGB input for live samples while equivocal depth info for spoof ones), which benefits the self-supervised pre-training for generalized task-aware feature representation.
Comparison between self-Supervised learning (SSL) and supervised methods Here we show the results of SSL with multimodal MAE and M\(^{2}\)A\(^{2}\)E using linear probes. Specifically, we pretrain models on the training set of WMCA without using labels. Then the labeled data from WMCA are used for tuning the linear classification head only. The ACER of supervised SSL-MAE/SSL-M\(^{2}\)A\(^{2}\)E/ViT with RGB+IR+Depth on ‘seen’ and ‘unseen’ protocols are 4.08%/3.35%/2.52% and 8.6 ± 11.85%/7.72 ± 10.37%/6.46± 8.12%, respectively. It indicates the superiority of M\(^{2}\)A\(^{2}\)E over MAE despite performance gaps between SSL and supervised methods.

Ablation of local descriptors at the feature level

Ablation on various ViT structures
Exploration of local descriptors at the feature level Besides leveraging local descriptors at the input level, we also evaluate the results when merging the philosophy of local gradient difference clues into the feature-level adapters [e.g., AMA with CDC (Yu et al., 2020c) and with DCDCA (Cai et al., 2023)]. We can find from Fig. 18 that AMA-CDC (when hyperparameter \(\theta \) = 0.7) and AMA-DCDCA perform better or on par with the vanilla AMA in most multimodal settings. Compared with multimodal settings with Depth modality, AMA-CDC and AMA-DCDCA improves significantly on settings with IR modality using ‘GRAY_HOG_PLGF’ input, indicating the potential of combining local descriptors for multimodal ViT from both input level and feature level.
Discriminative capacity of M\(^{2}\)A\(^{2}\)E Despite generalized task-aware contextual semantics and intrinsic physical features representation via cross-modality translation, compared with supervised pretrained models via large-scale categories in ImageNet, the discriminative capacity of M\(^{2}\)A\(^{2}\)E is slightly limited. These phenomena can be observed from the results between ‘ViT+AMA (Ours)’ and ‘ViT+AMA+M\(^{2}\)A\(^{2}\)E (Ours)’ of ‘Modalities: RGB+IR, RGB+Depth, IR+Depth, and RGB+IR+Depth’ under ‘seen’ protocol of Table 1. The reason behind this might be M\(^{2}\)A\(^{2}\)E is conducted on the instance level but weak in mining contrastive and discriminative live/spoof clues across multiple instances. One possible solution is to introduce self-supervised contrastive learning (Cao et al., 2022) and design distillation-based strategy to improve the discriminative capacity of M\(^{2}\)A\(^{2}\)E models via teacher ImageNet pretrained models.
Generalization on various ViT structures Here we show the results on ‘seen’ protocol of WMCA with ‘Modalities: RGB+IR, RGB+Depth, IR+Depth, and RGB+IR+Depth’ using two more efficient backbones, which is edge-friendly and practical for real-world deployment. The results are shown in Fig. 19. We can find from the figure below that MobileViT-S (Mehta &, 2021) and SwinTransformer-S (Liu et al., 2021d) with AMA respectively achieve \(-2.08\)%/\(-3.41\)%/\(-3.26\)%/\(-1.47\)% and \(-1.99\)%/\(-3.11\)%/\(-3.05\)%/\(-1.58\)% ACER for RGB+Depth/RGB+IR/IR+Depth/RGB+IR+Depth modality settings, indicating the superiority and generalization of AMA on different ViT-based models.
Fairness of the evaluation protocols Please note that only ‘ViT+AMA+M\(^{2}\)A\(^{2}\)E’ needs self-supervised pertaining from CeFA. In other words, all results of ‘ViT+AMA’ are fairly compared with other methods without CeFA. The reasons we use CeFA for self-supervised pertaining are that (1) self-supervised pertaining usually conducts on large-scale unlabeled task-aware datasets; and (2) to use CeFA for pertaining can avoid data leakage on WMCA and CASIA-SURF. We also show the results of intra-dataset testings on WMCA and CASIA-SURF datasets when self-supervised pretrained on WMCA and CASIA-SURF, respectively. In this case, no extra datasets (e.g., CeFA) are introduced. ‘ViT+AMA+M\(^{2}\)A\(^{2}\)E’ with ‘RGB+IR+Depth’ modalities can achieve 1.16%, 3.43 ± 6.52%, and 0.56% ACER for ‘seen’ protocol WMCA, ‘unseen’ protocol WMCA, and CASIA-SURF, respectively.
5 Conclusions and Future Work
In this paper, we investigate three key factors (i.e., inputs, pretraining, and finetuning) for ViT-based multimodal FAS. We propose to combine local descriptors for IR inputs, and design modality-asymmetric masked autoencoder and adaptive multimodal adapter for efficient self-supervised pre-training and supervised finetuning for multimodal FAS. We note that the study of ViT-based multimodal FAS is still at an early stage. Future directions include: 1) Besides inputs, integrating local descriptors into transformer blocks (Yu et al., 2022) or adapters is potential for ViT-based multimodal FAS; 2) Besides generalization, the discriminative capacity of M\(^{2}\)A\(^{2}\)E pre-trained models should be improved.
Availability of data and material
The data from three public multimodal face anti-spoofing datasets (i.e., WMCA (George et al., 2019), CASIA-SURF (Zhang et al., 2019b) and CASIA-SURF CeFA (Liu et al., 2021a)) that support the findings of this study are available from the third party institutions (including Idiap Research Institute and Institute of Automation, Chinese Academy of Sciences) but restrictions apply to the availability of these data, which were used under license for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of the above-mentioned third-party institutions.
References
Akbari, H., Yuan, L., Qian, R., Chuang, W.-H., Chang, S.-F., Cui, Y., & Gong, B. (2021). Vatt: Transformers for multimodal self-supervised learning from raw video, audio and text. NeurIPS, 34, 24206–24221.
Atoum, Y., Liu, Y., Jourabloo, A., & Liu, X. (2017). Face anti-spoofing using patch and depth-based CNNs. In IJCB (pp. 319–328).
Bachmann, R., Mizrahi, D., Atanov, A., & Zamir, A. (2022). Multimae: Multi-modal multi-task masked autoencoders. In ECCV (pp. 348–367).
Bao, H., Dong, L., Piao, S., & Wei, F. (2021). Beit: Bert pre-training of image transformers. arXiv:2106.08254.
Bhattacharjee, D., & Roy, H. (2019). Pattern of local gravitational force (PLGF): A novel local image descriptor. IEEE TPMAI, 43(2), 595–607.
Boulkenafet, Z., Komulainen, J., & Hadid, A. (2015). Face anti-spoofing based on color texture analysis. In ICIP (pp. 2636–2640).
Boulkenafet, Z., Komulainen, J., & Hadid, A. (2017). Face antispoofing using speeded-up robust features and fisher vector encoding. IEEE SPL, 24(2), 141–145.
Cai, R., Cui, Y., Li, Z., Yu, Z., Li, H., Hu, Y., & Kot, A. (2023). Rehearsal-free domain continual face anti-spoofing: Generalize more and forget less. In ICCV (pp. 8037–8048).
Cao, J., Liu, Y., Ding, J., & Li, L. (2022). Self-supervised face anti-spoofing via anti-contrastive learning. In PRCV (pp. 479–491).
Chen, Z., Du, Y., Hu, J., Liu, Y., Li, G., Wan, X., & Chang, T.-H. (2022b). Multi-modal masked autoencoders for medical vision-and-language pre-training. In MICAI (pp. 679–689).
Chen, H., Tao, R., Zhang, H., Wang, Y., Ye, W., Wang, J., Hu, G., & Savvides, M. (2022a). Conv-adapter: Exploring parameter efficient transfer learning for convnets. arXiv:2208.07463.
Dalal, N., & Triggs, B. (2005). Histograms of oriented gradients for human detection. CVPR, 1, 886–893.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., Dehghani, M., Minderer, M., Heigold, G., & Gelly, S., & Uszkoreit, J. (2021). An image is worth \(16\times 16\) words: Transformers for image recognition at scale. In ICLR.
Gan, J., Li, S., Zhai, Y., & Liu, C. (2017). 3d convolutional neural network based on face anti-spoofing. In International conference on multimedia and image processing (ICMIP) (pp. 1–5).
George, A. & Marcel, S. (2019). Deep pixel-wise binary supervision for face presentation attack detection. In International conference on biometrics (ICB) (pp. 1–8).
George, A. & Marcel, S. (2020b). On the effectiveness of vision transformers for zero-shot face anti-spoofing. In IJCB (pp. 1–8).
George, A. & Marcel, S. (2021). Cross modal focal loss for RGBD face anti-spoofing. In CVPR (pp. 7882–7891).
George, A., & Marcel, S. (2020). Learning one class representations for face presentation attack detection using multi-channel convolutional neural networks. TIFS, 16, 361–375.
George, A., Mostaani, Z., Geissenbuhler, D., Nikisins, O., Anjos, A., & Marcel, S. (2019). Biometric face presentation attack detection with multi-channel convolutional neural network. TIFS, 15, 42–55.
He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2022). Masked autoencoders are scalable vision learners. In CVPR (pp. 16000–16009).
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Gesmundo, A., Attariyan, M., & Gelly, S. (2019). Parameter-efficient transfer learning for NLP. In ICML (pp. 2790–2799).
Huang, H.-P., Sun, D., Liu, Y., Chu, W.-S., Xiao, T., Yuan, J., Adam, H., & Yang, M.-H. (2022). Adaptive transformers for robust few-shot cross-domain face anti-spoofing. In ECCV (pp. 37–54).
international organization for standardization (2016). Iso/iec jtc 1/sc 37 biometrics: Information technology biometric presentation attack detection part 1: Framework. https://www.iso.org/obp/ui/iso.
Jia, M., Tang, L., Chen, B.-C., Cardie, C., Belongie, S., Hariharan, B., & Lim, S.-N. (2022). Visual prompt tuning. In ECCV (pp. 709–727).
Jie, S. & Deng, Z.-H. (2022). Convolutional bypasses are better vision transformer adapters. arXiv:2207.07039.
Komulainen, J., Hadid, A., & Pietikainen, M. (2013). Context based face anti-spoofing. In BTAS (pp. 1–8).
Li, L. & Feng, X. (2019). Face anti-spoofing via deep local binary pattern. In Deep learning in object detection and recognition (pp. 91–111). Springer.
Li, Z., Li, H., Luo, X., Hu, Y., Lam, K.-Y., & Kot, A. C. (2021). Asymmetric modality translation for face presentation attack detection. IEEE TMM, 25, 62–76.
Liu, A. & Liang, Y. (2022). Ma-vit: Modality-agnostic vision transformers for face anti-spoofing. In IJCAI (pp. 1180–1186).
Liu, Y., Jourabloo, A., & Liu, X. (2018). Learning deep models for face anti-spoofing: Binary or auxiliary supervision. In CVPR (pp. 389–398).
Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., & Guo, B. (2021d). Swin transformer: Hierarchical vision transformer using shifted windows. In ICCV (pp. 10012–10022).
Liu, A., Tan, Z., Wan, J., Escalera, S., Guo, G., & Li, S. Z. (2021a). Casia-surf cefa: A benchmark for multi-modal cross-ethnicity face anti-spoofing. In WACV.
Liu, A., Tan, Z., Wan, J., Liang, Y., Lei, Z., Guo, G., & Li, S. Z. (2021). Face anti-spoofing via adversarial cross-modality translation. TIFS, 16, 2759–2772.
Liu, A., Tan, Z., Yu, Z., Zhao, C., Wan, J., Lei, Y. L. Z., Zhang, D., Li, S. Z., & Guo, G. (2023). Fm-vit: Flexible modal vision transformers for face anti-spoofing. IEEE TIFS, 18, 4775–4786.
Liu, W., Wei, X., Lei, T., Wang, X., Meng, H., & Nandi, A. K. (2021). Data fusion based two-stage cascade framework for multi-modality face anti-spoofing. TCDS, 14(2), 672–683.
Liu, A., Zhao, C., Yu, Z., Wan, J., Su, A., Liu, X., Tan, Z., Escalera, S., Xing, J., Liang, Y., et al. (2022). Contrastive context-aware learning for 3d high-fidelity mask face presentation attack detection. TIFS, 17, 2497–2507.
Loshchilov, I. & Hutter, F. (2017). Decoupled weight decay regularization. arXiv:1711.05101.
Ma, X., Zhang, J., Zhang, Y., & Zhou, D. (2022). Exploring masked image modeling for face anti-spoofing. In PRCV (pp. 814–826).
Mehta, S. & Rastegari, M. (2021). Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv:2110.02178.
Ming, Z., Yu, Z., Al-Ghadi, M., Visani, M., Luqman, M. M., & Burie, J.-C. (2022). Vitranspad: Video transformer using convolution and self-attention for face presentation attack detection. In ICIP (pp. 4248–4252).
Muhammad, U., Yu, Z., & Komulainen, J. (2022). Self-supervised 2d face presentation attack detection via temporal sequence sampling. Pattern Recognition Letters, 156, 15–22.
Nikisins, O., George, A., & Marcel, S. (2019). Domain adaptation in multi-channel autoencoder based features for robust face anti-spoofing. In International conference on biometrics (ICB) (pp. 1–8). IEEE.
Ojala, T., Pietikainen, M., & Maenpaa, T. (2002). Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE TPAMI, 24(7), 971–987.
Patel, K., Han, H., & Jain, A. K. (2016). Secure face unlock: Spoof detection on smartphones. TIFS, 11(10), 2268–2283.
Qin, Y., Zhao, C., Zhu, X., Wang, Z., Yu, Z., Fu, T., Zhou, F., Shi, J., & Lei, Z. (2020). Learning meta model for zero-and few-shot face anti-spoofing. Proceedings of the AAAI Conference on Artificial Intelligence, 34, 11916–11923.
Shen, T., Huang, Y., & Tong, Z. (2019). Facebagnet: Bag-of-local-features model for multi-modal face anti-spoofing. In CVPRW.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł, & Polosukhin, I. (2017). Attention is all you need. NIPS, 30, 6000–6010.
Wang, Z., Wang, Q., Deng, W., & Guo, G. (2022). Face anti-spoofing using transformers with relation-aware mechanism. TBIOM, 4(3), 439–450.
Wang, Z., Wang, Q., Deng, W., & Guo, G. (2022). Learning multi-granularity temporal characteristics for face anti-spoofing. IEEE TIFS, 17, 1254–1269.
Wang, W., Wen, F., Zheng, H., Ying, R., & Liu, P. (2022). Conv-MLP: A convolution and MLP mixed model for multimodal face anti-spoofing. IEEE TIFS, 17, 2284–2297.
Xiao, T., Singh, M., Mintun, E., Darrell, T., Dollár, P., & Girshick, R. (2021). Early convolutions help transformers see better. NeurIPS, 34, 30392–30400.
Xie, Z., Zhang, Z., Cao, Y., Lin, Y., Bao, J., Yao, Z., Dai, Q., & Hu, H. (2022). Simmim: A simple framework for masked image modeling. In CVPR (pp. 9653–9663).
Yang, X., Luo, W., Bao, L., Gao, Y., Gong, D., Zheng, S., Li, Z., & Liu, W. (2019). Face anti-spoofing: Model matters, so does data. In CVPR, (pp. 3507–3516).
Yu, Z., Cai, R., Cui, Y., Liu, A., & Chen, C. (2023a). Visual prompt flexible-modal face anti-spoofing. arXiv:2307.13958.
Yu, Z., Li, X., Niu, X., Shi, J., & Zhao, G. (2020a). Face anti-spoofing with human material perception. In ECCV (pp. 557–575).
Yu, Z., Liu, A., Zhao, C., Cheng, K. H., Cheng, X., & Zhao, G. (2023b). Flexible-modal face anti-spoofing: A benchmark. In CVPRW (pp. 6345–6350).
Yu, Z., Qin, Y., Li, X., Wang, Z., Zhao, C., Lei, Z., & Zhao, G. (2020b). Multi-modal face anti-spoofing based on central difference networks. In CVPRW (pp. 650–651).
Yu, Z., Qin, Y., Zhao, H., Li, X., & Zhao, G. (2021b). Dual-cross central difference network for face anti-spoofing. In IJCAI (pp. 1281–1287).
Yu, Z., Shen, Y., Shi, J., Zhao, H., Torr, P. H., & Zhao, G. (2022). Physformer: Facial video-based physiological measurement with temporal difference transformer. In CVPR (pp. 4186–4196).
Yu, Z., Zhao, C., Wang, Z., Qin, Y., Su, Z., Li, X., Zhou, F., & Zhao, G. (2020c). Searching central difference convolutional networks for face anti-spoofing. In CVPR (pp. 5295–5305).
Yu, Z., Li, X., Wang, P., & Zhao, G. (2021). Transrppg: Remote photoplethysmography transformer for 3d mask face presentation attack detection. IEEE SPL, 28, 1290-1294.
Zhang, S., Wang, X., Liu, A., Zhao, C., Wan, J., Escalera, S., Shi, H., Wang, Z., & Li, S. Z. (2019b). A dataset and benchmark for large-scale multi-modal face anti-spoofing. In CVPR.
Zhang, P., Zou, F., Wu, Z., Dai, N., Mark, S., Fu, M., Zhao, J., & Li, K. (2019a). Feathernets: Convolutional neural networks as light as feather for face anti-spoofing. In CVPRW.
Zhang, S., Liu, A., Wan, J., Liang, Y., Guo, G., Escalera, S., Escalante, H. J., & Li, S. Z. (2020). Casia-surf: A large-scale multi-modal benchmark for face anti-spoofing. TBIOM, 2(2), 182–193.
Zhang, K., Zhang, Z., Li, Z., & Qiao, Y. (2016). Joint face detection and alignment using multitask cascaded convolutional networks. IEEE SPL, 23(10), 1499–1503.
Zhou, K., Yang, J., Loy, C. C., & Liu, Z. (2022). Learning to prompt for vision-language models. In: IJCV.
Acknowledgements
This work was supported by Open Fund of National Engineering Laboratory for Big Data System Computing Technology (Grant No. SZU-BDSC-OF2024-02), National Natural Science Foundation of China under Grant 62306061 and 62171309, and Science and Technology Foundation of Guangzhou Huangpu Development District under Grant 2022GH15. This work is also supported in part by the Rapid-Rich Object Search (ROSE) Lab of Nanyang Technological University and the NTU-PKU Joint Research Institute (a collaboration between NTU and Peking University that is sponsored by a donation from the Ng Teng Fong Charitable Foundation).
Funding
Open Access funding provided by University of Oulu (including Oulu University Hospital).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Segio Escalera.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yu, Z., Cai, R., Cui, Y. et al. Rethinking Vision Transformer and Masked Autoencoder in Multimodal Face Anti-Spoofing. Int J Comput Vis (2024). https://doi.org/10.1007/s11263-024-02055-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11263-024-02055-1