
Abstract
Transformer architectures have brought about fundamental changes to computational linguistic field, which had been dominated by recurrent neural networks for many years. Its success also implies drastic changes in cross-modal tasks with language and vision, and many researchers have already tackled the issue. In this paper, we review some of the most critical milestones in the field, as well as overall trends on how transformer architecture has been incorporated into visuolinguistic cross-modal tasks. Furthermore, we discuss its current limitations and speculate upon some of the prospects that we find imminent.



Similar content being viewed by others

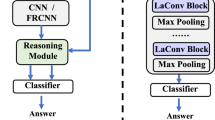

Notes
Note that attention mechanism referred to here, while nearly identical in its motivation, deviates from the same term employed in transformer architecture, and must not be confused with the works that do employ transformer architecture to tackle the same task, which will be introduced in Sect. 4
References
Abu-El-Haija, S., Kothari, N., Lee, J., Natsev, P., Toderici, G., Varadarajan, B., Vijayanarasimhan, S. (2016), Youtube-8m: A large-scale video classification benchmark. CoRR abs/1609.08675, http://arxiv.org/abs/1609.08675, 1609.08675
Agrawal P, Carreira J, Malik J (2015) Learning to see by moving. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Akbari H, Yuan L, Qian R, Chuang W, Chang S, Cui Y, Gong B (2021) VATT: transformers for multimodal self-supervised learning from raw video, audio and text. CoRR abs/2104.11178, https://arxiv.org/abs/2104.11178, 2104.11178
Alberti C, Ling J, Collins M, Reitter D (2019) Fusion of detected objects in text for visual question answering. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hong Kong, China, pp 2131–2140, https://doi.org/10.18653/v1/D19-1219, https://www.aclweb.org/anthology/D19-1219
Anderson P, Fernando B, Johnson M, Gould S (2016) Spice: Semantic propositional image caption evaluation. In: ECCV
Antol S, Agrawal A, Lu J, Mitchell M, Batra D, Zitnick CL, Parikh D (2015) Vqa: Visual question answering. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Ba JL, Kiros JR, Hinton GE (2016) Layer normalization. 1607.06450
Banerjee S, Lavie A (2005) METEOR: An automatic metric for MT evaluation with improved correlation with human judgments. In: Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, Association for Computational Linguistics, Ann Arbor, Michigan, pp 65–72, https://www.aclweb.org/anthology/W05-0909
Barbu A, Bridge A, Burchill Z, Coroian D, Dickinson S, Fidler S, Michaux A, Mussman S, Narayanaswamy S, Salvi D, Schmidt L, Shangguan J, Siskind JM, Waggoner J, Wang S, Wei J, Yin Y, Zhang Z (2012) Video in sentences out. 1204.2742
Ben-younes H, Cadene R, Cord M, Thome N (2017) Mutan: Multimodal tucker fusion for visual question answering. 1705.06676
Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P, Neelakantan A, Shyam P, Sastry G, Askell A, Agarwal S, Herbert-Voss A, Krueger G, Henighan T, Child R, Ramesh A, Ziegler D, Wu J, Winter C, Hesse C, Chen M, Sigler E, Litwin M, Gray S, Chess B, Clark J, Berner C, McCandlish S, Radford A, Sutskever I, Amodei D (2020) Language models are few-shot learners. In: Larochelle H, Ranzato M, Hadsell R, Balcan MF, Lin H (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 33, pp 1877–1901, https://proceedings.neurips.cc/paper/2020/file/1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
Carion N, Massa F, Synnaeve G, Usunier N, Kirillov A, Zagoruyko S (2020) End-to-end object detection with transformers. 2005.12872
Chang WC, Yu FX, Chang YW, Yang Y, Kumar S (2020) Pre-training tasks for embedding-based large-scale retrieval. In: International Conference on Learning Representations, https://openreview.net/forum?id=rkg-mA4FDr
Chen H, Wang Y, Guo T, Xu C, Deng Y, Liu Z, Ma S, Xu C, Xu C, Gao W (2020a) Pre-trained image processing transformer. 2012.00364
Chen M, Radford A, Child R, Wu J, Jun H, Luan D, Sutskever I (2020b) Generative pretraining from pixels. In: III HD, Singh A (eds) Proceedings of the 37th International Conference on Machine Learning, PMLR, Proceedings of Machine Learning Research, vol 119, pp 1691–1703, http://proceedings.mlr.press/v119/chen20s.html
Chen YC, Li L, Yu L, Kholy AE, Ahmed F, Gan Z, Cheng Y, Liu J (2020c) Uniter: Universal image-text representation learning. In: ECCV
Child R, Gray S, Radford A, Sutskever I (2019) Generating long sequences with sparse transformers. CoRR abs/1904.10509, http://arxiv.org/abs/1904.10509, 1904.10509
Cho K, van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y (2014) Learning phrase representations using RNN encoder–decoder for statistical machine translation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Doha, Qatar, pp 1724–1734, https://doi.org/10.3115/v1/D14-1179, https://www.aclweb.org/anthology/D14-1179
Dai B, Fidler S, Urtasun R, Lin D (2017) Towards diverse and natural image descriptions via a conditional gan. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Dai Z, Yang Z, Yang Y, Carbonell J, Le Q, Salakhutdinov R (2019) Transformer-XL: Attentive language models beyond a fixed-length context. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Florence, Italy, pp 2978–2988, https://doi.org/10.18653/v1/P19-1285, https://www.aclweb.org/anthology/P19-1285
Das P, Xu C, Doell RF, Corso JJ (2013) A thousand frames in just a few words: Lingual description of videos through latent topics and sparse object stitching. 2013 IEEE Conference on Computer Vision and Pattern Recognition pp 2634–2641
Devlin J, Chang MW, Lee K, Toutanova K (2019) BERT: Pre-training of deep bidirectional transformers for language understanding. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Association for Computational Linguistics, Minneapolis, Minnesota, pp 4171–4186, https://doi.org/10.18653/v1/N19-1423, https://www.aclweb.org/anthology/N19-1423
Donahue J, Hendricks LA, Guadarrama S, Rohrbach M, Venugopalan S, Saenko K, Darrell T (2014) Long-term recurrent convolutional networks for visual recognition and description. CoRR abs/1411.4389, http://arxiv.org/abs/1411.4389, 1411.4389
Dong L, Xu S, Xu B (2018) Speech-transformer: A no-recurrence sequence-to-sequence model for speech recognition. In: 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp 5884–5888, 10.1109/ICASSP.2018.8462506
Dosovitskiy A, Beyer L, Kolesnikov A, Weissenborn D, Zhai X, Unterthiner T, Dehghani M, Minderer M, Heigold G, Gelly S, Uszkoreit J, Houlsby N (2020) An image is worth 16x16 words: Transformers for image recognition at scale. 2010.11929
Dufter P, Schmitt M, Schütze H (2021) Position information in transformers: An overview. CoRR abs/2102.11090, https://arxiv.org/abs/2102.11090, 2102.11090
Elliott D, Keller F (2013) Image description using visual dependency representations. In: Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Seattle, Washington, USA, pp 1292–1302, https://www.aclweb.org/anthology/D13-1128
Elman, J. L. (1990). Finding structure in time. COGNITIVE SCIENCE, 14(2), 179–211.
Farhadi A, Hejrati M, Sadeghi M, Young P, Rashtchian C, Hockenmaier J, Forsyth D (2010) Every picture tells a story: Generating sentences from images. In: Computer Vision, ECCV 2010 - 11th European Conference on Computer Vision, Proceedings, Springer-Verlag Berlin Heidelberg, no. PART 4 in Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), pp 15–29, 10.1007/978-3-642-15561-1_2, copyright: Copyright 2019 Elsevier B.V., All rights reserved.; 11th European Conference on Computer Vision, ECCV 2010 ; Conference date: 10-09-2010 Through 11-09-2010
Fedus W, Zoph B, Shazeer N (2021) Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. 2101.03961
Fukui A, Park DH, Yang D, Rohrbach A, Darrell T, Rohrbach M (2016) Multimodal compact bilinear pooling for visual question answering and visual grounding. In: Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Austin, Texas, pp 457–468, https://doi.org/10.18653/v1/D16-1044, https://www.aclweb.org/anthology/D16-1044
Gabeur V, Sun C, Alahari K, Schmid C (2020) Multi-modal Transformer for Video Retrieval. In: European Conference on Computer Vision (ECCV)
Gella S, Lewis M, Rohrbach M (2018) A dataset for telling the stories of social media videos. In: Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Association for Computational Linguistics, Brussels, Belgium, pp 968–974, https://doi.org/10.18653/v1/D18-1117, https://www.aclweb.org/anthology/D18-1117
Gillick D, Presta A, Tomar GS (2018) End-to-end retrieval in continuous space. CoRR abs/1811.08008, http://arxiv.org/abs/1811.08008, 1811.08008
Ging S, Zolfaghari M, Pirsiavash H, Brox T (2020) Coot: Cooperative hierarchical transformer for video-text representation learning. 2011.00597
Girshick R (2015) Fast r-cnn. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y (2014) Generative adversarial nets. In: Ghahramani Z, Welling M, Cortes C, Lawrence N, Weinberger KQ (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 27, pp 2672–2680, https://proceedings.neurips.cc/paper/2014/file/5ca3e9b122f61f8f06494c97b1afccf3-Paper.pdf
Goyal Y, Khot T, Summers-Stay D, Batra D, Parikh D (2017) Making the V in VQA matter: Elevating the role of image understanding in Visual Question Answering. In: Conference on Computer Vision and Pattern Recognition (CVPR)
Guo J, Zhu C, Zhao Y, Wang H, Hu Y, He X, Cai D (2020) Lamp: Label augmented multimodal pretraining. 2012.04446
Han K, Wang Y, Chen H, Chen X, Guo J, Liu Z, Tang Y, Xiao A, Xu C, Xu Y, Yang Z, Zhang Y, Tao D (2021) A survey on visual transformer. 2012.12556
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp 770–778, 10.1109/CVPR.2016.90
Heilbron FC, Escorcia V, Ghanem B, Niebles JC (2015) Activitynet: A large-scale video benchmark for human activity understanding. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp 961–970, 10.1109/CVPR.2015.7298698
Hendrycks D, Gimpel K (2016) Bridging nonlinearities and stochastic regularizers with gaussian error linear units. CoRR abs/1606.08415, http://arxiv.org/abs/1606.08415, 1606.08415
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9(8), 1735–1780.
Hodosh, M., Young, P., & Hockenmaier, J. (2013). Framing image description as a ranking task: Data, models and evaluation metrics. J Artif Intell Res, 47, 853–899.
Hu R, Singh A (2021) Transformer is all you need: Multimodal multitask learning with a unified transformer. CoRR abs/2102.10772, https://arxiv.org/abs/2102.10772, 2102.10772
Huang G, Pang B, Zhu Z, Rivera C, Soricut R (2020a) Multimodal pretraining for dense video captioning. In: Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing, Association for Computational Linguistics, Suzhou, China, pp 470–490, https://www.aclweb.org/anthology/2020.aacl-main.48
Huang Z, Zeng Z, Liu B, Fu D, Fu J (2020b) Pixel-bert: Aligning image pixels with text by deep multi-modal transformers. 2004.00849
Hudson DA, Manning CD (2019) Gqa: A new dataset for real-world visual reasoning and compositional question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Jiao X, Yin Y, Shang L, Jiang X, Chen X, Li L, Wang F, Liu Q (2020) Tinybert: Distilling bert for natural language understanding. https://openreview.net/forum?id=rJx0Q6EFPB
Johnson J, Karpathy A, Fei-Fei L (2016) Densecap: Fully convolutional localization networks for dense captioning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Karpathy A, Li F (2014) Deep visual-semantic alignments for generating image descriptions. CoRR abs/1412.2306, http://arxiv.org/abs/1412.2306, 1412.2306
Karpathy A, Toderici G, Shetty S, Leung T, Sukthankar R, Fei-Fei L (2014) Large-scale video classification with convolutional neural networks. In: CVPR
Karras T, Laine S, Aila T (2019) A style-based generator architecture for generative adversarial networks. In: 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp 4396–4405, 10.1109/CVPR.2019.00453
Karras T, Laine S, Aittala M, Hellsten J, Lehtinen J, Aila T (2020) Analyzing and improving the image quality of stylegan. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Kazemzadeh S, Ordonez V, Matten M, Berg T (2014) ReferItGame: Referring to objects in photographs of natural scenes. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Doha, Qatar, pp 787–798, https://doi.org/10.3115/v1/D14-1086, https://www.aclweb.org/anthology/D14-1086
Kervadec C, Antipov G, Baccouche M, Wolf C (2019) Weak supervision helps emergence of word-object alignment and improves vision-language tasks. 1912.03063
Khan S, Naseer M, Hayat M, Zamir SW, Khan FS, Shah M (2021) Transformers in vision: A survey. 2101.01169
Kim JH, On KW, Lim W, Kim J, Ha JW, Zhang BT (2017) Hadamard product for low-rank bilinear pooling. 1610.04325
Kim W, Son B, Kim I (2021) Vilt: Vision-and-language transformer without convolution or region supervision. 2102.03334
Kingma DP, Welling M (2014) Auto-Encoding Variational Bayes. In: 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, April 14-16, 2014, Conference Track Proceedings, http://arxiv.org/abs/1312.6114v10
Kiros R, Zhu Y, Salakhutdinov R, Zemel RS, Torralba A, Urtasun R, Fidler S (2015) Skip-thought vectors. 1506.06726
Kitaev N, Kaiser L, Levskaya A (2020) Reformer: The efficient transformer. In: International Conference on Learning Representations, https://openreview.net/forum?id=rkgNKkHtvB
Korbar B, Petroni F, Girdhar R, Torresani L (2020) Video understanding as machine translation. 2006.07203
Krishna R, Zhu Y, Groth O, Johnson J, Hata K, Kravitz J, Chen S, Kalanditis Y, Li LJ, Shamma DA, Bernstein M, Fei-Fei L (2016) Visual genome: Connecting language and vision using crowdsourced dense image annotations
Krizhevsky A, Sutskever I, Hinton GE (2012) Imagenet classification with deep convolutional neural networks. In: Pereira F, Burges CJC, Bottou L, Weinberger KQ (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 25, pp 1097–1105, https://proceedings.neurips.cc/paper/2012/file/c399862d3b9d6b76c8436e924a68c45b-Paper.pdf
LeCun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. In: Proceedings of the IEEE, vol 86, pp 2278–2324, http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.42.7665
Lei J, Li L, Zhou L, Gan Z, Berg TL, Bansal M, Liu J (2021) Less is more: Clipbert for video-and-language learning via sparse sampling. 2102.06183
Li C, Yan M, Xu H, Luo F, Wang W, Bi B, Huang S (2021a) Semvlp: Vision-language pre-training by aligning semantics at multiple levels. https://openreview.net/forum?id=Wg2PSpLZiH
Li, G., Duan, N., Fang, Y., Gong, M., & Jiang, D. (2020a). Unicoder-vl: A universal encoder for vision and language by cross-modal pre-training. Proceedings of the AAAI Conference on Artificial Intelligence, 34(07), 11336–11344. https://doi.org/10.1609/aaai.v34i07.6795, https://ojs.aaai.org/index.php/AAAI/article/view/6795
Li L, Chen YC, Cheng Y, Gan Z, Yu L, Liu J (2020b) Hero: Hierarchical encoder for video+language omni-representation pre-training. 2005.00200
Li LH, Yatskar M, Yin D, Hsieh CJ, Chang KW (2019) Visualbert: A simple and performant baseline for vision and language. In: Arxiv
Li X, Yin X, Li C, Zhang P, Hu X, Zhang L, Wang L, Hu H, Dong L, Wei F, Choi Y, Gao J (2020c) Oscar: Object-semantics aligned pre-training for vision-language tasks. 2004.06165
Li X, Zhang Y, Liu C, Shuai B, Zhu Y, Brattoli B, Chen H, Marsic I, Tighe J (2021b) Vidtr: Video transformer without convolutions. CoRR abs/2104.11746, https://arxiv.org/abs/2104.11746, 2104.11746
Lin CY (2004) ROUGE: A package for automatic evaluation of summaries. In: Text Summarization Branches Out, Association for Computational Linguistics, Barcelona, Spain, pp 74–81, https://www.aclweb.org/anthology/W04-1013
Lin J, Yang A, Zhang Y, Liu J, Zhou J, Yang H (2021) M6-v0: Vision-and-language interaction for multi-modal pretraining. 2003.13198
Lin TY, Maire M, Belongie S, Bourdev L, Girshick R, Hays J, Perona P, Ramanan D, Zitnick CL, Dollár P (2014) Microsoft coco: Common objects in context. http://arxiv.org/abs/1405.0312, cite arxiv:1405.0312Comment: 1) updated annotation pipeline description and figures; 2) added new section describing datasets splits; 3) updated author list
Liu X, He P, Chen W, Gao J (2019a) Multi-task deep neural networks for natural language understanding. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Florence, Italy, pp 4487–4496, https://doi.org/10.18653/v1/P19-1441, https://www.aclweb.org/anthology/P19-1441
Liu Y, Ott M, Goyal N, Du J, Joshi M, Chen D, Levy O, Lewis M, Zettlemoyer L, Stoyanov V (2019b) Roberta: A robustly optimized bert pretraining approach. http://arxiv.org/abs/1907.11692, cite arxiv:1907.11692
Lu J, Yang J, Batra D, Parikh D (2016) Hierarchical question-image co-attention for visual question answering. In: Lee D, Sugiyama M, Luxburg U, Guyon I, Garnett R (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 29, pp 289–297, https://proceedings.neurips.cc/paper/2016/file/9dcb88e0137649590b755372b040afad-Paper.pdf
Lu J, Batra D, Parikh D, Lee S (2019) Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. In: Wallach H, Larochelle H, Beygelzimer A, d’Alché-Buc F, Fox E, Garnett R (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 32, pp 13–23, https://proceedings.neurips.cc/paper/2019/file/c74d97b01eae257e44aa9d5bade97baf-Paper.pdf
Luo F, Yang P, Li S, Ren X, Sun X (2020a) Capt: Contrastive pre-training for learning denoised sequence representations. 2010.06351
Luo H, Ji L, Shi B, Huang H, Duan N, Li T, Li J, Bharti T, Zhou M (2020b) Univl: A unified video and language pre-training model for multimodal understanding and generation. 2002.06353
Miech A, Zhukov D, Alayrac JB, Tapaswi M, Laptev I, Sivic J (2019) HowTo100M: Learning a Text-Video Embedding by Watching Hundred Million Narrated Video Clips. In: ICCV
Mikolov T, Sutskever I, Chen K, Corrado GS, Dean J (2013) Distributed representations of words and phrases and their compositionality. In: Burges CJC, Bottou L, Welling M, Ghahramani Z, Weinberger KQ (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 26, pp 3111–3119, https://proceedings.neurips.cc/paper/2013/file/9aa42b31882ec039965f3c4923ce901b-Paper.pdf
Miller, G. A. (1995). Wordnet: A lexical database for english. COMMUNICATIONS OF THE ACM, 38, 39–41.
Ordonez V, Kulkarni G, Berg T (2011) Im2text: Describing images using 1 million captioned photographs. In: Shawe-Taylor J, Zemel R, Bartlett P, Pereira F, Weinberger KQ (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 24, pp 1143–1151, https://proceedings.neurips.cc/paper/2011/file/5dd9db5e033da9c6fb5ba83c7a7ebea9-Paper.pdf
Papineni K, Roukos S, Ward T, Zhu WJ (2002) Bleu: a method for automatic evaluation of machine translation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Philadelphia, Pennsylvania, USA, pp 311–318, https://doi.org/10.3115/1073083.1073135, https://www.aclweb.org/anthology/P02-1040
Parmar N, Vaswani A, Uszkoreit J, Łukasz Kaiser, Shazeer N, Ku A, Tran D (2018) Image transformer. 1802.05751
Patashnik O, Wu Z, Shechtman E, Cohen-Or D, Lischinski D (2021) Styleclip: Text-driven manipulation of stylegan imagery. CoRR abs/2103.17249, https://arxiv.org/abs/2103.17249, 2103.17249
Pennington J, Socher R, Manning C (2014) GloVe: Global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Association for Computational Linguistics, Doha, Qatar, pp 1532–1543, https://doi.org/10.3115/v1/D14-1162, https://www.aclweb.org/anthology/D14-1162
Peters M, Neumann M, Iyyer M, Gardner M, Clark C, Lee K, Zettlemoyer L (2018) Deep contextualized word representations. In: Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), Association for Computational Linguistics, New Orleans, Louisiana, pp 2227–2237, https://doi.org/10.18653/v1/N18-1202, https://www.aclweb.org/anthology/N18-1202
Qi D, Su L, Song J, Cui E, Bharti T, Sacheti A (2020) Imagebert: Cross-modal pre-training with large-scale weak-supervised image-text data. 2001.07966
Radford A, Sutskever I (2018) Improving language understanding by generative pre-training. In: arxiv
Radford A, Wu J, Child R, Luan D, Amodei D, Sutskever I (2019) Language Models are Unsupervised Multitask Learners https://openai.com/blog/better-language-models/
Radford A, Kim JW, Hallacy C, Ramesh A, Goh G, Agarwal S, Sastry G, Askell A, Mishkin P, Clark J, Krueger G, Sutskever I (2021) Learning transferable visual models from natural language supervision. 2103.00020
Ramesh A, Pavlov M, Goh G, Gray S, Voss C, Radford A, Chen M, Sutskever I (2021) Zero-shot text-to-image generation. 2102.12092
Reed S, Akata Z, Yan X, Logeswaran L, Schiele B, Lee H (2016) Generative adversarial text-to-image synthesis. In: Proceedings of The 33rd International Conference on Machine Learning
Ren S, He K, Girshick R, Sun J (2015) Faster r-cnn: Towards real-time object detection with region proposal networks. In: Cortes C, Lawrence N, Lee D, Sugiyama M, Garnett R (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 28, pp 91–99, https://proceedings.neurips.cc/paper/2015/file/14bfa6bb14875e45bba028a21ed38046-Paper.pdf
Rezende DJ, Mohamed S, Wierstra D (2014) Stochastic backpropagation and approximate inference in deep generative models. In: Xing EP, Jebara T (eds) Proceedings of the 31st International Conference on Machine Learning, PMLR, Bejing, China, Proceedings of Machine Learning Research, vol 32, pp 1278–1286, http://proceedings.mlr.press/v32/rezende14.html
Sanh V, Debut L, Chaumond J, Wolf T (2020) Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter. 1910.01108
Shao S, Li Z, Zhang T, Peng C, Yu G, Zhang X, Li J, Sun J (2019) Objects365: A large-scale, high-quality dataset for object detection. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Sharir O, Peleg B, Shoham Y (2020) The cost of training nlp models: A concise overview. 2004.08900
Sharma P, Ding N, Goodman S, Soricut R (2018) Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Association for Computational Linguistics, Melbourne, Australia, pp 2556–2565, https://doi.org/10.18653/v1/P18-1238, https://www.aclweb.org/anthology/P18-1238
Simonyan K, Zisserman A (2015) Very deep convolutional networks for large-scale image recognition. 1409.1556
Su W, Zhu X, Cao Y, Li B, Lu L, Wei F, Dai J (2020) Vl-bert: Pre-training of generic visual-linguistic representations. In: International Conference on Learning Representations, https://openreview.net/forum?id=SygXPaEYvH
Suhr A, Zhou S, Zhang A, Zhang I, Bai H, Artzi Y (2019) A corpus for reasoning about natural language grounded in photographs. In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Association for Computational Linguistics, Florence, Italy, pp 6418–6428, https://doi.org/10.18653/v1/P19-1644, https://www.aclweb.org/anthology/P19-1644
Sun C, Shrivastava A, Singh S, Gupta A (2017) Revisiting unreasonable effectiveness of data in deep learning era. In: Proceedings of the IEEE International Conference on Computer Vision (ICCV)
Sun C, Myers A, Vondrick C, Murphy K, Schmid C (2019) Videobert: A joint model for video and language representation learning. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Sun C, Baradel F, Murphy K, Schmid C (2020) Learning video representations using contrastive bidirectional transformer. https://openreview.net/forum?id=rJgRMkrtDr
Tan H, Bansal M (2019) LXMERT: Learning cross-modality encoder representations from transformers. In: Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Association for Computational Linguistics, Hong Kong, China, pp 5100–5111, https://doi.org/10.18653/v1/D19-1514, https://www.aclweb.org/anthology/D19-1514
Tan M, Le Q (2019) EfficientNet: Rethinking model scaling for convolutional neural networks. In: Chaudhuri K, Salakhutdinov R (eds) Proceedings of the 36th International Conference on Machine Learning, PMLR, Proceedings of Machine Learning Research, vol 97, pp 6105–6114, http://proceedings.mlr.press/v97/tan19a.html
Tan M, Pang R, Le QV (2020) Efficientdet: Scalable and efficient object detection. 1911.09070
Tapaswi M, Zhu Y, Stiefelhagen R, Torralba A, Urtasun R, Fidler S (2016) MovieQA: Understanding Stories in Movies through Question-Answering. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Touvron H, Cord M, Douze M, Massa F, Sablayrolles A, Jégou H (2020) Training data-efficient image transformers & distillation through attention. 2012.12877
Ushiku Y, Harada T, Kuniyoshi Y (2012) Efficient image annotation for automatic sentence generation. In: ACM Multimedia
Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Lu, Polosukhin I (2017) Attention is all you need. In: Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, Garnett R (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 30, pp 5998–6008, https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf
Vedantam R, Zitnick CL, Parikh D (2015) Cider: Consensus-based image description evaluation. 1411.5726
Venugopalan S, Rohrbach M, Donahue J, Mooney RJ, Darrell T, Saenko K (2015a) Sequence to sequence - video to text. CoRR abs/1505.00487, http://arxiv.org/abs/1505.00487, 1505.00487
Venugopalan S, Xu H, Donahue J, Rohrbach M, Mooney R, Saenko K (2015b) Translating videos to natural language using deep recurrent neural networks. In: Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Association for Computational Linguistics, Denver, Colorado, pp 1494–1504, https://doi.org/10.3115/v1/N15-1173, https://www.aclweb.org/anthology/N15-1173
Vinyals O, Toshev A, Bengio S, Erhan D (2015) Show and tell: A neural image caption generator. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp 3156–3164, 10.1109/CVPR.2015.7298935
Vondrick C, Shrivastava A, Fathi A, Guadarrama S, Murphy K (2018) Tracking emerges by colorizing videos. In: Proceedings of the European Conference on Computer Vision (ECCV)
Wang B, Shang L, Lioma C, Jiang X, Yang H, Liu Q, Simonsen JG (2021a) On position embeddings in bert. In: International Conference on Learning Representations, https://openreview.net/forum?id=onxoVA9FxMw
Wang H, Zhu Y, Adam H, Yuille A, Chen LC (2020a) Max-deeplab: End-to-end panoptic segmentation with mask transformers. 2012.00759
Wang J, Hu X, Zhang P, Li X, Wang L, Zhang L, Gao J, Liu Z (2020b) Minivlm: A smaller and faster vision-language model. 2012.06946
Wang W, Xie E, Li X, Fan D, Song K, Liang D, Lu T, Luo P, Shao L (2021b) Pyramid vision transformer: A versatile backbone for dense prediction without convolutions. CoRR abs/2102.12122, https://arxiv.org/abs/2102.12122, 2102.12122
Wang X, Gupta A (2015) Unsupervised learning of visual representations using videos. CoRR abs/1505.00687, http://arxiv.org/abs/1505.00687, 1505.00687
Wang, Y., Mohamed, A., Le, D., Liu, C., Xiao, A., Mahadeokar, J., Huang, H., Tjandra, A., Zhang, X., Zhang, F., et al. (2020c). Transformer-based acoustic modeling for hybrid speech recognition. In: ICASSP 2020–2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) https://doi.org/10.1109/icassp40776.2020.9054345, http://dx.doi.org/10.1109/ICASSP40776.2020.9054345
Wu, L., Fisch, A., Chopra, S., Adams, K., Bordes, A., & Weston, J. (2017). Starspace: Embed all the things! http://arxiv.org/abs/1709.03856, cite arxiv:1709.03856
Xie, S., Sun, C., Huang, J., Tu, Z., & Murphy, K. (2018). Rethinking spatiotemporal feature learning: Speed-accuracy trade-offs in video classification. 1712.04851
Xu, J., Mei, T., Yao, T., & Rui, Y. (2016). Msr-vtt: A large video description dataset for bridging video and language. In: IEEE International Conference on Computer Vision and Pattern Recognition (CVPR)
Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., Zemel, R., & Bengio, Y. (2015). Show, attend and tell: Neural image caption generation with visual attention. In: Bach F, Blei D (eds) In: Proceedings of the 32nd International Conference on Machine Learning, PMLR, Lille, France, Proceedings of Machine Learning Research, vol 37, pp. 2048–2057, http://proceedings.mlr.press/v37/xuc15.html
Yang, J., Ren, Z., Xu, M., Chen, X., Crandall, D., Parikh, D., & Batra, D. (2019a). Embodied visual recognition. 1904.04404
Yang, Z., He, X., Gao, J., Deng, L., & Smola, A. J. (2015). Stacked attention networks for image question answering. CoRR abs/1511.02274, http://arxiv.org/abs/1511.02274
Yang, Z., Dai, Z., Yang, Y., Carbonell, J., Salakhutdinov, R. R., & Le, Q. V. (2019b). Xlnet: Generalized autoregressive pretraining for language understanding. In: Wallach H, Larochelle H, Beygelzimer A, d’Alché-Buc F, Fox E, Garnett R (eds) Advances in Neural Information Processing Systems, Curran Associates, Inc., vol 32, pp 5753–5763, https://proceedings.neurips.cc/paper/2019/file/dc6a7e655d7e5840e66733e9ee67cc69-Paper.pdf
You, Q., Jin, H., Wang, Z., Fang, C., & Luo, J. (2016). Image captioning with semantic attention. 1603.03925
Young, P., Lai, A., Hodosh, M., & Hockenmaier, J. (2014). From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2, 67–78. https://doi.org/10.1162/tacl_a_00166, https://www.aclweb.org/anthology/Q14-1006
Yu, F., Tang, J., Yin, W., Sun, Y., Tian, H., Wu, H., & Wang, H. (2020). Ernie-vil: Knowledge enhanced vision-language representations through scene graph. 2006.16934
Yu, L., Poirson, P., Yang, S., Berg, A. C., & Berg, T. L. (2016). Modeling context in referring expressions. In B. Leibe, J. Matas, N. Sebe, & M. Welling (Eds.), Computer Vision - ECCV 2016 (pp. 69–85). Cham: Springer.
Zadeh, A., Zellers, R., Pincus, E., & Morency, L. P. (2016). Multimodal sentiment intensity analysis in videos: Facial gestures and verbal messages. IEEE Intelligent Systems, 31(6), 82–88. https://doi.org/10.1109/MIS.2016.94, http://ieeexplore.ieee.org/abstract/document/7742221/
Zellers, R., Bisk, Y., Farhadi, A., & Choi, Y. (2019). From recognition to cognition: Visual commonsense reasoning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang, B., Hu, H., & Sha, F. (2018a). Cross-modal and hierarchical modeling of video and text. 1810.07212
Zhang, P., Goyal, Y., Summers-Stay, D., Batra, D., & Parikh, D. (2016). Yin and Yang: Balancing and answering binary visual questions. In: Conference on Computer Vision and Pattern Recognition (CVPR)
Zhang, S., Jiang, T., Wang, T., Kuang, K., Zhao, Z., Zhu, J., Yu, J., Yang, H., & Wu, F. (2020). Devlbert. In: Proceedings of the 28th ACM International Conference on Multimedia https://doi.org/10.1145/3394171.3413518, https://doi.org/10.1145/3394171.3413518
Zhang, Z., Xie, Y., & Yang, L. (2018b). Photographic text-to-image synthesis with a hierarchically-nested adversarial network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Zhou, L., Xu, C., Koch, P., & Corso, J. J. (2016). Watch what you just said: Image captioning with text-conditional attention. 1606.04621
Zhou, L., Xu. C., & Corso, J. J. (2017). Procnets: Learning to segment procedures in untrimmed and unconstrained videos. CoRR abs/1703.09788, http://arxiv.org/abs/1703.09788, 1703.09788
Zhou, L., Zhou, Y., Corso, J. J., Socher, R., & Xiong, C. (2018). End-to-end dense video captioning with masked transformer. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
Zhou, L., Palangi, H., Zhang, L., Hu, H., Corso, J. J., & Gao, J. (2019). Unified vision-language pre-training for image captioning and vqa. 1909.11059
Zhu, L. & Yang, Y. (2020). Actbert: Learning global-local video-text representations. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Zhukov, D., Alayrac, J. B., Cinbis, R. G., Fouhey, D., Laptev, I., & Sivic, J. (2019). Cross-task weakly supervised learning from instructional videos. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Karteek Alahari.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Shin, A., Ishii, M. & Narihira, T. Perspectives and Prospects on Transformer Architecture for Cross-Modal Tasks with Language and Vision. Int J Comput Vis 130, 435–454 (2022). https://doi.org/10.1007/s11263-021-01547-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-021-01547-8