
Abstract
Model uncertainty is a prominent feature in many applied settings. This is certainty true in the efficiency analysis realm where concerns over the proper distributional specification of the error components of a stochastic frontier model is, generally, still open along with which variables influence inefficiency. Given the concern over the impact that model uncertainty is likely to have on the stochastic frontier model in practice, the present research proposes two distinct model averaging estimators, one which averages over nested classes of inefficiency distributions and another that has the ability to average over distinct distributions of inefficiency. Both of these estimators are shown to produce optimal weights when the aim is to uncover conditional inefficiency at the firm level. We study the finite-sample performance of the model average estimator via Monte Carlo experiments and compare with traditional model averaging estimators based on weights constructed from model selection criteria and present a short empirical application.
Similar content being viewed by others

Notes
For example, Lai and Huang (2010) include years of education of the primary decision maker in the household in their study of Indian farming. It is not theoretically clear if, and how, this variable should enter the production structure.
Note that the model averaging estimator of Hansen and Racine’s (2012) can accommodate nonlinearity of the unknown conditional mean through a sequence of bases such as orthogonal polynomials of varying order, splines of varying order and so forth, but their construction of weights is designed around a quadratic objective function with parameters which enter the model linearly. Here our focus is on the construction of weights when we have parameters which enter the model in a nonlinear fashion and/or the objective function is not quadratic.
The use of J ≫ 1 is to reduce the number of leave-one-out samples that need to be constructed to average over making the estimation more streamlined.
A similar strategy, in the context of productivity measurement across countries, appears in Sickles et al. (2015).
See also Shang (2015).
See Parmeter and Kumbhakar (2014) for a detailed account of this model.
Given that the error term \(\varepsilon _i^ \ast\) is heteroskedastic, \(Var(\varepsilon ^ \ast |{\boldsymbol{x}}_i,{\boldsymbol{z}}_{u,i}) = \sigma _v^2 + \sigma _u^{2 \ast }e^{2{\boldsymbol{z}}_{u,i}^\prime {\boldsymbol{\delta }}^u}\), where \(\sigma _v^2 = Var(v_i)\) and \(\sigma _u^{2 \ast } = Var(u^ \ast )\), a generalized nonlinear least squares algorithm (though this requires distributional assumptions to disentangle \(\sigma _v^2\) and \(\sigma _u^{2 \ast }\)) or heteroscedasticity robust standard errors would be required to conduct valid inference.
See Coelli et al. (2005, Appendix 2) for a more detailed description of the data.
References
Aigner DJ, Lovell CAK, Schmidt P (1977) Formulation and estimation of stochastic frontier production functions. J Econom 6(1):21–37
Alvarez A, Amsler C, Orea L, Schmidt P (2006) Interpreting and testing the scaling property in models where inefficiency depends on firm characteristics. J Prod Anal 25(2):201–212
Battese GE, Coelli TJ (1988) Prediction of firm-level technical efficiencies with a generalized frontier production function and panel data. J Econom 38:387–399
Buckland ST, Burnham KP, Augustin NH (1997) Model selection: an integral part of inference. Biometrics 53(4):603–618
Coelli TJ, Rao DP, O’Donnell CJ, Battese GE (2005) An Introduction to Efficiency and Productivity Analysis. Springer, New York
Hansen BE (2007) Least squares model averaging. Econometrica 75(4):1175–1189
Hansen BE, Racine JS (2012) Jackknife model averaging. J Econom 167(1):38–46
Huang CJ, Lai H-P (2012) Estimation of stochastic frontier models based on multimodel inference. J Prod Anal 38:273–284
Jondrow J, Lovell CAK, Materov IS, Schmidt P (1982) On the estimation of technical efficiency in the stochastic frontier production function model. J Econom 19(2/3):233–238
Kneip A, Simar L, Van Keilegom I (2015) Frontier estimation in the presence of measurement error with unknown variance. J Econom 184:379–393
Kumbhakar SC, Parmeter CF, Tsionas E (2013) A zero inefficiency stochastic frontier estimator. J Econom 172(1):66–76
Lai H-P, Huang CJ (2010) Likelihood ratio tests for model selection of stochastic frontier models. J Prod Anal 34(1):3–13
Mallows CL (1973) Some comments on cp. Tehcnometrics 15:661–675
Meeusen W, van den Broeck J (1977) Efficiency estimation from Cobb-Douglas production functions with composed error. Int Econ Rev 18(2):435–444
Olesen OB, Ruggiero J (2018) An improved Afriat-Diewert-Parkan nonparametric production function estimator. Eur J Operat Res 264:1172–1188
Parmeter CF, Kumbhakar SC (2014) Efficiency analysis: a primer on recent advances. Found Trends Econom 7(3-4):191–385
Parmeter CF, Wang H-J, Kumbhakar SC (2017) Nonparametric estimation of the determinants of inefficiency. J Prod Anal 47(3):205–221
Rho S, Schmidt P (2015) Are all firms inefficient? J Prod Anal 43(3):327–349
Shang C (2015) Essays on the use of duality, robust empirical methods, panel treatments, and model averaging with applications to housing price index construction and world productivity growth, PhD thesis, Rice University
Sickles RC (2005) Panel estimators and the identification of firm-specific efficiency levels in parametric, semiparametric and nonparametric settings. J Econom 126(2):305–334
Sickles RC, Hao J, Shang C (2014) Panel data and productivity measurement: an analysis of Asian productivity trends. J Chin Econ Bus Stud 12(3):211–231
Sickles RC, Hao J, Shang C (2015) Panel data and productivity measurement. In: Baltagi B (ed) Ch 17, Oxford Handbook fo Panel Data. Oxford University Press, New York, pp 517–547
Simar L, Lovell CAK, van den Eeckaut P (1994) Stochastic frontiers incorporating exogenous inuences on efficiency. Discussion Papers No. 9403, Institut de Statistique, Universite de Louvain
Stone M (2002) How not to measure the efficiency of public services (and how one might). J R Stat Soc Ser A 165:405–434
Tsionas EG (2017) “When, where and how” of efficiency estimation: Improved procedures for stochastic frontier modeling. J Am Stat Assoc 112:948–965
Wan ATK, Zhang X, Zou G (2010) Least squares model averaging by Mallows criterion. J Econom 156(4):277–283
Wang H-J, Schmidt P (2002) One-step and two-step estimation of the effects of exogenous variables on technical efficiency levels. J Prod Anal 18:129–144
White H (1982) Maximum likelihood estimation of misspecified models. Econometrica 50(1):1–25
Acknowledgements
We thank participants at the New York Camp Econometrics X, the 14th European Workshop on Efficiency and Productivity Analysis, LECCEWEPA 2015, the CEPA Workshop on Economic Measurement and the 2016 North American Productivity Workshop for valuable insight. Xinyu Zhang acknowledges the support from National Natural Science Foundation of China (Grant numbers 71522004, 11471324 and 71631008). The usual disclaimer applies.
Author contributions
All three authors contributed equally to this work and the order of authorship has nothing other than alphabetical significance.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendices
Appendices
A.1. Proof of Theorem 1. We first decompose C(w) as follows:
From the \(\sqrt n\)-consistency property of MLE and Assumption C.1, we have, for any \(s^ \ast \in \{ {\cal O} \cup \{ t\} \}\),
where \(\widetilde {\boldsymbol{\theta }}_{s^ \ast ,i}\) lies between \(\widehat {\boldsymbol{\theta }}_{s^ \ast }\) and \({\boldsymbol{\theta }}_{s^ \ast }\). By the definition of \(\widehat {\boldsymbol{w}}\) in Eq. (14), we have
which, along with (A.1), implies that
and thus
Therefore,
The full model belongs to \({\cal O}_1\) provided that any one candidate model belongs to \({\cal O}_1\). Hence we can obtain Eq. (15) from (A.2) and (A.4).
We next prove Eq. (16). Let
and Φ be an S × S matrix with its smth element given by
It can be easily shown that for any \({\boldsymbol{w}} \in {\cal W}\), C(w) = w′Φw. Now, define
Then we have
where the seventh equality expression is obtained using (A.2), (A.5) and (A.6). This yields
and hence \(\widehat w_{m^ \ast } = O_p(\log ^{ - 1}(n))\), which is Eq. (16).
A.2. Proof of Theorem 2. Write
From (A.1), (A.7), Assumption C.2, and the proof of Theorem 1′ in Wan et al. (2010), Theorem 2 holds provided that the following conditions hold:
and
From Eq. (17) and Assumption C.1, we have
It follows from (A.11) and Assumption C.2 that (A.8) holds. In a similar way, we can prove that (A.9) and (A.10) hold. This proves Theorem 2.
A.3. Proof of Theorem 3. It can be seen that
and
Hence to prove Theorem 3, it suffices to show that
and
Similar to the proof of (A.2), by Eq. (17) and Assumption C.4, we have
It is readily seen that
and
For any δ > 0,
where x = (x1, …, xn)′ and z = (z1, …, zn)′, and σ2 is defined in the line above Assumption C.3. Together with Assumption C.3, this implies
By combining (A.14)–(A.17) and Assumption C.3, we can obtain (A.12) and (A.13) and hence Eq. (21). This completes the proof of Theorem 3.
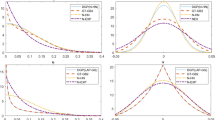
A.4. Simulation Results with Smaller Hold Out Sample. Similar to Tables 2 and 4 presents the mean, median and standard deviation of \(\left\Vert {{\boldsymbol{b}}(\widehat {\boldsymbol{w}}) - {\boldsymbol{b}}} \right\Vert^2/n_{}^{}\), where b = E[y|x, z], based on AIC and BIC model selection, as well as s-AIC and s-BIC model averaging, the full (correctly specified model) and two variants of JCVMA across 1000 replications. JCVMA1 uses \({\boldsymbol{b}}(\widehat {\boldsymbol{w}}) = \widehat {\boldsymbol{b}}(\widehat {\boldsymbol{w}})\), as defined in Eq. (11), the fitted values from S candidate models not using hold-out samples, while JCVMA2 uses \({\boldsymbol{b}}(\widehat {\boldsymbol{w}}) = \widetilde {\boldsymbol{b}}(\widehat {\boldsymbol{w}})\), as defined in Eq. (12), the leave-J-observations-out fitted values from the estimated models. Note that both JCVMA1 and JCVMA2 use the same weights, \(\widehat {\boldsymbol{w}}\), obtained from Eq. (20), they just conduct the averaging over different sets of fitted values. For all the simulations we leave out 2.5% of the sample size for our hold out prediction (i.e., for n = 200, we hold out 5 observations at a time, for n = 400 we hold out 10 observations at a time, etc.).
Several insights are immediate from Table 4 relative to the results from Table 2. JCVMA2 still outperforms JCVMA1. JCVMA2 always outperforms the other methods in terms of mean risk, and also has equal standard deviation of risk. Comparing mean and median risk, it does not appear that the size of the hold out sample has much effect on the performance of either of the JCVMA estimators.
Rights and permissions
About this article

Cite this article
Parmeter, C.F., Wan, A.T.K. & Zhang, X. Model averaging estimators for the stochastic frontier model. J Prod Anal 51, 91–103 (2019). https://doi.org/10.1007/s11123-019-00547-8
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11123-019-00547-8