
Abstract
With an increasing demand for raw materials, predictive models that support successful mineral exploration targeting are of great importance. We evaluated different machine learning techniques with an emphasis on boosting algorithms and implemented them in an ArcGIS toolbox. Performance was tested on an exploration dataset from the Iberian Pyrite Belt (IPB) with respect to accuracy, performance, stability, and robustness. Boosting algorithms are ensemble methods used in supervised learning for regression and classification. They combine weak classifiers, i.e., classifiers that perform slightly better than random guessing to obtain robust classifiers. Each time a weak learner is added; the learning set is reweighted to give more importance to misclassified samples. Our test area, the IPB, is one of the oldest mining districts in the world and hosts giant volcanic-hosted massive sulfide (VMS) deposits. The spatial density of ore deposits, as well as the size and tonnage, makes the area unique, and due to the high data availability and number of known deposits, well-suited for testing machine learning algorithms. We combined several geophysical datasets, as well as layers derived from geological maps as predictors of the presence or absence of VMS deposits. Boosting algorithms such as BrownBoost and Adaboost were tested and compared to Logistic Regression (LR), Random Forests (RF) and Support Vector machines (SVM) in several experiments. We found performance results relatively similar, especially to BrownBoost, which slightly outperformed LR and SVM with respective accuracies of 0.96 compared to 0.89 and 0.93. Data augmentation by perturbing deposit location led to a 7% improvement in results. Variations in the split ratio of training and test data led to a reduction in the accuracy of the prediction result with relative stability occurring at a critical point at around 26 training samples out of 130 total samples. When lower numbers of training data were introduced accuracy dropped significantly. In comparison with other machine learning methods, Adaboost is user-friendly due to relatively short training and prediction times, the low likelihood of overfitting and the reduced number of hyperparameters for optimization. Boosting algorithms gave high predictive accuracies, making them a potential data-driven alternative for regional scale and/or brownfields mineral exploration.
Similar content being viewed by others
Introduction
A continually increasing demand for raw materials in modern societies and the depletion of already-known resources highlights the importance of mineral exploration to find new deposits. Probabilistic modeling using digital information such as remote sensing, geochemical, geophysical and geological data is a useful tool for exploration and mining since it provides low-cost, readily available information that supports exploration and mine development decision-making. Thus, new and reliable GIS-based methods for predicting prospective areas and defining exploration targets would be an asset to the mining industry.
Many knowledge-driven and data-driven geo-computational methods for mineral potential mapping have been developed in recent years. Knowledge-driven approaches require expert knowledge about spatial associations between the evidential layers and the mineral deposit type sought. Weights assigned to each layer of spatial evidence reflect this knowledge. This kind of approach is suitable for regions that are not well-explored, so-called greenfield exploration terrains (Carranza and Hale 2003; Carranza and Laborte 2015). On the other hand, data-driven approaches are appropriate for moderately to well-explored brownfield regions, where mining companies are interested in identifying new deposits in the proximity of known deposits or operating mines (Carranza et al. 2008). In this scenario, the weights assigned to the layers are spatial associations between the evidential layers and the already-known deposits (Carranza and Laborte 2015).
A wide selection of algorithms have been used to find favorable areas using knowledge-based methods such as evidential belief functions (e.g., Carranza et al. 2005; Tien Bui et al. 2012; Ford et al. 2016), fuzzy logic (e.g., Knox-Robinson 2000, Nykänen et al. 2008) or data-driven approaches like weights of evidence (e.g., Chung and Agterberg 1980; Agterberg 1992a, b; Tangestani and Moore 2001; Xiao et al. 2015) and logistic regression (e.g., Reddy and Bonham-Carter 1991; Oh and Lee 2008) Currently, there is a trend toward machine learning techniques such as artificial neural networks (e.g., Singer and Kouda 1996; Porwal et al. 2003), decision trees (Reddy and Bonham-Carter 1991), random forest (RF) (Carranza and Laborte 2015; Rodriguez-Galiano et al. 2015) and support vector machines (SVM) (Zuo and Carranza 2011; Abedi et al. 2012). Each of these algorithms has advantages and limitations. Weights of evidence, for example, offer intuitive implementation and resistance to the “curse of dimensionality” that arises in classification problems when dealing with data in high-dimensional spaces (Bellman 2015). Additionally, the parameters of a linear model allow geoscientific interpretations (Harris and Pan 1999; Porwal et al. 2003). Weights of evidence, however, requires many known mineral occurrences for training and is not suitable for poorly explored areas (Brown et al. 2000). Furthermore, the assumption of conditional independence of the input data with regard to the training sites affects the quality of the prediction of the weights of evidence algorithm (Porwal et al. 2003; Zuo and Carranza 2011; Andrada de Palomera et al. 2015). More complex methods like artificial neural networks may provide great accuracy, especially when the relationships are nonlinear (Brown et al. 2000; Zuo and Carranza 2011; Abedi et al. 2012). The black-box nature of the algorithms, as well as the time and performance required to estimate potentially many hyper-parameters can, however, be seen as a drawback when applying these techniques (Rodriguez-Galiano et al. 2015).
Despite their significant advantages and several promising studies in other fields such as ecotope mapping (Chan and Paelinckx 2008), land-cover classification (Ghimire et al. 2012), and ore reserve estimation, to the authors’ knowledge, only one paper, by Cheng (2015), exists on boosting in mineral exploration. In this paper, boosting along with weights of evidence was used to overcome the problem of conditional independence (Cheng 2015). The objective of the current study is to present and discuss a new approach for prospectivity mapping using boosting algorithms. We implemented these methods as python toolboxes in the ArcGIS platform and performed several experiments on exploration data from the Iberian Pyrite Belt (IPB) in Spain to evaluate their accuracy, performance and robustness in comparison with other machine learning approaches such as SVM. The implementation within the ArcGIS platform allows the use of results on mobile devices for ground-truthing and thus provides a streamlined workflow for the exploration industry. This is done by uploading the modeling results to the ArcGIS cloud or server and then accessing it using ArcGIS Collector, which allows data acquisition in the field. In areas without mobile coverage, working offline is also possible, and data can be synchronized once there is coverage again.
Geology and Mineralization of the Iberian Pyrite Belt
To evaluate the performance of boosting and other commonly used ML algorithms, we used data from the IPB. This study area is ideal for data-driven methods because there are a large number of known deposits to be used for training and validation and data with overlapping coverage is available. In addition, no previous ML studies related to mineral prospectivity have been carried out in the region.
The IPB is situated in the south of the Iberian Peninsula, covering a 250 km by 60 km area from the city of Sevilla (Spain) to the south-eastern part of Portugal (Toscano et al. 2014). It is one of the largest and most important volcanic-hosted massive sulfide (VMS) metallogenic provinces (Leistel et al. 1998; Carvalho et al. 1999) and also one of the oldest mining districts in the world (Carvalho et al. 1999).
The IPB hosts several giant ore bodies with reserves of some hundreds of millions of tons (e.g., Rio Tinto, Neves Corvo, Aljustrel, Tharsis, Sotiel, Aznalcollar; Velasco et al. 1998). According to Carvalho et al. (1999), the original, pre-erosional endowment of sulfides concentrated in approximately 90 deposits amounts to 1.7 billion tons. Of this number, about 20% were mined and another 10–15% eroded. The high concentrations of S, Fe, Zn, Cu, Pb, Sn and several other metals make it an exceptional area for studying the genesis of this type of mineralization. This has led to diverse studies in different disciplines, including tectonics, magmatism, ore mineralogy, geochemistry, hydrothermal alteration and metallogenesis, providing a rich source of information (Carvalho et al. 1999). An extensive literature exists on the geology and the deposits of the IPB, a precise of which exceeds the scope of this study. Thus, only an overview is provided. For more detailed information, the reader is referred to the specific publications and references provided (e.g., Almodóvar et al. 1997; Mitjavila et al. 1997; Barriga 1990a, b; González et al. 2002).
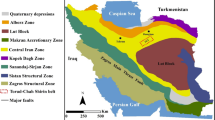
The IPB forms part of the South Portuguese Zone of the Hercynian Iberian Massif (Fig. 1a, Julivert and Fontboté 1974), which is interpreted as a tecto-stratigraphic terrane accreted to the Iberian Massif during the Middle Carboniferous (Quesada 1991). The South Portuguese Zone, together with the Ossa-Morena Zone and the Central Iberian Zone to the north, formed due to collision, with left-lateral transpressional kinematics, of Laurentia (South Portuguese Zone) with Gondwana (Ossa-Morena Zone and Central Iberian Zone, Expósito et al. 2003; Mantero et al. 2011; Martin-Izard et al. 2015). The southern boundary of the Ossa-Morena Zone is the Arcana Metamorphic Belt, which is regarded as a major suture related to the Hercynian convergence (Sáez et al. 1999).

(a) Overview showing the IPB (red box): SPZ South Portuguese Zone, OMZ Ossa-Morena Zone, CIZ Central Iberian Zone, WALZ West Asturian-Leonese Zone. (b) Lithological map of the area with deposits and mineral occurrences. The VMS deposits were used for modeling, while the Manganese occurrences were left out
The initial collision stages were dominated by transtensional lateral escape of units from the South Portuguese continental margin coeval with bimodal magmatism, hydrothermal circulation and ore deposition. These marginal units have been affected by the transtensional event that formed the IPB. The major overall effects of the collisional event were related to structural inversion of the South Portuguese margin as a response to the obduction of the OMZ active margin onto it (Oliveira 1990; Sáez et al. 1996). This led to a southerly propagation of a thin-skinned fold and thrust-type orogen and was accompanied by the transformation of the pre-existing platform into a foreland basin (Oliveira 1990; Quesada 1991).
The genetic model for the formation of the VMS deposits assumes that transtensional tectonic processes during the early Carboniferous controlled the emplacement of volcanic rocks with related hydrothermal activity and ore deposition (Oliveira 1990; Moreno and González 2004; Mantero et al. 2011). Oliveira (1990) and Gumiel et al. (2010) proposed that the IPB formed in a series of restricted pull-apart basins within a transpressive orogeny and coeval with the presence of a mantle plume (Simancas et al. 2006). These models and the strong relationship of ore genesis to fractures are generally accepted even though the relationships between specific deposits and transtensional tectonics are not clearly understood (Simancas et al. 2006; Martin-Izard et al. 2015). This is partly due to the intense continuing superimposed deformation during the progress of the Variscan orogeny, which overprinted earlier transtensional structures.
For the same reason outlined above, establishing a lithostratigraphic succession of the IPB is difficult (Routhier et al. 1980; Oliveira 1990). Oliveira (1990) divided the IPB into a southern parautochthonous and northern, essentially allochthonous, branch consisting of three main formations that are well-established in the southern branch. These formations were summarized by Leistel et al. (1998) as follows, and used in this study as input datasets (Fig. 1, Table 1: lithological units)
- 1.
The oldest late Devonian Phyllitic Quartzite (PQ) formation consists of shale and quartz sandstone and rare conglomerates as well as a 30 m thick top sequence containing bioclastic carbonate lenses and nodules. The conglomerates are interpreted to have formed in shallow water and the top sequence as shelf deposition (Leistel et al. 1998). It crops out in the central part of the study area. (Fig. 1).
- 2.
The volcano-sedimentary (VS) sequence is of late Famennian to early late Visean age, (Van den Boogaard 1963; Oliveira 1983; Oliveira et al. 1986; 1990), and has a thickness between 100 and 600 m. The complete VS sequence consists of six sub-sequences:
- (a)
A lowermost rhyolitic sequence (VA1) composed of fine- to coarse-grained pyroclastics and lava. This is one of the host rocks of the VMS deposits.
- (b)
A second rhyolitic sequence (VA2) with pyroclastics and lava. This is also a host rock for the VMS deposits.
- (c)
A third rhyolitic sequence (VA3) of reworked tuff and siliceous shale.
- (d)
Basic lavas, locally pillowed and intercalated between VA1 and VA3, basic dykes and sills intruded into the lower part of the complex.
- (e)
A purple-blue shale layer that is used as a marker horizon directly below VA3.
- (f)
An intermediate series consisting of pelite-black shales and sandstone sequences containing jasper and rare limestone.
The sequence is intercalated with VA1 and VA2 volcanic rocks. The VS sequence crops out in much of the IPB (Fig. 1) and is the host lithology of the known VMS deposits, either in the black shale such as Tharsis and Sotiel or resting on acidic volcanic facies such as Rio Tinto (Leistel et al. 1998).
- (a)
- 3.
The last formation is known as the Culm facies (Schermerhorn 1971) or Baixo Alentejo flysch group 69 and rests diachronously over the underlying series. The Culm group is a turbidite formation that forms a south-westward prograding detrital cover (Fig. 1).
Data and Pre-processing
A summary of the available data for this study is provided in Table 1, and a flowchart outlining the ideal workflow for pre-processing, modeling and validation is shown in Figure 2. The data were provided as GIS layers by Atalaya Mining. The geological map in ArcGIS format contains linear features such as faults, as well as polygons representing the respective lithological units described in the previous section. Additional information about the data can be found in the project report by IGME (Conde Rivas et al. 2007).

Flowchart showing the overall workflow for pre-processing, modeling and validation using the new toolbox
Faults play a crucial role in the mineralization process of the IPB, as they allow fluid flow and the transport of metals. We calculated the Euclidean distance from faults as an evidential layer. Different lithological units such as volcanic rocks and intrusive rocks may have acted as heat sources or played a crucial role because of their chemical reactivity or specific physical properties (black shales of VS sequence). The distance to lithological units was calculated for modeling using our new pre-processing tool “Multiclass to binary” that converts categorical layers into binary layers with the option of calculating different distance metrics. This results in continuous raster layers, similar to cost surfaces, with the same spatial resolution. Besides the host rock lithologies (VS1 and 2) and other volcanics that could have acted as heat sources (undifferentiated granites, gabbros and diorites, mafic volcanics,), the other lithological units were also used as modeling inputs to the ML algorithms enabling us to learn whether the non-deposit characteristics and inverse spatial relationships of the mapped feature to the deposits might exist.
Geophysical data from the airborne campaign conducted in 1997 was also utilized. The magnetic data were leveled and were provided as total magnetic field data. This layer was used because many sulfide minerals, e.g., pyrite, pyrrhotite and non-sulfides found around VMS orebodies, e.g., magnetite, have high values of magnetic susceptibility that can lead to positive magnetic anomalies associated with VMS deposits (Morgan 2012). Radiometric data were provided as total counts. As radioactive elements K, U, and Th can be enriched or depleted in or around certain deposits or (altered) lithological units related to deposits, the data can map valuable information for modeling. K-alteration in mafic and felsic volcanics related to the IPB deposits might cause strong gamma-ray signatures, and thus, this dataset was included to capture alteration features. Gravity data available as Bouguer gravity anomaly maps were the main data leading to discovery of the IPB (McIntosh et al. 1999). Bouguer anomalies indicated an extension of the IPB lithologies beneath 120 m of cover. Minerals found in VMS deposits have relatively high specific gravity values in contrast with lower specific gravity values of the sedimentary and volcanic host rocks, which can allow the mapping of VMS deposits directly by gravity data. All distance and geophysical raster layers were resampled to 232 m pixel size and projected into the metric coordinate system ETRS 1989 TM29.
The mineral deposit database used for training and testing includes the location and main commodity of 351 deposits of pyrite, copper, lead and zinc. The database was filtered to only include VMS deposits (130 in total) and to exclude the other metals and minor manganese occurrences.
Methods
Implementation of Boosting Algorithms
AdaBoost, i.e., Adaptive Boosting is one of the first and most widely used boosting methods, introduced in 1997 by Freund and Schapire (1997). On each boosting round (t), AdaBoost calls a given weak learning algorithm h(t) and estimates how well the prediction performs in order to recalculate the weight of the weak learner \( \beta^{\left( t \right)} \) (Eq. 1). The smaller the error, the smaller \( \beta^{\left( t \right)} \), and therefore the smaller the level of importance assigned to the final classifier. In each round, the weight of the sample \( w_{i}^{t + 1} \) is redistributed, increasing the weight for incorrectly classified elements and decreasing it for correctly classified ones (Eq. 2). Therefore, the algorithm focuses on wrongly classified points identified in previous rounds. Thus, the final hypothesis hf is a consensus of the weak learners given by their weight (Eq. 3).
The original AdaBoost algorithm is shown to be highly successful in binary classification, but its performance decreases in multiclass cases (Zhu et al. 2006). The algorithm Stagewise Additive Modeling using a Multiclass Exponential loss function (SAMME, Zhu et al. 2006) is adapted from the original AdaBoost technique to deal with multiclass classifications. The way in which the weights of the weak learners are calculated remains almost identical (Eq. 4), but the redistribution of weights for the samples introduces the use of the function \( {\mathbb{I}}\left( a \right) \) to account for multiple classes (Eq. 5). Here, the final hypothesis is the class that has the highest weighted value (Eq. 6).
Note that for binary classification (as is the case in this study), SAMME results are equivalent to AdaBoost. As SAMME is included in the machine learning library Scikit-learn as AdaBoost, this algorithm was used and implemented in this study.
The article by Zhu et al. (2006) introduces another variant of SAMME, Stagewise Additive Modeling using a Multiclass Exponential loss function for Real estimations (SAMME.R). SAMME.R takes advantage of the possibility of weak learners to deliver information not just of the classification, but also a probability estimate of belonging to each class. One important difference of this model is that the weak learner is not used directly to calculate the final hypothesis, but it is used instead to calculate class probability estimates. These estimates are then used to calculate the weak hypothesis (Eq. 7). Similar to SAMME, the final classifier results in a class with the highest value (Eq. 8: hf(x)).
where
The main advantage of SAMME.R over SAMME is that a solution can be reached more quickly, and, in certain circumstances, better results can be achieved when compared to those produced by SAMME (Zhu et al. 2006).
The nature of AdaBoost makes it sensitive to noise and outliers since in each boosting step the incorrectly classified samples acquire more voting power. Noisy points can have a profound impact on results, thus creating bias in the predictions. A solution to this problem, called BrownBoost, is proposed by Freund (2001). Here, the number of boosting iterations is not set beforehand but is solved during the training stage. Instead of fixing the iterations, a type of countdown timer is implemented. When the countdown gets smaller, the algorithm gives up on data points that are too difficult to classify. The time reduction along with the weight of the weak learner on each iteration is given by solving a differential equation. This process is complicated and not intuitive; hence, the reader is referred to the original publication by Freund (2001) for a detailed description.
For all the presented algorithms, the final hypothesis hf is calculated from a weighted sum of weak hypotheses. If we assume that each of these hypotheses considers just one evidential layer (e.g., decision stump), the importance of each regressor can be calculated as a weighted sum of the importance given in each weak learner. In ArcGIS, the information is provided in the processing report of the modeling tool. This can be crucially important for prospectivity modeling as it allows for assessment of the role of each evidential layer to the model and thus also changes to the predictive layers to improve the model. Data layers that have low or no importance to the final classifier can be omitted from the model with minor effect on its predictive power. This feature is available for BrownBoost, RF, SAMME and SAMME.R.
Besides boosting algorithms, we also implemented and applied other machine learning algorithms for comparison to provide users with several modeling options. The models for SAMME, SAMME.R, RF, LR and SVM are from the Scikit-learn library (Pedregosa et al. 2011), an open source machine learning library for Python. The BrownBoost algorithm was coded from scratch, using some modified SAMME code from Scikit-learn as template. The code is described on GitHub. Each of these algorithms was selected for different reasons. RF belongs to the family of ensemble methods with boosting and has been successfully applied for mineral prospectivity mapping in previous studies (Rodriguez-Galiano et al. 2012; Carranza and Laborte 2015). SVM is popular because of its ability to generalize from training data (Al-Anazi and Gates 2010), making it one of the best algorithms for prospectivity mapping, whereas LR is one of the most widely used methods (e.g., Agterbeg 1981; Reddy and Bonham-Carter 1991; Oh and Lee 2008).
Additional functions to help data processing were written in Python using the ArcPy module including Multiclass Split, Select and Create Random Points, Enrich Points (Table 2). Train model, Apply model and Model validation utility tools were created for training and applying the machine learning algorithms and for assessing accuracy and performance based on functions also available in the Scikit-learn library (Table 2).
Once a model is trained, the next step is to calculate the response map, i.e., a prospectivity map, to visualize the likelihood of mineralization occurring in the study area. This is done by taking the value of all the data layers and using the model to calculate the result for every pixel. For all the discussed methods, it is possible to obtain continuous output, i.e., its decision function, rather than just the classification. SAMME, SAMME.R, BrownBoost, LR and SVM have an implemented response function, while RF lacks this capability. Instead, the probability of belonging to the prospective class is used for RF.
Implementation of Validation Methods
In order to assess the quality of a model, good validation methods are vital. We implemented the most commonly used validation statistics from the Scikit-learn package. The calculation of the confusion matrix (Table 3), i.e., error matrix, and several other statistics to estimate the quality of the prediction based on the confusion matrix:
Accuracy: Calculates the rate of correctly classified objects (Table 3 for abbreviations),
Precision: Reports the correct classification rate using only the positively predicted cases,
Recall: Also called true positive rate or hit rate,
Fall-out: Also known as false positive rate,
In addition, a visualization tool for the receiver operating characteristics (ROC) graph and the area under the curve (AUC) numeric estimator (Bradley 1997; Fawcett 2006) based on Scikit-learn functions and matplotlib plotting capabilities (Hunter 2007) is implemented in the toolbox. This tool illustrates the trade-off between benefits (recall) in the y-axis and costs (fall-out) along the x-axis. For a classifier, this trade-off is drawn as a point in the graph. If the classifier can also provide continuous probability or response function, the so-called ROC curve can be drawn. It has been used previously in prospectivity mapping and is considered a robust validation method for spatial predictive models (Nykänen et al. 2015).
The final prospectivity maps can be re-classified by the user into prospective or non-prospective areas by thresholding. Setting the threshold value depends on whether it is better to risk not finding all deposits or whether the goal is to minimize the area of investigation. Another way to represent this benefit–cost compromise is to plot the recall against the proportion of prospective area (PPA), mostly because the cost of exploration increases with the area to be explored (Rodriguez-Galiano et al. 2012). This representation is called a success rate curve.
Besides the pre-processing and modeling tools, all described tools use the Matplotlib library and are available in the newest version of the ArcGIS Spatial Data Modeller (ArcSDM, version 5) in a toolbox called ‘Experimental Tools’ at the following GitHub link (https://github.com/gtkfi/ArcSDM).
Performance Experiments and Effect of Data Augmentation
Several experiments were conducted to assess the performance of the different machine learning algorithms as well as the effects of data augmentation to the prospectivity mapping of VMS deposits. Training and test data sets were created from 130 deposits. For model training purposes, data that represents both deposits and non-deposits (areas where the sought mineral is absent) were selected. The VMS deposits were used as located in the GIS, but the non-deposits present difficulties due to the lack of complete data coverage, which is typical of most exploration projects. This can lead to choosing non-deposit areas that actually host a deposit at depth. Approaches for selecting non-deposits locations for training and testing found in the literature include using previous prospectivity studies and selecting points of low prospectivity (Porwal et al. 2003; Nykänen 2008), selecting deposits of other mineral deposit types (Nykänen et al. 2015) or a selection of random points within the study area but at a certain distance to known deposits (Rodriguez-Galiano et al. 2015; Carranza and Laborte 2015). The latter is implemented in this study as it is the most widely used and accepted approach in the literature. It can also be used on areas without previous prospectivity studies. Accordingly, the same number of non-deposit points was created randomly at least 5 km away from known deposits and at least 500 m away from each other. The Enrich Points tool was used to write all the data from the evidential layers into the attribute table of the training and test points that were used as inputs for the ML algorithms.
The first experiment was designed to evaluate the performance of the ML algorithms described above. The VMS deposits set were randomly partitioned into a training dataset with 90% of the deposits (117 points), and 10% as an independent test data set (13 points). This was repeated nine times to collate nine different pairs of testing and training datasets, and the results obtained during modeling were averaged to avoid outliers in the results. After creating the training and test data, the BrownBoost, SAMME, SAMME.R, LR, RF, and SVM algorithms were trained and applied to the evidential layers to create the response maps. During the model creation process, the algorithm automatically calculates a threefold-validation score, which is recorded in the modeling report. Additionally, the models were evaluated with the respective independent proportioned test data set pair described above.
To evaluate the performance of the algorithms with restricted data, a second experiment was performed by decreasing the size of the training dataset and assigning the remainder to the test data set. Training datasets were selected from 10 up to 90% and with a step size of 10%, for the 130 original VMS deposits. For the performance experiment, the random selection was repeated nine times for each size of training data set to avoid outliers. The algorithms were trained, applied and evaluated the same way as in the first experiment.
Finally, a third experiment was conducted to address the issue of the number of deposits (= training samples) required to train the models. For most available datasets, deposits are represented by single point features representing the center of a deposit while an ore deposit in reality is an area of variable dimensions. One strategy to overcome this or similar problems in machine learning is to use data augmentation. One of the simplest and widely used approaches consists of adding training samples perturbed with noise: Noise is added to training samples in order to obtain additional samples that represent a class. The approach selected for this study is perturbing the location of the deposits and creating new points physically close to the centers of known deposits. The level of perturbation spread around the center is based on expert knowledge about the dimensions of the VMS deposits and/or, trial and error during modeling.
Sets of 13, 26, 39, 52 and 65 random points were created using the data augmentation tool: a tool that creates random additional deposit points within a specified distance of the known deposit. The new points were constrained to less than 1 km away from the known deposits. This distance was chosen because the deposits sizes range up to lenses or sheets 4 to 5 km long and 1.5 km wide (Carvalho et al. 1999). By choosing a radius of one around the central pixel, we averaged the deposits sizes. The created points were labeled as deposits and merged with the real deposits, to create an integrated set of training points together with the same number of non-deposit points. BrownBoost and SAMME.R algorithms were trained with the augmented datasets, and the resulting models were evaluated.
Results
The first experiment was designed to assess the performance of the different machine learning algorithms. High overall accuracies (> 89%) were achieved for all implemented algorithms (Table 4), but RF and boosting produced the highest accuracies. Besides, the overall accuracy, average values ± standard deviations for AUC, Precision, PPA and Recall are summarized for each algorithm in Table 3. All boosting methods produce a perfect score in true positive (and false negative) rate which in turn gives a recall value of 1. LR performed worst determined by all accuracy measures, except for PPA according to which SVM performs the worst.
Table 5 shows the average importance of each information layer done with the nine runs of SAMME. The most important evidential layer is the distance to undifferentiated metamorphic rocks which is quite surprising considering the genesis of the deposits. However, it is followed with similar importance by the distances to granites (340-300 Ma), metapelites and volcanics that are closely related to the genesis of the deposits (compare with previous sections). The most important geophysical data layer is the Bouguer anomaly map, while the total magnetic field map contributes less than 2%. Gravity data were previously used successfully to locate deposits in the area, and this result is in accordance with these findings (McIntosh et al. 1999). Note, however, that the importance of a layer in a SAMME model might differ from the way the other algorithms use the data.
The results of the sample size reduction are summarized in Figure 3. In terms of overall accuracy, the results from all ensemble methods decrease except for the lowest number of training data where SAMME.R has a greater loss of performance compared to the other algorithms. SVM has, in general, the same rate of accuracy decrement as ensemble methods but at a slightly lower accuracy. We clearly see that boosting algorithms outperform LR and SVM but follow a similar decrease in accuracy with the reduction of samples. LR performed the worst in terms of accuracy. An exception here was the last experiment (with 13 training points), which was the most accurate model. This might indicate that LR is better suited for very small numbers of training samples even though small sample sizes in general introduce bias. The AUC graph has a much more stable slope until reaching a breakpoint of 13 samples (Fig. 3b). In general, all algorithms seem to be quite stable and perform best with more than 80 training points. Accuracy decreases rapidly, however, when less training points are used and diminishes rapidly when only 13 points are used.

Plot of average (a) accuracy (%) and (b) area under the curve (AUC) plotted against the number of training deposits for BrownBoost, Logistic Regression, Random Forest, SAMME.R, SAMME and Support Vector Machine. We observe a decrease in both metrics with a general better performance of boosting algorithms. Accuracy remains relatively stable until a critical point of ca. 26 train deposits. The same is true for the AUC measure. Please refer to the section about accuracy assessment for more details about the metrics used
Results for data augmentation experiment are summarized in Figure 4. There is a small increase in accuracy and AUC from 76 to 83% for BrownBoost and SAMME.R compared to the experiments without augmentation. When increasing the number of augmented deposits to more than 13 deposits, the results did not improve further, with values staying at approximately 81% for accuracy and 90% for AUC. This is most likely due to the increase in noise in the data.

Plot of average (a) accuracy and (b) area under the curve (AUC) plotted against the number of augmented deposits for BrownBoost and SAMME.R. For both metrics, accuracy (%) and AUC (refer to section accuracy assessment for more details), we observe an increase when using data augmentation. However, augmentation by more than ca. 26 deposits does not lead to improved results anymore
After analyzing the performance of the algorithms and data augmentation, the complete set of 130 deposits along with 130 random non-deposits were used to create the final response maps with BrownBoost, LR, RF and SVM using all evidential layers (Fig. 5). All boosting algorithms provide similar accuracies. An example of the results from BrownBoost is shown in Figure 5. SVM, RF and LR have significant differences in terms of the predictive map patterns. The smooth spatial patterns created by variations in the pixel values in SAMME, SAMME.R and BrownBoost are caused by the distance metrics (L2) used in the calculations.

VMS prospectivity map created with 130 training deposits (black) with BrownBoost (a), LR (b), SVM (c) and RF (d)
The scaling of the outputs is different due to the different nature of the algorithms. While most algorithms provide information on the decision function, which is usually centered on 0, RF delivers probability estimations. Therefore, the output values exist in the set [0,1] and are usually centered on 0.5. The threshold differentiating prospective from non-prospective areas is usually chosen in the above-mentioned centers, but they can be changed to increase recall or fall-out values.
Discussion
The results of this study confirm that boosting algorithms are a promising alternative to other ML algorithms. The results agree with previous studies, which suggest that data-driven approaches, especially of SVM (Zuo and Carranza 2011; Rodriguez-Galiano et al. 2015) and RF (Rodriguez-Galiano et al. 2012; Carranza and Laborte 2015) are suitable for probabilistic modeling such as mineral prospectivity modeling.
The high level of accuracy based on independent test samples (0.962 for BrownBoost and SAMME, and 0.949 for SAMME.R) indicates that the purely data-driven approach using boosting algorithms can generalize and extract relationships in data related to VMS mineral systems in the Iberian Pyrite Belt. The smoothly curved spatial patterns observed in BrownBoost (and SAMME, SAMME.R that are not shown) prospective maps (Fig. 5) are produced by the influence of the evidential layers using distance measurements. The calculated distance is the l2 norm or Euclidean distance, causing the characteristic circular patterns.
The differences between the machine learning algorithms are rather small compared to the variability between different runs. Thus, with this amount of data, it is not possible to confirm that one of the methods outperforms the others and future studies in other settings are thus required to better evaluate these ML algorithms. The availability of an assortment of methods in the newly created Experimental tools in the ArcSDM v. 5 is therefore a great asset for testing the modeling of different scenarios.
The high accuracy of SAMME and SAMME.R compared to the BrownBoost algorithm indicates relatively low levels of noise in the data. BrownBoost is an algorithm designed to deal with noisy data (Freund 2001) and does not present a significant advantage over other boosting methods in this setting. Noisier datasets could assess the capabilities of BrownBoost better and should be experimented with in future studies.
In accordance with Rodriguez-Galiano et al. (2015), the accuracy and AUC decrease with a lower number of training samples. This result could be expected since with less information the algorithms are not capable of generalizing correctly. By creating artificial points representing the VMS deposits using data augmentation, the accuracy of predictions improves by several percent. However, choosing an optimal distance from known deposit points reflecting the deposit size or radius that will contain the information relevant for the formation of the deposit, is fundamentally dependent on the knowledge of the geologist.
It is important to note that the results of this study are constrained by the quality and resolution of datasets. The data were ideal for developing and testing the new data-driven tools due to the many known deposits in the area but, as indicated by Rodriguez-Galiano et al. (2015) and Schaeben and Semmler (2016), assumptions with respect to the general superiority of boosting algorithms for mineral prospectivity mapping should be further tested by additional new studies in other settings and for other deposit types.
According to SAMME, the distance to undifferentiated metamorphic rocks is the most important layer predicting the location of pyrite deposits followed closely by distance to granites, metapelites and felsic volcanic rocks. The presence of undifferentiated metamorphic rocks is rare in the study area and remote from the deposits (Fig. 1). This result is somewhat surprising, and several explanations may be postulated. These include, for example, the spatial pattern of the lithological units (Fig. 6). Many deposits and non-deposits are aligned following a pattern described by the distance to undifferentiated metamorphic rocks that might also indicate some symmetry of the overall structures or paleogeography and therefore be related to the ore system. Another explanation may be related to data issues like artifacts. More research needs to be conducted to solve this question, especially since the performance of the algorithm is very good. The distance to granites (Devonian, probably syngenetic) and especially felsic volcanics (VS1 and 2 as main host lithologies) is crucially important. These lithologies are related to the genesis of the deposits as outlined in the geological and data processing sections. As, however, no other prospectivity model has been published for the IPB, we cannot compare our findings to other studies.

Map of distance to undifferentiated metamorphic rocks, color classification for visual enhancement. Showing training points with deposits (black) and non-deposits (blue). The general direction of lithological contacts is clearly visible
The low importance of the distance to the faults layer (only in the SAMME model) appears to disagree with previous research relating fractures to the pyrite deposits of the IPB (Simancas et al. 2006; Martin-Izard et al. 2015). One possible reason for this is the nature of the weak learners. Decision stumps account just for one evidential layer at a time and the information of distance to faults might not contain enough information to accurately model the deposits’ presence. The same information might be contained in another layer in a slightly better way. Further studies on different weak learners and how they affect the importance of evidential layers are required to better understand this result. Comparing the four response maps created by boosting (Fig. 5), a prospective band is present in the southwest of the map. Several manganese deposits are located in this area (compare to Fig. 1).
The proportion of prospective area in our results appears to be higher in comparison with other mineral prospectivity studies (Porwal et al. 2003; Carranza and Laborte 2015; Rodriguez-Galiano et al. 2015). However, a comparison is not straightforward since (a) the studies are conducted on different areas and with different datasets and, (b) the threshold between the classes can be changed manually and the results are based on different cost functions and estimates. In addition, this effect can be caused by (a) the fact that decision stumps (used as weak learners) do not optimize the covered area but rather the prediction error; (b) large portions of the area are, indeed, prospective and, most likely (c) more, or more detailed, evidential layers are needed to further decrease the PPA values for the IPB. Due to the geology with steeply dipping synclinal structures, three-dimensional approaches would be ideal to capture the complexity of the geological setting. Recent exploration has focused on better understanding the three-dimensional setting. Such datasets are, as yet, unavailable for this area to be used in prospectivity modeling studies.
Conclusion and Future Work
The reported results indicate that boosting algorithms are a possible data-driven alternative to other machine learning and knowledge-based methods of prospectivity mapping. They perform well in the mineral prospectivity mapping conducted in this study and are also robust enough when using small training datasets.
Moreover, boosting methods provide a set of desirable qualities that include:
- (1)
the ability to find nonlinear relationships between variables that might be ignored by knowledge-based methods,
- (2)
they provide information on the importance of regressors to the final model,
- (3)
resistance to overfitting for scenarios with low noise and
- (4)
the number of parameters to customize is small, making it very user-friendly.
- (5)
importantly, conditional independence is not a problem.
As all tools were implemented into the ArcGIS platform, modeling results can be synchronized with mobile apps such as ArcGIS Collector to use results directly during fieldwork and to add data into the database. Thus, a streamlined workflow for industrial application is available. The results of the study confirm that research on the algorithms used in the study should continue. Future research should also focus on other boosting algorithms such as gradient boosting or LogitBoost. LogitBoost, as well as on other types of ore deposits. The boosting algorithms should also be considered for other fields of research, including mapping of oil and water resources or for geohazard mapping.
References
Abedi, M., Norouzi, G.-H., & Bahroudi, A. (2012). Support vector machine for multi-classification of mineral prospectivity areas. Computers & Geosciences,46, 272–283.
Agterberg, F. P. (1992a). Combining indicator patterns in weights of evidence modelling for resource evaluation. Nonrenewable Resources,1, 39–50.
Agterberg, F. P. (1992b). Estimating the Probability of Occurrence of Mineral Deposits from Multiple Map Patterns. In H. Kürzl & D. F. Merriam (Eds.), Use of microcomputers in geology (pp. 73–92). Boston: Springer.
Al-Anazi, A., & Gates, I. D. (2010). A support vector machine algorithm to classify lithofacies and model permeability in heterogeneous reservoirs. Engineering Geology,114, 267–277.
Almodóvar, G. R., Sáez, R., Pons, J. M., Maestre, A., Toscano, M., & Pascual, E. (1997). Geology and genesis of the Aznalcóllar massive sulphide deposits, Iberian Pyrite Belt, Spain. Mineralium Deposita,33, 111–136.
Andrada de Palomera, P., van Ruitenbeek, F. J. A., & Carranza, E. J. M. (2015). Prospectivity for epithermal gold–silver deposits in the Deseado Massif, Argentina. Ore Geology Reviews,71, 484–501.
Barriga, F. J. A. S. (1990a). Metallogenesis in the Iberian Pyrite Belt. In R. D. Dallmeyer & E. M. Garcia (Eds.), Pre-Mesozoic geology of Iberia (pp. 369–379). Berlin: Springer.
Barriga, F. J. A. S. (1990b). Metallogenesis in the Iberian Pyrite Belt. In R. D. Dallmeyer & E. M. Garcia (Eds.), Pre-Mesozoic geology of Iberia (pp. 369–379). Berlin: Springer.
Bellman, R. E. (2015). Adaptive control processes: A guided tour. Princeton: Princeton University Press.
Bradley, A. P. (1997). The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognition,30, 1145–1159.
Brown, W. M., Gedeon, T. D., Groves, D. I., & Barnes, R. G. (2000). Artificial neural networks: a new method for mineral prospectivity mapping. Australian Journal of Earth Sciences,47, 757–770.
Carranza, E. J. M., & Hale, M. (2003). Evidential belief functions for data-driven geologically constrained mapping of gold potential, Baguio district, Philippines. Ore Geology Reviews,22, 117–132.
Carranza, E. J. M., Hale, M., & Faassen, C. (2008). Selection of coherent deposit-type locations and their application in data-driven mineral prospectivity mapping. Ore Geology Reviews,33, 536–558.
Carranza, E. J. M., & Laborte, A. G. (2015). Data-driven predictive mapping of gold prospectivity, Baguio district, Philippines: Application of random forests algorithm. Ore Geology Reviews,71, 777–787.
Carranza, E. J. M., Woldai, T., & Chikambwe, E. (2005). Application of data-driven evidential belief functions to prospectivity mapping for aquamarine-bearing pegmatites, Lundazi district, Zambia. Natural Resources Research,14, 47–63.
Carvalho, D., Barriga, F., & Munhá, J. (1999). Bimodal-siliciclastic systems—the case of the Iberian Pyrite Belt. Reviews in Economic Geology,8, 375–408.
Chan, J. C.-W., & Paelinckx, D. (2008). Evaluation of Random Forest and Adaboost tree-based ensemble classification and spectral band selection for ecotope mapping using airborne hyperspectral imagery. Remote Sensing of Environment,112, 2999–3011.
Cheng, Q. (2015). BoostWofE: A new sequential weights of evidence model reducing the effect of conditional dependency. Mathematical Geosciences,47, 591–621.
Chung, C. F., & Agterberg, F. P. (1980). Regression models for estimating mineral resources from geological map data. Journal of the International Association for Mathematical Geology,12, 473–488.
Conde Rivas, C., González Clavijo, E., Mellado Sánchez, D., & Tornos Arroyo, F. (2007). Apoyo cartográfico y estructural de los sulfuros masivos del sector septentrional de la faja pirítica ibérica. Instituto Geológico y Minero de España. http://info.igme.es/sidPDF/123000/836/123836_0000002.pdf. Accessed April 22, 2017.
Expósito, I., Simancas, J., Lodeiro, F. G., Bea, F., Montero, P., & Salman, K. (2003). Metamorphic and deformational imprint of Cambrian-Lower Ordovician rifting in the Ossa-Morena Zone (Iberian Massif, Spain). Journal of Structural Geology,25, 2077–2087.
Fawcett, T. (2006). An introduction to ROC analysis. Pattern Recognition Letters,27, 861–874.
Ford, A., Miller, J. M., & Mol, A. G. (2016). A comparative analysis of weights of evidence, evidential belief functions, and fuzzy logic for mineral potential mapping using incomplete data at the scale of investigation. Natural Resources Research,25, 19–33.
Freund, Y. (2001). An adaptive version of the boost by majority algorithm. Machine Learning,43, 293–318.
Freund, Y., & Schapire, R. E. (1997). A decision-theoretic generalization of on-line learning and an application to boosting. Journal of Computer and System Sciences,55, 119–139.
Ghimire, B., Rogan, J., Galiano, V. R., Panday, P., & Neeti, N. (2012). An evaluation of bagging, boosting, and random forests for land-cover classification in Cape Cod, Massachusetts, USA. GIScience & Remote Sensing,49, 623–643.
González, F., Moreno, C., Sáez, R., & Clayton, G. (2002). Ore genesis age of the Tharsis mining district (Iberian Pyrite Belt): a palynological approach. Journal of the Geological Society,159, 229–232.
Gumiel, P., Sanderson, D. J., Arias, M., Roberts, S., & Martín-Izard, A. (2010). Analysis of the fractal clustering of ore deposits in the Spanish Iberian Pyrite Belt. Ore Geology Reviews,38(4), 307–318.
Harris, D., & Pan, G. (1999). Mineral favorability mapping: a comparison of artificial neural networks, logistic regression, and discriminant analysis. Natural Resources Research,8, 93–109.
Hunter, J. D. (2007). Matplotlib: A 2D graphics environment. Computing in Science & Engineering,9, 90–95.
Julivert, M., and Fontboté, J., (1974). Mapa tectónico de la Península Ibérica y Baleares. Inst. Geol. Min. España.
Knox-Robinson, C. M. (2000). Vectoral fuzzy logic: a novel technique for enhanced mineral prospectivity mapping, with reference to the orogenic gold mineralisation potential of the Kalgoorlie Terrane. Western Australia. Australian Journal of Earth Sciences,47, 929–941.
Leistel, J., Marcoux, E., Thieblemont, D., Quesada, C., Sanchez, A., & Almodovar, G. (1998). The volcanic-hosted massive sulphide deposits of the Iberian Pyrite Belt. Review and preface to the Thematic Issue. Mineralium Deposita,33, 2–30.
Mantero, E. M., Alonso-Chaves, F. M., García-Navarro, E., & Azor, A. (2011). Tectonic style and structural analysis of the Puebla de Guzmán Antiform (Iberian Pyrite Belt, South Portuguese Zone, SW Spain). Geological Society London, Special Publications,349, 203–222.
Martin-Izard, A., Arias, D., Arias, M., Gumiel, P., Sanderson, D., Castañon, C., et al. (2015). A new 3D geological model and interpretation of structural evolution of the world-class Rio Tinto VMS deposit, Iberian Pyrite Belt (Spain). Ore Geology Reviews,71, 457–476.
McIntosh, S. M., Gill, J. P., & Mountford, A. J. (1999). The geophysical response of the Las Cruces massive sulphide deposit. Exploration Geophysics,30(3–4), 123–133.
Mitjavila, J., Marti, J., & Soriano, C. (1997). Magmatic evolution and tectonic setting of the Iberian Pyrite Belt volcanism. Journal of Petrology,38, 727–755.
Moreno, C., & González, F. (2004). Estratigrafía de la Zona Sudportuguesa. In J. A. Vera (Ed.), Geología de España (pp. 201–205). Madrid: IGME-Soc. Geol. Esp.
Morgan, L.A. (2012). Geophysical characteristics of volcanogenic massive sulfide deposits in volcanogenic massive sulfide occurrence model. U.S. Geological Survey Scientific Investigations Report, 2010–5070 –C, 16.
Nykänen, V. (2008). Radial basis functional link nets used as a prospectivity mapping tool for orogenic gold deposits within the Central Lapland Greenstone Belt, Northern Fennoscandian Shield. Natural Resources Research,17, 29–48.
Nykänen, V., Groves, D. I., Ojala, V. J., Eilu, P., & Gardoll, S. J. (2008). Reconnaissance-scale conceptual fuzzy-logic prospectivity modelling for iron oxide copper – gold deposits in the northern Fennoscandian Shield, Finland. Australian Journal of Earth Sciences,55, 25–38.
Nykänen, V., Lahti, I., Niiranen, T., & Korhonen, K. (2015). Receiver operating characteristics (ROC) as validation tool for prospectivity models—magmatic Ni–Cu case study from the Central Lapland Greenstone Belt, Northern Finland. Ore Geology Reviews,71, 853–860.
Oh, H.-J., & Lee, S. (2008). Regional probabilistic and statistical mineral potential mapping of gold-silver deposits using GIS in the Gangreung Area, Korea. Resource Geology,58, 171–187.
Oliveira, J. T. (1983). The marine carboniferous of South Portugal: a stratigraphic and sedimentological approach. In Lemos de Sousa L., Oliveira, J.T. (Eds.), The Carboniferous of Portugal (29–37). Mem. Serv. Geol. Port.
Oliveira, J. T. (1990). Stratigraphy and synsedimentary tectonism. In R. D. Dallmeyer & E. M. Garcia (Eds.), Pre-Mesozoic geology of Iberia (pp. 334–347). Berlin: Springer.
Oliveira, J. T., Garcia-Alcalde, J. L., Liñan, E., & Truyols, J. (1986). The Famennian of the Iberian Peninsula. Annales de la Société géologique de Belgique,109, 159–174.
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., et al. (2011). Scikit-learn: Machine learning in Python. Journal of Machine Learning Research,12, 2825–2830.
Porwal, A., Carranza, E. J. M., & Hale, M. (2003). Artificial neural networks for mineral-potential mapping: A case study from Aravalli Province, Western India. Natural Resources Research,12, 155–171.
Quesada, C. (1991). Geological constraints on the Paleozoic tectonic evolution of tectonostratigraphic terranes in the Iberian Massif. Tectonophysics,185, 225–245.
Reddy, R. K. T., & Bonham-Carter, G. F. (1991). A decision-tree approach to mineral potential mapping in Snow Lake Area, Manitoba. Canadian Journal of Remote Sensing,17, 191–200.
Rodriguez-Galiano, V. F., Chica-Olmo, M., Abarca-Hernandez, F., Atkinson, P. M., & Jeganathan, C. (2012). Random forest classification of mediterranean land cover using multi-seasonal imagery and multi-seasonal texture. Remote Sensing of Environment,121, 93–107.
Rodriguez-Galiano, V., Sanchez-Castillo, M., Chica-Olmo, M., & Chica-Rivas, M. (2015). Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geology Reviews,71, 804–818.
Routhier, P., Aye, F., Boyer, C., Lécolle, M., Molière, P., Picot, P., & Roger, G. (1980). La Ceinture sud-ibérique à amas sulfurés dans sa partie espagnole médiane. Tableau géologique et métallogénique. Synthèse sur le type amas sulfurés volcano-sédimentaires. In 26th International Geological Congress, Editions du BRGM (94-265). Paris: BRGM.
Sáez, R., Almodóvar, G., & Pascual, E. (1996). Geological constraints on massive sulphide genesis in the Iberian Pyrite Belt. Ore Geology Reviews,11, 429–451.
Sáez, R., Pascual, E., Toscano, M., & Almodóvar, G. (1999). The Iberian type of volcano-sedimentary massive sulphide deposits. Mineralium Deposita,34, 549–570.
Schaeben, H., & Semmler, G. (2016). The quest for conditional independence in prospectivity modelling: weights-of-evidence, boost weights-of-evidence, and logistic regression. Frontiers of Earth Science,10, 389–408.
Schermerhorn, L. J. G. (1971). An outline stratigraphy of the Iberian Pyrite Belt. Boletín Geológico y Minero,82, 239–268.
Simancas, J. F., Carbonell, R., Lodeiro, F. G., Estaún, A. P., Juhlin, C., Ayarza, P., et al. (2006). Transpressional collision tectonics and mantle plume dynamics: The Variscides of southwestern Iberia. Geological Society London, Memoirs,32, 345–354.
Singer, D. A., & Kouda, R. (1996). Application of a feedforward neural network in the search for Kuroko deposits in the Hokuroku district, Japan. Mathematical Geology,28, 1017–1023.
Tangestani, M. H., & Moore, F. (2001). Porphyry copper potential mapping using the weights-of- evidence model in a GIS, northern Shahr-e-Babak, Iran. Australian Journal of Earth Sciences,48, 695–701.
Tien Bui, D., Pradhan, B., Lofman, O., Revhaug, I., & Dick, O. B. (2012). Spatial prediction of landslide hazards in Hoa Binh province (Vietnam): A comparative assessment of the efficacy of evidential belief functions and fuzzy logic models. CATENA,96, 28–40.
Toscano, M., Pascual, E., Nesbitt, R. W., Almodóvar, G. R., Sáez, R., & Donaire, T. (2014). Geochemical discrimination of hydrothermal and igneous zircon in the Iberian Pyrite Belt, Spain. Ore Geology Reviews,56, 301–311.
Van den Boogaard, M. (1963). Conodonts of the upper Devonian and lower Carboniferous age from Southern Portugal. Geologie en Mijnbouw,42, 248–259.
Velasco, F., Sánchez-España, J., Boyce, A., Fallick, A., Sáez, R., & Almodóvar, G. (1998). A new sulphur isotopic study of some Iberian Pyrite Belt deposits: evidence of a textural control on sulphur isotope composition. Mineralium Deposita,34, 4–18.
Xiao, K., Li, N., Porwal, A., Holden, E.-J., Bagas, L., & Lu, Y. (2015). GIS-based 3D prospectivity mapping: A case study of Jiama copper-polymetallic deposit in Tibet, China. Ore Geology Reviews,71, 611–632.
Zhu, J., Rosset, S., Zou, H., & Hastie, T. (2006). Multi-class adaboost. Ann Arbor,1001(48109), 1612.
Zuo, R., & Carranza, E. J. M. (2011). Support vector machine: A tool for mapping mineral prospectivity. Computers & Geosciences,37, 1967–1975.
Acknowledgments
We would like to thank Esri Germany for funding the thesis leading to this manuscript. Furthermore, we would also like to thank Fernando Cortés Caballero (Proyecto Río Tinto, Exploración y Geología) for explaining and providing the GIS datasets used in this study and Isla Fernandez for providing information about the geophysical datasets. Furthermore, we would like to thank Marjean Pobuda, Esri Inc., Kent Middleton and Chris Smith for their help with spelling and grammar corrections. Finally, we would like to thank the anonymous reviewers for their effort that helped improve the paper significantly.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Brandmeier, M., Cabrera Zamora, I.G., Nykänen, V. et al. Boosting for Mineral Prospectivity Modeling: A New GIS Toolbox. Nat Resour Res 29, 71–88 (2020). https://doi.org/10.1007/s11053-019-09483-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11053-019-09483-8