
Abstract
We consider systems of rational agents who act and interact in pursuit of their individual and collective objectives. We study and formalise the reasoning of an agent, or of an external observer, about the expected choices of action of the other agents based on their objectives, in order to assess the reasoner’s ability, or expectation, to achieve their own objective. To formalize such reasoning we extend Pauly’s Coalition Logic with three new modal operators of conditional strategic reasoning, thus introducing the Logic for Local Conditional Strategic Reasoning \(\mathsf {ConStR}\). We provide formal semantics for the new conditional strategic operators in concurrent game models, introduce the matching notion of bisimulation for each of them, prove bisimulation invariance and Hennessy–Milner property for each of them, and discuss and compare briefly their expressiveness. Finally, we also propose systems of axioms for each of the basic operators of \(\mathsf {ConStR}\) and for the full logic.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Consider the following scenario. Alice and Bob are students at DownTown University. Alice is coming to campus today, and has some agenda to complete. Bob wants to meet Alice somewhere on campus today. She does not know that (maybe, even does not know Bob) and they have no communication. Bob may, or may not, know what Alice is going to do on campus, or where and at what time she will go during the day. Using his knowledge of what, where, and when Alice intends to do today, Bob wants to come up with a plan of how (where and when) to meet her.
From a more general perspective, we consider a scenario of agents acting independently, and possibly concurrently, in pursuit of their individual and collective goals and we analyse the reasoning of an agent (or, observer) about the possible local actions (at the current state only) of the other agents and their effect for realising or enabling the outcome of interest for the reasoner.
Related work and motivation. The kind of strategic reasoning discussed here is within the conceptual thrust motivating the research on logic-based strategic reasoning over the past two decades, starting with Coalition Logic CL (Pauly, 2001, 2002), its temporal extension, the alternating-time temporal logic ATL (Alur et al., 2002), its epistemic extension ATEL (van der Hoek & Wooldridge, 2004), and gradually evolving towards increasingly expressive formalisms, such Strategy Logic SL (Mogavero et al., 2014; cf. 2017). See Ågotnes et al. (2015) and van Benthem et al. (2015) for overviews of the area. Most of these logical systems (except SL where the agents’ strategies are explicitly named in the language) assume arbitrary or adversarial behaviour of the agents outside of the proponent coalitions in CL, ATL, and ATEL. Also, the knowledge of the agents involved in ATEL refers to truths (of formulae in the language) at the current state, rather than to their knowledge about each others’ objectives and available actions. Thus, these logics formalise absolute/unconstrained strategic reasoning—usually, by an external observer—about the unconditional strategic abilities of agents and coalitions to achieve their goals. However, such unconstrained strategic reasoning is seldom applicable in practice, except in purely adversarial zero-sum games. Usually, all agents acting in the system (except for the environment, or an absolute adversary) have their own goals and act in pursuit of their fulfilment, rather than just to prevent the proponents from achieving their goals. This calls for a more refined strategic reasoning, conditional on the agents’ knowledge of the opponents’ goals and possible available actions to achieve them, which is the proposal of the present paper. It should be noted that there is a recent line of research on rational synthesis (Fisman et al., 2010; Kupferman et al., 2016) and rational verification (Gutierrez et al., 2017; Wooldridge et al., 2016), which does take into account all agents’ goals, but aims at designing stable strategy profiles (Nash equilibria) that only guarantee the satisfaction of the goal of one special agent (the proponent, representing the system), whereas all others are supposed to act rationally and accept the proposed solution, whether it satisfies their own goals or not. Thus, our work takes an essentially different perspective and has quite different objectives. We are aware of few other works that deal more directly and explicitly with conditional strategic reasoning in a sense akin to the present paper. Besides the earlier, conference version (Goranko & Ju, 2019) of this work, perhaps the closest to it in spirit is the recent (Goranko & Enqvist, 2018), to which the present work relates both conceptually and technically, as well as the conceptually related work (Naumov & Yuan, 2019), which presents a logic which can express statement of the type: “The coalition \(\mathrm {B}\) has a strategy to achieve their goal once they know the strategy of the coalition \(\mathrm {A}\), no matter what the strategy is”. If the epistemic ingredient in it is considered implicit, this statement is expressible by our operator for ‘reactive strategic ability’ \({\mathsf {O}}_{\beta } \). We also note that an axiomatic system is proposed and proved complete in Naumov and Yuan (2019), which shares some basic axioms with our axiom system for \({\mathsf {O}}_{\beta } \) presented in Sect. 6.3, but differs from it on others.
Our contributions. In this work we identify several patterns of conditional strategic reasoning of an observer or an active agent, depending on his/her knowledge about the objectives and possible actions of the other agents. To formalize such reasoning we extend Coalition Logic (Pauly, 2001, 2002) with three new modal operators of conditional strategic reasoning, thus introducing the Logic for Local Conditional Strategic Reasoning \(\mathsf {ConStR}\). We provide formal semantics for the new conditional strategic operators, introduce the matching notion of bisimulation for each of them and discuss and compare briefly their expressiveness. We then also propose systems of axioms for each of the basic operators of \(\mathsf {ConStR}\) and for the whole logic, without stating yet completeness claims (for lack of space, these are left to future work).
Structure of the Paper. Section 2 provides some preliminaries on concurrent game models and the coalition logic CL. Then, Sect. 3 presents an informal discussion on conditional strategic reasoning, motivating the further technical work. Section 4 introduces three modal operators formalising patterns of conditional strategic reasoning and the new logic \(\mathsf {ConStR}\) as an extension of Coalition Logic with these operators. Section 5 introduces the matching notion of bisimulation for that logic and discuss briefly it expressiveness. In Sect. 6 we propose systems of axioms for each of the basic operators of \(\mathsf {ConStR}\) and for the full logic. We end with brief concluding remarks in Sect. 7.
2 Preliminaries
Multi-agent game models. We fix a finite set of agents \({{\,\mathrm{{\mathbb {A}}gt}\,}}= \{a_1,\ldots ,a_n\}\) and a set of atomic propositions \(\Pi \). Subsets of \({{\,\mathrm{{\mathbb {A}}gt}\,}}\) will also be called coalitions.
Definition 1
A game modelFootnote 1 for \({{\,\mathrm{{\mathbb {A}}gt}\,}}\) and \(\Pi \) is a tuple
where S is a non-empty set of states; each \(\varSigma _{a}\) is a non-empty set of possible actions of agent a; \(V: \Pi \rightarrow {\mathcal {P}}({S}) \) is a valuation of the atomic propositions from \(\Pi \) in S; and g is a game map that assigns to each \(s \in S\) a strategic game form \(g(s) = (\varSigma ^{s}_{a_1},\ldots \varSigma ^{s}_{a_n},o_{s})\), where each \(\varSigma ^{s}_{a_i} \subseteq \varSigma _{a_i}\) is a non-empty set of actions available to player \(a_i\) at s, and
is a local outcome function assigning to any action profile \(\sigma \in \varSigma ^{s}_{a_1} \times \cdots \times \varSigma ^{s}_{a_n}\) the outcome state \(o_{s}(\sigma )\) produced by \(\sigma \) when applied at \(s\in S\). The set \(\varSigma ^{s}_{a_1} \times \cdots \times \varSigma ^{s}_{a_n}\) of action profiles available at s will be denoted by \({{\,\mathrm{Act}\,}}_s\).
Now, the global outcome function in \({\mathcal {M}} \) is the partial mapping
defined by \(O(s,\sigma ) = o_{s}(\sigma )\), whenever \(\sigma \in {{\,\mathrm{Act}\,}}_s\).
Given a coalition \(\mathrm {C} \subseteq {{\,\mathrm{{\mathbb {A}}gt}\,}}\), a joint action for \(\mathrm {C} \) in the model \({\mathcal {M}} \) is a tuple of individual actions \(\sigma _{\mathrm {C}} \in \prod _{a \in \mathrm {C}} \varSigma _a\). For any such joint action \(\sigma _{\mathrm {C}}\) that is available at \(s \in S\), we define the set of outcome states from \(\sigma _{\mathrm {C}}\) at s:
where \(\sigma \vert _{\mathrm {C}}\) is the restriction of \(\sigma \) to \(\mathrm {C} \). Note that the empty tuple \(\sigma _\emptyset \) is the only available joint action for the empty coalition \(\emptyset \) at any state.
The basic logic for coalitional strategic reasoning \(\mathsf {CL}\). The Coalition Logic \(\mathsf {CL}\) was introduced in Pauly (2001), cf. also Pauly (2002). \(\mathsf {CL}\) extends the classical propositional logic with coalitional strategic modal operators \(\left[ {\mathrm {C}} \right] \), for any coalition of agents \(\mathrm {C} \). The formulae of \(\mathsf {CL}\) are defined as follows:
We will write \(\left[ {{\mathsf {i}}} \right] \) instead of \(\left[ {\{{\mathsf {i}} \}} \right] \). The intuitive reading of \(\left[ {\mathrm {C}} \right] \varphi \) is:
“The coalition \(\mathrm {C} \) has a joint action that ensures an outcome (state) satisfying \(\varphi \), regardless of how all other agents act.”
The semantics of \(\mathsf {CL}\) is defined in terms of the notion of truth of a \(\mathsf {CL}\)-formula \(\psi \) at a state s of a game model \({\mathcal {M}} \), denoted \({{\mathcal {M}},s \vDash \psi }\), by induction on formulae, via the key clause:
-
\({\mathcal {M}},s\models \left[ {\mathrm {C}} \right] \phi ~ \Leftrightarrow \) there exists a joint action \(\sigma _{\mathrm {C}}\) available at s, such that \({\mathcal {M}},u\models \phi \) for each \(u \in \mathsf {Out} [s,\sigma _{\mathrm {C}}]\)
Thus, \(\left[ {\mathrm {C}} \right] \phi \) formalises a claim of the ability of the agent/coalition \(\mathrm {C} \) to choose a suitable (joint) action to ensure achieving the goal \(\phi \) regardless of how all other agents choose to act, and therefore without assuming that the agents in \(\mathrm {C} \) know the goal(s) of the remaining agents and their available actions to achieve these goals.
The notion of bisimulation that guarantees truth invariance of all \(\mathsf {CL}\)-formulae was first defined in Alur et al. (1998) for the so called ‘alternating transition systems’ (equivalent to a special case of concurrent game models), then independently in Pauly (2001) for the abstract game models defined there, and later in Ågotnes et al. (2007) for concurrent game models, which definition we give here.
Definition 2
(\(\mathsf {CL}\)-bisimulation) Let \({\mathcal {M}} = (S,\{\varSigma _{a}\}_{a\in {{\,\mathrm{{\mathbb {A}}gt}\,}}},g,V)\) be a concurrent game model. A binary relation \({\mathcal {R}}\subseteq S^{2}\) is a \(\mathsf {CL}\)-bisimulation in \({\mathcal {M}} \)if it satisfies the following conditions for every pair of states \((s_1, s_2)\) such that \(s_1 {\mathcal {R}}s_2\) and for every coalition \(\mathrm {C} \):
-
Atom equivalence: For every \(p \in \Pi \): \(s_1 \in V(p)\) iff \(s_2 \in V(p)\).
-
Forth: For every joint action \(\sigma ^{1}_{\mathrm {C}}\) of \(\mathrm {C} \) at \(s_1\), there is a joint action \(\sigma ^{2}_{\mathrm {C}}\) of \(\mathrm {C} \) at \(s_2\) such that for every \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {C}}]\) there exists \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {C}}]\) such that \(u_1 {\mathcal {R}}u_2\).
-
Back: Like Forth, but with 1 and 2 swapped.
\(\mathsf {CL}\)-bisimulation is defined here within a model. It readily extends to \(\mathsf {CL}\)-bisimulation between models, by treating both as parts of a single model.
The Alternating-time Temporal Logic \(\mathsf {ATL}^* \). The Alternating-time Temporal Logic \(\mathsf {ATL}^* \), proposed by Alur et al. (2002), is an extension of \(\mathsf {CL}\) with temporal operators. Its featured operator is \(\langle \!\langle {\mathrm {\mathrm {C}}}\rangle \!\rangle \phi \), denoting the claim that \(\mathrm {C} \) has a joint strategy that guarantees the satisfaction of \(\phi \), where \(\phi \) is a ‘temporal objective’, i.e. a (path) formula beginning with a temporal operator ‘nexttime’ \(\mathord {\mathsf {X}}\, \), ‘always’ \(\mathord {\mathsf {G}}\, \), or ‘until’ \(\, {\mathsf {U}} \, \). The logic \(\mathsf {CL}\) embeds into \(\mathsf {ATL}^* \) as the fragment extending propositional logic only with combinations of strategic and temporal operators of the type \(\langle \!\langle {\mathrm {\mathrm {C}}}\rangle \!\rangle \mathord {\mathsf {X}}\, \), cf. Goranko (2001). We only mention \(\mathsf {ATL}^* \) here for the sake of some further references, but the present paper will not make any essential use of that logic, and no familiarity with it, nor even with its fragment \(\mathsf {ATL}\), is required.
3 Conditional Strategic Reasoning: An Informal Discussion
Footnote 2Recall the scenario with the students Alice and Bob. Suppose that Alice has an objective \(\gamma _{A}\) to achieve—say, to meet with her supervisor Carl on campus today. Suppose also that Alice has several possible choices of an action (or a ‘strategy’)Footnote 3 that would possibly, or certainly, guarantee the achievement of her objective. In our example, suppose these choices are: meeting in the supervisor’s office, or in the library, or at the campus café.
3.1 Observer’s Conditional Reasoning About An Outcome from Agent’s Actions
Let us first consider the case where Bob is just an observer who is not acting, but only reasoning about the consequences from Alice’s possible actions with respect to the occurrence of another—intended or not—outcome event \(\gamma _{B}\). For instance, suppose that Bob is interested in meeting with Alice on campus today—let us call that event \(\gamma _{B}\)—and is sitting in the campus café and reasoning about whether Alice will happen to come to the café, thus enabling the event \(\gamma _{B}\) (recall that Alice may not know about bob expecting her there, or at all). More generally, we can also assume that there are other agents, besides Alice, also acting in pursuit of their own goals, and Bob is reasoning about their individual and collective choices of action and the consequences from these choices. This leads to an observer’s conditional strategic reasoning about claims of the type:
“Some/every action of Alice that guarantees achievement of \(\gamma _{A}\) also guarantees/enables occurrence of the outcome \(\gamma _{B}\)”.
Depending on Bob’s knowledge about Alice’s objective and of her expected choices of action there can be several possible cases for Bob’s reasoning about the expected occurrence of the outcome \(\gamma _{B}\).
3.1.1 Observer Bob’s Reasoning, Case 1: Bob Knows Nothing About Alice
Suppose that Bob does not know Alice’s objective \(\gamma _{A}\), and therefore has no a priori expectations about her choice of action. In our example, suppose that Bob only knows that Alice is coming to campus today, but not why and where on campus she is going. Then, Bob can only claim for sure that the outcome \(\gamma _{B}\) will occur if \(\gamma _{B}\) is inevitable, regardless of how Alice (and all others) will act. For instance, if Bob knows that Alice is coming to campus and he is standing by the only entrance of the campus, then he will know for sure that he is going to meet Alice (\(\gamma _{B}\) will occur), no matter what she will do there. This claim can be expressed in Coalition Logic \(\mathsf {CL}\) simply as \([\emptyset ] \gamma _{B}\).
3.1.2 Observer Bob’s Reasoning, Case 2: Bob Only Know Alice’s Goal
Suppose now that Bob does know Alice’s objective and knows that Alice can guarantee the achievement of that objective and will act towards that, but Bob does not know how exactly Alice might act. E.g., Bob knows that Alice is coming to campus to meet with her supervisor Carl but does not know where and when. Then, Bob can only claim that the outcome \(\gamma _{B}\) will occur for sure if \(\gamma _{B}\) is true on every possible course of events (“play”) on which \(\gamma _{A}\) is true. For instance, if Bob knows that Alice’s supervisor will be working in his office for the whole day, and he is sitting in the corridor, next to Carl’s office, then he knows that he will meet with Alice (\(\gamma _{B}\) will occur) no matter when Alice comes to meet with Carl (i.e. no matter how \(\gamma _{A}\) occurs).
This can be expressed in \(\mathsf {CL}\) simply as \([ \emptyset ] (\gamma _{A} \rightarrow \gamma _{B})\) and reflects the case when \(\gamma _{A}\) can occur in various, possibly unintended ways, but its occurrence always implies the occurrence of \(\gamma _{B}\) (e.g. if Bob is with Carl throughout the day, then even if Alice bumps into Carl accidentally, Bob will still meet her).
3.1.3 Observer’s Reasoning, Case 3: Bob Knows Alice’s Goal and Actions
Suppose now that Bob not only knows Alice’s objective, but also knows all possible actions (or, strategies) of Alice that can ensure the satisfaction of her objective \(\gamma _{A}\), and knows that Alice will perform one of them, but does not know to which one. (E.g., Bob knows that Alice, who is coming to campus to meet with her supervisor, can meet with him either in his office, or in the library, or in the café.)
Now, for Bob to claim that the outcome \(\gamma _{B}\) will occur for sure, it suffices to know that each action of Alice that guarantees \(\gamma _{A}\) will also guarantee \(\gamma _{B}\). (E.g., suppose that all possible meeting places for Alice and her supervisor are in the main building and Bob is waiting at the only entrance of the main building.)
Here the conditional “If \(\gamma _{A}\) then \(\gamma _{B}\)” has a suitably constrained context, specifying that \(\gamma _{A}\) can occur only because the agent (Alice) takes a deliberate action to bring about \(\gamma _{A}\). This can no longer be expressed in \(\mathsf {CL}\) and requires introducing a new strategic operator.
Lastly, suppose that Bob also knows the specific action which Alice is taking in order to guarantee the achievement of her goal. Then, Bob can claim that the outcome \(\gamma _{B}\) will occur for sure, as long as that specific action of Alice guarantees the satisfaction of \(\gamma _{B}\). To formalise that one needs explicit names for actions, but in our logic we will be able to state something stronger, viz. that every specific action of Alice that guarantees \(\gamma _{A}\) will also bring about \(\gamma _{B}\).
3.2 Conditional Reasoning of an Agent About Another Agent’s Actions
Suppose now that Bob is not just a passive observer, but an acting agent, who has the outcome \(\gamma _{B}\) as his own goal. There may be other agents, besides Alice and Bob, also acting in pursuit of their own goals, and Bob is reasoning about their expected choices of action and the consequences from these choices. Now, Bob is to decide—based on his reasoning about Alice’s (and other agents’) possible choices of actions—on his own action in pursuit of \(\gamma _{B}\). This calls for an agent’s conditional strategic reasoning about statements of the type:
“For some/every action of Alice that guarantees achievement of \(\gamma _{A}\), Bob has an action of his own to guarantee achievement of his objective \(\gamma _{B}\)”.
We call this local conditional strategic reasoning, as it only refers to the immediate actions of the agents, not about their global strategies. Respectively, the outcomes from the local action profiles are just successor states, while in the general case they are (finite or possibly infinite) plays. The global conditional strategic reasoning will be treated in a follow-up work.
Each of the cases considered in Sect. 3.1 accordingly applies here, too, with the only difference being that now Bob is to choose a suitable action of his own. Besides, there are several additional cases to consider regarding the possible choice of action of Bob.
3.2.1 Agent Bob’s Reasoning, Case 1a: Assuming Alice’s Cooperation
First, suppose, in addition, that Alice also knows Bob’s objective and can choose to cooperate with Bob by selecting a suitable action \(\sigma _\mathrm {A} \) that would not only guarantee achievement of her objective but will also enable Bob to supplement \(\sigma _\mathrm {A} \) with an action \(\sigma _\mathrm {B} \) which would then also guarantee achievement of his objective, too. (So, we also assume that Alice knows enough about Bob’s possible actions.) We refer the reader to Example 1 for a formal model illustrating the agent’s ability assuming cooperation from the other agent.
3.2.2 Agent Bob’s Reasoning, Case 1b: Not Assuming Alice’s Cooperation
Now, suppose Bob cannot count on Alice’s cooperation. Still, the statement
“Whichever way Alice acts towards achieving the objective \(\gamma _{A}\), Bob can act so as to bring about achievement of his objective \(\gamma _{B}\).”
admits two different readings, which we respectively call ‘proactive ability’ and ‘reactive ability’ which we discuss below.Footnote 4
3.2.3 Agent Bob’s Reasoning, Case 2: Reactive Ability
In this case, for every action of Alice that ensures \(\gamma _{A}\) Bob is to choose reactively an action of his, generally dependent on Alice’s action, that would also ensure the occurrence of \(\gamma _{B}\) (possibly in different ways for the different actions). This essentially corresponds to the case where Bob knows Alice’s action at the time of choosing his own action, and for every choice of action of Alice that guarantees \(\gamma _{A}\), Bob’s respective choice will also bring about \(\gamma _{B}\). For instance, in our running example, if Bob knows where Alice is going to meet with her supervisor, he can choose respectively where to go and wait for her.
More formally, each of Alice’s actions that would guarantee \(\gamma _{A}\) generates a set of possible outcome states (plays), and for each such set Bob is looking for a respective action that will bring about \(\gamma _{B}\) on that set of outcome states.
3.2.4 Agent Bob’s Reasoning, Case 3: Proactive Ability
The case of proactive ability is when Bob only knows that Alice has committed to act so as to achieve her goal \(\gamma _{A}\) (to meet with Carl at one of the 3 possible meeting places), but does not knows the action that Alice has chosen and her choice will remain unknown to Bob at the time when he is to choose his action aiming at satisfying \(\gamma _{B}\) (meet Alice).
In this case Bob must consider all possible courses of events (plays) that can occur as a result of Alice acting towards achieving \(\gamma _{A}\) and reason about whether he can choose proactively and uniformly one action that would bring about \(\gamma _{B}\) regardless of which action Alice may choose to apply in order to achieve her goal \(\gamma _{A}\). For instance, in our running story, assuming that all meeting places are in the main building, Bob can choose to wait for Alice at the only entrance of that building. Formally speaking, in this case, based on his knowledge Bob considers the set of states in the model which is the union of all sets of outcome states enabled by the specific actions of Alice that would guarantee \(\gamma _{A}\), and is looking for an action that will bring about \(\gamma _{B}\) on each of these outcome states.
We refer the reader to Example 2 for a formal model illustrating the concepts of proactive and reactive abilities of an agent and their difference.
Top sum up, the proactive–reactive ability distinction applies to Bob depending on whether or not he knows Alice’s choice at the time when he is to make his own choice of action. If he knows Alice’s choice at that time, his reasoning is about reactive ability, else it is a proactive ability reasoning. We note that the notions of proactive and reactive ability respectively correspond to the notions of \(\alpha \)-effectivity and \(\beta \)-effectivity in game theory (cf. e.g. Abdou & Keiding, 1991).
Lastly, an important point: even though knowledge of the agent about the other’s goals and possible actions is essential, it will not feature in our formal logical language, nor in the formal semantics, but only in the external reasoners’ analysis of which case of conditional strategic ability applies.
4 The Logic of Conditional Strategic Reasoning \(\mathsf {ConStR}\)
4.1 Modal Operators for Conditional Strategic Reasoning
Given coalitions \(\mathrm {A} \) and \(\mathrm {B} \) and joint actions \(\sigma _\mathrm {A} \) for \(\mathrm {A} \) and \(\sigma _\mathrm {B} \) for \(\mathrm {B} \), we say that \(\sigma _\mathrm {B} \) is consistent with \(\sigma _\mathrm {A} \) if \(\sigma _\mathrm {B} \) coincides with \(\sigma _\mathrm {A} \) on \(\mathrm {A} \cap \mathrm {B} \).
We now introduce new operators for conditional strategic reasoning, for any coalitions \(\mathrm {A} \) and \(\mathrm {B} \), with intuitive semantics corresponding to the three reasoning cases in Sect. 3.2, as follows.
(\({\mathsf {O}}_{c} \)) \(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\) says that \(\mathrm {A} \) has a joint action \(\sigma _\mathrm {A} \) which, when applied, guarantees the truth of \(\phi \) and enables \(\mathrm {B} \) to apply a joint action \(\sigma _\mathrm {B} \) that is consistent with \(\sigma _\mathrm {A} \) and guarantees \(\psi \) when additionally applied by \(\mathrm {B} \), in sense that all agents in \(\mathrm {A} \) act according to \(\sigma _\mathrm {A} \) and those in \(\mathrm {B} {\setminus } \mathrm {A} \) act according to \(\sigma _\mathrm {B} \)Footnote 5 This operator formalises the agent’s reasoning Case 1 discussed in Sect. 3.2, where \(\mathrm {A} \) knows the objective of \(\mathrm {B} \) and can choose to cooperate with \(\mathrm {B} \) by selecting a suitable action.
(\({\mathsf {O}}_{\alpha } \)) \([\mathrm {\mathrm {A}}]_\alpha (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\) says that the coalition \(\mathrm {B} {\setminus } \mathrm {A} \) has an action \(\sigma _{\mathrm {B} {\setminus } \mathrm {A}}\) such that if \(\mathrm {A} \) applies any action that guarantees the truth of \(\phi \), then \(\mathrm {B} {\setminus } \mathrm {A} \) can guarantee the truth of \(\psi \) by applying additionally the action \(\sigma _{\mathrm {B} {\setminus } \mathrm {A}}\).
This operator formalises a claim of the ability of the agent/coalition \(\mathrm {B} \) to choose a suitable (joint) action so as to achieve the goal \(\psi \) assuming that \(\mathrm {A} \) acts so as to achieve the goal \(\phi \), if \(\mathrm {B} \) is to choose their (joint) action before \(\mathrm {A} \) chooses their (joint) action, or before \(\mathrm {B} \) learns the action of \(\mathrm {A} \). This corresponds to the notion of agent’s proactive ability discussed in Sect. 3.2.4, respectively to the game-theoretic notion of \(\alpha \)-effectivity, hence the notation.
(\({\mathsf {O}}_{\beta } \)) \([\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\) says that for any joint action \(\sigma _\mathrm {A} \) of \(\mathrm {A} \) that guarantees the truth of \(\phi \), when applied by \(\mathrm {A} \) there is an action \(\sigma _\mathrm {B} \) that is consistent with \(\sigma _\mathrm {A} \) and guarantees \(\psi \) when additionally applied by \(\mathrm {B} \).Footnote 6 This operator formalises a claim of the ability of the agent/coalition \(\mathrm {B} \) to choose a suitable (joint) action so as to achieve the goal \(\psi \) assuming that \(\mathrm {A} \) acts so as to achieve the goal \(\phi \), if \(\mathrm {B} \) is to choose their (joint) action after \(\mathrm {B} \) learns the (joint) action of \(\mathrm {A} \). This corresponds to the notion of agent’s reactive ability discussed in Sect. 3.2.3, respectively to the game-theoretic notion of \(\beta \)-effectivity, hence the notation.
4.2 The Language of \(\mathsf {ConStR}\)
We fix a finite nonempty set of agents \({{\,\mathrm{{\mathbb {A}}gt}\,}}\) and a countable set of atomic propositions \(\Pi \). The formulae of \(\mathsf {ConStR} \), where \(p \in \Pi \) and \(\mathrm {A}, \mathrm {B} \subseteq {{\,\mathrm{{\mathbb {A}}gt}\,}}\) are defined as follows:
4.3 Some Definable Operators and Expressions in \(\mathsf {ConStR}\)
The following can be easily seen from the informal semantics above, and can also be easily verified with the formal semantics introduced further.
- –:
-
The coalitional operator from \(\mathsf {CL}\) is definable as a special case of each of \({\mathsf {O}}_{c} \), \({\mathsf {O}}_{\alpha } \), \({\mathsf {O}}_{\beta } \) as follows:
- (\({\mathsf {O}}_{c} \)):
-
\([\mathrm {\mathrm {A}}] \phi := \langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {A}} \rangle \phi )\) or \([\mathrm {\mathrm {A}}] \phi := \langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {A}} \rangle \top )\);
- (\({\mathsf {O}}_{\alpha } \)):
-
\([\mathrm {\mathrm {A}}] \phi := [\mathrm {\emptyset }]_\alpha (\top ; \langle \mathrm {\mathrm {A}} \rangle \phi )\). This expresses the case when \(\mathrm {B} \) is not informed about the goal of \(\mathrm {A} \) and has to choose proactively a joint action, before \(\mathrm {A} \) has chosen their action. Thus, it indeed claims an unconditional ability of \(\mathrm {B} \) to choose an action that guarantees \(\phi \).
- (\({\mathsf {O}}_{\beta } \)):
-
\([\mathrm {\mathrm {A}}] \phi := [\mathrm {\emptyset }]_\beta (\top ; \langle \mathrm {\mathrm {A}} \rangle \phi )\), or \([\mathrm {\mathrm {A}}] \phi := [\mathrm {{\overline{\mathrm {A}}}}]_\beta (\top ; \langle \mathrm {\mathrm {A}} \rangle \phi )\); (the empty coalition has only one strategy, and it guarantees the satisfaction of \(\top \))
Thus, the cases of observer’s reasoning discussed in Sects. 3.1.1 and 3.1.2 are readily formalisable in \(\mathsf {ConStR}\).
- –:
-
The dual to \({\mathsf {O}}_{c} \) operator \(\lnot \langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \lnot \psi )\) says that every joint action of \(\mathrm {A} \) that, when applied, guarantees the truth of \(\phi \), would prevent \(\mathrm {B} \) from acting additionally so as to guarantee \(\psi \). This formalises the conditional reasoning scenario where the goals of \(\mathrm {A} \) and \(\mathrm {B} \) are conflicting and where Bob can establish that whichever way \(\mathrm {A} \) acts towards their goal, that would block \(\mathrm {B} \) from acting to guarantee achievement of its goal.
- –:
-
\([\mathrm {\mathrm {A}}]_\beta (\top ; \langle \mathrm {\mathrm {B}} \rangle \psi )\) essentially formalises the case when \(\mathrm {B} \) is not informed about the goal of \(\mathrm {A} \), but has to choose their action after learning the action of \(\mathrm {A} \).
- –:
-
On the other hand, \([\mathrm {\mathrm {A}}]_{\mathsf {c}}(\phi | \psi ) := [\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\emptyset } \rangle \psi )\), also equivalent to \([\mathrm {\mathrm {A}}]_\alpha (\phi ; \langle \mathrm {\emptyset } \rangle \psi )\), says that for any joint strategy of \(\mathrm {A} \), if it guarantees \(\phi \) to be true, then it guarantees \(\psi \) to be true, too. That formalises the case in Sect. 3.1.3 of reasoning of an observer who knows both the goal \(\phi \) and the possible actions of \(\mathrm {A} \), about the occurrence of outcome \(\psi \).
- –:
-
\(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi | \psi ) := \lnot [\mathrm {\mathrm {A}}]_{\mathsf {c}}(\phi | \lnot \psi )\) says that there is a joint strategy of \(\mathrm {A} \) that guarantees \(\phi \) to be true and enables \(\psi \) to be true, too. Note that it is equivalent to a special case of the “socially friendly coalitional operator" SF, \([\mathrm {C}](\phi ; \psi _{1},\ldots ,\psi _{k})\), introduced in Goranko and Enqvist (2018), viz. \(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi | \psi ) \equiv [\mathrm {A}](\phi ; \psi )\).
Moreover, \(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi | \psi )\) is also definable as \(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {{\overline{\mathrm {A}}}} \rangle \psi )\), where \({\overline{\mathrm {A}}} = {{\,\mathrm{{\mathbb {A}}gt}\,}}{\setminus } \mathrm {A} \).
- –:
-
The coalitional operator \([\mathrm {A} ]\) from \(\mathsf {CL}\) is a special case of the above: \([\mathrm {\mathrm {A}}] \phi :=\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi | \top )\), meaning “\(\mathrm {A} \) has a joint action to ensure the truth of \(\phi \)”.Footnote 7
- –:
-
\(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\) is definable in terms of the “group protecting coalitional operator" GP, introduced in Goranko and Enqvist (2018): \(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \equiv \langle \![A \triangleright \phi , \mathrm {A} \cup \mathrm {B} \triangleright \psi ]\!\rangle \). Nevertheless, it now has a different motivation and intuitive interpretation.
4.4 Formal Semantics of \(\mathsf {ConStR} \)
Given coalitions \(\mathrm {A}, \mathrm {B} \subseteq {{\,\mathrm{{\mathbb {A}}gt}\,}}\) and joint actions \(\sigma _\mathrm {A} \) for \(\mathrm {A} \) and \(\sigma _\mathrm {B} \) for \(\mathrm {B} \), we define \(\sigma _\mathrm {A} \uplus \sigma _\mathrm {B} \) to be the joint action for \(\mathrm {A} \cup \mathrm {B} \) which equals to \(\sigma _\mathrm {A} \) when restricted to \(\mathrm {A} \) and equals to \(\sigma _\mathrm {B} \vert _{\mathrm {B} {\setminus } \mathrm {A}}\) when restricted to \(\mathrm {B} {\setminus } \mathrm {A} \). Thus, in particular, \(\sigma _\mathrm {A} \uplus \sigma _\mathrm {B} =\sigma _\mathrm {A} \) for any \(\mathrm {B} \subseteq \mathrm {A} \subseteq {{\,\mathrm{{\mathbb {A}}gt}\,}}\).
Now, let \({\mathcal {M}} = (S,\{\varSigma _{a}\}_{a\in {{\,\mathrm{{\mathbb {A}}gt}\,}}}, g,V)\) be a game model. The formal semantics of \(\mathsf {ConStR}\) extends the one of \(\mathsf {CL}\) to the new operators as follows:
-
\({\mathcal {M}}, s \Vdash \langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) ~ \Leftrightarrow \) \(\mathrm {A} \) has a joint action \(\sigma _\mathrm {A} \), such that
\({\mathcal {M}}, u \Vdash \phi \) for every \(u \in \mathsf {Out} [s,\sigma _\mathrm {A} ]\) and \(\mathrm {B} \) has a joint action \(\sigma _\mathrm {B} \)
such that \({\mathcal {M}}, u \Vdash \psi \) for every \(u \in \mathsf {Out} [s,\sigma _\mathrm {A} \uplus \sigma _\mathrm {B} ]\).
-
\({\mathcal {M}}, s \Vdash [\mathrm {\mathrm {A}}]_\alpha (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) ~ \Leftrightarrow \) \(\mathrm {B} \) has a joint action \(\sigma _\mathrm {B} \) such that
for every joint action \(\sigma _\mathrm {A} \) of \(\mathrm {A} \), if \({\mathcal {M}}, u \Vdash \phi \) for every \(u \in \mathsf {Out} [s,\sigma _\mathrm {A} ]\),
then \({\mathcal {M}}, u \Vdash \psi \) for every \(u \in \mathsf {Out} [s,\sigma _\mathrm {A} \uplus \sigma _\mathrm {B} ]\).
-
\({\mathcal {M}}, s \Vdash [\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) ~ \Leftrightarrow \) for every joint action \(\sigma _\mathrm {A} \) of \(\mathrm {A} \) such that \({\mathcal {M}}, u \Vdash \phi \) for every \(u \in \mathsf {Out} [s,\sigma _\mathrm {A} ]\), \(\mathrm {B} \) has a joint action \(\sigma _\mathrm {B} \) (generally, dependent on \(\sigma _\mathrm {A} \)) such that \({\mathcal {M}}, u \Vdash \psi \) for every \(u \in \mathsf {Out} [s,\sigma _\mathrm {A} \uplus \sigma _\mathrm {B} ]\).
Remark
The semantics of each of the operators above can be re-stated to consider joint actions for \(\mathrm {B} {\setminus } \mathrm {A} \) rather than the whole \(\mathrm {B} \). For instance, it can be easily verified for the latter operator, that \({\mathcal {M}}, s \Vdash [\mathrm {\mathrm {A}}]_\alpha (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\) iff \(\mathrm {B} {\setminus } \mathrm {A} \) has a joint action \(\sigma _{\mathrm {B} {\setminus } \mathrm {A}}\) such that for every joint action \(\sigma _\mathrm {A} \) of \(\mathrm {A} \), if \({\mathcal {M}}, u \Vdash \phi \) for every \(u \in \mathsf {Out} [s,\sigma _\mathrm {A} ]\), then \({\mathcal {M}}, u \Vdash \psi \) for every \(u \in \mathsf {Out} [s,\sigma _\mathrm {A} \uplus \sigma _{\mathrm {B} {\setminus } \mathrm {A}}]\).
4.5 Some Examples
Here we provide a few simple examples illustrating the semantics of \(\mathsf {ConStR} \).
Example 1
The game model \({\mathcal {M}}\) below has two players, \({\mathsf {a}} \) and \({\mathsf {b}} \). Each has two actions at state \(s_0\): \(a_1, a_2\), resp. \(b_1, b_2\).

It is easy to see that \({\mathcal {M}}, s_0 \Vdash \langle \mathrm {{\mathsf {a}}}\rangle _{\mathsf {c}}(p; \langle \mathrm {{\mathsf {b}}} \rangle q)\), while \({\mathcal {M}}, s_0 \not \Vdash [\mathrm {{\mathsf {b}}}] q\).
Thus, an agent may have only conditional ability to achieve its goal.
Example 2
The game model \({\mathcal {M}}\) below has two players, \({\mathsf {a}} \) and \({\mathsf {b}} \). The agent \({\mathsf {a}} \) has 3 actions at state \(s_0\), \(a_1, a_2, a_3\), and \({\mathsf {b}} \) has 2 actions, \(b_1, b_2\).

Note that:
-
\({\mathcal {M}}, s_0 \Vdash [\mathrm {{\mathsf {a}}}]_\beta (p; \langle \mathrm {{\mathsf {b}}} \rangle q)\). Indeed, agent \({\mathsf {a}} \) has two actions at state \(s_0\) to ensure p: \(a_1\) and \(a_2\). For each of them, \({\mathsf {b}} \) has an action to ensure q, viz.: choose \(b_2\) if \({\mathsf {a}} \) chooses \(a_1\), and choose \(b_1\) if \({\mathsf {a}} \) chooses \(a_2\).
-
\({\mathcal {M}}, s_0 \not \Vdash [\mathrm {{\mathsf {a}}}]_\alpha (p; \langle \mathrm {{\mathsf {b}}} \rangle q)\). Indeed, neither \(b_1\) nor \(b_2\) ensures q against both choices \(a_1\) and \(a_2\) of \({\mathsf {a}} \). Thus, \({\mathsf {b}} \) does not have a uniform action to ensure q against any action of \({\mathsf {a}} \) that ensures p.
Therefore, \([\mathrm {{\mathsf {a}}}]_\alpha (p; \langle \mathrm {{\mathsf {b}}} \rangle q)\) and \([\mathrm {{\mathsf {a}}}]_\beta (p; \langle \mathrm {{\mathsf {b}}} \rangle q)\) are semantically different.
-
However, if the outcomes of \(({a_2}, {b_1})\) and \(({a_2}, {b_2})\) are swapped, then \([\mathrm {{\mathsf {a}}}]_\alpha (p; \langle \mathrm {{\mathsf {b}}} \rangle q)\) becomes true at \(s_0\) in the resulting model.
-
\(({\mathcal {M}}, s_0)\) does not satisfy the \(\mathsf {ATL}^* \) formula \([\![\mathrm {{\mathsf {a}}}]\!] (\mathrm {X} p \rightarrow \langle \!\langle {\mathrm {{\mathsf {b}}}}\rangle \!\rangle \mathrm {X} q)\) (where \([\![\mathrm {\mathrm {C}}]\!] \phi := \lnot \langle \!\langle {\mathrm {\mathrm {C}}}\rangle \!\rangle \lnot \phi \)), hence it is not equivalent to \([\mathrm {{\mathsf {a}}}]_\beta (p; \langle \mathrm {{\mathsf {b}}} \rangle q)\).
5 Bisimulations and Expressiveness of \(\mathsf {ConStR}\)
5.1 Bisimulations for \(\mathsf {ConStR}\)
The definition of \(\mathsf {ConStR}\)-bisimulation involves, besides atomic equivalence, 3 nested Forth and Back conditions, for each of the respective new operators \({\mathsf {O}}_{c} \), \({\mathsf {O}}_{\alpha } \), and \({\mathsf {O}}_{\beta } \).Footnote 8 As the definition of \(\mathsf {CL}\)-bisimulation given in Sect. 2, we only define \(\mathsf {ConStR}\)-bisimulation within a game model, which generalises to \(\mathsf {ConStR}\)-bisimulation between game models easily. Note that the nested back-and-forth conditions are needed because of the patterns of quantification in the semantic definitions of the new strategic operators: first quantification over the actions of \(\mathrm {A} \) and \(\mathrm {B} \), and then over the outcomes generated by these actions.
Definition 3
(\(\mathsf {ConStR}\)-bisimulation) Let \({\mathcal {M}} = (S,\{\varSigma _{a}\}_{a\in {{\,\mathrm{{\mathbb {A}}gt}\,}}}, g,V)\) be a game model. A binary relation \({\mathcal {R}}\subseteq S^{2}\) is a \(\mathsf {ConStR}\)-bisimulation in \({\mathcal {M}} \)if it satisfies the following conditions for every pair of states \((s_1, s_2)\) such that \(s_1 {\mathcal {R}}s_2\) and for every coalitions \(\mathrm {A} \) and \(\mathrm {B} \):
-
Atom equivalence: For every \(p \in \Pi \): \(s_1 \in V(p)\) iff \(s_2 \in V(p)\).
-
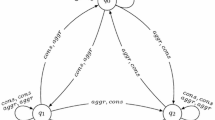
\({\mathsf {O}}_{c} \)-bisimulation: (For illustration, see Fig. 1.)
-
\(\mathrm {A} \)-\({{{\textbf {Forth}}}}_{\mathsf {c}}\): For every joint action \(\sigma ^{1}_{\mathrm {A}}\) of \(\mathrm {A} \) at \(s_1\) there is a joint action \(\sigma ^{2}_{\mathrm {A}}\) of \(\mathrm {A} \) at \(s_2\), such that:
-
\(\mathrm {A} \)-\({{\textbf {LocalBack}}}_{\mathsf {c}}\): For every \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}}]\) there exists \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}}]\) such that \(u_1 {\mathcal {R}}u_2\).
-
\(\mathrm {B} \)-\({{\textbf {Forth}}}_{\mathsf {c}}\): For every joint action \(\sigma ^{1}_{\mathrm {B}}\) of \(\mathrm {B} \) at \(s_1\) there is a joint action \(\sigma ^{2}_{\mathrm {B}}\) of \(\mathrm {B} \) at \(s_2\), such that:
-
(\(\mathrm {A} \uplus \mathrm {B} \))-\({{\textbf {LocalBack}}}_{\mathsf {c}}\): For every \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}} \uplus \sigma ^{2}_{\mathrm {B}}]\) there exists \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}} \uplus \sigma ^{1}_{\mathrm {B}}]\) such that \(u_1 {\mathcal {R}}u_2\).
-
-
-
\(\mathrm {A} \)-\({{\textbf {Back}}}_{\mathsf {c}}\): Like \(\mathrm {A} \)-\(\hbox {Forth}_c\), but with 1 and 2 swapped.
-
-
\({\mathsf {O}}_{\alpha } \)-bisimulation: (For illustration, see Fig. 2.)
-
\(\mathrm {B} \)-\({{\textbf {Forth}}}_{\alpha }\): For every joint action \(\sigma ^{1}_{\mathrm {B}}\) of \(\mathrm {B} \) at \(s_1\) there is a joint action \(\sigma ^{2}_{\mathrm {B}}\) of \(\mathrm {B} \) at \(s_2\), such that:
-
\(\mathrm {A} \)-\({{\textbf {Back}}}_{\alpha }\): For every joint action \(\sigma ^{2}_{\mathrm {A}}\) of \(\mathrm {A} \) at \(s_2\) there is a joint action \(\sigma ^{1}_{\mathrm {A}}\) of \(\mathrm {A} \) at \(s_1\), such that:
-
(\(\mathrm {A} \))-\({{\textbf {LocalForth}}}_{\alpha }\): For every \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}}]\) there exists \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}}]\) such that \(u_1 {\mathcal {R}}u_2\).
-
(\(\mathrm {A} \uplus \mathrm {B} \))-\({{\textbf {LocalBack}}}_{\alpha }\): For every \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}} \uplus \sigma ^{2}_{\mathrm {B}}]\) there exists \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}} \uplus \sigma ^{1}_{\mathrm {B}}]\) such that \(u_1 {\mathcal {R}}u_2\).
-
-
-
\(\mathrm {B} \)-\({{\textbf {Back}}}_{\alpha }\): Like \(\mathrm {B} \)-Forth, but with 1 and 2 swapped.
-
-
\({\mathsf {O}}_{\beta } \)-bisimulation: (For illustration, see Fig. 3.)
-
\(\mathrm {A} \)-\({{\textbf {Forth}}}_{\beta }\): For every joint action \(\sigma ^{1}_{\mathrm {A}}\) of \(\mathrm {A} \) at \(s_1\) there is a joint action \(\sigma ^{2}_{\mathrm {A}}\) of \(\mathrm {A} \) at \(s_2\), such that:
-
\(\mathrm {A} \)-\({{\textbf {LocalBack}}}_{\beta }\): For every \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}}]\) there exists \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}}]\) such that \(u_1 {\mathcal {R}}u_2\).
-
\(\mathrm {B} \)-\({{\textbf {Back}}}_{\beta }\): For every joint action \(\sigma ^{2}_{\mathrm {B}}\) of \(\mathrm {B} \) at \(s_2\) there is a joint action \(\sigma ^{1}_{\mathrm {B}}\) of \(\mathrm {B} \) at \(s_1\), such that:
-
(\(\mathrm {A} \uplus \mathrm {B} \))-\({{\textbf {LocalForth}}}_{\beta }\): For every \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}} \uplus \sigma ^{1}_{\mathrm {B}}]\) there exists \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}} \uplus \sigma ^{2}_{\mathrm {B}}]\) such that \(u_1 {\mathcal {R}}u_2\).
-
-
-
\(\mathrm {A} \)-\({{\textbf {Back}}}_{\beta }\): Like \(\mathrm {A} \)-Forth, but with 1 and 2 swapped.
-
States \(s_1, s_2 \in {\mathcal {M}} \) are \(\mathsf {ConStR}\)-bisimulation equivalent, or just \(\mathsf {ConStR}\)-bisimilar if there is a \(\mathsf {ConStR}\)-bisimulation \({\mathcal {R}}\) in \({\mathcal {M}} \) such that \(s_1 {\mathcal {R}}s_2\).

The \(\mathrm {A} \)-\(\hbox {Forth}_{\mathsf {c}}\) half of \({\mathsf {O}}_{c} \)-bisimulation

The \(\mathrm {B} \)-\(\hbox {Forth}_{\alpha }\) half of \({\mathsf {O}}_{\alpha } \)-bisimulation

The \(\mathrm {A} \)-\(\hbox {Forth}_{\beta }\) half of \({\mathsf {O}}_{\beta } \)-bisimulation
Proposition 1
(\(\mathsf {ConStR}\)-bisimulation invariance) Let \({\mathcal {R}}\) be a \(\mathsf {ConStR}\)-bisimulation in a game model \({\mathcal {M}} \). Then for every \(\mathsf {ConStR}\)-formula \(\theta \) and a pair \(s_1, s_2 \in {\mathcal {M}} \) such that \(s_1 {\mathcal {R}}s_2\): \({\mathcal {M}}, s_{1} \models \theta \ \text{ iff } \ {\mathcal {M}}, s_{2} \models \theta \).
Proof
Induction on \(\theta \). All boolean cases are straightforward. The cases for the 3 strategic operators are similar, but we will nevertheless check each of them, to ensure that the bisimulation conditions above are correctly defined.
(Case \({\mathsf {O}}_{c} \) ) Let \(\theta = \langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\), assuming that the claim holds for \(\phi \) and \(\psi \).
Suppose, \({\mathcal {M}}, s_{1} \models \theta \). Then \(\mathrm {A} \) has a joint action \(\sigma ^{1}_\mathrm {A} \) at \(s_1\) such that, when applied, it guarantees \(\phi \) and enables \(\mathrm {B} \) to adopt a joint action \(\sigma _\mathrm {B} \) that is consistent with \(\sigma _\mathrm {A} \) and guarantees \(\psi \) when additionally applied by \(\mathrm {B} \). By \(\mathrm {A} \)-Forth\(_{\mathsf {c}}\), there is a joint action \(\sigma ^{2}_{\mathrm {A}}\) of \(\mathrm {A} \) at \(s_2\), such that, by \(\mathrm {A} \)-LocalBack\(_{\mathsf {c}}\), for each \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}}]\) there exists \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}}]\) such that \(u_1 {\mathcal {R}}u_2\). By the choice of \(\sigma ^{1}_\mathrm {A} \), \({\mathcal {M}}, u_{1} \models \phi \) for each \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}}]\). It follows, by the inductive hypothesis applied to \(\phi \), that \({\mathcal {M}}, u_{2} \models \phi \) for each \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}}]\). Moreover, \(\mathrm {B} \) has a joint action \(\sigma ^{1}_\mathrm {B} \) at \(s_1\) such that, when applied by \(\mathrm {B} \), in addition to \(\mathrm {A} \) applying \(\sigma ^{1}_\mathrm {A} \), it guarantees \(\psi \), i.e. \({\mathcal {M}}, u_{1} \models \psi \) for each \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}} \uplus \sigma ^{1}_{\mathrm {B}}]\). By condition \(\mathrm {B} \)-Forth\(_{\mathsf {c}}\), there is a joint action \(\sigma ^{2}_{\mathrm {B}}\) of \(\mathrm {B} \) at \(s_2\), such that, by (\(\mathrm {A} \uplus \mathrm {B} \))-LocalBack\(_{\mathsf {c}}\), for every \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}} \uplus \sigma ^{2}_{\mathrm {B}}]\) there exists \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}} \uplus \sigma ^{1}_{\mathrm {B}}]\) such that \(u_1 {\mathcal {R}}u_2\). Therefore, by the inductive hypothesis applied to \(\psi \), \({\mathcal {M}}, u_{2} \models \psi \) for each \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}} \uplus \sigma ^{2}_{\mathrm {B}}]\). Thus, \({\mathcal {M}}, s_{2} \models \theta \).
The converse is similar, using \(\mathrm {A} \)-Back\(_{\mathsf {c}}\).
(Case \({\mathsf {O}}_{\alpha } \) ) Let \(\theta = [\mathrm {\mathrm {A}}]_\alpha (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\), assuming the claim holds for \(\phi \) and \(\psi \).
Suppose, \({\mathcal {M}}, s_{1} \models \theta \). Let \(\sigma ^{1}_{\mathrm {B}}\) be a joint action of \(\mathrm {B} \) at \(s_1\) satisfying the truth condition of \(\theta \). By \(\mathrm {B} \)-\({{\textbf {Forth}}}_{\alpha }\), there is a joint action \(\sigma ^{2}_{\mathrm {B}}\) of \(\mathrm {B} \) at \(s_2\), such that \(\mathrm {A} \)-\({{\textbf {Back}}}_{\alpha }\) holds. Now, take any joint action \(\sigma ^{2}_{\mathrm {A}}\) of \(\mathrm {A} \) at \(s_2\) such that \({\mathcal {M}}, u_{2} \models \phi \) for each \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}}]\). Then, by \(\mathrm {A} \)-\({{\textbf {Back}}}_{\alpha }\), there is a joint action \(\sigma ^{1}_{\mathrm {A}}\) of \(\mathrm {A} \) at \(s_1\) such that, by (\(\mathrm {A} \))-\({{\textbf {LocalForth}}}_{\alpha }\), for every \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}}]\) there exists \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}}]\) such that \(u_1 {\mathcal {R}}u_2\). Then, by the inductive hypothesis applied to \(\phi \), it follows that \({\mathcal {M}}, u_{1} \models \phi \) for each \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}}]\). By the choice of \(\sigma ^{1}_{\mathrm {B}}\), this implies \({\mathcal {M}}, u_{1} \models \psi \) for each \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}} \uplus \sigma ^{1}_{\mathrm {B}}]\). By (\(\mathrm {A} \uplus \mathrm {B} \))-\({{\textbf {LocalBack}}}_{\alpha }\), for every \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}} \uplus \sigma ^{2}_{\mathrm {B}}]\) there exists \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}} \uplus \sigma ^{1}_{\mathrm {B}}]\) such that \(u_1 {\mathcal {R}}u_2\). Therefore, by the inductive hypothesis applied to \(\psi \), we have \({\mathcal {M}}, u_{2} \models \psi \) for each \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}} \uplus \sigma ^{2}_{\mathrm {B}}]\). Thus, \(\sigma ^{2}_{\mathrm {B}}\) satisfies the truth condition of \(\theta \) at \(s_{2}\). Hence, \({\mathcal {M}}, s_{2} \models \theta \).
The converse direction is analogous, using \(\mathrm {B} \)-Back\(_{\alpha }\).
(Case \({\mathsf {O}}_{\beta } \) ) Let \(\theta = [\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\), assuming the claim holds for \(\phi \) and \(\psi \).
Suppose, \({\mathcal {M}}, s_{2} \models \theta \). Then, consider any joint action \(\sigma ^{1}_\mathrm {A} \) of \(\mathrm {A} \) at \(s_1\) such that, when applied by \(\mathrm {A} \), it guarantees \(\phi \). (If no such joint action exist at \(s_1\), then \({\mathcal {M}}, s_{1} \models \theta \) is vacuously true.) Then, by \(\mathrm {A} \)-\({{\textbf {Forth}}}_{\beta }\), there is a joint action \(\sigma ^{2}_{\mathrm {A}}\) of \(\mathrm {A} \) at \(s_2\), such that, by \(\mathrm {A} \)-\({{\textbf {LocalBack}}}_{\beta }\), for every \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}}]\) there exists \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}}]\) such that \(u_1 {\mathcal {R}}u_2\). Then, by the inductive hypothesis applied to \(\phi \), it follows that \({\mathcal {M}}, u_{2} \models \phi \) for each \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}}]\). Therefore, by the assumption for the truth of \(\theta \) at \(s_{2}\), \(\mathrm {B} \) has a joint action \(\sigma ^{2}_\mathrm {B} \) at \(s_2\) such that, when applied by \(\mathrm {B} \), in addition to \(\mathrm {A} \) applying \(\sigma ^{2}_\mathrm {A} \), it guarantees the truth of \(\psi \), i.e. \({\mathcal {M}}, u_{2} \models \psi \) for each \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}} \uplus \sigma ^{2}_{\mathrm {B}}]\). Then, by \(\mathrm {B} \)-\({{\textbf {Back}}}_{\beta }\), there is a joint action \(\sigma ^{1}_{\mathrm {B}}\) of \(\mathrm {B} \) at \(s_1\), such that, by (\(\mathrm {A} \uplus \mathrm {B} \))-\({{\textbf {LocalForth}}}_{\beta }\), for every \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}} \uplus \sigma ^{1}_{\mathrm {B}}]\) there exists \(u_{2} \in \mathsf {Out} [s_{2},\sigma ^{2}_{\mathrm {A}} \uplus \sigma ^{2}_{\mathrm {B}}]\) such that \(u_1 {\mathcal {R}}u_2\). Therefore, \({\mathcal {M}}, u_{1} \models \psi \) for each \(u_{1} \in \mathsf {Out} [s_{1},\sigma ^{1}_{\mathrm {A}} \uplus \sigma ^{1}_{\mathrm {B}}]\). Thus, \({\mathcal {M}}, s_{1} \models \theta \).
The converse is analogous, using \(\mathrm {A} \)-Back\(_{\beta }\). \(\square \)
We also obtain the Hennessy–Milner property for \(\mathsf {ConStR}\)-bisimulations:
Proposition 2
(Hennessy–Milner property) For any finite game model \({\mathcal {M}} \) the relation of \(\mathsf {ConStR} \)-equivalence (satisfaction of the same \(\mathsf {ConStR} \)-formulae) between states in \({\mathcal {M}} \) is a \(\mathsf {ConStR}\)-bisimulation in \({\mathcal {M}} \).
Proof
(Sketch) One direction follows from Proposition 1. We now prove the converse. Since \({\mathcal {M}} \) is finite, there is a mapping \(\chi \) from \({\mathcal {M}} \) to the formulae of \(\mathsf {ConStR} \) that assigns to each state s in \({\mathcal {M}} \) its characteristic formula \(\chi (s)\), such that \(s_1,s_2\) are \(\mathsf {ConStR} \)-equivalent if and only if \(s_1\) satisfies \(\chi (s_2)\) (and vice versa), iff \(\chi (s_1) \equiv \chi (s_2)\). Furthermore, \(\chi (s_1) \wedge \chi (s_2) \equiv \bot \) whenever \(s_1\) and \(s_2\) are not \(\mathsf {ConStR} \)-equivalent. Now, for any set of states Z in \({\mathcal {M}} \) we define \(\chi (Z) := \bigvee _{z\in Z} \chi (z)\). The crucial observation for proving the claim is that every state \(s\in {\mathcal {M}} \) satisfies each of the following formulae, enabling the verification of the respective \(\mathsf {ConStR} \)-bisimulation conditions:

\(\square \)
5.2 Some Remarks on Expressiveness and Definability
Proposition 3
Let \({\mathsf {a}}, {\mathsf {b}} \) be different agents and p, q be different atomic propositions. Then the following hold.Footnote 9
-
1.
\([\mathrm {{\mathsf {a}}}]_\beta (p; \langle \mathrm {{\mathsf {b}}} \rangle q) \not \equiv [\mathrm {{\mathsf {a}}}]_\alpha (p; \langle \mathrm {{\mathsf {b}}} \rangle q)\).
-
2.
\(\langle \mathrm {{\mathsf {a}}}\rangle _{\mathsf {c}}(p; \langle \mathrm {{\mathsf {b}}} \rangle q)\) is not definable in \(\mathsf {CL} \).
-
3.
\([\mathrm {{\mathsf {a}}}]_{\mathsf {c}}(p | q)\) (and, consequently, \([\mathrm {{\mathsf {a}}}]_\beta (p; \langle \mathrm {\emptyset } \rangle q)\)) is not definable in \(\mathsf {CL} \).
-
4.
\([\mathrm {{\mathsf {b}}}]_\alpha (q; \langle \mathrm {{\mathsf {a}}} \rangle p)\) is not definable in \(\mathsf {CL} \).
Proof
The claims follow respectively from Examples 2, 3, 4 and 5. \(\square \)
The results above generalise to pairwise coalitions in a straightforward way.
Example 3
The game models \({\mathcal {M}}_1\), \({\mathcal {M}}_2\) below involve three players: \({\mathsf {a}} \), \({\mathsf {b}} \), \({\mathsf {c}} \).

Note that (1) The relation \({\mathcal {R}}= \{(s_i,t_i) \mid i = 0,1,2,3\}\) is an \(\mathsf {CL}\)-bisimulation between \({\mathcal {M}}_1\) and \({\mathcal {M}}_2\); (2) \({\mathcal {M}}_1, s_0 \Vdash \langle \mathrm {{\mathsf {a}}}\rangle _{\mathsf {c}}(p; \langle \mathrm {{\mathsf {b}}} \rangle q)\) but \({\mathcal {M}}_2, t_0 \not \Vdash \langle \mathrm {{\mathsf {a}}}\rangle _{\mathsf {c}}(p; \langle \mathrm {{\mathsf {b}}} \rangle q)\).
Example 4
The game models \({\mathcal {M}}_1\) and \({\mathcal {M}}_2\) below involve two players: \({\mathsf {a}} \) and \({\mathsf {b}} \).

Note that (1) The relation \({\mathcal {R}}= \{(s_i,t_i) \mid i = 0,1,2,3\}\) is an \(\mathsf {CL}\)-bisimulation between \({\mathcal {M}}_1\) and \({\mathcal {M}}_2\); (2) \({\mathcal {M}}_1, s_0 \Vdash [\mathrm {{\mathsf {a}}}]_{\mathsf {c}}(p | q)\) but \({\mathcal {M}}_2, t_0 \not \Vdash [\mathrm {{\mathsf {a}}}]_{\mathsf {c}}(p | q)\).
Example 5
The game models \({\mathcal {M}}_1\), \({\mathcal {M}}_2\) below involve three players: \({\mathsf {a}} \), \({\mathsf {b}} \), \({\mathsf {c}} \).

Note that (1) The relation \({\mathcal {R}}= \{(s_i,t_i) \mid i = 0,1,2,3\}\) is an \(\mathsf {CL}\)-bisimulation between \({\mathcal {M}}_1\) and \({\mathcal {M}}_2\); (2) \({\mathcal {M}}_1, s_0 \Vdash [\mathrm {{\mathsf {b}}}]_\alpha (q; \langle \mathrm {{\mathsf {a}}} \rangle p)\) but \({\mathcal {M}}_2, t_0 \not \Vdash [\mathrm {{\mathsf {b}}}]_\alpha (q; \langle \mathrm {{\mathsf {a}}} \rangle p)\).
6 Axiomatic System for \(\mathsf {ConStR}\)
Here we propose systems of axiom schemes for each of the basic operators of \(\mathsf {ConStR}\) and for the whole logic, without stating completeness claims; these are left for a follow-up work. Some of these axiom schemes are adapted from the axiomatic systems for SFCL and GPCL presented in Goranko and Enqvist (2018).
6.1 Common Axiom Schemes and Rules for \(\mathsf {ConStR}\)
The axiomatic system \(\mathsf {Ax} _{\mathsf {ConStR}}\) builds on the axiom schemes and rules of the complete axiomatic system for Coalition Logic \(\mathsf {Ax} _{\mathsf {CL}}\), given in Pauly (2001, 2002). Analogues of these axiom schemes and rules are added for each of the conditional strategic operators occurring in the fragment of \(\mathsf {ConStR}\) that is to be axiomatized. (Recall that the coalitional operator of \(\mathsf {CL}\) is a special case of each of \({\mathsf {O}}_{c} \), \({\mathsf {O}}_{\alpha } \), \({\mathsf {O}}_{\beta } \).) Some of these common axiom schemes and rules will turn out derivable from the special ones added below, but we are not concerned now with minimality of our system.
6.2 Additional Axiom Schemes and Rules for \({\mathsf {O}}_{c} \)
Axiom schemes:
- (\({\mathsf {O}}_{c} \)1):
-
Monotonicity w.r.t. \(\mathrm {A} \):
\(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \rightarrow \langle \mathrm {\mathrm {A} \cup \mathrm {C}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\) for any \(\mathrm {C} \subseteq {{\,\mathrm{{\mathbb {A}}gt}\,}}\)
- (\({\mathsf {O}}_{c} \)2):
-
Monotonicity w.r.t. \(\mathrm {B} \):
\(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \rightarrow \langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B} \cup \mathrm {C}} \rangle \psi )\) for any \(\mathrm {C} \subseteq {{\,\mathrm{{\mathbb {A}}gt}\,}}\)
- (\({\mathsf {O}}_{c} \)3):
-
\(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \rightarrow \langle \mathrm {\mathrm {A} \cup \mathrm {B}}\rangle _{\mathsf {c}}((\phi \wedge \psi ); \langle \mathrm {\emptyset } \rangle \top )\)
- (\({\mathsf {O}}_{c} \)4):
-
\(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\emptyset } \rangle \psi ) \leftrightarrow \langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}((\phi \wedge \psi ); \langle \mathrm {\emptyset } \rangle \top )\)
(NB: the direction \(\rightarrow \) follows from (\({\mathsf {O}}_{c} \)3).)
- (\({\mathsf {O}}_{c} \)5):
-
\(\lnot \langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\bot ; \langle \mathrm {\mathrm {B}} \rangle \psi )\)
- (\({\mathsf {O}}_{c} \)6):
-
\(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \leftrightarrow \langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B} \!{\setminus }\!\mathrm {A}} \rangle \,\psi )\)
- (\({\mathsf {O}}_{c} \)7):
-
\(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \leftrightarrow \langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle (\phi \wedge \psi ))\)
Rule of inference: \({\mathsf {O}}_{c} \)-Monotonicity ( \({\mathsf {O}}_{c} \)-Mon):
6.3 Additional Axiom Schemes and Rules for \({\mathsf {O}}_{\beta } \)
Axiom schemes:
- (\({\mathsf {O}}_{\beta } \)1):
-
Monotonicity w.r.t. \(\mathrm {B} \):
\([\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \rightarrow [\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B} \cup \mathrm {C}} \rangle \psi )\) for any \(\mathrm {C} \subseteq {{\,\mathrm{{\mathbb {A}}gt}\,}}\).
- (\({\mathsf {O}}_{\beta } \)2):
-
\([\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\emptyset } \rangle \phi )\)
- (\({\mathsf {O}}_{\beta } \)3):
-
\([\mathrm {\mathrm {A}}]_\beta (\bot ; \langle \mathrm {\emptyset } \rangle \psi )\)
- (\({\mathsf {O}}_{\beta } \)4):
-
\([\mathrm {\emptyset }]_\beta (\top ; \langle \mathrm {\mathrm {A}} \rangle \phi ) \rightarrow \lnot [\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B}} \rangle \bot )\)
- (\({\mathsf {O}}_{\beta } \)5):
-
\([\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \leftrightarrow [\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B} \!{\setminus }\!\mathrm {A}} \rangle \,\psi )\)
- (\({\mathsf {O}}_{\beta } \)6):
-
\([\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \leftrightarrow [\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B}} \rangle (\phi \wedge \psi ))\)
Rule of inference: \({\mathsf {O}}_{\beta } \)-Monotonicity ( \({\mathsf {O}}_{\beta } \)-Mon):
6.4 Additional Axiom Schemes and Rules for \({\mathsf {O}}_{\alpha } \)
Axiom schemes: All axioms (\({\mathsf {O}}_{\beta } \)1) - (\({\mathsf {O}}_{\beta } \)6), rewritten for \({\mathsf {O}}_{\alpha } \). In addition:
- (\({\mathsf {O}}_{\alpha } \)*):
-
Anti-monotonicity w.r.t. \(\mathrm {A} \):
\([\mathrm {\mathrm {A} \cup \mathrm {C}}]_\alpha (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \rightarrow [\mathrm {\mathrm {A}}]_\alpha (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\) for any \(\mathrm {C} \subseteq {{\,\mathrm{{\mathbb {A}}gt}\,}}\).
Rule of inference: \({\mathsf {O}}_{\alpha } \)-Monotonicity ( \({\mathsf {O}}_{\alpha } \)-Mon):
6.5 Interacting Axioms for \(\mathsf {ConStR}\)
- (\(\mathsf {ConStR}\) 1):
-
\([\mathrm {\mathrm {A}}]_\alpha (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \rightarrow [\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\)
- (\(\mathsf {ConStR}\) 2):
-
\([\mathrm {\emptyset }]_\beta (\top ; \langle \mathrm {\mathrm {A}} \rangle \phi ) \wedge [\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \rightarrow \langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\) Footnote 10
Proposition 4
(Soundness) The following hold for the system \(\mathsf {Ax} _{\mathsf {ConStR}}\).
-
1.
All axiom schemes are valid in the formal semantics of \(\mathsf {ConStR}\).
-
2.
The analogue of the anti-monotonicity axiom with respect to \(\mathrm {A} \) for \({\mathsf {O}}_{\beta } \):
\([\mathrm {\mathrm {A} \cup \mathrm {C}}]_\beta (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi ) \rightarrow [\mathrm {\mathrm {A}}]_\beta (\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\), for any \(\mathrm {A},\mathrm {B},\mathrm {C} \subseteq {{\,\mathrm{{\mathbb {A}}gt}\,}}\), is not valid.
Proof
Checking the soundness of most of the axioms is routine application of the formal semantics and we leave the details to the reader. We will only verify here the anti-monotonicity axiom scheme (\({\mathsf {O}}_{\alpha } \)*), which is less straightforward and plays a special role of distinguishing \({\mathsf {O}}_{\beta } \) and \({\mathsf {O}}_{\alpha } \).
It suffices to prove the validity of the following instance:
\([\mathrm {\mathrm {A} \cup \mathrm {C}}]_\alpha (p; \langle \mathrm {\mathrm {B}} \rangle q) \rightarrow [\mathrm {\mathrm {A}}]_\alpha (p; \langle \mathrm {\mathrm {B}} \rangle q)\), for any \(\mathrm {A},\mathrm {B},\mathrm {C} \subseteq {{\,\mathrm{{\mathbb {A}}gt}\,}}\).
Consider any CGM \({\mathcal {M}} \) and a state s in it.
For any formula \(\phi \) we denote \(\Vert \phi \Vert _{\mathcal {M}}:= \{ w \in {\mathcal {M}} \mid {\mathcal {M}}, w \Vdash \phi \}\).
Suppose \({\mathcal {M}}, s \Vdash [\mathrm {\mathrm {A} \cup \mathrm {C}}]_\alpha (p; \langle \mathrm {\mathrm {B}} \rangle q)\). Fix a joint action \(\sigma _\mathrm {B} \) witnessing the truth of that antecedent. Thus, for every joint action \(\sigma _{\mathrm {A} \cup \mathrm {C}}\) such that \(\mathsf {Out} [s,\sigma _{\mathrm {A} \cup \mathrm {C}}] \subseteq \Vert p\Vert _{\mathcal {M}} \) we have that \(\mathsf {Out} [s,\sigma _{(\mathrm {A} \cup \mathrm {C})} \uplus \sigma _{\mathrm {B}}] \subseteq \Vert q\Vert _{\mathcal {M}} \).
To show that \({\mathcal {M}}, s \Vdash [\mathrm {\mathrm {A}}]_\alpha (p; \langle \mathrm {\mathrm {B}} \rangle q)\), we use the same joint action \(\sigma _\mathrm {B} \).
Consider any joint action \(\sigma _\mathrm {A} \) such that \(\mathsf {Out} [s,\sigma _{\mathrm {A}}] \subseteq \Vert p\Vert _{\mathcal {M}} \).
That implies that for any additional joint action \(\sigma _{\mathrm {C} {\setminus } \mathrm {A}}\), we have for the resulting joint action \(\sigma _{\mathrm {A} \cup \mathrm {C}} := \sigma _{\mathrm {A}} \uplus \sigma _{\mathrm {C} {\setminus } \mathrm {A}}\) that \(\mathsf {Out} [s,\sigma _{\mathrm {A} \cup \mathrm {C}}] \subseteq \Vert p\Vert _{\mathcal {M}} \).
Then, by the assumption above, we have that \(\mathsf {Out} [s,\sigma _{(\mathrm {A} \cup \mathrm {C})} \uplus \sigma _{\mathrm {B}}] \subseteq \Vert q\Vert _{\mathcal {M}} \).
Now, note that every extension of \(\sigma _{\mathrm {A}} \uplus \sigma _{\mathrm {B}}\) to a full strategy profile \(\sigma '\) can be obtained by first selecting a joint action \(\sigma '_{\mathrm {C}}\) which coincides with \(\sigma _{\mathrm {A}} \uplus \sigma _{\mathrm {B}}\) on \(\mathrm {A} \cup \mathrm {B} \) and is defined according to \(\sigma '\) for the agents in \(\mathrm {C} {\setminus } (\mathrm {A} \cup \mathrm {B})\). Equivalently, every such strategy profile \(\sigma '\) can be generated by first selecting a joint action \(\sigma _{\mathrm {A} \cup \mathrm {C}}\) which extends \(\sigma _{\mathrm {A}}\) with the joint action \(\sigma _{\mathrm {C} {\setminus } \mathrm {A}}\) obtained by restricting \(\sigma '_{\mathrm {C}}\) to \(\mathrm {C} {\setminus } \mathrm {A} \), then adding the actions of the agents from \(\mathrm {B} {\setminus } (\mathrm {A} \cup \mathrm {C})\) according to \(\sigma _{\mathrm {A}} \uplus \sigma _{\mathrm {B}}\), and then adding the remaining actions according to \(\sigma '\). Thus, \(\sigma '\) can be constructed as an extension of \(\sigma _{(\mathrm {A} \cup \mathrm {C})} \uplus \sigma _{\mathrm {B}}\), where \(\sigma _{(\mathrm {A} \cup \mathrm {C})}\) extends \(\sigma _\mathrm {A} \). Hence, the outcome from s of every such \(\sigma '\) is in \( \Vert q\Vert _{\mathcal {M}} \).
Therefore \(\mathsf {Out} [s,\sigma _{\mathrm {A}} \uplus \sigma _{\mathrm {B}}] \subseteq \Vert q\Vert _{\mathcal {M}} \). Hence, \({\mathcal {M}}, s \Vdash [\mathrm {\mathrm {A}}]_\alpha (p; \langle \mathrm {\mathrm {B}} \rangle q)\). Thus, we have shown that \({\mathcal {M}}, s \Vdash [\mathrm {\mathrm {A} \cup \mathrm {C}}]_\alpha (p; \langle \mathrm {\mathrm {B}} \rangle q) \rightarrow [\mathrm {\mathrm {A}}]_\alpha (p; \langle \mathrm {\mathrm {B}} \rangle q)\), whence the validity of that formula.
2. The instance \([\mathrm {\{{\mathsf {a}}, {\mathsf {c}} \}}]_\beta (p; \langle \mathrm {{\mathsf {b}}} \rangle q) \rightarrow [\mathrm {{\mathsf {a}}}]_\beta (p; \langle \mathrm {{\mathsf {b}}} \rangle q)\) of the anti-monotonicity principle w.r.t. \(\mathrm {A} \) for \({\mathsf {O}}_{\beta } \) is falsified in the example below of a game model \({\mathcal {M}}\) with three players, \({\mathsf {a}} \), \({\mathsf {b}} \) and \({\mathsf {c}} \).

It is easy to verify that \({\mathcal {M}}, s_0 \Vdash [\mathrm {\{{\mathsf {a}}, {\mathsf {c}} \}}]_\beta (p; \langle \mathrm {{\mathsf {b}}} \rangle q)\) but \({\mathcal {M}}, s_0 \not \Vdash [\mathrm {{\mathsf {a}}}]_\beta (p; \langle \mathrm {{\mathsf {b}}} \rangle q)\). Hence, \({\mathcal {M}}, s_0 \not \Vdash [\mathrm {\{{\mathsf {a}}, {\mathsf {c}} \}}]_\beta (p; \langle \mathrm {{\mathsf {b}}} \rangle q) \rightarrow [\mathrm {{\mathsf {a}}}]_\beta (p; \langle \mathrm {{\mathsf {b}}} \rangle q)\). \(\square \)
Thus, the anti-monotonicity principle with respect to \(\mathrm {A} \) is (at least so far) the only axiom scheme in our system, that distinguishes \({\mathsf {O}}_{\alpha } \) from \({\mathsf {O}}_{\beta } \).
7 Concluding Remarks: The Road Ahead
First, we note that, while the new strategic operators introduced here can be expressed in a suitable version of Strategy Logic (cf. Mogavero et al. 2017), we choose—for both conceptual and computational reasons—to stay within a purely modal framework where actions and strategies are not explicitly referred and quantified over in the language, but are only present in the semantics.
We regard this work as a step towards developing a rich technical framework for logic-based conditional strategic reasoning of rational agents. The major further steps and directions include:
-
1.
Completeness proofs of the proposed axiomatizations of the 3 main fragments and the entire logic \(\mathsf {ConStR}\) are currently under construction.
-
2.
We also claim that, for general reasons, \(\mathsf {ConStR}\) has the finite tree-model property, and is therefore decidable (to be proved in a follow-up paper). We further conjecture that its satisfiability problem is PSPACE-complete—a major argument in favour of the modal approach to formalising conditional strategic reasoning advocated here, as opposed to one based on a version of Strategy Logic. We also leave the question of the precise complexity of model checking subject to further investigation, but conjecture that it will still be tractable in the size of the model, as in \(\mathsf {CL}\) and \(\mathsf {ATL}\).
-
3.
Extension of the framework to a full-fledged, long term conditional strategic reasoning, by extending the language with standard temporal operators, to produce an \(\mathsf {ATL}\)-like extension of \(\mathsf {ConStR}\).
-
4.
Long term conditional strategic reasoning naturally requires considerations about strategic commitments and model updates (cf. Ågotnes et al., 2007, 2008) and, more generally, requires involving strategy contexts in the semantics (Brihaye et al., 2009).
-
5.
Adding knowledge in the semantics, and explicitly in the language, by assuming that the agents reason and act under imperfect information.
-
6.
Last, but most important long-term objective of this project is to model and capture by semantically richer logic-based formalism the mutually conditional strategic reasoning, where all agents reason about their strategic choices, conditional on the others’ strategic choices, conditional on the reasoners’ choices, etc., recursively.
Change history
03 August 2022
Missing Open Access funding information has been added in the Funding Note.
Notes
These game models are essentially equivalent to concurrent game models used in Alur et al. (2002).
The reader who is only interested in the technical part of the paper can skip this section without essential loss.
In this paper we focus on local reasoning, about once-off actions, but in this section the word ‘action’ can be conceived in a wider sense, and may mean either a once-off action, or a global strategy guiding the long term behaviour of the agent.
In Goranko and Ju (2019) these were called respectively ‘ability de re’ and ‘ability de dicto’.
We note that \(\langle \mathrm {\mathrm {A}}\rangle _{\mathsf {c}}(\phi ; \langle \mathrm {\mathrm {B}} \rangle \psi )\) is equivalent to \(\langle \!\langle {\mathrm {\mathrm {A}}}\rangle \!\rangle (\phi \wedge \langle \!\langle {\mathrm {B} {\setminus } \mathrm {A}}\rangle \!\rangle \psi )\) in \(\mathsf {ATL}^* \).
Note that \([\mathrm {\mathrm {A}}]_\beta (\bot ; \langle \mathrm {\mathrm {B}} \rangle \psi )\) is vacuously true for any \(\mathrm {A} \), \(\mathrm {B} \), and \(\psi \), as then there cannot be such joint actions \(\sigma _\mathrm {A} \) that enable satisfying \(\bot \). This may sounds odd, but it is no special phenomenon in \(\mathsf {ConStR}\), as the same effect occurs in FOL with universal quantification over an empty set of objects.
NB: We have preserved the box-like notation for \([\mathrm {A} ]\) from \(\mathsf {CL}\), even though it is not consistent with ours.
Each of these conditions is a respective variation of the bisimulation conditions for the basic strategic operators in the logics \(\mathsf {SFCL}\) and \(\mathsf {GPCL}\) defined in Goranko and Enqvist (2018).
Even though we state the non-definability claims for \(\mathsf {CL}\), they apply likewise even to \(\mathsf {ATL}^* \) with its standard, memory-based semantics, because all formulae of \(\mathsf {ATL}^* \) are invariant under \(\mathsf {CL}\)-bisimulations with respect to that semantics.
An analogue of (\(\mathsf {ConStR}\) 2) for \({\mathsf {O}}_{\alpha } \) is easily derivable from (\(\mathsf {ConStR}\) 1) and (\(\mathsf {ConStR}\) 2).
References
Abdou, J., & Keiding, H. (1991). Effectivity functions in social choice. Springer.
Ågotnes, T., Goranko, V., & Jamroga, W. (2007). Alternating-time temporal logics with irrevocable strategies. In D. Samet (Ed.) Proceedings of TARK XI (pp. 15–24).
Ågotnes, T., Goranko, V., & Jamroga, W. (2008). Strategic commitment and release in logics for multi-agent systems (Extended abstract). Technical Report IfI-08-01, Clausthal University of Technology.
Ågotnes, T., Goranko, V., Jamroga, W., & Wooldridge, M. (2015). Knowledge and ability. In H. van Ditmarsch, J. Halpern, W. van der Hoek, & B. Kooi (Eds.), Handbook of epistemic logic (pp. 543–589). College Publications.
Alur, R., Henzinger, T.A., Kupferman, O., & Vardi, M. (1998). Alternating refinement relations. In D. Sangiorgi, & R. de Simone (Eds.), Proceedings of CONCUR’98. LNCS 1466. Springer.
Alur, R., Henzinger, T. A., & Kupferman, O. (2002). Alternating-time temporal logic. Journal of the ACM, 49(5), 672–713.
Brihaye, T., Lopes, A. D. C., Laroussinie, F., & Markey, N. (2009). ATL with strategy contexts and bounded memory. In S. Artëmov & A. Nerode (Eds.), Proceedings of LFCS’2009, LNCS (Vol. 5407, pp. 92–106). Springer.
Fisman, D., Kupferman, O., & Lustig, Y. (2010). Rational synthesis. In Proceedings of TACAS (Vol. 2010, pp. 190–204).
Goranko, V. (2001). Coalition games and alternating temporal logics. In J. van Benthem (Ed.), Proceedings of TARK VIII (pp. 259–272). Morgan Kaufmann.
Goranko, V., & Enqvist, S. (2018). Socially friendly and group protecting coalition logics. In Proceedings of AAMAS 2018 (pp. 372–380).
Goranko, V., & Ju, F. (2019). Towards a logic for conditional local strategic reasoning. In P. Blackburn, E. Lorini, & M. Guo (Eds.), Logic, rationality, and interaction—7th international workshop, LORI 2019, Chongqing, China, October 18–21, 2019, Proceedings, Lecture Notes in Computer Science (Vol. 11813, pp. 112–125). Springer.
Gutierrez, J., Harrenstein, P., & Wooldridge, M. J. (2017). From model checking to equilibrium checking: Reactive modules for rational verification. Artificial Intelligence, 248, 123–157.
Kupferman, O., Perelli, G., & Vardi, M. Y. (2016). Synthesis with rational environments. Annals of Mathematics and Artificial Intelligence, 78(1), 3–20.
Mogavero, F., Murano, A., Perelli, G., & Vardi, M. Y. (2014). Reasoning about strategies: On the model-checking problem. ACM Transactions on Computational Logic, 15(4), 34:1-34:47.
Mogavero, F., Murano, A., Perelli, G., & Vardi, M. Y. (2017). Reasoning about strategies: On the satisfiability problem. Logical Methods in Computer Science, 13(1), 1–37.
Naumov, P., & Yuan, Y. (2019). Intelligence in strategic games. CoRR arXiv:1910.07298
Pauly, M. (2001). Logic for social software. Ph.D. thesis, University of Amsterdam
Pauly, M. (2002). A modal logic for coalitional power in games. Journal of Logic and Computation, 12(1), 149–166.
van Benthem, J., Ghosh, S., & Verbrugge, R. (Eds.). (2015). Models of strategic reasoning—Logics, games, and communities, LNCS (Vol. 8972). Springer.
van der Hoek, W., & Wooldridge, M. (2004). Cooperation, knowledge, and time: Alternating-time temporal epistemic logic and its applications. Studia Logica, 75(1), 125–157.
Wooldridge, M., Gutierrez, J., Harrenstein, P., Marchioni, E., Perelli, G., & Toumi, A. (2016). Rational verification: From model checking to equilibrium checking. In Proceedings of AAAI 2016 (pp. 4184–4191).
Acknowledgements
We thank the reviewers for some helpful remarks. The first author’s work was partly supported by a research Grant 2015-04388 of the Swedish Research Council. The second author’s work was funded by the Minister of Science and Higher Education within the program under the name ‘Regional Initiative of Excellence’ in 2019-2022, Project No. 028/RID/2018/19; the amount of funding: 11 742 500 PLN.
Funding
Open access funding provided by Stockholm University.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This paper is a revised and extended version of Goranko and Ju (2019).
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Goranko, V., Ju, F. A Logic for Conditional Local Strategic Reasoning. J of Log Lang and Inf 31, 167–188 (2022). https://doi.org/10.1007/s10849-022-09357-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10849-022-09357-y