
Abstract
This study developed a framework incorporating economies of scale into the multimodal minimum cost flow problem. To properly account for the economies of scale observed in practice, we explicitly modelled economies of scale on quantity, distance and vehicle size in a given multimodal freight network. The proposed multimodal minimum cost flow problem formulation has concave equations due to economies of scale for quantity, non-linear equations due to economies of scale for both quantity and distance, and non-continuous equations due to the economies of scale for vehicle size. A genetic algorithm was applied to find acceptable route, mode, and vehicle size choices for the multimodal minimum cost flow problem. We demonstrated how the economies of scale influenced system (mode), route choices, and total cost under various demand/service capacity scenarios. Our results will lead into more realistic assessments of intermodal system by explicitly considering the three types of economies of scale.




Similar content being viewed by others


Notes
The sequence of freight transport modes (i.e., multimodal system).
The batch strategy is, when several sized vehicles of a transport mode are available, a decision on the sequence of them. (e.g. For shipping 200 TEU, if there are 60, 75, 140 TEU trains are available, a feasible batch strategy is that 140 TEU train is used first and then 60 TEU train is used).
It is obvious ESVS influences the batch strategy, which is a main issue of this paper.
TEU is Twenty-foot Equivalent Unit; containers or swap bodies are used as common loading unit in multimodal/multimodal freight operations due to the simplicity of transhipment.
The cost function of truck-only system looks a wave. However, the actually shape is also broken like others when truck-batch is changed.
Actually, the minimum cost of truck-only system is also non-continuous breaking at 1TEU, 2TEU, and 2.5 TEU. However, it was not expressed well in the graph.
References
Bärthel F, Woxenius J (2004) Developing intermodal transport for small flows over short distances. Transp Plan Technol 27:403–424
Bontekoning YM, Priemus H (2004) Breakthrough innovations in intermodal freight transport. Transp Plan Technol 27:335–345
Chang T-S (2008) Best routes selection in international intermodal networks. Comput Oper Res 35:2877–2891
Cullinance K, Khanna M (1999) Economies of scale in large container ships. J Transp Econ Policy 33:185–208
Cullinane K, Khanna M (1999) Economies of scale in large container ships. J Transp Econ Policy 33:185–208
Deb K (2000) An efficient constraint handling method for genetic algorithms. Comput Methods Appl Mech Eng 186:311–338
EC (2001) White Paper—European Transport Policy for 2010: time to decide. EC
ECMT (1998) Terminology on combined transport. ECMT(European Conference of Ministers of Transport), Paris
Holland JH (1975) Adaptation in natural and artificial systems. University of Michigan Press, Ann Arbor
Horner MW, O’Kelly ME (2001) Embedding economies of scale concepts for hub network design. J Transp Geogr 9:255–265
Janic M (2007) Modelling the full costs of an intermodal and road freight transport network. Transp Res Part D 12:33–44
Janic M (2008) An assessment of the performance of the European long intermodal freight trains (LIFTS). Transp Res Part A Policy Pract 42:1326–1339
Jara-Díaz SR, Donoso PP, Araneda JA (1992) Estimation of marginal transport costs: the flow aggregation function approach. J Transp Econ Policy 26:35–48
Kim NS, Van Wee B (2009) Assessment of CO2 emissions for truck-only and rail-based intermodal freight systems in Europe. Transp Plan Technol 32:313–330
Kreutzberger ED (2008) Distance and time in intermodal goods transport networks in Europe: a generic approach. Transp Res Part A Policy Pract 42:973–993
McCann P (2001) A proof of the relationship between optimal vehicle size, haulage and the structure of distance-transport cost. Transp Res Part A 35:671–693
Michalewicz Z (1995) Genetic algorithms, numerical optimization, and constraints. In: Sixth international conference on genetic algorithms, Morgan Kauffman, San Mateo
Michalewicz Z, Fogel DB (2000) How to solve it: modern heuristics. Springer, Berlin
Michalewicz Z, Schoenauer M (1996) Evolutionary algorithms for constrained parameter optimization problems. Evol Comput 4:1–32
O’Kelly ME, Bryan DL (1998) Hub location with flow economies of scale. Transp Res Part B 32:605–616
Piramuthu S, Shaw MJ (2009) Learning-enhanced adaptive DSS: a Design Science perspective. Inf Technol Manag 10:41–54
Racunica I, Wynter L (2005) Optimal location of intermodal freight hubs. Transp Res Part B 39:453–477
Rees J, Koehler G (2001) Evolution in groups: a genetic algorithm approach to group decision support systems. Inf Technol Manag 3:213–227
Skorin-Kapov D, Skorin-Kapov J, O’Kelly ME (1996) Tight linear programming relaxations of uncapacitated p-hub median problems. Eur J Oper Res 94:582–593
Sikora R, Piramuthu S (2005) Efficient genetic algorithm based data mining using feature selection with Hausdorff distance. Inf Technol Manag 6:315–331
USDOT (1991) The intermodal surface transportation efficiency act of 1991. U.S. Department of Transportation, Washington
Wang X, Wang H, Wang H, Zhang L, Cao X (2011) Constructing a decision support system for management of employee turnover risk. Inf Technol Manag 12(2):187–196
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Rationale to use GA
In this Appendix, the complexity of the proposed problem and the reason to use GA are demonstrated with a simple example. Assume r = 9 feasible routes (based on Fig. 2) from node 1 to node 3 via origin hub 5 and destination hub 6. Also, consider four types of cost functions: (1) simple constant cost functions (based on Eq. 1), (2) constant hub-discount cost functions (based on Eq. 2), (3) demand-dependent hub discount cost functions (based on Eq. 3), and (4) the proposed demand-dependent cost function with multiple sized vehicle options (based on Eq. 4 or, specifically, Eq. 6). The type of problem needed to estimate the number of cases to assign might be ∑ r X r 13 (a certain quantity) to 9 slots (where 0 ≤ r ≤ 9, X r ij is a non-negative integer).
-
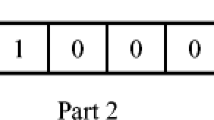
When ∑ r X r 13 = 1, the four cases obviously have nine different costs for the nine options for assignment: 9C1. The feasible assignments are
-
[1,0,0,0,0,0,0,0,0], [0,1,0,0,0,0,0,0,0], …[0,0,0,0,0,0,0,1,0], [0,0,0,0,0,0,0,0,1].
-
-
When ∑ r X r 13 = 2, the four cases have 45 different costs for the nine options for assignment: 1 × 9C1 + 1 × 9C2. The feasible assignments are
-
[2,0,0,0,0,0,0,0,0], [0,2,0,0,0,0,0,0,0], …[0,0,0,0,0,0,0,2,0], [0,0,0,0,0,0,0,0,2] when one option (|r| = 1) is exclusively chosen, or
-
[1,1,0,0,0,0,0,0,0], [1,0,1,0,0,0,0,0,0], …[0,0,0,0,0,0,1,0,1], [0,0,0,0,0,0,0,1,1] when two options (|r| = 2) are chosen.
-
In the first (1) and second (2) cost functions, the total cost for all the other cases (i.e., ∑ r X r 13 = X, where X is a positive integer greater than 1) can be estimated through simple a arithmetic calculation once ∑ r X r 13 = 1 is separately estimated and saved. For example, the total cost for [1–8] can be easily estimated by multiplying 1,2,…,9 by [1,0,0,0,0,0,0,0,0], [0,1,0,0,0,0,0,0,0], …, [0,0,0,0,0,0,0,0,1], respectively. No further complexity is required. In the third (3) and fourth (4) cost functions, the total cost for ∑ r X r 13 = X should be independently estimated. In general, as one unit of demand increases, the total costs for all r should be estimated.
-
When ∑ r X r 13 = 3, the four cases have nine different costs for the 9 options for assignment: 1 × 9C1 + 2 × 9C1 + 1 × 9C1. The feasible assignments are
-
[3,0,0,0,0,0,0,0,0], [0,3,0,0,0,0,0,0,0], …[0,0,0,0,0,0,0,3,0], [0,0,0,0,0,0,0,0,3] when one option (|r| = 1) is exclusively chosen, or
-
[2,1,0,0,0,0,0,0,0], [2,0,1,0,0,0,0,0,0], …[0,0,0,0,0,0,1,0,2], [0,0,0,0,0,0,0,1,2] when two options (|r| = 2) are chosen, or
-
[1,1,1,0,0,0,0,0,0], [1,1,0,1,0,0,0,0,0], …[0,0,0,0,0,1,0,1,1], [0,0,0,0,0,0,1,1,1] when three options (|r| = 3) are chosen.
-
In general, the number of the routing cases for one OD pair is β 1 × 9C1 + β 2 × 9C ···2 + β 9 ×9C9, where β i is the sequence number in Pascal triangles (i = 1, 2,…, 9). Using this formula, the number of cases between any two nodes is \(\sum\limits_{i = 1}^{9} {{}_{{\sum\limits_{r = 1}^{9} {X_{ij}^{r} } }}C_{i - 1} \times {}_{9}C_{i} }\). The number of cases are crucially dependent on \(\sum\limits_{r = 1}^{9} {X_{ij}^{r} }\). For example, when \(\sum\limits_{r = 1}^{9} {X_{ij}^{r} }\) = 10, 102, and 103, the number of cases for a possible route combination are 7.64, 3.811, and 2.619, respectively. In addition, if we take the batch strategy into account, the number of cases is increased to \(\left( {\sum\limits_{i = 1}^{9} {{}_{{\sum\limits_{r = 1}^{9} {X_{ij}^{r} } }}C_{i - 1} \times {}_{9}C_{i} } } \right) \times \left( {2^{N} - 1} \right)^{K}\), where N is the type of vehicle and K is the number of freight modes (see the algorithm for finding the minimum unit cost in the previous section). Furthermore, some inflows from the other nodes to hubs (e.g., X r 24 for any r) possibly change \(\varPsi_{hohd}^{{k_{2} }} (\sum\limits_{(i,j) \in A} {X_{ij}^{{k_{2} }} } ,d_{HoHd}^{{k_{2} }} ,S^{kv} ) \times d_{HoHd}^{{k_{2} }}\) (Eq. 6). For example, if 1 TEU shifts from r = 3 to r = 7 for X13, it not only causes changes in the minimum unit costs (\(\varPhi_{13}^{r}\)) of the two shifted r for r = 3 and r = 7 but also changes in the minimum unit costs for all the other multimodal options (r). Therefore, the number of different cases in the function type (4) that are proposed in this study is \(\left( {\sum\limits_{i = 1}^{9} {{}_{{\sum\limits_{r = 1}^{9} {X_{ij}^{r} } }}C_{i - 1} \times {}_{9}C_{i} } } \right) \times \left( {2^{N} - 1} \right)^{K} \times OD\), where OD is the number of OD pairs in a given network. Compared to function type (3), there are obviously fewer feasible assignments than for function type (4) due to non-road drayage. If we ignore non-road drayage, |r| is reduced from 9 to 3—that is, the number of cases related to non-road drayage is 6 (i.e., r = 3, 4, 5, 7, 8, and 9). In addition, if the batch strategy is not considered in cases with function type (3), the number of cases can be defined as \(\left( {\sum\limits_{i = 1}^{3} {{}_{{\sum\limits_{r = 1}^{3} {X_{ij}^{r} } }}C_{i - 1} \times {}_{3}C_{i} } } \right) \times OD\), which is significantly less than the proposed function. Unless a meta-heuristic method such as GA is used, the proposed problem might not be solvable within a reasonable amount of time.
Appendix 2: GA-based heuristic algorithm
-
Step 1: Initialize the parameters for given data such as generation number, population size, length of chromosome (which is equivalent to the number of decision variables in real-coded GA), OD demand matrix (\(D_{ij}^{{}}\)), OD distance matrix \(d_{ij}^{k}\) for all (i,j) pairs and all modes in the cost function (\(\varPsi_{ij}^{k} (X_{ij}^{k} ,d_{ij}^{k} ,S^{kv} )\)), the lower bound (i.e., Constraint 4), and constant penalty (p).
-
Step 2: Generate the initial population (\(\tilde{X}_{ij}^{r}\)) with two vectors: \(\bar{X}_{ij}^{r}\) and \(\hat{X}_{ij}^{r}\)
-
Step 2.1: \(\bar{X}_{ij}^{r}\) is a vector including N random real numbers, where N is the number of decision variables on arc (i,j), 0\(\le\) \(\bar{X}_{ij}^{r}\) \(\le\) 1. Note: N is determined by the number of |r| and OD pairs (for example, N = 36 if |r| = 9 as in Fig. 2 and |OD| = 4 as in Table 2).
-
Step 2.2: \(\hat{X}_{ij}^{r}\) is a vector including N random binary numbers, \(\hat{X}_{ij}^{r}\) \(\in\) [0, 1]. 1 is assigned as a component of \(\hat{X}_{ij}^{r}\) if a random number is greater than 0.5; otherwise, 0 is assigned.
-
Step 2.3: The initial population (\(\tilde{X}_{ij}^{r}\)) is a vector placing \(\bar{X}_{ij}^{r}\) and \(\hat{X}_{ij}^{r}\) in the same raw in order.
Note: the number of raw of \(\tilde{X}_{ij}^{r}\) is 2N.
-
Step 2.4: Generate the matrix \(\tilde{X}_{ij}^{r}\) until it reaches the maximum population size.
Note: the matrix size of \(\tilde{X}_{ij}^{r}\) should be 2N multiplied by the maximum population size. It is assumed that the number of decision variables should be even.
-
-
Step 3: Update the initial population satisfying equality constraints (i.e., Constraint 1) for each arc (i,j) and generate the new population (\(X_{ij}^{r}\)).
-
\(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{X}_{ij}^{r}\) is the element-wise vector multiplication for the real number side (\(\bar{X}_{ij}^{r}\)) and the binary number side (\(\hat{X}_{ij}^{r}\)) of the initial population (\(\tilde{X}_{ij}^{r}\)).
-
\(X_{ij}^{r}\) = (\(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{X}_{ij}^{r} \times D_{ij}^{{}}\) /\(\sum\limits_{r} {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{X}_{ij}^{r} }\)), where \(\sum\limits_{r} {\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{X}_{ij}^{r} }\) is the sum of \(\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{X}_{ij}^{r}\) for all r on (i,j) and \(D_{ij}^{{}}\) is a given demand between i and j (TEU).
-
Note: a raw vector of \(X_{ij}^{r}\) is a candidate solution for (i,j) satisfying equality constraints and the size is N.
-
Step 4: Calculate the objective function (i.e., Eq. 5) for the population (\(X_{ij}^{r}\)) with g = 1 where g is generation number;
-
Save the objective function value for the gth population (Obj(g)).
-
Step 5: Check for inequality constraints (Constraints 3 and 4);
-
for each arc (i,j)
-
If \(\sum\limits_{{r_{k} }} {\sum\limits_{(i,j) \in A} {x_{ij}^{{r_{k} }} } } \le u_{{}}^{k}\) and \(\sum\limits_{{r_{k} }} {\sum\limits_{(i,j) \in A} {x_{ij}^{{r_{k} }} } } \le Hub_{{}}^{k}\)
-
Obj(g) = Obj(g)
-
Otherwise,
-
Obj(g) = Obj(g) + Penalty (p)
-
Step 6: Estimate the fitness function.
-
Step 7: Increase the generation number (g = g + 1) and Run Reproduce, Crossover, Mutation, and Elitism for \(X_{ij}^{r}\).
-
Step 8: Return to Step 3 if g is less than the maximum number of generations.
Steps 2 and 3 are not normally included in prototypes of the GA procedure. These two steps are designed to generate the initial population and simultaneously ensure the equality constraint. These steps would be removed if another technique to handle equality constraints could be developed. In addition, Step 7 is not fully described here. For the details of Step 7, see two pioneer studies by Holland [9].
Rights and permissions
About this article

Cite this article
Kim, N.S., Park, B. & Lee, KD. A knowledge based freight management decision support system incorporating economies of scale: multimodal minimum cost flow optimization approach. Inf Technol Manag 17, 81–94 (2016). https://doi.org/10.1007/s10799-014-0209-x
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10799-014-0209-x