
Abstract
We investigate the impact of implementing capitated-based Universal Health Coverage (UC) in Thailand on technical efficiency in larger public hospitals during the policy transition period. We measure efficiency before and during the transition period of UC using a two-stage analysis with Data Envelopment Analysis, bootstrap DEA, and truncated regressions. Our analysis indicates that during the transition period efficiency in larger public hospitals across the country increased. The findings differed by region, and hospitals in provinces with more wealth not only started with greater efficiency, but improved their relative position during the transitional phases of the UC system.

Similar content being viewed by others
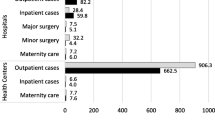
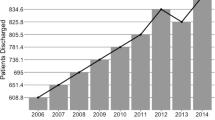
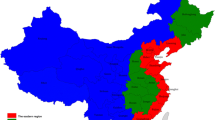
Notes
State enterprise hospitals are hospitals under state jurisdiction. Four of the nine such hospitals are located in Bangkok. Most municipal hospitals (11 out of 14), which are under provincial control, are located in Bangkok. Designation as a regional, large general or small general hospital is based primarily on size.
There were 137 public providers and 132 private providers in SSS in 2003.
A capitation payment is made to every hospital depending on the enrolled UC population in its service area. In 2002, the capitation payment was 1,204.30 baht (approximately $30 per person). The capitation rate has increased slightly since then.
This discussion relies heavily on Friesner et al. [23]. The primary difference between SFA and DEA lies in how the efficient frontier is calculated. SFA employs regression analysis to estimate the efficient frontier, and calculates individual efficiency scores by decomposing the error term of the regression equation. Because regression analysis is used, the efficiency scores can be analyzed using standard statistical techniques. However, a drawback to SFA is that the results may be subject to parametric specification bias; if one miss-specified the regression equation, the efficiency scores will be biased. DEA uses linear-programming methods to calculate both the efficient frontier and the efficiency scores. The advantage of DEA is that it is nonparametric in nature; that is, it does not require the researcher to specify a functional form for the production process being analyzed. Unlike SFA, DEA also allows the researcher to simultaneously examine several different types of efficiency (including technical, allocative, cost and scale), and allows for the specification of multiple outputs, especially when calculating technical and scale efficiency. A potential drawback is that DEA-generated efficiency scores are usually not normally distributed, and thus cannot be analyzed with standard, parametric hypothesis tests. In fact, DEA ignores stochastic elements in production and thus may be biased if any stochastic elements are correlated with specific hospital characteristics.
Some studies utilize both SFA and DEA; for example see [41].
The algorithm is available upon request.
We exclude community hospitals from the sample because they offer fewer and less intense services than do the general and regional hospitals. The almost 700 community hospitals have 70 beds or less and provide only primary care services. Regional and general hospitals tended to experience financial problem because community hospitals can off-load expensive and difficult cases onto them.
MOPH has collected financial and activity database for administrative purposes. Although later data are available since the 2003 fiscal year MOPH stopped collecting the numbers of inpatients and outpatients visits categorized by specialties. Thus, we cannot extend our specific analysis beyond 2002.
For outputs, we need to consider severity, which may influence utilization and therefore measured efficiency. One customary approach is to adjust outputs by case mix. However, MOPH does not provide direct measures of patient severity. As an alternative we estimate overall severity within a hospital by the ratio of number of large surgeries to total surgeries, which is used to adjust all outputs. The number of adjusted inpatient visits in each group is defined as \(\frac{{{{{\text{number}}\;{\text{of}}\;{\text{large}}\;\;{\text{surgeries}}} \mathord{\left/ {\vphantom {{{\text{number}}\;{\text{of}}\;{\text{large}}\;\;{\text{surgeries}}} {{\text{small}}\;{\text{surgeries}}}}} \right. \kern-\nulldelimiterspace} {{\text{small}}\;{\text{surgeries}}}}}}{{{\text{maximum}}\;{\text{of}}\;{\text{the}}\;{\text{numerator}}}} \times {\text{number}}\;{\text{of}}\;{\text{inpatient}}\;{\text{visits}}\)). A justification for adjusting all patients with this ratio is this; hospitals that attract a larger share of more complicated (i.e. large) surgeries likely attract more severe cases of other types of patients as well. See the Appendix C for more on this adjustment factor.
One of the referees of this paper noted that this might explain why we found that the estimated technical efficiency was higher for smaller hospitals and lower for larger hospitals, provided that quality improves with the size of the hospital. Likewise, this might also explain why the estimated technical efficiency was higher in wealthier provinces, provided that people in wealthier regions are healthier and thus treatment intensity in these regions is lower. We appreciate this valuable insight.
Most full-time personnel are nurses. Before the reform periods, Suraratdecha and Okunade [50] indicated that between 1985 and 1995, although the growth of nurses was higher than that of the physicians, the supply of nurses relative to population fell especially in early 1990s. They also found a gradual substitution of nurses and pharmacists for physicians.
The other intuitive reason of including LOS in the equation is that, if some unobserved heterogeneity affects both INEFF and LOS, then LOS serves as a good instrument for the unobserved heterogeneity.
The values of GPPCR are in real terms (1988 constant price).
The formula is defined as \(HI\; = \;\sum\limits_i^n {\Pi ^2 }\) where ∏ is the market share of a firm i, and n is a number of firms in that province.
One referee suggested that the ratio of private hospital beds to public beds would be an alternative, and perhaps superior, measure of private competition. There is value in both approaches. Using the ratio of private to public hospital beds would indicate, in our opinion, the extent of competition from private hospitals relative to the market size. Using the absolute number of private beds gives, again in our opinion, a better idea of the absolute level of competition from private hospitals. In any case, we ran the second step regressions using the ratio suggested by the referee and found no substantive difference in the results.
We dropped INUC due to a high collinearity. We retained OUTUC in the model because the number of outpatients has significantly changed during the period of study, while the number of inpatients was more stable.
By definition the variable (OUTUC) is zero before UC.
Kernel density estimation is a nonparametric technique for density estimation in which a known density function (the kernel) is averaged across the observed data points to create a smooth approximation. Usually, the kernel function is a probability density function, symmetric around zero.
The choice of smoothing variable is chosen because it copes very well for a wide range of densities; both unimodal densities and moderately bimodal densities.
Replications is set to B = 1,000. Efron and Tibshirani [17], p.275, recommend at least this number of simulation replicates in order to make the variability of the boundaries of the bootstrap confidence intervals “acceptably” low.
References
Abbott M, Doucouliagos C (2003) The efficiency of Australian universities: a data envelopment analysis. Econ Educ Rev 22:89–97
Banker RD (1993) Maximum likelihood, consistency and data envelopment analysis: a statistical foundation. Manage Sci 39(10):1265–1273
Badin L, Simar L (2003) Confidence intervals for DEA-type efficiency scores: how to avoid the computational burden of the bootstrap. Discussion paper 0316, Universit’e Catholique de Louvain
Barnum H, Kutzin J (1993) Public hospitals in developing countries: resource use, cost financing. The Johns Hopkins University Press, Baltimore
Burgess J Jr, Wilson P (1998) Variation in inefficiency among US Hospitals. Infor 36(3):84–102
Carey K (2000) Hospital cost containment and length of stay: an econometric analysis. South Econ J 67(2):363–380
Chang H (1998) Determinants of hospital efficiency: the case of central government-owned hospitals in Taiwan. Int J Manag Sci 26(2):307–317
Chattopadhyay S, Ray C (1996) Technical, scale and size efficiency in nursing home care: a non-parametric analysis of Connecticut homes. Health Econ 5:363–373
Chilingerian JA (1995) Evaluating physician efficiency in hospitals: a multivariate analysis of best practices. Eur J Oper Res 80:548–574
Chinlingerian JA, Sherman HD (2004) Health care applications: from hospitals to physicians, from productive efficiency to quality frontiers. In: Cooper WW, Zhu J (eds) Handbook on data envelopment analysis. Kluwer, Boston, MA
Conrad D, Wickizer T, Maynard C, Klastorin T, Lesser D et al (1996) Managing care, incentives, and information: an exploratory look inside the black box of hospital efficiency. Health Serv Res 31:235–59
Chu HL, Lui HZ, Romeis JC (2004) Does capitated contracting improve efficiency? Evidence from California hospitals. Health Care Manage Rev 29(4):344–352
Coelli T, Prasada Rao DS, Battese GE (1998) An introduction to efficiency and productivity analysis. Kluwer, Boston, MA
Defelice L, Bradford W (1997) Relative inefficiencies in production between solo and group practice physicians. Health Econ 6:455–465
Delsi E, Ray H (2004) A bootstrap-regression procedure to capture unit specific effects in data envelopment analysis. Working Paper 2004-15, University of Connecticut
Donaldson D, Pannarunothai S, Tangcharoensathien V (1999) Health financing in Thailand: technical report. Health Management and Financing Study Project, ADB no. 2997, Boston. Available at http://www.msh.org/resources/online_reports/pdf/thaihf0.PDF
Efron B (1982) The jackknife, the bootstrap, and other resampling plans. Monograph 38. Society for Industrial and Applied Mathematics, Philadelphia, PA
Enthoven AC (1988) Managing competition: an agenda for action. Health Aff 7(3):25–47
Enthoven AC, Richard K (1989a) A consumer-choice health plan for the 1990s: universal health insurance in a system designed to promote quality and economy (part 1). N Engl J Med 320(1):29–37
Enthoven AC, Richard K (1989b) A consumer-choice health plan for the 1990s: universal health insurance in a system designed to promote quality and economy (part 2). N Engl J Med 320(2):94–101
Ferrier GD, Hirschberg JG (1997) Bootstrapping confidence intervals for linear programming efficiency scores: with an illustration using Italian bank data. Journal of Productivity Analysis 8:19–33
Folland S, Hofler R (2001) How reliable are hospital efficiency estimates? Exploiting the dual to homothetic production. Health Econ 10:683–698
Friesner D, Rosenman R, McPherson M (2008) Are hospitals seasonally inefficient? Evidence from Washington State Hospitals. Appl Econ. Published online at http://dx.doi.org/10.1080/00036840600749730
Grootendorst PV (1997) Health care policy evaluation using longitudinal insurance claims data: an application of the panel Tobit estimator. Health Econ 6:365–382
Hamilton BH (1999) HMO selection and Medicare costs: Bayesian MCMC estimation of a robust panel data Tobit model with survival. Health Econ 8:403–414
Heflinger CA, Northrup DA (2000) What happens when capitated behavioral health comes to town? The transition from the Fort Bragg demonstration to a capitated managed behavioral health contract. Journal of Behavioral Health Services and Research 27:390–405
Hollingsworth B, Dawson P, Manadiakis N (1999) Efficiency measurement of health care: a review of nonparametric methods and applications. Health Care Manage Sci 2(3):161–172
Hollingsworth B (2003) Non-parametric and parametric applications measuring efficiency in health care. Health Care Manage Sci 6(4):203–218
Koopmans TC (1951) An analogus of production as an efficient combinations of activities. In: Koopmans TC (ed) Activity analysis of production and allocation. Cowles commission for research in economics. Monograph 13. Wiley, New York
Leger PT (2000) Quality control mechanism under capitation for medical services. Can J Econ 33(2):564–586
Lovell CAK (1993) Production frontiers and production efficiency. In: Fried HO, Lovel CAK, Schmidet SS (eds) The measurement of productive efficiency: techniques and applications. Oxford University Press, New York, pp 3–67
Mills A, Bennett S, Siriwanarangsun P, Tangcharoensathien V (2000) The response of providers to capitation payment: a case-study from Thailand. Health Policy 51:163–180
Ministry of Public Health, Thailand (2001) Health insurance systems in Thailand. Health Systems Research Institute, Nonthaburi, Thailand
Na Ranong V et al (2002) Evaluation of the universal coverage scheme in Thailand FY2001. Thailand Development Research Institute, Thailand
Na Ranong V et al (2004) The monitoring and evaluation of the universal health coverage in Thailand, second phase 2003–2004. Thailand Development Research Institute, Thailand
Ngorsuraches S, Sornlertlumvanich A (2006) Determinants of hospital loss in Thailand: experience from the first year of a universal coverage health insurance program. Health Care Manage Sci 9:59–70
Ozcan Y, McCue M, Okasha A (1996) Measuring the technical efficiency of psychiatric hospitals. J Med Syst 20(3):141–150
Ozcan Y, Wogen S, Mau L (1998) Efficiency evaluation of skilled nursing facilities. J Med Syst 22(4):211–224
Pannarunothai S, Patmasiriwat D, Srithamrongsawat S (2004) Universal health coverage in Thailand: ideas for reform and policy struggling. Health Policy 68(1):17–30
Rodriguez-Alvareza A, Fernandez V, Lovell CAK (2004) Allocative inefficiency and its cost: the case of Spanish public hospitals. Int J Prod Econ 92(2):99–111
Rosenman R, Friesner D (2004) Scope and scale inefficiencies in physician practices. Health Econ 13:1091–1116
Rosko M et al (1995) The effects of ownership, operating environment, and strategic choices on nursing-home efficiency. Med Care 33(10):1001–1021
Sheskin DJ (1997) Handbook of parametric and nonparametric statistical procedures. CRC Press, Florida
Silverman BW (1986) Density estimation for statistics and data analysis. Chapman and Hall, London
Simar L, Wilson PW (2000) A general methodology for bootstrapping in non-parametric frontier models. J Appl Stat 27(6):779–802
Simar L, Wilson PW (2000) Statistical inference in nonparametric frontier models: the state of the art. Journal of Productivity Analysis 13:49–78
Simar L, Wilson PW (2003) Estimation and inference in two-stage, semi-parametric models of production processes. Discussion paper 0307, Universit’e Catholique de Louvain
Simar L, Wilson PW (2004) Performance of the bootstrap for DEA estimators and iterating the principle. In: Cooper WW, Zhu J (eds) Handbook on data envelopment analysis. Kluwer, Boston, MA
Simar L, Wilson PW (2007) Estimation and inference in two-stage, semi-parametric models of production processes. J Econom 136:31–64
Suraratdecha C, Okunade A (2006) Measuring operational efficiency in a health care system: a case study from Thailand. Health Policy 77:2–23
Suraratdecha C, Saithanu S, Tangcharoensathien V (2005) Is the universal coverage a solution for disparities in healthcare? Finding from three low-income provinces of Thailand. Health Policy 73:272–284
Tangcharoensathien V et al (2002) Universal coverage and its impact on reproductive health services in Thailand. Reprod Health Matters 10(20):59–69
Tobin J (1958) Estimation of relationships for limited dependent variables. Econometrica 26(1):24–36
Valdmanis V (1992) Sensitivity analysis for DEA models—an empirical examination using public versus NFP Hospitals. J Public Econ 48(2):185–205
Valdmanis V, Kumanarayake L, Lertiendumrung J (2004) Capacity in Thai public hospitals and the production of care for poor and non-poor patients. Health Serv Res 39(6 Pt 2):2117–2134
Worthington A (1999) An empirical survey of frontier efficiency measurement techniques in healthcare services. Working paper, School of Economics and Finance, Queensland University of Technology, Australia
Xue M, Harker PT (1999) Overcoming the inherent dependency of DEA efficiency scores: a bootstrap approach. Unpublished working paper, Wharton Financial Institutions Center, University of Pennsylvania
Zuckerman S, Hadley S, Iezzoni L (1994) Measuring hospital efficiency with frontier cost functions. J Health Econ 13:255–280
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendices
1.1 Appendix A: bootstrap DEA estimators algorithm
This appendix borrows heavily from Badin and Simar [3].
Step 1. Find the original efficiency estimates from the sample of n producers \(\chi _n = \left\{ {\left( {x_i ,y_i } \right),i = 1, \ldots ,n} \right\}\), where x i ∈ R p is the input vector and y i ∈ R q is the output vector of producer i. For each observed producer \(\left( {x_i ,y_i } \right) \in \chi _n \), compute the DEA estimator of the efficiency score \(\hat \theta _i = \hat \theta _{{\text{DEA}}} \left( {x_i ,y_i } \right),\,i = 1, \ldots ,\,n\).
Step 2. If \(\left( {x_0 ,y_0 } \right) \notin \chi _n \) repeat step 1 for \(\left( {x_0 ,y_0 } \right)\) to obtain \(\hat \theta _i = \hat \theta _{{\text{DEA}}} \left( {x_0 ,y_0 } \right)\).
Step 3. Define \(S_m = \left\{ {\hat \theta _i , \ldots ,\,\hat \theta _m } \right\}\) where \(m = \# \left\{ {\hat \theta _i < 1} \right\}_{1 \leqslant i \leqslant n} \), i.e. the number of inefficient producers.
Step 4. Giving n is the number of decision-making units (DMUs), estimate the distribution \(f\left( {\hat \theta } \right)\) from the remaining \(\hat \theta \) and generate B samples of the boundary condition \(\hat \theta < 1\) (the size n − 1), which is \(\left\{ {\hat \theta _1^{*b} , \ldots ,\,\hat \theta _{n - 1}^{*b} .} \right\}_{b = 1}^B \). The steps are as follows:
4.1. Given a random sample \(\theta _1 , \ldots ,\theta _n \) with a continuous, univariate density f, the kernel density estimator is defined by:Footnote 18
where K( ) is the kernel function and h is the bandwidth parameter. Under mild conditions (h must decrease with increasing n) the kernel estimate converges in probability to the true density. Performance of kernel is measured by Mean Integrated Squared Error (MISE).
Bandwidth selection is a crucial issue in the application of the smoothing procedure. Refer to Silverman [44] for a completed review of several approaches of bandwidth selection. In this paper, the bandwidth function rule for univariate data recommended by is
where R 13 denotes the inter-quartile range of the sample \(\left\{ {\hat \theta _i } \right\}\) and denotes the standard deviation estimate of the efficiency estimates \(\left\{ {\hat \theta _i } \right\}\), respectively.Footnote 19
4.2. Using the reflection method [44] we estimate \(f\left( {\hat \theta } \right)\) under the boundary condition \(\hat \theta < 1\). Suppose we have m inefficient producers, denoting \(S_m = \left\{ {\hat \theta _i , \ldots ,\,\hat \theta _m } \right\}\). In order to find a consistent estimator of \(f\left( {\hat \theta } \right)\), let\(\left\{ {\beta _1^ * , \ldots ,\beta _{n - 1}^ * } \right\}\) be a bootstrap sample, obtained by sampling with replacement from S m and \(\left\{ {\varepsilon _1^ * , \ldots ,\varepsilon _{n - 1}^ * } \right\}\) a random variable of standard normal deviates. By the convolution formula, we have:
for i = 1,…, n − 1. Define now for i = 1,…, n − 1 the bootstrap data:
where \(\theta _i^ * \) defined in Eq. 6 is proved to be random variables distributed according to \(\hat f_h \left( z \right)\). The final smoothed resample efficiencies are obtained by rescaling the bootstrap data making the variance is approximately the sample variance of \(\hat \theta _i \). We employ the following transform: \(\hat \theta _i^* = \bar \hat \theta + \frac{1}{{\sqrt {\left( {1 + {{h^2 } \mathord{\left/ {\vphantom {{h^2 } {\bar \hat \sigma ^2 }}} \right. \kern-\nulldelimiterspace} {\bar \hat \sigma ^2 }}} \right)} }}\left( {\theta _i^* - \bar \hat \theta } \right)\),
where \(\bar \hat \theta = \frac{1}{n}\sum\limits_{j = 1}^n {\hat \theta _j } \) and \(\hat \sigma ^2 = \frac{1}{n}\sum\limits_{j = 1}^n {\left( {\hat \theta _j - \bar \hat \theta } \right)^2 } \).
Step 5. Then, draw n − 1 bootstrap values \(\hat \theta _i^* ,\,i = 1, \ldots ,\,n - 1\) from the kernel density estimate of \(f\left( {\hat \theta } \right)\) and sort in ascending order: \(\hat \theta _{\left( 1 \right)}^* \leqslant \ldots \leqslant \hat \theta _{\left( {n - 1} \right)}^* .\)
Step 6. Repeat step 5 (drawing n − 1 bootstrap values \(\hat \theta _i^* \)) B times (in this study, 1,000 times), to obtain a set of B bootstrap estimates \(\left\{ {\hat \theta _{\left( {n - j} \right)}^{*b} } \right\}_{b = 1}^B \), for some \(1 \leqslant j \leqslant n - 1.\) Footnote 20
Step 7. Finally, approximate \(\tilde \theta _{\left( {n - j} \right)} \) for some j \(\left( {1 \leqslant j \leqslant n - 1} \right)\) by the average of \(\hat \theta _{\left( {n - j} \right)}^{*b} \) over the B simulations:
Step 8. The confidence intervals for θ 0 are:
1.2 Appendix B: the adjustment factor
Without some measure of case mix it is possible that what shows up as inefficiency may in fact be due to case mix variation. The Ministry of Public Health (MOPH) does not gather direct information about patient severity so no common case mix measure is available. However, in the output mix, MOPH differentiates between large surgeries and small surgeries. “Large surgeries” are more complicated, require more staff time and equipment, and usually indicate a more severely ill patient. MOPH classifies large surgeries as those that apply epidural/spinal blocks or general anesthesia. Small surgeries are uncomplicated minor surgeries that do not need general anesthesia. Under the assumption that a hospital that does a greater share of large surgeries is more likely to attract more severely ill patients in all areas of care provision, we estimate relative severity for each hospital compared to severity of all hospitals in the sample by first computing the surgery mix in each hospital. Thus for hospital i:
mix i = (number of large surgeries in hospital i/number of small surgeries in hospital i).
Relative severity (or our case mix adjustment factor) for hospital i is then computed by the formula:
where (max × mix) is the largest value of mix in the sample over all i. Thus, INSUR which is the adjusted inpatient visits in acute surgical—general surgery and orthopedic surgery multiplies the number of inpatient visits within this category by the adjustment factor.
Table 17 shows simple statistics for the adjustment factor by year. Overall, there was little change in the adjustment factor over time. In fact, a hospital-by-hospital analysis of changes in the adjustment factor year to year showed that the average change in the adjustment factor by hospital from 2000 to 2001 was 0.009 with a standard deviation of 0.062 indicating that the change was not statistically different from zero with any reasonable level of confidence. For the change from 2001 to 2002 the mean was 0.009 with a standard deviation of 0.067, again not statistically significant. It is interesting to note that on average the net effect from 2000 to 2002 was zero. A more detailed analysis looking at the number of hospitals that increased or decreased year to year split almost evenly each year, again with no statistically significant pattern to these changes.
While there seems to be no change in the adjustment factor year to year, there are clear differences by hospital type, as shown in Table 18. Both the mean and median of the adjustment factor for regional and large general hospitals exceeds that of small general hospitals, indicating, as expected, that the former two types of hospitals handle more severely ill patients. Means for both regional and large general hospitals are significantly different from the mean for small general hospitals with over 95% confidence.
Finding differences in the adjustment factor by hospital type, but not over years, supports using this ratio as a severity adjustor for outputs, especially as we look for changes in efficiency over time. It indicates that individual hospital severity remained relatively constant. Moreover, our focus on changes in relatively efficiency of individual hospitals over time means the adjustment factor is less important than if we were most concerned with a comparing efficiency among hospitals. There is sometimes difficulty discerning differences in efficiency from differences in quality or case mix, with higher quality hospitals or those with more severe case mixes appearing inefficient. Since we concentrate on the change in efficiency, if we have measurement errors due to quality or case mix differences those should carryover year-to-year (recall that the adjustment factor showed little year-to-year changes but significant cross-section changes) and the responses we see should therefore be robust nonetheless.
1.3 Appendix C
Rights and permissions
About this article
Cite this article
Puenpatom, R.A., Rosenman, R. Efficiency of Thai provincial public hospitals during the introduction of universal health coverage using capitation. Health Care Manage Sci 11, 319–338 (2008). https://doi.org/10.1007/s10729-008-9057-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10729-008-9057-8