
Abstract
We study a dynamic game where blocs of fossil fuel importers and exporters exercise market power using taxes or quotas. A non-strategic fringe of emerging and developing countries consume and produce fossil fuels. Cumulated emissions from fossil fuel consumption create climate damages. We examine Markov perfect equilibria under the four combinations of trade policies, and compare these to the corresponding static games. Taxes dominate quotas for both the strategic importer and exporter; the fringe is better off under taxes than quotas, because taxes result in lower fuel prices and less consumption by the strategic importer, lowering climate damages.





Similar content being viewed by others

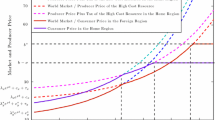
Notes
The presence of a third country can qualitatively alter even a non-strategic setting. For example, a transfer from country \(A\) to \(B\) cannot increase country \(A\)’s welfare in a two-country world, but it can increase \(A\)’s welfare in a three-country world. Dixit (1983) summarizes and generalizes this paradox.
As noted above, this explanation is intended to provide context for an otherwise hard-to-interpret numerical value, not to represent a plausible outcome. In particular, the calibration described here implies \(z=900\). However, world equilibrium production under the monopoly price, when \(I\) has exited the market, would be too little to sustain the stock at that level.
The equations for \(\phi \) and for \(\omega \) are quadratics. For both of these equations we take the smaller root, leading to the first line of Eq. (15). The smaller root satisfies the transversality condition. In addition, when we repeat this procedure for the importer, the smaller root is the only negative root. The coefficient of \(x^{2}\) in the importer’s value function must be negative, as discussed in the text.
We confirmed that the choice of the smaller root for both quadratics is correct by solving these equations for the other three combinations of roots. For two of these combinations, there was no equilibrium candidate because there was no solution to the two equations given by the two roots. For the third combination, there was a solution to these two equations, but it resulted in negative stocks, and thus violates the requirement that stocks be non-negative.
References
Amundsen E, Schöb R (1999) Environmental taxes on exhaustible resources. Eur J Polit Econ 15(2):311–329
Bergstrom T (1982) On capturing oil rents with a national excise tax. Am Econ Rev 72(1):194–201
Brander J, Djajic S (1983) “Rent-extracting tariffs and the management of exhaustible resources. Can J Econ 16(2):288–298
Dixit A (1983) The multicountry transfer problem. Econ Lett 13:49–53
Dong Y, Whalley J (2009) A third benefit of joint non-OPEC carbon taxes: transferring OPEC monopoly rent. In: CESifo Working Paper Series, 2741
Goulder LH, Schein AR (2013) Carbon taxes versus cap and trade: a critical review. Clim Change Econ 4(3):28
Johnson H (1953) Optimum tariffs and retaliation. Rev Econ Stud 21(2):142–153
Jørgensen S, Martín-Herrán G, Zaccour G (2010) Dynamic games in the economics and management of pollution. Environl Model Assess 15(6):433–467
Kalkuhl M, Edenhofer O (2010) Prices versus quantities and the intertemporal dynamics of the climate rent. In: CESifo Working Paper Series No. 3044
Karp L (1984) Optimality and consistency in a differential game with non-renewable resources. J Econ Dyn Control 8(1):73–97
Karp L (1988) A comparison of tariffs and quotas in a strategic setting. In: Giannini Foundation Working Paper 88–86
Karp L, Newbery D (1991) Optimal tariffs on exhaustible resources. J Int Econ 30(3–4):285–299
Liski M, Tahvonen O (2004) Can carbon tax eat OPEC’s rents? J Environ Econ Manag 47(1):1–12
Long NV (2010) A survey of dynamic games in economics. World Scientific, Singapore
Montero JP (2011) A note on environmental policy and innovation when governments cannot commit. Energy Econ 33:S13–S19
Njopmouo O (2010) On capturing foreign oil rents. In: Working Paper, University of Montreal
Rubio SJ (2005) Tariff agreements and non-renewable resource international monopolies: prices versus quantities. In: Department of Economic Analysis, University of Valencia, Discussion paper no 2005–2010
Strand J (2011) Taxes and caps as climate policy instruments with domestic and imported fuels. In Metcalf G (ed) U.S. Energy Tax Policy, Cambridge University Press
Strand J (2013) Strategic climate policy with offsets and incomplete abatement: carbon taxes versus cap-and-trade. J Environ Econ Manag 66(2):202–218
Tower E (1975) The optimum quota and retaliation. Rev Econ Stud 42(4):623–630
Wirl F (1995) The exploitation of fossil fuels under the threat of global warming and carbon taxes: a dynamic game approach. Environ Resour Econ 5(4):333–352
Wirl F (2012) Global warming: prices versus quantities from a strategic point of view. J Environ Econ Manag 64:217–229
Wirl F, Dockner E (1995) Leviathan governments and carbon taxes: costs and potential benefits. Eur Econ Rev 39:1215–1236
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: The Calibration of \(d\)
Suppose that \(I\) believes that if it were to drop out of the market (e.g. use a prohibitive tariff or set its import quota to 0), \(E\) would subsequently behave as a monopolist with respect to \(R\)’s import demand function. In that case (assuming \(f=1,g=0), E\) would set \(q=\frac{a}{2+b} \), implying that \(p=\frac{a+ab}{b^{2}+2b}\). The single period emissions in this case is the constant \(y\equiv \frac{a}{2+b}+b_{1}\frac{a+ab}{b^{2}+2b}\) and the equation of motion is \(x_{t+1}=\delta x_{t}+y\). If \(I\) ceases consumption when the stock reaches \(z\), the stock \(n\) periods later, denoted \(x_{\tau }\), equals
The present discounted value of the stream of marginal damages, when the stock reaches \(z\), is then
The marginal value to \(I\) of consuming the first unit is the difference between its choke price and the monopoly price, \(\frac{A}{B}-\frac{a+ab}{ b^{2}+2b}\). If it is optimal for \(I\) to cease consumption, under the belief that subsequent emissions would be \(y\) in each period, then the marginal benefit of an additional unit of production equals the present discounted value of the stream of future marginal damages,
This expression gives \(d\) as an implicit function of \(z\), the threshold stock above which it is optimal for \(I\) to cease consumption.
Under perfect competition, let annual production equal \(s\). Denote \(N\) as the number of years that it would take the stock to reach \(z\) units, starting from a zero stock level, given annual emissions \(s\): \(N\) is the solution to \(z=s\frac{\delta ^{N}-1}{\delta -1}\). We can use this equation to eliminate \(z\) from Eq. (9), resulting in an implicit expression for \(d\) as a function of the previously defined parameters and the new parameter, \(T\). Our choice \(d=3.3043\times 10^{-4}\) is equivalent to setting \(N=105\). In summary, our choice of \(d\) is consistent with a circumstance where it would be optimal for \(I\) to stop consuming the carbon intensive good after approximately 105 years of world consumption at the competitive level, given \(I\)’s belief that subsequent consumption would be at the monopoly price with respect to \(R\) excess demand.Footnote 2
Appendix 2: The Solution to the Model
We first explain how we re-write the problem in order to unify the four scenarios. This procedure enables us to solve a single game, and then obtain each of the policy scenarios by appropriate choice of parameters. We then explain how to solve the unified model.
1.1 The Unified Model
In all four scenarios, corresponding to the different policy mixes, we can write the single period payoffs of \(E\) and \(I\) and their “perceived” equations of motion (defined below) as
We intentionally abuse notation here in order to obtain a unified (for all four policy scenarios) expression of the game, so that we can use a single program to obtain the equilibrium in all four cases. We now explain the relation between Eqs. (10) and (11).
Consider first the case where both \(I\) and \(E\) choose quantities, \(Q\) and \(q\). In a linear MPE both agents believe that their rival uses a linear control rule. Suppressing time subscripts, \(I\) believes that \(E\) sets \( q=\lambda +\mu x\) and \(E\) believes that \(I\) sets \(Q=\rho +\sigma x\), where the endogenous parameters \(\lambda ,\mu ,\rho ,\sigma \) are to be determined. The beliefs are confirmed in equilibrium. That is, given \(I\) ’s belief about \(E\)’s policy, \(I\)’s optimal policy is \(Q=\rho +\sigma x\), and given \(E\)’s belief about \(I\)’s policy, \(E\)’s optimal policy is \( q=\lambda +\mu x\).
Using the price under quotas, and \(I\)’s belief, \(I\) expects the equilibrium price to be
Using this expression and \(P=\frac{A-Q}{B}\) in \(I\)’s flow payoff, Eq. (1), we write that payoff as a quadratic function in \(q\) and \(x\), as in the first line of Eq. (10). Equating coefficients of terms of the same power (e.g., equating the coefficient of \(x^{2}\) in both equations), we obtain the formulae for \( f_{I},g_{I},h_{I},r_{I},s_{I}\). Similarly, given its beliefs, \(I\)’s “perceived” equation of motion (i.e., its belief about the equation of motion) is
which has the same form as the second line in Eq. (10). Again, equating coefficients of terms of the same power, we obtain the formulae for \(k_{I},m_{I},n_{I}\). We obtain the formulae for the coefficients in Eq. (11) using the same procedure.
We use the same method to obtain formulae for the coefficients of the other three control problems.
1.2 Solution to the Unified Model
We now work with the control problems defined by Eqs. (10) and (11). Each agent’s equilibrium control rule, \(q=\lambda +\mu x\) for \(E\) and \(Q=\rho +\sigma x\) for \(I\), appears in the other agent’s control problem. Consider \(E\)’s control problem. Its dynamic programming equation (DPE) is
where the second line uses the second line in Eq. (11) to write \(W(x^{\prime })\) as a function of the current \(x\) and the current choice \(q\). Because of our choice of a linear equilibrium, \(E\) solves a linear quadratic control problem, for which it is well known that the unique solution is a quadratic value function. We write this function as \( W(x)=\epsilon +\nu x+\frac{\phi }{2}x^{2}\), where the parameters \(\epsilon ,\nu ,\phi \) are to be determined. Using this function to eliminate \( W\left( x^{\prime }\right) \) on the right side of Eq. (12), we express the right side as a linear quadratic function of \(q,x\) and the unknown coefficients. We maximize this expression with respect to \(q\) to obtain the coefficients of \(E\)’s control rule \(Q=\lambda +\mu x\):
The maximized value of the right side of the DPE (12) is a quadratic function in \(x\), as is the left side. The DPE holds identically in \(x\) if and only if the coefficients of terms of order of \(x\) are equal. We define
and equate coefficients of terms of order of \(x\) on the two sides of the maximized DPE to obtain the following formula for the unknown parameters.Footnote 3
The importer \(I\) solves a similar control problem, where its single period payoff is the first line of Eq. (10) and its perceived equation of motion is the second line of that equation. Denoting \(I\)’s value function as \(V(x)\), we write its DPE as
Equation (16) has the same form as the exporter’s DPE (12), except that the subscript \(I\) replaces the subscript \(E\) on parameter coefficients, the function \(V\) replaces \(W\), and the control \(Q\) replaces \(q\). Denote the quadratic value function as \(V(x)=\chi +\psi x+ \frac{\omega }{2}x^{2}\). Substituting this function into the DPE (16) we repeat the procedure above to obtain expressions for the endogenous parameters \(\chi ,\psi ,\omega ,\sigma ,\rho \). These formulae are identical to those in Eqs. (13) and (15), except that the subscript \(I\) replaces the subscript \(E\), and the parameters \(\chi ,\psi ,\omega ,\sigma ,\rho \) replace the parameters \(\epsilon ,\nu ,\phi ,\lambda ,\mu \); we also define a function \( \Delta _{I}\) using an equation analogous to (14).
The system consisting of (13) and (15) and the definition (14), together with the corresponding equations (not shown) for \(I\) can be solved recursively. We first solve the four equations that determine \(\omega ,\phi ,\sigma ,\mu \). This four dimensional system can be reduced to a two-dimensional system by noting that for all policy scenarios, \(g_{E}\) is a linear function of \( \sigma \), and \(g_{I}\) is a linear function of \(\mu \). The second line of Eq. (13) shows that \(\mu \) is a linear function of \(g_{E}\), and hence a linear function of \(\sigma \). Inspection of the analogous equation for \(I\) (not shown), shows that \(\sigma \) is a linear function of \(\mu \). We can solve this two dimensional linear system to obtain values of \(\sigma \) and \(\mu \) as functions of \(\omega \) and \(\phi \). Substituting these expressions into the equations that determine \(\omega \) and \(\phi \) (the first line of Eq. (15) for \( \omega \) and the corresponding equation—not shown—for \(\phi \)), we obtain two cubics in \(\omega \) and \(\phi \). We can numerically solve these two cubics to find the correct values of \(\omega \) and \(\phi \).
Given the values of \(\omega \) and \(\phi \), we can then obtain \(\sigma \) and \(\mu \) using the the expressions described in the previous paragraph. With numerical values for \(\omega ,\phi ,\sigma ,\mu \), we then use the equations for \(\lambda \) and \(\nu \) and the corresponding equations (not shown) for \( \rho \) and \(\psi \) to solve for these four parameters; this system is linear. We then solve the decoupled equations for \(\tau \) and \(\chi \) (again, the equation for \(\chi \) is not shown).
We also need an expression for the present discounted value of the stream of \(R\)’s payoff. Equation (2) gives \(R\)’s single period payoff. Denote \(p=\mu _{R}x+\lambda _{R}\) and \(Q=\sigma _{R}x+\rho _{R}\) as the equilibrium values of \(p\) and \(Q\). The parameters of these functions depend on the particular policy scenario, and their values are obtained from the solution to the different games. \(R\)’s flow payoff depends on \(p\), which in equilibrium is a function of \(x\), and the evolution of \(x\) depends on both \(p\) and \(Q\), via Eq. (8). \(R\)’s continuation payoff is therefore a function of \(x\), which we denote \( Y(x)\). The value of the stream of \(R\)’s payoff equals its flow payoff plus its discounted continuation payoff. Therefore, \(Y(x)\) must satisfy the functional equation
Substituting the quadratic trial solution, \(Y(x)=\frac{\gamma }{2}x^{2}+\eta x+\varsigma \), into Eq. (17) and equating coefficients of terms in order of \(x\) provides the equations for the parameters of \(R\)’s value function:
Appendix 3: Calculation of a Pigouvian Tax
As in the text, the world price, defined as the price that \(E\) receives, is \( p\). Consumers in \(I\) pay an additional Pigouvian Tax (\(\Upsilon \)) added to the price: \(p+\Upsilon \) and consumers in \(R\) face the same price.
Country \(I\) has no domestic production; its demand for imports equals \( A-B(p+\Upsilon )\). The climate-related damages, conditional on \(x\), are \( \frac{d}{2}x^{2}\) where \(d\) is a constant. \(I\)’s single period payoff equals consumer surplus minus environmental damages:
At price \(p+\Upsilon , R\)’s domestic demand is \(a-b_{0}(p+\Upsilon )\) and its domestic supply is \(b_{1}p\), so its net imports equal \( a-bp-b_{0}\Upsilon \), with \(b_{0}+b_{1}\equiv b\). \(R\)’s gains from trade minus its climate related damages \(\frac{\kappa }{2}x^{2}\) equal its flow payoff:
The exporter, \(E\), has no domestic consumption. These producers’ marginal cost function, equal to \(E\)’s supply function, is \(f+gp\), where \(f\) and \(g\) are constants. The exporter’s single period payoff equals its domestic profits
Each agent has the same constant discount factor, \(\beta \). Welfare for each agent equals the discounted stream of their single period payoff.
The social planner maximizes the sum of the payoffs plus rents collected through the tax.
We can write the total demand equal to total supply (to get \(p\) in terms of \( \Upsilon \)) and the “perceived” equation of motion (defined below) as
The social planner will choose a tax \(\Upsilon \) which in equilibrium is a linear function of the state, \(\Upsilon =\lambda +\mu x\). The social planner solves the following optimization problem
where the second line uses the equation of motion to write \(S(x^{\prime })\) as a function of the current \(x\) and the current choice \(\Upsilon \). The social planner solves a linear quadratic control problem, for which it is well known that the unique solution is a quadratic value function. We write this function as \(S(x)=\epsilon +\nu x+\frac{\phi }{2}x^{2}\), where the parameters \(\epsilon ,\nu ,\phi \) are to be determined. Using this function to eliminate \(S\left( x^{\prime }\right) \) on the right side of Eq. (12), we express the right side as a linear quadratic function of \(\Upsilon ,x\) and the unknown coefficients. We maximize this expression with respect to \(\Upsilon \) to obtain the coefficients of the control rule \(\Upsilon =\lambda +\mu x\):
The maximized value of the right side of the DPE (12) is a quadratic function in \(x\), as is the left side. The DPE holds identically in \(x\) if and only if the coefficients of terms of order of \(x\) are equal. We equate coefficients of terms of order of \(x\) on the two sides of the maximized DPE to obtain the unknown coefficients. Hence, we obtain \( \Upsilon =\lambda +\mu x\), the optimal Pigouvian tax as determined by the social planner.
Rights and permissions
About this article

Cite this article
Karp, L., Siddiqui, S. & Strand, J. Dynamic Climate Policy with Both Strategic and Non-strategic Agents: Taxes Versus Quantities. Environ Resource Econ 65, 135–158 (2016). https://doi.org/10.1007/s10640-015-9901-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10640-015-9901-5