
Abstract
When building a space catalogue, it is necessary to acquire multiple observations of the same object for the estimated state to be considered meaningful. A first concern is then to establish whether different sets of observations belong to the same object, which is the association problem. Due to illumination constraints and adopted observation strategies, small objects may be detected on short arcs, which contain little information about the curvature of the orbit. Thus, a single detection is usually of little value in determining the orbital state due to the very large associated uncertainty. In this work, we propose a method that both recognizes associated observations and sequentially reduces the solution uncertainty when two or more sets of observations are associated. The six-dimensional (6D) association problem is addressed as a cascade of 2D and 4D optimization problems. The performance of the algorithm is assessed using objects in geostationary Earth orbit, with observations spread over short arcs.
Similar content being viewed by others


1 Introduction
Updating and maintaining a catalogue of resident space objects (RSOs) is fundamental for keeping the space environment collision-free, predicting space events and performing activities. Due to the development of new observing hardware and the increasing number of RSOs, the number of observations available is increasing by the day. However, these data are not all equivalent: some are planned re-acquisitions for a specific object, while others are obtained when surveying the sky and thus need to be associated with an RSO. Once an observation is known to pertain to a specific object, the catalogue can be updated and the uncertainty associated with its state reduced. Observations that are not linked to any object in the catalogue are called uncorrelated tracks (UCTs). The main sources of UCTs are operational satellites manoeuvres, break-up events, small objects that are occasionally observed and newly launched satellites (Pastor-Rodríguez et al. 2018). When a new object is observed, initial orbit determination (IOD) techniques can compute a solution orbit. The uncertainty of this solution can, however, be very large, and consequently a single track is of little value unless it is associated with other tracks of the same object (Lei et al. 2018). When three or four UCTs are associated, the state estimate is considered meaningful and the object is then added to the catalogue (Hill et al. 2012).
In the literature, a number of methods have been proposed to tackle the problem of associating UCTs. For example, in the fixed-gate association technique the threshold for association is computed on the position difference between two UCTs. However, this technique has some limitations, in that it does not consider relative velocities and the association volume is based neither on the estimated uncertainties of the tracks, nor on how these uncertainties change with time (Hill et al. 2012). Other methods do take into account track uncertainty and compute a distance-like metric to measure the closeness of two UCTs when the orbits and uncertainties are propagated to a common epoch (Lei et al. 2018). For most Earth-orbiting space objects, the state uncertainty of the track is assumed to be Gaussian (Vittaldev et al. 2015): the covariance matrix is then representative of the state uncertainty. Hill et al. (2008) proposed the covariance-based track association method, which derives the association volume from the covariance matrix for each UCT. The method propagates the two covariance matrices to a common epoch and then calculates how closely the two tracks correlate. This statistical quantity is called Mahalanobis distance and follows a Chi-squared distribution.
The most challenging problem, however, is the uncertainty propagation. Hence, several combinations of different coordinates and propagation techniques have been proposed, which improve the success rate of the association method (Hill et al. 2012). In Hussein et al. (2015b), the unscented transform (Julier et al. 2000) is used to propagate the covariances including second-order effects. Hussein et al. (2014, 2015a, b, 2016) also proposed association methods using information theoretic criteria, including the Bhattacharyya information divergence and the mutual information. All methods mentioned so far assume initial Gaussian statistics and consider only the mapped means and covariances. However, due to strong nonlinearities in orbital dynamics, the propagated uncertainties can quickly become non-Gaussian. Some methods go beyond the Gaussian assumption and map the uncertainty by using state transition tensors (Park and Scheeres 2006) or Gaussian mixture models (Terejanu et al. 2008; DeMars and Jah 2013). All these approaches fall within the “single frame methods”, which are most suitable for sparse data and decide the best association per target given a specific figure of merit. More recently, there has been increased interest in the so-called multiple frame methods: they temporarily keep multiple associations per target and sequentially eliminate them with further observations. They are more suitable when re-acquisition is performed within a limited amount of time, such as for catalogue build-up. An example of this is the multiple hypothesis tracking method (Aristoff et al. 2014).
In this paper, we introduce a method that addresses some of the issues and limitations in linking different types of new observations to a previously obtained track determined from a short arc observation, thus placing our approach within the above-mentioned “single frame methods”. The track is computed as the solution of a least squares (LS) problem, while the uncertainty region is defined considering nonlinearities in the mapping between observations and state. For this purpose, the two-dimensional extension of the line-of-variation (LOV) algorithm, that is the gradient extremal surface (GES) (Principe et al. 2019), is used to define an initial two-dimensional uncertainty box, as explained in Sect. 2.3. Whenever new observations are acquired, this box is nonlinearly propagated to the time of the new observations using automatic domain splitting (ADS) techniques to guarantee accuracy, and a target function is computed to perform the association. We formulate different target functions according to the following three different types of new observation: a sparse single optical observation, a too-short arc (TSA) and another track. The main difference between the scenarios is the length of the observed arc, which determines the possibility of carrying out orbit determination and thus the associated uncertainty dimension. Different from a short arc, a TSA, also known as tracklet, is not sufficient to determine an orbit. The TSA is typically linearly approximated and its partial information stored in a four-dimensional vector known as attributable. Given the two degrees of freedom of the solution, the orbit can only be determined when two or more TSAs are associated. This is known as the linkage process in the asteroid research community (Gronchi et al. 2015) or observation-to-observation association (OTOA). In the case of space debris, the definition of TSA depends on the orbital period of the object. In general, when the observed arc length is shorter than \(0.2\%\) of the orbital period, we are dealing with a TSA (Milani et al. 2004). In the case of a geostationary earth orbit (GEO), it translates into observations taken in a 2–3-min span. In Pirovano et al. (2018), a detailed analysis of observation conditions for IOD can be found. In the literature, both the tracklet-to-track and the single observation to track association scenarios are referred to as observation-to-track association (OTTA), since the new observations cannot determine the state. For clarity purposes, in this manuscript we will refer to OTTA only for the case of a single observation, while we will call tracklet-to-track association the case in which a TSA is observed. When two tracks are available, we adopt the classical nomenclature of track-to-track association (TTTA).
Once the different target functions are defined, the association problem is reduced to a sequence of three main steps: i) the use of polynomial bounder to quickly prune away regions in which the target function is high; ii) 2D optimization in the remaining domains to compute the minimum of the target function; iii) when necessary, running an additional 4D optimization to check whether uncertainties in the 4 neglected directions significantly affect the target function. Addressing the 6D association problem as a series of 2D and 4D sub-problems is beneficial in terms of computational cost. In particular, the high-order nonlinear propagation maps only a two-dimensional domain and is thus very efficient. This paper builds on results obtained in Principe et al. (2019, 2017), Pirovano et al. (2018).
2 Relevant background
This section describes the mathematical background necessary for the algorithm developed in the paper. Firstly, Sects. 2.1 and 2.2, respectively, describe the differential algebra (DA) framework and the ADS tool, a routine developed to ensure accurate polynomial representations. Section 2.3 defines the method exploited to determine the confidence region associated with the orbit determination (OD) solution initially obtained through a LS. This method is the GES.
2.1 Differential algebra framework
DA is a computing technique that substitutes the classical implementation of real algebra with the implementation of a new algebra of Taylor polynomials, enabling the efficient computation of the derivatives of functions within a computer environment Berz (1999). In DA, any function f of v variables that is \(\mathcal {C}^{k+1}\) differentiable in the domain of interest can be expanded into its Taylor polynomial up to an arbitrary order k with limited computational effort. These properties are assumed to hold for any function dealt with in this work. The notation for this is: \( f \approx \mathcal {T}_f^{(k)} \). An important tool exploited in this work is the polynomial bounder, which estimates the bounds of a polynomial over a specific domain. The implementation of DA used in this work is contained in the C++ library differential algebra computational engine (DACE), available for download on GitHub.Footnote 1
2.2 Automatic domain splitting
DA tools provide an approximation of a function f by using a Taylor polynomial of an arbitrary order k. As one moves away from the center of the expansion, the approximation’s accuracy decreases and thus a crucial issue is to estimate the truncation error of the Taylor polynomial in the domain of interest. If the estimated truncation error is larger than a required accuracy for the problem at hand, the initial domain is subsequently halved into smaller domains, and the Taylor approximation of f around the center point of each of the new domains is computed. The splitting process is stopped once the prescribed accuracy is met over the entire initial domain. As a result, the error of the new polynomial expansions in each sub-domain is reduced, while the union of the expansions still covers the entire initial set, effectively creating a mesh. This procedure for estimating and controlling the truncation error of Taylor approximations is referred to as ADS. Details of its implementation can be found in Wittig et al. (2015). The algorithm presented in this paper takes full advantage of the ADS.
2.3 Least squares solution and its confidence region
After refining and IOD solution with a LS routine, the confidence region of the LS solution can be defined from an optimization perspective as the region Z including orbits with acceptable values of the target function \(J(\varvec{x})\) within a certain variation \(K^2\) (Milani and Gronchi 2010):
where \(\varvec{x}^*\) is the solution of the LS and the control value \(K^2\) can be determined with the F-test method (Seber and Wild 2003). In the classical 2nd-order approximation, the confidence region is represented by an ellipsoid with axes aligned with the eigenvectors of the Hessian matrix of J and size determined by its eigenvalues. The weak direction, which is the main direction of uncertainty in the OD problem, is aligned with the eigenvector \(\varvec{v}_1\) corresponding to the smallest eigenvalue of H. This direction is meaningful because, under some conditions, the uncertainty region can be approximated as a unidimensional set along the weak direction, leading to the introduction of the LOV (Milani et al. 2005) in astrodynamics. However, in the case of short observation arcs, nonlinearities in the mapping between observations and state are relevant and thus terms above 2nd-order in the expression of \(J(\varvec{x})\) are also needed. The resulting weak direction may be curve. The concept of the LOV can then be extended to directions other than \(\varvec{v}_1\), when nonlinearities are relevant in more than one direction. In Principe et al. (2019), it was shown that nonlinearities are only significant in 2 directions for the short-arcs problem and it is then sufficient to run the LOV algorithm along the two main directions of uncertainty, \(\varvec{v}_1\) and \(\varvec{v}_2\), with \(\varvec{v}_2\) being the eigenvector corresponding to the second smallest eigenvalue of H. In Fig. 1, the resulting LOV\(_1\) and LOV\(_2\) are shown to depart from the corresponding eigenvectors (i.e. the semiaxes of the ellipsoid), thus justifying the computational cost of the procedure. Although not evidently curved, the two LOVs have different lengths with respect to the corresponding ellipsoid axes. Hence, the nonlinear analysis leads to an uncertainty region that was different from the linear approach. This can be noted comparing the grey box (enclosing the “linear” confidence region) against the red one (enclosing the nonlinear set). The GES algorithm (Principe et al. 2019), which is the 2D extension of the LOV, can then be used to correctly represent the structure of the confidence region with a nonlinear approach. Even though the confidence region associated with the LS solution is in general an n-dimensional region, in many cases of practical interest this region is stretched along two directions, and can be approximated as a 2D set. In mathematics, this concept is known as principal component analysis, a statistical procedure that uses an orthogonal transformation to convert a set of possibly correlated variables into a set of linearly uncorrelated variables called principal components. This transformation is defined in such a way that the first principal component has the largest possible variance and hence accounts for most of the variability in the dataset. Each subsequent component contains the highest variance in the remaining orthogonal directions. Since the first principal components account for most of the variability, dimensionality reduction can be introduced to decrease the problem complexity without substantial loss of information, which in our case coincides with two principal components. Exploiting this result from Principe et al. (2019), we now continue this two-dimensional analysis to investigate its usefulness in an observation correlation problem.

LOV\(_1\) and LOV\(_2\) compared to the 2nd-order ellipsoid semiaxes on the \(\{\pmb {v}_1,\pmb {v}_2\}-\)plane for an object in GEO (NORAD Catalog number 36830)
In this work, the uncertainty region is considered as a two-dimensional box that encloses both the 2nd-order ellipse and the GES to keep a conservative approach. Accordingly, a map is introduced to transform a point \(\tilde{\varvec{x}}_{{0}}\) on the plane \(\{\pmb {v}_1,\pmb {v}_2\}\), into a point \(\varvec{x}_{{0}}\) belonging to the full-dimensional space:
with V being the matrix whose columns are \(\pmb {v}_1\) and \(\pmb {v}_2\).
3 Association and domain pruning
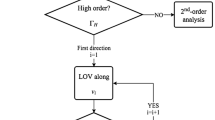
As introduced in Sect. 2, whenever a set of observations is available, an IOD solution is initially computed and then refined using a LS. This solution will be referred to as track from now on. The track uncertainty is very large when the object is observed on a short arc, even when approximated as a two-dimensional region. To reduce the uncertainty, new observations have to be acquired. The association and uncertainty pruning (AUP) algorithm presented here takes newly available data and looks for compatibility with the track in question. For this purpose, a residual function \(J_k\) is computed, which serves as a discriminating factor to decide whether portions of the initial uncertainty region are compatible with the new observation. Figure 2 shows the flowchart for the association process with different types of observations. In Sect. 3.1, the different expressions of \(J_k\) are shown, keeping in mind that they are all computed in the two-dimensional domain introduced above. Portions of the initial uncertainty that do not comply with the new information are then pruned away. A null intersection (i.e. no portion of the initial region retained) implies no correlation.

Flowchart of the AUP algorithm with initialization of track and different types of new observations. The blue rectangle is explained in detail in Fig. 4
3.1 Target function
The form of the target function depends on the type of newly acquired data. In the following, we give the different expressions of the target function \(J_{{k}}\) that, regardless of the type of observations, is a function of two variables \(v_1\) and \(v_2\), approximated as a mesh of Taylor polynomials, thanks to the use of DA and ADS to maintain high accuracy.
3.1.1 Observation-to-track
Let us first consider the case when a single observation is acquired, which comprises m independent measurements at a single epoch. That is, at time \(t_{{k}}\) new measurements \(\varvec{y}_{{k}}\) are acquired, with \(\varvec{y}_{{k}}\) being an m-dimensional vector. For an optical observation, each measurement is made of right ascension and declination (thus \(m=2\)), with corresponding covariances and time of observation. Modelled measurements \(\hat{\varvec{y}}_{{k}} = \varvec{h}(\varvec{x}_{{k}})\) are then computed from the available track and tested against the actual measurements \(\varvec{y}_k\), obtaining the residual function
where \(\sigma _j^2\) is the covariance of the jth measurement. Each observation is modelled as an independent Gaussian random variable. Equation (3) shows that \(2J_{{k}}\) is the sum of the squares of m independent standard normal random variables: it then follows a Chi-squared distribution with 2 degrees of freedom, \(J_k \sim \frac{1}{2} \chi ^2(2)\). Thus, depending on the confidence level desired, the threshold T can be chosen from the Chi-squared quantiles. In the following, this value will be indicated by \(q_{\chi ^2}(m,\alpha )\), where \(m\) coincides with the degrees of freedom and \((1-\alpha )\) is the confidence level.
3.1.2 Tracklet-to-track
In most cases, observation strategies are able to gather a trail of measurements rather than a single observation. When the observed arc is not long enough to run IOD+LS, it is still possible to extract valuable information from the tracklet: indeed a trail of observations contains information about the rate of change of the observed measurements. The following paragraph shows the statistical manipulations required to compute it, where a more in-depth analysis is carried out.
When the vector of right ascensions and declinations is linearly regressed with respect to time using the classical equation of linear regression
one can estimate the rate of change of the observations:
The overall information, which can be exploited for the association, is contained in the so-called attributable vector \(\mathcal {A}=(\alpha ,\dot{\alpha },\delta ,\dot{\delta })^T\) (Milani et al. 2004). A convenient choice is to perform the regression at central time of observation, so that \(\hat{\varvec{\beta } _0}\) and \(\hat{\varvec{\beta }}\) are uncorrelated. Then, \(\mathcal {A}=(\hat{\alpha }_C, \hat{\dot{\alpha }}, \hat{\delta }_C, \hat{\dot{\delta }})\).
The quantity
is known to follow a Student’s T distribution (Casella and Berger 2002), where \(\hat{\beta }\) stands for any of the four estimated coefficients that constitute \(\mathcal {A}\), \(N\) is the number of fitted parameters, and \(s_{\hat{\beta }}\) is standard estimate (SE) of the coefficient \(\hat{\beta }\). By construction, the attributable elements are uncorrelated and thus the covariance \(\Sigma _\mathcal {A} = Cov(\mathcal {A})\) is a diagonal matrix. The elements are a function of \(N\), the root mean square error (RMSE) of the regression \(s_{\hat{Y}}\) and the tracklet length \(\Delta t\):
Finally, the residual function \(J_k\) can be expressed as
where \(k\) is the central time of observation, \(\hat{\mathcal {A}}\) is the predicted attributable, while \(\mathcal {A}\) is the observed one. In the case of a tracklet, \(J_k \sim \frac{1}{2} \chi ^2(4)\), the threshold T can thus be chosen accordingly.
3.1.3 Track-to-track
The third and last case comprises a trail of observations long enough to compute a track. We then need to determine whether the two tracks belong to the same object. Let \(\varvec{x}_2(t_2)\) and P be the solution and covariance matrix of the newly acquired track, respectively. Similarly, \(\varvec{x}_1(t_1;{v}_1,{v}_2)\) is the solution of the initial track. \(\varvec{x}_1(t_1;{v}_1,{v}_2)\) is then propagated to the time of the new track, obtaining \(\varvec{x}_1(t_2;{v}_1,{v}_2)\). The residual function \(J_k\) can finally be expressed as:
where
When another track is acquired, \(J_k \sim \frac{1}{2} \chi ^2(6)\).
3.2 Orthogonal correction
Once \(J_k\) is updated according to the new type of observation, it is a function defined on \(\{\pmb {v}_1,\pmb {v}_2\}\), that is the plane of the slowest rate of change. Following principal component analysis, one can estimate the loss in information as a result of dimensionality reduction through the eigenvalues of the discarded directions:
For the work at hand, the eigenvalues of the four dimensions discarded are always several orders of magnitude smaller than the two principal directions, causing a mean loss of \(10^{-7}\%\). However, once the uncertainty is propagated and the residual function calculated, this loss is not assured to stay constant and limited. The true minimum of the residual function will not lie exactly on the plane, meaning that the 2D restriction will introduce an error which can invalidate the approximation \( \min J_k \approx \min J_k^V\), where \(J_k^V\) is the restriction of \(J_k\) onto \( V = \{\pmb {v}_1,\pmb {v}_2\}\). The association quality might thus be affected. To avoid this issue, we introduce a map to analyse the variation of \(J_k\) in the subspace \(V^C = \{\varvec{v}_1,\varvec{v}_2\}^\perp = \left\{ \varvec{v}_3,\dots ,\varvec{v}_6\right\} \), which is the 4D region initially neglected.
Let \(\varvec{x}_{k}^{V}\) be the point for which \(J_k^V\) is minimal. As the confidence region is narrow in the space \(V^C\), we can approximate the map \(\mathscr {M}: V^C\rightarrow J_{k}^{V^C}\) by a single Taylor polynomial around \(\varvec{x}_{k}^{V}\) and find its minimum \(\varvec{x}_{k}^{V^C}\). The minimum \( \varvec{x}_{k}\) of \(J_k\) in the full-dimensional space is then approximated by \( (\varvec{x}_{k}^{V},\varvec{x}_{k}^{V^C})\), and it is assumed \(\min J_k = J_k(\varvec{x}_{k}) \approx J_k(\varvec{x}_{k}^V, \varvec{x}_{k}^{V^C})\).
The strategy of splitting the 6D optimization into a cascade of 2D and 4D sub-problems is supported by the limited coupling between the two sub-spaces that show up in \(J_k\). This was assessed by computing the Taylor expansion of \(J_k\) in the 6D space and checking the magnitude of coefficients of the corresponding monomials. However, an a priori and rigorous estimate of these terms is not available. Thus, a statistical analysis of the difference between the minimum found in 6D and that resulting from the search in the two orthogonal spaces is presented in Sect. 4.3 to validate our strategy.
3.3 Association and uncertainty pruning algorithm overview
As shown in Sect. 2.3, the uncertainty region can be approximated as a two-dimensional set on \(V\). Assuming new observations are acquired at time \(t_{{k}}\), the state \(\tilde{\pmb {x}}_{{0}}\) (see Eq. 2) defined over the uncertainty region can be propagated to \(t_{{k}}\), obtaining \(\varvec{x}_{{k}}=\varvec{f}(\varvec{x}_{{0}})=\varvec{f}(V\tilde{\varvec{x}}_{{0}})\), where the function \(\varvec{f}\) represents the dynamics. \(\varvec{x}_k\) is then projected onto the observations space for the observations and tracklets cases and the appropriate \(J_k^V\) is computed. Points \(\tilde{\varvec{x}}_{{0}}\) for which \(J_k^V\) is small are good candidate orbits according to newly acquired measurements. Thus, portions of the initial uncertainty region in which \(J_k^V\) is larger than an established threshold T,
can be pruned away. This is not performed on a point-wise sampling base. DA can be used to approximate map points \(\tilde{\varvec{x}}_{{0}}\) into \(J_{k}^V\) with a Taylor polynomial up to an arbitrary order. However, the accuracy of the approximation tends to decrease drastically when the initial confidence region is large and/or the propagation time is long, due to high nonlinearity of the dynamics (Wittig et al. 2015). Hence, a single polynomial expansion may not be sufficient to accurately cover the entire confidence region: thus, the ADS introduced in Sect. 2.2 is applied to the 2D confidence region in \((\pmb {v}_1,\pmb {v}_2)\). The result is a mesh of sub-domains where each polynomial approximation accurately describes the confidence region as shown in Fig. 3. \(J_k^V\) is then expressed as:
where \(N_s\) is the number of sub-domains and \(J_{k,i}^V\) is the polynomial expansion over the \(i\)th sub-domain. This analytical representation allows a polynomial bounder to estimate the range of the function. Thus, an initial pruning can be performed by excluding domains where the lower bound of the range over the \(i\)th sub-domain exceeds the threshold T: \({\hbox {LB}} ( J_{k,i}^V ) > T\). The search for the minimum in 2D is then carried out for each remaining sub-domain using an optimizer, which proved to be more efficient than a grid search due to the rapid changes in the objective function. The BFGS algorithm from dlibFootnote 2 is used to perform a constrained optimization. This method is appropriate because splitting the domain into sub-domains due to nonlinearities reduces the likelihood of having multiple minima within each sub-domain. The sub-domains are then ordered in increasing values of the minima, and only those with minimum below the threshold are retained. For the others, the orthogonal correction defined in Sect. 3.2 is calculated again using the BFGS optimizer. This step ends whenever an acceptable minimum cannot be found for four consecutive sub-domains or the list is entirely inspected. In the end, the uncertainty kept is the union of those sub-domains where the minimum is found below the threshold either in the 2D or 4D search. In this way, the mesh created by the ADS for accuracy reasons is also exploited for uncertainty reduction. The pruning is shown by the black box in Fig. 3. The algorithm that updates the residual function \(J_k\), performs association and sequentially prunes the uncertainty region is the AUP algorithm, which is detailed in Algorithm 1 and summarized in Fig. 4.

Plot of the split \(J_k\) function (white) over the \(\{\pmb {v}_1,\pmb {v}_2\}-\)plane for an observation of object 36830 after 6 h as a track, with new uncertainty after association (black). The true state retrieved from TLEs is contained in the new uncertainty. The colour map shows the value of \(J_{{k}}\) in logarithmic scale

Detailed flowchart of the update of J following initial pruning by the bounder, then 2D optimization and finally 4D optimization

4 Result analysis
The association and uncertainty pruning algorithm was tested with objects in GEO, whose TLEs are available in Appendix 1. In particular, objects 26470, 36830, 37816 and objects 38778, 39285, 40364 have very similar orbital parameters and the association task is thus challenging. Data were obtained by adding Gaussian white noise \(\epsilon \) with standard deviation of \(\sigma = 0.5\) arcsec to simulated optical observations. It is to be noted that in this paper we have used Keplerian dynamics both for the uncertainty propagation and for the simulation of observations. The effects of unmodelled perturbations and real measurement errors are left for future investigation. However, working in a semi-analytical environment, the algorithm can receive as input any type of dynamics wanted. This means that perturbations may be added with no modifications to the current algorithm.
Lastly, the order for the DA variables is chosen. It is to be noted that both high-order and low-order polynomial expansions have large computational cost. The former requires computing several monomials, while the latter results in a large number of sub-domains to accurately describe the region. As a trade-off, 6th-order polynomial approximation is thus used.
The initial uncertainty was obtained by applying the LS method to a track of 8 observations. This region was such as to ensure a confidence level of \(99.9\%\) and then approximated as a 2D set as described in Sect. 2.3. Two different scenarios were analysed. In the first one, which will be referred to as scenario A, the observations of the initial track were 2 minutes apart and follow-up observations were then acquired after 24, 48, 72 h. In the second scenario, referred to as scenario B, observations of the initial track were 60 s apart and the follow-up observations acquired after 1, 3, 6 h. Scenario A follows a typical re-acquisition schedule for GEO satellites, while scenario B represents a possible schedule for catalogue build-up.
4.1 Computation time and pruning percentage
The algorithm was initially tested to analyse both the computation time and the pruning percentage of the different steps of the algorithm: the polynomial bounder, the 2D optimization and the 4D optimization. Such an analysis allowed us to determine whether all steps of the algorithm were efficient and/or worth the computational cost. Each bar of the pruning plot in Fig. 5b consists of \(250\) simulations in scenario A and re-observation after \(24\) h, while the computation time is averaged on correlated and uncorrelated simulations. Two sets of clustered GEO objects were used for these simulations: objects \(36830\), \(37816\) and objects \(38778\), \(39285\), \(40364\). Their observation was simulated from the location of the TFRM observatory (Spain) on consecutive nights starting from 14 January 2016. This date was chosen to ensure visibility of the satellites following sky background luminosity, object illumination and object elevation constraints. Figure 5a shows the computation time for the propagation and pruning routines. A computational analysis for the GES had previously been performed by Principe et al. (2019). Propagation takes around \(99\%\) of the total computation time for all three cases. The small difference lies in the type of data to be obtained at the new epoch: for example, the function to project on the attributable space is highly nonlinear and thus requires the ADS to perform more splits, hence increasing the total amount of propagation time for the tracklet scenario. Furthermore, propagating in DA may cost as much as two order of magnitude more in time than propagating in double precision. However, as underlined in Pirovano et al. (2018), the cost of propagating a state in DA comes with two main advantages: first of all, the possibility to then evaluate every possible initial condition as a function evaluation rather than a new propagation and secondly, the availability of higher-order terms, necessary to understand the influence that each variable has on the solution. The BFGS algorithm highly relies on both of them to find the correct optimum, and thus the cost of propagating a polynomial is balanced when performing association using an optimization method. To assess the efficiency of the three pruning steps, one can compare the computation time against the pruning percentage in Fig. 5b. It can be immediately noted that the DA built-in polynomial bounder routine eliminates more than \(98\%\) of uncertainty in a very small amount of time, thus proving its efficiency. However, this tool alone is not sufficient for association, as it can be noted in the uncorrelated cases where only the 2D and 4D searches discard the last \(1\%\) of domains. This result supports the implementation of these two further steps to assess correlation. The 2D search is mostly effective in the observation and track scenarios, where it always finds at least one sub-domain in all simulations, thus proving the effectiveness of searching the \(\left\{ \pmb {v}_1,\pmb {v}_2\right\} -\)plane. The 4D search is mostly effective in the tracklet scenario, where the highly nonlinear function to project on the attributable space sometimes does not find an optimum below the threshold in 2D, but correlation is recovered with the 4D search. Overall, the 2D and 4D searches take roughly \(1\%\) of the computation time but precisely pinpoint correlated and uncorrelated observations.

Average time and pruning percentage for correlated and uncorrelated observations of clustered objects in GEO
4.2 Algorithm validation
To test the accuracy of the analytic maps and the correct implementation of the optimization tools—in particular addressing a 6D problem with a cascade of 2D and 4D problems—a simple test was carried out. The GES region associated with the LS solution is scaled on \(I = \lbrace {[-1,1]\times [-1,1]\rbrace }\) interval, which means that any new observation that falls on this plane has to be associated with the existent track and the uncertainty domain kept has to contain this new observation. To prove this, the following test was constructed: the LS solution \(\pmb {x}_{LS}\) was perturbed by a \(\delta \pmb {x} = V \delta \tilde{\pmb {x}}\), where \(\delta \tilde{\pmb {x}} \in S = \lbrace {[-2,2]\times [-2,2]\rbrace }\), following a uniform distribution over \(S\). The new perturbed state \(\pmb {x}_p = \pmb {x}_{LS} + \delta {\pmb {x}}\) was then propagated to a second epoch where observations were simulated. This test was carried out on the track-to-track scenario. After obtaining the second track, correlation was looked for. One would expect to correlate the observations when \(\delta \tilde{\pmb {x}} \in I\), while no correlation was expected for \(\delta \tilde{\pmb {x}} \in S \backslash I\). Figure 6 shows the outcome of \(100\) simulations: the crosses and circles represent the perturbation \(\delta \tilde{\pmb {x}}\), which is enclosed in a sub-domain (white rectangle) whenever in \(I\) and not correlated with any pruned domain when outside. A further enforcement of this positive outcome is the fact that all correlations were performed in 2D and never in 4D, by test construction.

Perturbations on \(\left\{ \pmb {v}_1,\pmb {v}_2\right\} \)-plane to test association. Crosses show no correlation, while circles are enclosed by the sub-domain retained during correlation
4.3 Minimum search in 6D versus 2D+4D
A second test was carried out to validate the choice of splitting the search for the minimum in the residual function to a two-step optimization. The minima found by firstly searching \(\{\varvec{v}_1,\varvec{v}_2\}\) and later \(\{\varvec{v}_1,\varvec{v}_2\}^\perp \) were compared to the full 6D approach, where the BFGS algorithm was run on all six principal directions simultaneously. Figure 7 shows a simulated association case for object 25516 in both scenarios A and B for the track-to-track case. Scenario A involves more splits in 6D than in 2D, and this causes an increase in the computational cost in addition to the overhead introduced by the higher number of DA variables. It is to be noted that in all but one case, the splits were performed in the two principal directions, thus confirming the much lager influence that they have on the target function. In scenario B, the splitting structure was identical in 2D and 6D. One can see that despite retaining fewer sub-domains in scenario A, the two-step search never discarded the box containing the true solution. Given the 1-to-1 relationship between the sub-domains in scenario B, it was easy to compare the minima found in the 2D, 2D+4D and 6D case in each sub-domain. Table 1 shows the quantiles for the statistical distribution of the relative errors. As can be seen, a large difference is introduced when searching for the minima only in two dimensions (thus showing that the residual function is steep in the entire domain), but this difference becomes very small when the orthogonal correction is applied. Indeed, \(75\%\) of the minima found for all cases have a relative error of less than \(5\%\) with respect to the true minimum in 6D. Overall the two-step search alleviated the computational cost by considering less DA variables simultaneously and performing less splits, while achieving a satisfying level of accuracy on the result.

Association results for object 25516 in scenarios A and B with pruning performed both in 2D+4D and 6D
4.4 Association results
In a real-world scenario, one has to establish whether two different sets of observations are compatible, meaning correlation between observations may exist. These two sets are here analysed as a track and a single observation, a track and a tracklet or two different tracks. Association results were then assessed in terms of false positive and false negative rates. False negative means that the algorithm fails to identify observations belonging to the same object, thus effectively creating multiple instances of a same object, while false positive means that observations are associated although they belong to different objects.
4.4.1 Scenario A
The two above-mentioned rates do depend on the chosen threshold (Eq. 12), as well as the type of follow-up observations. In Fig. 8a, the case of a single follow-up observation is shown. Statistic considerations described in Sect. 3.1 suggested \(T=\frac{1}{2}q_{\chi ^2}(2,0.001)=6.91\) to fix the upper limit of false negative to \(0.1\%\). However, this value of T led to false negative rates of 5, 10 and \(25\%\), in the case of 2D approximation of the uncertainty set, when re-observing the object after 24, 48 and 72 h, respectively. This issue could be worked out by appropriately tuning the threshold T. The tuning, however, takes time and is case dependent—e.g. the time interval before the follow-up observation affects the choice of the optimal threshold. In addition, increasing the threshold could increase the rate of false positive. The 4D optimization allows us to solve this issue avoiding the tuning. With the 4D optimization, indeed the resulting rates of false positive and false negative drastically decreased, resulting in zero false positives over \(250\) simulations for each case. In the case of a tracklet, due to large nonlinearities in the target function, the 4D optimization was even more relevant as illustrated in Fig. 8b. The chosen threshold was \(T=\frac{1}{2}q_{\chi ^2}(4,0.001)=9.24\). The 2D approximation led to 20, 45 and \(70\%\) of false negative rates after 1, 2, 3 days, respectively. Again, these values dropped down, when including the 4D optimization. This behaviour confirmed the considerations described in Sect. 4.1 about the effect of the 4D optimization in the case of a tracklet. Similar results were obtained in the case of a track, with \(T=\frac{1}{2}q_{\chi ^2}(6,0.001)=11.23\). The 4D optimization significantly reduced the false negative rate, as depicted in Fig. 8c.

False negative and false positive rates in scenario A

False negative and false positive rates with covariance-based linear track-to-track association method in scenario A
Figure 9 displays false positive and false negative rates with a covariance-based linear track-to-track association method in scenario A. The statistical threshold, namely \(T=\frac{1}{2}q_{\chi ^2}(6,0.001)=11.23\), led to high false negative rates, hence the necessity to properly tune this value. The optimal threshold can be found at the intersection of the curves representing the two rates, and depends on the follow-up interval. With a follow-up interval of 24 h, the optimal threshold would be around 80, which led to false positive and negative rates of \(15\%\). In contrast, in the case of re-observations after 48 and 72 h the optimal threshold was between 40 and 45, with resulting false rates of \(10\%\).
4.4.2 Scenario B
In scenario B, the rate of false positives with a single observation was very high, due to both larger initial uncertainty set (due to the shorter arc used to determine the initial track) and shorter follow-up interval—see Fig. 10a. Exploiting all observations of the follow-up tracklet came in handy: with the knowledge of the angular-rate indeed different objects could be discriminated despite the short follow-up interval. The false positive rate then decreased and became as small as in scenario A, as illustrated in Fig. 10b. A similar plot was obtained in Fig. 10c with a follow-up track. In both cases, only one false positive was obtained and no false negatives. This result is also evident in Fig. 11 where a case where no correlation was analysed. The initial track was computed with a batch of 8 observations of object 37816 taken 60 s apart. Then, object 36830 was observed 1 h later. Figure 11a shows the \(J_k\) computed with a sparse observation. The short follow-up interval did not allow us to discriminate the two objects: the algorithm failed and associated the observations, resulting in a false positive. In the case of a tracklet, the resulting value of \(J_k\) was larger and the observations uncorrelated, as shown in Fig. 11b. Similarly, Fig. 11c illustrates the distribution of \(J_k\) with a track. Having more information about the object state, the minimum of the target function was larger than in the tracklet case, making it easier to discard uncorrelated observations.
It is to be noted that with this approach the threshold only depends on the type of re-observations and not on the time between re-acquisitions.

False negative and false positive rates in scenario B

Value of \(J_k\) with a single observation, a tracklet or a track of the object 36830, both observed after 1 h from the initial track. The initial uncertainty set of the track was obtained with LS with 8 observations 60 s apart of the object 37816. The colour map shows the value of \(J_{{k}}\) in logarithmic scale
4.5 Domain pruning results
During the solution of the association problem, the AUP algorithm sequentially reduced the initial uncertainty region. When new observations were acquired, the initial domain was propagated from \(t_{{0}}\) to \(t_{{k}}\). Then, sub-domains in which the minimum value of \(J_{{k}}\) was greater than T were pruned away. T was the same threshold as in the association task: \(T=6.91\) for a single observation, \(T=9.24\) for a tracklet and \(T=11.23\) for a track.

Sequential pruning of the domain for the object 36830 in scenario A. The 2D domain is defined by eigenvectors \(v_1\) and \(v_2\) associated with the two largest eigenvalues of the covariance matrix \(\gamma _1^2\) and \(\gamma _2^2\). The axes are scaled according to \(\gamma _1^2\) and \(\gamma _2^2\). The colour map shows the value of \(J_{{k}}\) in logarithmic scale. The black dot is the true solution
4.5.1 Scenario A
Figure 12 displays the sequential pruning of the initial domain in scenario A for the object 36830. Figure 12a illustrates that with a single observation \(98.4375\%\) of the domain was pruned away after 24 h, \(99.2188\%\) after 48 h. The last re-observation after 72 h was ineffective, with no further sub-domain discarded. The split direction was approximately aligned with the valley of \(J_k\), and hence the minimum of every sub-domain was below the threshold. In contrast, Fig. 12b shows that with a tracklet \(99.2188\%\) of the domain was pruned away after 24 h and \(99.9023\%\) after 48 and \(99.9268\%\) after 72 h. Thus, a slightly larger percentage of the domain was pruned away when considering the whole tracklet. It is to be noted that if tracklets had been treated as a sequence of sparse observations, one would have obtained the same pruning result as only considering the first observation, given the very small propagation time in between observations and hence the absence of further split. Thus, gathering information of very close observations in a tracklet rather than considering them as a sequence of sparse observations improved the percentage of pruning, due to the larger number of splits. With a track, the pruning of the domain is shown in Fig. 12c. The percentage of pruned domain was \(99.8047\%\) and \(99.9756\%\) after 24 and 48 h, respectively. In the case of the track, the retained domain after 48 h was so small that it did not split when the new track was acquired after 72 h. It is finally worth noting that in all cases the reduced domain contained the true solution retrieved from TLEs, represented by a black dot.
4.5.2 Scenario B
Similar results were obtained in scenario B, as shown in Fig. 13. With a single observation, \(93.75\%\) of the initial domain was pruned after 1 h, \(99.2188\%\) after 3 h and \(99.9023\%\) after 6 h. In contrast, acquiring a tracklet led to prune \(97.6563\%\) of the initial domain after 1 h, \(99.5117\%\) after 4 h and \(99.9512\%\) after 6 h. Finally, with a track \(93.75\%\) of the initial domain was pruned after 1 h, \(99.6094\%\) after 4 h and \(99.9023\%\) after 6 h. The pruning proved to be more effective when time separation was longer. With the first two re-observations, the percentage of cut domain was smaller than in scenario A, while the third re-observation led to a higher percentage of pruned domain in scenario B in all cases. However, the initial uncertainty set was significantly larger in scenario B, due to shorter observational arc of the initial track. Hence, a larger percentage of pruned domain does not necessarily mean smaller uncertainty set.

Sequential pruning of the domain for the object 36830 in scenario B. The 2D domain is defined by eigenvectors \(v_1\) and \(v_2\) associated with the two largest eigenvalues of the covariance matrix \(\gamma _1^2\) and \(\gamma _2^2\). The axes are scaled accordingly to \(\gamma _1^2\) and \(\gamma _2^2\). The colour map shows the value of \(J_{{k}}\) in logarithmic scale. The black dot is the true solution
5 Conclusions
In this work, we focused our investigation on the data association problem in which at least one track is determined on a short arc and the GES, the two-dimensional extension of the LOV, was used to estimate its uncertainty. This region was then nonlinearly propagated with Keplerian dynamics to the time of new observations. A target function was then computed over the uncertainty region. This function depended on the type of acquired observations: cases with single observations, tracklets and whole tracks were analysed. Taking advantage of ADS techniques, the uncertainty domain was split into sub-domains to ensure an accurate representation of the target function. In each sub-domain, the minimum of the target function was computed and the sub-domains incompatible with the new observations were pruned away. This computation involved, when necessary, more than one step: polynomial bounder, 2D optimization and 4D optimization. All steps contributed to the pruning process, with different computational costs and accuracy levels. Propagation took most of the computation time. The polynomial bounder cut away more than \(98\%\) of the uncertainty region in all cases while occupying a mere \(0.05\%\) of the computation time, but it was not accurate enough to discard uncorrelated objects, indeed the last 1–2\(\%\) of the domain was discarded by the two optimizations. These optimizations only took around \(1\%\) of the computation time, but could accurately discriminate between correlated and uncorrelated objects, with very low rates of false positive and negative. In particular, the 4D optimization prevented us from tuning the threshold of the target function used to determine whether observations were correlated.
With short follow-up intervals, the target function computed with a tracklet or a track proved to discard uncorrelated observations more accurately than the single observation scenario. The resulting false positive rates were indeed much lower. Finally, in the case of longer time separations and correlated objects, the overall percentage of pruned domain was in general larger.
Future work will undertake the analysis of real observations and perturbed dynamics as a 2D+4D problem, as shown in this paper for the Keplerian case. We will investigate the influence that the mismodellings will have on the two-dimensional definition of the residual function and the role of the 4D orthogonal correction to recover correlation.
References
Aristoff, J., Horwood, J., Singh, N., Poore, A., Sheaff, C., Jah, M.: Multiple hypothesis tracking (mht) for space surveillance: theoretical framework. Adv. Astronaut. Sci. 150, 55–74 (2014)
Berz, M.: Modern Map Methods in Particle Beam Physics. Academic Press, Cambridge (1999)
Casella, G., Berger, R.L.: Statistical inference, vol. 2. Duxbury, Pacific Grove (2002)
DeMars, K.J., Jah, M.K.: Probabilistic initial orbit determination using Gaussian mixture models. J. Guidance Control Dyn. 36(5), 1324–1335 (2013)
Gronchi, G.F., Baù, G., Marò, S.: Orbit determination with the two-body integrals: Iii. Celest. Mech. Dyn. Astron. 123(2), 105–122 (2015)
Hill, K., Alfriend, K., Sabol, C.: Covariance-based uncorrelated track association. In: AIAA/AAS Astrodynamics Specialist Conference and Exhibit, p. 7211 (2008)
Hill, K., Sabol, C., Alfriend, K.T.: Comparison of covariance based track association approaches using simulated radar data. J. Astron. Sci. 59(1–2), 281–300 (2012)
Hussein, I.I., Roscoe, C.W., Wilkins, M.P., Schumacher Jr., P.W.: Information theoretic criteria for observation-to-observation association, p. 15. Tech. rep, Air Force Research Lab, Kihei Maui (HI), Detachment (2014)
Hussein, I.I., Roscoe, C.W., Wilkins, M.P., Schumacher, P.W.: On mutual information for observation-to-observation association. In: 2015 18th International Conference on Information Fusion (Fusion). IEEE, pp. 1293–1298 (2015a)
Hussein, I.I., Roscoe, C.W., Wilkins, M.P., Schumacher, Jr P.W.: Track-to-track association using Bhattacharyya divergence. In: Proceedings of the Advanced Maui Optical and Space Surveillance Technologies Conference (AMOS 2015), Wailea, HI (2015b)
Hussein, I.I., Roscoe, C.W., Schumacher, Jr P.W., Wilkins, M.P.: UCT Correlation using the Bhattacharrya Divergence. In: Paper No. AAS-16-319, AAS/AIAA Space Flight Mechanics Meeting, Napa, CA, pp. 14–18 (2016)
Julier, S., Uhlmann, J., Durrant-Whyte, H.F.: A new method for the nonlinear transformation of means and covariances in filters and estimators. IEEE Trans. Autom. Control 45(3), 477–482 (2000)
Lei, X., Wang, K., Zhang, P., Pan, T., Li, H., Sang, J., et al.: A geometrical approach to association of space-based very short-arc LEO tracks. Adv. Space Res. 62(3), 542–553 (2018)
Milani, A., Gronchi, G.: Theory of Orbit Determination. Cambridge University Press, Cambridge (2010)
Milani, A., Gronchi, G.F., Vitturi, M.D.M., Knežević, Z.: Orbit determination with very short arcs. I admissible regions. Celest. Mech. Dyn. Astron. 90(1), 57–85 (2004)
Milani, A., Chesley, S.R., Sansaturio, M.E., Tommei, G., Valsecchi, G.B.: Nonlinear impact monitoring: line of variation searches for impactors. Icarus 73(2), 362–384 (2005)
Park, R.S., Scheeres, D.J.: Nonlinear mapping of Gaussian statistics: theory and applications to spacecraft trajectory design. J. Guidance Control Dyn. 29(6), 1367–1375 (2006)
Pastor-Rodríguez, A., Escobar, D., Sanjurjo-Rivo, M., Águeda, A.: Correlation techniques to build-up and maintain space objects catalogues. In: Proceedings of the 7th International Conference on Astrodynamics Tools and Techniques (ICATT), 6–9 November 2018 DLR Oberpfaffenhofen, Germany (2018)
Pirovano, L., Santeramo, D.A., Armellin, R., di Lizia, P., Wittig, A.: Probabilistic data association based on intersection of Orbit Sets. In: Proceedings of the 19th AMOS Conference, September 11–14: Maui. Maui Economic Development Board Inc, USA (2018)
Principe, G., Pirovano, L., Armellin, R., Di Lizia, P., Lewis, H.: Automatic domain pruning filter for optical observations on short arcs. In: 7th European Conference on Space Debris, Darmstadt, Germany (2017)
Principe, G., Armellin, R., Di Lizia, P.: Nonlinear representation of the confidence region of orbits determined on short arcs. Celest. Mech. Dyn. Astron. 131(9), 41 (2019)
Seber, A.F., Wild, C.J.: Nonlinear Regression. Wiley, New York (2003)
Terejanu, G., Singla, P., Singh, T., Scott, P.D.: Uncertainty propagation for nonlinear dynamic systems using Gaussian mixture models. J. Guidance Control Dyn. 31(6), 1623–1633 (2008)
Vittaldev, V., et al.: Uncertainty propagation and conjunction assessment for resident space objects. Ph.D. thesis (2015)
Wittig, A., Di Lizia, P., Armellin, R., Makino, K., Bernelli-Zazzera, F., Berz, M.: Propagation of large uncertainty sets in orbital dynamics by automatic domain splitting. Celest. Mech. Dyn. Astron. 122(3), 239–261 (2015)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: Objects data
Appendix A: Objects data
Data of the objects used in the simulations are reported in Table 2.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Pirovano, L., Principe, G. & Armellin, R. Data association and uncertainty pruning for tracks determined on short arcs. Celest Mech Dyn Astr 132, 6 (2020). https://doi.org/10.1007/s10569-019-9947-8
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1007/s10569-019-9947-8