
Abstract
Estimation of the covariance matrix of asset returns from high frequency data is complicated by asynchronous returns, market microstructure noise and jumps. One technique for addressing both asynchronous returns and market microstructure is the Kalman-Expectation-Maximization (KEM) algorithm. However the KEM approach assumes log-normal prices and does not address jumps in the return process which can corrupt estimation of the covariance matrix. In this paper we extend the KEM algorithm to price models that include jumps. We propose a sparse Kalman filtering approach to this problem. In particular we develop a Kalman Expectation Conditional Maximization algorithm to determine the unknown covariance as well as detecting the jumps. In order to promote a sparse estimate of the jumps,we consider both Laplace and the spike and slab jump priors. Numerical results using simulated data show that each of these approaches provide for improved covariance estimation relative to the KEM method in a variety of settings where jumps occur.




Similar content being viewed by others

References
Aravkin, A., Bell, B., Burke, J., Pilonetto, G.: An \(\ell _{1}\) Laplace robust Kalman smoother. IEEE Trans. Autom. Control 56(12), 2898–2911 (2011)
Aït-Sahalia, Y., Fan, J., Xiu, D.: High-frequency covariance estimates with noisy and asynchronous financial data. J. Am. Stat. Assoc. 105(492), 1504–1517 (2010)
Aït-Sahalia, Y., Myklank, P., Zhang, L.: How often to sample a continuous-time process in the presence of market microstructure noise. Rev. Financ. Stud. 100, 1394–1411 (2005)
Bandi, F., Russell, J.: Separating microstructure noise from volatility. J. Financ. Econ. 79, 655–692 (2006)
Barndorff-Nielsen, O., Hansen, P., Lunde, A., Shephard, N.: Multivariate realised kernels: consistent positive semi-definite estimators of the covariation of equity prices with noise and non-synchronous trading. J. Econom. 162, 149–169 (2011)
Barry, C.B.: Portfolio analysis under uncertain means, variances and covariances. J. Finance 29, 515–522 (1974)
Beck, A., Teboulle, M.: A fast iterative shrinkage-thresholding algorithm for linear inverse problems. SIAM Imaging Sci. 2(1), 183–202 (2009)
Bollerslev, T.: Modeling the coherence in short-run nominal exchange rates: a multivariate generalized ARCH approach. Rev. Econ. Stat. 72, 498–505 (1990)
Boudt, K., Croux, C., Laurent, S.: Outlyingness weighted covariation. J. Financ. Econom. 9(4), 657–684 (2011)
Boudt, K., Zhang, J.: Jump robust two time scale covariance estimation and realized volatility budgets. Quant. Finance 15(6), 1041–1054 (2015)
Boyd, S., Parikh, N., Chu, E., Peleato, B., Eckstein, J.: Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3(1), 1–122 (2011)
Campbell, J., Lo, A., MacKinlay, A.C.: The Econometrics of Financial Markets. Princeton University Press, Princeton (1996)
Candès, E., Wakin, M., Boyd, S.: Enhancing sparsity by reweighted \(\ell _{1}\) minimzation. J. Fourier Anal. Appl. 14, 877–905 (2008)
Chan, W., Maheu, J.: Conditional jump dynamics in stock market returns. J. Bus. Econ. Stat. 20(3), 377–389 (2002)
Corsi, F., Peluso, S., Audrino, F.: Missing in asynchronicity: a Kalman-EM approach for multivariate realized covariance estimation. J. Appl. Econom. 30(3), 377–397 (2015)
DeMiguel, V., Garlappi, L., Uppal, R.: Optimal versus Naive diversification: how inefficient is the 1/n portfolio strategy? Rev. Financ. Stud. 22(5), 1915–1953 (2009)
Dempster, A., Laird, N., Rubin, D.: Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 39(1), 1–38 (1977)
Fan, J., Li, Y., Yu, K.: Vast volatility matrix estimation using high frequency data for portfolio selection. J. Am. Stat. Assoc. 107(497), 412–428 (2012)
Fan, J., Wang, Y.: Multi-scale jump and volatility analysis for high-frequency financial data. J. Am. Stat. Assoc. 102(480), 1349–1362 (2007)
Fink, D.: A compendium of conjugate priors. Technical Report, Montana State Univeristy (1997)
Ghahramani, Z., Hinton, G.E.: Variational learning for switching state-space models. Neural Comput. 12(4), 963–996 (2000)
Goldstein, T., Osher, S.: The split Bregman method for \(\ell _{1}\) regularized problems. SIAM J. Imaging Sci. 2(2), 323–343 (2009)
Jobson, J.D., Korkie, B.: Estimation for Markowitz efficient portfolios. J. Am. Stat. Assoc. 75, 544–554 (1980)
Karpoff, J.: The relation between price changes and trading volume: a survey. J. Financ. Quant. Anal. 22, 109–126 (1987)
Liu, C., Tang, C.Y.: A quasi-maximum likelihood approach for integrated covariance matrix estimation with high frequency data. J. Econom. 180, 217–232 (2014)
Lo, A., MacKinlay, A.C.: An econometric analysis of nonsynchronous trading. J. Econom. 45, 181–211 (1990)
Lunenberger, D., Ye, Y.: Linear and Nonlinear Programming. Addison-Wesley, New York (2008)
Maheu, J.M., McCurdy, T.H.: News arrival, jump dynamics, and volatility components for individual stock returns. J. Finance 59(2), 755–793 (2004)
Mattingley, J., Boyd, S.: Real-time convex optimization in signal processing. IEEE Signal Process. Mag. 27, 50–61 (2010)
Meng, X.L., Rubin, D.: Maximum likelihood estimation via the ECM algorithm: a general framework. Biometrika 80, 267–278 (1993)
Peluso, S., Corsi, F., Mira, A.: A Bayesian high-frequency estimator of the multivariate covariance of noisy and asynchronous returns. J. Financ. Econom. 13(3), 665–697 (2015)
Roll, R.: A simple implicit measure of the effective bid-ask spread in an efficient market. J. Finance 39(4), 1127–1139 (1984)
Seeger, M.W.: Bayesian inference and optimal design for the sparse linear model. J. Mach. Learn. Res. 9, 759–813 (2008)
Shumway, R., Stoffer, D.: Time Series Analysis and its Applications with R Examples. Springer, Berlin (2011)
Shumway, R.H., Stoffer, D.S.: An approach to time series smoothing and forecasting using the EM algorithm. J. Time Ser. Anal. 3(4), 253–264 (1982)
Wu, C.F.: On the convergence properties of the EM algorithm. Ann. Stat. 11(1), 95–103 (1983)
Zangwill, W.: Nonlinear Programming: A Unified Approach. Prentice-Hall, Upper Saddle River (1969)
Zhang, L.: Estimating covariation: Epps effect and microstructure noises. J. Econ. 160(1), 33–47 (2011)
Zhang, M., Russel, J., Tsay, R.: Determinants of bid and ask quotes and implications for the cost of trading. J. Empir. Finance 15(4), 656–678 (2008)
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The work was partially supported by NSF Grants DMS-1522383 and IIS-1632935.
Appendices
Appendices
A Kalman smoothing equations
The Kalman smoother can be used to compute the posterior distribution of X(t) given Y and an estimate of \(\varTheta = [D,\varGamma ,\varSigma _{o}',J]\). From [35] the posterior distribution is normal and is completely characterized by the following quantities for \(m=T\)
These values can be computed efficiently using a set of well known forward and backward recursions [34] known as the Rauch–Tung–Striebel (RTS) smoother. The forward recursions are
with \(\bar{X}(0|0)=\mu \) and \(P(0|0)=K\).
The backward equations are given by
A backward recursion for computing \(P(t,t-1|T)\) is
where
B Convergence of KECM algorithms
Convergence of the EM and ECM algorithms in general is considered in [30, 36] respectively. It is shown in [30] that the ECM algorithm converges to stationary point of the log posterior under the following mild regularity conditions
-
1.
Any sequence \(\varTheta ^{(k)}\) obtained using the ECM algorithm lies in a compact subset of the parameter space, \(\varOmega \). For our case we need to restrict the parameter space such that \(\sigma _{o}^{2} \ne 0\) and \(\varGamma \) is positive definite.
-
2.
\(\mathcal {G}(\varTheta ,\varTheta ')\) is continuous in both \(\varTheta \) and \(\varTheta '\).
-
3.
The log posterior \(L(\varTheta )\) is continuous in \(\varOmega \) and differentiable in the interior of \(\varOmega \).
1.1 B.1 Algorithm 1
Since the Laplace prior on J is not differentiable condition 3 is not satisfied and the results in [30] are not directly applicable. However the proofs and solution set in [30] can be modified to handle this irregularity.
Before addressing condition 3 we first verify condition 1. We start by examining the sequence of covariance estimates \(\varGamma ^{(k)}\).
Lemma 1
Assume a noisy asset price is observed at least one time for each asset for \(t>1\) and that \(\tilde{I}(t) \ne 0\) for all t. Let \(\varGamma ^{(k)}\) be a sequence of solutions obtained with Algorithm 1, where \(\varGamma ^{(0)}\) is positive definite. Then sequences \(\varGamma ^{(k)}\) and \(\frac{1}{s^{(k)}}\) are bounded where \(s^{(k)}\) is the minimum eigenvalue of \(\varGamma ^{(k)}\). In addition the sequence \(\sigma _{o,i}^{2,(k)}\) is bounded below and above by positive values for all i.
Proof
Since \(W_{o}\) is positive definite we have from Eq. (9) that \(s^{(k)}\) is bounded below by a positive constant which implies \(\frac{1}{s^{(k)}}\) is bounded. Similarly by Eq. (10) we have \(\sigma _{o,i}^{2,(k)}\) is bounded below by a positive constant. To prove that \(\varGamma ^{(k)}\) is bounded we note that the posterior may be written as
where \(C_{1}\) is a constant not dependent on \(\theta \) and where \(C_{2} = C_{1}\sup _{\theta }p(\theta )\). Note that \(C_{2} < \infty \).
For \(t>1\) each of the conditional distributions \(p(y(t)|y(1:t-1),\theta )\) is a normal distribution with covariance
where for notational simplicity we suppress the dependence of Q(t) and \(P(t|t-1)\) on k. Since \(\sigma _{o,i}^{2}\) is bounded below by a positive value, it follows that \(\frac{1}{|Q(t)|}\) is bounded.
Now suppose that \(\varGamma ^{(k)}\) is unbounded. Then since
\(P(t|t-1)\) is unbounded as k goes to \(\infty \). Since an observation of each asset’s price occurs at least once for \(t>1\) it follows that \(Q(\tau )\) is unbounded (as \(k \rightarrow \infty \)) for some \(\tau >1\). Then since the smallest eigenvalue of \(Q(\tau )\) is bounded below by a positive constant, the determinant of \(Q(\tau )\) is unbounded. Thus a subsequence of \(p(y(\tau )|y(1:\tau -1),\varTheta ^{(k)})\) will approach 0. Since \(\frac{1}{|Q(t)|}\) is bounded, \(p(y(t)|y(1:t-1),\varTheta ^{(k)})\) will remain bounded above for all t. Then using (30) we have
which implies a subsequence of \(p(\varTheta ^{(k)}|y)\) will converge to 0. This contradicts the monotonicity of the ECM algorithm [30]. The proof that the sequence \(\sigma _{o,i}^{2,(k)}\) is bounded above for all i is similar. \(\square \)
Lemma 2
Assume the conditions of Lemma 1. Let \(\lambda (t)^{-1,(k)}\) be a sequence of solutions obtained with Algorithm 1 where \(\varGamma ^{(0)}\) is positive definite. Then there exist finite positive numbers a, b where \(a\le \lambda _{i}(t)^{(k)} \le b\) for all t, k and i.
Proof
By the update equation (14) we may set \(b=\frac{\alpha _{\lambda }+2}{\beta _{\lambda }}\) which is positive and finite. By way of contradiction assume the lower bound does not hold. Then for some i and t there exists a subsequence \(\lambda _{i}(t)^{(k_{n})}\) such that \(\lim _{n \rightarrow \infty } \lambda _{i}(t)^{-1,(k_{n})} =\infty \). Since each \(\lambda _{i}(t)^{-1}\) is the mode of an inverse gamma distribution it follows that the posterior scale parameter,(\(\beta _{\lambda }+|j^{(k_{n})}|\)) goes to infinity . This implies that \(p(\lambda _{i}(t)^{-1,(k_{n})},j_{i}(t)^{(k_{n})}) \rightarrow 0\). Since each prior density function is bounded as \(\lambda _{i}(t) \rightarrow 0\) this implies that \(p(\theta )\) goes to zero, contradicting the monotonicity of the ECM algorithm. Thus there exists an \(a>0\) such that \(\lambda _{i}(t)^{(k)}>a\) for all t, k and i. \(\square \)
Now we prove that the sequences \(J^{(k)}\) and \(D^{(k)}\) are also well behaved.
Lemma 3
Assume the conditions of Lemma 1. Let \(J^{(k)}\) and \(D^{(k)}\) be sequences of solutions obtained with Algorithm 1 where \(\varGamma ^{(0)}\) is positive definite. Then sequences \(J^{(k)}\) and \(D^{(k)}\) are bounded.
Proof
From Lemma 1 the likelihood \(p(y|\theta )\) is bounded above. Recall from the previous lemma that there exists an \(a>0\) such that for all k, \(\lambda _{i}(t)^{(k)} \ge a\). Since the prior density function is bounded above for each parameter it follows that \(\lim _{j \rightarrow \infty } p(\theta ) =0\). This implies \(J^{(k)}\) is bounded by the monotonicity of the ECM algorithm. Since \(\lim _{d \rightarrow \infty } p(\theta ) =0\) it also follows that \(D^{(k)}\) is bounded. \(\square \)
The above lemmas imply the following corollary.
Corollary 1
The sequence \(\varTheta ^{(k)}\) is bounded and all limit points are feasible ( e.g. variance non-zero, positive definite covariance).
Now we derive some additional properties of the limit points of \(\varTheta ^{(k)}\). To do this we shall refer to Zangwill’s convergence theorem [37]. To use Zangwill’s theorem, we first define \(\mathcal {A}\) to be a point to set mapping defined by the ECM algorithm i.e. \(\varTheta ^{(k+1)} \in \mathcal {A}(\varTheta ^{(k)})\). Let us define a solution set, \(\mathcal {S}\), as the set of \(\theta \) such that
By definition \(\theta \in \mathcal {A}(\theta )\) for all \(\theta \in \mathcal {S}\). This along with the monotonicity of the ECM algorithm implies that \(L(\theta )\) is an ascent function, i.e.
Since \(\mathcal {G}(\theta ,\theta ')\) is continuous in both \(\theta \) and \(\theta '\) we have that \(\mathcal {A}\) is a closed mapping. Thus we have the following theorem.
Theorem 1
All limit points of \(\varTheta ^{(k)}\) belong to \(\mathcal {S}\).
Proof
This is a direct consequence of Zangwill’s convergence theorem [37] (also known as the Global convergence theorem [27]). To invoke the theorem we must meet the following conditions
-
\(\varTheta ^{(k)}\) belongs to a compact subset of the feasible solutions
-
\(\mathcal {A}\) is closed
-
There exists a continuous ascent function
All three of these conditions were shown above, thus the theorem follows from Zangwill’s convergence theorem. \(\square \)
Now we show that if \(\theta ' \in \mathcal {S}\) then \(\theta '\) is in some sense a “stationary” point of the log posterior \(L(\theta )=\log p(\theta |y)\).
Theorem 2
Let \(\theta ' \in \mathcal {S}\). Then
and
Proof
To show this we first note that \(L(\theta )\) can be written as [30]
where
From the information inequality we have that \(H(\theta ',\theta ') \ge H(\theta ,\theta ')\) for all feasible \(\theta \). Since \(H(\theta ,\theta ')\) is differentiable with respect to \(\theta \) it follows that
Since \(\nabla _{\theta _{i}}\mathcal {G}(\theta ,\theta ')_{|\theta =\theta '}=0\) for \(i \in {1,2,3,5}\) it follows that
Also since \(\mathcal {G}(\theta ,\theta ')\) and \(H(\theta ,\theta ')\) are convex in j, and \(\theta ' \in \mathcal {S}\), it follows that
which implies
\(\square \)
1.2 B.2 Algorithm 3
Analogous results to Corollary 1 and Theorem 1 may proven for Algorithm 3 using same arguments as Algorithm 1. The following result is analogous to Theorem 2.
Theorem 3
Let \(\theta ' \in \mathcal {S}\) where \(\mathcal {S}\) is the set of fixed points of the Algorithm 3. Then
The proof of this result is the same as Theorem 2.
C Procedure for selecting \(q(\lambda )\)
In this section we outline the method for selecting the distribution \(q(\lambda )\) for a special case of when the prior distribution of volatility of each asset is identical. Suppose the squared volatility of each asset return is inverse gamma distributed with scale c and shape \(\eta \). Let \(\sigma _{v}^{2}\) be distributed as \(IG(c,\eta )\) and be statistically independent of \(\zeta '\) and \(\sigma _{j}^{2}\).
To determine an appropriate prior distribution of \(\lambda \) we first obtain samples of \(\lambda \),
by the performing the following steps
-
1.
For \(k=1, \dots , M_{\lambda }\)
-
2.
Draw independent samples from the distribution of \((\sigma _{v}^{2'},\zeta ',\sigma _{j}^{2'})\). This is relatively straight forward using standard statistical functions due to the independence assumptions.
-
3.
Determine a \(\lambda '\) such that \(\lambda ' \sim _{\sigma _{v}^{2'}} (\zeta ',\sigma _{j}^{2'})\). This can be done via Monte Carlo integration as shown below.
-
For a large number L draw a sample \(v_{1} \dots v_{L}\) from the distribution \(\mathcal {N}(0,\sigma _{v}^{2})\).
-
Compute \(P_{i}=Pr(J=0|J+V=v_{i})\), where \(J \sim SpikeSlab(\zeta ',\sigma _{j}^{2'})\). The value of \(P_{i}\) is
$$\begin{aligned} \frac{ \frac{\zeta '}{\sqrt{\sigma _{v}^{2'}}}\exp (-v_{i}^{2}/(2\sigma _{v}^{2})) }{\frac{\zeta '}{\sqrt{\sigma _{v}^{2'}}}\exp (-v_{i}^{2}/(2\sigma _{v}^{2'})) + \frac{1-\zeta '}{\sqrt{\sigma _{v}^{2'}+\sigma _{j}^{2'}}}\exp (-v_{i}^{2}/(2( \sigma _{v}^{2'}+\sigma _{j}^{2'})))}. \end{aligned}$$ -
Compute the simulated empirical mean \(\bar{P}=\frac{1}{L}\sum _{i=1}^{L} P_{i}\).
-
Choose \(\lambda '\) such that (5) is satisfied with \(\mathbb {E}_{p(y_{2}|J_{2}=0)}Pr(J_{2}=0|Y_{2})\) approximated as \(\bar{P}\). This value is given below
$$\begin{aligned} \lambda ' =\frac{\text{ erf }^{-1}(\bar{P})\sqrt{2\sigma _{v}^{2'}}}{\sigma _{v}^{2'}} \end{aligned}$$where \(\text{ erf }^{-1}()\) is the inverse error function.
-
-
4.
Set \(\tilde{\lambda }_{k}=\lambda '\)
-
5.
Goto step 1
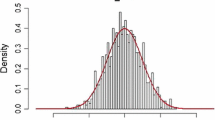
Examples of histograms of samples obtained using the above procedures are shown in Fig. 5. Once we obtain samples of \(\lambda \) we fit a smooth distribution to the sampled data. Since the gamma distribution is a conjugate prior to the Laplace distribution a gamma distribution is a convenient choice for \(q(\lambda )\). Furthermore examination of Fig. 5 indicates that a gamma distribution is a reasonable approximation. Thus we choose
where \(\varGamma _{f}()\) is the gamma function. Here \(\alpha _{\lambda }\) and \(\beta _{\lambda }\) can be selected using maximum likelihood or method of moments.
Since \(q(\lambda )\) develops a singularity near zero for large values of \(\beta _{\lambda }\) we shall impose a prior of \(\lambda ^{-1}\) rather than \(\lambda \). We denote this prior as \(q_{inv}(\lambda ^{-1})\). Since \(\lambda \) is gamma distributed with shape \(\alpha _{\lambda }\) and rate \(\beta _{\lambda }\) it follows that \(q_{inv}(\lambda ^{-1})\) is the inverse gamma distribution with shape \(\alpha _{\lambda }\) and scale \(\beta _{\lambda }\)

Normalized histograms of \(\lambda \) samples. In all experiments \(\sigma _{j}^{2} \sim IG(10,0.0011)\), \(\zeta \sim \text{ Beta }(5,1.0201)\), \(\sigma _{v}^{2} \sim IG(5,\beta _{v})\)
Rights and permissions
About this article

Cite this article
Ho, M., Xin, J. Sparse Kalman filtering approaches to realized covariance estimation from high frequency financial data. Math. Program. 176, 247–278 (2019). https://doi.org/10.1007/s10107-019-01371-6
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10107-019-01371-6