
Abstract
Micro-structural analyses are an important tool to understand material behavior on a macroscopic scale. The analysis of a microstructure is usually computationally very demanding and there are several reduced order modeling techniques available in literature to limit the computational costs of repetitive analyses of a single representative volume element. These techniques to speed up the integration at the micro-scale can be roughly divided into two classes; methods interpolating the integrand and cubature methods. The empirical interpolation method (high-performance reduced order modeling) and the empirical cubature method are assessed in terms of their accuracy in approximating the full-order result. A micro-structural volume element is therefore considered, subjected to four load-cases, including cyclic and path-dependent loading. The differences in approximating the micro- and macroscopic quantities of interest are highlighted, e.g. micro-fluctuations and stresses. Algorithmic speed-ups for both methods with respect to the full-order micro-structural model are quantified. The pros and cons of both classes are thereby clearly identified.
Similar content being viewed by others


1 Introduction
In recent years the use of composite or multi-phase, high performance steels and hybrid materials in advanced structures has increased significantly. Due to the ability to tailor their mechanical properties, these materials are applied in high-tech systems and structures where optimal material properties such as a high strength to weight ratio are essential. To achieve these excellent properties, the underlying microstructures in these heterogeneous materials tend to become increasingly complex, with strongly non-linear behavior of the constituents.
As a consequence, the material testing procedures have become intricate, time-consuming and expensive. The number of required experiments can be reduced drastically by reliable modeling of the material behavior. Computational homogenization is one of the most accurate modeling techniques currently available to analyze and design the material behavior of heterogeneous materials on a structural scale. Microstructures of heterogeneous materials can be modeled adequately, but it remains a computationally demanding problem when applied on materials with a large scale separation between the structural dimensions and the dimensions of the material heterogeneities.
The early concepts of computational homogenization were introduced by Suquet [1] and extended and refined by several authors over the years, e.g. Renard and Marmonier [2], Guedes and Kikuchi [3] and Terada and Kikuchi [4]. The framework captures the behavior on the macroscopic scale by solving a boundary value problem on a representative volume element of the microstructure of the material. Smit et al. [5] adapted the framework to account for large deformations and rotations. Miehe et al. [6] combined this framework with a crystal plasticity material model to study texture development in polycrystalline metals. By means of a volume averaging technique, the homogenized relations between stress, stiffness and strain can be found [7]. Feyel and Chaboche modeled a SiC/Ti composite material using computational homogenization in [8], where the term FE\({}^2\) was coined for the first time. A second-order computational homogenization framework which inherently accounts for the size of the microscale model was proposed by Kouznetsova et al. [9]. More recently, computational homogenization has been used in various fields to analyze the material behavior, such as acoustics [10], composites [11] among many other fields. A detailed overview of the advances in computational homogenization is presented by Geers et al. [12] and Matouš et al. [13].
The common denominator in the aforementioned models is that the material behavior on the macroscale is obtained from a detailed model of the microstructure of the material. When the microscopic model is sufficiently large and detailed to accurately capture the homogenized behavior of the material it is referred to as a representative volume element (RVE). In solving a macroscopic problem one can use the computationally homogenized model of the representative volume element or in materials design analysis one can use the RVE to analyze the resulting macroscopic response of different microstructures. This requires the same microscopic RVE problem to be resolved numerous times for different load-cases.
One approach to decrease the required computation time is to increase the efficiency of solving the microscopic system of equations, Michel et al. [14] used a Fast-Fourier Transform to reduce the computational costs of solving a stress-controlled microscopic problem. Another approach is to reduce the number of unknowns of the microscopic model. This can be achieved by using a more suitable global basis to solve the problem as done using a classical Rayleigh-Ritz technique [15].
This reduced order modeling technique was originally proposed in the late 70’s begin 80’s with Almroth et al. and Noor et al. [16, 17]. The global basis is generated a-priori from a local basis using Proper Orthogonal Decomposition (POD) [18] going back to the works of Pearson [19] and Schmidt [20]. Variants to this technique are known as principle component analysis (PCA) [21], Karhunen–Loève transform (KLT) [22, 23], proper orthogonal eigenfunctions [24], factor analysis [25] and total least squares [26]. The procedure of finding the global basis is strongly related to the singular value decomposition [26].
The number of global basis functions required to capture the solution accurately is typically orders of magnitude smaller than the number of local basis functions used in classical discretization techniques such as the Finite Element Method. Rewriting the problem onto the global basis reduces the size of the algebraic system of equations that needs to be resolved at every iteration. A detailed overview of the advances in reduced order modeling is presented in [27] and [28].
As pointed out by Rathinam and Petzold [29] the reduction of the number of degrees of freedom does not necessarily result in a reduction of the computational costs as the integration of the nonlinear terms in the model is not tackled by the reduced basis approach. To resolve the high computational costs of evaluating the nonlinear integrand, a number of methods have been proposed, such as Proper Generalized Decomposition [30], which reduces the costs through separation of variables. Transformation Field Analysis is another semi-analytical approach, introduced by Dvorak [31], in which the computational costs of the FE\({}^2\) scheme are reduced by assuming constant plastic strain fields. The method was later extended by Michel and Suquet [32] to account for non-uniform plastic strain fields. As pointed out by Hernández et al. [33], hyper-reduction techniques can be divided into two categories; (1) models reducing the costs by interpolation of the nonlinear terms, i.e. Empirical Interpolation Methods (EIM) and (2) models reducing the costs of the integration scheme, minimizing the number of evaluations of the non-linear term required, i.e. Cubature Methods.

Outline of the macro- and microscopic problem
Empirical interpolation of the nonlinear stress is done by projecting locally sampled values, also known as gappy data, onto a basis for the nonlinear term. The reconstruction of gappy data using modes is pioneered by Everson and Sirovich [34] from which several techniques originated such as the Empirical Interpolation Method [35], and later the Best Point Interpolation Method (BPIM) [36], Missing Point Estimation (MPE) [37], Discrete Empirical Interpolation Method (DEIM) [38]. A comparison between different interpolating methods is given by Soldner et al. [39]. This review considers a geometrically non-linear hyper-elastic RVE which is reduced using three hyper-reduction methods, namely Discrete Empirical Interpolation Method (DEIM), Gappy-POD and Gauss-Newton with Approximated Tensors (GNAT). The focus of the review by Soldner et al. lies on the robustness of the methods.
On the other hand, cubature methods reduce the cost of the integration of the nonlinear integrand by using a reduced set of integration points (or elements) with weights that minimize the integration error. The first cubature method was proposed by An et al. [40] and later Farhat et al. [41] introduced the Energy-Conserving Sampling and Weighting (ECSW) hyper reduction method in the field of computational mechanics.
This paper studies the accuracy and efficiency of hyper-reduction techniques in the context of microstructural volume element analysis. To this purpose, a detailed comparison will be made between the Empirical Interpolation Method on the one hand and the Cubature Method on the other hand. We will compare two specific implementations of these methods, namely the High-Performance Reduced Order Modeling technique (HP-ROM) [42] and the Empirical Cubature Method [33], respectively. Both implementations are selected for their capability to handle the singularities arising when hyper-reduction techniques are applied to microstructural models loaded through macroscopic prescribed fields.
In this comparison emphasis is given on the reduction of the computational costs of evaluating the nonlinear stress, the efficiency in terms of computational time and accuracy in resolving the RVE problem. In particular, this comparison will focus on the path-dependency originating from the elasto-viscoplastic material behavior.
The paper is organized as follows. In Sect. 2, a small-strain computational homogenization procedure is outlined, after which the standard Reduced Order Modeling approach is introduced in Sect. 3. In Sect. 4 the two classes of hyper-reduction will be explained briefly. The core of this paper is the evaluation of different hyper-reduction methods to resolve the expensive computation of the stress field, as presented in Sect. 5. The conclusions will be presented in Sect. 6.
2 Computational homogenization
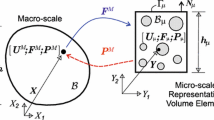
In this section, the two-scale computational homogenization procedure will be outlined briefly. In the computational homogenization framework a high-fidelity problem at the macroscopic length scale \(l_\mathrm{M}\) involving microscopic details with a characteristic length scale \(l_\mathrm{m}\ll l_\mathrm{M}\) is decomposed into two boundary value problems at separate scales, as schematically depicted in Fig. 1. By decomposing the problem into a micro- and macroscale problem, the numerical costs of solving the full-scale problem are reduced drastically.
At the macroscale, where the variables and fields are denoted by subscript \(\mathrm{M}\), the constitutive behavior is derived from the homogenized response of a Representative Volume Element living at the microscale. Computational homogenization is easily formulated as a deformation driven problem, i.e. the RVE is loaded with a deformation tensor from a macroscopic point, where the resulting stress tensor is required. Using a Hill–Mandel based homogenization procedure, the macroscopic stress can be derived from the microscopic stress-field of the RVE. The macroscale problem, the microscale problem and the coupling will be outlined subsequently.
2.1 Macroscale problem
The macroscopic problem is defined as a material body \(\mathcal {V}_\mathrm{M}\) which consist of a heterogeneous material with a particular microstructure. A material point at the macroscopic scale is described by its position vector \({\mathbf {X}}(t)\). The position vector on the reference configuration at time \(t= 0\) is denoted as \({\mathbf {X}}_0\). In a small-strain framework the motion of a material point over time can be described by
in which \({\mathbf {u}}= {\mathbf {u}}({\mathbf {X}}_0, t)\) is the displacement vector. Assuming small-strain kinematics, the strain at the macroscale, \({\mathsf {\varepsilon }}_\mathrm{M}= {\mathsf {\varepsilon }}_\mathrm{M}({\mathbf {X}}_0, t)\) is then defined as
Static equilibrium at the macroscale implies
where the stress tensor \({\mathsf {\sigma }}_\mathrm{M}({\mathsf {\varepsilon }}_\mathrm{M}, {\mathbf {\xi }})\) depends on the strain tensor \({\mathsf {\varepsilon }}_\mathrm{M}\) and the history parameters \({\mathbf {\xi }}\). The body forces are denoted by \(\mathbf {b}\). The macroscopic stress \({\mathsf {\sigma }}_\mathrm{M}\) is obtained from the RVE problem through the micro-macroscale transition.
2.2 Microscale problem
To characterize the microstructure of the material a Representative Volume Element \(\mathcal {V}_\mathrm{m}\) is defined. The position of a material point in the RVE over time is described by \({\mathbf {x}}(t)\). The reference configuration at \(t= 0\) is denoted by \({\mathbf {x}}_0\). The displacement of a material point over time is a superposition of the displacement induced by the macroscopic deformation \({\mathsf {\varepsilon }}_\mathrm{M}\cdot {\mathbf {x}}_0\) and the microscopic fluctuation \({\mathbf {w}}= {\mathbf {w}}({\mathbf {x}}_0, t)\),
The microscopic strain \({\mathsf {\varepsilon }}_\mathrm{m}\) is then given by
The influence of the body forces is assumed to be negligible at this scale, such that the linear momentum balance of the RVE simplifies to
where \({\mathsf {\sigma }}_\mathrm{m}= {\mathsf {\sigma }}_\mathrm{m}({\mathsf {\varepsilon }}_\mathrm{m}, {\mathbf {\xi }})\) is the microscopic Cauchy stress and \({\mathbf {\xi }}\) are the history variables required for the constitutive relation.
2.3 Coupling of the scales
The homogenization is based on two principles. The first principle is the volume average of the stress or the strain, which should match the macroscopic strain and stress respectively.
The second principle is the Hill–Mandel condition [43] which prescribes that the virtual work performed per unit volume at the macroscale should equal the volume average of the virtual work at the microscale.
It has been shown that periodic boundary conditions on the microfluctuation field \({\mathbf {w}}^+ = {\mathbf {w}}^-\) comply with these homogenization equations. To discriminate rigid body displacements and rotations, the microfluctuations on the corners of the RVE \(\mathcal {S}_\mathrm{m}\) are constrained by \({\mathbf {w}}= \mathbf {0}\). The macroscopic stress \({\mathsf {\sigma }}_\mathrm{M}\) is then given by volume averaging the microscopic stress \({\mathsf {\sigma }}_\mathrm{m}\) and the macroscopic tangent stiffness can be deduced using, for example, direct condensation [44].
2.4 Spatial discretization
Both the macroscopic and microscopic problems, Eqs. (3) and (6) can be put in the weak form by following the Bubnov–Galerkin approach. Integrating these equations with test-functions \({\mathbf {\phi }}_\mathrm{M}({\mathbf {X}}_0)\) and \({\mathbf {\phi }}_\mathrm{m}({\mathbf {x}}_0)\) respectively and application of the divergence theorem, yields:
Both the macro- and microscopic domain are discretized using standard, Lagrangian finite elements. The discretization introduces interpolation functions \(\mathbf {N}_i({\mathbf {X}}_0)\), and nodes for \(i=1,\ldots ,n^\mathrm{d}_\mathrm{M}\) at the macroscale and \(\mathbf {N}_j({\mathbf {x}}_0)\) for \(j=1,\ldots ,n^\mathrm{d}_\mathrm{m}\) at the microscale. Here, \(n^\mathrm{d}_\mathrm{M}\) and \(n^\mathrm{d}_\mathrm{m}\) denote the number of nodes and thereby implicitly define the number of unknowns.
The trial functions \({\mathbf {\phi }}_\mathrm{M}({\mathbf {X}}_0)\) and \({\mathbf {\phi }}_\mathrm{m}({\mathbf {x}}_0)\) are approximated by their discrete counterparts \({\mathbf {\phi }}_\mathrm{M}({\mathbf {X}}_0) \approx {\mathbf {\phi }}^{h}_\mathrm{M}({\mathbf {X}}_0)\), \({\mathbf {\phi }}_\mathrm{m}({\mathbf {x}}_0) \approx {\mathbf {\phi }}^{h}_\mathrm{m}({\mathbf {x}}_0)\). A similar approximation is used for the displacement-field \({\mathbf {u}}({\mathbf {X}}_0) \approx {\mathbf {u}}^{h}({\mathbf {X}}_0)\) and the microfluctuation field \({\mathbf {w}}({\mathbf {x}}_0) \approx {\mathbf {w}}^{h}({\mathbf {x}}_0)\).
where \({\mathbf {w}}^{h}({\mathbf {x}}_0)\) is constrained using periodic boundary conditions on the RVE’s boundary and vanishing at the corners. The macroscopic problem takes conventional boundary conditions, e.g. displacements \({\mathbf {u}}^{h} = {\mathbf {u}}^*\) or tractions \({\mathsf {\sigma }}_\mathrm{M}\cdot \mathbf {n}= \mathbf {t}^*\). The Newton-Raphson method is used to solve the resulting equilibrium Eqs. (7) and (8).
2.5 Computational size and cost of the problem
Applying computational homogenization to a high-fidelity problem with ample microscopic details entails a significant increase of the required time and computational resources. Despite the reductions achieved by the homogenization procedures, the size of the macroscopic problem that can be computed within a feasible amount of time and computational resources is still limited for RVEs with nonlinear constituents.
The term FE\({}^2\) by Chaboche illustrates the computational difficulty of the homogenization problem. An RVE needs to be resolved in every integration point at the macroscale. The amount of iterations required to solve the momentum balance on the macro- and the microscale is denoted by \(n^\mathrm{it}_\mathrm{M}\) and \(n^\mathrm{it}_\mathrm{m}\) respectively. The number of Degrees of Freedom (DOF) on the macro- and the microscale are denoted by \(n^\mathrm{d}_\mathrm{M}\) and \(n^\mathrm{d}_\mathrm{m}\) respectively. For a nonlinear RVE, the required amount of floating point operations (FLOPs) to solve the matrix-vector equations are given by
in which \(\#^\mathrm{flop}_\mathrm{LA}\) is the number of required FLOPs to solve the matrix-vector systems in the homogenization problem.
The same scaling relation of the number of floating point operations holds for the number of evaluations of the ordinary differential equation in the material model. The ordinary differential equation in the material model has to be solved in every integration point at the microscale. The number of integration points on the macro- and microscale are denoted by \(n^\mathrm{g}_\mathrm{M}\) and \(n^\mathrm{g}_\mathrm{m}\) respectively. The number of FLOPs associated with solving the material model is proportional to the number of integration points and iterations
in which \(\#^\mathrm{flop}_\mathrm{mat}\) is the number of required FLOPs to solve the material models used in the RVE. The total number of calculations is then given by
The computational costs associated with FE\({}^2\) problems are quantitatively illustrated using a straightforward example. Let’s consider a micro-structural element that is discretized with a grid of \(100 \times 100\) quadrilateral elements with 4 integration points per element, yielding \(n^\mathrm{g}_\mathrm{m}\approx 40000\) and \(n^\mathrm{d}\approx 80000\). When the macroscopic problem is of the same dimension and an assumed average of 4 iterations in the Newton-Raphson procedures, the number of FLOPs per time increment required to solve the matrix-vector systems \(\#^\mathrm{flop}_\mathrm{LA}\) is in the order of \( \mathcal {O}\left( {10^{11}}\right) \) and the number of FLOPs associated with solving the nonlinear material model \(\#^\mathrm{flop}_\mathrm{mat}\) is in the order of \( \mathcal {O}\left( {10^{10}}\right) \).
3 Reduced order modeling
As shown in the previous section, the computational cost of the homogenization scales with the number of DOFs \(n^\mathrm{d}_\mathrm{M}\) and \(n^\mathrm{d}_\mathrm{m}\) and the number of integration points \(n^\mathrm{g}_\mathrm{M}\) and \(n^\mathrm{g}_\mathrm{m}\). By reducing the amount of DOFs of the RVE problem, the costs of solving the matrix-vector equations in the computational homogenization problem will decrease proportionally.
Using a reduced basis, the finite element discretization is mapped onto a global basis. In most physical problems this yields a significant reduction of the required number of DOFs \(n^\mathrm{d}_\mathrm{m}\) since the problem will have considerably less physical modes for the kinematics then the number of local basis functions required to capture all the local features. Reduced Order Modeling using the Reduced Basis technique is outlined in Sect. 3.1.
After the reduction of the number of DOFs the number of integration points \(n^\mathrm{g}_\mathrm{m}\) is still equivalent to the original problem. The reduction of the integral is done using High-Performance Reduced Order Modeling or Empirical Cubature, outlined in Sect. 4.
3.1 Reduced basis approach
The number of DOFs \(n^\mathrm{d}\) scales with the spatial resolution of the mesh. The number of kinematic modes \(n^{w}\) present in the RVE is independent of the spatial resolution. Moreover, many modes have a negligible contribution. When discretizing the RVE, without prior knowledge, the number of DOFs used to accurately capture these kinematics is relatively high with respect to the relevant number of relevant modes.
If there is prior knowledge of the kinematics occurring in the RVE, it is possible to construct a basis that captures the kinematics more efficiently with a limited number of DOFs. Since Computational Homogenization often involves repetitive calculations of an RVE, it calls for an additional optimization step. The extra computational costs for identifying a Reduced Basis for the problem are justified by the higher costs for solving the RVE multiple times.
To find a more optimal basis for the microscale problem, prior knowledge of the relevant kinematics needs to be obtained. This is done by repetitively solving the RVE-problem under different macroscopic strains \({\mathsf {\varepsilon }}^i_\mathrm{M}(t_j)\) for \(i = 1,\ldots , n^\mathrm{\ell }\) and \(j = 1,\ldots , n^\mathrm{t}\) to gather a database with snapshots of the occurring microfluctuation fields. Here, each separate time-step of each load-case is considered as a snapshot, which is numbered as k. In total there are \(n^\mathrm{s}= n^\mathrm{\ell }\cdot n^\mathrm{t}\) snapshots of the microfluctuation field. The snapshot of the microfluctuation field \({\mathbf {w}}^{h}_k({\mathbf {x}}_0)\) is then expressed by
Equation (9) can be rewritten as a matrix-vector equation where the snapshots are collected in the so-called snapshot-matrix \(\underline{\underline{\mathfrak {X}}} \in \mathbb {R}^{n^\mathrm{s}\times n^\mathrm{d}}\) in which \(\left. \underline{\underline{\mathfrak {X}}} \right| _{kl} = { {w} } _{kl}\).
An orthonormal basis is derived from the snapshot matrix \(\underline{\underline{\mathfrak {X}}}\) using the Proper Orthogonal Decomposition (POD). This mathematical procedure provides the most optimal basis (in the least-square sense) to represent the snapshots in combination with their corresponding eigenvalue \(\lambda _i\) Footnote 1. The eigenvalues denote the energy-content of their corresponding eigenmodes \(\underline{v}_i\) in representing the modes of the DOF.

Outline of the proper orthogonal decomposition
Based on their eigenvalues the most important modes can be selected to construct a Reduced Basis for the microscale problem. The eigenvalues and their corresponding eigenvectors are sorted in descending order, allowing to construct the basis from the first \(n^{w}\) eigenvectors. The required number of modes to capture the snapshot up to a given tolerance \(\delta \in [0,1]\) is found by increasing \(n^{w}\) until the following relation holdsFootnote 2
The Proper Orthogonal Decomposition is outlined schematically in Fig. 2.
3.2 Construction of the reduced order model
After determining the number of required modes \(\underline{\underline{V}} = [ \underline{v}_1,\underline{v}_2, \ldots , \underline{v}_{n^{w}}]\) the reduced basis functions \(\mathbf {R}_l({\mathbf {x}}_0)\) can be constructed as a linear combination of the traditional basis functions \(\mathbf {N}_m({\mathbf {x}}_0)\) using the modes \(\underline{v}_l\) resulting from the POD.
Using a Galerkin approach for discretizing the reduced system, the test and trial functions are discretized using the reduced basis
which \({\varPhi }_j\) and \({W}_i\) are the reduced test and microfluctuation coefficients. Substituting the reduced functions into the weak formulation of the microscopic momentum balance (8) the following reduced internal force \(\bar{f}^\mathrm{int}\) is found
with \(i = 1,\ldots , n^{w}\) and \(\underline{{W}}\) the reduced vector with unknowns \([{W}_1, {W}_2, \ldots , {W}_{n^{w}}]^T\) used to discretize the microfluctuation field. The number of modes \(n^{w}\) is often orders of magnitude smaller than the number of DOFs \(n^\mathrm{d}\). The linear momentum balance is solved using the same Newton-Raphson procedure for the microscale problem. The computational costs for solving the system of equations scales proportionally to the number of microfluctuation modes \(n^{w}\).
After reducing the number of microfluctuation DOFs, the computational costs for solving the RVE problem are determined by the solution of the material-model. Due to the nonlinear character of the internal force, the integral in equation (13) can not be precomputed. This procedure remains computationally expensive since the material model needs to be resolved on each integration point to compute the integral of the internal force.
4 High-performance reduced order modeling
In this section two approaches to reduce the costs of evaluating the nonlinear internal force are reviewed:
-
1.
The Empirical Interpolation Method (EIM) [42] projects the nonlinear term onto a reduced basis for the stress field. The stress field is approximated by the reduced modal basis, enabling pre-computation of the integral.
-
2.
Alternatively, the integration scheme can be reduced directly. This approach is known in literature as Energy-Conserving Sampling and Weighting (ECSW) hyper reduction method or Empirical Cubature Method (ECM) [33]. The integration costs are reduced by using a preselected subset of sampling points and assigning a positive weighting factor to them.
4.1 Empirical interpolation method
In the Empirical Interpolation Method, the stress field is approximated by interpolating between weighted stress modes \(\varPsi ^j({\mathbf {x}}_0)\) dependent on the microscopic coordinates, which are scaled by the coefficients \(C^j({\mathsf {\varepsilon }}_\mathrm{M}, {\mathbf {\xi }})\) that depend on the macroscopic deformation \({\mathsf {\varepsilon }}_\mathrm{M}\) and material point history \({\mathbf {\xi }}\). The advantage of introducing modes for the stress-field is that the integration of these modes can be performed in the off-line stage since the interpolating coefficients no longer have a spatial dependency.
The weighted strain modes \(\varPhi ^k({\mathbf {x}}_g)\) are constructed by taking the symmetric gradient of the micro-fluctuation modes weighted by the square-root of the integration weight (including the Jacobian). The weighted stress modes \({\mathsf {\mu }}^k({\mathbf {x}}_g)\) are obtained from the square-root weighted stress snapshot matrix \(\underline{\underline{\mathfrak {X}}}_{{\mathsf {\sigma }}}\). The orthogonal weighted stress-basis can be obtained by applying a standard POD procedure on the vectorized components of the sampled stresses or by using a tensorial decomposition such as the procedure outlined by Roussette et al. [45].
The square-root weighted stress and strain can be approximated as
Substituting the stress basis (14) into the reduced order model (12) after applying Gaussian quadrature to calculate the integral leads to the following expressions for the internal force vector.
The modal coefficients \(C^j({\mathsf {\varepsilon }}_\mathrm{M}, {\mathbf {\xi }})\) are to still be determined for the current strain state. The stress modes are weighted by selecting a set of integration points as sampling points and applying a Least-Square fitting such that the error between these points and the approximated stresses will be minimized in the Least-Squares sense.
4.1.1 Reformulation of the ill-posed stress–strain problem
The stress- and strain basis are composed out of stress- and strain-fields resulting from the converged linear momentum balance (8). This leads to an ill-posed system of equations since the reduced linear momentum balance (18) constructed using the modal bases for the stress- and strain fields is in equilibrium regardless of the coefficients \(\underline{C}_{{\mathsf {\sigma }}}\), as stated in [42].
In order to solve this problem, the Expanded Basis Approach (EBA) is applied, where the stress-basis \(\varPsi \) and corresponding coefficients \(\underline{C}_{{\mathsf {\sigma }}}\) are enriched with the weighted strain basis \(\varPhi \) and corresponding (inadmissible) coefficients \(\underline{C}_{{\mathsf {\varepsilon }}}\), such that the basis does not satisfy equilibrium independently of the coefficients \(\underline{C}_{{\mathsf {\sigma }}}\).
By rewriting the strains and stresses in Voigt notation, the tensorial bases \(\varPsi \) and \(\varPhi \) are reformatted into the matrix formats \(\underline{\underline{\varPsi }}\) and \(\underline{\underline{\varPhi }}\) respectively. An example of this procedure is illustrated for a set of two-dimensional strain modes:
The gappy stress basis \(\hat{\underline{\underline{\varPsi }}}\) is formed by selecting all the rows corresponding to the selected integration points \({\mathbf {x}}_g\) for \(g \in \mathcal {I}\) where \(\mathcal {I}\) is the set with selected integration point indices.
The coefficients for the expanded basis (19) \(\underline{C} = [ \underline{C}^T_{{\mathsf {\sigma }}}, \underline{C}^T_{{\mathsf {\varepsilon }}} ]^T\) are identified from a set of \(\hat{n}^\mathrm{g}\ll n^\mathrm{g}\) sampled gappy stresses in Voigt notation \(\hat{\underline{ { \sigma } }}\) to approximate the stress in the Least-Squares sense using:
Using the Schur complement, the coefficients \(\underline{C}\) can be expressed by
in which the matrix \(\hat{\underline{\underline{\varPsi }}}^\dag \) is the pseudo-inverse of the gappy-stress basis matrix and \(\underline{\underline{S}}\) is Schur’s complement matrix defined by
Matrix \(\underline{\underline{S}}\) is invertible since the sampled stressed are chosen such that \(\hat{\varPsi }^{\mathrm{ex}}\) is of full rank. The problem can be rewritten into finding a solution for which the inadmissible coefficients vanish, i.e. \(\underline{C}_{ { \varepsilon } } = \underline{0}\), such that the stress solution is interpolated using only stress basis vectors in equilibrium. Since \(\underline{\underline{S}}\) is non-singular, as shown by [42], the coefficients can only be \(\underline{0}\) when the following holds:
This form of the problem is referred to as the hyper-reduced problem [42].
4.1.2 Gappy point selection
To complete the hyper-reduced model a set of integration points \({\mathbf {x}}_g\) for which \(g \in \mathcal {I}\) suitable for the Empirical Interpolation of the stress field is chosen. This is done by using the snapshots of the stress field as samples to find a set of integration points that yield a good approximation of the complete stress-field. It is computationally intractable to evaluate the approximative qualities of the subset of integration points for all \(\genfrac(){0.0pt}1{n^\mathrm{g}}{\hat{n}^\mathrm{g}}\) possible combinations. Therefore the sub-optimal Greedy algorithm is applied to find a set of integration points which has a good interpolating quality for the snapshot data [42].
To improve the stability of the system of equations, the selected points are complemented with a second set of points selected from the remaining integration points. These points are selected using the Greedy algorithm using a criterion that aims at optimizing the conditioning of the resulting reduced tangent stiffness matrix.
Accuracy points Hernández et al. [42] select the integration points based on minimizing the error between the stress snapshots \({\mathsf {\sigma }}^j\) and the interpolated stress \({\mathsf {\sigma }}^*_j(\varPsi , \mathcal {I})\) constructed using the subset of integration points \({\mathbf {x}}_g\) with \(g \in \mathcal {I}\). The error in the stress approximation is given by
which is split up by Hernández et al. [42] into a truncation error that represents the error introduced due to the use of a reduced stress basis and a reconstruction error \(\epsilon ^\mathrm{rec}\). The reconstruction error measures the error introduced by the Least-Squares fit of the stresses onto the modal basis, which is given by
This error measure is used to select the integration points that are best suited for an accurate stress interpolation.
Stability points Hernández reported that using integration points that are only selected on the basis of accuracy, provides a system of equations that is not unconditionally stable. Therefore, the set of selected integration points needs to be complemented with a set of extra points to ensure the stability of the system. The same Greedy selection procedure is used with a criterion that aims to optimize the positive-definiteness of the tangent stiffness matrix. To ensure maximum stability, the criterion given in [42] that needs to be minimized reads
This yields a second set of integration points in favor of the stability of the Empirical Stress Interpolation.
4.1.3 Reconstruction of the reduced stress field
The resulting weighted stress field in the RVE is given by the Empirical Interpolation (17). The coefficients \(\underline{C}_{ { \sigma } }\) can be found using the expression (21) by substituting \(\underline{C}_{ { \varepsilon } } = 0\).
where \(\underline{\underline{R}}\) is referred to as the weighted reconstruction matrix.
To reconstruct the macroscopic stress, the reconstructed stress-field \({\mathsf {\sigma }}_\mathrm{m}({\mathbf {x}}_g, t)\) has to be integrated over the RVE and volume averaged. The relation between the gappy-stress and the macroscopic stress is then given by the following linear operator:
which projects the gappy stresses \(\hat{\underline{ { \sigma } }}\) onto the macroscopic stress \(\underline{ { \sigma } }_\mathrm{M}= \underline{\underline{T}} \hat{\underline{ { \sigma } }}\).
4.2 Empirical cubature method
Instead of approximating the stress field using a Proper Orthogonal Basis constructed from the stress snapshots, the expensive integral of the internal forces can be approximated using the Empirical Cubature Method.
For a polynomial FEM basis one can construct an exact quadrature scheme. This classical Gaussian quadrature scheme approximates the integral summing up weighted samples of the integrand at specific points, the Gauss integration points
where \(w_g\) denote the Gaussian quadrature weights (including the determinant of the Jacobian).
When rewriting the problem using the reduced-order basis to (12) one can imagine that it is possible to reduce the integration as well since the number of unknowns describing the integrand has decreased drastically. The underlying idea of the reduced integration is to select a subset of integration points and appoint a (positive) weight to them such that they approximate the integral as accurately as possible. This concept is demonstrated in [33, 40, 41].
The method will be outlined briefly in two steps. First the determination of the integration weights is discussed; next the selection procedure for the integration points is presented.
4.2.1 Determining the integration weights
To determine the weights, the internal force contributions at each integration point \(\mathbf {f}_i^p({\mathbf {x}}_g)\) under snapshot \(p = 1,\ldots , n^\mathrm{s}\) resulting from each modal virtual strain \(\mathbf {\nabla }^\mathrm{s}\mathbf {R}_i({\mathbf {x}}_g)\) for \(i = 1,\ldots , n^{w}\) are considered. The modal internal force contributions for each snapshot are collected in a snapshot matrix \(\underline{\underline{\mathfrak {X}}}_{f} \in \mathbb {R}^{n^\mathrm{g}\times n^{w}\cdot n^\mathrm{s}}\).
furthermore the resulting integrals are collected in the right-hand side vector \(\underline{b} = [ \mathcal {F}^1_1, \ldots , \mathcal {F}^1_{n^{w}}, \mathcal {F}^2_1, \ldots , \mathcal {F}^{n^\mathrm{s}}_{n^{w}} ]^T\) in which \(\mathcal {F}^j_i = \int _{\mathcal {V}_\mathrm{m}} f^j_i({\mathbf {x}}) \, \mathrm{d}{\mathcal {V}_\mathrm{m}}\). The integration error for a selected subset of integration points \(\mathcal {G} \subset \lbrace 1, 2,\ldots , n^\mathrm{g}\rbrace \) using the associated integration weights \(\alpha _i\) for \(i \in \mathcal {G}\) is found by
where the matrix \(\underline{\underline{J}}_\mathcal {G}\) is defined by
To find the optimal weights, the following minimization problem has to be solved
in which \(\hat{n}^\mathrm{g}\) integration points need to be selected and their corresponding (positive) integration weights \(\alpha \) need to be determined.
4.2.2 Reformulation of the ill-posed minimization problem
Note that problem (35) is again ill-posed for the case in which the integrals of the internal force fields are all equilibrium solutions of the RVE problem. This yields a right-hand side vector \(\underline{b} = \underline{0}\), therefore the minimization problem (35) yields the trivial solution to the problem \(\underline{\alpha } = \underline{0}\). The ill-posed problem is regularized by integrating an extra function \(g({\mathbf {x}}) = 1\) which needs to result in the volume of the RVE \(|\mathcal {V}_\mathrm{m}|\) [33].
4.2.3 Cubature weights
It is intractable to evaluate all the \(\genfrac(){0.0pt}1{n^\mathrm{g}}{\hat{n}^\mathrm{g}}\) possible combinations. To obtain a good approximation of the minimum a Greedy procedure is applied to select the integration points that are suitable to reduce the integration error. For a given subset of integration points \(\mathcal {G}\) the coefficients \(\underline{\alpha }\) can be determined using a Least-Square (and when negative values occur a Non-Negative Least-Square) algorithm.
The criterion used to identify candidate points, selects the point that is currently most aligned to the residual of the snapshot integrals. This procedure repeats until enough integration points are selected to drop the residual under the required tolerance for the integration accuracy or the maximum number of gappy integration points \(\hat{n}^\mathrm{g}\) is reached.

It is not trivial to reconstruct the microscopic stress field from the sampled stresses as the Empirical Cubature Method does not use stress-modes. One can however follow the approach proposed by [33] to reconstruct the microscopic stress field using the weighted reconstruction matrix \(\underline{\underline{R}}\) for the selected integration points.
4.2.4 Reduced integration of the RVE
The linear momentum balance with reduced internal force (12) is solved by using the Empirical Cubature scheme to resolve the integral. This leads to the following reduced integration scheme
for which the unknown reduced micro-fluctuations \(\underline{{W}}\) can be solved using a Newton-Raphson method.
5 A comparative analysis of EIM versus ECM
To assess the performance of the hyper-reduced models, a critical comparison is made between the empirical models, the reduced order models and the full-order model of a RVE. Focus is put on the suitability for the hyper-reduced models as a stand-in replacement of the complex full-order model of the RVE in a computational homogenization framework. Small plane-strain is assumed in the model of the RVE. The RVE consists of fibers in a soft matrix. The matrix is modeled using a small-strain elasto-viscoplastic material constitutive law of De Souza Neto et al. [46, p. 148]. The fibers are elastic. The difference in stiffness of the fibers and the matrix is chosen to be a factor 10 to replicate a carbon-fiber epoxy bundle. The properties of both phases in the RVE are listed in Table 1.
In which \(E\) is the Young’s modulus, \(\nu \) the Poisson’s ratio, \(\gamma _0\) the initial slip rate, \(n\) the rate exponent, \(\sigma ^{\mathrm{y}}_0\) the initial yield stress, \(H\) the hardening parameter and \(m\) the hardening exponent. A time-increment \(\Delta t= 2.5 \times 10^{-4}\)s is used.

Discretization of the composite microstructure with the fiber and matrix phases. The domain width and height are given by \(L = 2.0\). The RVE contains a total of 30 circular fibers with diameter \(l = 0.20\). The domain consists of 20,206 triangular elements
The dimensions and topology of the composite microstructure are shown in Fig. 3. The topology is meshed using 20,602 bilinear triangular elements and 10,462 nodes. The full-order problem uses 20,602 integration points for integration and 20,924 degrees of freedom to discretize the microfluctuations.
5.1 Snapshot construction
The reduced order models are initialized using an orthogonal set of macroscopic strains (computed off-line). The full-order model results for the microfluctuations and stresses are stored in the snapshot matrix for each time-increment. The loading paths chosen to initialize the model run from 0 to \(0.2 \varepsilon ^\mathrm{eq}_\mathrm{M}\) in 20 steps in the \({\mathsf {\varepsilon }}_{xx}\), \({\mathsf {\varepsilon }}_{yy}\) and \({\mathsf {\varepsilon }}_{xy}\) direction. In this way 60 equilibrium configurations are obtained.
The microfluctuation and stress-modes are determined from the snapshot matrices using POD. The eigenvalues that correspond to these modes are shown in Fig. 4. To investigate the influence of the number of modes taken into account, two reductions are formulated with a different number of modes. The reduced microfluctuation basis is formed out of the \(n^{w}= 10\) and \(n^{w}= 20\) most dominant modes of the POD. In the remainder, these reductions will be denoted as the low- and high-fidelity models, respectively. The same number of modes are used to approximate the stress-field in the empirical interpolation model. In correspondence to Hernández [42], the number of sampling points used for accuracy and stability corresponds to the number of stress- and strain-modes respectively.
To generate the empirical cubature scheme, a cut-off tolerance on the integration error is required. The order of magnitude of the interpolation error is predicted by the sum of the squared eigenvalues of the truncated modes of the stress basis. These interpolation errors \(\delta _1 = 10^{-3}\) and \(\delta _2 = 10^{-4}\) are used as tolerances to cut of the integration point selection algorithm.
In the remainder of this paper, three different techniques will be compared: (1) standard reduced order (with full integration), (2) empirical interpolation and (3) empirical cubature models. A summary of all the specifications of the (Hyper-)Reduced Order Models in terms of modes and sampling points are given in Table 2.

The eigenvalues corresponding to the microfluctuation and stress modes
In order to assess the achieved approximative qualities of the reduced models, the microfluctuations and micro- and macroscopic stresses are compared to the full-order model. In the reduced order model there is no loss of information present during the integration of the stress-field to obtain the internal forces. Therefore, this model can be regarded as the best-approximation for the applied reduced basis and serves as a reference model to investigate the performance of the hyper-reduced models. The achieved time reduction will be evaluated by comparing the CPU-time required to perform the computations to the CPU-time required to solve the original full-order model.
5.2 Uniaxial loading
The accuracy of the empirical methods are first investigated for one of the load-cases used to generate the snapshots (\({\mathsf {\varepsilon }}_\mathrm{M}^{xx}\)). This case serves to highlight the influence of the reduced stress integration in the (hyper-)reduced order models. Note that the modes required to represent the microfluctuation and the stress-fields are then present up to the cut-off tolerance of the POD basis. The effects of the stress-field reconstruction for EIM and integral reconstruction for ECM using gappy sampling on the final deformation and stress fields will therefore be dominant.

The deformed RVE under macroscopic strain \({\mathsf {\varepsilon }}_{\mathrm{M},xx} = 0.2\) resolved with the full-order method (a), EIM (b) and ECM (c). The microfluctuations along line A–B and the relative error \(\epsilon _{w} = \frac{\bar{w}_x - w^\mathrm{FOM}_x}{w^\mathrm{FOM}_x}\) plotted in (d) and (e) respectively
The Representative Volume Element is loaded with a macroscopic strain \({\mathsf {\varepsilon }}^{\mathrm{M}}_{xx}\) from 0 to 0.2 in 20 time-increments (each with the specified time-step \(\Delta t\)). Figure 5 shows the RVEs loaded up to a macroscopic strain of \( { \varepsilon } _{\mathrm{M},xx} = 0.2\). The deformed RVEs solved by the full-order model and the low-fidelity hyper-reduced models are plotted in Fig. 5a–c. Not surprisingly, the essential deformation modes for this case are all captured by the low-fidelity models. The microfluctuation \(w_x\) along the line A–B and the errors, defined as
for the hyper-reduced models, are plotted in Fig. 5d, e respectively. The error of the hyper-reduced RVEs are both of order \( \mathcal {O}\left( {10^{-4}}\right) \) or lower.

Residual fields of the microscopic stress component \({\mathsf {\sigma }}_\mathrm{xx}\) in the loading direction \(\mathrm{xx}\) for the hyper-reduced models w.r.t. the full-order solution. The first row shows the residual for the Lo-Fidelity EIM (a) and ECM (b) models and the second row shows the residual for the Hi-Fidelity EIM (c) and ECM (d) models
Secondly, the errors in the microscopic stress field are analyzed. The stress fields \(\bar{{\mathsf {\sigma }}}({\mathbf {x}})\) resulting from the (hyper-)reduced models are compared to the stress field \({\mathsf {\sigma }}({\mathbf {x}})\) of the FOM model. It should be noted that the local-stress field for the ECM method is obtained by creating the reconstruction operator \(\underline{\underline{R}}\) for the sampled points. The error in the stress in the xx-direction \(\epsilon _{ { \sigma } _\mathrm{xx}}\) is defined as
The stress residuals are depicted in Fig. 6. For both the LoFi and the HiFi model, the EIM method performs better than the ECM method. This difference results from the extra information that the empirical interpolation model uses from the stress-modes. Since these modes contain a lot more spatial details, the stress-field is captured more accurately.
Furthermore, it can be concluded that the error bounds, although they are lower, do not differ significantly between the LoFi and the HiFi models. The volume averaged error in the stress dropped significantly for both models.

Macroscopic stress–strain plot in xx-direction for the full-order model and the low-fidelity reduced order models

Macroscopic stress–strain plot in xx-direction for the full-order model and the high-fidelity reduced order models
The macroscopic stress resulting from full- and (hyper-)reduced order models are plotted in Figs. 7 and 8. For this load-case the resulting macroscopic stresses show no large deviations from the full-order result. Interestingly, the errors plotted on the right hand side, show a clear difference in the EIM and ECM approximation of the macroscopic stress. The EIM approximation follows the error trend of the reduced order model, while the error made by the ECM model is several decades higher than the error of the reduced order model.

Error in the integrated micro-fluctuation fields for the full-order model and the hyper-reduced models
The error in the microfluctuations of the hyper-reduced models (\(\bar{{\mathbf {w}}}\)) relative to the full-order model (\({\mathbf {w}}\)) is plotted in Fig. 9. The error is defined as follows:
The error in the microfluctuation fields decreases with increasing number of strain modes. The reduction in error is however not equal for each increment. The error in the empirical cubature method between \({\mathsf {\varepsilon }}^\mathrm{M}_{xx} = 0.00\) and 0.10 is significantly reduced (where most of the non-linearity is concentrated) by the added modes and integration points.
It is noteworthy that the reduction by the empirical interpolation method seems to outperform the empirical cubature method only to small extent, which is remarkable since the difference in approximation errors of the macroscopic stress for both models differed by several decades.
The computation times for all models are assessed on a single CPU (Intel® Xeon® CPU E5-2667 v3 processor @ 3.20 GHz), without parallelization to keep the comparison clear. The speed-up with respect to the full-order model are presented in Table 3. The speed-up for the ROM model is relatively insensitive to the number of modes used and the gain in computational time is small compared to the full-order model of the RVE. This illustrates the poor performance of classical ROM for non-linear reduced models. The EIM model speeds up between a factor 112 and 123 times. The speed-up in the ECM models are between 73 and 113 times. The ECM model is somewhat slower due to the larger amount of integration points required.

The resulting stresses in xx and yy direction of the full- and reduced-order model of the RVE under biaxial loading

Macroscopic stress–strain curve for biaxial loading in xx and yy direction for strains ranging from \({\mathsf {\varepsilon }}_\mathrm{M}= 0.0\) to 0.2 (left) and the relative error in the von Mises stress \(\sigma ^\mathrm{VM}_\mathrm{M}\) of both hyper-reduced models with respect to the full-order model (right)
5.3 RVE under biaxial loading
A biaxial load is applied next to test the performance of the reduced models under loads not present in the snapshots used to train them. The macroscopic strain is increased to \({\mathsf {\varepsilon }}_\mathrm{M}=\left[ \begin{array}{ll} 0.2, &{} 0.0 \\ 0.0, &{} 0.2 \end{array}\right] \) in 20 equal load-increments.
From the FOM and ECM stress fields presented in Fig. 10, it is clear that all the dominant plastic zones are recovered by the reduced model. The stress–strain curves of the biaxial load-case presented in Fig. 11, indicate that in the linear regime the EIM model outperforms the ECM model. Since the corresponding modes are present, the stress approximation of the interpolating model is more accurate. However, when entering the plastic regime, the ECM model seems to perform at consistent error level, while the error in the macroscopic von-Mises stress predicted by the EIM model increases due to lack of the sampling points required to accurately interpolate the stress modes for this load case.

Macroscopic stress–strain curve for sequential path dependent loading in two directions: first 10 strain increments up to \({\mathsf {\varepsilon }}^\mathrm{M}_\mathrm{xx} = 0.1\) followed by 10 strain increments up to \({\mathsf {\varepsilon }}^\mathrm{M}_\mathrm{xy} = 0.1\)
The cpu-times of the simulations are given in Table 4. The hyper-reduced methods EIM and ECM are 54 and 88 times faster than the full-order method respectively. The difference in speed-up between the empirical interpolation and the empirical cubature method can be explained by the extra gappy points required by ECM to obtain accurate solutions.
5.4 Path dependency
To investigate the sensitivity of both reduced models to history dependent behavior, the models are preloaded with 10 increments of strain in the xx-direction \({\mathsf {\varepsilon }}^\mathrm{M}= \left[ \begin{array}{ll} 0.1,&{} 0.0 \\ 0.0, &{} 0.0 \end{array}\right] \). After preloading the RVE, the model is loaded under shear \({\mathsf {\varepsilon }}^\mathrm{M}= \left[ \begin{array}{ll} 0.0,&{} 0.5 \\ 0.5, &{} 0.0 \end{array} \right] \). The macroscopic von Mises stress at each increment is plotted in Fig. 12.
In the first regime, the EIM model is more accurate than the ECM model due to availability of the correct modes. When entering the shear strain regime at increment 10, the ECM method starts to perform better than the EIM method. The EIM model depends strongly on the stress-modes found during the off-line phase. Since the reduced-model was only trained using RVEs with virgin material without prior loading history, the required modes are not present to accurately capture the path-dependent stress fields. The small dependence on stress modes makes the ECM easier to train. Obviously, strain modes are also different for different loading paths, whereas the modes found in the snapshots include monotonic paths only. For this small-strain model, this mainly effects the stresses, since the ECM does not show a significant drop in accuracy after increment 10.
The speed-up achieved by the (hyper-)reduced models for the path-dependent case is presented in Table 5. The speed-ups achieved during the path-dependent loading are comparable to the speed-up factors found in the biaxial test-case presented in Table 4.
5.5 Cyclic loading
Finally, the behavior of the models under repetitive loading is analyzed. The RVE is exposed to a cyclic load in the xx-direction, shifting its history increasingly further away from its virgin state. The loading direction corresponds to the snapshots, excluding the influence of any interpolation in between different loading directions.

Macroscopic stress–strain curve for cyclic loading in xx direction between strains \({\mathsf {\varepsilon }}^\mathrm{M}_\mathrm{xx} = -0.1\) and 0.1
The stress–strain curve is shown in Fig. 13. The error in between the full-order model and the hyper-reduced models increases slowly over the increments. Due to the single loading direction the difference between the EIM and the ECM method is much less pronounced than in the path dependent case. When switching between tensile and compressive loading, the error shows significant jumps indicating that the unloading stage, which is absent in the off-line initialization stage, is hard to capture for both the ECM and EIM models.
The speed-up achieved by the (hyper-)reduced models for the cyclic load-case are presented in Table 6. Although the runtime of the simulations is longer due to the extra increments, the speed-ups achieved during the path-dependent loading are comparable to the speed-up factors found in the previous test-cases presented in Tables 4 and 5.
6 Conclusions
Both the empirical interpolation method and empirical cubature method yield a significant reduction in computation time and memory footprint compared to traditional ROM. Both models are capable of interpolating between the sampled deformations as shown for the biaxial load-case. When the load-case includes unsampled states of the history parameters, the empirical interpolation method result in errors above 1% for the macroscopic stress with respect to the full-order model. The empirical cubature method is less sensitive to the extrapolation of the snapshot space, since it only depends on the strain modes and not on the stress-modes.
The main asset of the ECM method is that it naturally preserves the stability of the full-order model and therefore does not require the added stabilization needed for the EIM method. However, with the stabilizing integration points added, the EIM models showed good convergence for all the cases demonstrated in Sect. 5, using the (heuristic) criterion of \(n^{w}\) stabilization points suggested in literature.
The empirical cubature method requires more computational time and has a larger memory footprint than the empirical interpolation method due to the extra integration points needed to accurately capture the behavior of the full-order model. The EIM method outperforms the ECM method when on-line computational efficiency is considered due to the extra information it has available in the stress-modes. However, this dependence on stress-modes makes EIM also more vulnerable for ill-sampled path dependent problems, as demonstrated in the path-dependent and cyclic examples.
The largest reduction in required memory and computation time can therefore be achieved using the empirical interpolation method in a computational homogenization setting, due to the smaller amount of memory required to store the history of the sampling. To get accurate results, the high-dimensional snapshot space needs to be sampled sufficiently well such that the paths found in the macroscopic problem can be interpolated sufficiently accurate by the EIM model.
Herein lies an open challenge, since the material model used in the above examples requires 7 history parameters and 3 strain parameters to calculate the macroscopic stress, the sample space of the model is 10 dimensional. It is therefore not trivial to obtain a sufficiently dense sampling of the parameter-space to capture the path-dependent macroscopic stress.
In the considered computational homogenization problems, the microscopic RVE has to be evaluated numerous times in the deformation and history space. It is therefore necessary to construct an accurate yet compact snapshot space. The empirical interpolation method is expected to be sufficiently accurate for many engineering purposes (within 10% error). However, when a higher accuracy is required, ECM methods are more promising since they are less prone to produce large interpolation errors. In problems with a strong path-dependence, it is more straightforward to construct an accurate snapshot space for ECM models.
Notes
Note that the singular values \(\sigma _i\) resulting from singular value decomposition (SVD) are related to the eigenvalues of the proper orthogonal decomposition via \(\sigma _i = \sqrt{\lambda _i}\)
This relation holds only for fluctuation fields that are present in the snapshot matrix.
References
Suquet PM (1985) Local and global aspects in the mathematical theory of plasticity. Plast Today 279–310
Renard J, Marmonier MF (1987) Etude de l’initiation de l’endommagement dans la Matrice d’un matériau Composite par une Méthode d’homogénisation. Aerosp Sci Technol 6:37–51
Guedes JM, Kikuchi N (1990) Preprocessing and postprocessing for materials based on the homogenization method with adaptive finite element methods. Comput Methods Appl Mech Eng 83(1):143–198
Terada N, Kikuchi K (1995) Nonlinear homogenization method for practical applications. ASME Appl Mech Div 212:1–16
Smit RJM, Brekelmans WAM, Meijer HEH (1998) Prediction of the mechanical behavior of nonlinear heterogeneous systems by multi-level finite element modeling. Comput Methods Appl Mech Eng 155(1–2):181–192
Miehe C, Schotte J, Schröder J (1999) Computational micro-macro transitions and overall moduli in the analysis of polycrystals at large strains. Comput Mater Sci 16(1):372–382
Miehe C, Koch A (2002) Computational micro-to-macro transitions of discretized microstructures undergoing small strains. Arch Appl Mech 72(4–5):300–317
Feyel F, Chaboche J-L (2000) FE2 multiscale approach for modelling the elastoviscoplastic behaviour of long fibre SiC/Ti composite materials. Comput Methods Appl Mech Eng 183(3–4):309–330
Kouznetsova VG, Geers MGD, Brekelmans WAM (2002) Multi-scale constitutive modelling of heterogeneous materials with a gradient-enhanced computational homogenization scheme. Int J Numer Methods Eng 54(8):1235–1260
Gao K, van Dommelen JAW, Geers MGD (2017) Investigation of the effects of the microstructure on the sound absorption performance of polymer foams using a computational homogenization approach. Eur J Mech A Solids 61:330–344
Nezamabadi S, Potier-Ferry M, Zahrouni H, Yvonnet J (2015) Compressive failure of composites: a computational homogenization approach. Compos Struct 127:60–68
Geers MGD, Kouznetsova VG, Brekelmans WAM (2010) Multi-scale computational homogenization: trends and challenges. J Comput Appl Math 234(7):2175–2182
Matouš K, Geers MGD, Kouznetsova VG, Gillman A (2017) A review of predictive nonlinear theories for multiscale modeling of heterogeneous materials. J Comput Phys 330:192–220
Michel JC, Moulinec H, Suquet P (1999) Effective properties of composite materials with periodic microstructure: a computational approach. Comput Methods Appl Mech Eng 172(1–4):109–143
Cook RD (1994) Finite element modeling for stress analysis. Wiley, New York, NY
Almroth BO, Stern P, Brogan FA (1978) Automatic choice of global shape functions in structural analysis. AIAA J 16(5):525–528
Noor AK, Peters JM (1980) Reduced basis technique for nonlinear analysis of structures. AIAA J 18(4):455–462
Lumley JL (1967) The structure of inhomogeneous turbulent flows. Atmos Turbul Radio Wave Propag 166–178
Pearson K (1901) Principal components analysis. Lond Edinb Dublin Philos Mag J 6(2):566
Schmidt E (1989) Zur Theorie der linearen und nichtlinearen Integralgleichungen. Springer, Vienna
Hotelling H (1933) Analysis of a complex of statistical variables into principal components. J Educ Psychol 24(6):417
Karhunen K (1946) Zur Spektraltheorie Stochastischer Prozesse. Ann Acad Sci Fenn 34
Loève M (1955) Probability theory; foundations, random sequences. D. Van Nostrand Company, New York
Lorentz EN (1956) Empirical orthogonal functions and statistical weather prediction, M.I.T. Department of Meteorology, Scientific Report No. 1, Contract AF19(604)–1566, 49 pp
Harman HH (1960) Modern factor analysis. Chicago University Press, Chicago, IL
Golub GH, Van Loan CF (1983) Matrix computations. North Oxford Academic, Oxford
Yvonnet J, He Q-C (2007) The reduced model multiscale method (R3M) for the non-linear homogenization of hyperelastic media at finite strains. J Comput Phys 223(1):341–368
Prud’homme C, Rovas DV, Veroy K, Machiels L, Maday Y, Patera AT, Turinici G (2002) Reliable real-time solution of parametrized partial differential equations: reduced-basis output bound methods. J Fluids Eng 124(1):70–80
Rathinam M, Petzold LR (2003) A new look at proper orthogonal decomposition. SIAM J Numer Anal 41(5):1893–1925
Cremonesi M, Néron D, Guidault P-A, Ladevèze P (2013) A PGD-based homogenization technique for the resolution of nonlinear multiscale problems. Comput Methods Appl Mech Eng 267:275–292
Dvorak GJ (1992) Transformation field analysis of inelastic composite materials. Proc R Soc A Math Phys Eng Sci 437(1900):311–327
Michel JC, Suquet P (2003) Nonuniform transformation field analysis. Int J Solids Struct 40(25):6937–6955
Hernández JA, Caicedo MA, Ferrer A (2017) Dimensional hyper-reduction of nonlinear finite element models via empirical cubature. Comput Methods Appl Mech Eng 313:687–722
Everson R, Sirovich L (1995) Karhunen–Loève procedure for gappy data. J Opt Soc Am A 12(8):1657–1664
Barrault M, Maday Y, Nguyen NC, Patera AT (2004) An ’empirical interpolation’ method: application to efficient reduced-basis discretization of partial differential equations. Comptes Rendus Math 339(9):667–672
Nguyen NC, Patera AT, Peraire J (2008) A ‘best points’ interpolation method for efficient approximation of parametrized functions. Int J Numer Methods Eng 73(4):521–543
Astrid P, Weiland S, Willcox K, Backx T (2008) Missing point estimation in models described by proper orthogonal decomposition. IEEE Trans Automat Control 53(10):2237–2251
Chaturantabut S, Sorensen DC (2010) Nonlinear model reduction via discrete empirical interpolation. SIAM J Sci Comput 32(5):2737–2764
Soldner D, Brands B, Zabihyan R, Steinmann P, Mergheim J (2017) A numerical study of different projection-based model reduction techniques applied to computational homogenisation. Comput Mech 60(4):613–625
An SS, Kim T, James DL (2008) Optimizing cubature for efficient integration of subspace deformations. ACM Trans Graph 27(5):165:1–165:10
Farhat C, Avery P, Chapman T, Cortial J (2014) Dimensional reduction of nonlinear finite element dynamic models with finite rotations and energy-based mesh sampling and weighting for computational efficiency. Int J Numer Methods Eng 98(April):625–662
Hernández JA, Oliver J, Huespe AE, Caicedo MA, Cante JC (2014) High-performance model reduction techniques in computational multiscale homogenization. Comput Methods Appl Mech Eng 276:149–189
Hill R (1972) On constitutive macro-variables for heterogeneous solids at finite strain. Proc R Soc A Math Phys Eng Sci 326(1565):131–147
Kouznetsova VG, Brekelmans WAM, Baaijens FPT (2001) An approach to micro-macro modeling of heterogeneous materials. Comput Mech 27(1):37–48
Roussette S, Michel JC, Suquet P (2009) Nonuniform transformation field analysis of elastic-viscoplastic composites. Compos Sci Technol 69(1):22–27
de Souza Neto EA, Peric D, Owen DRJ (2008) Computational methods for plasticity. Wiley, London
Acknowledgements
The research leading to these results has received funding from the European Research Council under the European Union’s Seventh Framework Programme (FP7/2007-2013)/ERC Grant Agreement No. [339392]
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
van Tuijl, R.A., Remmers, J.J.C. & Geers, M.G.D. Integration efficiency for model reduction in micro-mechanical analyses. Comput Mech 62, 151–169 (2018). https://doi.org/10.1007/s00466-017-1490-4
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00466-017-1490-4