
Abstract
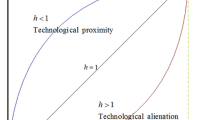
This paper discusses the role of technological spillovers and technological races in dynamic strategic interactions setup. Two firms invest simultaneously into new products creation and into further development of the quality of these products. Each firm may benefit from the costless technological spillover in case of technological leadership of the other firm. At the same time they cooperate in the joint creation of new products. Three different scenarios emerge: constant technological leadership, the technological leapfrogging and symmetric outcome with or without potential spillovers. R&D is maximal for the first scenario and minimal for the symmetric play under the threat of spillover with endogenous specialization of firms’ activities in cases of constant leadership and leapfrogging. Definition of technological competition intensity as inverse to the technology gap allows to recover inverted-U relationship between those two in a multidimensional context.




Similar content being viewed by others

Notes
1 Zero quality in between two points follows from the continuity
References
Aghion P, Howitt P (1992) A model of growth through creative destruction. Econometrica 60(2):323–351
Aghion P, Bloom N, Blundell R, Griffith R, Howitt P (2005) Competition and innovation: and inverted u-relationship. Q J Econ 120(2):701–728
Amable B, Demmou L, Lezdema I (2007) Competition, innovation and distance to frontier. CEPREMAP Working Papers (Docweb) 0706, CEPREMAP
Baveja A, Feichtinger G, Hartl R, Haunschmied J, Kort P (2000) A resource-constrained optimal control model for crackdown on illicit drug markets. Open access publications from Tilburg University. Tilburg University
Belyakov A, Tsachev T, Veliov V (2011) Optimal control of heterogeneous systems with endogenous domain of heterogeneity. Appl Math Optim 64(2):287–311
Belyakov AO, Haunschmied JL, Veliov VM (2014) Heterogeneous consumption in olg model with horizontal innovations. Port Econ J 13(3):167–193
Bernstein JI, Nadiri MI (1989) Research and development and intra-industry spillovers: an empirical application of dynamic duality. Rev Econ Stud 56(2):249–267
Bloom N, Schankerman M, Van Reenen J (2013) Identifying technology spillovers and product market rivalry. Econometrica 81(4):1347–1393
Bondarev A (2012) The long run dynamics of heterogeneous product and process innovations for a multi product monopolist. Econ Innov New Technol 21(8):775–799
Bondarev A (2014) Endogenous specialization of heterogeneous innovative activities of firms under the technological spillovers. J Econ Dyn Control 38(0):235–249
Bos J W, Economidou C, Sanders M W (2013) Innovation over the industry life-cycle: evidence from EU manufacturing. J Econ Behav Organ 86(C):78–91
Cellini R, Lambertini L (2002) A differential game approach to investment in product differentiation. J Econ Dyn Control 27(1):51–62
Chu A C (2011) The welfare cost of one-size-fits-all patent protection. J Econ Dyn Control 35(6):876–890
Chu A C, Cozzi G, Galli S (2012) Does intellectual monopoly stimulate or stifle innovation? Eur Econ Rev 56(4):727–746
D’Aspremont C, Jacquemin A (1988) Cooperative and noncooperative r & d in duopoly with spillovers. Am Econ Rev 78(5):1133–1137
Dawid H, Greiner A, Zou B (2010) Optimal foreign investment dynamics in the presence of technological spillovers. J Econ Dyn Control 34(3):296–313
Denicolo V (1996) Patent races and optimal patent breadth and length. J Ind Econ 44(3):249–265
Hartwick J (1984) Optimal r&d levels when firm j benefits from firm i’s inventive activity. Econ Lett 16(1–2):165–170
Henderson R (1993) Underinvestment and incompetence as responses to radical innovation: evidence from the photolithographic alignment equipment industry. RAND J Econ 24(2):248–270
Henderson R, Cockburn I (1996) Scale, scope, and spillovers: the determinants of research productivity in drug discovery. RAND J Econ 27(1):32–59
Jaffe A (1986) Technological opportunity and spillovers of R&D: evidence from firms’ patents, profits, and market value. Am Econ Rev 76(5):984–1001
Judd K L (2003) Closed-loop equilibrium in a multi-stage innovation race. Econ Theory 21(2):673–695
Lambertini L (2003) The monopolist optimal R&D portfolio. Oxf Econ Pap 55 (4):561–578
Lambertini L (2009) Optimal product proliferation in a monopoly: a dynamic analysis. Rev Econ Anal 1:28–46
Lambertini L, Mantovani A (2010) Process and product innovation: a differential game approach to product life cycle. Int J Econ Theory 6(2):227–252
Lambertini L, Orsini R (2001) Network externalities and the overprovision of quality by a monopolist. South Econ J 67(2):969–982
Navas J, Kort P M (2007) Time to complete and research joint ventures: a differential game approach. J Econ Dyn Control 31(5):1672–1696
Peretto P F (1998) Technological change and population growth. J Econ Growth 3(4):283–311
Peretto P, Connolly M (2007) The manhattan metaphor. J Econ Growth 12(4):329–350
Reinganum J (1982) A dynamic game of r and d: patent protection and competitive behavior. Econometrica 50(3):671–688
Romer P (1990) Endogenous technological change. J Polit Econ 98(5):S71–S102
Rosenkranz S (2003) Simultaneous choice of process and product innovation when consumers have a preference for product variety. J Econ Behav Organ 50(2):183–201
Schumpeter J (1942) Capitalism, socialism and democracy. Harper & Row, New York
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix A
1.1 Value functions of the quality game under constant leadership
Under constant leadership value functions of both players are linear in both states. Namely, they have the form
for both players. Solving HJB equations (8) with a constant leader one arrives to a system of algebraic equations on coefficients of both value functions. Solution yields value functions of the following form (with L denoting the leader and F denoting the follower quantities):
from which the optimal strategies (11), (12) and quality paths (13), (14) follow.
Appendix B
1.1 Derivation of optimal strategies for symmetric game of vertical innovations
First observe, that functions (8) are non-differentiable along the line q j (i) = q −j (i). Thus the optimal strategies of players cannot be found through usual first order conditions on HJB equations. To derive strategies Eqs. 17 and 18 first establish the following:
Lemma 11
In the symmetric case, ( 15 ), one-sided derivatives of value functions of players are not equal to each other,
and thus a continuous spectrum of possible strategies for both players exist, with limits being given by leader’s strategy ( 11 ) and follower’s strategy ( 12 ).
The proof amounts to direct computation of derivatives of value functions, given that value functions for both players are Eq. A.2. For every player j the derivative is computed using the leader’s value function for \(q_{j}(i)\overset {+}{\rightarrow } q_{-j}(i)\) and the follower’s value function for \(q_{j}(i)\overset {-}{\rightarrow } q_{-j}(i)\).
Given Eq. B.1 it is straightforward to conclude, that candidates for optimal strategies for both players are indeed in the above mentioned spectrum. The problem of finding the optimal strategy in symmetric game thus amounts to the problem of selection of a pair of candidates from the spectrum (11), (12). For this establish
Lemma 12
The pair of optimal controls in symmetric case is a unique one.
Observe that value functions have to be continuous along the line q j (i) = q −j (i). Thus they are unique and have to be generated by a unique pair of optimal controls. Continuity of value functions requires that they should converge to the same value for q(i) values lower and higher than the symmetric one, q SYM(i) = q j (i) = q −j (i). This is given by
with V SYM(i) denoting the symmetrical value of vertical innovations for both players. Assuming linear value functions and constant strategies as for the constant leader-follower case one can compute this limits as:
These two expressions coincide only for 𝜃 = 0. Thus we obtain the first pair of symmetric strategies, (17) which correspond to the absence of the spillover effect.
Now consider the case of 𝜃>0. Value functions of both players are no longer continuous along the symmetry line. However since constant strategies correspond to the open-loop equilibrium, players cannot alter their behaviour after choosing their strategies at the point q j (i) = q −j (i) = 0. At this point both players have the incentive to minimize their investments in an effort to benefit from the technological spillover. At the same time the set of possible strategies is given by the range (11), (12). Observe that the minimum of investments is reached for any player j following (12). Thus with positive technological spillover in symmetric case both players choose the strategy (18).
Value functions of both players under the symmetric regime resemble the one of the leader in constant leadership mode:
Appendix C
1.1 Derivation of optimal strategies for catching-up game of vertical innovations
First establish the auxiliary Lemma 13
Lemma 13 (Uniqueness of the catching-up event)
If the parameters of both firms allow for the catching-up, at most one trigger point, \(\{q^{TRIG}_{i},t_{i}^{TRIG}\}\) for each i exists. It is defined by the condition
Proof of this lemma amounts to the observation that in constant leadership case strategies are constant, (11), (12). Thus even if parameters of the game allow for the eventual catching-up of technologies at zero technology level, the strategies of players after this event are formulated in the same form as for the constant leadership but with the after-trigger non-zero technology level. Since strategies are linear combinations of parameters, they allow for at most one point of equal qualities except for the t 0(i). It follows, that if the game allows for the catching-up, it can happen only once for each product i, changing relative positions of the leader and the follower. Thus one may speak about situations before the catching-up and after the catching-up as uniquely defined.
Next define the boundary conditions for the problem before catching-up.
Lemma 14 (Boundary conditions for value functions)
The player, which is the leader before the trigger, receives the value of the follower in constant leadership game as a payoff after the trigger and the player which is the follower before the trigger, receives the value of the leader in constant leadership game as a payoff after the trigger. They are boundary conditions for value functions of both players before the trigger point:
With this salvage values objectives of both firms before the trigger are Eqs. 22 and 23. The solution is found by the application of the Maximum Principle. Hamiltonians of both players before the trigger are (with player j being the leader in technology before the trigger for certainty):
The time and state constraints of this problem are taken into account by the augmented Hamiltonians:
Multipliers μ j (i, t), μ −j (i, t) are zero as long as the j’s quality is higher than that of the −j player. This holds during the before the trigger phase always, thus,
Note that the Lagrange multipliers η j,−j are defined as functions of the opportunity costs of moving the trigger time. These are constant in time and depend only on the time of the trigger itself. Since the trigger point is unique, Lagrange multipliers defining this point are similar for both players:
Now taking F.O.C. w. r. t. controls of Eq. C.5 one arrives to the formulation of optimal controls and qualities evolution.
Lemma 15 (Solution of the quality game before the catching-up)
When parameters of the model allow for the catching-up to occur, the solution of the game before the catching-up is the maximization of Eqs. 22 and 23 w. r. t. Eq. 3 via the Maximum principle. Strategies of the players before the catching-up are given by linear functions of shadow costs of increasing own direct investments \({\psi ^{j}_{j}}\) :
and evolution of qualities is given by the dynamical system
where η are the opportunity costs of changing the time of a trigger, \(t_{i}^{TRIG}\).
The system of co-states evolution for player j is the boundary value problem due to Lemma 14:
yielding co-sates as functions of η and parameters of the model. The same type of dynamical system holds for player −j:
with derivatives of value functions computed from Eq. A.2. As these derivatives are constant, co-states for both players may be expressed as functions of parameters and η only. Thus the system (C.10) may be solved w. r. t. η and trigger time.
Provided the solution for qualities evolution before the trigger time this last may be obtained from equalizing opportunity costs η across players. For this one make use of Lemma 13. By definition
from which \(\eta (t_{i}^{TRIG})\) follows.
Finally the trigger time \(t_{i}^{TRIG}\) is defined from the condition (24).
Value functions of both players in the catching-up mode correspond to the optimized Hamiltonians (4), since the optimal co-states \(\psi _{j,-j}^{j,-j}\) already include the future value of the evolution after the catching-up, which are in turn linear functions of i:
Appendix D
1.1 Optimal strategies and solution for the problem of variety expansion
Construct (current-value) Hamiltonian functions for both firms:
The first-order conditions on the investments into the variety expansion for both firms define investments as functions of co-state variables. Substituting these into Hamiltonian functions and writing down co-state equations yields the canonical system for the variety expansion game. Inserting optimal controls into the dynamic constraint for variety expansion together with canonical system constitutes the system of 3 linear ODEs with one initial condition and two boundary conditions (transversal ones) which is then solved. The solution for variety expansion is:
Then I use (D.3) to define explicitly investments of both firms as functions of time:
Equations D.3 and D.4 give Proposition 5.
Appendix E
1.1 Conditions on multiplicity of steady states of the quality game
It may be the case that for the given player the steady-state level of quality in the follower mode is higher than of being in the leader mode giving rise to multiple equilibria of the game. I first establish the conditions for the existence and realization of the unique steady state of the game.
Lemma 16 (Uniqueness of the steady state)
-
1.
For the game of quality development to have unique non-symmetric steady state it is necessary, that
$$ q^{STL}_{j}(i)>q^{STL}_{-j}(i). $$(E.1)Then player j is the final leader in this game for any i.
For the game to realize in constant leadership mode, it is sufficient:
$$\begin{array}{@{}rcl@{}} &q^{STL}_{j}(i)>q^{STF}_{j}(i),\\ &q^{STF}_{-j}(i)>q^{STL}_{-j}(i). \end{array} $$(E.2)Then there is the unique steady state in quality game, \(\left \{q^{STL}_{j}(i),q^{STF}_{-j}(i)\right \}\) which is realized through constant leadership strategies (11), (12).
-
2.
In the case of symmetric outcome there is always the unique steady state, associated with equal qualities of both players, realized through either (18) or (17) for both players.
However, these opportunities do not exhaust the set of possible outcomes of the quality game. It might be the case, that two potential steady states of the system exist. This is the case when \(q^{STF}_{-j}(i)<q^{STL}_{-j}(i)\) and the player −j is better off as the leader also. In this situation the catching up of quality levels may occur.
Lemma 17 (Existence of multiple steady states)
For two steady states of the quality game to exist, the following conditions have to hold:
-
1.
Both players are better off in the leadership mode,
$$\begin{array}{@{}rcl@{}} &&q^{STL}_{j}(i)>q^{STF}_{j}(i),\\ &&q^{STL}_{-j}(i)>q^{STF}_{-j}(i), \end{array} $$(E.3) -
2.
For both players in the leadership mode quality level is higher, than for the other player in the follower mode:
$$\begin{array}{@{}rcl@{}} &&q^{STL}_{j}(i)>q^{STF}_{-j}(i),\\ &&q^{STL}_{-j}(i)>q^{STF}_{j}(i). \end{array} $$(E.4)than there are two steady states in the non-symmetric quality game, given by \(\left \{q^{STL}_{j}(i),q^{STF}_{-j}(i)\right \}\) and \(\left \{q^{STL}_{-j}(i),q^{STF}_{j}(i)\right \}\).
The first condition is straightforward. The second condition is the requirement, that the leader’s quality is higher than that of the follower, otherwise no spillover may occur.
Appendix F
1.1 Potential values of the quality game for product i = n(t)
They are given by setting q j (i) = q −j (i) = 0 in Eqs. A.2, B.6 and C.14:
Rights and permissions
About this article

Cite this article
Bondarev, A. Intensity of R&D competition and the generation of innovations in heterogeneous setting. J Evol Econ 26, 621–653 (2016). https://doi.org/10.1007/s00191-016-0457-5
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00191-016-0457-5
Keywords
- Heterogeneous innovations
- Technological race
- Technology spillovers
- Distributed control
- Differential games