
Abstract
Salient region is the most prominent object in the scene which attracts to the human vision system. This paper presents a novel algorithm that is based on the separated Red, Green and Blue colour channels. Most prominent regions of all the three channels of RGB colour model are extracted using mean value of the respective channels. Pixels of extracted salient region of RGB channels are counted and then some specified rules are applied over these channels to generate final saliency map. To evaluate the performance of the proposed novel algorithm, a standard dataset MSRA-B has been used. The proposed algorithm presents better result and outperformed to the existing approaches.
Similar content being viewed by others


Keywords
1 Introduction
Salient region detection is a challenging research field of the image processing and computer vision. Human vision system is highly capable to separate the distinct object in the scene and mostly have a deep focus on the most prominent part of the scene. The object or portion of the image, which attracts to the human vision system in first sight is called as salient region or salient object in the scene. Colours play important role to highlight the salient object in the image. RGB image has three basic colours red, green, and blue which has contribution in some specific ratio to complete an image. Image has background as well as foreground objects. These foreground objects may be the salient object.
Most important issue is to detect these most attractive salient regions in the image through an intelligent machine. Salient region or salient object detection reduces computational complexity in the various applications-object detection and recognition, video and image compression, segmentation, and image classification.
Proposed algorithm is robust to salient region detection in the image with the following features:
-
1.
The proposed algorithm is able to detect the saliency region in cluttered background.
-
2.
The proposed algorithm is better to extract the correct saliency region with almost complete portion of the salient object under illumination effects.
-
3.
The proposed algorithm outperformed to almost all the exiting approaches on the basis quantitative measures - precision and recall.
The rest parts of the paper is arranged as follows: Sect. 2 discusses some existing approaches for finding salient region, Sect. 3 discusses the proposed algorithm, Sect. 4 presents the result analysis, and Sect. 5 presents the conclusion.
2 Related Work
This section discusses the progress of the existing approaches of the recent decade in the field of salient region detection. In the recent years, many salient region extraction approaches have been developed. Itti et al. [12] introduced saliency model for rapid scene analysis using orientation, luminance and color opposition. The works of saliency region findind can be categorized into three ways: i) local-contrast ii) global-contrast and iii) statistical-learning based models.
Local contrast based approaches detects the salient region by extracting features of small regions and higher weightage is assigned to high contrast. Harel et al. [8] applied Markovian approach check the dissimilarity feature of histogram of surrounding the center. Goferman et al. [7] utilized both local and global saliency map to generate final salient region of the image. Klein and Frintrop [15] applied KL Divergence to compute prominent part and extraction of correct salient region. Jiang et al. [13] presented saliency based on a super pixel which is multi-scale and boundary pair that is closed. Yan et al. [23] introduced a hierarchical-model by applying features based on contrast at different scales of a scene and then fusion is applied by graphical model. Hou et al. [10] used informative divergence to represent non-uniform visual information’s distribution of an image. Zhu et al. [26] proposed an optimization framework for modeling the background measure.
Global contrast based approaches utilize color contrast over the whole image globally for saliency detection. These approaches are less complex on the basis of computational complexity. Achanta et al. [2] extracted the saliency with the help of frequency domain by using luminance and colour of the scene. Cheng et al. [4] introduced spatial weighted coherence and global contrast differences to extract salient region. Shen and Wu [22] presented decomposition of low-rank matrix to extract foreground and background separately. He and Lau [9] exploited brightness of prominent region to generate final saliency map using pairs of flash and no flash image. Statistical learning based approaches employ models based on Machine learning. In these methods, accuracy of the saliency map is increased and complexity of computation is also increased. Wang et al. [21] presented an auto context model which combined salient region finding and segmentation using trained classifier. Borji and Itti [3] computed saliency map based on rarity of different color spaces using local-global patch dictionary learning. Yang et al. [24] used graph based manifold to assign the rank to regions of image based on similarity. Li et al. [16] computed saliency region using sparse and dense representation errors of the image region. Jiwhan et al. [14] applied local and global contrast approach, spatial distribution, center prior and backgroundness as a set of features for salient region finding. Sikha et al. [20] proposed a hybrid approach for saliency driven transition using DMD to generate saliency map. The proposed algorithm used colour channels mean and rules on the basis of pixel count to extract salient region of the image.

3 Proposed Work
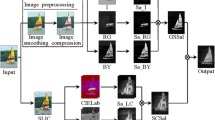
This section presents the functionality of the proposed algorithm that is able to extract most prominent region of the image. The proposed algorithms is robust to most prominent region of the image through red, green and blue channels. A region-based rules are applied over the region of RGB channels to find the salient region, that is highly focused by human vision system. The proposed approach consists of two algorithms: Algorithm 1 is responsible to extract the most of the prominent region of RGB channels which plays important role in the removal of background details. Output generated by Algorithm 1 is passed to Algorithm 2, where Algorithm 2 apply rules on count of pixels present in the RGB channels to decide salient object.
Algorithm 1 presents its well defined steps for background removal which are non-salient region. Steps 1–5 takes an colored input image, RGB channels are extracted as \(I_{R}, I_{G}, I_{B}\) and gaussian filter is utilized to remove the noise. Mean of each channel is computed as \(M_{{I}_{{R}}}\), \(M_{{I}_{{G}}}\), \(M_{{I}_{{B}}}\) and average of mean of RGB channels is computed. Dimension r and c is computed to process the image of any dimension in step 6. Steps 7–19 preserves those pixels of each channels which are more than the average mean of RGB channels. Morphological operations are applied over these obtained RGB images. Pixels of RGB regions are counted and represented as c1, c2 and c3 respectively.
Algorithm 2 uses the region count of RGB channel to decide the prominent region of the image. Algorithm 2 extracts the saliency region of an image after applying its rule over the segmented R, G, and B images. Therefore, proposed approach is robust to find salient region of the image correctly with complete portion of the object in complex background.
4 Performance Analysis
To measure and analyze the performance of the proposed novel algorithm, 1000 complex and challenging images of standard dataset MSRA-B [4] have been used. The implementation of the proposed algorithm has been done on a computer having configuration- Intel Core i7 \(8^{th}\) Gen CPU, 8GB DDR 3 RAM, windows 10 operating system using Matlab 2016a.
Performance analysis of the proposed algorithm has been done by quantitative as well as qualitative. Quantitative analysis has been performed using two frequently used measures-precision and recall. Qualitative analysis have presented as salient region of the image with respect to ground truth. The quantitative and qualitative results have been compared with the following existing approaches: DMD [20], SUN [25], FES [18], SIM [17], SR [11], SER [19], SWD [6], HDCT [14], HC [4], GC [5], FT [2], MC [13], GB [8], AC [1].

The precision and recall quantitative measures have been utilized to analyze the performance according to the presented formulas: Precision refers to accurate salient region detection, and it is defined as the ratio of the total number of pixels of ground truth’s salient region to the total count of the pixels of extracted salient region. It is represented as equation given below:
Recall refers to the portion of the extracted salient region, and it can be defined as the ratio of pixels of the extracted salient region to the total count of the pixels of ground truth salient region. It is represented as equation given below:
where F is the binary foreground and G is the ground truth binary image. In other ways, precision refers to correct salient region detection while recall refers to the how much portion of the correct salient region is detected in comparison to the ground truth.

Comparative study of visual saliency results of the proposed algorithm and different existing approaches on complex images.
Table 1 shows the performance of the proposed algorithm and above mentioned existing approaches in terms of precision and recall. The proposed algorithm outperformed to some existing approaches and comparable to a few approaches.

Comparative study of visual salient region obtained by the proposed algorithm and different existing approaches.
It has been observed that the methods SUN [25], FES [18], SR [11] and AC [1] failed to detect few of the saliency map due to the use of limited set of local features. A few algorithms-SIM [17], SER [19], SWD [6] and GB [8] are failed to detect salient region with better resolution. Although some methods GB [8], SER [19], FT [2], SIM [17], GC [5], MC [13], HC [4], SWD [6], and SEG detected most of the saliency map and some non saliency map were also detected. The proposed algorithm outperformed to the following existing approaches-SUN [25], FES [18], SIM [17], SR [11], SER [19], SWD [6], HC [4], GC [5], FT [2], GB [8], AC [1] in terms of precision and recall measures excepting DMD [20], HDCT [14], and MC [13].
Figure 1 shows the qualitative results for analysis of correctly salient region detection as well as how much portion of the salient region detected. The proposed algorithm can be compared with the following approaches-DMD [20], HDCT [14], and MC [13] as qualitative and quantitative as well. The proposed algorithm is lacking in terms of precision from DMD [20], HDCT [14] by small margin i.e. .001 and .004 respectively while outperformed both by small margin in terms of recall. The proposed algorithm is lacking by small margin in terms of recall by MC [13] but outperformed in terms of precision.
Figure 2 shows results of some challenging images of the proposed algorithm and the existing approaches. Result of proposed algorithm for image a, b, d, h is better than existing approaches. Result of c is very close to DMD [20] and better than other approaches. Result of images e, f and g are better than other approaches excepting DMD [20]. In comparison to DMD [20], result is better including small noise.
5 Conclusion
The proposed algorithm separated RGB channels from the RGB colored image and extracted the most prominent region using the mean value of the three channel images. Some rules have been applied based on pixel count of the salient region of three channels to find final salient region.
The proposed approach performed well and outperformed to the existing approaches, excepting a few approaches with which lacking by a small margin. In future, improvement in the algorithm is required which can improve both the precision and recall measures simultaneously.
References
Achanta, R., Estrada, F., Wils, P., Süsstrunk, S.: Salient region detection and segmentation. In: Gasteratos, A., Vincze, M., Tsotsos, J.K. (eds.) ICVS 2008. LNCS, vol. 5008, pp. 66–75. Springer, Heidelberg (2008). https://doi.org/10.1007/978-3-540-79547-6_7
Achanta, R., Hemami, S., Estrada, F., Süsstrunk, S.: Frequency-tuned salient region detection. In: IEEE International Conference on Computer Vision and Pattern Recognition (CVPR 2009), pp. 1597–1604 (2009). For code and supplementary material http://infoscience.epfl.ch/record/135217
Borji, A.: Exploiting local and global patch rarities for saliency detection. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), CVPR 2012, pp. 478–485. IEEE Computer Society, Washington (2012). http://dl.acm.org/citation.cfm?id=2354409.2354899
Cheng, M.M., Mitra, N.J., Huang, X., Torr, P.H.S., Hu, S.M.: Global contrast based salient region detection. IEEE TPAMI 37(3), 569–582 (2015)
Cheng, M.M., Warrell, J., Lin, W.Y., Zheng, S., Vineet, V., Crook, N.: Efficient salient region detection with soft image abstraction (2013)
Duan, L., Wu, C., Miao, J., Qing, L., Fu, Y.: Visual saliency detection by spatially weighted dissimilarity, pp. 473–480 (2011)
Goferman, S., Zelnik-Manor, L., Tal, A.: Context-aware saliency detection. IEEE Trans. Pattern Anal. Mach. Intell. 34(10), 1915–1926 (2012). https://doi.org/10.1109/TPAMI.2011.272
Harel, J., Koch, C., Perona, P.: Graph-based visual saliency. In: Proceedings of the 19th International Conference on Neural Information Processing Systems, NIPS 2006, pp. 545–552. MIT Press, Cambridge (2006). http://dl.acm.org/citation.cfm?id=2976456.2976525
He, S., Lau, R.W.: Saliency detection with flash and no-flash image pairs. In: Proceedings of European Conference on Computer Vision, pp. 110–124 (2014)
Hou, W., Gao, X., Tao, D., Li, X.: Visual saliency detection using information divergence. Pattern Recogn. 46(10), 2658–2669 (2013). https://doi.org/10.1016/j.patcog.2013.03.008
Hou, X., Zhang, L.: Saliency detection: a spectral residual approach (2007)
Itti, L., Koch, C., Niebur, E.: A model of saliency-based visual attention for rapid scene analysis. IEEE Trans. Pattern Anal. Mach. Intell. 20(11), 1254–1259 (1998). https://doi.org/10.1109/34.730558
Jiang, B., Zhang, L., Lu, H., Yang, C., Yang, M.H.: Saliency detection via absorbing Markov chain. In: 2013 IEEE International Conference on Computer Vision, pp. 1665–1672 (2013)
Kim, J., Han, D., Tai, Y., Kim, J.: Salient region detection via high-dimensional color transform and local spatial support. IEEE Trans. Image Process. 25(1), 9–23 (2016)
Klein, D.A., Frintrop, S.: Center-surround divergence of feature statistics for salient object detection. In: 2011 International Conference on Computer Vision, pp. 2214–2219 (2011)
Li, Z., Tang, K., Cheng, Y., Hu, Y.: Transition region-based single-object image segmentation. AEU Int. J. Electron. Commun. 68(12), 1214–1223 (2014)
Murray, N., Vanrell, M., Otazu, X., Párraga, C.A.: Saliency estimation using a non-parametric low-level vision model, pp. 433–440 (2011)
Rezazadegan Tavakoli, H., Rahtu, E., Heikkilä, J.: Fast and efficient saliency detection using sparse sampling and kernel density estimation. In: Heyden, A., Kahl, F. (eds.) SCIA 2011. LNCS, vol. 6688, pp. 666–675. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-21227-7_62
Seo, H., Milanfar, P.: Static and space-time visual saliency detection by self-resemblance. J. Vis. 9(15), 1–27 (2009)
Sikha, O., Kumar, S.S., Soman, K.: Salient region detection and object segmentation in color images using dynamic mode decomposition. J. Comput. Sci. 25, 351–366 (2018)
Wang, L., Xue, J., Zheng, N., Hua, G.: Automatic salient object extraction with contextual cue. In: Proceedings of the 2011 International Conference on Computer Vision, ICCV 2011, pp. 105–112. IEEE Computer Society, Washington (2011). https://doi.org/10.1109/ICCV.2011.6126231
Wu, Y.: A unified approach to salient object detection via low rank matrix recovery. In: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), CVPR 2012, pp. 853–860. IEEE Computer Society, Washington (2012). http://dl.acm.org/citation.cfm?id=2354409.2354676
Yan, Q., Xu, L., Shi, J., Jia, J.: Hierarchical saliency detection. In: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2013, pp. 1155–1162. IEEE Computer Society, Washington (2013). https://doi.org/10.1109/CVPR.2013.153
Yang, C., Zhang, L., Lu, H., Ruan, X., Yang, M.: Saliency detection via graph-based manifold ranking. In: 2013 IEEE Conference on Computer Vision and Pattern Recognition, pp. 3166–3173, June 2013
Zhang, L., Tong, M.H., Marks, T.K., Shan, H., Cottrell, G.W.: SUN: a Bayesian framework for saliency using natural statistics. J. Vis. 8, 32 (2008)
Zhu, W., Liang, S., Wei, Y., Sun, J.: Saliency optimization from robust background detection. In: Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, pp. 2814–2821. IEEE Computer Society, Washington (2014). https://doi.org/10.1109/CVPR.2014.360
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Tripathi, R.K. (2020). A Novel Algorithm for Salient Region Detection. In: Bhattacharjee, A., Borgohain, S., Soni, B., Verma, G., Gao, XZ. (eds) Machine Learning, Image Processing, Network Security and Data Sciences. MIND 2020. Communications in Computer and Information Science, vol 1241. Springer, Singapore. https://doi.org/10.1007/978-981-15-6318-8_33
Download citation
DOI: https://doi.org/10.1007/978-981-15-6318-8_33
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-6317-1
Online ISBN: 978-981-15-6318-8
eBook Packages: Computer ScienceComputer Science (R0)