
Abstract
Big Data is the term that describes any voluminous amount of structured, semi-structured and unstructured data that has the potential to be mined for information. Clustering is an essential tool for clustering Big Data. Multi-machine clustering technique is one of the very efficient methods used in the Big Data to mine and analyse the data for insights. K-Means partition-based clustering algorithm is one of the clustering algorithm used to cluster Big Data. One of the main disadvantage of K-Means clustering algorithms is the deficiency in randomly identifying the K number of clusters and centroids. This results in more number of iterations and increased execution times to arrive at the optimal centroid. Sorting-based K-Means clustering algorithm (SBKMA) using multi-machine technique is another method for analysing Big Data. In this method, the data is sorted first using Hadoop MapReduce and mean is taken as centroids. This paper proposes a new algorithm called as SBKMEDA: Sorting-based K-Median clustering algorithm using multi-machine technique for Big Data to sort the data and replace median with mean as centroid for better accuracy and speed in forming the cluster.
Similar content being viewed by others



Keywords
1 Introduction
Big Data analytics examines large amount of data to uncover hidden patterns, correlations and other insights. Many social networking Websites such as Facebook, Twitter have billions of users who produce gigabytes of contents per minute. Similarly, many online retail stores conduct business worth millions of dollars. Hence, it is necessary to have efficient algorithms to analyse and group the data and derive meaningful information [1]. Clustering of data is a method by which large sets of data is grouped into clusters of smaller sets of similar data.
Clustering algorithms have emerged as an alternative powerful meta-learning tool to accurately analyse the massive volume of data generated by modern applications. Multi-machine techniques are flexible in scalability and offer faster response time to the users. K-Means clustering algorithm follows a simple and easy way to classify a given data set through a certain number of clusters fixed a priori. The main idea is to define k-centroids, one for each cluster. SBKMA: Sorting-based K-Means clustering algorithm using multi-machine techniques a partition-based clustering algorithm which reduces the iteration and execution time of traditional K-Means algorithm. It is found that SBKMA based on mean reduces the iteration and execution time and this gave an idea to include median instead of mean for this proposed work. This paper is further written as follows. It discusses other related and relevant work in Sect. 2. Section 3 gives a small introduction about multi-machine clustering technique followed by the proposed work in Sect. 4. The Experimentation and Analysis is explained in Sect. 5 followed by the Conclusion in Sect. 6.
2 Related Work
Jane and George Dharma Prakash Raj [1] proposes an Algorithm called as SBKMA. In the SBKMA algorithm, the centroids are identified by sorting the objects first and then identifying the mean from the partition done as per the K-clusters. Each K-cluster is partioned and mean of each cluster is taken as centroid. Multi-machine clustering technique which is discussed in Sect. 3 allows to breakdown the huge amount of data into smaller pieces which can be loaded on different machines and then uses processing power of these machines to solve the problem. Hence, number of iterations and execution time are considerably reduced. Vrinda and Patil [2] describe the various K-Means algorithm, their advantages and disadvantages. Patil and Vaidya [3] present the implementation of K-Means clustering algorithm over a distributed environment using Apache Hadoop. This work explains the design of K-Means algorithm using Mapper and Reducer routines. It also provides the steps involved in the implementation and execution of the K-Means algorithm. Baswade and Nalwade [4] in this paper present the drawback of traditional K-Means algorithm of selection initial centroid is removed. Here, mean is taken as the initial centroid value. Vishnupriya and Sagayaraj Francis [5], in this method, describe that the K-Means algorithm is used to cluster the data for different type of data sets in Hadoop framework and calculate the sum of squared error value for the given data. Gandhi and Srivastava [6] suggest different partitioning techniques, such as k-means, k-medoids and clarans. In terms of data set attributes, the objects within single clusters are of similar characteristics where the objects of different cluster have dissimilar characteristic. Bobade [7] describes the concept of Big Data along with Operational versus Analytical systems of Big Data.
3 Multi-Machine Clustering Technique
Multi-Machine clustering technique is a clustering method where data are analysed using multiple machines. It enables to reduce the execution time and improves the speed of the clusters formed. Multi-machine clustering technique is divided into parallel clustering and map-reduced based clustering. This type of techniques allows the data to be divided into multiple servers and processes the request.
4 Proposed Algorithm: SBKMEDA: Sorting-Based K-Median Clustering Algorithm Using Multi-Machine Technique
In SBKMA algorithm, sorting is initially done with multi-machine technique. K-value is chosen randomly. Mean is taken as the centroid. The proposed SBKMEDA algorithm is the modified version of the previous SBKMA algorithm suggested by us. Here, median is taken as centroids to get more accurate results in the formation of clusters.
The proposed SBKMEDA algorithm is given below:
-
Step 1:
Load the data set
-
Step 2:
Choose K-clusters.
-
Step 3:
Sort the data set
-
Step 4:
Calculate the median and choose centroids based on the K-clusters
-
Step 5:
Find the distance between the objects and centroids
-
Step 6:
Group objects with minimum distance
-
Step 7:
Repeat 4, 5 and 6 until no change in the pattern
-
Step 8:
Stop the program (Fig. 1).
Fig. 1 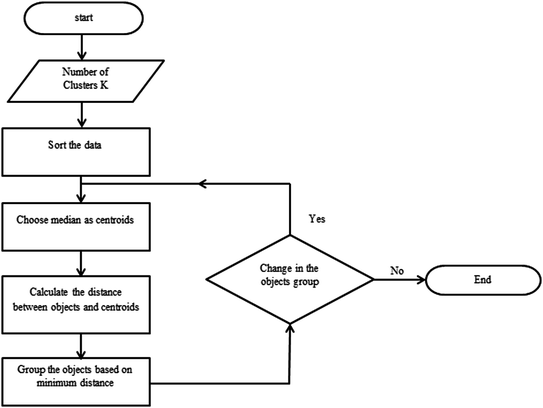
Working of SBKMEDA

In this algorithm, the data is sorted first using Hadoop MapReduce. When sorting is completed, the data is divided into k-clusters. Median is taken as centroids. Then, the distance between the object and the centroid is calculated. When the distance is calculated, the objects are grouped with the nearest centroid. Repetitively the process is carried out till there is no change in the group. When there is no change in the formation, the process is finished.
5 Experimentation and Analysis
SBKMA algorithm, enhanced traditional K-Means algorithm [8] and the proposed SBKMEDA clustering algorithm are implemented in Hadoop MapReduce framework. Hadoop MapReduce is a software framework for easily writing applications which process vast amounts of data in parallel on large clusters of commodity hardware in a reliable, fault-tolerant manner [9].
MapReduce usually splits the input data set into independent chunks which are processed by the map tasks in a completely parallel manner. The framework sorts the outputs of the maps, which are then input to the reduce tasks. Typically, both the input and the output of the job are stored in a file system. The framework takes care of scheduling tasks, monitoring them and re-executes the failed tasks [9].
The process of Experimentation of this paper using MapReduce using Multiple Machine Technique is explained next. First, Java file with 1 terabyte of mobile data set is randomly generated. This data is stored in the form of text files. This data is consumed by the Hadoop MapReduce and the two algorithms are compared for analysis (Table 1).
The execution time of SBKMEDA is lesser when compared to SBKMA and the existing traditional enhanced K-Means algorithm. When the number of nodes is increased, the efficiency increases even more. This can be seen in Fig. 2. Execution time is measured in seconds. The number of nodes is different when compared to the previous SBKMA algorithm (Table 2).

Execution time
Here, the number of times the algorithm is iterated is less for SBKMEDA when compared to SBKMA and the existing traditional enhanced K-Means algorithm as shown in Fig. 3.

No. of iterations
6 Conclusion
In this paper, the algorithm is compared with already existing sorting-based K-Means algorithm and Enhanced traditional K-Means algorithm. Here, multi-machine technique with Hadoop MapReduce is used to sort the data. To improve the efficiency, median is taken as centroids. This algorithm reduces time and the number of iterations when compared with sorting-based K-Means algorithm. In future, it can be extended with other partition-based algorithms.
References
Jane, M., George Dharma Prakash Raj, E.: SBKMA: sorting based K-Means clustering algorithm using multi machine technique for Big Data. Int. J. Control Theory Appl. 8, 2105–2110 (2015)
Vrinda, Patil, S.: Efficient clustering of data using improved K-Means algorithm—a review. Imp. J. Interdiscip. Res. 2(1) (2016)
Patil, Y.S., Vaidya, M.B.: K-Means clustering with MapReduce technique. Int. J. Adv. Res. Comput. Commun. Eng. (2015)
Baswade, A.M., Nalwade, P.S.: Selection of initial centroids for K-Means Algorithm. IJCSMC 2(7), 161–164 (2013)
Vishnupriya, N., Sagayaraj Francis, F.: Data clustering using MapReduce for multidimensional datasets. Int. Adv. Res. J. Sci. Eng. Technol. (2015)
Gandhi, G., Srivastava, R.: Review paper: a comparative study on partitioning techniques of clustering algorithms. Int. J. Comput. Appl. (0975-8887) 87(9) (2014)
Bobade, V.B.: Survey paper on Big Data and Hadoop. Int. Res. J. Eng. Technol. (IRJET) 03(01) (2016)
Rauf, A., Sheeba, Mahfooz, S., Khusro, S., Javed, H.: Enhanced K-Mean clustering algorithm to reduce number of iterations and time complexity. Middle-East J. Sci. Res. 12(7), 959–963 (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Mahima Jane, E., George Dharma Prakash Raj, E. (2018). SBKMEDA: Sorting-Based K-Median Clustering Algorithm Using Multi-Machine Technique for Big Data. In: Rajsingh, E., Veerasamy, J., Alavi, A., Peter, J. (eds) Advances in Big Data and Cloud Computing. Advances in Intelligent Systems and Computing, vol 645. Springer, Singapore. https://doi.org/10.1007/978-981-10-7200-0_19
Download citation
DOI: https://doi.org/10.1007/978-981-10-7200-0_19
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-7199-7
Online ISBN: 978-981-10-7200-0
eBook Packages: EngineeringEngineering (R0)