
Abstract
In Chap. 1, the terms “latent trait” and “construct” are used to refer to the psycho-social attributes that are of interest to be measured.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
References
Adams RJ, Wu ML (2002) PISA 2000 technical report. OECD, Paris
Downing SM, Haladyna TM (eds) (2006) Handbook of test development. Lawrence Erlbaum Associates, Mahwah, NJ
Mullis I, Martin M, Ruddock G, O’Sullivan C, Preuschoff C (2009) TIMSS 2011 Assessment Frameworks. TIMSS & PIRLS International Study Center Lynch School of Education Boston College, Boston, MA
OECD (2013) PISA 2012 Assessment and analytical framework: mathematics, reading, science, problem solving and financial literacy. OECD Publishing, Paris. doi:10.1787/9789264190511-en
Osterlind SJ (2002) Constructing test items: Multiple-choice, constructed-response, performance, and other formats, 2nd edn. Kluwer Academic Publishers, New York
Reckase MD, Ackerman TA, Carlson JE (1988) Building a unidimensional test using multidimensional items. J Educ Meas 25:193–203
Further Reading
Hogan TP, Murphy G (2007) Recommendations for preparing and scoring constructed response items: what the experts say. Appl Measur Educ 20(4):427–441
Mellenbergh GJ (2011) A conceptual introduction to psychometrics: development, analysis, and application of psychological and educational tests. Eleven International Publishing, Hague, Netherlands
Netemeyer RG, Bearden WO, Sharma S (2003) Scaling procedures: issues and applications. Sage, Thousand Oaks, CA
Schmeiser CB, Welch CJ (2006) Test development. In: Brennan R (ed) Educational measurement, 4th edn. Praeger publishers, Westport, CT, pp 307–354
Wu ML (2010) Measurement, sampling and equating errors in large-scale assessments. Educ Measur: Issues Pract 29(4):15–27
Author information
Authors and Affiliations
Corresponding author
Appendices
Discussion Points
-
(1)
In many cases, the clients of a project provide a pre-defined framework, containing specific test blueprints, such as the one shown in Fig. 2.4.
Fig. 2.4 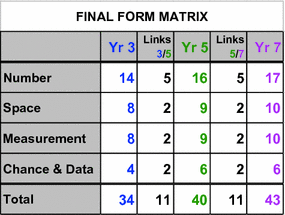
Example client specifications for a test

These frameworks and test blueprints were usually developed with no explicit consideration of the latent trait model. So when we assess items from the perspective of item response models, we often face a dilemma whether to reject an item because the item does not fit the latent trait model, but yet the item belongs to part of the blueprint specified by the clients. How do we reconcile the ideals of measurement against client demands?
-
(2)
To what extent do we make our test “unidimensional”? Consider a spelling test. Spelling words generally have different discriminating power, as shown in the following examples.

Can we select only spelling words that have the same discriminating power to ensure we have “unidimensionality”, and call that a spelling test? If we include a random sample of spelling words with varying discriminating power, what are the consequences in terms of the departure from the ideals of measurement?
-
(3)
Can we assume that the developmental stages from year 1 to year 12 form one unidimensional scale? If not, how do we carry out equating across the year levels?
Exercises
In the SACMEQ project, some variables were combined to form a composite variable. For example, the following seven variables were combined to derive a composite score:
-
24.
How often does a person other than your teacher make sure that you have done your homework?
(Please tick only one box.)
PHMWKDON
(1) | I do not get any homework |
(2) | Never |
(3) | Sometimes |
(4) | Most of the time |
-
25.
How often does a person other than your teacher usually help you with your homework?
(Please tick only one box.)
PHMWKHLP
(1) | I do not get any homework |
(2) | Never |
(3) | Sometimes |
(4) | Most of the time |
-
26.
How often does a person other than your teacher ask you to read to him/her?
(Please tick only one box.)
PREAD
(1) | Never |
(2) | Sometimes |
(3) | Most of the time |
-
27.
How often does a person other than your teacher ask you to do mathematical calculations?
(Please tick only one box.)
PCALC
(1) | Never |
(2) | Sometimes |
(3) | Most of the time |
-
28.
How often does a person other than your teacher ask you questions about what you have been reading?
(Please tick only one box.)
PQUESTR
(1) | Never |
(2) | Sometimes |
(3) | Most of the time |
-
29.
How often does a person other than your teacher ask you questions about what you have been doing in Mathematics?
(Please tick only one box.)
PQUESTM
(1) | Never |
(2) | Sometimes |
(3) | Most of the time |
-
30.
How often does a person other than your teacher look at the work that you have completed at school?
(Please tick only one box.)
PLOOKWK
(1) | Never |
(2) | Sometimes |
(3) | Most of the time |
The composite score, ZPHINT, is an aggregate of the above seven variables.
Q1. In the context of IRT, the value of ZPHINT can be regarded as reflecting the level of a construct, where the seven individual variables are manifest variables. In a few lines, describe what this construct may be.
Q2. For the score of the composite variable to be meaningful and interpretable in the context of IRT, what are the underlying assumptions regarding the seven indicator variables?
Q3. In evaluating the quality of test items, which one of the following is the most undesirable outcome for an item?
The item is difficult and less than 25% of the students obtained the correct answer |
One distractor attracted only 5% of the responses. That is, one distractor is not “working” well |
The percentage correct for high ability students is about the same as the percentage correct for low ability students |
A lot of students skipped this question because they don’t know the answer |
Q4. In determining the maximum score of an item (e.g., an item is worth two or four marks), which of the following is the most important consideration?
The number of steps needed to reach the final answer |
The difficulty of the question. The more difficult, the higher the maximum score should be |
The range of possible responses. If there are more different responses, there should be more score points |
The extent to which a question can separate good and poor students |
Q5. Answer TRUE or FALSE to the following statement:
For an item where the maximum score is more than 1 (e.g., an item with a maximum score of 3), the scores (0, 1, 2, 3) should reflect increasing difficulties of the expected responses. That is, the assignment of the scores to responses should reflect an increasing ability, where a student receiving a higher score is expected to have a higher ability than a student receiving a lower score on this item.
TRUE/FALSE
Q6. Can you have a think about Questions 4 and 5. Write a short summary about the considerations of the assignment of partial credit scores within an item, and across items?
Rights and permissions
Copyright information
© 2016 Springer Nature Singapore Pte Ltd.
About this chapter
Cite this chapter
Wu, M., Tam, H.P., Jen, TH. (2016). Construct, Framework and Test Development—From IRT Perspectives. In: Educational Measurement for Applied Researchers. Springer, Singapore. https://doi.org/10.1007/978-981-10-3302-5_2
Download citation
DOI: https://doi.org/10.1007/978-981-10-3302-5_2
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-3300-1
Online ISBN: 978-981-10-3302-5
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)