
Abstract
Many modern parsers identify the head word of each constituent they find. This makes it possible to identify the word-to-word dependencies implicit in a parse. Some parsers, known as dependency parsers, even return these dependencies as their primary output. Why bother to identify dependencies? The typical reason is to model the fact that some word pairs are more likely than others to engage in a dependency relationship.
This is a preview of subscription content, log in via an institution.
Buying options
Tax calculation will be finalised at checkout
Purchases are for personal use only
Learn about institutional subscriptionsNotes
- 1.
In a phrase-structure parse, if phrase X headed by word token x is a subconstituent of phrase Y headed by word token \(y \neq x\), then x is said to depend on y. In a more powerful compositional formalism like LTAG or CCG, dependencies can be extracted from the derivation tree.
- 2.
- 3.
In this paper, we consider only a crude notion of “closeness”: the number of intervening words. Other distance measures could be substituted or added (following the literature on heavy-shift and sentence comprehension), including the phonological, morphological, syntactic, or referential (given/new) complexity of the intervening material (Gibson, 1998). In parsing, the most relevant previous work is due to Collins, (1997), Klein and Manning, (2003c), and McDonald et al. (2005), discussed in more detail in Section 8.7.
- 4.
Whereas *a politician taller and *a taller-than-all-her-rivals politician are not allowed. The phenomenon is pervasive. Other examples: a sleeping baby vs. a baby sleeping in a crib; a gun-toting honcho vs. a honcho toting a gun; recently seen friends vs. friends seen recently.
- 5.
This actually splits the heavy left dependent [an aardvark who …] into two non-adjacent pieces, moving the heavy second piece. By slightly stretching the aardvark-who dependency in this way, it greatly shortens aardvark-walked. The same is possible for heavy, non-final right dependents: I met an aardvark yesterday who had circumnavigated the globe again stretches aardvark-who, which greatly shortens met-yesterday. These examples illustrate (3) and (2) respectively. However, the resulting non-contiguous constituents lead to non-projective parses that are beyond the scope of this paper; see Section 8.8.
- 6.
There is a straightforward generalization to weighted SBGs, which need not have a stochastic generative model.
- 7.
It is equivalent to the “dependency!model with valence ” of Klein and Manning, (2004).
- 8.
The SHAG notation was designed to highlight the connection to non-split HAGs.
- 9.
In the present paper, we adopt the simpler and slightly more flexible SBG formalism of Eisner, (2000), which allows explicit word senses, but follow the asymptotically more efficient SHAG parsing algorithm of Eisner and Satta, (1999), in order to save a factor of g in our runtimes. Thus Fig. 8.2 presents a version of the Eisner–Satta SHAG algorithm that has been converted to work with SBGs, exactly as sketched and motivated in footnote 6 of Eisner and Satta, (1999).
This conversion preserves the asymptotic runtime of the Eisner-Satta algorithm. However, notice that the version in Fig. 8.2 does have a practical inefficiency, in that Start-Left nondeterministically guesses each possible sense \(w \in W_h\), and these g senses are pursued separately. This inefficiency can be repaired as follows. We should not need to commit to one of a word’s g senses until we have seen all its left children (in order to match the behavior of the Eisner–Satta algorithm, which arrives at one of g “flip states” in the word’s FSA only by accepting a sequence of children). Thus, the left triangles and left trapezoids of Fig. 8.2 should be simplified so that they do not carry a sense :w at all, except in the case of the completed left triangle (marked F) that is produced by Finish-Left. The Finish-Left rule should nondeterministically choose a sense w of W h according to the final state q, which reflects knowledge of W h ’s sequence of left children.
For this strategy to work, the transitions in L w (used by Attach-Left) clearly may not depend on the particular sense \(w \in W_h\) but only on W h . In other words, all \(L_w: w \in W_h\) are really copies of a shared \(L_{W_h}\), except that they may have different final states. This slightly inelegant restriction on the SBG involves no loss of generality, since the nondeterministic shared \(L_{W_h}\) is free to branch as soon as it likes onto paths that commit to the various senses w.
We remark without details that this modification to Fig. 8.2, which defers the choice of w for as long as possible, could be obtained mechanically as an instance of the speculation transformation of Eisner and Blatz, (2007). Speculation could similarly be used to extend the trick to the lattice parsing of Section 8.3.7, where a left triangle would commit immediately to the initial state of its head arc but defer committing to the full head arc for as long as possible.
- 10.
- 11.
It is an arbitrary decision for a dependency’s length to include the length of its right word but not the length of its left word. We adopt that convention only for consistency with our earlier definition of dependency length, and to simplify the relationship between dependency length and derivation width. It might however be justified in terms of incremental parsing , since it encodes the wait time once the left word has been heard until the right word is fully available to link to it.
- 12.
This exclusion ensures that when we combine two such derivations using Complete or Attach, then the consequent derivation’s width is always the sum of its antecedent derivations’ widths. Recall from the first bullet point above that the same exclusion was used when defining the weight of an item, and for the same reason.
- 13.
One could change the arc lengths to measure not in words but in one of the other measurement units from footnote 3.
- 14.
Although uniform-cost search will still terminate, provided that all cycles in Ω have positive cost. All sufficiently wide items will then have a cost worse than that of the best parse, so only finitely many items will pop from the priority queue.
- 15.
The shortest-path distances between all state pairs can be precomputed in \(O(n^3+m)\) time using the Floyd–Warshall algorithm.
This preprocessing time is asymptotically dominated by the runtime of Fig. 8.2.
- 16.
A related trick is to convert Ω to a trie (if it is acyclic). This makes the lower bound exact by ensuring that there are never multiple paths from i to j, but potentially increases the size of Ω exponentially.
- 17.
For the expected-width case, each item must maintain both \(\sum_d p(d) \varDelta(d)\) and \(\sum_d p(d)\), where d ranges over derivations. These quantities can be updated easily, and their ratio is the expected width.
- 18.
This is more precise than using the \(\bar{\varDelta}\) of the consequent, which is muddied by other derivations that are irrelevant to this dependency length.
- 19.
Heads were extracted for English using Michael Collins’ rules and for Chinese using Fei Xia’s rules (defaulting in both cases to right-most heads where the rules fail). German heads were extracted using the TIGER Java API; we discarded all resulting dependency structures that were cyclic or unconnected (6%).
- 20.
In all cases, we measure runtime abstractly by the number of items built and pushed on the agenda, where multiple ways of building the same item are counted multiple times. The items in question are
 , and in the case of Fig. 8.4, also
, and in the case of Fig. 8.4, also  and
and 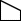 .) Note that if the agenda is a general priority queue
, then popping an item takes logarithmic time, although pushing an item can be achieved in constant time using a Fibonacci-heap implementation.
.) Note that if the agenda is a general priority queue
, then popping an item takes logarithmic time, although pushing an item can be achieved in constant time using a Fibonacci-heap implementation. - 21.
Owing to our deficient model. A log-linear or discriminative model would be trained to correct for overlapping penalties and would avoid this risk. Non-deficient generative models are also possible to design, along lines similar to footnote 22.
- 22.
One proof is to construct a strongly equivalent CFG without center-embedding (Nederhof, 2000). Each nonterminal has the form \(\langle w,q,i,j\rangle\), where \(w \in \varSigma\), q is a state of L w or R w , and \(i,j \in \{0,1,\ldots k-1,\geq k\}\). We leave the details as an exercise.
- 23.
Any dependency covering the child must also be broken to preserve projectivity. This case arises later; see footnote 34.
- 24.
Although our projective parser will still not be able to find it if it is non-projective (possible in German). Arguably we should have defined a more aggressive grafting procedure that produced projective parses, but we did not. See Section 8.8 for discussion of non-projective vine grammar parsing, which would always be able to recover the best feasible parse.
- 25.
The full runtime is \(O(nE)\), where E is the number of FSA edges, or for a tighter estimate, the number of FSA edges that can be traversed by reading ω.
- 26.
With a small change that when two items are combined, the right item (rather than the left) must be simple (in the terms of Eisner, (2000)).
- 27.
For the experiments of Section 8.6.1, where k varied by type, we restricted these rules as tightly as possible given h and h′.
- 28.
We do not specialize the vine items, i.e., items whose left boundary is \(0{\!:\!} \textbf{\$}\). Vine items can have unbounded width \(\varDelta > k\), but it is unnecessary for them to record this width because it never comes into play.
- 29.
As in footnote 15, we may precompute the shortest-path distances between all state pairs, but here we only need to do this for the mM pairs whose distances are \(\leq k\). Using a simple agenda-based relaxation algorithm that derives all such pairs together with their shortest-path distances, this takes time \(O(mMb)\), where \(b \leq M'\) is an upper bound on a state’s number of outgoing transitions of length \(\leq k\). This preprocessing time is asymptotically dominated by the runtime of the main algorithm.
- 30.
This test is more efficient to implement in a chart parser than requiring the width of the consequent to be \(\leq k\). It rules out more combinations, since with lower-bound widths, a consequent of width \(\leq k\) could be produced from two antecedents of total width > k. (The shortest path connecting its endpoints may not pass through the midpoint where the antecedents are joined.)
- 31.
For instance, suppose the best derivation of an item of width 3 happens to cover a subpath in Ω of length 5. The item will nonetheless permitted to combine with an adjacent item of width \(k-3\), perhaps resulting in the best parse overall, with a dependency of length \(k+2\).
- 32.
Note that \(k(h,c,\textrm{right})=7\) bounds the width of;
 . For a finer-grained approach, we could instead separately bound the widths of
. For a finer-grained approach, we could instead separately bound the widths of  and , say by \(k_r(h,c,\textrm{right})=4\) and \(k_l(h,c,\textrm{right})=2\).
and , say by \(k_r(h,c,\textrm{right})=4\) and \(k_l(h,c,\textrm{right})=2\). - 33.
In the case of the German TIGER corpus, which contains non-projective dependencies, we first make the training trees into projective vines by raising all non-projective child nodes to become heads on the vine.
- 34.
Not counting dependencies that must be broken indirectly in order to maintain projectivity. (If word 4 depends on word 7 which depends on word 2, and the \(4 \rightarrow 7\) dependency is broken, making 4 a root, then we must also break the \(2 \rightarrow 7\) dependency.)
- 35.
Of course, this still allows right-branching or left-branching to unbounded depth.
- 36.
The obvious reduction for unsplit head automaton grammars, say, is only \(O(n^4) \rightarrow O(n^3 k)\), following Eisner and Satta, (1999). Alternatively, one can convert the unsplit HAG to a split one that preserves the set of feasible (length \(\leq k\)) parses, but then g becomes prohibitively large in the worst case.
- 37.
Note that the vine grammar as we have presented it is a deficient model, since unless we reparameterize it to consider dependency lengths, it also allocates some probability to infeasible parses that are not included in this sum. However, the short-dependency preference suggests that these infeasible parses should not usually contribute much to the total probability that we seek.
 , and in the case of Fig.
, and in the case of Fig.  and
and 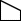 .) Note that if the agenda is a general priority queue
, then popping an item takes logarithmic time, although pushing an item can be achieved in constant time using a Fibonacci-heap implementation.
.) Note that if the agenda is a general priority queue
, then popping an item takes logarithmic time, although pushing an item can be achieved in constant time using a Fibonacci-heap implementation. . For a finer-grained approach, we could instead separately bound the widths of
. For a finer-grained approach, we could instead separately bound the widths of  and
and References
Abney, S.P. (1991). Parsing by chunks. In R. Berwick, S. Abney, and C. Tenny (eds.), Principle-Based Parsing: Computation and Psycholinguistics. Dordrecht: Kluwer.
Appelt, D.E., J.R. Hobbs, J. Bear, D. Israel, and M. Tyson (1993). FASTUS: A finite-state processor for information extraction from real-world text. In Proceedings of the 13th International Joint Conference on Artificial Intelligence (IJCAI), Chambery, pp. 1172–1178.
Bangalore, S. and A.K. Joshi (1999). Supertagging: an approach to almost parsing. Computational Linguistics 25(2), 237–265.
Bertsch, E. and M.-J. Nederhof (1999). Regular closure of deterministic languages. SIAM Journal on Computing 29(1), 81–102.
Bikel, D. (2004). A distributional analysis of a lexicalized statistical parsing model. In Proceedings of 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP), Barcelona.
Caraballo, S.A. and E. Charniak (1998). New figures of merit for best-first probabilistic chart parsing. Computational Linguistics 24(2), 275–98.
Charniak, E., S. Goldwater, and M. Johnson (1998). Edge-based best-first chart parsing. In Proceedings of 6th Workshop on Very Large Corpora, Montreal, pp. 127–133.
Charniak, E. and M. Johnson (2005). Coarse-to-fine n-best parsing and maxent discriminative reranking. In Proceedings of 43rd Annual Meeting of the Association for Computational Linguistics (ACL), Ann Arbor, Michigan, pp. 173–180.
Chelba, C. and F. Jelinek (2000). Structured language modeling. Computer Speech and Language 14, 283–332.
Chen, S. (1995). Bayesian grammar induction for language modeling. In Proceedings of 33rd Annual Meeting of the Association for Computational Linguistics (ACL), Cambridge, Massachussetts, pp. 228–235.
Chiang, D. (2005). A hierarchical phrase-based model for statistical machine translation. In Proceedings of 43rd Annual Meeting of the Association for Computational Linguistics (ACL), Ann Arbor, Michigan, pp. 263–270.
Church, K.W. (1980). On memory limitations in natural language processing. Master’s thesis, MIT.
Collins, M. (1997). Three generative, lexicalised models for statistical parsing. In Proceedings of 33rd Annual Meeting of the Association for Computational Linguistics (ACL), Madrid, pp. 16–23.
Dreyer, M., D.A. Smith, and N.A. Smith (2006). Vine parsing and minimum risk reranking for speed and precision. In Proceedings of 10th Conference on Computational Natural Language Learning, New York.
Eisner, J. (2000). Bilexical grammars and their cubic-time parsing algorithms. In H. Bunt and A. Nijholt (eds.), Advances in Probabilistic and Other Parsing Technologies. Dordrecht: Kluwer, pp. 29–61.
Eisner, J. and J. Blatz (2007). Program transformations for optimization of parsing algorithms and other weighted logic programs. In Proceedings of FG.
Eisner, J., E. Goldlust, and N.A. Smith (2005). Compiling Comp Ling: practical weighted dynamic programming and the Dyna language. In Proceedings of Human Language Technology and Conference on Empirical Methods in Natural Language Processing (HLT/EMNLP), Vancouver, pp. 281–290.
Eisner, J. and G. Satta (1999). Efficient parsing for bilexical CFGs and head automaton grammars. In Proceedings of 37th Annual Meeting of the Association for Computational Linguistics (ACL), University of Maryland, pp. 457–480.
Eisner, J. and N.A. Smith (2005). Parsing with soft and hard constraints on dependency length. In Proceedings of the 9th International Workshop on Parsing Technologies (IWPT), Vancouver, pp. 30–41.
Frazier, L. (1979). On Comprehending Sentences: Syntactic Parsing Strategies. Ph. D. thesis, University of Massachusetts.
Gibson, E. (1998). Linguistic complexity: Locality of syntactic dependencies. Cognition 68, 1–76.
Gildea, D. and D. Temperley (2007). Optimizing grammars for minimum dependency length. In Proceedings of 45th Annual Meeting of the Association for Computational Linguistics (ACL), Prague, pp. 184–191.
Goodman, J. (1999). Semiring parsing. Computational Linguistics 25(4), 573–605.
Grefenstette, G. (1996). Light parsing as finite-state filtering. In Proceedings of the ECAI Workshop on Extended Finite-State Models of Language, Budapest, pp. 20–25.
Hall, K. (2007). k-best spanning tree parsing. In Proceedings of 45th Annual Meeting of the Association for Computational Linguistics (ACL), Prague, pp. 392–399.
Hawkins, J. (1994). A Performance Theory of Order and Constituency. Cambridge: Cambridge University Press.
Hindle, D. (1990). Noun classification from predicate-argument structure. In Proceedings of 28th Annual Meeting of the Association for Computational Linguistics (ACL), Pittsburgh, pp. 268–275.
Hobbs, J.R. and J. Bear (1990). Two principles of parse preference. In Proceedings of the 13th International Conference on Computational Linguistics (COLING), Helsinki, pp. 162–167.
Klein, D. and C.D. Manning (2003a). A\(^\ast\) parsing: Fast exact viterbi parse selection. In Proceedings of the Conference on Human Language Technology and the North Amercan Chapter of the Association for Computational Linguistics (HLT-NAACL), Edmonton, pp. 40–47.
Klein, D. and C.D. Manning (2003b). Accurate unlexicalized parsing. In Proceedings of 41st Annual Meeting of the Association for Computational Linguistics (ACL), Sapporo, pp. 423–430.
Klein, D. and C.D. Manning (2003c). Fast exact inference with a factored model for natural language parsing. In S. Becker, S. Thrun, and K.Obermayer (eds.), Advances in Neural Information Processing Systems (NIPS 2002), MIT Press, Cambridge, MA, pp. 3–10.
Klein, D. and C.D. Manning (2004). Corpus-based induction of syntactic structure: models of dependency and constituency. In Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics (ACL), Barcelona, pp. 479–486.
Liu, Y., A. Stolcke, E. Shriberg, and M. Harper (2005). Using conditional random fields for sentence boundary detection in speech. In Proceedings of 43rd Annual Meeting of the Association for Computational linguistics (ACL), Ann Arbor, Michigan, pp. 451–458.
McDonald, R., K. Crammer, and F. Pereira (2005). Online large-margin training of dependency parsers. In Proceedings of 43rd Annual Meeting of the Association for Computational Linguistics (ACL), Ann Arbor, Michigan, pp. 91–98.
McDonald, R., F. Pereira, K. Ribarov, and J. Hajič (2005). Non-projective dependency parsing using spanning tree algorithms. In Proceedings of Human Language Technology and Conference on Empirical Methods in Natural Language Processing (HLT/EMNLP), Vancouver, pp. 523–530.
Miyao, Y. and J. Tsujii (2002). Maximum entropy estimation for feature forests. In Proceedings of the Conference on Human Language Technology (HLT), Edmonton, pp. 1–8.
Nederhof, M.-J. (2000). Practical experiments with regular approximation of context-free languages. Computational Linguistics 26(1), 17–44.
Nederhof, M.-J. (2003). Weighted deductive parsing and Knuth’s algorithm. Computational Linguistics 29(1), 135–143.
Reynar, J.C. and A. Ratnaparkhi (1997). A maximum entropy approach to identifying sentence boundaries. In Proceedings of the 5th Applied Natural Language Conference, Washington, pp. 16–19.
Schafer, C. and D. Yarowsky (2003). A two-level syntax-based approach to Arabic-English statistical machine translation. In Proceedings of the Workshop on Machine Translation for Semitic Languages, New Orleans.
Shieber, S. and Y. Schabes (1990). Synchronous tree adjoining grammars. In Proceedings of the 13th International Conference on Computational Linguistics (COLING), Helsinki.
Sikkel, K. (1997). Parsing Schemata: A Framework for Specification and Analysis of Parsing Algorithms. Texts in Theoretical Computer Science. Berlin, Heidelberg, New York: Springer.
Smith, N.A. (2006). Novel Estimation Methods for Unsupervised Discovery of Latent Structure in Natural Language Text. Ph. D. thesis, Johns Hopkins University.
Smith, N.A. and J. Eisner (2005). Contrastive estimation: Training log-linear models on unlabeled data. In Proceedings of 43rd Annual Meeting of the Association for Computational Linguistics (ACL), Ann Arbor, Michigan, pp. 354–362.
Smith, N.A. and J. Eisner (2006). Annealing structural bias in multilingual weighted grammar induction. In Proceedings of 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics (COLING-ACL), Sydney, pp. 569–576.
Stolcke, A. (1995). An efficient probabilistic context-free parsing algorithm that computes prefix probabilities. Computational Linguistics 21(2), 165–201.
Tarjan, R.E. (1977). Finding optimum branchings. Networks 7(1), 25–35.
Taskar, B., D. Klein, M. Collins, D. Koller, and C. Manning (2004). Max-margin parsing. In Proceedings of 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP), Barcelona, pp. 1–8.
Temperley, D. (2007). Minimization of dependency length in written English. Cognition 105, 300–333.
Turian, J. and I.D. Melamed (2006). Advances in discriminative parsing. In Proceedings of 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguistics (COLING-ACL), Sydney, pp. 873–880.
Wu, D. (1997). Stochastic inversion transduction grammars and bilingual parsing of parallel corpora. Computational Linguistics 23(3), 377–404.
Acknowledgements
This work was supported by NSF ITR grant IIS-0313193 to the first author and a fellowship from the Fannie and John Hertz Foundation to the second author. The views expressed are not necessarily endorsed by the sponsors. The authors thank Mark Johnson, Eugene Charniak, Charles Schafer, Keith Hall, and John Hale for helpful discussion and Elliott Drébek and Markus Dreyer for insights on (respectively) Chinese and German parsing. They also thank an anonymous reviewer for suggesting the German experiments.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2010 Springer Science+Business Media B.V.
About this chapter
Cite this chapter
Eisner, J., Smith, N.A. (2010). Favor Short Dependencies: Parsing with Soft and Hard Constraints on Dependency Length. In: Bunt, H., Merlo, P., Nivre, J. (eds) Trends in Parsing Technology. Text, Speech and Language Technology, vol 43. Springer, Dordrecht. https://doi.org/10.1007/978-90-481-9352-3_8
Download citation
DOI: https://doi.org/10.1007/978-90-481-9352-3_8
Published:
Publisher Name: Springer, Dordrecht
Print ISBN: 978-90-481-9351-6
Online ISBN: 978-90-481-9352-3
eBook Packages: Humanities, Social Sciences and LawSocial Sciences (R0)