
Zusammenfassung
In diesem Kapitel werden die wichtigsten Konzepte des modernen Node-based Compositings vorgestellt. Da das Compositing der letzte Schritt in der Produktionspipeline vor dem Mastering (Digital Intermediate) ist, werden dort alle in den vorhergehenden Kapiteln kreierten Assets zu einem stimmigen Gesamtbild kombiniert. Im ersten Abschnitt werden deshalb Verfahren zur Kombination von Bildern ohne Maske vorgestellt. Im zweiten Abschnitt werden die verschiedenen Erscheinungsformen des Alpha-Kanals (vormultipliziert, nichtvormultipliziert und Straight-Alpha) diskutiert. Ein anderer wichtiger Gesichtspunkt ist die Integration von 3D-Computergrafiken (CG) in Live-Action-Footage. Set-Erweiterungen sind ein weiteres wichtiges Anwendungsgebiet für das Compositing. Im nächsten Abschnitt werden allgemeine und spezielle Compositing-Aufgaben vorgestellt. Das Kapitel wird mit dem Konzept des Depth- und Deep-Compositings abgeschlossen.
Die Technik des Compositings geht in ihren Ursprüngen zurück bis zu den Anfängen des Filmemachens. Wesentliche Entwicklungsstufen wurden bereits in Kap. 8 in Zusammenhang mit dem Matte-Painting, dem Generieren von Masken und vor allem mit Chroma-Keying vorgestellt. In den frühen 1990er-Jahren kam es mit dem Wechsel auf die digitale Plattform zu einer grundlegenden Revolution der Art und Weise, wie Bilder unterschiedlicher Herkunft kombiniert werden. Die Basistechnik des Compositings, das Ausschneiden und Replatzieren der Bildelemente, wurde wesentlich erleichtert. Vor allem die Möglichkeit der Farbmanipulation ermöglichte es, andere Farben als Blau für den zu separierenden Hintergrund (bluescreen) zu nutzen.
Die rasante Entwicklung der verhältnismäßig günstigen Desktop Computer versetzten die Compositing-Artists in die Lage, mit neuartigen Methoden der Kombinationen von Bildelementen unterschiedlichster Herkunft, nie gesehene Welten und Aktionen zu kreieren. Bilder, als technische Reproduktionen der Realität, haben eine früher kaum vorstellbare Präsenz gewonnen. Digitale Fotoapparate aller Preisklassen und vor allem die Kamerafunktion der Smartphones erzeugen eine ständig anschwellende Bilderflut. Professionelle Produktionen müssen eine Qualität bieten, die sie deutlich von der Masse der Bilder absetzt. Das hat faktisch zur Folge, dass Herangehensweisen und Werkzeuge, nicht denen der Amateurproduktionen entsprechen. Im Bereich des Compositing dominieren im professionellen Einsatz Node-basierte Programme wie Blackmagicdesign Fusion Footnote 1, das in den 1990er und 2000er-Jahren sehr erfolgreiche Shake , das Apple nach der Übernahme konzeptionell nicht weiterentwickelte und das inzwischen als Standard anzusehende Nuke/NukeX der englischen Firma The Foundry.Footnote 2
Ihre Graphenstruktur ermöglicht diesen Anwendungen, beliebige Verbindungen zwischen den Bearbeitungsschritten zu erzeugen, sodass zum Beispiel Masken mehrmals genutzt und kombiniert werden können. Auch die für die VFX- und Werbeindustrie unverzichtbare effiziente Verknüpfung zwischen 2D- und 3D-Räumen ist eine Stärke dieser Programme. Die in den Nodes (Operatoren) implementierten Algorithmen ermöglichen nicht nur die Bearbeitung der Farbinformationen von Bildmaterial, sondern auch das Einlesen von 3D-Objekten und deren Positionen im 3D-Raum als diskrete Werte oder auch als Vektordaten. Hinzu kommen Kamera- und Objektanimationen, Punktwolken und weitere Vektordaten zum Generieren von Bewegungsunschärfe und Informationen für verschiedene Anwendungen, die sich mit der Tiefenstaffelung auseinandersetzen.
In diesem Kapitel werden die wichtigsten Konzepte des modernen Node-based Compositings vorgestellt. Da das Compositing der letzte Schritt in der Produktionspipeline vor dem Mastering (Digital Intermediate) ist, werden dort alle in den vorhergehenden Kapiteln kreierten Assets zu einem stimmigen Gesamtbild kombiniert. Der Zuschauer kann dann nicht mehr erkennen, aus welchen Einzelteilen ein Bild zusammengesetzt wurde. Naturgemäß bilden die Möglichkeiten der Bildverknüpfung die Basis für jedes Compositing. Im ersten Abschnitt werden deshalb Verfahren zur Kombination von Bildern ohne Maske vorgestellt. Je nach Implementierung werden diese auch als Füllmethode oder Überblendungsmodi (engl. blend modes ) bezeichnet.
Im zweiten Abschnitt werden die verschiedenen Erscheinungsformen des Alpha-Kanals (vormultipliziert, nicht-vormultipliziert und Straight-Alpha) diskutiert. Der richtige Umgang mit diesen Formen ist die Grundlage für ein professionelles Compositing und sehr komplex.
Ein anderer wichtiger Gesichtspunkt ist die Integration von 3D-Computergrafiken (CG) in Live-Action-Footage. Dies geschieht mithilfe einer Reihe von Verfahren (Multi-Pass, Multi-Layer, Multi-Channel), die an die Erfordernisse einer modernen Produktionspipeline angepasst sind und die Arbeiten effizienter gestalten.
Set-Erweiterungen sind ein weiteres wichtiges Anwendungsgebiet für das Compositing.
Ab einem bestimmten Budget gibt es kaum Produktionen mit Spielfilmcharakter, die ohne diese kostensenkende Technologie auskommen. Digitale Set-Erweiterungen müssen bei geschickter Planung selbst bei Kamerabewegungen mit starker Parallaxenänderung nicht zwingend im 3D-Raum modelliert werden. In den letzten Jahren hat sich eine effiziente Produktionsweise etabliert, bei der fotorealistischer Inhalt auf im 3D-Raum verteilte 2D-Objekte (engl. cards) projiziert wird. Diese Anwendung ist als 2.5D-Technologie bekannt und wird auch für Establishing-Shots, Digital-Matte-Paintings, das Entfernen von Bild- und Szenenfehlern, die Beseitigung von regional falschen oder unpassenden und von anachronistischen Details eingesetzt.
Im nächsten Abschnitt werden allgemeine und spezielle Compositing-Aufgaben vorgestellt. Aus Platzgründen erfolgen nur eine Auswahl und ein allgemeiner Überblick. Es sei hier auf weiterführende Literatur verwiesen, in der dieses Thema in größerem Detail diskutiert wird (Brinkmann 1999; Okun und Zwermann 2010; Wright 2010).
Immer mehr an Bedeutung gewinnt die Verarbeitung von Daten, die die Tiefe von Objekten spezifizieren. Hier ist vor allem die Konvertierung von Mono-Filmmaterial zu Stereo3D ein Einsatzgebiet. Aber auch die Veränderung des Fokus – tiefenabhängige Effekte wie Nebel, Staub und die Schleierbildung bei Stadtaufnahmen – wird mit diesen Technologien ermöglicht und trägt in nicht unerheblichem Maße zu einem realistischen Ergebnis bei.
Das Kapitel wird mit dem Konzept des Deep-Compositings abgeschlossen, bei dem vor allem die Tiefeninformationen halb transparenter Objekte wie Regen, Nebel, Schnee, Rauch, Feuer, Wasser und Staub pixelweise vorliegen, sodass ein Charakter- oder anderweitiges Objekt an eine andere Position im Compositing eingeordnet werden kann, ohne die Szene neu rendern zu müssen. Dieses Verfahren ist recht neu und viele Firmen sind zurückhaltend mit seinem Einsatz, da ein Frame Daten von mehreren Gigabyte enthalten kann.
10.1 Verknüpfung von Bildern ohne Maske
Obwohl im Compositing die Over-Node (siehe Abschn. 10.2.6) der zentrale Operator ist, da sie maskierte Bilder miteinander verknüpft, gibt es auch die Möglichkeit, Bilder ohne Maske zu kombinieren. Dies erfolgt mit zum Teil komplexen mathematischen Formeln (siehe Tab. 10.3), bei denen die RGB-Werte zweier Elemente – Image A und Image B – verknüpft werden. Diese maskenlosen Verfahren sind als sogenannte Überblendungsmodi bekannt.
Die beiden Bilder A und B können zwar über Masken im Alpha-Kanal verfügen, diese werden aber nicht für die Berechnung der RGB-Werte hinzugezogen. Sollten die Masken weiterverwendet werden, ist darauf zu achten, dass diese durch die Überblendungsoperationen nicht verändert werden. Moderne Compositing-Anwendungen bieten auch die Möglichkeit, die Alpha-Kanäle – oder andere Maskenkanäle – von der Bearbeitung auszuschließen.
Pionierarbeit bei den Überblendungsmodi hat Adobe Inc. in Photoshop Footnote 3 geleistet und eine Reihe proprietärer Algorithmen implementiert. Da die Berechnungsgrundlagen nicht veröffentlicht wurden, gab es Anstrengungen, diese mit Reverse-Engineering-Methoden nachzustellen; je nach Implementierung mit mehr oder weniger Nähe zum ursprünglichen Algorithmus.
In Photoshop gilt für Überblendungsmodi, dass die dem Algorithmus zugeordnete Ebene (engl. layer) Image A ist. Alle darunter liegenden Ebenen kombiniert sind Image B. Um mehr Flexibilität bei der Einbindung dieser Algorithmen zu erreichen, gibt es einerseits die Möglichkeit, den Überblendungsmodus auf die darunter liegende Ebene zu beschränken. Andererseits können Bilder in Gruppen zusammengefasst werden, um die Wirkung der Überblendungsmodi zu kontrollieren. Diese Herangehensweise in Photoshop gilt im Prinzip ebenso für Timeline-basierendes Compositing wie in Adobe After Effects Footnote 4.
10.1.1 Die Opazitäts-Überblendung
Die Opazitäts -Überblendung ist der älteste Überblendungsmodus und dementsprechend weit verbreitet. Hierbei werden gewichtete Anteile von Image A und Image B addiert. Der Modus heißt deshalb auch Mix oder im Englischen add mix . In Gl. 10.1 ist die mathematische Berechnung dargestellt, wobei O das Ergebnis der Operation und V m der Gewichtungsfaktor (prozentualer Anteil des Images am Gesamtergebnis) ist.
Wird der Wert von V m animiert, entsteht ein Dissolve-Übergang. Wird vom Wert 0 zum Wert 1 animiert, erfolgt eine Überblendung von Image A zu Image B. Umgekehrt wird Image B über Image A geblendet.
Der Dissolve-Übergang sollte mit Vorsicht verwendet werden, da er in der Film-Grammar, das heißt, in der Art und Weise, wie Film wahrgenommen wird, angibt, dass zwischen Aufnahme A und Aufnahme B Zeit vergangen ist. Noch dramatischer ist ein Übergang von Image A zu Schwarz (engl. drop to black ). Dies bedeutet, dass sehr viel Zeit vergangen ist. Bei kinematischen Werken in Spielfilmlänge können ein oder zwei dieser Übergänge eingesetzt werden, bei Kurzfilmen nur in wirklich bedeutungsvollen Situationen. Ein Übergang zu Weiß indiziert meist ein Flashback: Man befindet sich in den Gedanken des Protagonisten.
Für diese Dissolve -Übergänge wird oft ein grafisches Muster verwendet, das in den zu überblendenden Bildern ähnlich an der gleichen Position vorhanden ist. Damit können vor allem Zeit- und Ortssprünge interessanter gestaltet werden. Als zu Beginn von Sergio Leones Film Once Upon A Time in America Noodles (Robert De Niro) im Chinesischen Salon durch einen Zeitungsartikel schmerzhaft daran erinnert wird, dass er seine drei Freunde offenbar verraten hat, fängt die Kamera eine neben der Liege stehende Petroleumlampe ein, die in der Unschärfe verschwindet. Aus der Unschärfe kommt eine ebenso runde Straßenlaterne, die den Übergang der realen Szene in die schmerzlichen Erinnerungen nachvollziehbar macht. In Abb. 10.1 ist ein Dissolve-Übergang dargestellt, der ein vertikales Muster verwendet.

Opazitäts-Überblendung unter Nutzung eines grafischen Elements
10.1.2 Die Addieren-Überblendung
Der Addieren -Überblendungsmodus gehört zu den meist genutzten Methoden zum Kombinieren von Bildern, vor allem da er auch Bestandteil komplexerer Algorithmen ist. Auch in 3D-Programmen findet er Verwendung. Dort ermöglicht er die Kombination der in den Buffern liegenden Berechnungen der unterschiedlichen Lichtkomponenten (diffus, spektral, glossy etc.) zu einem Beauty-Pass. Um diese Passes selbst wiederum bei Verwendung der ursprünglichen Berechnungsgrundlage im Compositing zu kombinieren, sollten die einzeln vorliegenden Renderpasses ebenfalls addiert werden, damit das gleiche Ergebnis zustande kommt. Die Mathematik ist einfach (Gl. 10.2), die Entsprechung in Photoshop ist Linear Abwedeln .
Der Addieren-Modus wird vor allem dann verwendet, wenn sich helle Elemente – vor allem Lichteffekte – vor schwarzem Hintergrund befinden. Der Hintergrund muss komplett schwarz (null) sein, da eine Addition mit null keine Veränderung hervorruft (siehe Abb. 10.2). Andere Werte als null, selbst geringe Werte, führen zu einer Veränderung der entsprechenden Stellen des Hintergrundbildes. Beim Addieren-Modus kann der Anteil von Image A und Image B am Endergebnis festgelegt werden.

Addieren-Überblendung
Ein nicht zu unterschätzendes Problem bereitet die Tatsache, dass durch die Addition mehrerer Bilder ein Ergebnis entsteht, das die Auflösung der Farbkanäle überschreiten kann. Werden Farbwerte über dem Einheitswert von 1,0 erreicht, spricht man auch vom Clipping. Wie mit diesem umgegangen wird, hängt von der Pipeline ab, in der die Arbeiten ausgeführt werden und der Auflösung des zugrunde liegenden Farbraums. In einer scene-referred linearen 32-Bit-Arbeitsumgebung kann dieses Clipping gewollt sein, vor allem, um sehr helle Elemente für die Bearbeitung an die Digital-Intermediate -Stufe weiterzuleiten. Dort muss allerdings sichergestellt werden, dass nach der finalen Farbkorrektur die Auflösung des Zielfarbraums des Projektors oder des Displays nicht überschritten wird. Zumeist muss das Clipping jedoch vermieden werden, vor allem dann, wenn in einer 8-Bit-Umgebung gearbeitet wird.
Abbildung 10.3 zeigt eine Addition im linearen Arbeitsumfeld, bei der zwei gleiche Graustufenverläufe addiert werden. Bereits zur Hälfte der horizontalen Achse des resultierenden Bildes wird der Wert 1,0 erreicht und im weiteren Verlauf überschritten. Das Bild brennt aus. In Tab. 10.1 werden ein Graustufenverlauf und ein dunkles Bild mit konstanter Helligkeit addiert. Auch hier wird der Wertebereich über 1,0 überschritten. Die entsprechenden Werte der Tabelle sind markiert.

Addieren (Schema)
10.1.3 Die Negativ-Multiplizieren-Überblendung
Negativ Multiplizieren (engl. screen ) ist einer der meist angewendeten und wichtigsten Überblendungsmodi. Wie der englische Name Screen andeutet, liegt der Ursprung im analogen Filmbereich, in dem die grundlegenden Überblendungen mit Negativfilm ausgeführt werden. Die Bearbeitung erfolgt nach Gl. 10.3. Das Ergebnis der Operation ist das Komplement der Multiplikation der komplementären Pixelwerte von Image A und Image B.
Die Screen-Operation ist – ebenso wie der Addieren-Modus – kommutativ, die Reihenfolge beider Bilder spielt keine Rolle. Der große Vorteil bei der Verwendung des Screen-Modus gegenüber dem Addieren ist, dass durch die zugrunde liegende Berechnungsmethode kein Clipping auftritt.
In Tab. 10.2 sind die Ergebnisse der einzelnen Terme in Gl. 10.3 angegeben. Es werden die gleichen Werte verwendet wie in Tab. 10.1. Aufgrund der speziellen mathethematischen Grundlage nähern sich die Werte der höchsten Auflösung (1,0). Sie erreichen diese aber nur, wenn beide Bilder an der betreffenden Stelle den Wert 1,0 haben. Im Resultat überschreiten sie ihn aber nicht. Der Verlauf der resultierenden Kurve ist in Abb. 10.4 dargestellt. Hier ist zu erkennen, dass das finale Bild nicht ausbrennt, sondern einen weichen Graustufenverlauf aufweist.

Negativ-Multiplizieren (Schema)
Der Screen-Modus ist gut geeignet, um die allgemeine Helligkeit unterbelichteter Bilder ohne großen Aufwand zu erhöhen. Da keine Überbelichtungen auftreten können, ist dieses Verfahren sehr leicht zu implementieren. Abbildung 10.5 zeigt das Originalbild und eine zweimalige Anwendung des Negativ-Multiplizieren-Modus.

Negativ-Multiplizieren-Überblendung
Der Screen-Algorithmus lässt sich a priori nicht kontrollieren, da die Mathematik feststeht. Moderne Implementierungen besitzen jedoch einen Mix-Parameter, in der die Gewichtung der Bilder festgelegt werden kann. Das Anwendungsgebiet für Negativ-Multiplizieren ist ähnlich dem des Addieren-Modus, es gilt aber als „feinsinniger“, das heißt, es bleibt mehr Detail vom Hintergrund erhalten und die ausgebrannten Flächen werden reduziert (siehe Abb. 10.6). Umgekehrt dazu können sich im Addieren-Modus Lichter – vor allem im Hintergrund des Bildes – besser durchsetzen.

Vergleich Addieren – Negativ-Multiplizieren
10.1.4 Die Multiplizieren-Überblendung
Während der Addieren- und der Negativ-Multiplizieren-Modus das Bild aufhellen, verdunkelt die Multiplizieren-Operation das Bild. Diese auf den ersten Blick paradoxe Situation – Multiplizieren vervielfacht gewöhnlich die Grundelemente – entstammt der Beschränkung des Arbeitsbereichs des normalisierten Farbraums auf Werte zwischen 0,0 und 1,0. Multipliziert man einen hohen Wert wie 0,9 mit einem noch höheren Wert – zum Beispiel 0,99 – ist das Resultat mit 0,89 niedriger als die beiden Einzelwerte (siehe Abb. 10.7).

Multiplizieren (Schema)
Da die Multiplizieren-Überblendung die Bilder verdunkelt, ist sie prädestiniert für das Einfügen von Schatten und Verdeckungen, weshalb Schatten- und Ambient-Occlusion -Passes multipliziert werden(siehe Abschn. 10.3.3). Auch bei dieser Operation sind die Bilder kommutativ, es spielt im Compositing keine Rolle, welches Image im Eingang A oder B des entsprechenden Operators anliegt.
Es gibt eine Reihe weiterer Anwendungsbereiche für die Multiplikation. Hier können vor allem schwarze oder dunkle Elemente vor weißem Hintergrund komponiert werden. Da die weißen Bereiche des Bildes den Wert 1,0 besitzen, verändern sie ein zu multiplizierendes Bild nicht (Multiplikation mit 1 ergibt den Ausgangswert). Diese Überblendung ist deshalb gut geeignet, Grafiken, Text oder Zahlenwerte – zum Beispiel Slates Footnote 5 – in ein Bild zu schreiben. Diese Zusatzinformationen sind in der Produktionspipeline hilfreich, Quellen zu identifizieren und Synchronisationen zu erleichtern, zum Beispiel im Sounddesign und bei Musikaufnahmen. Dabei ist zu beachten, dass der Hintergrund tatsächlich weiß ist, da er sonst das Bild – wenn auch gering – verdunkelt.
Ein sehr interessanter und auf der analogen Ebene im Zusammenhang mit Matte-Painting und Miniaturen oft angewandter Trick ist der sogenannte Slot-Gag . Dabei werden ausgestanzte Maskenmuster in verschiedenen Bewegungsrichtungen miteinander kombiniert, sodass die sich überlagernden Muster interessante Öffnungen erzeugen, durch die Licht einfällt oder Elemente für die Animation freigegeben werden. Auf diese Weise wurden zum Beispiel im Film Bladerunner (Regie Ridley Scott, USA 1982) sich bewegende Lichter von Luftfahrzeugen realisiert.
Die digitale Entsprechung der sich bewegenden analogen Muster ist das Multiplizieren unterschiedlicher Masken. Eine populäre Anwendung der Slot-Gags sind wandernde Glanzlichter auf einem Text (engl. glint ).
Dabei bewegt sich eine Maske entlang des Textes oder eines anderen Elements, das das Glanzlicht formt, und gibt es partiell frei (vgl. Wright 2010, S. 192 f.).
Abbildung 10.8 zeigt das Vorgehen. Hier wurde eine Vorlage so bearbeitet, dass für den in der Aufnahme gezeigten Text ein vertikaler Sobel-Filter verwendet wurde, um einen dreidimensionalen Effekt zu erhalten. Die Kernmatrix für den sehr oft verwendeten vertikalen Sobel-Filter wird in Gl. 10.5 und die Kernmatrix für einen horizontalen Sobel-Filter in Gl. 10.6 angegeben.

Anwendung der Multiplizieren-Überblendung (Slot-Gag)
Weiterhin bewegt sich eine Roto-Maske entlang des Textes. Werden die Textmaske A und die Roto-Maske B multipliziert, entsteht im Ergebnis ein Slot-Gag (unteres linkes Bild). Das Resultat kann dann weiter bearbeitet werden, wie hier mit dem God-Ray-Effekt .
10.1.5 Die Differenz-Überblendung
Die Differenz -Überblendung ist eine Subtraktion, bei der Minuend und Subtrahend nicht ohne Weiteres ausgetauscht werden können. Dieses ist allerdings anwendungsabhängig.
Ein Problem bei diesem Modus besteht darin, dass auch negative Werte entstehen. Diese werden je nach zugrunde liegendem Arbeitsfarbraum (displaybezogen oder szenenbezogen) unterschiedlich behandelt. Sie können, szenenbezogen, negativ bleiben, werden auf null gekappt oder bei einer absoluten Berechnung als positive Werte weitergegeben. Es ist somit darauf zu achten, welche Implementierung des Algorithmus vorliegt, um keine unvorhersehbaren Ergebnisse zu erhalten.
Aus diesem Grunde eignet sich der Algorithmus auch nicht, Masken miteinander zu verknüpfen. Hier sollten entweder Minimum -/Maximum - oder In-/Out -Operationen verwendet werden, deren Ergebnisse innerhalb des für Masken vorgesehenen Wertebereichs zwischen 0 und 1 bleiben.
Differenz-Überblendungen finden Anwendung, wenn Elemente subtrahiert werden sollen, wie der grüne Überschuss beim Berechnen der Spill-Map . Das größte Einsatzgebiet bietet sich beim Vergleich zweier Bilder. Hier kann genau festgestellt werden, ob diese exakt gleich sind. Eine prominente Implementierung ist die Justierung zweier Beamsplitter-Kameras für Stereo3D-Aufnahmen, da beide Kameras in der Grundeinstellung (Justierung in Parallel-Stellung) das exakt gleiche Bild liefern sollten. In den speziellen Stereo3D-Monitoren ist deshalb ein Differenz-Modus zum Anzeigen beider Bilder vorhanden, mit dem selbst geringste Abweichungen sehr gut zu erkennen sind. Eine ähnliche Funktion ist in Video-/Film-Schnittprogrammen integriert. Hier kann festgestellt werden, ob zwei Sequenzen genau zeitgleich übereinander liegen. Dies ist vor allem für das Conforming (siehe Abschn. 5.3) wichtig, da hier infolge von unterschiedlichen Schnittversionen die Abfolge der Clips und deren Länge verändert wird.
Abbildung 10.9 zeigt eine solche Anwendung. Im linken Bild gibt es die Differenz von einem Frame zwischen beiden Sequenzen. Im rechten Bild liegen beide übereinander.

Differenz-Überblendung
Auch wird die Arbeit von Codecs mit der Differenz-Methode evaluiert. Indem das mit dem Codec bearbeitete Bild vom Originalbild abgezogen wird, kann anhand der noch vorhandenen Bildelemente festgestellt werden, welche Artefakte der Codec verursacht.
Eine weitere wichtige Anwendung ist das Zusammenfügen einer Clean-Plate , wobei bestimmte Elemente entfernt werden können, wie zum Beispiel ins Bild ragende Schienen eines Dolly-Systems oder Stunt-Personal, das durch Aliens ersetzt werden soll. Zum manuellen Erstellen einer Clean-Plate werden oft verschiedene Bilder zusammengesetzt – entweder Bilder aus unterschiedlichen Zeiten einer Bildsequenz oder aus Standfotos vom Set. Durch das Übereinanderlegen und Bilden der Differenz kann die Position zweier Bilder zueinander sehr genau eingestellt werden. Dies ist vor allem dann hilfreich, wenn das Bearbeitungsprogramm Positionen im Subpixelbereich zulässt.
10.1.6 Die Minimum und Maximum-Überblendung
Minimum - und Maximum -Überblendungen eignen sich für Masken-Operationen, da sie kein Clipping produzieren und ihre Ergebnisse sich immer im Bereich zwischen 0 und 1 einordnen – vorausgesetzt, die Ausgangswerte der Bilder überschreiten diesen Bereich nicht.
Das Zusammenfügen von Graustufenmasken fällt in den Anwendungsbereich des Maximum-Modus (Gl. 10.8). Die Schreibweise der Logik der Gleichung folgt der Syntax gängiger Skriptsprachen und beinhaltet eine konditionelle Abfrage: Ist A größer als B, wird A verwendet, wenn nicht, kommt B zur Anwendung. Damit ist sichergestellt, dass sich das jeweils hellere Element durchsetzt. In Photoshop wird der entsprechende Modus mit Aufhellen bezeichnet.
Maximum
Soll Maske A von Maske B begrenzt werden, findet der Minimum-Modus Anwendung (Gl. 10.9). Hier wird nur der Bereich von Maske A weitergegeben, der innerhalb von Maske B liegt. In Photoshop wird die entsprechende Operation als Dunklere Farbe bezeichnet. Die konditionelle Abfrage lautet: Ist A kleiner als B, wird A verwendet, wenn nicht, kommt B zur Anwendung. Damit ist sichergestellt, dass das jeweils dunklere Pixel verwendet wird.
Minimum
Beide Modi können auch bei der Kombination von RGB-Werten eingesetzt werden. Hierbei müssen die beiden Bilder bestimmte Voraussetzungen erfüllen, wobei die gleichmäßige Helligkeitsverteilung in den kritischen Bereichen die wichtigste ist.
Abbildung 10.10 zeigt das Einfügen einer Fahne im Zusammenhang und den Austausch des Himmels im Hintergrundbild. Da das Hintergrundbild für den Himmel eine gleichmäßige Fläche aufweist, kann die Komposition mit dem Minimum-Modus ausgeführt werden.

Minimum-Überblendung
10.1.7 Weitere Überblendungsmodi
In Tab. 10.3 sind die gebräuchlichsten Überblendungsmodi mit ihren mathematischen Funktionen aufgeführt. Da viele der berechnungstechnischen Grundlagen Eigentum von Adobe Inc. sind und nicht veröffentlicht werden, sind die Funktionen als Annäherungen zu betrachten. Abbildung 10.11 zeigt das Ergebnis einiger ausgewählter Modi.

Weitere Überblendungsmodi
10.2 Der Umgang mit dem Alpha-Kanal
Wenn auch auf den ersten Blick nicht ersichtlich, so ist der Umgang mit dem Alpha-Kanal eines der komplexesten Themen im Compositing und in der gesamten Medien-Pipeline. Das Konzept des Alpha-Kanals als viertem Kanal zusätzlich zu den RGB-Kanälen wurde in den 1970er-Jahren von Ed Catmull zusammen mit Alvy Ray Smith am New York Institut of Technology entwickelt und 1984 von Thomas Porter und Tom Duff ausgebaut. Aber erst mit der Implementierung des Alpha-Kanals in Photoshop fand der Alpha-Kanal weitere Verbreitung.
10.2.1 Das Speichern von Masken
Nachdem Masken entweder manuell in Bildbearbeitungsprogrammen oder automatisch in 3D-Programmen erzeugt wurden, stellt sich die Frage: Wie werden diese in die Pipeline weitergeleitet? Hier gibt es mehrere Möglichkeiten. Die erste besteht in der Verwendung von Graustufenbildern.
Verwendung von Graustufenbildern
Der Export von Masken als Graustufen-RGB-Bilder ist in den meisten Grafik-Programmen möglich. In Photoshop kann der Alpha-Kanal in die RGB-Kanäle kopiert und das Resultat als dreikanaliges RGB-Bild weitergegeben werden. Um Probleme bei der späteren Verarbeitung in der Produktionspipeline zu vermeiden, sollten keine einkanaligen 8-Bit-Graustufenbilder verwendet werden.
In 3D-Programmen werden die Transparenzwerte der Szene in der Regel als Maske in den Alpha-Kanal des Beauty-Passes geschrieben. Um ein Graustufenbild zu generieren, muss für die Maske ein zusätzlicher Render-Layer erzeugt werden, der dann separat gerendert wird. Dies bietet eine hohe Kontrolle und wird im professionellen Rendering angewendet, wobei mehrere Masken als IDs in einem OpenEXR-Bild ausgegeben werden.
Eine Graustufenmaske liegt immer separat vor und ist nicht mit Bildinformationen kombiniert wie beim Beauty-Pass . Das erleichtert die Identifizierung im Dateisystem und im Compositing-Nodegraph anhand des Node-Icons. Der Nachteil ist, dass die Erstellung einer Graustufenmaske einen zusätzlichen Aufwand bedeutet, da 3D-Elemente im Gegensatz dazu auch mit einer automatisch generierten Maske im Alpha-Kanal ausgegeben werden können. Außerdem weist die Graustufenmaske Redundanzen auf, da alle drei Farbkanäle die gleichen Informationen erfassen.
In Abb. 10.12 ist das Compositing-Schema bei Verwendung einer Graustufenmaske angegeben. Es handelt sich dabei um Blatt-Texturen für Baummodelle der Firma Dosch-DesignFootnote 6. Für die Textur werden zwei Bilder ausgeliefert: ein Farbbild und eine Maske. Aber interessant: Die Maske ist entgegengesetzt aller Gewohnheiten im opaken Bereich schwarz. Dieser Umstand erklärt sich aus der Art der Einbindung der Modelle in die entsprechenden 3D-Programme (zum Beispiel Maya), deren Shader-Aufbau, der nicht die Opazität verarbeitet, sondern die Transparenz. An den Stellen, an denen die Maske weiß ist, wird das korrespondierende RGB-Bild transparent und lässt den Hintergrund durchscheinen. Im Schema von Abb. 10.12 erfolgt zuerst die Inversion der Maske, um sie im Compositing anzuwenden. Danach wird einer der Farbkanäle der Maske in den Alpha-Kanal der Textur kopiert. Da alle Farbkanäle über die gleichen Informationen verfügen, spielt es keine Rolle, welcher der RGB-Kanäle ausgewählt wird – im Beispiel ist es der rote. Danach wird die Textur vormultipliziert und kann verwendet werden.

Anwendung einer Graustufenmaske im Compositing
An dieser Stelle sei die Nomenklatur im Compositing kurz vorgestellt, um die Ablaufbilder besser verständlich zu machen. In der Regel werden zwei Bilder Image A und Image B durch mathematische Compositing-Operatoren verknüpft. Oft wird dabei auf die unterschiedlichen Farbkanäle und andere Eigenschaften der Bilder zugegriffen. Die Kennzeichnung der Kanäle erfolgt hier in der sogenannten Dot-Syntax , bei der zuerst das Bild (B) und dann nach einem Punkt die Eigenschaft (red – der rote Kanal) angegeben wird. Der Term B.red → A1.alpha bedeutet somit, dass der rote Kanal von Image B in den Alpha-Kanal von Image A1 kopiert wird.
RGB-Farbkanäle als Masken
Da Graustufenbilder eine gewisse Redundanz aufweisen, Speicherplatz verbrauchen und damit den Arbeitsspeicher und den Prozessor unnötig belasten, wird oft die Möglichkeit genutzt, die einzelnen RGB-Kanäle zum Speichern von unterschiedlichen Masken zu verwenden. Dies ist in der Regel besonders bei Bildbearbeitungsprogrammen wie Photoshop einfacher zu realisieren, als eine Reihe von Graustufenbildern zu erstellen. Es wird dann der Verlauf der Maske ausgewählt und mit der entsprechenden Farbe – zum Beispiel Rot RGB[255 0 0] – gefüllt. Dies geschieht ebenso mit dem grünen und blauen Kanal. Bei Überlappungen addieren sich die Farben – zum Beispiel Rot und Grün zu Gelb.
Dieses Verfahren wird oft in der Produktfotografie (zum Beispiel Autowerbung) verwendet, wo dem Photoshop-Artist zusätzlich zu dem gerenderten Fahrzeug farbige Masken übergeben werden, damit er bestimmte Fahrzeugteile separat bearbeiten kann.
Abbildung 10.13 zeigt das Schema der Anwendung von Farbmasken auf ein Vordergrundbild. Zunächst wird das Vordergrundbild zweimal kopiert. Dann wird jeweils eine Maske in die entsprechenden Alpha-Kanäle der drei Vordergrundbilder kopiert und das Bild danach vormultipliziert. Hier ist zwar ein gewisser Aufwand notwendig, um die Masken zu isolieren und anzuwenden. Da aber moderne Compositing-Programme immer wiederkehrende Arbeitsschritte durch Makros und Gizmos automatisieren können, fällt dies kaum ins Gewicht.

Anwendung von Farbmasken im Compositing
10.2.2 Der Alpha-Kanal
Der Alpha-Kanal ist ein zusätzlicher Kanal zu den RGB-Kanälen in einer Grafikdatei und wird vor allem zur Weitergabe von Masken verwendet. Die grundlegende Idee von Catmull und Smith war, dass die Maske nicht getrennt vom zu maskierenden Bild aufbewahrt und weitergegeben werden sollte, was im Ergebnis Registrierung und Synchronisation beider stark vereinfachte. Der Name des Kanals stammt von der Variable α in der Gleichung zur linearen Interpolation (engl. alpha blending – siehe Abschn. 10.2.6).
Im Videobereich war der QuickTime-Animations-Codec lange Zeit der einzige den Alpha-Kanal unterstützende Codec, der weitere Verbreitung fand. Heute bieten noch andere Codecs diese Möglichkeit an (u. a. Apple ProRes 4444, ProRes 4444 XQ oder Avid DNxHD).
Das System des Alpha-Kanals beinhaltet eine weiße Maske der Silhouette des Vordergrundbildes, das sich in den dazugehörigen RGB-Kanälen befindet. In diesem Bereich wird es vollständig opak dargestellt. Der schwarze Bereich in der Maske lässt ein zukünftiges Hintergrundbild durchscheinen. Graustufenwerte blenden zwischen Vorder- und Hintergrund. Die Graustufen-Übergänge umfassen den komplexesten Bereich und sind anfällig für auftretende Artefakte.
Abbildung 10.14 zeigt eine Maske einerseits als 1-Bit-Alpha-Kanal – es ist nur weiß oder schwarz möglich – und andererseits als 8-Bit-Alpha-Kanal. Die unterschiedliche Wirkung auf das Vordergrundbild ist deutlich zu erkennen. Im rechten Bild integriert sich das Vordergrundbild, das mit der 8-Bit-Graustufenmaske freigestellt wurde, wesentlich besser mit dem Hintergrund als das linke Bild, das ausgeschnitten wirkt.

Maske mit hartem und weichem Übergang
Alpha-Kanäle können abhängig von ihrer Integration in das RGBA -Bild weiter klassifiziert werden. Man unterscheidet einerseits einen Alpha-Kanal, der beim Erstellen des Bildes mit den RGB-Kanälen multipliziert wurde. Dabei handelt sich um ein vormultipliziertes Bild und dementsprechend um einen vormultiplizierten Alpha-Kanal (engl. premultiplied alpha channel). Des Weiteren gibt es Alpha-Kanäle, die keinen direkten Einfluss auf das RGB-Bild haben und im Bild mittransportiert werden. Diese werden als direkte Alpha-Kanäle bezeichnet. Jedoch findet in der Literatur keine eindeutige Terminologie Verwendung. Im Deutschen umfasst die Bezeichnung Direkter Alpha-Kanal zwei unterschiedliche Konzepte. Das erste beinhaltet den oben beschriebenen nicht-multiplizierten Alpha-Kanal, bei dem eine Maske vorhanden ist, die aber keine Auswirkungen auf die RBG-Kanäle hat. Das zweite Konzept beinhaltet den im Englischen als Straight-Alpha bezeichneten Kanal. Dieser hat jedoch ein spezielles Verhalten in Bezug auf die RGB-Kanäle und unterscheidet sich in der Wirkung signifikant von dem nicht-multiplizierten Kanal. Um in der Terminologie zielführend zu bleiben, verwenden wir hier die Begriffe nicht-vormultiplizierter Alpha-Kanal (engl. unpremultiplied), vormultiplizierter Alpha-Kanal (engl. premultiplied) und Straight-Alpha-Kanal (engl. straight alpha). Alle drei haben ihre Vor- und Nachteile und exklusive Einsatzgebiete.
10.2.3 Der nicht-vormultiplizierte Alpha-Kanal
Ein nicht-vormultiplizierter Alpha-Kanal beinhaltet eine Maske, die zwar erstellt und weitergegeben wurde, aber noch keine Anwendung auf die RGB-Werte fand. Ein Konzept, das grundlegend für das Verständnis von Compositing ist, besteht darin, dass eine Maske im Alpha-Kanal grundsätzlich keine Wirkung auf die dazugehörigen RGB-Werte ausübt, bis eine bewusst ausgelöste Operation beide verknüpft.
Abbildung 10.15 zeigt das Prinzip. Hier wird zum besseren Verständnis der Ausschnitt aus einem Compositing-Programm als 3D-Szene dargestellt. Drei monochrome Farbkanäle und der Alpha-Kanal bilden in der Darstellung jeweils eine Ebene. Ein umschaltbarer Viewer deutet an, dass in gängigen Grafik-Programmen nicht ohne Weiteres die RGB-Kanäle und der Alpha-Kanal gleichzeitig betrachtet werden können. Der Viewer wird durch ein Kabel mit den drei Graustufen-RGB-Kanälen verbunden und zeigt das resultierende Farbbild (oberes linkes Bild). Wird das Kabel mit dem Alpha-Kanal verbunden, wird dieser gezeigt. Der Alpha-Kanal beinhaltet eine Maske, die mit der Intention erstellt wurde, das Schild in den RGB-Kanälen freizustellen. Da dieser Vorgang aber noch nicht aufgerufen wurde, sind beide Elemente weiterhin separat (Bild oben rechts).

Nicht-vormultiplizierter Alpha-Kanal
Es wird nun ein Schmetterling in den Alpha-Kanal kopiert mit der Intention, diese Maske später im Compositing zu verwenden (Bild unten links). Wird der Viewer wieder auf die RGB-Werte umgeschaltet, hat sich das RGB-Bild nicht verändert.
Zum Erstellen eines solchen Alpha-Kanals kann in Photoshop die Maske im Alpha-Kanal gespeichert werden (Auswahl-Menü). In 3D-Programmen wird die Vormultiplikation abgeschaltet. Der nicht-vormultiplizierte Alpha-Kanal wird dann verwendet, wenn über die Art und Weise wie er eingesetzt wird erst in der nachfolgenden Anwendung entschieden werden soll. Der große Vorteil bei der Verwendung dieses Alpha-Kanals besteht darin, dass alle Bildinformationen noch vorhanden sind, das heißt, die Maske kann in der folgenden Anwendung verändert und andere als die in der ersten Intention festgelegten Bildausschnitte verwendet werden – dies gilt in der Regel vor allem für den Randbereich der Maske.
Abbildung 10.16 gibt einen Einblick in die Anwendungsmöglichkeiten. Das Bild Image A wird in das Compositing-Programm importiert und enthält die unbearbeiteten RGB-Kanäle und die Maske. Die für den weiteren Verlauf der Komposition notwendige Vormultiplikation findet im nächsten Schritt statt. Nun fällt dem Produzenten beim Testen auf, dass auch der Sockel gut in die zukünftige Komposition passen würde. Bei einem bereits vormultiplizierten Bild wäre dieses Bildteil nicht mehr vorhanden (Variante 1). Da aber das Vordergrund-Bild nach dem Import noch vollständig ist, kann der Compositing-Artist eine Roto-Maske zeichnen und diese mit der originalen Maske des Alpha-Kanals verknüpfen (Maximum-Operation). Diese neue Maske wird in den Alpha-Kanal des Vordergrund-Bildes kopiert und das Bild dann vormultipliziert (Variante 2). Nun kann das Bild entsprechend den Wünschen des Supervisors komponiert werden.

Änderung der Maske in einem nicht-vormultiplizierten Bild
Dieser Typ Alpha-Kanal sollte dann verwendet werden, wenn zum Beispiel in Photoshop Bilder freigestellt werden. Hier hat der Compositing-Artist Spielraum – vor allem auch, weil die in Photoshop produzierten Masken aufgrund der nicht vektorbasierenden Painting-Grundlage meist nachbearbeitet werden müssen. Ein – wenn auch geringer – Nachteil ist der Extra-Aufwand, an geeigneter Stelle eine Vormultiplikation auszuführen. Ein anderer ist, dass manche Anwendungen einen vormultiplizierten Alpha-Kanal erwarten. Abbildung 10.17 zeigt die Fehlinterpretation eines als Projektionstextur fungierenden nicht-vormultiplizierten Bildes in Autodesk Maya.

Fehlinterpretation des Alpha-Kanals in einer komplexen Anwendung
Hier erwartete der Algorithmus ein vormultipliziertes Bild und produziert deshalb eine Art Geisterbild. Der erfahrene Compositing-Artist kann anhand der Charakteristika einer solchen Erscheinung relativ schnell die Ursache in einem falsch angewendeten Alpha-Kanal finden.
10.2.4 Vormultiplizierter Alpha-Kanal
Der vormultiplizierte Alpha-Kanal ist der Standard im Compositing, da die wichtigsten Operationen von diesem Zustand ausgehen. Bei einem vormultiplizierten Bild wurden die RGB-Kanäle mit dem Alpha-Kanal multipliziert. Durch diese Operation gehen alle nicht benötigten Bildinformationen verloren. Das Bild wird an diesen Stellen schwarz, was auch für eine effiziente Codierung von großem Nutzen ist. Die betreffenden Bereiche des Bildes können mit statistischen Methoden (zum Beispiel Huffmann) verlustfrei sehr stark komprimiert werden. Außerdem kann die Region, die die Bildinformationen enthält, als Domain of Definition in einer OpenEXR-Datei gespeichert werden. Dieser Ausdruck, der im Compositing-Programm Shake verwendet wurde, bezeichnet den Bereich der Bildinformationen, die bei einem vormultiplizierten Bild innerhalb der Maske liegen. Die Domain of Definition wird verwendet, um bei Elementen, die nicht das ganze Bild umfassen, Arbeitsspeicherbelastung zu verringern und Prozessorzeit zu sparen, da der Bereich außerhalb der Domain of Definition (DoD) nicht in Betracht gezogen und vom Compositing-Programm nicht bearbeitet wird.
Die meisten 3D-Programme produzieren Renderings, in denen das Bild automatisch vormultipliziert ist. In Photoshop kann ein Bild im Bildmenü vormultipliziert werden. Im Compositing wird eine Vormultiplikations-Operation (engl. premultiplication, abgekürzt premult) aufgerufen, eine der meist genutzten Funktionen (siehe Abb. 10.18).

Der vormultiplizierte Alpha-Kanal
Ist das Bild vormultipliziert, wird das Vordergrundbild in dem Bereich, in dem die Maske weiß ist, vollständig opak dargestellt. Im dem Bereich, in dem die Maske schwarz ist, wurden durch die Multiplikation alle Farbwerte entfernt. Dieser Bereich ist ebenfalls schwarz. Hier erscheint der Hintergrund eines anderen Bildes. Im Übergang zwischen beiden Bildteilen erfolgt eine Wichtung des Anteils der RGB-Kanäle je nach Graustufenwert der Maske. Ein Wert von 0,25 des Alpha-Kanals führt dazu, dass 25 % der korrespondierenden RGB-Kanäle verwendet werden, der Rest wird mit Schwarz ausgefüllt. Umgekehrt werden bei einem Wert des Alpha-Kanals von 0,75 75 % der Farben in den RGB-Kanälen verwendet und der Rest ebenfalls mit Schwarz gefüllt. Bei der Anwendung eines Over-Algorithmus , der das Bild mit einem neuen Hintergrund verknüpft (siehe nächster Abschnitt), tragen die schwarzen Elemente nicht zum resultierenden Bild bei, da eine Addition stattfindet und Schwarz den Wert null hat. In der Bildkombination erscheinen nur diejenigen Teile des Vordergrundbildes, deren Farbinformationen größer als null ist. Der restliche – schwarze – Anteil wird mit dem Hintergrundbild gefüllt.
Wird aus verschiedensten Gründen – beabsichtigt oder aus Versehen – der Alpha-Kanal ein weiteres Mal vormultipliziert, werden die transparenten Übergänge qualitativ verschlechtert. Der 25%ige Anteil des Vordergrundes im oben genannten Beispiel wird noch einmal mit dem Wert von 0,25 des Alpha-Kanals multipliziert und damit auf 6 % reduziert, der Rest wird wieder mit Schwarz aufgefüllt. Der 75%ige Anteil des Vordergrunds wird auf 56 % reduziert. Dadurch werden die Kanten im Bild dunkler und Transparenzen opaker.
In Abb. 10.19 ist ein Bild mit einer Reihe transparenter Glasobjekte im oberen Bild einmal vormultipliziert und im unteren Bild dreimal vormultipliziert dargestellt. Dabei ist deutlich zu erkennen, in welcher Form die Kanten – zum Beispiel an der Mundpartie des Glasfisches – durch die mehrmalige Anwendung der Vormultiplikation hervortreten. Schattierungen werden dramatisch verstärkt und die im oberen Bild durchsichtige Rückenflosse erhält die Konsistenz einer Milchglasscheibe.

Mehrmaliges Anwenden der Vormultiplikation
Eine der wichtigsten Qualifikationen eines Compositing-Artists ist das Vermeiden der mehrmaligen Vormultiplikation von Bildelementen. Hier stellt sich nun bereits seit Längerem die Frage, wieso das Bild überhaupt vormultipliziert wird und warum der Begriff vormultipliziert und nicht einfach multipliziert lautet? Die Antwort liegt in der Anwendung des Algorithmus der linearen Interpolation, der zwei Bilder gewichtet miteinander kombiniert und im Compositing als Over-Operation bekannt ist.
10.2.5 Der Over-Algorithmus
Der Over-Algorithmus ist die wichtigste Compositing-Operation zur Verknüpfung zweier Bilder unter Verwendung einer Maske, die im Alpha-Kanal von Bild A liegt. Die praktische Anwendung beinhaltet, dass ein maskiertes Vordergrundbild über ein Hintergrundbild gelegt wird. Das Hintergrundbild benötigt keine Maske, kann aber eine Maske besitzen. Die Kombination der beiden Bilder erfolgt nach Gl. 10.10 für die RGB-Kanäle und Gl. 10.11 für die Alpha-Kanäle. Sie ist ähnlich der Opazitäts-Überblendung in Gl. 10.1.
Dabei sind
A die RGB-Kanäle von Bild A, |
B die RGB-Kanäle von Bild B, |
Aa der Alpha-Kanal von Bild A, |
Ba der Alpha-Kanal von Bild B. |
Es gibt somit zwei Terme. Der Term A * A a ist das vormultiplizierte Bild A. Der Term (1 − A a ) * B ist der invertierte Alpha-Kanal von Bild A, multipliziert mit den RGB-Kanälen von Bild B. Abbildung 10.20 zeigt die Anordnung als Netzwerk mit Compositing-Operatoren und den jeweiligen Status der entsprechenden Kanäle.

Der Over-Algorithmus
Diese Operation führt zu einer Reihe von Konsequenzen:
-
1.
Bei der additiven Verknüpfung von Bildern muss der Bildbereich, der dargestellt werden soll, im jeweils anderen Bild null – also schwarz – sein, damit seine Farbwerte das Ergebnis nicht verfälschen. Wird dagegen verstoßen, erscheinen die sogenannten Geisterbilder wie in Abb. 10.20 unten rechts.
-
2.
Es ist für die Funktion des Algorithmus – im Gegensatz zur Opazitäts-Gleichung – von herausragender Bedeutung, welches Bild dem Algorithmus als Bild A oder B präsentiert wird, das heißt, mit welchem Eingang der Compositing-Node verbunden wird. Das Bild mit dem Alpha-Kanal muss immer am Eingang A anliegen.
-
3.
Da vor allem Renderings aus 3D-Programmen und Bilder aus Pre-Compositings bereits vormultipliziert sind, führt der Algorithmus den Term A*Aa nicht aus, sondern nimmt an, dass dies bereits geschehen ist – daher der Begriff vormultipliziert. Damit wird verhindert, dass eine erneute Multiplikation stattfindet und die Qualität der Bildkanten beeinträchtigt wird. In älteren Compositing-Programmen wie Apple Shake wurde dieser Term ausgeführt und musste jeweils abgeschaltet werden. Inzwischen verzichten moderne Implementierungen des Over-Algorithmus aus praktischen Gründen auf die Vormultiplikation.
-
4.
Durch die unterschiedliche Handhabung des Terms A*Aa ist es notwendig, die Implementierung des Over-Algorithmus zu evaluieren. Eventuell muss die Vormultiplikation abgeschaltet werden oder es ist sicherzustellen, dass das zu verwendende Bild vormultipliziert ist.
-
5.
Es ist für ein komplexes Compositing von allergrößter Wichtigkeit, stets die Kontrolle über die einzelnen Bildmultiplikationen und die Anwendung und Interpretation von Alpha-Kanälen zu behalten. Compositing-Programme, die dies nicht gewährleisten, können für komplexere Aufgaben nicht verwendet werden.
-
6.
Da voreingestellt auch eine Addition der Alpha-Kanäle der beiden Bilder erfolgt, muss festgelegt werden, in welcher Weise der resultierende Alpha-Kanal weiterverwendet werden soll. Sind zwei Bilder vorhanden, die jeweils Masken besitzen, ist eine Addition der beiden Alpha-Kanäle sinnvoll, da die resultierende Maske als Grundlage für eine eventuell folgende Over-Operation verwendet wird. In dem Fall kann die Voreinstellung verwendet werden (siehe Abb. 10.28). Soll die Maske von Bild A erhalten bleiben, wie beim Edge-Blending (siehe Abb. 8.55), muss sichergestellt werden, dass der Alpha-Kanal von Bild B diese nicht überschreibt. Eventuell muss er von der Addition ausgeschlossen werden.
-
7.
Farbkorrekturen bei vormultiplizierten Bildern müssen in der Regel vor der Vormultiplikation stattfinden. Kann dies nicht gewährleistet werden, da das Bild bereits vormultipliziert importiert wurde, muss es ent-vormultipliziert werden (engl. unpremultiplied). Erst dann wird die Farbkorrektur ausgeführt. Anschließend wird es wieder vormultipliziert.
Der letzte Punkt soll hier auf Grund seiner Wichtigkeit noch ein wenig im Detail diskutiert werden. Da besonders bei additiven Farbkorrekturen, die den Schwarzpunkt verändern (zum Beispiel lift in der Grade-Node von Nuke), ein Sockelbetrag zu den Farbwerten des gesamten Bildes hinzugefügt wird, kann der eigentlich schwarze (vormultiplizierte) Bereich Werte annehmen, die größer als null sind. Nehmen wir an, ein dunkles vormultipliziertes Bild wird um 10 % in der Helligkeit angehoben, damit es sich besser in den Hintergrund einfügt. Da diese Bearbeitung das gesamte Bild betrifft, werden auch die eigentlich schwarzen Bereiche angehoben und aufgrund des linearen Arbeitsumfeldes zu einem mittleren dunklen Grau. Obwohl der Alpha-Kanal indiziert, dass diese Bereiche null sein sollten, hat er nach der Vormultiplikation keinen Einfluss mehr auf die RGB-Kanäle. Bei der nun folgenden Anwendung der Over-Operation werden die Grauwerte von Bild 1 infolge der Addition der beiden Terme auf das Hintergrundbild übertragen. Es wird aufgehellt.
Dies könnte durch eine weitere Vormultiplikation nach der Farbkorrektur vermieden werden, da diese Bereiche des 10%igen Grau im Vordergrundbild wieder auf null setzen würde. Sie darf aber nicht angewendet werden, da dadurch die Kanten und transparenten Teile des Bildes beschädigt würden. Die einzige Lösung ist, das vormultiplizierte Bild vor der Farbkorrektur zu entvormultiplizieren, dann die Farbkorrektur durchzuführen und erst zum Schluss die Vormultiplikation anzuwenden. Dadurch wird gewährleistet, dass die betreffenden Bereiche unabhängig von den Helligkeitswerten nach der Farbkorrektur zuverlässig auf null gesetzt und andererseits die Kanten nicht zweimal multipliziert werden (siehe Abb. 10.21)

Farbkorrektur bei vormultiplizierten Bildern
10.2.6 Der Straight-Alpha-Kanal
Der Straight-Alpha -Kanal hat seinen Ursprung in Vektorgrafikprogrammen wie Adobe Illustrator. Aber auch die Transparenz in Photoshop wird beim Export in eine PNG-Datei von verschiedenen Programmen u. a. Nuke als Straight-Alpha-Kanal interpretiert. Des Weiteren wird er oft angewendet, um volumetrische und Lichteffekte wie Nebel, Rauch und Feuer in besserer Transparenzqualität zu exportieren. Der Straight-Alpha-Kanal ist ein direkter Kanal und wurde nicht mit den RGB-Werten multipliziert, hat also einen ähnlichen Status, wie der nicht-vormultiplizierte Kanal. Im Gegensatz zu letzterem, bei dem noch das gesamte Bild in den RGB-Kanälen vorhanden ist, sind bei einem Bild mit Straight-Alpha-Kanal nur die RGB-Werte präsent, an deren Position der Alpha-Kanal nicht gleich null ist. Alle anderen werden in der Regel als weiß oder im Falle von Photoshop als transparent interpretiert.
Abbildung 10.22 zeigt das System. Im linken Bild wurde in Photoshop ein Farbverlauf mit einer Maske versehen, sodass der untere Teil des Bildes transparent wird. Das rechte Bild zeigt die Interpretation des Straight-Alpha-Kanals der PNG-Datei in Nuke. Dabei fällt der typische Farbverlauf eines solchen Bildes auf. Es ist kein weicher Übergang vorhanden, denn alle Pixel, bei denen der korrespondierende Alpha-Kanal nicht null ist, werden mit den vollständigen RGB-Werten dargestellt, alle anderen sind weiß. Um das Bild im Compositing anzuwenden, wird es im nächsten Schritt vormultipliziert und über ein anderes Bild komponiert.

Der Straight-Alpha-Kanal
Der große Vorteil des Straight-Alpha-Kanals liegt darin, dass die unmaskierten Bereiche in Photoshop transparent dargestellt und nicht mit Weiß oder Schwarz gefüllt werden. Der Matte-Painting-Artist kann so auf der einen Seite ein vollständiges Bild in den Ebenen mit allen Transparenzen erstellen. Danach werden bestimmte Ebenen des Matte-Paintings in Photoshop zusammengefasst und jeweils als PNG-Datei exportiert.
Der Compositing-Artist hat nun – besonders an den Kanten der Ebenenmasken – etwas Spielraum, da noch alle RGB-Werte vollständig, das heißt, nicht gegen Schwarz geblendet, vorhanden sind. Er kann den Alpha-Kanal justieren und dann erst die Vormultiplikation einleiten.
Unabhängig von seinem Status ist ein Problem des Alpha-Kanals, dass die Interpretation des dazugehörigen Bildes abhängig von der entsprechenden Software oder dem Betriebssystem stark differiert. Abbildung 10.23 zeigt verschiedene Darstellungen eines vormultiplizierten Bildes mit Alpha-Kanal. Im oberen linken Bild ist das Bild in seiner Entstehung in Photoshop angegeben. Es wurde mithilfe der Bildberechnungen (Ebene 1 multipliziert mit Alpha 1) vormultipliziert. Das so erstellte Bild wird von den Mac OS X- und Windows-Betriebssystemen mit weißem Hintergrund dargestellt. Die Betriebssysteme verwenden das vormultiplizierte Bild und führen eine Over-Operation aus, wobei als Image B eine weiße Fläche verwendet wird. Die Vorschau in Mac OS X stellt das gleiche Bild mit grauem Hintergrund dar. Dies wird allerdings auch bei Bildern mit nicht-vormultipliziertem Alpha-Kanal und bei Bildern mit Straight-Alpha so gehandhabt. Die Konsequenz ist, dass man nicht mehr unterscheiden kann, welchen Status der Alpha-Kanal hat.

Unterschiedliche Interpretation eines vormultiplizierten Bildes
Als Nutzer muss man davon ausgehen können, dass der festgelegte Status des Alpha-Kanals vom Compositing-Programm respektiert wird. Deshalb sind Konzepte, die zum Beispiel den Over-Algorithmus automatisch anwenden, wenn ein Alpha-Kanal vorhanden ist, für ein komplexes Compositing nicht zielführend, denn der Compositing-Artist muss selbst entscheiden können, wie er mit dem Alpha-Kanal umgeht.
10.3 Multi-Layer-, Multi-Pass- und Multi-Channel-Compositing
3D-Rendering ist ein aufwendiger Prozess und kostet Zeit und Geld. Oft muss eine gesamte Sequenz neu gerendert werden, wenn nur eine Kleinigkeit – zum Beispiel ein Farbton in einem Kleidungsstück – angepasst werden muss. Deshalb wurde in der VFX- und Animationsindustrie frühzeitig das Konzept von Multi-Passes und Render-Layern entwickelt.
Dabei wird die 3D-Szene nach bestimmten Gesichtspunkten in sogenannte Render-Layer unterteilt und separat gerendert. Die Bildsequenzen der einzelnen Render-Layer werden dann im Compositing zusammengesetzt und bieten Spielraum für Farbkorrekturen und Beleuchtungsänderungen. Weitverbreitete Anwendung finden Licht-Render-Layer und Objekt-Render-Layer . Erstere beinhalten die gesamte Szene, die jeweils separat von einem Licht oder einer Gruppe von Lichtern beleuchtet wird, sodass nachträglich der Einfluss der einzelnen Lichtquellen justiert werden kann. Bei der Verwendung von Objekt-Render-Layern wird die Szene in Objekte unterteilt, die dann im Compositing neu zusammengesetzt werden können.
Ein weiteres wichtiges Konzept ist das Multi-Pass-Rendering. Hier werden die unterschiedlichen Oberflächeneigenschaften der Objekte in einzelnen Passes (diffus, spekular, reflexiv, refraktiv, Schatten etc.) separat gerendert. Mit dem Aufkommen des OpenEXR-Dateiformats wurde das Multi-Channel-/Multi-Pass-Rendering entwickelt, wobei alle Passes in einer Datei gespeichert werden. Die einzelnen Multi-Passes können dann im Compositing verknüpft werden, ohne sie zu separieren. Durch diese Techniken sind weitreichende Farbkorrekturen in den Objekten und Render-Passes möglich, ohne die Szene neu rendern zu müssen. Nicht notwendige Elemente können leicht entfernt werden und eine interaktive BeleuchtungFootnote 7 lässt sich unkompliziert einfügen. Außerdem ist es dadurch möglich, aufwendig zu berechnende 3D-Effekte wie Dunst, Nebel, Bewegungsunschärfe, Schärfentiefe und Leuchteffekte (engl. glow effects) von der 3D-Ebene auf die schneller zu bearbeitende 2D-Ebene zu verlagern.
10.3.1 Verwenden von Channel-Layern (Multi-Channel-Compositing)
Modernes digitales Compositing folgt in der Abfolge der Operatoren dem Prinzip von einem Stamm und Ästen, die sich verzweigen. Zentrales Element ist der Stream (Stamm), der meist vom Hintergrundbild ausgeht. Zusätzliche Elemente kommen durch die Äste von der Seite und werden meist durch den Over-Algorithmus mit dem Stream verknüpft.
Ein weiteres zentrales Konzept im Compositing beinhaltet die Verwendung einer zusätzlichen Maske zu den beiden Eingangsbildern (Image A und B). Die Maske ermöglicht, dass zum Beispiel bei der Farbkorrektur nur spezielle Bildbereiche beeinflusst werden. In älteren Compositing-Programmen (zum Beispiel Shake) wurde dies mit einem speziellen Maskeneingang realisiert, der die Maske von der Seite in den Stream einspeiste. Diese Herangehensweise hat allerdings eine Reihe gravierender Nachteile. Wird der Stream beispielsweise räumlich vor der Maskenanwendung transformiert, stimmt die Position der Maske nicht mehr. Sie muss ebenfalls angepasst werden. Dies wird allgemein mit einer Kopie (Klon) des originalen Transform-Operators, die dessen Parameteränderungen automatisch aktualisiert, oder mit Expressions realisiert. Das ist aufwendig und sehr unübersichtlich.
Moderne Compositing-Konzepte folgen dem Konzept von Multi-Channels. Hierbei gibt es ähnlich wie bei den Ebenen in Photoshop mehrere Zusammenstellungen von RGBA-Kanälen (engl. channel sets ). Die Sets können dann beliebig innerhalb der einzelnen Bilddateien verknüpft werden.
Abbildung 10.24 zeigt den Vorgang anhand einer sekundären Farbkorrektur. Image A ist der Beginn eines Streams. Das Bild enthält einen Laubbaum in den RGB-Kanälen und die Maske im Alpha-Kanal. Das Bild texturiert später eine 3D-Card. Von der Seite wird eine Roto-Maske eingespeist, die nur das Blattwerk umschließt, da der Stamm samt der Holzkonstruktion, die den Baum hält, nicht verändert werden soll. Die Frage, die sich der Compositing-Artist stellt, ist: Wie füge ich die Maske in den Stream ein? Hierbei gibt es drei Möglichkeiten:

Unterschiedliche Maskenkanäle im Compositing
-
1.
Die Farbkorrektur-Node besitzt einen Maskeneingang, um die Operation zu begrenzen. Dies ist aber aus oben angegebenen Gründen ungünstig.
-
2.
Die Maske kann in den Alpha-Kanal gelegt werden. Dies ist in diesem Beispiel zu vermeiden, da die Maske im Alpha-Kanal für die nach der Farbkorrektur folgende Vormultiplikation benötigt wird.
-
3.
Ein neues Channel-Set wird erzeugt. Dies wird für modernes Compositing empfohlen. Die Maske befindet sich im Stream und wird bei räumlichen Transformationen mitbewegt. Dabei ist es eine gute Arbeitsweise, die Maske direkt am Beginn der Komposition in den Stream einzufügen. Eventuelle räumliche Transformationen, zu denen auch Skalierungen und Reformatierungen gehören, beeinflussen somit alle Materialien und Channel-Sets gleichzeitig und damit auch diejenigen, die erst später Anwendung finden.
Der erste Schritt, den der Compositing-Artist ausführt, besteht darin, die Roto-Maske in den Stream zu kopieren. Er kann hier den in Nuke bereits vordefinierten Maskenkanal (mask.red) nutzen, der nur den roten Farbkanal eines Channel-Sets verwendet. Die nun folgende Farbkorrektur-Operation (Grade-Node) wird dann auf den von der Maske umschlossenen Bereich – das Blattwerk – begrenzt. Nach der Farbkorrektur wird die Vormultiplikation ausgeführt, das heißt, die RGB-Kanäle werden mit dem Alpha-Kanal multipliziert.
Channel-Sets in Nuke sind zum Teil vordefiniert. Der Nutzer kann sie aber auch nach seinen Vorstellungen erzeugen und benennen. Die dritte Möglichkeit ist ihre Übernahme aus einer OpenEXR-Datei.
Abbildung 10.25 zeigt den Aufbau einer OpenEXR-Datei, die eine Reihe Channel-Sets mit Multi-Passes enthält. Alle diese Channel-Sets besitzen RGB-Kanäle und einen Alpha-Kanal. Wie und ob diese belegt werden hängt von den Einstellungen im 3D-Programm ab. Oft liegt der Beauty-Pass – das heißt, die Zusammenfassung aller Passes – in den RGBA-Kanälen. Er enthält auch die Maske für das Objekt. Die einzelnen Beleuchtungs-Passes werden in entsprechenden Channel-Sets ausgegeben. Diese Channel-Sets und ihre Namen, die ebenfalls im 3D-Programm festgelegt wurden, werden von Nuke übernommen. Es sei darauf hingewiesen, dass in diesem Beispiel die Multi-Passes keine Maske besitzen, der Alpha-Kanal bleibt leer. Bei der finalen Vormultiplikation wird die Maske im Alpha-Kanal des Beauty-Passes genutzt (siehe Abschn. 10.3.3).

Aufbau einer OpenEXR-Datei
10.3.2 Arbeiten mit Render-Layern
Render-Layer bieten die Möglichkeit, 3D-Szenen nach flexiblen Gesichtspunkten zu rendern. Sie werden in der Regel firmenintern festgelegt und sind abhängig von der Gestalt des zu bearbeitenden Projektes. Licht-Render-Layer und Objekt-Render-Layer sind aber weit verbreitet.
Licht-Render-Layer
Die Beleuchtung einer 3D-Szene ist traditionell aufwendig zu berechnen. Trotz Optimierungen – wie dem Verwenden von Faked-Global-Illumination (siehe Abschn. 9.7.5) – ist es sinnvoll, die Szene in einzelne Beleuchtungssysteme zu unterteilen, die dann separat gerendert werden können. So ist bei einer Szene mit KaustikenFootnote 8 die Berechnung des Spotlights, das diese generiert, wesentlich aufwendiger als die der anderen Lichter, die nur für eine bestimmte Stimmung im Bild sorgen. Soll diese Stimmung verändert werden, muss nur das entsprechende Licht oder die entsprechende Lichtgruppe gerendert werden. Das Rendering der Kaustiken wird unverändert übernommen und beim Compositing addiert.
Die Abb. 10.26 und 10.27 zeigen das Compositing einer einfachen 3D-Szene mit den Render-Layern von drei Lichtern als Schema und die Renderings. Als Grundlicht ist ein direktes Licht vorhanden, das die Abendstimmung nach Sonnenuntergang simuliert. Durch das im Rendering nicht sichtbare Fenster fällt bläuliches Licht in die Szene. Ein Flächenlicht simuliert die Innenbeleuchtung mit einer Glühlampe und sorgt für eine Lichtstimmung, die sich vor allem aus Orangetönen zusammensetzt. Die Kaustiken der Glaselemente werden von einem Spotlight erzeugt. Die Render-Layer werden addiert. Durch unterschiedliche Gewichtung der einzelnen Lichter kann die Stimmung der Szene verändert werden. So ist es zum Beispiel möglich, die Schattenbildung besser herauszuarbeiten, wenn das Spotlight-Rendering einen höheren Einfluss erhält, oder die Kaustiken sind weniger prominent, wenn es anstelle des Plus-Modus mit dem Screen-Modus komponiert wird.

Kombinieren von Licht-Passes (Schema)

Kombinieren von Light-Passes (Renderings)
Objekt-Render-Layer
Das Vorgehen bei der Verwendung von Objekt-Render-Layern ist ähnlich wie bei den Licht-Render-Layern. Der Unterschied besteht darin, dass die Szene in unterschiedliche Objekte aufgeteilt wird, die dann beim Compositing – im Gegensatz zu den addierten Licht-Layern – mit dem Over-Modus kombiniert werden. Der Vorteil bei dieser Herangehensweise ist, einzelne Objekte separat bearbeiten zu können, um zum Beispiel eine Farbkorrektur anzuwenden. Außerdem ist es möglich, Effekte wie Bewegungsunschärfe, Schärfentiefe, Dunst und andere mit unterschiedlicher Gewichtung auf die einzelnen Objekte anzuwenden. Für eine effiziente Herangehensweise ist es wichtig, dass das 3D-Programm die Beleuchtung nicht für jeden einzelnen Objekt-Render-Layer neu berechnet. Hier bietet zum Beispiel Maya sogenannte Contribution-Maps an, bei dem die Objekte separiert werden, die Lichtberechnung aber nur einmal stattfindet.
Die Abb. 10.28 und 10.29 zeigen das Compositing einer stilisierten 3D-Szene mit den Render-Layern von drei Objekten als Schema und die entsprechenden Renderings. Sie bestehen aus einer metallischen Falkenfigur, dem Boden mit dem Schatten der Figur und Schilfhalmen. Die einzelnen Render-Layer werden nun mit dem Over-Modus zusammengesetzt. Zuerst der Falke über den Boden zu Comp. 1 und dann die Schilfhalme über Comp. 1 zu Comp. 2.

Kombinieren von Objekt-Passes (Schema)

Kombinieren von Objekt-Passes (Schema)
10.3.3 Multi-Pass-Compositing
Beim Multipass-Compositing werden die berechneten Lichtkomponenten und Oberflächeneigenschaften der 3D-Objekte aufgebrochen und in einzelnen Passes ausgegeben. Dies ist relativ unproblematisch und schnell, da die einzelnen Komponenten (diffus, direkt, spekular, refraktiv, reflexiv) vom Renderer unabhängig voneinander berechnet und in Buffern gespeichert werden. Der zusätzliche Aufwand ist lediglich, diese auf die Festplatte zu schreiben. Der Renderer im 3D-Programm setzt die einzelnen Komponenten in den Buffern mittels Addition zu einem Beauty-Pass zusammen und gibt diesen ebenfalls aus, wobei je nach Vorgaben auch bestimmte Komponenten (reflexiv, refraktiv) vom Beauty-Pass ausgeschlossen werden können.
Beim Compositing können diese Multi-Passes dann zusammengesetzt und neu gewichtet werden. Außerdem sind Farbkorrekturen einfacher auszuführen. Des Weiteren können aufwendige Berechnungen im 3D-Raum wie die von Bewegungsunschärfen oder der Schärfentiefe auf die 2D-Ebene ausgelagert werden.
Render-Passes werden in der Regel in Color-Passes , Shadow-Passes , Masken-Passes und Utility - oder Daten-Passes unterteilt. Die wichtigsten Colorpasses sind: diffuse , indirect lighting , direct lighting , reflection , refraction und specular . Die verwendete Arithmetik (Überblendungsmodus) bei Color-Passes ist die Addition. Aus künstlerischen Gründen wird hin und wieder auch der Screen-Modus angewandt. Dies entspricht aber nicht der originalen Mathematik, die der Renderer beim Zusammensetzen dieser Passes verwendet.
Die wichtigsten Color-Passes beinhalten die folgenden Beleuchtungskomponenten (es sei aber darauf hingewiesen, dass die Implementierung in den einzelnen 3D-Programmen und Renderern – auch abhängig von der Komplexität der Szene – unterschiedlich sein kann):
-
Diffuser Pass: lokales Beleuchtungsmodell,
-
Indirekter Pass: globales Beleuchtungsmodell,
-
Direkter Pass: nur direktes Licht ohne Streulicht,
-
Spekularer Pass: Glanzlichter – lokales Beleuchtungsmodell,
-
Reflexions-Pass: globales Beleuchtungsmodell,
-
Refractions-Pass (Brechungen): globales Beleuchtungsmodell,
-
Schatten-Pass: mit Raytracing oder Shadow-Map kreierte Schatten, lokales und globales Beleuchtungsmodell,
-
Ambient-Occlusion : Selbstverschattung – kein Licht involviert, geometrische Grundlage.
Mit Shadow-Maps oder Raytracing generierte Shadow-Passes und Ambient-Occlusion-Passes werden in der Literatur oft auch zu den Color-Passes gezählt, sie unterscheiden sich aber in der Arithmetik der Zusammenfügung – sie werden multipliziert.
Neben diesen weit verbreiteten Multi-Passes gibt es noch eine Reihe von Spezial- und Ausschluss-Passes wie subsurface scattering , diffuse without shadows , direct without shadows , beauty without reflection and refraction , translucence etc.
Shader-ID- und Objekt-ID-Passes besitzen Masken für nach unterschiedlichen Gesichtspunkten ausgewählte Elemente.
Utility- oder Daten-Passes enthalten meist keine Farbinformationen, sondern Positions- und Vektor-Daten. Sie können aber als Farbdaten dargestellt werden und weisen ein bestimmtes Erscheinungsbild auf, anhand dessen der Compositing-Artist bereits wichtige Informationen ablesen kann. Zu den wichtigsten gehören: 2d motion vector pass , world position pass , normal pass , depth pass und eine Reihe projektspezifischer Passes, die von den Firmen erstellt und in die Pipeline eingespeist werden. Ein Problem besteht hin und wieder darin, Color- und Daten-Passes in eine gemeinsame OpenEXR -Datei zu schreiben. Da für letztere eine höhere Auflösung benötigt wird, wird die gemeinsame Datei zumeist mit höherer Bit-Tiefe ausgegeben, was das Datenaufkommen marginal erhöht. Es wird aber auch der für mathematische Kalkulationen bevorzugte CIE-XYZ-Farbraum verwendet. Dies führt dazu, dass für die Color-Passes eine Farbraum-Konversion (CIE XYZ – sRGB) durchgeführt werden muss. Es ist deshalb zu empfehlen, Color-Passes und Daten-Passes in unterschiedlichen Dateien zu exportieren.
In Abschn. 10.4 wird die Anwendung des World-Position-Passes und des World-Normal-Passes diskutiert, in Abschn. 10.5 die Anwendung des 2D-Motion-Vector-Passes und in Abschn. 10.6 die Anwendung des Depth-Passes.
Zusammensetzen eines Beauty-Passes aus einzelnen Multi-Passes
In Abb. 10.30 wird schematisch das Zusammensetzen der einzelnen Color-Passes zu einem Beauty-Pass gezeigt. Die Darstellung folgt der traditionellen Methode, diese Passes als separate Bildsequenzen zu rendern und dann mittels Addition zu kombinieren. Eine modernere Herangehensweise wird in Abschn. 10.3.4 diskutiert.

Zusammensetzen eines Beauty-Passes
Der Stream beginnt mit dem Direktes-Licht-Pass , wobei es aber keine Rolle spielt, in welcher Reihenfolge die Passes zusammengefügt werden, da eine Addition kommutativ ist. Im ersten Schritt wird der Indirektes-Licht-Pass addiert (Comp. 1). Danach erfolgt das Hinzufügen des Reflexionen-Passes und des Refraktionen-Passes jeweils mittels Addition (Comp. 2 und Comp. 3). Bei dieser Herangehensweise werden keine Masken in den einzelnen Renderpasses generiert, da diese bei den angewendeten Überblendungsmodi ebenfalls addiert würden, was die ursprüngliche Maske verfälschen könnte. Da die Dateien nur drei Farbkanäle besitzen, ist das Datenaufkommen auch geringfügig kleiner als bei Dateien mit integriertem Alpha-Kanal. Die zum Vormultiplizieren benötigte Maske wird nun entweder aus dem Alpha-Kanal des Beauty-Passes oder einer separaten ID-Maske in den Stream kopiert (Comp. 4). Da es sich bei der Maske im Beispiel um ein Graustufenbild handelt, muss einer der RGB-Kanäle in den Alpha-Kanal des Streams gelegt werden. Im Bild befindet sich mit der Bodenplatte ein Fremdelement, sodass noch eine Vormultiplikation stattfinden muss, um das Fahrzeug freizustellen.
Anwenden von Shadow-Passes
Schatten (engl. shadows) sind für einen realistischen Bildeindruck von herausragender Bedeutung. Deshalb wird oft nicht nur die Schattenbildung in der Interaktion zwischen den Objekten und Lichtern einer 3D-Szene gerendert, sondern auch – zumindest grob – die Umgebung auf der Filmaufnahme nachmodelliert (engl. shadow catcher ) oder eine Bodenplatte eingefügt, um einen wirklichkeitsgetreuen Schattenwurf zu erhalten.
Shadow-Passes werden zwar prinzipiell multipliziert, in der praktischen Anwendung ist allerdings ein alternatives Vorgehen gebräuchlich. Um mehr Kontrolle zu erhalten, wird der Schattenpass als Maske verstanden und der Hintergrund im Maskenbereich abgedunkelt. Dadurch ist eine bessere Färbung des Schattens und eine genauere Gestaltung der Schattendichte möglich. Konsequenterweise wird die Maske in den 3D-Programmen deshalb auch invers – der Schattenbereich ist weiß – ausgegeben.
Abbildung 10.31 zeigt das Schema und Abb. 10.32 die einzelnen Renderphasen der Anwendung eines Ambient-Occlusion-Passes und eines Shadow-Passes. Der Stream beginnt beim Hintergrund (Image B). Im ersten Schritt wird der zusammengesetzte und vormultiplizierte Beauty-Pass über den Hintergrund komponiert (Comp. 1). Es ist deutlich zu erkennen, dass das Bild nicht realistisch ist, da die Schattenkomponente fehlt (Abb. 10.32, oberes linkes Bild). Nun wird der Ambient-Occlusion-Pass multipliziert (Comp. 2). Da dabei auch die beiden Alpha-Kanäle von Image C und Comp. 1 multipliziert werden, muss der Alpha-Kanal des Ambient-Occlusion-Passes weiß (1,0) sein, wenn die Maske im Stream (Comp. 1) beibehalten werden soll (Multiplikation mit 1 verändert den Ausgangszustand nicht). Im nächsten Schritt wird der Schatten-Pass dem Stream als Maske hinzugefügt. Bei einer komplexen Komposition, in der die Original-Maske noch benötigt wird, kann dafür der Masken-Layer (mask.a) verwendet werden (siehe Abb. 10.24).

Anwenden eines Shadow-Passes (Schema)

Anwenden eines Shadow-Passes (Renderings)
Da in diesem Beispiel die Originalmaske nicht mehr benötigt wird, kann der Schattenpass in den Alpha-Kanal kopiert werden (Comp. 3) und sie überschreiben. Zum Abschluss findet eine Farbkorrektur statt (Comp. 4). Hier wird der von der Maske des Schatten-Passes umschlossene Bereich des Bildes abgedunkelt und eingefärbt. Der Vorteil bei einem solchen Herangehen ist, dass die Struktur des Hintergrundes teilweise beibehalten werden kann, wenn die Maske nicht vollständig opak angewendet wird. Alternativ zu diesem Beispiel kann der Schattenpass auch direkt auf den Hintergrund angewendet werden, noch vor der Komposition des Beauty-Passes.
Anwendung von ID-Passes
Obwohl die Verwendung von Render-Layern und Multi-Passes eine weitgehende Kontrolle über das Compositing von 3D-Inhalten bietet, ist oft eine noch genauere Unterteilung der 3D-Elemente gefordert. Hier kommen die Shader-ID-Passes und Objekt-ID-Passes zum Einsatz.
Diese ID-Passes sind einfache Graustufenmasken, die die entsprechenden Elemente umschreiben. Die Grundidee bei der Verwendung von Shader-IDs ist, dass die Shader Oberflächeneigenschaften generieren, die – unabhängig von den 3D-Modellen – bei einer Farbkorrektur gleich behandelt werden sollten. Somit ist es sinnvoll, alle Objekte, für die der Shader angewandt wurde, in einer Shader-ID-Maske zusammenzufassen.
Weit verbreitet sind auch Objekt-ID-Masken. Hier wird für jedes Objekt oder Element eine eigene Maske erzeugt und gemeinsam in einer OpenEXR-Datei ausgegeben. Hierbei ist bei der Planung eine auf Erfahrung basierende vorausschauende Arbeitsweise sinnvoll, um einerseits nicht zu viele Masken zu erzeugen und andererseits fehlende nicht nachliefern zu müssen. Das relativ aufwendige Erstellen dieser ID-Passes kann in der Regel durch spezialisierte Plug-ins und Skripte weitestgehend automatisiert werden.
Abbildung 10.33 zeigt die Anwendung eines Object-ID-Passes. Die gerenderten Scheinwerfer eines Fahrzeuges sind durch die starken Brechungen im Refraction-Pass unnatürlich eingefärbt und sollen entsättigt werden. Dazu wird die entsprechende Maske aus einer Object-ID-Datei (OpenEXR) in den Alpha-Kanal des Refraction-Passes kopiert. Anschließend erfolgt die Farbkorrektur des Refraction-Passes in dem maskierten Bereich. Er kann dann nach der Bearbeitung gemäß Abb. 10.30 in das Multi-Pass-System eingefügt werden.

Anwendung eines Objekt-ID-Passes
10.3.4 Multi-Pass-Compositing in Multi-Channel-Layern
Für komplexe Szenen können teilweise mehr als hundert Pässe vorhanden sein. Dies stellt hohe Anforderungen an die Organisation dieser Daten. Von großem Vorteil ist deshalb die Verwendung von OpenEXR-Dateien, die mehrere Multi-Passes enthalten können. Der Nachteil ist allerdings, dass die einzelnen Passes im traditionellen Compositing jeweils in RGB-Kanäle gelegt werden müssen, um sie weiterzuverarbeiten. Um das zu vermeiden, wurde im modernen Herangehen das Konzept von Multi-Channel-Layern (Channel-Sets ) entwickelt. Dabei wird nur ein Bild geladen, in dem alle Multi-Passes in einzelnen Channel-Sets (ähnlich wie Photoshop-Ebenen) angeordnet sind. Bei der Bearbeitung wird dann direkt auf diese Channel-Sets zugegriffen, ohne diese extrahieren zu müssen.
Abbildung 10.34 zeigt den Aufbau einer OpenEXR-Datei. Sie beinhaltet den Beauty-Pass im obersten Channel-Set und in den anderen Ebenen fünf Render-Passes. Das oberste Channel-Set wird als Standard-RGBA-Layer interpretiert und im Viewer des Compositing-Programms dargestellt. Deshalb ist es sinnvoll, die Ergebnisse der Compositing-Operationen in den RGB-Kanälen zu platzieren, da sie sofort angezeigt werden und der Viewer nicht umgeschaltet werden muss. Dabei wird zwar der Beauty-Pass überschrieben, da Compositing aber prinzipiell non-destruktiv ist, kann er bei Bedarf aus der Original-Datei kopiert werden.

Multipass-Compositing mit Multi-Channel-Layern
Nun werden die einzelnen Passes zusammengefügt. Im ersten Schritt erfolgt die Addition des Direkten-Licht-Passes mit dem Indirekten-Licht-Pass, wobei das Ergebnis in die RGB-Kanäle geschrieben wird. Im nächsten Schritt werden die RGB-Kanäle der Datei – die das Zwischenergebnis enthalten – mit dem nächsten Pass addiert und das Ergebnis wieder in die RGB-Kanäle gelegt, bis alle Passes zusammengefügt wurden.
Compositing-technisch werden bei diesen Verknüpfungen der Operator (Merge-Node) in beiden Eingängen mit der OpenEXR-Datei verbunden und die entsprechenden Channel-Sets ausgewählt (siehe Abb. 10.35). Die Alpha-Kanäle werden dabei nicht berücksichtigt.

Multipass-Multi-Channel-Compositing in der Merge-Node in Nuke
10.4 2.5D-Technologien und Set-Extensions
Das 2.5D-Compositing ist eine innovative Technologie, die in den letzten Jahren in der Bewegtbildproduktion weite Verbreitung gefunden hat. Sie kombiniert Fotorealismus mit 3D-Kamerabewegungen und ist dadurch gegenüber einer 3D-Pipeline mit Modellieren, UV-Mapping, Texturieren, Beleuchten und Rendern wesentlich unaufwendiger bei oft gleicher oder besserer Qualität des Endergebnisses. Von großem Vorteil ist, dass die Beleuchtung bereits in den fotografischen Texturen enthalten ist. Dies ist allerdings auch ein Nachteil, da sie nachträglich nur bedingt geändert werden kann.
2.5D-Compositing wird vor allem bei der Set-Erweiterung und beim Matte-Painting eingesetzt, wenn nur Teile der Szene praktisch gebaut werden oder die Akteure vor dem Blue-/Greenscreen agieren. Das Grundelement bei der 2.5D-Technologie sind die Cards (dt. Karten), flache Objekte ohne Tiefenausdehnung, die im 3D-Raum platziert werden. Aber auch eine grobe Geometrie ohne größere Details wird verwendet, wenn zum Beispiel Gebäude dargestellt werden sollen. Die 2.5D-Technik kann vor allem dann ihre Stärken ausspielen, wenn die zu texturierende Geometrie eben ist wie zum Beispiel eine Hauswand, Fenster, Türen oder Werbeplakate. Aber auch Hintergrundobjekte können gut dargestellt werden, da durch die Raumkomprimierung ihre Tiefenwirkung weitestgehend aufgehoben wird, wenn sie weit genug von der Kamera entfernt sind. So können ab einen gewissen Abstand Bäume, Kraftfahrzeuge und ab dem Mittelgrund auch Menschen und Tiere problemlos auf Cards texturiert oder projiziert werden. Der Nachteil ist allerdings, dass dreidimensionales Detail besonders im Vordergrund meist nicht ausreichend dargestellt werden kann. Auch ist die Fahrt der Kamera, die die Szene abfotografiert, begrenzt, da vor allem projizierte Texturen leicht zu Verzerrungen neigen. Kann mit der 2.5D-Technik keine befriedigende Lösung gefunden werden, muss die Umgebung vollständig dreidimensional modelliert werden.
10.4.1 Verwenden von Cards im Compositing
Cards (dt. Karten) sind zweidimensionale Objekte, die beliebig im Raum platziert werden können und beim traditionellen Herangehen texturiert sind. Sie benötigen keine separate UV-Map, da sie keine Tiefenausdehnung haben und somit Fotografien problemlos in den 3D-Raum übertragen. Die Compositing-Programme verwenden dafür eine automatische Referenzierung.
In vielen Fällen ist es möglich, eine 3D-Szene allein mit diesen Karten aufzubauen, die entsprechend räumlich transformiert und auch animiert werden können. So ist es zum Beispiel möglich, den Boden der Szene mit einer Card, die entsprechend gedreht wurde, darzustellen. Die Cards werden dann mit Hilfe der programmeigenen unsichtbaren UV-Map texturiert.
Abbildung 10.36 zeigt eine Card in Nuke. Die Baumtextur ist vormultipliziert und ihr transparenter Teil wird dementsprechend nicht dargestellt. Ebenso zu erkennen sind die räumlichen Unterteilungen der Card, die weitestgehend frei angeordnet werden können. Die Karte lässt sich durch Anfasser manipulieren und formen, was besonders beim manuellen Aufbau von 360°-Szenen von großem Vorteil ist, da nicht passende Übergänge nachjustiert werden können. Da sich diese Anfasser animieren lassen, kann bei geschickter Manipulation zum Beispiel bei Bäumen der Eindruck von windbewegten Ästen hervorgerufen werden.

Card mit 4 × 4-Rasterung
Die Cards können nun frei im Raum angeordnet werden. Abbildung 10.37 zeigt den Aufbau eines Zaunes, der in die Landschaft eingefügt werden soll. In die Szene sind vier Zaunpfähle in unterschiedlicher Tiefenstaffelung eingefügt. Außerdem befindet sich im 3D-Raum eine entsprechend geformte Card, die in der z-Richtung angeordnet ist, in die Tiefe führt und Verbindungsdrähte enthält. Das entsprechende Rendering kann dann auf die Landschaftsaufnahme komponiert werden. Da die Objekte an der richtigen Position im Raum angeordnet sind, generieren sie auch die entsprechende Parallaxenänderung, wenn sich die Render-Kamera bewegt.

Texturierte Cards
10.4.2 Kameraprojektion auf Cards
Die Kameraprojektion (engl. camera projection) ist ein mächtiges Werkzeug im 2.5D-Compositing. Diese Technik kombiniert Matte-Painting mit 3D-Umgebungen. Auch hier finden Cards ihre Verwendung, die bei Bedarf von grob modellierter Geometrie ergänzt werden. Auf diese Cards wird dann das Bild im Gegensatz zur traditionellen Vorgehensweise nicht texturiert, sondern mit einer als Projektor fungierenden Kamera projiziert. Dies ist ähnlich einer modernen Theateraufführung, bei der das Bühnenbild mit Leinwänden gestaltet wird, auf die die entsprechenden Bilder projiziert werden. In dem so aufgespannten Kunstraum können sich die Schauspieler bewegen.
Es ist möglich, die Projektionskamera frei im 3D-Raum zu positionieren. In vielen Fällen wird sie aber anhand einer bestimmten Position (Frame) innerhalb einer bereits vorhandenen Kamerabewegung definiert. Hierzu ist eine vom Matchmoving-Prozess generierte Kamera prädestiniert, da einerseits Blickwinkel, Brennweite und andere Kameraparameter auf die digitale Ebene übertragen wurden und andererseits Positionen im 3D-Raum durch die entsprechenden Marker vorhanden sind. Dies erfordert eine gute Kommunikation zwischen den Filmabteilungen, da die Marker für die Platzierung der Cards an den entsprechenden Positionen im 3D-Raum vorhanden sein müssen (vgl. Diskussion Abschn. 10.4.6). Für diese Arbeiten ist eine Repräsentation der Umgebung in Form einer Lidar-Scan-Punktwolke von großer Hilfe.
Die grundlegende Aufgabe für das Generieren dieser Projektionskamera liegt somit vor allem in der Auswahl des in der Bildsequenz vorhandenen besten Frames, das so viel wie möglich von dem zu projizierenden Objekt zeigt. Das dazugehörige Bild wird dann grafisch manipuliert und von der Kamera auf eine Card oder ein 3D-Modell projiziert. Die Projektionskamera kann dann entweder aus der Matchmoving-Sequenz kopiert werden oder es wird ein Operator eingefügt, der die Kamera über die gesamte Sequenz in dem Projektionsframe festhält (engl. frame hold).
Die Abb. 10.38 und 10.39 zeigen das Schema einer Kamera-Projektion und das entsprechende Rendering. Dabei wird eine Card in der x/z-Ebene im 3D-Raum als Bodenplatte eingefügt. Die Projektions-Kamera wird in Position und Projektionswinkel entsprechend angepasst oder aus einer Matchmove-Sequenz generiert und projiziert das Bild auf die Card. Eine weitere Kamera nimmt die Szene auf. In diesem Fall hat sie zu Beginn der Kamerafahrt die gleiche Position wie die Projektions-Kamera (siehe auch Abschn. 10.2.3).

Projektion auf eine Card (Schema)

Projektion auf eine Card (Rendering)
Im Compositing wird die Szene dann zusammengesetzt. Ein entsprechender Hintergrund beginnt den Compositing-Stream. Im nächsten Schritt wird die Bodenplatte hinzugefügt und zum Abschluss werden die Zaunelemente aus Abb. 10.37 darüber komponiert.
10.4.3 Re-Fotografieren der 2.5D-Szene
Ein wichtiger Bestandteil des Kamera-Projektions-Workflows ist die Render-Kamera (auch Shot-Kamera), die die 2.5D-Szene abfotografiert. Hierbei gibt es eine Reihe von Möglichkeiten:
-
1.
Eine neue Kamera kann an einer beliebigen Stelle der Szene eingefügt werden. Die Position muss allerdings so festgelegt werden, dass keine Verzerrungen der Texturen auftreten (siehe Abb. 10.42, Bild unten links).
Abb. 10.40 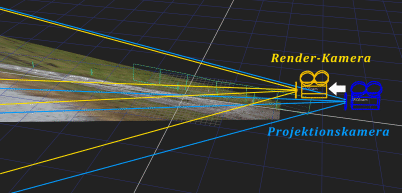
Re-Fotografieren der Szene (Schema)
Abb. 10.41 
Re-Fotografieren der Szene (Renderings)
Abb. 10.42 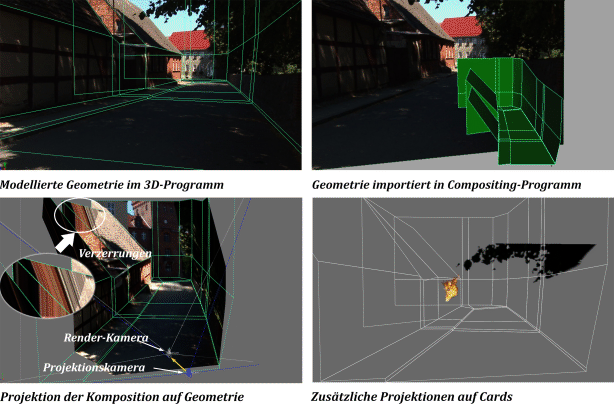
Projektion auf 3D-Geometrie (Schema)
-
2.
Die Projektionskamera fungiert als Render-Kamera. Dazu wird die Projektionskamera in der Regel kopiert. Da der Blickwinkel zwischen Projektionskamera und Render-Kamera identisch ist, treten keine Verzerrungen auf.
-
3.
Die Matchmove-Kamera filmt die Szene ab.



Alle drei Kameratypen können animiert werden oder sind es bereits, wie im Falle der Matchmove-Kamera. Dabei können sie sich nur in einem begrenzten Rahmen bewegen, ohne dass die Texturen verzerrt aufgenommen werden. Dieser Rahmen ist aber meist ausreichend, um eine sichtbare Parallaxenänderung zu generieren und damit den Eindruck einer realen Kamerafahrt zu erzeugen.
Die Abb. 10.40 und 10.41 zeigen das Schema des Re-Fotografierens einer 2.5D-Szene und vier Frames des Renderings. Hierbei wird die blaue Projektionskamera kopiert. Die gelbe Render-Kamera bewegt sich entlang der Projektionsrichtung und fotografiert die Szene ab. Infolge der Parallaxenänderung der Zaunpfähle und vor allem des Zaundrahtes wird eine reale Kamerafahrt simuliert.
10.4.4 Projektionen auf 3D-Geometrie
Der Bodenbereich in der Szene im Abschn. 10.4.3 steigt nach rechts an. Abhängig von der Weiterverwendung einer Aufnahme – Dauer der Sequenz, Qualitätsansprüche, Schnittumgebung im Film usw. – ist es möglich, den Betrachter mit der hier verwendeten flachen Bodenplatte zu täuschen. Es kann aber auch notwendig sein, das Gelände zu modellieren. Dies ist vor allem dann sinnvoll, wenn noch weitere CG-Elemente (wie z. B. Charaktere) eingefügt werden sollen, die mit dem Bodenbereich interagieren, oder Schatten realistisch auf das Gelände fallen sollen.
Eine 3D-Geometrie, auf die die entsprechenden Bilder projiziert werden, weist zumeist nur das notwendigste Detail auf. Auch hier ist es wichtig, dass die Perspektive der Projektionskamera in Bezug zur 3D-Geometrie korrekt ist. Dies ist bei Verwendung von Matchmove-Kameras und dem dazugehörigen Bildmaterial automatisch der Fall. Wird ein Standbild am Set aufgenommen, das für Projektionen verwendet werden soll, ist es sinnvoll, den Kamerastandpunkt und damit den Blickwinkel der späteren Render-Kamera zu simulieren.
Manchmal ist es notwendig, den Standpunkt der Kamera aus einem vorhandenen Bild zu ermitteln. Hier kommen Technologien wie das Perspektive-Matching zum Einsatz (siehe Abschn. 9.6.3). Die so gewonnene Kamera kann dann ebenfalls in den im vorhergehenden Abschnitt definierten Grenzen bewegt werden.
Abbildungen 10.42 und 10.43 zeigen das Schema der Projektion auf 3D-Geometrie einer 2.5D-Szene und vier Frames des Renderings. Im ersten Schritt wird der Kamerastandpunkt der originalen fixierten Kamera ermittelt und die Geometrie der Szene grob nachgebaut (siehe Abb. 10.42, Bild oben links). Diese Geometrie und die dazugehörige 3D-Kamera werden in das Compositing-Programm importiert (Bild oben rechts). Dann wird das Compositing aufgebaut und die Bildsequenz auf die Geometrie projiziert. Im nächsten Schritt erfolgt das Kopieren der Projektionskamera, die dann als Render-Kamera verwendet wird. Die Render-Kamera kann sich in begrenztem Maße bewegen und führt eine Kamerafahrt in die Tiefe der Szene aus (Bild unten links). In diesem Bild sind auch die Verzerrungen der Textur zu erkennen, die aufgrund der Position der Editor-Kamera, die diese Abbildung fotografiert, auftreten. Als weitere Elemente wurden Teile des Blattwerks eines Baumes auf eine Card gelegt und eine Feuersequenz auf einer weiteren Card eingefügt. Auch hier sorgt die Parallaxenänderung für den Eindruck einer realen Kamerafahrt.

Projektion auf 3D-Geometrie (Renderings)
10.4.5 Erzeugen einer Clean Plate
Der Einsatz der 2.5D-Projektionstechnik in einer Film-Pipeline ist vielfältig. Die wichtigsten Anwendungsgebiete sind die Set-Erweiterung und das Erzeugen einer Clean-Plate. Eine Clean-Plate ist eine Filmaufnahme, in der bestimmte störende Elemente entfernt wurden. Das kann anachronistisches Detail sein, regional falsche Bildelemente, Fehler in der Aufnahme wie sichtbare Dolly-Schienen oder Glas- und Wasserspiegelungen in einer Stereo3D-Aufnahme. Auch Shots, in denen Requisiten ausgetauscht, Stuntmen mit CG-Charakteren ersetzt oder die Steuerkabel von Animatronics entfernt werden sollen, gehören zu den Anwendungsgebieten der Clean-Plate. Dabei muss der durch die Objekte partiell verdeckte Hintergrund wiederhergestellt werden. Clean-Plates können mit den folgenden Techniken erzeugt werden:
-
1.
Die Szene wird zweimal aufgenommen – einmal mit Vordergrundobjekt, einmal nur der Hintergrund. Dabei ist die Kamera entweder unbewegt (locked-off) oder ein Motion-Control-System wird verwendet.
-
2.
Reveal-Painting in der Postproduktion. Ein oder mehrere Bilder aus der Bildsequenz, in denen das zu entfernende Objekt nicht vorhanden ist, werden verwendet. Der freie Hintergrund in den einzelnen Frames wird maskiert und zu einem Bild zusammengesetzt.
-
3.
Wire- oder Rig-Removal kann verwendet werden.
-
4.
Ein Standbild (Still) des wiederherzustellenden Elementes wird mittels eines Trackers an die Originalaufnahme angepasst.
-
5.
Die Kameraprojektion wird verwendet.
Abbildung 10.44 zeigt das Schema des Generierens einer Clean-Plate und Abb. 10.45 stellt ausgewählte Ansichten im 3D-Raum bzw. Renderings dar. Die Aufgabe in diesem Beispiel ist, Elemente – hier die beiden gelben Turngeräte – aus einer VFX-Aufnahme zu entfernen (siehe Abb. 10.45, obere Reihe links). Außerdem muss die Einstrahlung der Sonne durch das rechte Fenster teilweise beseitigt werden, damit sie nicht mit dem vom einzufügenden Objekt generierten Schatten kollidiert.

Generieren einer Clean-Plate (Schema)

Generieren einer Clean-Plate (Renderings)
Aus der Bildsequenz wird deshalb ein Frame ausgewählt, das den entsprechenden Bereich gut abbildet (Frame 35). Dieses Bild wird in Photoshop bearbeitet und die infrage kommenden Objekte übermalt. Mit diesem Arbeitsschritt sind die Objekte aber nur in einem Frame der gesamten Sequenz entfernt worden. Da sich die Kamera bewegt und ein Weitwinkelobjektiv bei der Aufnahme genutzt wurde, sind die perspektivischen Verzerrungen zu groß, um die wiederhergestellten Teile des Turnhallenbodens in die anderen Frames ohne perspektivische Nachbearbeitung zu kopieren.
Es wird deshalb die 2.5D-Kameraprojektion angewendet. Dazu wird die Matchmove-Kamera kopiert und als Projektionskamera verwendet. Damit sie sich nicht bewegt, sondern in der Position von Frame 35 fixiert bleibt, wird ein Frame-Hold-Operator eingefügt. Die Projektionskamera (blaue Kamera in Abb. 10.45) projiziert das in Photoshop bearbeitete Bild auf eine unter Verwendung der Matchmove-Daten in einem 3D-Programm erzeugte grobe Geometrie des Turnhallensaals. Diese wird als FBX-Datei importiert. Die originale Matchmove-Kamera (gelbe Kamera in Abb. 10.45) filmt dann die Projektion der bearbeiteten Clean-Plate ab. Je weiter sie sich vom Ausgangspunkt in Frame 35 entfernt, desto mehr ändert sie die Position gegenüber der fixierten Projektionskamera (Abb. 10.45, obere Reihe rechtes Bild). Dadurch filmt sie Bereiche der 3D-Geometrie, die nicht von dem Projektionsbild bedeckt sind.
Dies ist im Schema in Abb. 10.44 im 3D-Rendering zu erkennen, das einen schwarzen Rand aufweist, der desto größer wird, je weiter sich die Matchmove-Kamera dem Ende der Aufnahmesequenz nähert. Da aber nur der Bereich der Clean-Plate benötigt wird, der die gelben Turngeräte und den Lichteinfall bedeckt, können diese maskiert und über die Originalaufnahme gelegt werden. Aufgrund der Tatsache, dass die Perspektive zwischen 3D-Turnhallengeometrie und Render-Kamera infolge des Matchmove-Prozesses stimmt, werden auch alle perspektivischen Verzerrungen erfasst und führen zu einem nahtlosen Ergebnis.
10.4.6 Anwenden des Multi-Channel-Systems im 3D-Raum
Insbesondere beim Compositing mit bewegter Kamera befinden sich häufig Elemente im programmeigenen 3D-Raum. Oft ist es dabei notwendig, diese auf unterschiedlichen Ebenen mit dem Live-Action-Footage zu verknüpfen. Teile der internen 3D-Szene werden somit hinter der Live-Aufnahme angeordnet und andere davor, die fertige 3D-Szene wird kopiert und das Ergebnis der jeweiligen Renderer entsprechend übereinander komponiert. Ein eleganterer Weg ist die Nutzung des Multi-Channel-Systems. Hierbei werden die Texturen und Projektionsbilder in andere Channel-Sets als in das grundlegende RGBA-Set gelegt. Da der Renderer die einzelnen Channel-Sets gleichzeitig rendert, aber unterschiedlich ausgibt, können mehrere Compositing-Ebenen in einer Szene gerendert werden. Problematisch ist dabei allerdings der Umgang mit den Alpha-Kanälen, die sich teilweise überlagern. Hier ist vorausschauende Planung notwendig.
Abbildung 10.46 stellt ausgewählte Renderings einer Komposition dar, bei dem das Multi-Channel-System für 3D-Rendering angewendet wurde. Abbildung 10.47 zeigt das Schema. Die Kompositionsebenen sind wie folgt angeordnet:

Das Channel-System im Rendering (Renderings)

Das Multi-Channel-System im Rendering (Schema)
-
1.
Der Hintergrund ist ein auf eine grobe 3D-Geometrie projiziertes, vom Scanline-Renderer des Compositing-Programmes gerendertes Matte-Painting (c). Zur Projektion wird die Position der Matchmove-Kamera verwendet, die in einem Frame festgehalten wird, das eine möglichst vollständige Sicht auf die Szene beinhaltet.
-
2.
Nun folgt das maskierte Live-Action-Footage (b), das mit dem Over-Algorithmus über den Hintergrund komponiert wird (d).
-
3.
Das Problem bei dieser Aufnahme ist, dass Teile der Hecke mit einem weißen Tuch maskiert wurden, um einen CG-Charakter einzubauen. Das zur Fixierung verwendete Stativ ist allerdings im Bildbereich des Live-Action -Footage vorhanden, das den Hintergrund bedeckt (a und d). Um das Stativ zu entfernen, muss eine Buschtextur über die entsprechende Stelle des Live-Action-Footages gelegt werden (f).
Das Rendern des Buschelements wird realisiert, indem seine Textur maskiert wird und dann mit einer eigenen Projektionskamera aus der Matchmove-Sequenz auf eine Card projiziert wird. Auch hier wird die Kamera in einem Frame festgehalten. Sie muss aber nicht zwingend die gleiche Position der Hintergrundkamera besitzen. Das genutzte Frame muss vor allem den Busch perspektivisch gut abbilden. Damit es keine Parallaxenverschiebung zwischen dem Live-Action-Footage und der Card gibt, ist es notwendig, die genaue Position des originalen Buschs in der 3D-Szene zu kennen und dort die Card zu platzieren. Hierbei ist ein vorhandener Lidar-Scan äußerst hilfreich. Damit der Hintergrund vom Busch-Rendering getrennt werden kann, wird die Busch-Textur in ein eigenes Channel-Set gelegt und die RGBA-Kanäle mit Schwarz gefüllt (Comp. 1).
Der Renderer rendert dann ein Bild, das aus zwei Channel-Sets besteht – RGBA (c) und Busch-RGBA (e). Nun kann das Footage unter Verwendung der ebenfalls gerenderten Maske über den Hintergrund gelegt werden (d, Comp. 2). Zum Schluss wird das Rendering in den Bush-Kanälen über das bisherige Ergebnis gelegt (f). Mit dieser Methode kann erhebliche Renderzeit eingespart werden und das Compositing ist auch übersichtlicher.
10.4.7 Set-Erweiterungen
Set-Erweiterungen (engl. set extensions ) sind eines der wichtigsten Anwendungsgebiete des Compositings. Schon seit den frühen 1900er-Jahren ist diese Filmtechnik gebräuchlich. Sie wurden weitestgehend analog mit Hilfe von Miniaturen, Matte-Paintings, Projektionen und anderen Technologien realisiert. Der Einsatz von Computergrafik findet in größerem Maßstab seit den frühen 1990er-Jahren statt. Je nach Komplexität der Aufnahme kommt entweder die 2.5D- oder 3D-Technik zum Einsatz.
Set-Erweiterungen werden verwendet,
-
wenn der Aufbau des kompletten Sets zu teuer ist,
-
wenn das Set regional angepasst werden muss (der Film wird zum Beispiel in Marokko gedreht, spielt aber in Bagdad, wo es zum Filmen zu gefährlich ist),
-
wenn sich die Szene in einer nicht oder schwierig zu filmenden Umgebung (Luft, unter Wasser, Weltraum, Gletscher, große Höhe) stattfindet,
-
wenn es sich um eine Fantasieumgebung handelt,
-
wenn die Umgebung im Film stark stilisiert ist usw.
Bei guter Planung können wichtige Objekte, die in der Set-Erweiterung erscheinen sollen, bereits am Set als einfache Modelle grob nachgebaut werden, um eine Referenz für den Lichteinfall zu erhalten. Ein sehr gutes Beispiel dafür ist das Matte-Painting von Mike Pangrazio am Ende des Filmes Raiders of the lost Ark (dt. Jäger des verlorenen Schatzes, Regie Steven Spielberg, USA 1981). Hier wird eine Kiste wichtigen Inhalts in einer Lagerhalle mit einer schier unüberschaubaren Menge weiterer Kisten an ihren Platz bewegt. Um eine interessante Lichtstimmung zu erzeugen, experimentierte Pangrazio mit einer Reihe von Modellkisten, die er beleuchtete. Schließlich übernahm er einige Stimmungen in das Matte-Painting, um die Kistenmenge aufzulockern.
Bei Greenscreen-Aufnahmen werden oft nur die Objekte gebaut, mit denen der Darsteller direkt agiert. Abbildung 10.48 zeigt eine solche Aufnahme, bei der der Darsteller in einer großen Höhe aus einer Tür auf ein am Gebäude entlang führendes Belüftungsrohr tritt. Hier wurde eine Tür als praktisches Requisit verwendet, um die Interaktionen des Schauspielers realistischer zu gestalten. Anhand der im Matchmoving generierten Marker kann die 3D-Szene modelliert und gerendert werden. Der im Keying freigestellte Akteur wird dann über den Hintergrund komponiert.

Anwendung einer Set-Extension
10.4.8 D-Relighting und Position-to-Points
Das 2.5D-Relighting ist ein modernes Compositing-Verfahren, bei dem die Beleuchtung gerenderter 2D-Bilder ohne Re-Rendering nachträglich verändert werden kann. Eng mit diesem Verfahren verknüpft ist die Point-to-Position-Technik, bei der die 2D-Renderings – ebenfalls wieder ohne Zuhilfenahme von 3D-Geometrie – im 3D-Raum dargestellt werden können.
Position-to-Points-Technik
Oft ist es notwendig, im internen 3D-Raum dem Compositing spezielle zusätzliche Elemente hinzuzufügen. Dies können texturierte oder projizierte Cards sein, einfache geometrische Objekte, aber auch Particle-Simulationen wie Schnee oder Regen. Ein prominentes Beispiel sind sogenannte Dust-Hits . Hierbei werden die kleinen Staubwolken simuliert, die ein Darsteller aufwirbelt, der sich in einem staubigen Terrain bewegt. Diese werden zumeist nicht mit aufwendigen 3D-Simulationen generiert, sondern man verwendet spezielle Filmsequenzen, in denen diese Verwirbelungen abfotografiert wurden. Die kurzen Dust-Hit-Filme werden dann als bewegte Texturen auf Cards gelegt und im 3D-Raum positioniert.
Da es für einen Compositing-Artist schwierig ist, die exakte Position der Dust-Hit-Card zu schätzen, ist der Import der 3D-Animationssequenz als Referenz von großer Hilfe. Dies ist aber in Bezug auf Performance und Speicherbedarf sehr aufwendig. Deshalb wird die Referenzierung der 3D-Positionen auf die 2D-Ebene verlagert. Dazu werden im 3D-Programm zusätzlich zum Beauty-Pass ein Position-Pass und ein Normal-Pass gerendert (siehe Abb. 10.51), wobei jeweils die Weltkoordinaten der 3D-Szene als Bezugspunkt gelten. Im Compositing angewendet, generieren beide Passes eine Punktwolke der im Beauty-Pass vorhandenen Pixel (Abb. 10.49, linkes Bild). Da nur die von der Render-Kamera gesehenen Teile der Geometrie im Beauty-Pass vorhanden sind, kann naturgemäß nicht das gesamte 3D-Objekt dargestellt werden (Abb. 10.49, rechtes Bild). Dies ist aber auch nicht nötig, denn der Compositing-Artist hat auch mit diesen rudimentären Informationen einen guten Überblick über die Positionen der entsprechenden Objekte im 3D-Raum, und da es sich bei den Render-Passes um 2D-Bildsequenzen handelt, ist der Rechen- und Speicheraufwand gering. Mit den Informationen der Punktwolke können dann die Dust-Hit-Cards an die entsprechenden Stellen, an denen die Füße des animierten Charakters den Boden berühren, eingefügt werden (vgl. Fxguidetv 2009).

Anwendung des Point-to-Position-Passes
In Abb. 10.50 erzeugt ein Position-to-Point-Operator die Punktwolke einer Szene, die neu beleuchtet werden soll. Um die Funktionalität des Operators zu gewährleisten, müssen die drei Passes Point-Pass , Normal-Pass und Beauty-Pass mit den entsprechenden Eingängen des Position-to-Point-Operators verbunden werden. In der 3D-Sicht wird dann die resultierende Punktwolke dargestellt.

2.5D-Relighting (Schema)
2.5D-Relighting
Mithilfe des 2.5D-Relightings können 2D-Renderings neu beleuchtet werden, ohne aufwendige 3D-Renderings durchführen zu müssen. Die Möglichkeiten der Beleuchtung sind allerdings sehr begrenzt, denn für das Erzeugen eines Schattenwurfs müsste das originale 3D-Modell importiert werden. 2.5D-Relightings sind aber sehr gut geeignet, die für das Compositing wichtigen Füll-, Streu- und Bounce-Lichter zu generieren. Die Anwendung bezieht sich deshalb vor allem auf oben genannte Lichtarten, dem Erzeugen farblicher Stimmungen und interaktiver Beleuchtung, wo Helligkeits- oder andere aus verschiedenen Quellen stammende Informationen dazu verwendet werden, den Lichteinfall auf ein bestimmtes Compositing-Objekt zu animieren.
Der Relight-Algorithmus verwendet die gleichen Passes, die beim Position-to-Points-Verfahren genutzt werden. Diese Passes werden mit den entsprechenden Eingängen der Relight-Node verbunden. Nun können ein oder mehrere 3D-Lichter hinzugefügt werden. Damit der Renderer die lokale Beleuchtung berechnen kann, muss ein Shader mit der Relight-Node verbunden werden, der die Materialeigenschaften vorgibt, die als Grundlage der Berechnung für die Beleuchtung dienen. Außerdem muss die originale Render-Kamera importiert und ebenfalls mit dem Relight-Operator verbunden werden. Zur Positionierung der 3D-Lichter ist es hilfreich, mit der Position-to-Points-Technik eine Punktwolke zu erzeugen.
Der Relight-Algorithmus berechnet ohne Zuhilfenahme des Scanline-Renderers ein neu beleuchtetes Bild auf der 2D-Ebene, das eventuell mit dem originalen Beauty-Pass – meist mittels Multiplikation – verknüpft werden kann.
In Abb. 10.50 ist das entsprechende Schema dargestellt, in Abb. 10.51 die entsprechenden Passes und das finale Rendering. Zur weiteren Ausarbeitung der Lichtstimmung wurde ein volumetrisches Licht in den 3D-Raum eingefügt und separat gerendert. Dieses kann dann mit dem neu beleuchteten Bild verknüpft werden – entweder mit Addieren, Negativ Multiplizieren oder hier mit dem Over-Algorithmus.

2.5D-Relighting (Passes und Rendering). Bearbeitete Modellvorlage von Greg Sendor (siehe Birn 2008)
10.5 Allgemeine Compositing-Aufgaben
In diesem Abschnitt werden einige der wichtigsten, immer wiederkehrenden Compositing-Aufgaben überblickartig vorgestellt.
10.5.1 Split-Screen
Beim Split-Screen-Verfahren wird das Bild geteilt und zeigt unterschiedliche Bildquellen gleichzeitig. Dies wird oft bei Sportveranstaltungen angewandt, wenn verschiedene Rennsituationen zur gleichen Zeit dargestellt werden sollen. Weiterhin findet es beim Bild-in-Bild-Verfahren Verwendung, wenn zum Beispiel Werbung in das TV-Bild eingeblendet werden soll.
Im Compositing wird das Bild meist dann geteilt, wenn Schauspieler mit sich selbst spielen. In der einfachsten Anwendung ist die Kamera fixiert (locked-off). Bewegt sie sich, muss ein Motion-Control-System vorhanden sein oder ein solches simuliert werden (engl. faked motion control). Dabei ist zu beachten, dass der Übergang, an dem das Bild geteilt wird, ausreichend Raum zum Erzeugen der Maske bietet (siehe Abb. 10.52, linkes Bild). Ansonsten muss die Maske aufwendig Frame für Frame animiert werden (siehe Abb. 10.52, rechtes Bild).

Split-Screen
Faked-Motion-Control
Professionelle Motion-Control-Systeme sind aufwendig und teuer. Im begrenzten Maße ist es aber möglich sie zu simulieren, wenn bestimmte Grundbedingungen eingehalten werden. Da zwei identische Kamerafahrten ohne präzise externe Kontrolle nicht möglich sind, wird ein Trick angewandt, bei dem die zweite Kamerafahrt entweder 4 bis 5-mal langsamer stattfindet oder eine wesentlich höhere Bildrate bei der Aufnahme verwendet wird. Im ersten Fall darf sich das gedoppelte Objekt nicht bewegen (oder 4 bis 5-mal langsamer). Im zweiten Fall ist eine realistische Bewegung möglich.
Da durch dieses Herangehen für den Zeitpunkt eines Frames in der ersten Aufnahme vier bis fünf Frames in der zweiten Aufnahme vorhanden sind, geht man davon aus, dass eines der Frames in der zweiten Aufnahme räumlich genau der Position des korrespondierenden Frames in der ersten Aufnahme entspricht. Es muss nun manuell den Frames der ersten Aufnahme jeweils ein Frame der zweiten Aufnahme zugeordnet werden. Als Vergleichskriterium zwischen beiden Frames kann entweder der Differenz-Modus angewandt werden oder ein Marker muss sich bei beiden Aufnahmen an der gleichen Position befinden.
Abbildung 10.53 zeigt ein solches Vorgehen. Dem Frame 0081 der ersten Aufnahme soll ein Frame der zweiten Aufnahme zugeordnet werden. Zur Auswahl stehen das Frame 0336 und die folgenden. Die entsprechenden Frames der ersten und zweiten Aufnahme werden nun beim Compositing mit einem Differenz-Operator verknüpft. Als Vergleichskriterium fungiert hier der Rand eines Sitzes in der ersten Reihe. Bei Frame 0336 erzeugt er einen hellen Rand – ein Indiz, dass beide Aufnahmen nicht korrekt übereinander liegen. Dieser Rand wird in Frame 0337 geringer und verschwindet in Frame 0338. In Frame 0339 wird er wieder größer. Das passende Frame ist somit Frame 0338.

Faked-Motion-Control
Auf diese Weise kann nun für jedes Frame in der ersten Sequenz das korrespondierende Frame in der zweiten Aufnahme zugeordnet werden. Nachdem die zweite Sequenz richtig nummeriert wurde, kann eine Maske beide übereinander komponierten Aufnahmen trennen.
Dieses Verfahren hat natürlich seine Grenzen. Wird eine Aufnahme schneller, die andere langsamer ausgeführt, ist zwar die Belichtung bei beiden gleich, da die Kameraparameter nicht verändert werden, aber die Bewegungsunschärfe ist unterschiedlich, da sich die Kameras nicht gleich schnell bewegen. Ist hingegen die Bildrate in beiden Aufnahmen unterschiedlich, muss die Verschlusszeit (Shutter) angepasst werden, was fast immer eine Farbkorrektur nach sich zieht. Außerdem muss sichergestellt werden, dass sich die Kameraposition zwischen den einzelnen Fahrten nicht verstellt. Trotzdem sind bei ausreichender Planung mit dieser Technik gute Ergebnisse zu erzielen, die auch professionellen Qualitätsanforderungen standhalten.
10.5.2 Spiegeln von Textelementen
Mit dem Spiegeln von Textelementen sehen sich Compositing-Artists häufig konfrontiert. Manchmal entscheidet sich der Regisseur aus künstlerischen Gründen (Bildkomposition, Anschlüsse im Schnitt), die Aufnahme horizontal zu spiegeln. Befinden sich Plakate, Schilder, Texte und andere Indikatoren im Bild, die eine solche Manipulation verraten (wie z. B. die Position des Fahrers in einem Kraftfahrzeug) müssen diese ebenfalls gespiegelt werden.
Da bei den Aufnahmen für den Film Titanic (Regie James Cameron, USA 1997) das Schiff zwar nahezu in Originalgröße nachgebaut wurde, aber nur die Steuerbordseite auch modelliert wurde, konnte nur diese Ansicht verwendet werden. Unglücklicherweise lag die historische Titanic mit der Backbordseite im Hafen von Southampton. Deshalb mussten die Aufnahmen vor dem Auslaufen des Schiffs in der Postproduktion horizontal gespiegelt werden, was erforderte, dass alle Texte im Bild seitenverkehrt im Szenenbild vorliegen mussten.
Abbildung 10.54 zeigt ein solches Vorgehen. Nachdem das Originalbild gespiegelt wurde, wird der Text des Schildes in die richtige Perspektive gebracht und an der richtigen Position eingefügt. Hier ist darauf zu achten, dass auch Sonneneinstrahlung und Schatten richtig platziert werden.

Spiegeln von Textelementen
10.5.3 Einfügen von Mündungsfeuer
In Action- und Kriminalfilmen ist der Schusswaffengebrauch ein wichtiges Dramaturgieelement. Das Abfeuern dieser Waffen erzeugt Mündungsfeuer, bei dem nicht verbrannte Pulverbestandteile oder nicht oxidierte Pulvergase als Flamme verbrennen. Bei vielen Real-Aufnahmen fehlt aber dieses Feuer, da dort selbst der Gebrauch von Platzpatronen zu gefährlich oder zu teuer ist. Deshalb müssen die Mündungsfeuer im Compositing nachträglich hinzugefügt werden.
Je nach Komplexität der Szene und der damit verbundenen Verdeckungen und Maskierungen können Mündungsfeuer – meist kurze Filme aus einer Bibliothek – auf der 2D- oder 2.5D-Ebene eingefügt werden. Es ist dabei zu beachten, dass dieses sehr helle Feuer Interaktionen mit der Waffe und dem Schützen selbst hervorruft, die dargestellt werden müssen (siehe Abb. 10.55).

Einfügen von Mündungsfeuer
10.5.4 Hinzufügen eines Glow-Effekts
Der Glow-Effekt ist einer der ältesten Compositing-Effekte. Er wurde besonders im Zusammenhang mit den Lichtschwertern (engl. lightsaber) in den Star-Wars-Filmen bekannt. Aber auch andere Darstellungen sind gebräuchlich, bei denen meist eine Erscheinungsform von Energie gezeigt werden soll. Ein Beispiel eines In-Kamera-Effekts ist ein blitzähnliches Element, das von einem Tesla-Transformator (engl. tesla coil) erzeugt wurde und dann optisch mit einem angegriffenen Raumschiff überlagert wurde. Abweichend von der Darstellung energetischer Effekte wird im Compositing auch eine weichgezeichnete, kontrastreiche Filmaufnahme als Glow-Effekt bezeichnet, bei der vor allem im Weißbereich jegliche Zeichnung aufgehoben wurde.
Abbildung 10.56 zeigt die Imitation eines Lichtschwerts. Grundlage sind drei Roto-Shapes, die entsprechend eingefärbt sind und mit zunehmender Größe eine abnehmende Opazität besitzen. Dies wird durch eine Gradientmaske unterstützt, die zum Rand hin transparenter wird. Die drei Roto-Shapes werden überlagert und mittels Tracking an die Bewegung des Schwertes angepasst.

Erzeugen eines Glow-Effekts
10.5.5 Warping und Morphing
Beim Warping werden Bildelemente nichtlinear deformiert oder verzerrt. Das Verfahren wird verwendet, um die Gestalt von Objekten oder Personen zu verändern, damit sie in eine Bildkomposition passen oder auch, um übernatürliche Phänomene zu kreieren. Prinzipiell wird unterschieden in Grid-Warping und Spline-Warping.
Grid-Warping
Beim Grid-Warping wird das Bild in Raster unterteilt und kann dann mit den Kontrollelementen an den Rasterpunkten entsprechend manipuliert werden, ähnlich dem Verkrümmen-Algorithmus in Photoshop. Die einzelnen Rasterpunkte können verschoben werden und verzerren damit die darunter liegenden Bildelemente. Weitere Einstellmöglichkeiten bieten Bézier-Handler an den Kontrollpunkten. Auch ihre Animation ist möglich, sodass die Verzerrung erst nach und nach sichtbar wird.
Abbildung 10.57 zeigt in der oberen Zeile eine solche Anwendung. Dabei wird ein Warp-Raster auf die Wolkenformation in einer Hafenstadt angewandt und diese verzerrt, sodass die Wolken nach oben gezogen werden – ungute Vorboten für kommende Ereignisse. Da durch diese Technik die Stadtsilhouette ebenfalls verzerrt wird, muss diese maskiert und über das Warping des Himmels gelegt werden, wobei dieser nach unten versetzt werden muss, um eine klare Trennung zwischen Stadt und Himmel zu erzielen.

Warping-Technologien
Spline-Warping
Beim Spline-Warping wird der zu bearbeitende Bildausschnitt durch ein Roto-Shape, das Quell-Shape definiert. In einem anderen Frame wird ein zweites Roto-Shape erstellt, das den Zielbereich angibt. Die Pixel, die um einen der Kontrollpunkte des Quellshapes angeordnet sind, werden dann sofort oder während einer Animation kontinuierlich an die Position des Ziel-Shapes versetzt. Das Bild wird entsprechend verzerrt. Diese Methode bietet eine hohe Kontrolle und wird dementsprechend vor allem bei Gesichtsveränderungen und -anpassungen bei Charakteren verwendet.
Abbildung 10.57 zeigt in der unteren Zeile eine solche Anwendung. Hier soll die Mutation eines Bullen gezeigt werden, wobei langsam ein roter Augapfel zum Vorschein kommt, wenn er das Auge öffnet.
Morphing
Morphing ist eine Kombination zwischen einer normalen Überblendung (engl. dissolve), wie sie im Filmschnitt angewendet wird, und einem Warping – meist einem Spline-Warping. Der Eindruck, den der Zuschauer erhält, ist, dass Objekt oder Feature A die Gestalt von Objekt oder Feature B annehmen. Diese Technik wird vor allem für Fantasieeffekte und ungeschnittene Übergänge von Schauspielern zu ihren Doubles angewendet. Hier gibt es mehrere Methoden, wie der Übergang der beiden Features gehandhabt wird. Entweder erfolgt das Morphing von einer Gestalt auf die andere oder der Morphing-Vorgang läuft in zwei Richtungen, dann ändern beide Objekte ihre Gestalt und treffen sich in der Mitte. Durch einen Dissolve-Übergang wird dann Feature A zu Feature B überblendet.

Morphing
10.5.6 Day-for-Night und Dry-for-Wet
Bei Day-for-Night -Aufnahmen (dt. Amerikanische Nacht) wird die Aufnahmezeit für eine in der Nacht spielende Szene auf den Tag oder die Dämmerung verlegt, da am Tag die Lichtsituation und damit die Filmbelichtung besser ist und weniger Rauschen produziert.

Day-for-Night – Original und Bearbeitung (Bilder: © Christoph Hasche)
Die Compositing-Aufgaben liegen hier in der Absenkung der Luminanz, unterstützt durch Unterbelichtung und Verwendung eines ND-Filters bei der Aufnahme und dem Anheben von Kontrast und Gamma, wodurch größere Bildteile zu Schwarz verschwimmen. Oft wird der Aufnahme ein bläulicher Farbton gegeben, wenn sie direkt nach Sonnenuntergang spielt. Die Wirkung von im Bild befindlichen Lichtquellen wird meist verstärkt und zusätzliche Lichter, Lampen, Fackeln, Feuer etc. werden vom Compositing-Artist nachträglich eingefügt.
Christoph Hasche, Compositing-Artist bei RISE | Visual Effects Studios (The Avengers, Captain America, Harry Potter) sagt dazuFootnote 9:
Bei einer Day-for-Night-Aufnahme sollte man stets beachten, dass es nicht nur darum geht, die Sonne auszuschalten bzw. das Sonnenlicht als Mondlicht „zu verkaufen“, sondern vielmehr die Szenerie in „Nacht“ zu ändern.
Schauen wir auf eine Stadt, sind mit aller Wahrscheinlichkeit die Lichter der Fahrzeuge, Straßenbeleuchtung, Leuchtreklamen und Innenraumlichter der Gebäude an. Befinden wir uns in einem Raum, sehen wir die Lichter der Umgebung durch die Fenster. Findet die Szene in Gelände ohne Zeichen menschlicher Zivilisation statt, kann man darüber nachdenken, mit zusätzlichen Keyligths zu beleuchten, um die Szene besser gestalten zu können. Die Schatten des Mondlichtes sind zwar zumeist sehr hart, jedoch bekommt man oft bessere Ergebnisse bei Aufnahmen mit bedecktem Himmel. Grund sind die minimierten Reflexionen der Sonne. Gerade die Haut des Menschen, insbesondere die Stirn, ist sehr reflexiv. Hier muss man bei der Aufnahme vorsichtig sein, denn die Reflexion der Sonne im Gesicht sollte unbedingt vermieden werden, da sie in der Nachbearbeitung nur aufwendig zu entfernen ist.
Der Look einer Day-for-Night-Aufnahme sollte zunächst farblich neutral sein. Dass die Nacht „blau“ ist, ist falsch und eher emotional zu sehen. Bilder, die bei Mondlicht aufgenommen worden sind, haben eher einen leichten Grünstich, sind aber weitgehend neutral.
Meist erfordert ein Day-for-Night-Grading zusätzliche Luma-Keys und aufwendige Masken, um Highlights gesondert bearbeiten zu können. Ein hoher Kontrastumfang der Aufnahme ist notwendig, um die Highlightspitzen herunterregeln zu können. Durch die Komplexität ist es sinnvoll, Day-for-Night-Aufnahmen nicht während der der Standardfarbkorrektur, sondern in der VFX-Abteilung zu bearbeiten, da die Tools hier feiner und präziser sind.
Eine ähnliche Compositing-Aufgabe ist Dry-for-Wet , bei der durch die Verwendung von analogem Rauch, Farbfiltern und digitalen Effekten – wie eingefügte driftende Partikel und Luftblasen – die Illusion einer Unterwasseraufnahme erzeugt wird, zum Beispiel bei den Aufnahmen der U-Boote im Film The Hunt for Red October (dt. Jagd auf Roter Oktober, Regie John McTiernan, USA 1990).
10.5.7 Video-Look und Hologramme
Video-Look wird verwendet, wenn Video- oder Fernsehsignale dargestellt werden sollen. Dazu gehören Überwachungskameras, Kommunikationseinheiten, Helmkameras wie die im Film Aliens (Regie James Cameron, USA 1986) und alle Arten der elektronischen Bildübertragung, zum Beispiel die Werbetafeln in Blade Runner (Regie Ridley Scott, USA 1982). Die Darstellung des gesendeten Bildes ist meist grob, die Zeilen des Video-/Fernsehbildes sind zu erkennen und das Signal selbst ist oft instabil und neigt zu Störungen und Rauschen.
Im Gegensatz dazu werden Hologramme und dreidimensionale Projektionen verwendet, um die hochtechnologisierte Umgebung zu zeigen, in der der Film spielt. Hologramme sind fester Bestandteil von Science-Fiction und wurden bereits in den ersten Star-Wars-Filmen eingesetzt. Neuere Produktionen verwenden sie vor allem zur Darstellung von umfangreichen, unübersichtlichen Umgebungen (Prometheus – Regie Ridley Scott, USA 2012) oder umfangreichen Kampfhandlungen (Guardians of the Galaxy – Regie James Gunn, USA 2014).
Um den künstlichen und gleichzeitig übersichtlichen Hologrammlook zu erhalten, werden beim Shading in den 3D-Programmen Halbtransparenzen verwendet, die dafür sorgen, dass der Hauptkörper durchsichtig wird und nur die opaken Ränder die Form definieren. Außerdem werden Farbgradienten eingesetzt, die sich auf die Richtung der Normalen beziehen (engl. facing angle , fresnel pass ). Abbildung 10.60 zeigt zwei Helixmodelle, die mit diesen Techniken gerendert wurden.

Halbtransparente Helixe mit Ramp-Facing-Angle-Shader
10.5.8 Anwendung von 2D-Motion-Blur
Ein wichtiger Aspekt für die realistische Darstellung von bewegten Objekten ist die Gestaltung der Bewegungsunschärfe. Bei fotografischen Aufnahmen erfolgt dies durch eine entsprechend lange Öffnung des Verschlusses (engl. shutter ), während der das fotografierte Objekt seine Position verändert und unterschiedliche Teile des Filmes mit den gleichen Features unterschiedlich stark belichtet werden, sodass vor allem an den Rändern eine Unschärfe auftritt.
Im 3D-Rendering muss diese Unschärfe künstlich hinzugefügt werden. Das ist meist nur mit großem Rechenaufwand möglich. Deshalb werden die schneller zu ermittelnden Bewegungsvektoren der einzelnen Pixel auf die 2D-Ebene konvertiert und als 2D-Motion-Vector-Pass ausgegeben. Auf dessen Grundlage wird dann im Compositing die Bewegungsunschärfe hinzugefügt (siehe Abb. 10.61).

Anwendung des 2D-Motion-Vector-Passes
In modernen Compositing-Programmen ist es darüber hinaus möglich, die Bewegungsvektoren von Objekten in Filmaufnahmen zu ermitteln. Sind Vorder- und Hintergrund durch Masken separiert, können spezielle Algorithmen anhand der durch die Parallaxe unterschiedlich schnellen Bewegungen der Bildteile einen Vector-Pass erzeugen, der dann ebenso zur Gestaltung der Bewegungsunschärfe eingesetzt werden kann.
10.5.9 Retiming mit Optical-Flow
Die Änderung der Dauer und damit der Geschwindigkeit einer Aufnahme (engl. retiming ) gehört ebenfalls zu den Arbeiten, die ein Compositing-Artist ausführen muss. Dies geschieht aus technischen Gründen, wenn zum Beispiel ein Filmclip frame-genau in einen kurzen Werbespot eingepasst werden soll oder aus ästhetischen Gründen, beispielsweise wenn die wahrgenommene Geschwindigkeit der Aufnahme nicht den Intentionen des Regisseurs entspricht.
Die Geschwindigkeit einer Bildsequenz kann manuell erhöht werden, etwa durch die Entfernung von jedem dritten Bild. Bei geringer Verschlusszeit der Originalaufnahme kann allerdings ein sprunghafter stroboskopischer Eindruck bei der Wiedergabe entstehen, was wiederum oft gewollt ist. Besonders bei Actionfilmen kommt dieser Effekt zum Einsatz, um die Dynamik der Darstellung zu unterstreichen. Eine weitere Möglichkeit besteht darin, Bilder zu überlagern – zum Beispiel Bild 1 und 2 ergeben das neue Bild 1, Bild 3 und 4 ergeben das neue Bild 2 usw.
Im modernen Compositing wird das Retiming mithilfe der Optical-Flow-Technologie ausgeführt. Grundlage des Optical-Flows ist die scheinbare Bewegung von Bildpunkten oder Regionen von einem Frame zum anderen. Dabei wird ein Vektorfeld erzeugt, das die horizontale und vertikale Bewegung eines jeden Pixels im Bild beschreibt. Unterstützt wird dieses durch die Annahme, dass es Objekte in einer Szene gibt, deren Pixel die gleiche Bewegungsrichtung haben – zum Beispiel alle Pixel eines Autos. Der Optical-Flow einer Bildsequenz ist schwierig zu berechnen, da die Aufrechterhaltung der Luminanz im Bild – eine grundlegende und wichtige Annahme – durch unterschiedliche Faktoren erzielt werden kann. Andererseits ändern sich die Grenzlinien zwischen den bewegten Objekten aufgrund von Lichtveränderungen oder Bewegungsunschärfe etc. und machen es schwierig, die Pixel dem einen oder anderen Objekt zuzuordnen. Außerdem können sich Glanzlichter auf bewegten Objekten aufgrund der Winkeländerung in eine andere Richtung bewegen als das Objekt selbst. Trotzdem können mit dieser Technologie abhängig vom Material sehr gute Ergebnisse erzielt werden (vgl. Seymour 2006).
Abbildung 10.62 zeigt die Verlangsamung einer schnellen Bewegung um die Hälfte. Hierzu wurde der interne Nuke-Operator Kronos verwendet. Dieser berechnet für die angegebene Geschwindigkeitsänderung zwischen zwei Frames auf den Positionen 0 und 1 zwei Bilder auf den Positionen 0,25 und 0,75, um keine Originalbilder verwenden zu müssen, die im Look unterschiedlich sein könnten.

Retiming mit Optical-Flow-Technologie
Ein wichtiger Bestandteil für eine realistische Verlangsamung der Geschwindigkeit ist die Bewegungsunschärfe. Diese kann im Optical-Flow-Verfahren kontrolliert hinzugefügt werden (siehe Abb. 10.62, rechtes Bild).
10.5.10 Anpassung der Rauschmuster und der Körnung im Filmmaterial
Neben differierender Farbqualität stellen unterschiedliche Rauschmuster eines der Hauptprobleme beim Zusammenfügen von Bildmaterial aus verschiedenen Quellen dar. Aus unterschiedlichen Ausgangsmaterialien bestehende analoge Filmnegative weisen unterschiedliche Rauschmuster auf, wobei sich die Muster von Bild zu Bild aufgrund der Anordnung der Moleküle verändern. Video- und digitale Filmkameras unterscheiden sich ebenfalls im Rauschen. Ihre Muster sind in der Regel statisch und damit auffälliger als das analoge Rauschen im analogen Filmnegativ. Infolge der Verwendung der Path-Tracing-Renderer tritt auch in der zuvor als a priori rauschfrei angesehenen Computergrafik verstärkt Rauschen auf.
Zur Anpassung der Rauschmuster werden je nach Problemstellung entsprechende Herangehensweisen gewählt. Bei unterschiedlichen Rauschmustern der Bildsequenzen werden die stärker verrauschten bzw. weniger relevanten Aufnahmen zunächst entrauscht (engl. denoising , degraining für Film), um dann mit dem Rauschmuster der wichtigeren Aufnahme versehen zu werden. Bisweilen wird auch das Rauschen bzw. die Körnung beider Aufnahmen entfernt, um später ein anderes Körnungsmuster beispielsweise aus populären Film-Stocks „künstlich“ hinzufügen zu können.
Für VFX-Shots gilt auch hier die Regel, dass die Originalaufnahmen nicht verändert werden dürfen. Man würde somit versuchen, für eingefügte CG-Elemente das Rauschmuster des Live-Action-Footage zu imitieren.
Wird ein Standbild (Still) über Live-Action-Footage gelegt, zum Beispiel um eine Clean-Plate zu erzeugen, setzt sich dieses deutlich ab, da sich sein Rauschen bzw. die Körnung im Gegensatz zur Aufnahme nicht verändert. Hier ist es sinnvoll, eine ausreichend lange Schleife anstelle eines Einzelbildes zu verwenden, so dass die Wiederholung des Rauschmusters nicht auffällt. Beim Einfügen von Computergrafik wird bisweilen wiederum ein künstliches Rauschen hinzugefügt, um Kantenartefakte (engl. contouring artefacts) zu maskieren.
Abbildung 10.63 zeigt den Vorgang des Entrauschens mit dem Denoise-Operator in NukeX. Eine Region markiert eine Bildfläche ohne Detail. Der Algorithmus analysiert dann das Rauschen und entfernt es. Diese Daten können dann gespeichert werden und auf eine andere Aufnahme angewendet werden.

Denoising
10.6 Tiefen-Compositing
10.6.1 Grundlagen des Depth-Compositings
Beim Depth-Compositing werden einzelne Bildabschnitte anhand ihrer Entfernung zur Kamera bearbeitet. Dabei erhält der Compositing-Artist zusätzliche Informationen über die räumliche Anordnung des verwendeten Bildmaterials, die er für verschiedene tiefenabhängige Effekte verwenden kann, wie nachträgliches Festlegen der Schärfentiefe, Einfügen von Staub und Dunst und das Depth-Compositing im engeren Sinne, das ohne die Verwendung von Holdout- und anderen Masken auskommt.
Um die Tiefeninformationen zu generieren, muss entweder ein (Kamera)-z-Depth-Pass im 3D-Programm gerendert werden oder es ist möglich, im Compositing-Programm direkt aus einer Bildsequenz unter Zuhilfenahme einer Matchmove-Kamera diesen z-Pass zu generieren. Die Entfernung der einzelnen Pixel von der Kamera wird dann als Graustufenwert ausgegeben. Aufgrund der erforderten Genauigkeit ist es sinnvoll, diesen Pass mit 32-Bit-Fließkomma-Auflösung zu berechnen und dem Algorithmus Angaben zu machen, welcher räumliche Bereich in Betracht gezogen werden soll, um die Effizienz der Codierung zu verbessern. Je nach Implementierung werden Werte nahe an der Kamera mit Weiß (1,0) codiert und Werte am Ende des vorgegebenen Bereichs mit Schwarz (0,0) oder umgekehrt.
Abbildung 10.64 zeigt zwei Anwendungen des z-Depth-Passes. Das linke Bild stellt die Tiefenstaffelung von verschiedenen Objekten in einer 3D-Szene dar. Je dunkler der Graustufenwert der Objekte im z-Depth-Pass ist, desto größer ist ihre Entfernung von der Kamera. Die entsprechende Tiefenausdehnung der Objekte wird durch einen hier nicht sichtbaren Graustufenverlauf dargestellt (linkes Bild). Das rechte Bild zeigt die Tiefenstaffelung einer Bildsequenz, die im Compositing-Programm erzeugt wurde. Zur besseren Darstellung der Tiefeninformationen werden diese programmintern auf eine Card gelegt, die mithilfe der Displacement-Funktion so verzerrt wird, dass man einen ungefähren Anhaltspunkt für die Tiefenausdehnung der Szene erhält und gegebenenfalls andere Objekte einfügen kann. Es ist dabei zu beachten, dass bei der Ermittlung der z–Depth-Werte der einzelnen Pixel diese auf einer gedachten Ebene liegen, die senkrecht zur z-Achse steht. Bei der Ermittlung des z-Depth-Wertes wird der Abstand der Ebene von der Kamera berechnet und nicht die Distanz der Pixel zur Kamera, die in der Regel größer ist (siehe Abb. 10.64, rechtes Bild).

Prinzip der Anwendung des z-Depth-Passes
10.6.2 Anwendung des Depth-Compositings
Nachträgliches Festlegen der Schärfentiefe
Eine wichtige Anwendung des z-Depth-Passes besteht in der nachträglichen Festlegung der Schärfentiefe. Da die einzelnen Bestandteile der Komposition über Tiefeninformationen verfügen, ist es möglich, den Schärfebereich (engl. depth of field ) in Ausdehnung und Position frei zu justieren. Mit dem ZDefocus-Operator ist in Nuke ein hilfreiches Analysewerkzeug enthalten, mit dessen Hilfe die einzelnen Schärfebereiche dargestellt werden können.
In Abb. 10.65 sind zwei unterschiedliche Positionen des Schärfebereichs angegeben. Dabei sind die grünen Elemente im Fokus, die roten, hinter dem Schärfebereich liegenden Elemente und die blauen Elemente vor ihm sind unscharf. Der Algorithmus unterteilt den roten und blauen Unschärfebereich weiter in eine Anzahl von Ebenen und fügt einen größeren Betrag von Unschärfe hinzu, je entfernter die einzelnen Ebenen vom Schärfebereich liegen. Position und Ausdehnung des Schärfebereichs sowie der Betrag der Unschärfe können individuell festgelegt werden.

Einstellen der Schärfentiefe mithilfe einer Depth-Map
Bokeh-Effekt
Die künstlerische Ausgestaltung des Unschärfebereichs wird in der Fotografie unter dem Begriff Bokeh gefasst. Dabei wird versucht, die objektivabhängigen Unschärfen nach ästhetischen Gesichtspunkten zu nutzen. So werden Ringe, Kreise und auch die innere Form der Blende dargestellt. Konsequenterweise kann in der ZDefocus-Node in Nuke für einen Blendeneffekt die Anzahl der Blendenlamellen festgelegt werden.
Weitere tiefenabhängige Effekte
Atmosphärische Effekte wie Dunst, Nebel und Verschleierungen sind essenziell für eine glaubhafte Komposition von Außenaufnahmen. Besonders Städte leiden unter der Feinstaubeinwirkung, die dazu führt, dass besonders bei Panoramaaufnahmen entfernte Stadtteile im Staub verschwimmen. Streulichter des Himmels und der Umgebung überlagern die Komposition in unterschiedlicher Transparenz und werden stärker, je weiter die Objekte entfernt sind. Damit wird auch die Wirkung von Dunst und Staub größer. Durch eine Kombination von Farbkorrekturen (Verringerung des Kontrasts, Entsättigung, Luminanzerhöhung) und einer subtil angewendeten Unschärfe können diese Effekte im Compositing simuliert werden, wobei sie sich graduell entsprechend zum Hintergrund hin verstärken. Ein weiterer Effekt, der durch die Anwendung des z-Depth-Passes kontrolliert werden kann, ist der Lichtabfall von im Compositing eingefügten Lichtern.
Depth-Compositing
Eine weitere wichtige Anwendung des z-Depth-Passes ist das Depth-Compositing. Hier werden keine Masken verwendet, um die Bilder zu kombinieren. Da bei Verwendung eines z-Depth-Passes (auch engl. depth map ) jedes Pixel eine definierte Position in der Tiefe besitzt, kann der Algorithmus erkennen, wann es von einem Pixel eines anderen Bildes verdeckt wird, das sich näher an der Kamera befindet. Depth-Maps werden vor allem in 3D-Programmen generiert. Aber auch Footage kann in solche Kompositionen eingefügt werden. Hierbei wird dem Material ein z-Depth-Kanal hinzugefügt und mit Grauwerten versehen, die den jeweiligen Positionen der Pixel entsprechen. Der Depth-Compositing-Algorithmus ordnet die Aufnahmen dann an der entsprechenden Stelle ein.
Abbildung 10.66 zeigt das Schema einer Depth-Komposition in Nuke. Um die beiden Bilder (Image A und Image B) kombinieren zu können, müssen die Tiefeninformationen in ein gemeinsames Channel-Set kopiert werden, da beide Bilder in unterschiedlichen Channel-Sets in der jeweiligen OpenEXR-Datei liegen (Falke-Depth und Schilf-Depth). Hierzu bietet sich das vorgefertigte Depth-Channel-Set (depth) an. Da der Tiefenkanal nur ein Graustufenbild ist, wird lediglich der rote Kanal im Depth-Channel-Set verwendet, der zur besseren Übersicht bereits vordefiniert die Bezeichnung z erhalten hat. Die beiden anderen Kanäle (Grün, Blau) des Depth-Channel-Sets bleiben unbelegt, ebenso der Alpha-Kanal. Bei der Darstellung erscheinen die Tiefenwerte deshalb rot. Nun können die Pixel der RGB-Kanäle beider Bilder anhand der Verdeckungen im Tiefenkanal kombiniert werden.

Depth-Compositing (Schema)
Bei der Anwendung des Depth-Compositings ergibt sich auch die Möglichkeit, die Objekte in einem bestimmten Rahmen räumlich anders anzuordnen, ohne die Szene neu rendern zu müssen. Es treten allerdings zwei Probleme auf, die den Umgang mit Depth-Compositing erschweren. Das erste entsteht durch das Anti-Aliasing im Depth-Pass . Bei Depth-Passes handelt es sich um 32-Bit-Graustufenbilder, deren Grauwerte die Entfernung der Pixel von der Kamera angeben. Wird ein Anti-Aliasing-Algorithmus angewandt, werden die Kanten der Objekte im Depth-Pass geglättet, indem die Grauwerte durch Verläufe heller gemacht werden. Dadurch verändert sich aber auch ihre Position im Raum. Sie werden graduell näher an die Kamera versetzt.
Abbildung 10.67 zeigt die Artefakte. Teile der horizontalen Kante der Bodenplatte, die viel tiefer im Raum liegt als der Falke, werden – da sie durch das Anti-Alaising heller gemacht wurden – nach vorn verlagert und über dem Bauch des Falken dargestellt, da dessen Grauwerte dort dunkler und somit weiter von der Kamera entfernt sind. Noch problematischer ist die Situation im rechten Bild. Hier wurde der Falke nach rechts hinten verschoben. Nun erscheinen aus dem gleichen Grund vertikale Kanten des Schilfs vor dem Falken-Objekt. Für Depth-Passes muss deshalb das Anti-Aliasing beim Rendern abgeschaltet werden. Dies gilt gleichermaßen für Point-Position-Passes. Problematisch ist allerdings die Darstellung von feinem Detail wie Haar oder Fell, für das ein nicht weichgezeichneter (gefilterter) Depth-Pass nicht akkurat genug ist.

Grenzen des Depth-Compositings
Das zweite Problem besteht darin, dass der Depth-Pass nicht die gesamte Szene wiedergibt, sondern nur die Position von Pixeln auf der Oberfläche von Objekten, die jeweils am nahesten an der Kamera sind. Objekte, die diese verdecken, werden ignoriert. Dies führt zu einer falschen Darstellung, wenn halbtransparente Szenenelemente in der Tiefe hintereinander liegen und ein Objekt sich langsam vorwärts bewegt. Außerdem erzeugen Berechnungen von Bewegungsunschärfe und Schärfentiefe bei transparenten Objekten, detailreichen Elementen wie Haaren und Fell, aber auch an den Kanten von opaken Objekten eine Reihe von Artefakten. Diese Probleme werden vom Deep-Compositing adressiert.
10.6.3 Deep-Compositing
Im Deep-Compositing (auch Deep-Image oder Deep-Image-Compositing ) werden zusätzliche Informationen über die Tiefenstaffelung von Objekten in der 3D-Szene erzeugt. Dies hat eine Reihe von Vorteilen:
-
1.
Die Notwendigkeit, 3D-Szenen neu zu rendern, wird reduziert,
-
2.
die Qualität des Bildmaterials nach dem Compositing wird erhöht,
-
3.
das Bilden von Artefakten an Kanten und bei transparenten Objekten wird vermieden.
Abbildung 10.68 zeigt das traditionelle Vorgehen beim Re-Rendern eines Objekts, das sich innerhalb eines volumetrischen Effekts (Schneefall) befindet und in seiner Tiefenposition verändert wurde. Beim Rendern wird der volumetrische Effekt – hier zur besseren Übersicht gelb und weiß dargestellt – in zwei Render-Layer aufgeteilt und an der Position des Objektes geteilt. Es werden somit drei Render-Layer ausgegeben: der volumetrische Effekt hinter dem Objekt, das Objekt selbst und der volumetrische Effekt vor dem Objekt. Diese Render-Layer werden dann im Compositing in der angegebenen Reihenfolge übereinandergelegt. Wird das Objekt neu positioniert, müssen die Grenze des volumetrischen Effekts neu definiert und die beiden Render-Layer des Effekts neu gerendert werden.

Traditionelles Rendern eines volumetrischen Effekts
Das Konzept des Deep-Compositing beruht darauf, dass Informationen von Position, Farbe und Opazität für jedes volumetrische Partikel vorliegen, sodass eine Neupositionierung im Compositing vorgenommen werden kann, ohne die Szene neu zu rendern. Außerdem wird die Qualität der resultierenden Bilder erhöht, da transparente Pixel bei der Anwendung von Effekten, die Tiefeninformationen verwenden – wie beispielsweise Bewegungsunschärfe –, weitestgehend artefaktfrei gerendert werden.
Prinzip des Deep-Compositings
Beim Standard-Composting hat jedes Pixel nur einen Farb-, Tiefen- und Opazitätswert. Beim Verwenden von Deep-Images enthält jedes Pixel so viele unterschiedliche Farb-, Tiefen- und Opazitätsinformationen wie die in der Tiefe gestaffelten Objekte, die es repräsentiert.
Abbildung 10.69 zeigt das Prinzip. In der Szene befinden sich fünf Fensterrahmen mit Glasscheiben, die jeweils eine Opazität von 20 % besitzen. Die Render-Kamera sendet einen Strahl in die Szene. Dieser trifft nach und nach auf die Fensterscheiben und sammelt die entsprechenden Informationen. Die Position des Pixels im Rendering ist im unteren linken Bild angegeben, die entsprechenden Deep-Informationen werden im unteren rechten Bild dargestellt. Dabei handelt es sich um die Entfernungen von der Kamera (deep front, deep back), die Farbwerte (rgb.red, rgb.green, rgb.blue) und die Opazität (rgb.alpha). Da die Fensterscheibe im Modell aus einem Quader besteht, werden jeweils zwei Positionen angegeben. Die Opazitäten auf dem Weg des Render-Strahls durch die Szene addieren sich in diesem Beispiel in Form einer Treppenstufe (oberes linkes Bild).

Prinzip des Deep-Image-Compositings
Einfügen eines Objektes im Deep-Compositing
Der Vorteil des Deep-Image-Verfahrens besteht u. a. darin, den Hintergrund zu rendern und dann Objekte im Compositing an einer beliebigen Stelle einzufügen und zu animieren, ohne den Hintergrund neu rendern zu müssen. Da alle Daten der Objekte vorhanden sind, ordnet sich das Objekt an der richtigen Stelle ein.
Abbildung 10.70 zeigt wieder das Prinzip. Es wird ein Fußball in das Deep-Compositing eingefügt. Die Position eines beliebigen Pixels und die entsprechenden Daten werden in der unteren Reihe dargestellt.

Einfügen eines Deep-Image-Elementes
Da sich die Position des Balls hinter der ersten Scheibe befindet, wird er von dieser zu 20 % verdeckt. Da er selbst eine Opazität von 100 % hat, verdeckt er alle nachfolgenden Objekte.
Verändern der Position eines Objektes im Deep-Compositing
Die Möglichkeiten des Deep-Compositings können nun genutzt werden, um den Ball anders zu positionieren. Abbildung 10.71 zeigt das Prinzip. Der Ball wird nun hinter die dritte Fensterscheibe bewegt. Da – im Gegensatz zum traditionellen Compositing – die Informationen zu den Objekten hinter der Ballposition in Abb. 10.70 vorhanden sind, addieren sich die Opazitäten durch die nun drei Fensterscheiben auf 60 %. Der Ball wird dadurch zum Teil verdeckt und ist nicht mehr so klar zu sehen wie in der vorhergehenden Abbildung.

Verändern der Tiefenposition eines Deep-Image-Elementes (Grundlagen)
Abbildung 10.72 zeigt das Schema des Compositing-Netzwerks in Nuke. Die beiden Elemente der Szene – der Ball und die Fensterrahmen – werden mit je einer DeepRead-Node eingelesen. Diese importieren die Farb-, Opazitäts- und Deep-Informationen. Damit der Ball an eine andere Position in der Szene versetzt werden kann, wird ein DeepTransform-Node eingefügt. Da der Ball entfernter von der Kamera platziert wird, muss er verkleinert werden. Dazu wird eine Deep-Reformat-Node eingefügt.

Verändern der Tiefenposition eines Deep-Image-Elementes (Schema)
Zentraler Operator in diesem Beispiel ist die DeepMerge-Node, die anhand der Deep-Daten feststellt, welches Pixel in den unterschiedlichen Objekten näher an der Kamera positioniert ist. Unter Verwendung der Farb- und Opazitätsdaten wird dann das Ausgabebild gerendert. Da zumeist im 2D-Raum weitergearbeitet wird, muss das Deep-Image konvertiert werden. Der DeepToImage-Operator entfernt alle Deep-Daten, rendert das RGB-Bild und legt die Opazitätsinformationen in den Alpha-Kanal.
10.6.4 Praktische Erwägungen für das Deep-Compositing
Generieren von Deep-Image-Daten
Deep -Images können vor allem in 3D-Programmen erzeugt werden. Lange Zeit war Pixars PRMan der einzige Renderer mit dieser Funktionalität. Inzwischen können eine Reihe weiterer Renderer wie V-Ray Footnote 10 (Chaos Group), Maxwell Footnote 11 , Mantra (Side FX) Footnote 12 und Arnold (Solid Angle) Footnote 13 diese Daten erzeugen. In NukeX ab Version 8 ist es möglich, mithilfe des Scanline-Renderers Deep-Daten der internen 3D-Szene zu generieren. Generell ist zu überprüfen, ob Compositing-Programme unter dem Begriff Deep-Compositing auch das hier vorgestellte Verfahren verstehen. Manchmal wird auch das Point-Position-Konzept als Deep-Image-Verfahren deklariert.
Bevorzugtes Speicherformat sind OpenEXR 2.0-Dateien, da sie ohne zusätzliche Installation von Software geschrieben und gelesen werden können. Außerdem verfügen sie noch über einen sehr effektiven verlustfreien Kompressionsalgorithmus (zip 1), wodurch die teilweise erheblichen Datenmengen (bis zu einem TB pro Frame) in ihren Größenordnungen reduziert werden können.
Möglichkeiten des Einsatzes von Deep-Image-Daten
Deep-Daten können vor allem im Compositing in NukeX neben den schon genannten Einsatzmöglichkeiten weitere Anwendung finden:
-
1.
Es ist möglich, wie beim Position-to-Point-Verfahren die Deep-Daten als Punktwolke darzustellen, vor allem, um weitere Elemente platzieren zu können.
-
2.
Farbkorrektur kann tiefenabhängig ausgeführt werden. Durch entsprechende Maskierungen im DeepColor-Operator kann der Raum in Abschnitte mit weichen Kanten unterteilt und farbkorrigiert werden.
-
3.
Volumetrische Kompositionen können in gewissem Rahmen ausgeführt werden. Vor allem das interne Partikel-System in Nuke kann in das Deep-Compositing eingefügt werden.
-
4.
Footage kann ebenfalls im Zusammenhang mit Deep-Images Verwendung finden. Einerseits können Aufnahmen auf Cards im 3D-Raum eingefügt werden, andererseits ist es möglich, mit internen Werkzeugen einen Depth-Pass zu erzeugen, der von dem ImageToDeep-Operator als Tiefeninformationen interpretiert wird und in das interne Deep-Format umgewandelt wird. Ist kein Depth-Pass vorhanden, kann dieser als Graustufenbild hinzugefügt werden, wobei der Graustufenwert die Entfernung zur Kamera angibt. Es ist hierbei darauf zu achten, dass das Live-Action-Material einen Alpha-Kanal besitzt, damit der Deep-Algorithmus entsprechende Opazitätswerte generieren kann.
-
5.
3D-Animationen mit Deep-Images können weitestgehend artefaktfrei realisiert werden. Abbildung 10.73 zeigt drei Frames einer stilisierten 3D-Animation, bei der die sich bewegende Render-Kamera importiert wurde. Der Falke kann dann animiert werden. Er bewegt sich durch das Schilfgebiet, wobei sich die einzelnen Schilfhalme nahtlos vor oder hinter ihm platzieren. Die dabei auftretenden Überblendungen an den Kanten sind weich und ohne Artefakte.
Abb. 10.73 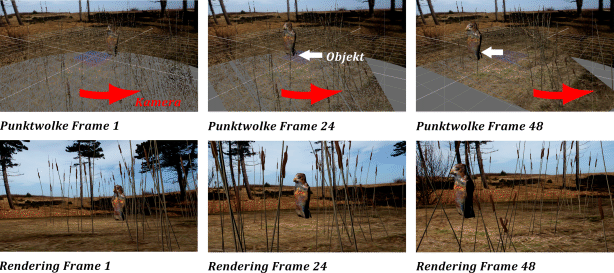
Deep-Image-Animation

Probleme im Deep-Compositing
Auch das Deep-Compositing ist naturgemäß nicht frei von Problemen. Während beim Compositing in der Regel kaum Artefakte auftreten, gibt es eine Reihe physikalisch bedingter Komplikationen, die auch das Deep-Compositing nicht sofort lösen kann. Abbildung 10.74 zeigt zwei traditionelle Renderings aus einem 3D-Programm mit unterschiedlicher Positionierung eines Balls. Würde man den Ball in der Form, in der er im linken Bild erscheint, ausgeben und beim Deep-Compositing an der Position des zweiten Renderings einfügen, entständen einige Problemzonen:

Probleme beim Deep-Image-Compositing
-
1.
Die Position zum Licht hat sich verändert. Während im linken Bild der Schatten rechts auf dem Ball ist, befindet er sich im rechten Bild links auf dem Ball. Des Weiteren ist ein marginales Glanzlicht zu erkennen.
-
2.
Der Ball interagiert mit dem Rahmen und wird von diesem reflektiert.
-
3.
Die Rotation des Balls hat sich aufgrund der Kameraperspektive verändert.
Diese Probleme sind aber im weiteren Compositing lösbar. Hierbei zeigt sich aber, welche Vorstellungskraft ein Compositing-Artist haben muss, um zu erkennen oder sich vorzustellen, welche Änderungen im Bild durch Einfügen von Objekten oder unterschiedliche Positionierung verursacht werden. Andererseits zeigt dieses Beispiel, welche enorme Rolle Referenzen im Compositing spielen und erklärt die Tatsache, weshalb bei VFX-Aufnahmen viel Wert darauf gelegt wird, solche in guter Qualität zu gewinnen.
10.7 Quellen
Filmmaterial der Abb. 10.48, 10.52, 10.53, 10.56: TH Brandenburg
Filmmaterial der Abb. 10.55: Carsten Benzin, Michael Günther, TH Brandenburg
Baummodelle der Abb. 10.68: Dosch Design, http://www.doschdesign.com, Zugriff: 23. September 2015
Texturen in Abb. 10.68 – Mayang http://www.mayang.com/textures/, Zugriff: 23. September 2015
Modell-Vorlage in Abb. 10.68: Digital Tutors http://www.digitaltutors.com/11/index.php, Zugriff: 23. September 2015
Modell und Textur der Abb. 10.61: Autodesk Maya 2014 – Painteffects http://www.autodesk.de/products/maya/overview, Zugriff: 23. September 2015
Notes
- 1.
- 2.
- 3.
- 4.
- 5.
Slates sind Bildinformationen wie die Bildnummer, die Bezeichnung der Filmrolle, Version, Datum, Timecode etc.
- 6.
- 7.
Simulation des Einflusses von Beleuchtungsänderungen – zum Beispiel Feuer – auf Objekte in der Szene
- 8.
Scharf gebündelter, durch Brechungen hervorgerufener Lichteffekt.
- 9.
Im Begleittext zu Abb. 10.59
- 10.
- 11.
- 12.
- 13.
Literatur
Birn J (2008) Lighting Challenge #15: Film Noir, Model by Greg Sendor. http://www.3drender.com/challenges/film_noir/index.htm. Zugegriffen: 23. September 2015
Brinkmann R (1999) The Art and Science of Digital Compositing. Elsevier, San Diege
Fxguidetv (2009) Shervin Shoghian, compositing supervisor at Image Engine, shows off some cool Nuke 3D techniques developed for their work on „District 9“. http://www.fxguide.com/fxguidetv/fxguidetv_071/. Zugegriffen: 30. August.2015
Okun, Zwermann (2010) The VES Handbook of Visual Efffects. Visual Effects Society. Elsevier Inc., Burlington
PegTop (2015) Blend Modes. http://www.pegtop.net/delphi/articles/blendmodes/. Zugegriffen: 30. August 2015
Seymour M (2006) Art of Optical Flow. http://www.fxguide.com/featured/art_of_optical_flow/. Zugegriffen: 30. August 2015
Wright S (2010) Digital Compositing for Film and Video. 3. Aufl. Elsevier, Amsterdam
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Copyright information
© 2016 Springer-Verlag Berlin Heidelberg
About this chapter
Cite this chapter
Hasche, E. (2016). Compositing. In: Game of Colors: Moderne Bewegtbildproduktion. X.media.press. Springer Vieweg, Berlin, Heidelberg. https://doi.org/10.1007/978-3-662-43889-3_10
Download citation
DOI: https://doi.org/10.1007/978-3-662-43889-3_10
Published:
Publisher Name: Springer Vieweg, Berlin, Heidelberg
Print ISBN: 978-3-662-43888-6
Online ISBN: 978-3-662-43889-3
eBook Packages: Computer Science and Engineering (German Language)