
Abstract
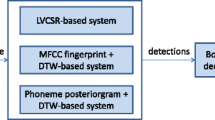
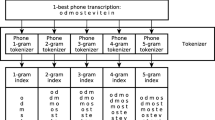
Query-by-Example Spoken Term Detection (QbE-STD) tasks are usually addressed by representing speech signals as a sequence of feature vectors by means of a parametrization step, and then using a pattern matching technique to find the candidate detections. In this paper, we propose a phoneme-based approach in which the acoustic frames are first converted into vectors representing the a posteriori probabilities for every phoneme. This strategy is specially useful when the language of the task is a priori known. Then, we show how this representation can be used for QbE-STD using both a Segmental Dynamic Time Warping algorithm and a graph-based method. The proposed approach has been evaluated with a QbE-STD task in Spanish, and the results show that it can be an adequate strategy for tackling this kind of problems.
Chapter PDF
Similar content being viewed by others

References
Anguera, X., Macrae, R., Oliver, N.: Partial sequence matching using an unbounded dynamic time warping algorithm. In: ICASSP, pp. 3582–3585 (2010)
Hazen, T., Shen, W., White, C.: Query-by-example spoken term detection using phonetic posteriorgram templates. In: ASRU, pp. 421–426 (2009)
Zhang, Y., Glass, J.: Unsupervised spoken keyword spotting via segmental DTW on gaussian posteriorgrams. In: ASRU, pp. 398–403 (2009)
Akbacak, M., Vergyri, D., Stolcke, A.: Open-vocabulary spoken term detection using graphone-based hybrid recognition systems. In: ICASSP, pp. 5240–5243 (2008)
Fiscus, J.G., Ajot, J., Garofolo, J.S., Doddingtion, G.: Results of the 2006 spoken term detection evaluation. In: Proceedings of ACM SIGIR Workshop on Searching Spontaneous Conversational, pp. 51–55 (2007)
Metze, F., Barnard, E., Davel, M., Van Heerden, C., Anguera, X., Gravier, G., Rajput, N., et al.: The spoken web search task. In: Working Notes Proceedings of the MediaEval 2012 Workshop (2012)
Gómez, J.A., Castro, M.J.: Automatic segmentation of speech at the phonetic level. In: Caelli, T.M., Amin, A., Duin, R.P.W., Kamel, M.S., de Ridder, D. (eds.) SSPR & SPR 2002. LNCS, vol. 2396, pp. 672–680. Springer, Heidelberg (2002)
Gómez, J.A., Sanchis, E., Castro-Bleda, M.J.: Automatic speech segmentation based on acoustical clustering. In: Hancock, E.R., Wilson, R.C., Windeatt, T., Ulusoy, I., Escolano, F. (eds.) SSPR & SPR 2010. LNCS, vol. 6218, pp. 540–548. Springer, Heidelberg (2010)
Moreno, A., Poch, D., Bonafonte, A., Lleida, E., Llisterri, J., Marino, J., Nadeu, C.: Albayzin speech database: Design of the phonetic corpus. In: Third European Conference on Speech Communication and Technology (1993)
Park, A., Glass, J.: Towards unsupervised pattern discovery in speech. In: ASRU, pp. 53–58 (2005)
Kullback, S.: Information theory and statistics. Courier Dover Publications (1997)
MAVIR corpus, http://www.lllf.uam.es/ESP/CorpusMavir.html
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Hurtado, LF., Calvo, M., Gómez, J.A., García, F., Sanchis, E. (2013). A Phonetic-Based Approach to Query-by-Example Spoken Term Detection. In: Ruiz-Shulcloper, J., Sanniti di Baja, G. (eds) Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications. CIARP 2013. Lecture Notes in Computer Science, vol 8258. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-41822-8_63
Download citation
DOI: https://doi.org/10.1007/978-3-642-41822-8_63
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-41821-1
Online ISBN: 978-3-642-41822-8
eBook Packages: Computer ScienceComputer Science (R0)
