
Abstract
In this chapter, we introduce some software-engineering approaches which make large programs viable.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
Notes
- 1.
Even in the example programs presented so far we used modularization, in the form of intrinsic procedures, such as for I/O operations.
- 2.
There is actually a new Fortran 2008 feature (
 —see Metcalf et al. [8]), which enables variable declarations in other parts of the code too (e.g. local variables inside a loop). However, we do not cover this feature, as extensive compiler support was still missing at the time of this writing.
—see Metcalf et al. [8]), which enables variable declarations in other parts of the code too (e.g. local variables inside a loop). However, we do not cover this feature, as extensive compiler support was still missing at the time of this writing. - 3.
For example, a sorting algorithm should work with elements of
 ,
,  , or even user-defined types, as long as a suitable binary operator (like “less than”) is defined on any two elements of the type. The ideal of GP is to write the algorithm only once, reducing duplication of code (the need to maintain a different implementation of sort for each type).
, or even user-defined types, as long as a suitable binary operator (like “less than”) is defined on any two elements of the type. The ideal of GP is to write the algorithm only once, reducing duplication of code (the need to maintain a different implementation of sort for each type). - 4.
The workflow is somewhat analogous to Richardson’s (Richardson and Lynch [9]) energy cascade in turbulence theory (replace energy with “work still to be done”, and viscous dissipation with writing code).
- 5.
We use the terms subprogram and procedure interchangeably in this text.
- 6.
Strictly speaking, the term SP also covers the use of flow-control constructs (
 s, loops, etc.), not only of subprograms. However, in this text we reserve the term for referring to the aspect of subprogram-based program design, since the use of flow-control constructs (instead of
s, loops, etc.), not only of subprograms. However, in this text we reserve the term for referring to the aspect of subprogram-based program design, since the use of flow-control constructs (instead of  -statements) is nowadays taken for granted.
-statements) is nowadays taken for granted. - 7.
In particular, internal subprograms have direct access to the data (and other internal subprograms) of their host. This form of unstructured data access may be tempting on the short-term, but generally has a negative effect on the readability of the software. Also, internal subprograms are fundamentally tied to their host, which makes them difficult to re-use in other (sub)programs (since the internal subprograms would need to be converted into normal subprograms first; however, this process may be nontrivial, especially if the above form of data access was (ab)used by the programmer).
- 8.
Packaging a lot of data inside modules can increase the probability of bugs, such as accidentally modifying the data from procedures that should not modify it (in contrast, passing data through the procedure interface allows more control on allowed operations). Also, subprograms which rely on much module data are generally more difficult to understand, and cannot be easily re-used.
- 9.
Derived Data Types (DTs), alternatively named “abstract” types, are discussed in Sect. 3.3.2.
- 10.
Although some compilers may still accept procedure-argument declarations without the
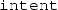 -attribute, it is always recommended to specify these attributes, to make it clear how each of the arguments is supposed to be used (good documentation); additionally, the compiler can then detect some frequent mistakes (such as accidentally overwriting a variable that is only supposed to be read).
-attribute, it is always recommended to specify these attributes, to make it clear how each of the arguments is supposed to be used (good documentation); additionally, the compiler can then detect some frequent mistakes (such as accidentally overwriting a variable that is only supposed to be read). - 11.
In this case, using
 improves performance for large values of N_MAX. However, for some simple procedures there might also be a performance penalty, as having multiple exit points from a procedure may prevent some compiler optimizations, e.g., auto-vectorization.
improves performance for large values of N_MAX. However, for some simple procedures there might also be a performance penalty, as having multiple exit points from a procedure may prevent some compiler optimizations, e.g., auto-vectorization. - 12.
Granted, this change is a little artificial in this context, but attempting to call procedures with the wrong type can happen often in complex and long-lived projects.
- 13.
Some compilers may issue a warning in our specific example, since the function and the main-program are still in the same file. If they are separated, however, this would not occur.
- 14.
There is also a third approach (assumed-size arrays), which is however strongly discouraged (and not covered in this text), since it provides little information about the array to the compiler, effectively disabling those high-level array features—see for example Chapman [3] if working with legacy code that uses this feature.
- 15.
The resulting data file can be easily visualized, for example, in (gnuplot), using the command:
 .
. - 16.
The resolution was hard-coded here, for brevity. However, the reader can find a more complete implementation, which re-introduces adjustable resolution and also demonstrates error-handling, in the program
 , in the source code repository.
, in the source code repository. - 17.
For convenience, we anticipate the discussion of
 s—we cover these shortly, in Sect. 3.2.7.
s—we cover these shortly, in Sect. 3.2.7. - 18.
In C/C++, there is no separation of procedures into
 s and
s and  s—only the former are allowed, although the
s—only the former are allowed, although the  return type allows emulation of Fortran
return type allows emulation of Fortran 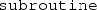 s. We will discuss in more detail this classification in Sect. 3.2.5.
s. We will discuss in more detail this classification in Sect. 3.2.5. - 19.
For our purpose here, the details of the algorithm are not important (but we refer the interested readers to Cormen et al. [6] for more details).
- 20.
The procedure is said to gain access to the module’s data through use association in this case.
- 21.
Data access is through what is known as host association then.
- 22.
In addition, compiler vendors are allowed to provide additional intrinsic subroutines, not specified by the language standard.
- 23.
Of course, a good rule of thumb for avoiding this issue altogether is to avoid such name clashes altogether, unless there is a very good justification (such as when extending the intrinsic procedure, to allow working with derived types in the same way as with the standard types—see Sect. 3.3.5).
- 24.
The library implementation may actually use a hierarchy of modules internally, but often a single
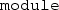 needs to be presented to the user.
needs to be presented to the user. - 25.
Interestingly, by adding such a line at the beginning of the module, it is not necessary to include it inside the procedure declarations (if there are any)—although it also does not hurt to keep that habit.
- 26.
Access control for modules will be discussed shortly.
- 27.
Who would be spared the effort to read through all of the
 d module to find a specific data/procedure definition.
d module to find a specific data/procedure definition. - 28.
In this context, “interface” represents the entire set of library procedures that can be called by the program.
- 29.
C++ programmers should note that “protected” here is not the same notion as in that language, where the keyword relates to visibility in relation to inheritance.
- 30.
Note that this example is meant only for illustrative purposes—for linear algebra there is already a wealth of good software available (see Sect. 5.6.2).
- 31.
This does not mean that knowing OOP in one language guarantees a smooth transition—unfortunately, there are no strict one-to-one mappings of terminology from traditional OOP languages (like C++ or Java) to equivalent Fortran constructs, hence confusion can occur.
- 32.
All this assumes that the interfaces between the modules are invariant.
- 33.
Such evolution phenomena reflect the attempts of the software community to keep up with the large leaps in the capabilities of the underlying hardware and in user expectations. Assembly language was an evolution from machine opcodes, which took place when the hardware became too complex to manage directly in terms of opcodes. Similarly, high-level SP-languages appeared as a second evolutionary step, when assembly was not sufficient anymore to handle the software- and requirements-complexity. Nowadays, we have OOP, but functional programming is also gaining more ground.
- 34.
Pioneering efforts in OOP using Fortran (e.g. Akin [1]) used
 s to emulate classes, since they can encapsulate both data and procedures. However, since there is no concept of multiple instances of a
s to emulate classes, since they can encapsulate both data and procedures. However, since there is no concept of multiple instances of a  , only “class-wide” data is supported (corresponding to
, only “class-wide” data is supported (corresponding to 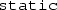 class members in C++). With these tools, it was still possible to emulate “usual” classes by making the static data an array, which held all “instances” of the class. However, this condemned the programmer of the module to handle tedious memory management for that array; since there is a more convenient alternative in Fortran 2003, we do not describe this practice in details, and instead view
class members in C++). With these tools, it was still possible to emulate “usual” classes by making the static data an array, which held all “instances” of the class. However, this condemned the programmer of the module to handle tedious memory management for that array; since there is a more convenient alternative in Fortran 2003, we do not describe this practice in details, and instead view  s largely as C++ namespaces.
s largely as C++ namespaces. - 35.
Of course, this is allowed only if the data is
 . This is the default policy, which we leverage here for brevity (we will soon discuss alternatives more consistent with the information hiding principle).
. This is the default policy, which we leverage here for brevity (we will soon discuss alternatives more consistent with the information hiding principle). - 36.
When this argument is present, it needs to be surrounded by round brackets.
- 37.
These are special DTs, which are relevant in inheritance-hierarchies, for fixating the interface for DTs in such a hierarchy, but deferring the actual implementation of methods to the leaf-DTs.
- 38.
In OOP jargon, method invocations are also referred to as “sending a message” to the object.
- 39.
For our simplified example, this would not be a big problem. However, in large projects, where the DT is used by many developers, such disruptive changes can cause significant friction.
- 40.
Making methods
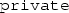 can be useful, for example, when some of them are implementation-specific, and the users do not need to know about them.
can be useful, for example, when some of them are implementation-specific, and the users do not need to know about them. - 41.
As we will demonstrate in the code, they cannot be type-bound procedure because they are functions which return the new DT-instance as their result.
- 42.
Try to compile the code while un-commenting line 48 and/or 50.
- 43.
Optimizing compilers should “see through” this intermediate layer, and inline the functions, so that they do not affect performance (although this needs to be verified through benchmarks, as usual).
- 44.
Of course, for such a simple DT, it would be easier (and potentially also more efficient) to write the class for \(3D\)-vectors from scratch. However, we implement it here based on
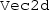 , to illustrate the techniques in a simple setting.
, to illustrate the techniques in a simple setting. - 45.
If the data of the parent was
 , an implicit constructor would have been created for the child type, which would accept as arguments first the components of the parent type (in sequence), followed by the additional components of the child type (also in sequence).
, an implicit constructor would have been created for the child type, which would accept as arguments first the components of the parent type (in sequence), followed by the additional components of the child type (also in sequence). - 46.
Unless those methods have the
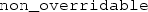 -specifier in their binding attribute list.
-specifier in their binding attribute list. - 47.
This is essentially what we referred to as the “interface”, without the return type, since most languages (including Fortran) do not look at this type when distinguishing overloads.
- 48.
This is also known as “type overloading”, since the name of the generic interface was that of the type.
- 49.
Note that they serve a different purpose than the unnamed
 -blocks, shown in the beginning of this chapter (which were demonstrated for making the
-blocks, shown in the beginning of this chapter (which were demonstrated for making the 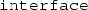 of an external procedure explicit).
of an external procedure explicit). - 50.
This type of overloading is named “defined assignment”, marked by changing the name of the generic interface by
 and implemented by a
and implemented by a  which takes two arguments (first
which takes two arguments (first 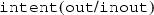 ) and second
) and second  ).
). - 51.
In that case, the implicit assignment implemented by the compiler would only perform a shallow copy of the object, without duplicating the data accessed by the
 . However, when pointers are not used, the implicit assignment will perform a proper deep copy of the object, even when the DT has allocatable arrays as data members.
. However, when pointers are not used, the implicit assignment will perform a proper deep copy of the object, even when the DT has allocatable arrays as data members. - 52.
To be precise, the concept we are referring to here is also known as “subtype polymorphism”, to distinguish it from other methodologies which are also named “polymorphism” sometimes—e.g., overloading (“ad-hoc polymorphism”) and generic programming (“parametric polymorphism”).
- 53.
There is no “template metaprogramming” in Fortran.
- 54.
We left the components of the DT
 here, for brevity.
here, for brevity. - 55.
Although this is standard Fortran 2003, most compilers had yet to implement this feature at the time of our writing unfortunately.
- 56.
Remember that
 -parameters are also
-parameters are also 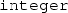 -values.
-values.
 —see Metcalf et al. [
—see Metcalf et al. [ ,
,  , or even user-defined types, as long as a suitable binary operator (like “less than”) is defined on any two elements of the type. The ideal of GP is to write the algorithm only once, reducing duplication of code (the need to maintain a different implementation of sort for each type).
, or even user-defined types, as long as a suitable binary operator (like “less than”) is defined on any two elements of the type. The ideal of GP is to write the algorithm only once, reducing duplication of code (the need to maintain a different implementation of sort for each type). s, loops, etc.), not only of subprograms. However, in this text we reserve the term for referring to the aspect of subprogram-based program design, since the use of flow-control constructs (instead of
s, loops, etc.), not only of subprograms. However, in this text we reserve the term for referring to the aspect of subprogram-based program design, since the use of flow-control constructs (instead of  -statements) is nowadays taken for granted.
-statements) is nowadays taken for granted.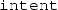 -attribute, it is always recommended to specify these attributes, to make it clear how each of the arguments is supposed to be used (good documentation); additionally, the compiler can then detect some frequent mistakes (such as accidentally overwriting a variable that is only supposed to be read).
-attribute, it is always recommended to specify these attributes, to make it clear how each of the arguments is supposed to be used (good documentation); additionally, the compiler can then detect some frequent mistakes (such as accidentally overwriting a variable that is only supposed to be read). improves performance for large values of N_MAX. However, for some simple procedures there might also be a performance penalty, as having multiple exit points from a procedure may prevent some compiler optimizations, e.g., auto-vectorization.
improves performance for large values of N_MAX. However, for some simple procedures there might also be a performance penalty, as having multiple exit points from a procedure may prevent some compiler optimizations, e.g., auto-vectorization. .
. , in the source code repository.
, in the source code repository. s—we cover these shortly, in Sect.
s—we cover these shortly, in Sect.  s and
s and  s—only the former are allowed, although the
s—only the former are allowed, although the  return type allows emulation of Fortran
return type allows emulation of Fortran 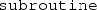 s. We will discuss in more detail this classification in Sect.
s. We will discuss in more detail this classification in Sect. 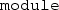 needs to be presented to the user.
needs to be presented to the user. d module to find a specific data/procedure definition.
d module to find a specific data/procedure definition. s to emulate classes, since they can encapsulate both data and procedures. However, since there is no concept of multiple instances of a
s to emulate classes, since they can encapsulate both data and procedures. However, since there is no concept of multiple instances of a  , only “class-wide” data is supported (corresponding to
, only “class-wide” data is supported (corresponding to 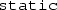 class members in
class members in  s largely as
s largely as  . This is the default policy, which we leverage here for brevity (we will soon discuss alternatives more consistent with the information hiding principle).
. This is the default policy, which we leverage here for brevity (we will soon discuss alternatives more consistent with the information hiding principle).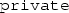 can be useful, for example, when some of them are implementation-specific, and the users do not need to know about them.
can be useful, for example, when some of them are implementation-specific, and the users do not need to know about them.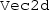 , to illustrate the techniques in a simple setting.
, to illustrate the techniques in a simple setting. , an implicit constructor would have been created for the child type, which would accept as arguments first the components of the parent type (in sequence), followed by the additional components of the child type (also in sequence).
, an implicit constructor would have been created for the child type, which would accept as arguments first the components of the parent type (in sequence), followed by the additional components of the child type (also in sequence).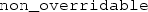 -specifier in their binding attribute list.
-specifier in their binding attribute list. -blocks, shown in the beginning of this chapter (which were demonstrated for making the
-blocks, shown in the beginning of this chapter (which were demonstrated for making the 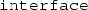 of an external procedure explicit).
of an external procedure explicit). and implemented by a
and implemented by a  which takes two arguments (first
which takes two arguments (first 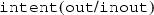 ) and second
) and second  ).
). . However, when pointers are not used, the implicit assignment will perform a proper deep copy of the object, even when the DT has allocatable arrays as data members.
. However, when pointers are not used, the implicit assignment will perform a proper deep copy of the object, even when the DT has allocatable arrays as data members. here, for brevity.
here, for brevity. -parameters are also
-parameters are also 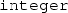 -values.
-values.References
Akin, E.: Object-Oriented Programming via Fortran 90/95. Cambridge University Press, Cambridge (2003)
Booch, G., Maksimchuk, R.A., Engle, M.W., Young, B.J., Connallen, J., Houston, K.A.: Object-Oriented Analysis and Design with Applications. Addison-Wesley Professional, Boston (2007)
Chapman, S.J.: Fortran 95/2003 for Scientists and Engineers. McGraw-Hill Science/Engineering/Math, New York (2007)
Chivers, I.D., Sleightholme, J.: Compiler support for the Fortran 2003 and 2008 standards (Revision 11). ACM SIGPLAN Fortran Forum 31(3), 17–28 (2012)
Clerman, N.S., Spector, W.: Modern Fortran: Style and Usage. Cambridge University Press, Cambridge (2011)
Cormen, T.H., Leiserson, C.E., Rivest, R.L., Stein, C.: Introduction to Algorithms. MIT Press, Cambridge (2009)
Hager, G., Wellein, G.: Introduction to High Performance Computing for Scientists and Engineers. CRC Press, Boca Raton (2010)
Metcalf, M., Reid, J., Cohen, M.: Modern Fortran Explained. Oxford University Press, Oxford (2011)
Richardson, L.F., Lynch, P.: Weather Prediction by Numerical Process. Cambridge University Press, Cambridge (2007)
Rouson, D., Xia, J., Xu, X.: Scientific Software Design: The Object-Oriented Way. Cambridge University Press, Cambridge (2011)
Stepanov, A.A., McJones, P.: Elements of Programming. Addison-Wesley Professional, Boston (2009)
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Copyright information
© 2015 Springer-Verlag Berlin Heidelberg
About this chapter
Cite this chapter
Chirila, D.B., Lohmann, G. (2015). Elements of Software Engineering. In: Introduction to Modern Fortran for the Earth System Sciences. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-37009-0_3
Download citation
DOI: https://doi.org/10.1007/978-3-642-37009-0_3
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-37008-3
Online ISBN: 978-3-642-37009-0
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)