
Abstract
In this paper, we propose a fast entropy-based variational scheme for learning Gaussian mixtures. The key element of the proposal is to exploit the incremental learning approach to perform model selection through efficient iteration over the Variational Bayes (VB) optimization step in a way that the number of splits is minimized. In order to minimize the number of splits we only select for spliting the worse kernel in terms of evaluating its entropy. Recent Gaussian mixture learning proposals suggest the use of that mechanism if a bypass entropy estimator is available. Here we will exploit the recently proposed Leonenko estimator. Our experimental results, both in 2D and in higher dimension show the effectiveness of the approach which reduces an order of magnitude the computational cost of the state-of-the-art incremental component learners.
Funded by the Project TIN2008- 04416/TIN of the Spanish Government.
Chapter PDF
Similar content being viewed by others


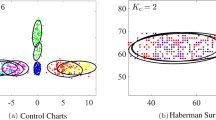
Keywords
- Mixture Model
- Markov Chain Monte Carlo
- Gaussian Mixture Model
- Markov Chain Monte Carlo Method
- Royal Statistical Society
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Jain, A., Dubes, R., Mao, J.: Statistical pattern recognition: A review. IEEE Trans. Pattern Anal. Mach. Intell. 22(1), 4–38 (2000)
Titterington, D., Smith, A., Makov, U.: Statistical Analysis of Finite Mixture Distributions. John Wiley and Sons, Chichester (2002)
Jain, A., Dubes, R.: Algorithms for Clustering Data. Prentice Hall, Englewood Cliffs (1988)
Hastie, T., Tibshirani, R.: Discriminant analysis by gaussian mixtures. Journal of The Royal Statistical Society(B) 58(1), 155–176 (1996)
Hinton, G., Dayan, P., Revow, M.: Modeling the manifolds of images of handwriting digits. IEEE Transactions On Neural Networks 8(1), 65–74 (1997)
Dalal, S., Hall, W.: Approximating priors by mixtures of natural conjugate priors. Journal of The Royal Statistical Society(B) 45(1) (1983)
Box, G., Tiao, G.: Bayesian Inference in Statistical Models. Addison-Wesley, Reading (1992)
Figueiredo, M., Jain, A.: Unsupervised learning of finite mixture models. IEEE Trans. Pattern Anal. Mach. Intell. 24(3), 381–399 (2002)
Husmeier, D.: The bayesian evidence scheme for regularizing probability-density estimating neural networks. Neural Computation 12(11), 2685–2717 (2000)
MacKay, D.: Introduction to Monte Carlo Methods. In: Jordan, M.I. (ed.) Learning in Graphical Models. MIT Press, MA (1999)
Ghahramani, Z., Beal, M.: Variational inference for bayesian mixture of factor analysers. In: Adv. Neur. Inf. Proc. Sys., MIT Press, Cambridge (1999)
Nasios, N., Bors, A.: Variational learning for gaussian mixtures. IEEE Trans. on Systems, Man, and Cybernetics - Part B: Cybernetics 36(4), 849–862 (2006)
Nasios, N., Bors, A.: Blind source separation using variational expectation-maximization algorithm. In: Petkov, N., Westenberg, M.A. (eds.) CAIP 2003. LNCS, vol. 2756, pp. 442–450. Springer, Heidelberg (2003)
Figueiredo, M., Leitao, J., Jain, A.: On fitting mixture models. In: Hancock, E.R., Pelillo, M. (eds.) EMMCVPR 1999. LNCS, vol. 1654, pp. 54–69. Springer, Heidelberg (1999)
Figueiredo, M.A.T., Jain, A.K.: Unsupervised selection and estimation of finite mixture models. In: Proc. Int. Conf. Pattern Recognition, pp. 87–90. IEEE, Los Alamitos (2000)
Penalver, A., Escolano, F., Sáez, J.: Learning gaussian mixture models with entropy-based criteria. IEEE Transactions on Neural Networks 20(11), 1756–1772 (2009)
Constantinopoulos, C., Likas, A.: Unsupervised learning of gaussian mixtures based on variational component splitting. IEEE Transactions on Neural Networks 18(3), 745–755 (2007)
Watanabe, K., Akaho, S., Omachi, S.: Variational bayesian mixture model on a subspace of exponential family distributions. IEEE Transactions on Neural Networks 20(11), 1783–1796 (2009)
Attias, H.: Inferring parameters and structure of latent variable models by variational bayes. In: Proc. of Uncertainty Artif. Intell., pp. 21–30 (1999)
Corduneau, A., Bishop, C.: Variational bayesian model selection for mixture distributions. In: Artificial Intelligence and Statistics, pp. 27–34. Morgan Kaufmann, San Francisco (2001)
Richardson, S., Green, P.: On bayesian analysis of mixtures with unknown number of components (with discussion). Journal of the Royal Statistical Society B 59(1), 731–792 (1997)
Hero, A., Michel, O.: Estimation of rényi information divergence via pruned minimal spanning trees. In: Workshop on Higher Order Statistics, Caessaria, Israel. IEEE, Los Alamitos (1999)
Leonenko, N., Pronzato, L.: A class of rényi information estimators for multi-dimensional densities. The Annals of Statistics 36(5), 2153–2182 (2008)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2010 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Peñalver, A., Escolano, F., Bonev, B. (2010). Entropy-Based Variational Scheme for Fast Bayes Learning of Gaussian Mixtures. In: Hancock, E.R., Wilson, R.C., Windeatt, T., Ulusoy, I., Escolano, F. (eds) Structural, Syntactic, and Statistical Pattern Recognition. SSPR /SPR 2010. Lecture Notes in Computer Science, vol 6218. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-14980-1_9
Download citation
DOI: https://doi.org/10.1007/978-3-642-14980-1_9
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-14979-5
Online ISBN: 978-3-642-14980-1
eBook Packages: Computer ScienceComputer Science (R0)
