
Abstract
We propose a new strategy to use Bit Filters for complex pipelined queries on large databases that we call Pushed Down Bit Filters. The objective of the strategy is to make use of the Bit Filters already created for upper nodes of the execution plan, in the leaves of the plan. The aim of this strategy is to reduce the traffic between the nodes of the execution plan. When traffic is reduced, the amount of CPU work is reduced and, in most of the cases, I/O is also reduced. In addition, this technique shows no degradation in cases with little effectiveness.
This work was supported by the Ministry of Education and Science of Spain under contract TIC2001-0995-C02-01, CEPBA, CIRI and an IBM CAS Fellowship grant.
Chapter PDF
Similar content being viewed by others
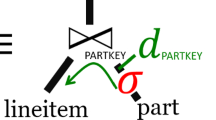


References
Bloom, B.H.: Space/time trade-offs in hash coding with allowable errors. Communications of the ACM 13(7), 422–426 (1970)
Bratbergsengen, K.: Hashing methods and relational algebra operations. In: Proc. of the Conf. on Very Large Data Bases (VLDB), pp. 323–333 (1984)
Chan, C.-Y., Ioannidis, Y.E.: Bitmap index design and evaluation. In: Proc. of the SIGMOD Conf. on the Management of Data, pp. 355–366 (1998)
Chen, M.-S., Hsiao, H.-I., Yu, P.S.: On applying hash filters to improving the execution of multi-join queries. VLDB Journal: Very Large Data Bases 6(2), 121–131 (1997)
Gongloor, P., Patkar, S.: Hash joins: Implementation and tuning, release 7.3. Technical report, Oracle Technical Report (March 1997)
Graefe, G., Bunker, R., Cooper, S.: Hash joins and hash teams in microsoft sql server. In: Proceedings of the 25th VLDB Conference, August 1998, pp. 86–97 (1998)
Hsiao, H.-I., Chen, M.-S., Yu, P.S.: Parallel execution of hash joins in parallel databases. IEEE-Trans. on Parallel and Distributed Systems 8(8), 872–883 (1997)
Bayardo Jr., R.J., Miranker, D.P.: Processing queries for first few answers. In: CIKM, pp. 45–52 (1996)
Kemper, A., Kossmann, D., Wiesner, C.: Generalized hash teams for join and group-by. In: Proc. of the Conf. on Very Large Data Bases (VLDB), September 1999, pp. 30–41 (1999)
O‘Neil, P., Graefe, G.: Multi-table joins through bitmapped join indices. SIGMOD Record 24(3), 8–11 (1995)
PostgreSQL, http://www.postgresql.org/
Schneider, D.A., DeWitt, D.J.: A performance evaluation of four parallel join algorithms in a shared-nothing multiprocessor environment. In: Proc. ACM SIGMOD, pp. 110–121 (1989)
Valduriez, P., Gardarin, G.: Join and semi-join algorithms for a multiprocessor database machine. TODS 9(1), 133–161 (1984)
Wilschut, A.N., Apers, P.M.G.: Dataflow query execution in a parallel mainmemory environment. Distributed and Parallel Databases 1(1), 103–128 (1993)
Wu, M.-C., Buchmann, A.P.: Encoded bitmap indexing for data warehouses. In: Intl. Conference on Data Engineering, pp. 220–230 (1998)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2003 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Aguilar-Saborit, J., Muntés-Mulero, V., Larriba-Pey, JL. (2003). Pushing Down Bit Filters in the Pipelined Execution of Large Queries. In: Kosch, H., Böszörményi, L., Hellwagner, H. (eds) Euro-Par 2003 Parallel Processing. Euro-Par 2003. Lecture Notes in Computer Science, vol 2790. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-45209-6_49
Download citation
DOI: https://doi.org/10.1007/978-3-540-45209-6_49
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-40788-1
Online ISBN: 978-3-540-45209-6
eBook Packages: Springer Book Archive