
Abstract
Corner detection is a fundamental step for many image processing applications including image enhancement, object detection and pattern recognition. Recent years, the quality and the number of images are higher than before, and applications mainly perform processing on videos or image flow. With the popularity of embedded devices, the real-time processing on the limited computing resources is an essential problem in high-performance computing. In this paper, we study the parallel method of Harris corner detection and implement it on a heterogeneous architecture using OpenCL. We also adopt some optimization strategy on the many-core processor. Experimental results show that our parallel and optimization methods highly improve the performance of Harris algorithm on the limited computing resources.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Corner detection is an important problem in many image processing applications including edge detection, object detection and pattern recognition [1]. It is a fundamental step in image processing. Recent years, with the development of embedded devices or high-performance computing, the real-time computing plays a crucial role in many applications, such as video game, communication app and media player. Especially in the area of computer vision, applications always require that the system can be request clients in a few seconds. As an indispensable corner detection algorithm, Harris corner detector has been successfully used in the image processing [25], such as feature selection or edge detection. It is also accelerated based on different strategy or various compute devices. However, much of them ignore the limitations of computing resources like embedded device, and they do not fully take advantage of the heterogeneous architecture.
Over past decades, the performance of computing device has achieved a significant development. Many large-scale computing tasks are benefited from modern processors like GPU, CPU or FPGA. Especially growing in many-core processors, massive algorithms have been parallelled and implemented on the many-core processor which could improve the efficiency of computing [11]. The general purpose computing on GPU pushed the revolution of many applications like machine learning, and more and more algorithms are transplanted to the many-core compute platforms. GPU also push the improvement of machine learning research. Many methods would be benefited from the high-performance of GPU [7, 10, 15, 19,20,21,22, 24].
However, large-scale computing task is suitable for the host or server devices. For the embedded devices, the limited computing resources cannot satisfy the complexity of massive data processing or the real-time reaction. For example, some image applications on the Android or IOS which should be reacted in a few seconds. Thus, how to fully utilize the limited computation resource is a key problem which is needed to solve urgently. Two types of strategy are used to speed up. One is reducing the complexity of an algorithm, and the other is optimizing based on the architecture of computing device. In real applications, the implementation is always combined this two idea to optimize the software.
In this paper, we parallel the Harris corner detection algorithm and implement it in an environment of heterogeneous architecture which is composed of many-core and multi-core processors. We also adopt some optimization for methods basing on this unique design. We implement the algorithm by OpenCL, which is an open source parallel library working for heterogeneous architecture and it is commonly used in cross computation platforms. Experimental results prove that our implementation is accuracy and efficiency. The rest paper is organized as follow: Sect. 2 introduces the background and Harris corner detection, Sect. 3 makes an instruction of heterogeneous architecture under the cross-platform software library OpenCL and the related work of parallel Harris corner algorithm implementation. Section 4 introduces details of our implementation and optimization. Section 5 lists the accuracy of detection and computing efficiency. At last, we give the conclusion and explanation.
2 Background of Harris Corner Detection
Harris corner detector is developed basing on Moravec corner detection to mark the location of corner points precisely [5]. It is a corner detection operator which is widely used in computer vision algorithms to extract corners and infer features of an image [23]. It also contributes to the area of computer vision [8]. At the rest of this section, we give an overview of the formulation of the Harris corner detection and its algorithm.
A corner is defined as the intersection of two edges. The main idea of Harris algorithm is that the corner would emerge when the value of an ROI (region of interest) variant dynamically with the shift to nearby regions [2]. The algorithm set a window scan the ROI in all directions; if it has a high gradient, we can infer that there may be corners in this region. We define \(I\left( x,y\right) \) as a pixel in the input image, \(\left( u,v\right) \) is the offset of shifted region from the ROI. \(w\left( x,y\right) \) is represented a convolution function which is Gaussian filter here. The function of the variable is defined as follow:
where \(\otimes \) is represented as a convolution operator. And then we make an approximation with shifted ROI value based on Taylor series expansion equation.
By substituting (2) into (1) and approximate the result can be converted to matrix form:
The matrix \(H\) which named Harris matrix is defined as:
To determine whether the pixel is a corner point or not, we need to compute pixel criterion score \(c\left( x,y\right) \) for each pixel. The function is given by
where \(\lambda _{1}, \lambda _{2}\) are the eigenvalues of the Harris matrix H. At the last step, we calculate the criterion score \(c\left( x,y\right) \) for each pixel, if the score higher than the threshold and it is the maximum value in the scan area, we mark this pixel as a corner point. The description of Harris corner detection algorithm is list in Algorithm 1.

3 Heterogeneous Architecture and Related Work
3.1 Heterogeneous Architecture
Since the improving requirement of complexity for large-scale computing, the performance of processors become more efficiently. Many-core and multi-core processors make a significant contribution to many fields [9]. CPU specialize in logic operation, and contrast, GPU does well in float or integer computing. These two kinds processors cooperate each other to enhance the computing speed. This structure of CPU-GPU is a typical kind of heterogeneous architecture. Figure 1 shows an example of heterogeneous architecture.

Multi-core and many-core heterogeneous architecture. There are several compute units in the GPU and each of them contains SIMD (single instruction multi data) unit, register stack and local data store. Most square of CPU is used to be memory, like cache and register.
However, some factors limit the development of processors, including memory access and power wall, particularly the finite square of the chip for the requirement of embedded devices. With the popularity of embedded devices, the square wall of a chip is a limitation. Thus, how to fully utilize resource on-chip, like register, local memory and compute units, is a critical problem in future.
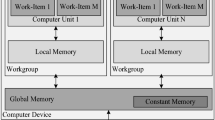
In this paper, we consider the heterogeneous architecture, which is composed of a GPU and a CPU. For implementation, we adopt a parallel open source library named OpenCL that can be performed on various devices. It is a popular framework for programming in the heterogeneous environment. It abstracts compute devices into the same structure and constructs a communication function among compute units or devices. The most advantage of OpenCL is cross-platform. Figure 2 shows the abstract structure in OpenCL.

OpenCL open source library abstracts computing devices in a unified framework [18]. The compute units are organized in clusters, compute devices are highest level contain several compute units which are composed by dozens of process element. Memory resources are organized in a multi-level style. The nearest from process elements are register, then in the order of local memory, global memory and host memory.
3.2 Related Works
Corner detection techniques are being widely used in many computer vision applications for example in object recognition and motion detection to find suitable candidate points for feature registration and matching. High-speed feature detection is a requirement for many real-time multimedia and computer vision applications. Harris corner detector (HCD) as one of many corner detection algorithm has become a viable solution for meeting real-time requirements of the applications. There are many works to improve the efficiency of the algorithm, and some parallel implementations has been developed on different platforms. In previous work, several implementation have been proposed which target a specific device or some particular aspects of the algorithm. Saidani et al. [16] used the Harris algorithm for the detection of interest points in an image as a benchmark to compare the performance of several parallel schemes on a Cell processor. To attain further speedup, Phull et al. [13] proposed the implementation of this low complexity corner detector algorithm on a parallel computing architecture, a GPU software library namely Compute Unified Device Architecture (CUDA). Paul and his co-author [12] present a new resource-aware Harris corner-detection algorithm for many-core processors. The novel algorithm can adapt itself to the dynamically varying load on a many-core processor to process the frame within a predefined time interval. The HDC algorithm was implemented as a hardware co-processor on the FPGA portion of the SoC, by Schulz et al. [17]. Haggui et al. [3] study a direct and explicit implementation of common and novel optimization strategies, and provide a NUMA-aware parallelization. Moreover, Jasani et al. [6] proposed a bit-width optimization strategy for designing hardware-efficient HCD that exploits the thresholding step in the algorithm. Han et al. [4] implement the HCD using OpenCL and perform it on the desktop level GPU and gain a 77 times speedup.
4 Harris Corner Detection OpenCL Implementation
In this section, we introduce our strategy of parallelization for Harris corner detection in OpenCL implementation. As shown in Sect. 2, there are many operators based on the pixel level. Thus, we design our parallel implementation in pixel grain size. We parallel the step of Gaussian blur convolution, Gradient X, Y computing and Harris matrix construction which are implemented on GPU. The step of eigenvalues computes and corner response are implemented on CPU.
We divide algorithm into two kernel function. One is the construction of Harris matrix, and another is pixel score. Compared with other implementation, we decrease the number of the kernels. We integrate the function into one kernel as far as possible for the reason that it can reduce the time of communication between host and kernel device, like host memory and graphics memory. It also increases the ratio of data reuse and speeds up the program. In our design, we assume that the computing resource is limited, such as register, shared memory or computing unit, and our primary target is speeding up our program in the limited resource.
4.1 Kernel of Convolution and Matrix Construction
The compute of Gaussian blur convolution, image gradient and Harris matrix are merged into one kernel. For this kernel, we construct a computing space which is the same dimension as an input image. Every thread deals a pixel task and output one Harris matrix. All outputs in threads compose a complete Harris matrix. For a thread In this kernel, we first compute the gradient X \(I_{x}\left( x,y \right) \)and gradient Y \(I_{y}\left( x,y \right) \) of this pixel and then compute its own \(I_{x}^2\left( x,y \right) \), \(I_{y}^2\left( x,y \right) \) and \(I_{x}\left( x,y \right) I_{y}\left( x,y \right) \). Finally, we use the operation of Gaussian blur convolution to filter the pixel with its neighbourhood. The procedure description of this kernel is shown in Fig. 3.

The figure indicates the process for the algorithm of Harris corner detection.
Optimization strategy: The pixel level computing is beneficial for many-core architecture since its high parallelism and numerical value compute. We utilize this advantage of convolution that every thread compute a mask filter. However, in the process of convolution or gradient compute, it exists many memory access. It is low efficiency when read data from global memory to compute unit frequently. To solve this problem, we move pixels nearby target to shared memory on-chip first. This method could improve the local data repetition rate and make computing units access data which are stored in the consecutive address, namely combination access. In our implementation, we set the local pixel to the size of local computing space.
4.2 Kernel of Corner Response
After the first kernel computing, we get the corner score for every pixel in the ROI which we defined. These corner scores can report the probability of a corner point existing in the corresponding ROI. If a corner score is a negative value, it means there may be an edge in this region, and a small value indicates this area may be a flat region. Thus, we need to get the score values which are larger than the threshold, which indicate that there exists a corner in the ROI of this pixel. At last, we adopt the non-maximum suppression (NMS) stage which is aim to get the local maximum value. We set the pixel which have local maximum value as a corner point.
In our implementation, we fix a \(3*3\) window to search the neighborhood nearby the pixel. Every thread in the computing space is assigned a \(3*3\) region, and if the corner score is larger than the threshold and it is the maximum value of this region, we set this pixel as a corner point. Similar to kernel convolution, we store consecutive data together from global memory to the local data memory on-chip. For limited store resource like register, we prefer the search window as little as possible.
5 Experimental Results
In this section, we will introduce experimental results for our implementation regarding accuracy and effectiveness on our heterogeneous hardware architecture.
5.1 Detection Accuracy
We use the function HarrisCorner in OpenCV as our benchmark of serial implementation. OpenCV is an open source software library, and it is utilized in image processing and computer vision. Similar with OpenCL, it can take advantage of the cross-platform and hardware acceleration based on heterogeneous compute device [14]. Figure 4 shows the results of corner detection.

The experimental results are shown in this figure. The corners detected by algorithms are in the red circles. The left image for each of sub-images is the detection result of baseline method, which is the function in OpenCV. The right image for each of sub-images is the results of our paralleled method. Contrast, our method is more stable and more precisely. (Color figure online)
5.2 Performance Results
To evaluate our implementation, we perform our experiments on MacOS with OpenCL 1.2. The hardware configure is a CPU of 2.6 GHz Intel Core i5 and a many-core processor namely Intel Iris. Iris is a lightweight GPU with limited compute units and memory, which provides 40 stream processors. It is a typically many-core processor with limited computing resource.
Comparing with OpenCV function HarrisCorner, our implementation (image size: \(640\times 480\)) on the CPU-GPU architecture could get speedup of 11.7. With the ROI increasing, the speedup is improved. It proves that our design is efficiency. The experimental results are lists in Table 1.
6 Conclusion
In this paper, we have paralleled the Harris corner detection algorithm and implemented it on the heterogeneous architecture using OpenCL. Our implementation has achieved an acceleration compared with open library function in OpenCV. Our design considers the utilization of memory resource. It increases memory reuse ratio as possible. We implement Harris corner detection on a limited resource device and gain a speedup.
References
Ben-Musa, A.S., Singh, S.K., Agrawal, P.: Object detection and recognition in cluttered scene using Harris corner detection. In: 2014 International Conference on Control, Instrumentation, Communication and Computational Technologies, pp. 181–184, July 2014
Dey, N., Nandi, P., Barman, N., Das, D., Chakraborty, S.: A comparative study between Moravec and Harris corner detection of noisy images using adaptive wavelet thresholding technique. Comput. Sci. (2012)
Haggui, O., Tadonki, C., Lacassagne, L., Sayadi, F., Ouni, B.: Harris corner detection on a NUMA manycore. Future Gener. Comput. Syst. (2018)
Han, X., Ge, M., Qinglei, Z.: Harris corner detection algorithm on OpenCL architecture. Comput. sci. 41(7), 306–309, 321 (2014)
Harris, C.: A combined corner and edge detector. In: 1988 Proceedings of the 4th Alvey Vision Conference, no. 3, pp. 147–151 (1988)
Jasani, B.A., Lam, S., Meher, P.K., Wu, M.: Threshold-guided design and optimization for Harris corner detector architecture. IEEE Trans. Circ. Syst. Video Technol. PP(99), 1 (2017)
Li, D., Tian, Y.: Global and local metric learning via eigenvectors. Knowl.-Based Syst. 116, 152–162 (2017)
Lowe, D.G.: Object recognition from local scale-invariant features. In: Proceedings of the 7th IEEE International Conference on Computer Vision, p. 1150 (2002)
Mittal, S., Vetter, J.S.: A survey of CPU-GPU heterogeneous computing techniques. ACM Comput. Surv. 47(4), 1–35 (2015)
Niu, L., Zhou, R., Tian, Y., Qi, Z., Zhang, P.: Nonsmooth penalized clustering via \(ell _{p}\) regularized sparse regression. IEEE Trans. Cybern. 47(6), 1423–1433 (2017)
Owens, J.D., Houston, M., Luebke, D., Green, S., Stone, J.E., Phillips, J.C.: GPU computing. Proc. IEEE 96(5), 879–899 (2008)
Paul, J., et al.: Resource-aware Harris corner detection based on adaptive pruning. In: Maehle, E., Römer, K., Karl, W., Tovar, E. (eds.) ARCS 2014. LNCS, vol. 8350, pp. 1–12. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-04891-8_1
Phull, R., Mainali, P., Yang, Q., Alface, P.R., Sips, H.: Low complexity corner detector using CUDA for multimedia application. In: International Conferences on Advances in Multimedia, MMEDIA (2011)
Pulli, K., Baksheev, A., Kornyakov, K., Eruhimov, V.: Real-time computer vision with OpenCV. Commun. ACM 55(6), 61–69 (2012)
Qi, Z., Meng, F., Tian, Y., Niu, L., Shi, Y., Zhang, P.: Adaboost-LLP: a boosting method for learning with label proportions. IEEE Trans. Neural Netw. Learn. Syst. PP(99), 1–12 (2018)
Saidani, T., Lacassagne, L., Falcou, J., Tadonki, C., Bouaziz, S.: Parallelization schemes for memory optimization on the cell processor: a case study on the Harris corner detector. In: Stenström, P. (ed.) Transactions on High-Performance Embedded Architectures and Compilers III. LNCS, vol. 6590, pp. 177–200. Springer, Heidelberg (2011). https://doi.org/10.1007/978-3-642-19448-1_10
Schulz, V.H., Bombardelli, F.G., Todt, E.: A Harris corner detector implementation in SoC-FPGA for visual SLAM. In: Santos Osório, F., Sales Gonçalves, R. (eds.) LARS/SBR -2016. CCIS, vol. 619, pp. 57–71. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-47247-8_4
Stone, J.E., Gohara, D., Shi, G.: OpenCL: a parallel programming standard for heterogeneous computing systems. Comput. Sci. Eng. 12(3), 66–73 (2010)
Tang, J., Tian, Y.: A multi-kernel framework with nonparallel support vector machine. Neurocomputing 266, 226–238 (2017)
Tang, J., Tian, Y., Zhang, P., Liu, X.: Multiview privileged support vector machines. IEEE Trans. Neural Netw. Learn. Syst. PP(99), 1–15 (2017)
Tian, Y., Ju, X., Qi, Z., Shi, Y.: Improved twin support vector machine. Sci. China Math. 57(2), 417–432 (2014)
Tian, Y., Qi, Z., Ju, X., Shi, Y., Liu, X.: Nonparallel support vector machines for pattern classification. IEEE Trans. Cybern. 44(7), 1067–1079 (2014)
Weijer, V.D., Gevers, T., Geusebroek, J.M.: Edge and corner detection by photometric quasi-invariants. IEEE Trans. Pattern Anal. Mach. Intell. 27(4), 625–630 (2005)
Xu, D., Wu, J., Li, D., Tian, Y., Zhu, X., Wu, X.: SALE: self-adaptive lsh encoding for multi-instance learning. Pattern Recogn. 71, 460–482 (2017)
Zhu, J., Yang, K.: Fast Harris corner detection algorithm based on image compression and block. In: IEEE 2011 10th International Conference on Electronic Measurement Instruments, vol. 3, pp. 143–146, August 2011
Acknowledgments
This work has been partially supported by grants from the National Natural Science Foundation of China (Nos. 61472390, 71731009, 71331005 and 91546201), the Beijing Natural Science Foundation (No. 1162005), Premium Funding Project for Academic Human Resources Development in Beijing Union University.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
He, Y., Ma, Y., Liu, D., Chen, X. (2018). Parallel Harris Corner Detection on Heterogeneous Architecture. In: Shi, Y., et al. Computational Science – ICCS 2018. ICCS 2018. Lecture Notes in Computer Science(), vol 10861. Springer, Cham. https://doi.org/10.1007/978-3-319-93701-4_34
Download citation
DOI: https://doi.org/10.1007/978-3-319-93701-4_34
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-93700-7
Online ISBN: 978-3-319-93701-4
eBook Packages: Computer ScienceComputer Science (R0)