
Abstract
Robot Assisted Training (RAT) systems have been successfully deployed to provide assistance during a training task, promoting an efficient interaction with the user. Personalization can improve the efficiency of the interaction and thus enhance the effects of the training session. Personalization can be achieved through user skill assessment in order to choose an appropriate robot behavior that matches user abilities and needs. Graphical User Interfaces have been used to enable human supervisors to control robots and guide the interaction in RAT-based systems. This work focuses on how such interfaces can be used to enable human supervisor users (e.g., therapists) to assess user skills during a robot-based cognitive task. In this study, we investigate how different visualization features affect decision making and efficiency, towards the design of an intelligent and informative interface.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction and Problem Motivation
Robot-Assisted Training (RAT) is an HRI research area that studies how robots can be used to assist users during a training task. Research in Socially Assistive Robotics (SAR) focuses on how social interaction can assist users for various applications, including educational assistants, exercise coaches and training instructors [6]. The main goal of such a system is to provide a personalized session that matches user abilities and needs. Based on the famous Bloom’s 2 sigma problem [1], one-to-one tutoring presents better learning effects than group (conventional) tutoring. However, personalization is a complex computational problem of (1) assessing user’s abilities and skills and (2) leveraging this information to adjust system behavior and match the user’s profile [2].
User skill assessment is essential in order to achieve a personalized training session. However, assessing the skills of a new individual is not straightforward, since such agents often require a huge amount of interaction data in order to build a representative model of user skills. Human experts have the ability to assess users in an intuitive way, by identifying the specific skills that need to be assessed. SAR-based systems can support the participation of a secondary user (e.g., supervisor, teacher, therapist), who can monitor and support the interaction between the assistive robot and the primary user, through graphical user interfaces [11].
We investigate how graphical user interfaces can be exploited to enhance the decision making of secondary users, considering user skill assessment. It has been shown that informative interfaces, i.e. interfaces that visualize task-related information, can increase user involvement and thereby improve system’s performance [10]. On the other hand, human input can be leveraged and allow the system to learn from human guidance and act in a progressively autonomous manner, decreasing expert’s workload [13]. Our work moves towards the design of an intelligent and informative interface which allows a human supervisor to monitor and control a SAR-based cognitive training session. The purpose is twofold; (1) to investigate which interface features (e.g., visualization, transparency, etc.) enhance human decision making and improve system performance and (2) to leverage human input (GUI) and enable the robot learn from human input models. In this study, we investigate how visualization affects decision making and efficiency, in a user skill assessment task.
2 Related Work and Background
In the context of RAT systems, graphical user interfaces can be used for both monitoring and control purposes. An informative interface can visualize essential information, i.e., task progress, user performance, task difficulty, and others. This information can be very useful as it can enhance human decision making. Such interfaces can be also used as Wizard-of-Oz interfaces to control robot’s behavior during the interaction. The Wizard-of-Oz robot control methodology provides an appropriate approach for human supervisors to control and guide the interaction between the robot and the primary user. This methodology can be utilized towards designing autonomous HRI systems [12]. Recent work suggests that such wizarded robots can be learning agents and learn online from human input [13]. The authors presented a user study where participants were asked to control a robot during a simulated RAT session. Their findings support that learning interfaces can reduce human workload and improve system performance over time and can facilitate robot personalization.
Personalization is essential in RAT systems, since it can increase user compliance and enhance training effects. In a human-robot tutoring scenario, a robot tutor has been proposed to assist users in logic puzzle solving (nanogram) [9]. The robot tutor learns a user skill assessment model, using a Bayesian Network, and uses it to select the most appropriate next lesson that suits individual’s skills. Another approach for the same task is a Reinforcement Learning (RL) approach [7]. In this approach, the robotic tutor learns a user model during the interaction which assesses whether the user is experiencing difficulties in the task. Based on this, the robot decides whether it will perform a supportive behavior or not. An RL-based personalization module learns which specific supportive behavior (tangible, esteem, emotional support) can maximize user performance. In another application area, dynamic user modeling has been proposed to assess the level of expertise in a dialogue-based instruction scenario in order to adjust the system’s referring expression [8]. The dialogue system uses a dynamic user model to update its knowledge about user’s expertise in a given topic.
These works indicate the importance of learning a representative user model that assesses user skills to enhance user’s performance, in the context of a training task. Moreover, human guidance can be integrated to the system through graphical user interfaces to control robot behavior, while the robot can learn from human input. Towards this direction, we present our approach on how informative interfaces can be used as both monitoring and control interfaces during a robot-based cognitive task. In the next section, we present our proposed SAR-based system architecture and the cognitive task.
3 System Architecture
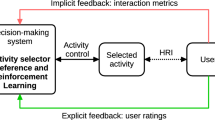
We illustrate our proposed personalization framework with a SAR-based system for cognitive training [14]. This framework integrates different types of human feedback (primary user, human supervisor) to achieve personalization. As a use case, we present the Sequence Learning task, a cognitive task related to working memory and the ability of sequencing.

The proposed system for personalized Robot Assisted Training. The system has two main modes: assessment and training mode. The GUI acts as both monitoring and control interface. Reinforcement Learning enables the system to learn from human-generated feedback (i.e., GUI input, EEG data, task performance)
During the task, users need to remember and repeat a spoken sequence of letters (A, B, C) for different sequence lengths L = [3, 5, 7, 9]. The system monitors user’s performance and adjusts the difficulty in order to maximize the effects of the cognitive training session. We deploy the NAO robot as a socially assistive robot that monitors both behavioral (task performance) and physiological (EEG) data and instructs the user towards a personalized cognitive training session. Moreover, a human supervisor can monitor and guide the interaction through an interface.
Briefly, the system has two modes: (a) assessment and (b) training mode. During the assessment mode, the goal of the system is to create a representative user model that depicts user skills on the task, during the early interaction steps. Under the training policy, the system leverages this assessment model to provide a personalized session, taking into consideration learned policies from previous interactions. In previous work, we have focused on how Reinforcement Learning can be used to learn personalized training policies for different users, considering task performance and engagement [14]. The outcome of this ongoing work is a set of user models and their corresponding personalized training policies, which can be utilized for real-time personalization (Fig. 1).
4 Methodology and Approach
This work focuses on the assessment phase of our proposed SAR-based system. More specifically, our goal is to develop an intelligent and informative interface that allows a human supervisor to monitor and guide the assessment phase of the system, as the robot interacts with a new user. In order to constrain our experimental setup, a user simulation model was used to stand in for a real human player. To this end, we follow a data-driven approach to build a set of simulation user models that capture different skills in the sequence learning task.
4.1 Data Collection for User Modeling
For the data collection procedure, we recruited 57 CSE undergraduate and graduate students to complete a session of the sequence learning task under different difficulty levels. After the data collection, each user was represented with an array \(UM_{user} = [P_1,\, P_2,\, P_3,\, P_4]\), where \(P_i = P(success|level = i)\), for level \(i\in [1,4]\). These arrays were then projected in a 2D visualization, using multidimensional scaling (MDS). K-Means clustering was applied to the projected data, to cluster users by their performance on the task. The 2D visualization and the cluster means (performance) are shown in Fig. 2.

Left: User clustering using multidimensional scaling and K-means. Right: cluster means as success probabilities at each level.
Based on the clustering, we built three user simulation models that capture different performance skills. For each cluster, the performance model estimates \(P(success|level, previous\_result)\), the probability of success given the current level and the previous result. More specifically, for each cluster, we apply Maximum Likelihood Estimation (MLE), to learn the probabilities \(P(success|level, previous\_result)\) on our observed data [5]. In order to deal with unobserved states, we deployed a neural network with softmax output, as a regressor, which estimates success probability for all levels and previous results. These different models capture different user skills considering performance in different difficulty levels.
4.2 User Study
In the user study, 30 participants (undergraduate/graduate students) were asked to monitor and guide the NAO robot using an interface during the assessment phase of the sequence learning task. The participants are 24 males and 6 females with an age range between 20 and 34 years old. Most of the participants had no prior interaction experience with a SAR; only 6 participants have reported such an experience. In order to provide the participants with a realistic environment, the study administrators acted as the primary users. Participants were under the impression that the primary users actually performed the task, while they actually interacted with a user simulation model. During the task, the participant selects a difficulty level using the GUI, the “fake” user presses the buttons (the participant can not observe which buttons), and the GUI visualizes the outcome (success, failure), based on the underlying user model. The goal is to assist participants to accurately estimate the behavior of the underlying user model. Each participant controls three short assessment sessions (9 turns/session), each one with a different interface, following the protocol shown in Fig. 3. At the beginning of the experiment, the participant was provided with a detailed description of the study and the goal of the assessment session. After the introduction, the participant performed three assessment sessions, each one under a different condition. There are three conditions: (1) control-only, (2) history-based monitoring and (3) model-based monitoring, one for each interface, as we show in Fig. 4. The order of the conditions is predefined for each experiment, to ensure a uniform sampling of all possible sequences of conditions. To remove any bias effect, for each session a different “fake” user (underlying user model) performed the task.

Experimental Protocol

The participant interacts with three different interfaces during a simulated robot assisted training assessment session. The (a) control-only interface does not have any monitoring features. The (b) history-based GUI provides a history of task performance over past levels, while (c) the model-based interface provides a visualization of the performance model as a set of success probabilities at each level.
For the control-only condition, the interface includes only the buttons that control the next difficulty level. The outcome (success/failure) is provided in written at the end of each turn. The history-based monitoring interface provides a visualization of the task history, considering previous outcomes and levels played. More specifically, the interface visualizes a plot where the x-axis is the number of turns and the y-axis is the score \(s\in [-4,4]\), defined as \(s = outcome*level\), where \(outcome = [-1,1]\) and \(level = [1,2,3,4]\). The model-based interface visualizes an estimation of the performance model P(success|level), where the x-axis represents the difficulty level and the y-axis the probability (frequency) of success at each level, updated after each turn. At each interaction step, the system uses human input (selected level) and the previous result to estimate \(P(success|level, previous\_result)\), based on which it returns success or failure. While the “fake” user pretends to repeat the sequence by pushing the buttons, the visualized outcome is estimated based on the model. During the interaction, we record turn number, reaction time, human input (selected level), and model outcome.

The participant completes this session survey after each session.
After each assessment session, the participant is asked to complete a session survey (Fig. 5) that reports the session ID, an estimation of the user success rate at each level, if it was easy to judge the user’s performance using the recent GUI and if the number if turns was enough. The session ID was provided to the participants without an explanation, and it is basically an indication of the condition and the user model, which were assigned to users in different orders to avoid the order effect. In the last session survey, the participant is also asked about their most enjoyed interface, which interface helped them the most to assess the users’ performance, their overall evaluation of the experiment and if they had any comments.
4.3 Experimental Results
This section discusses both the survey results and the data recorded while participants using the three interfaces. The majority of the participants reported in the surveys that the history-based monitoring was the most enjoyable and effective interface, followed by the model-based monitoring and the control-only monitoring, respectively (see Fig. 6). Out of the 30 participants, 29 participants reported that it was Easy or OK to judge the user’s performance using the history-based interface, compared to 21 and 28 participants on the usage of the control-only and model-based interfaces, respectively. Also, more than half of the participants agreed that the 9-turns were enough to judge user’s performance using the different interfaces, with one of the participants commenting that the number of turns should allow them to assign an equal number of difficulty levels (i.e. the number of turns should be based on multiples of 4).

Participants’ feedback on the enjoyability and the effectiveness of the three interfaces.
We compare the user survey reports to the underlying user model estimates (user model performance) and to what these estimates are based on the actual interaction (actual performance). Figure 7 shows that the mean squared error (MSE) of the performance evaluation between the survey and user models is large, which is expected as the underlying user models do not necessarily fully represent the actual performance of the user models (since it depends on user’s input). The actual user models performance depends on both the underlying user model and the difficulty levels selected by the participants. For instance, if the participant selects level 4 once and the user model reports Failure, then the actual performance is 0% even though the pre-calculated performance is 5%. The MSE between the survey data and actual data is much less, and it shows that the quality of participants evaluation is ranked the highest using the model-based GUI, followed by the history-based GUI and the control-only GUI, respectively.

The mean squared errors between the survey data and both the actual data and the pre-calculated user models
5 Discussion and Future Work
In this paper, we presented a personalization framework for a SAR-based cognitive training task, on how supervisor users can guide the assessment phase using an informative interface. For our experimental protocol, we developed a set of simulated user models that capture task performance over different difficulty levels of the sequence learning task. For our user study, participants were asked to use three different interfaces in order to guide the assessment phase and to use surveys to report on how the (simulated) users performed. Our results indicate that the participants preferred the interfaces in the following order: history-based GUI, model-based GUI and control-only GUI, respectively. However, their evaluation quality is the higher using model-based GUI, history-based GUI and control-only GUI, respectively. With that in mind, the control-only GUI was the least preferred monitoring interface and resulted in worst evaluation quality. Based on the results, we can argue that both user’s history and a model-based visualization are important features for our proposed interface.
The long-term goal of this research is to develop an intelligent and informative interface to: (1) provide human supervisors with an intuitive and efficient visualization of user skills to enhance their decision making and (2) leverage human input to enable the robot to dynamically learn human-like policies and act autonomously (interactive learning). Considering visualization, we investigate different underlying user modeling approaches in order to provide the user with a more informative and intuitive visualization [9]. Since transparency is essential in building an effective interaction between the user and the interface, we investigate additional metrics, such as model uncertainty, that can provide a better understanding to the supervisor [3, 10].
In order to enable the robot leverage human input, we will follow our proposed framework for learning from guidance [14], where human input can be used to modify an RL-based policy and enable the robot act in a progressively autonomous manner. Additionally, Active Learning methods [4] can be used to learn, based on state information, when the therapist should intervene, minimizing the expert’s workload as the system learns.
References
Bloom, B.S.: The 2 sigma problem: the search for methods of group instruction as effective as one-to-one tutoring. Educ. Res. 13(6), 4–16 (1984)
Canny, J.: Interactive Machine Learning. University of California, Berkeley (2014)
Chao, C., Cakmak, M., Thomaz, A.L.: Transparent active learning for robots. In: ACM/IEEE International Conference on Human-Robot Interaction, pp. 317–324. IEEE (2010)
Chernova, S., Veloso, M.: Interactive policy learning through confidence-based autonomy. J. Artif. Intell. Res. 34(1), 1 (2009)
Clabaugh, C., Tsiakas, K., Mataric, M.: Predicting preschool mathematics performance of children with a socially assistive robot tutor. Synergies Between Learning and Interaction Workshop, IROS (2018)
Feil-Seifer, D., Mataric, M.J.: Defining socially assistive robotics. In: 9th International Conference on Rehabilitation Robotics, 2005, ICORR 2005, pp. 465–468. IEEE (2005)
Gao, A.Y., Barendregt, W., Castellano, G.: Personalised human-robot co-adaptation in instructional settings using reinforcement learning. In: Persuasive Embodied Agents for Behavior Change (PEACH2017) Workshop at the International Conference on Intelligent Virtual Agents (IVA2017) (2017)
Janarthanam, S., Lemon, O.: Adaptive generation in dialogue systems using dynamic user modeling. Comput. Linguist. 40(4), 883–920 (2014)
Leyzberg, D., Spaulding, S., Scassellati, B.: Personalizing robot tutors to individuals’ learning differences. In: Proceedings of the 2014 ACM/IEEE International Conference on Human-Robot Interaction, pp. 423–430. ACM (2014)
Li, G., Whiteson, S., Knox, W.B., Hung, H.: Using informative behavior to increase engagement while learning from human reward. Auton. Agents Multi-agent Syst. 30(5), 826–848 (2016)
Magyar, G., Vircikova, M.: Socially-assistive emotional robot that learns from the wizard during the interaction for preventing low back pain in children. Social Robotics. LNCS (LNAI), vol. 9388, pp. 411–420. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-25554-5_41
Martelaro, N.: Wizard-of-oz interfaces as a step towards autonomous HRI. In: 2016 AAAI Spring Symposium Series (2016)
Senft, E., Baxter, P., Kennedy, J., Belpaeme, T.: SPARC: supervised progressively autonomous robot competencies. Social Robotics. LNCS (LNAI), vol. 9388, pp. 603–612. Springer, Cham (2015). https://doi.org/10.1007/978-3-319-25554-5_60
Tsiakas, K., Dagioglou, M., Karkaletsis, V., Makedon, F.: Adaptive robot assisted therapy using interactive reinforcement learning. In: Agah, A., Cabibihan, J.-J., Howard, A.M., Salichs, M.A., He, H. (eds.) ICSR 2016. LNCS (LNAI), vol. 9979, pp. 11–21. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-47437-3_2
Acknowledgments
This work was supported in part by the National Science Foundation under award numbers 1565328, 1719031 and 1338118. Also, the authors would like to thank Ashwin Ramesh Babu and Varun Kanal for their help in conducting the user studies.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Tsiakas, K., Abujelala, M., Rajavenkatanarayanan, A., Makedon, F. (2018). User Skill Assessment Using Informative Interfaces for Personalized Robot-Assisted Training. In: Zaphiris, P., Ioannou, A. (eds) Learning and Collaboration Technologies. Learning and Teaching. LCT 2018. Lecture Notes in Computer Science(), vol 10925. Springer, Cham. https://doi.org/10.1007/978-3-319-91152-6_7
Download citation
DOI: https://doi.org/10.1007/978-3-319-91152-6_7
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-91151-9
Online ISBN: 978-3-319-91152-6
eBook Packages: Computer ScienceComputer Science (R0)