
Abstract
Due to the storage and retrieval efficiency, hashing has been widely deployed to approximate nearest neighbor search for fast image retrieval on large-scale datasets. It aims to map images to compact binary codes that approximately preserve the data relations in the Hamming space. However, most of existing approaches learn hashing functions using the hand-craft features, which cannot optimally capture the underlying semantic information of images. Inspired by the fast progress of deep learning techniques, in this paper we design a novel Deep Graph Laplacian Hashing (DGLH) method to simultaneously learn robust image features and hash functions in an unsupervised manner. Specifically, we devise a deep network architecture with graph Laplacian regularization to preserve the neighborhood structure in the learned Hamming space. At the top layer of the deep network, we minimize the quantization errors, and enforce the bits to be balanced and uncorrelated, which makes the learned hash codes more efficient. We further utilize back-propagation to optimize the parameters of the networks. It should be noted that our approach does not require labeled training data and is more practical to real-world applications in comparison to supervised hashing methods. Experimental results on three benchmark datasets demonstrate that DGLH can outperform the state-of-the-art unsupervised hashing methods in image retrieval tasks.
Similar content being viewed by others


Keywords
1 Introduction
With the explosive growth of online images in recent years, large-scale image retrieval has attracted increasing attention [4, 16, 21], which tries to return visually similar images that match the visual query from a large database. However, retrieving the exact nearest neighbors is computationally impracticable when the reference database becomes very large. To alleviate this problem, hashing [20] has been widely used to speed up the query process. The basic idea of hashing approach is to transform the high dimensional data into compact binary codes, which preserve the semantic information. Then the distance between data points in high dimensional space can be approximated by Hamming distance.
Existing hashing methods can be classified into two categories: unsupervised hashing methods and supervised hashing methods. Unsupervised hashing methods only exploit unlabeled data to learn hash functions, such as Locality Sensitive Hashing (LSH) [1], Spectral Hashing (SH) [22], Iterative Quantization (ITQ) [2], Spherical Hashing (SpH) [9], and Discrete Graph Hashing (DGH) [13]. Different from unsupervised methods, supervised methods utilize label information to learn the hash codes, which can preserve the similarity relationships among data points in Hamming space, like Binary Reconstructive Embedding (BRE) [7], Minimal Loss Hashing (MLH) [17], and Kernel-based Supervised Hashing (KSH) [14]. However, these traditional hashing methods learn hash functions using hand-crafted features, like GIST [18] or SIFT [15], which are not sufficient to represent the visual content, hence these methods result in suboptimal hashing codes.
In recent years, with the rapid development of deep learning [6], it has become a hot topic to combine deep learning and hashing methods [27]. Some deep hashing methods, like CNNH [23], DNNH [8], DHN [28] and DPSH [10], have shown better performance than the traditional hashing methods because the deep architectures generate more discriminative feature representations.
However, most existing deep hashing methods are designed in the supervised scenario, which relies on the label information of data points to preserve the semantic similarity. With the rapid growth of visual data on the web, most of the online data do not have label annotations. In addition, labeling data is also very expensive, which means it is difficult to acquire sufficient semantic labels in real applications. Thus it is more acceptable to develop unsupervised hashing methods which can exploit unlabeled data directly. But the existing unsupervised hashing methods depend on hand-crafted features which cannot effectively capture the semantic information of images.
To alleviate the above problems, in this paper, we propose a novel unsupervised deep hashing method, named Deep Graph Laplacian Hashing (DGLH), to simultaneously learn the deep feature representation and the compact binary codes. We design a graph-based objective function [24,25,26] at the top layer of the deep network to preserve the adjacency relation of images without using the label information. We also minimize the quantization loss between the real-valued Euclidean distance and the Hamming distance. Moreover, we enforce the bits to be balanced and uncorrelated, which makes the learned hash codes more effective. Finally, the model parameters are learned by back propagation algorithm. The proposed DGLH is an end-to-end learning method, which means that we can directly obtain hash codes from the input images by utilizing DGLH directly. We compare the proposed DGLH method with state-of-the-art unsupervised hashing methods on several commonly-used image retrieval benchmarks, and the experimental results demonstrate the effectiveness of the proposed method.
The rest of this paper is organized as follows: The proposed DGLH method is introduced in Sect. 2. Section 3 presents the experimental results and analysis, followed by a conclusion in Sect. 4.

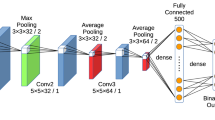
Deep Graph Laplacian Hashing (DGLH) model with a hash layer fch. The fc7 layer extracts the deep features for the input images, which are also used for graph constructing. We enforce four objectives on the neurons at the top layer of the network to learn compact binary codes: (1) we use graph Laplacian criterion to preserve the adjacency relation of images from the original feature space to the Hamming space, (2) the bits should be uncorrelated, (3) the bits should be balanced, and (4) the quantization loss should be minimized.
2 The Proposed Approach
In this paper, we use bold and uppercase letters, like \(\mathbf {X}\), to denote matrices. Bold and lowercase letters, like \(\mathbf {x}\), are used to denote vectors. 1 and 0 are used to denote the vectors with all ones and zeros, respectively. \( \mathbf I _k \) is used to denote the \( k\times k \) identity matrix. Further, the Frobenius norm \( \Vert \cdot \Vert _F \) is written as \( \Vert \cdot \Vert \).
2.1 Deep Hashing Model
Given a set of n data points \( \mathbf {X}=[\mathbf {x}_1, \mathbf {x}_2, \dots ,\mathbf {x}_n] \) where \( \mathbf {x}_i \in R^D \) is the feature vector of the i-th data point, we aim to learn a set of nonlinear hash functions to map the \( \mathbf {X} \) into compact k-bit hash codes \( \mathbf {H}=[\mathbf {h}_1, \mathbf {h}_2, \dots , \mathbf {h}_n] \) where \( \mathbf {h}_i\in \{-1,1\}^k \). During the projection, we should preserve the similarity relation among the data points in the Hamming space, which means the similar data points should have the similar hash codes. We denote \( \mathbf {S}_{ij} \) as the similarity between \( \mathbf {x}_i \) and \(\mathbf {x}_j\). So the similarity constraints are preserved as:
where \( D(\mathbf {h}_i, \mathbf {h}_j) \) is the Hamming distance between \( \mathbf {h}_i \) and \( \mathbf {h}_j \).
In order to simultaneously learn robust feature representation and compact hash codes, we utilize a deep neural network, the AlexNet [6], in this work. Figure 1 shows the framework of the proposed method. AlexNet [6] consists of five convolutional layers (conv1–conv5) and three fully connected layers (fc6–fc8). Each fc layer learns a nonlinear mapping as follows:
where \( \mathbf {f}_i^l \), \( \mathbf {W}^l \), \( \mathbf {b}^l \), and \( p^l \) are the output, the weight and bias parameters and the activation function of the l-th layer respectively. To learn compact hash codes, we change the fc8 layer with a new full-connected layer fch of k hidden units to compact the 4096-dimensional representation \( \mathbf {f}_i^7 \in R^{4096\times 1} \) of fc7 layer to k-dimensional representation \( \mathbf {y}_i \in R^{k} \).
Finally we can obtain the binary code \( \mathbf {h}_i \in R^{k} \) by following function:
where
2.2 Objective Function
In this work, we learn the compact hashing codes by a deep neural network with graph Laplacian constraint. In our method, we use spectral hashing method [22] to map the deep feature extracted from the each training sample \(\mathbf {x}_i\) to a binary hash code \(\mathbf {h}_i\). Besides, to obtain more robust feature, the learned hash codes should be balanced and uncorrelated. To this end, our objective function is defined as follows:
There are three terms in Eq. (6). The first term is used to preserve the similarity among the data points in Hamming space:
where \(\mathbf {S}_{ij}\) is the similarity matrix. For an image dataset, it could be computed by:
In Eq. (8), \( \rho >0 \) is the bandwidth parameter, \( \mathbf {f}_i^7 \) and \( \mathbf {f}_j^7 \) are the 4096-dimensional representation extracted from \( fc7 \) layer for \( \mathbf {x}_i \) and \( \mathbf {x}_j \) respectively.
For similarity, we define the graph Laplacian matrix: \( \mathbf {L}=\mathbf {D}-\mathbf {S} \), where \(\mathbf {D}\) is the diagonal degree matrix with \( \mathbf {D}_{ii}=\sum _j\mathbf {S}_{ij} \). And Eq. (7) could be rewritten as:
The second term in Eq. (6) is to enforce the hash codes to be balanced. According to the information theory, to maximize the information capacity of the hash codes, each bit should have a 50% chance to be 1 or \(-1\). In another words, an ideal hashing code \(\mathbf {h}_i\) has \( \sum _{i=1}^n\mathbf {h}_i=0\). On the learned hashing matrix H, we define the unbalanced loss as follows:
Moreover, the hash codes should be uncorrelated and different hashing code is desired to be independent to each other, to minimize the redundancy among the bits.
We use the last term in Eq. (6) to measure the correlation among the hashing codes, which could be defined as:
With \(\mathbf {G}\), \(\mathbf {B}\) and \(\mathbf {U}\), the objective function could be rewritten as:
where the \( \alpha >0 \) and \( \beta >0 \) are the balanced parameters of regularization terms.
Note that the above-mentioned optimization problem defined in Eq. (12) is a discrete optimization problem (NP hard problem) that is hard to solve. To tackle the challenging problem, inspired by [10], we relax Eq. (4) as \( \mathbf {h}_i=\mathbf {y}_i \). Then, the discrete optimization problem can be solved by a constraint approach. We reformulate the problem as:
where \( \mathbf {Y}\in R^{k\times n} \) is the output matrix of fch layer: \( \mathbf {Y}=\{\mathbf {y}_i\}_{i=1}^n \), and \( \mathbf {y}_i=\mathbf {W}^{fch}\mathbf {f}_i^7+\mathbf {b}^{fch} \). The last term in Eq. (13) is to minimize the quantization loss, and the parameter \( \varphi >0 \) is the regularization parameter.
2.3 Learning
In the DGLH model, we need to learn the parameters of the deep neural network, which could be solved by stochastic gradient descent algorithm. In each iteration we select a mini-batch of images from the training set to optimize the model parameters.
And the derivative of the objective function in Eq. (13) with respect to \(\mathbf {Y}\) is computed as:
Then we can update the parameters \( \mathbf {W}^{fch} \), \( \mathbf {b}^{fch} \) and the parameters of five convolutional layers (conv1–conv5) and two fully connected layers (fc6–fc7) by back propagation method.
3 Experiments
To evaluate the proposed method, we conduct large-scale similarity search experiments on three benchmark datasets: CIFAR-10, CIFAR-100, Flickr-25K, and compare the proposed DGLH method with five unsupervised hashing methods, including Locality Sensitive Hashing (LSH) [1], Spectral Hashing (SH) [22], Spherical Hashing (SpH) [9], Density Sensitive Hashing (DSH) [11] and PCA-Iterative Quantization (PCA-ITQ) [2].
3.1 Datasets and Setting
The CIFAR-10 [5] dataset consists of 60000 color images in 10 classes with size of \(32\times 32\) (6000 images per class). We randomly select 1000 images (100 images per class) as the query set, and the remaining 59000 images as the database for image retrieval.
The CIFAR-100 [5] dataset consists of 60000 color images in 100 classes (600 images per class). The size of each image is also \( 32\times 32 \). We randomly select 10000 images (100 images per class) as the query set, and the remaining 50000 images as the database for image retrieval.
The Flickr-25K [3] dataset consists of 25000 images collected from Flickr. The dataset are annotated by 24 topics such as bird, sky, night, and people. We randomly select 2000 images as the test query set, and the remaining images as the database for image retrieval. We resize each image in all dataset into \( 224\times 224 \) to feed the proposed neural network.
For DGLH method, we directly use the image pixels as input. For other compared unsupervised hashing methods, we represent each image in 4096-dimensional deep features extracted by the AlexNet [6] with pre-trained model on ImageNet dataset.
We implement the DGLH model based on the MatConvNet [19]. Specifically, we employ the AlexNet architecture [6], and reuse the parameters of convolutional layers conv1–conv5 and full-connect layers fc6–fc7 from the pre-trained model on ImageNet dataset, and train the last hashing layer fch from scratch. The bandwidth parameter is set as \( \rho =4 \). The two hyper-parameters \( \alpha =0.006 \), \( \beta =0.18 \). We set \( \varphi =100 \) for CIFAR dataset, and \( \varphi =1000 \) for Flickr-25K.
3.2 Experimental Results and Analysis
To evaluate the performance of different hashing methods on image retrieval, we follow [12] to use the mean Average Precision (mAP), precision and recall at top-K positions (Precision@K, Recall@K) as evaluation metrics.
Table 1 shows the mAP results of DGLH and other comparing unsupervised hashing methods on CIFAR-10,CIFAR-100 and Flickr-25K when learning 32, 48 and 64 bits hashing codes. Figures 2, 3 and 4 show the results of precision and recall curves with 48 and 64 bits for DGLH and other comparing unsupervised hashing methods on CIFAR-10, CIFAR-100 and Flickr-25K respectively. As above experimental results shown, it could be concluded that the proposed DGLH approach outperforms the comparing hashing methods.

The results of precision curves and recall curves with 48 and 64 bits hashing on the CIFAR-10.

The results of precision curves and recall curves with 48 and 64 bits hashing on the CIFAR-100.

The results of precision curves and recall curves with 48 and 64 bits hashing on the Flickr-25K.
4 Conclusion
In this paper, we propose a novel unsupervised deep hashing method for large-scale image retrieval. In this method, unlike most previous unsupervised hashing methods, we design a graph-based deep hashing network to simultaneously learn robust feature representation and compact hashing codes, which preserves the adjacency relation of images without using the label information. When training the model, we relax the discrete optimization problem and reduce quantization loss when learning the hashing code. We also use other two constraints to optimize the binary code learning to make the learned hash codes more effective. The proposed DGLH method is an end-to-end model, which can learn the hashing code from image pixels directly. Experimental results on three image retrieval datasets demonstrate that the DGLH method outperforms other state-of-the-art unsupervised hashing methods.
References
Andoni, A., Indyk, P.: Near-optimal hashing algorithms for approximate nearest neighbor in high dimensions. Commun. ACM 51(1), 117–122 (2008)
Gong, Y., Lazebnik, S.: Iterative quantization: a procrustean approach to learning binary codes. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 817–824 (2011)
Huiskes, M.J., Lew, M.S.: The MIR Flickr retrieval evaluation. In: ACM International Conference on Multimedia Information Retrieval (2008)
Jiang, S., Song, X., Huang, Q.: Relative image similarity learning with contextual information for internet cross-media retrieval. Multimed. Syst. 20(6), 645–657 (2014)
Krizhevsky, A., Hinton, G.: Learning multiple layers of features from tiny images. Technical report, University of Toronto (2009)
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: Advances in Neural Information Processing Systems, pp. 1097–1105 (2012)
Kulis, B., Darrell, T.: Learning to hash with binary reconstructive embeddings. In: Advances in Neural Information Processing Systems, pp. 1042–1050. Curran Associates Inc. (2009)
Lai, H., Pan, Y., Liu, Y., Yan, S.: Simultaneous feature learning and hash coding with deep neural networks. CoRR, abs/1504.03410 (2015)
Lee, Y.: Spherical hashing. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 2957–2964 (2012)
Li, W., Wang, S., Kang, W.: Feature learning based deep supervised hashing with pairwise labels. CoRR, abs/1511.03855 (2015)
Lin, Y., Cai, D., Li, C.: Density sensitive hashing. CoRR, abs/1205.2930 (2012)
Liu, H., Ji, R., Wu, Y., Liu, W.: Towards optimal binary code learning via ordinal embedding. In: AAAI Conference on Artificial Intelligence, pp. 1258–1265 (2016)
Liu, W., Mu, C., Kumar, S., Chang, S.-F.: Discrete graph hashing. In: Advances in Neural Information Processing Systems, pp. 3419–3427 (2014)
Liu, W., Wang, J., Ji, R., Jiang, Y.-G., Chang, S.-F.: Supervised hashing with kernels. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 2074–2081 (2012)
Lowe, D.G.: Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 60(2), 91–110 (2004)
Nie, L., Yan, S., Wang, M., Hong, R., Chua, T.-S.: Harvesting visual concepts for image search with complex queries. In: ACM International Conference on Multimedia, pp. 59–68. ACM (2012)
Norouzi, M., Blei, D.M.: Minimal loss hashing for compact binary codes. In: International Conference on Machine Learning, pp. 353–360 (2011)
Oliva, A., Torralba, A.: Modeling the shape of the scene: a holistic representation of the spatial envelope. Int. J. Comput. Vis. 42(3), 145–175 (2001)
Vedaldi, A., Lenc, K.: MatConvNet: Convolutional neural networks for MATLAB. In: ACM International Conference on Multimedia, pp. 689–692 (2015)
Wang, J., Shen, H.T., Song, J., Ji, J.: Hashing for similarity search: a survey. CoRR, abs/1408.2927 (2014)
Wang, S., Jiang, S.: INSTRE: a new benchmark for instance-level object retrieval and recognition. ACM Trans. Multimed. Comput. Commun. Appl. 11(3), 37 (2015)
Weiss, Y., Torralba, A., Fergus, R.: Spectral hashing. In: Advances in Neural Information Processing Systems, pp. 1753–1760 (2009)
Xia, R., Pan, Y., Lai, H., Liu, C., Yan, S.: Supervised hashing for image retrieval via image representation learning. In: AAAI Conference on Artificial Intelligence, pp. 2156–2162 (2014)
Liu, X., Wang, M., Yin, B.-C., Huet, B., Li, X.: Event-based media enrichment using an adaptive probabilistic hypergraph model. IEEE Trans. Cybern. 45(11), 2461–2471 (2015)
Yan, J., Cho, M., Zha, H., Yang, X., Chu, S.M.: Multi-graph matching via affinity optimization with graduated consistency regularization. IEEE Trans. Pattern Anal. Mach. Intell. 38(6), 1228–1242 (2016)
Yan, J., Yin, X.-C., Lin, W., Deng, C., Zha, H., Yang, X.: A short survey of recent advances in graph matching. In: ACM on International Conference on Multimedia Retrieval, pp. 167–174. ACM (2016)
Zhang, H., Shen, F., Liu, W., He, X., Luan, H., Chua, T.-S.: Discrete collaborative filtering. In: International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 325–334 (2016)
Zhu, H., Long, M., Wang, J., Cao, Y.: Deep hashing network for efficient similarity retrieval. In: AAAI Conference on Artificial Intelligence, pp. 2415–2421 (2016)
Acknowledgments
This work was supported in part by the National Natural Science Foundation of China (NSFC) under grants 61472116 and 61502139, in part by Natural Science Foundation of Anhui Province under grants 1608085MF128, and in part by the Open Projects Program of National Laboratory of Pattern Recognition under grant 201600006.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Ge, J., Liu, X., Hong, R., Shao, J., Wang, M. (2018). Deep Graph Laplacian Hashing for Image Retrieval. In: Zeng, B., Huang, Q., El Saddik, A., Li, H., Jiang, S., Fan, X. (eds) Advances in Multimedia Information Processing – PCM 2017. PCM 2017. Lecture Notes in Computer Science(), vol 10735. Springer, Cham. https://doi.org/10.1007/978-3-319-77380-3_1
Download citation
DOI: https://doi.org/10.1007/978-3-319-77380-3_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-77379-7
Online ISBN: 978-3-319-77380-3
eBook Packages: Computer ScienceComputer Science (R0)