
Abstract
Traditional Business Intelligence solutions allow decision makers to query multidimensional data cubes by using OLAP tools, thus ensuring summarizability, which refers to the possibility of accurately computing aggregation of measures along dimensions. With the advent of the Web of Open Data, new external sources have been used in Self-service Business Intelligence for acquiring more insights through ad-hoc multidimensional open data cubes. However, as these data cubes rely upon unknown external data, decision makers are likely to make meaningless queries that lead to summarizability problems. To overcome this problem, in this paper, we propose a framework that automatically extracts multidimensional elements from SPARQL query logs and creates a knowledge base to detect semantic correctness of summarizability.
Similar content being viewed by others


Keywords
1 Introduction
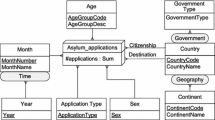
Traditional Business Intelligence (BI) rely on a well-controlled, consistent and certified Data Warehouse (DW) from which multidimensional cubes are designed in order to analyze data fast and accurately. Data cubes consists of measures or facts (representing events of interests for analysts) and dimensions (as different ways that data can be viewed, aggregated, and sorted). These Data Cubes (see Fig. 1 for a simplified example) are the basis of OLAP (OnLine Analytical Processing) tools that traditionally support the decision making process [5].

Source: [7]
Sample data cube for financial aid given by Finland, measured in amount and commitments, covering the Recipient Country, Year and Sector dimensions.
The advent of the Web of Data and the Open Data initiatives have made a tremendous amount of data to become available that can be combined with locally warehoused data, potentially improving the decision making process. The capability of (automatically) incorporating external data for supporting decision making processes gives rise to a novel branch of BI called Self-Service BI [1]. The goal of Self-Service BI is to accomplish the search, extraction, integration and querying of external data, while minimising the intervention of DW designers or programmers. Consequently, unlike the well-controlled and closed scenario of traditional BI, users of self-service BI do not necessarily know the nature of new external data to be analyzed [2], raising the issue of how to know if the multidimensional queries they ask on them are meaningful (i.e., semantically correct). This is especially significant when computing aggregations of measures with respect to dimensions, since summarizability problems may arise [11].
The simplified example on Table 1 illustrates the issue of semantics in summarizability. On the left side, a local dataset including cities in the UK is enriched with their temperatures, from external sources; on the right hand, a dataset containing chemical reactors in an industrial complex is enriched with temperature measures for each reactor. A syntactically-valid query for both datasets is to sum the temperature across cities/reactors. However, depending on the semantics, the query could be meaningless: while a meteorologist would argue that computing the sum of the temperatures across cities is not meaningful (instead, average could be more sensible), for the chief of the industrial complex, the sum of the temperatures across reactors being below or above a certain threshold might indicate a malfunction. Despite the syntactic correctness of both queries, a meaningful summarization also depends on the particular semantic of the involved multidimensional elements.
Previous works [6, 9, 11, 15] propose categories of measures and dimensions and develop algorithms to check if a given query ensures summarizability. However, in all of them, the task of categorising measures and dimensions is left to the designer of the cube which disagrees with the self-service essence. Furthermore, when integrating Web Data on the fly (even curated sources of statistical open data like those coming from The World BankFootnote 1 or EurostatFootnote 2), there is no metadata on measures or dimensions available. At best, they provide a verbose explanation as part of their metadataFootnote 3. Therefore, introducing manual annotations is required for categorizing MD elements, which hinders the ability to provide fast responses of self-service BI.
These issues lead us to argue that at Web-of-Data-Scale, the large amount of possible combinations of measure, dimensions and contexts makes very hard the development of an universal category of measures, thus, instead of trying to automate the mapping of measure and dimension types to one of the current categorisations, we propose to leverage the knowledge of query logs, made in possibly different contexts, by extracting semantic consistency information from queries made by others. The idea is to provide a hint on the semantic consistency of an aggregation query by looking if others have made the same or a similar query (in a crowdsourcing spirit). To improve the confidence on the hints, we consider the addition of provenance information to let users accept them or not depending on their own parameters (from the simple existence of a similar query, to more complex trust-based algorithms). Specifically, our contributions are as follows: (i) a framework to enable hinting of the summarizability of multidimensional queries based knowledge from queries issued by others, (ii) an extension to an existing vocabulary for describing Data Cubes in RDF for expressing the semantics of summarizability; and (iii) an algorithm to extract the multidimensional elements from SPARQL queries conforming to a multidimensional pattern.
The rest of the paper is organised as follows: preliminary definitions are provided in Sect. 2; Sect. 3 reviews the related work; Sect. 4 describe our general framework; Sect. 5 describes our extension to the QB4OLAP vocabulary; Sect. 6 describes our algorithm to extract semantics of multidimensional elements from SPARQL queries and reports our preliminary results; and finally, Sect. 7 concludes the paper and provides future work directions.
2 Preliminaries
The W3C recommends the use of the RDF Data Cube vocabulary [3]Footnote 4 (QB) to publish multidimensional data on the web. Multidimensional data in QB is comprised by a description of the observations it holds and a set of statements about them. Each observation is characterized by a set of dimensions that define what the observation applies to, along with metadata describing what has been measured, how it was measured and how the observations are expressed.
Example 1.1 shows the SPARQL version (assuming the cube is in RDF format following QB) of the multidimensional query What is the sum of commitment aid that the Philippines received from 2005 to 2008? Commitment is the measure, country and year are dimensions, while sum is the aggregation function.

However, as pointed out in [18], QB vocabulary has no support for representing: (i) dimension hierarchies, since QB only allows representing relationships between dimension instances, (ii) aggregate functions, (iii) descriptive attributes of dimension hierarchy levels. To overcome these drawbacks, QB was extended in QB4OLAP [4] to fully support the multidimensional model, also enabling the implementation of typical OLAP operations, such as rollup, slice, dice, and drill-across using standard SPARQL queries. Unfortunately, although QB4OLAP includes the concept of aggregation functions and how they are associated to measures, they do not provide the means to describe summarizability.
Executing a multidimensional querying on a data cube [17] refers to obtain a set of measures indexed by one or more dimensions and applying an aggregation function (e.g., sum, count or average) to it. Lenz and Shoshani [11] established the importance of summarizability for queries on multidimensional data, since violations of this property may lead to erroneous conclusions and decisions. They show that summarizability is dependent on (i) types of measures and (ii) the specific dimensions under consideration. Moreover, they state three necessary conditions for summarizability. The first of these conditions, called disjointness, states that consecutive levels of a dimension hierarchy must have a many-to-one relationship. The second condition, called completeness, requires that all the elements of each level of a dimension hierarchy exist as well as that each element in a level is assigned to one element of the upper level. These two conditions are at the syntactic level and they should be solved by manipulating schema to create hierarchies that ensure these summarizability constraints [16]. The third condition, called type compatibility, ensures that the aggregate function applied to a measure is summarizable according to the type of the measure (e.g., stock, flow and value per-unit as defined by Lenz and Shoshani) and the type of the related dimensions (e.g., temporal, non-temporal). According to [11], this third condition ensures the semantic correctness of summarizability in a multidimensional query.
After elaborating a multidimensional query and before executing it, a user would like to know if the summarizability is semantically ensured according to the type compatibility condition. In other words, and recalling our Example 1.1: does it make sense to sum the commitments across recipient countries and years?. The problem of semantic correctness of summarizability can be formalised as follows:
Definition 1 (Semantic correctness of summarizability)
Given a multidimensional query Q with aggregation function F, measure M and set of dimensions \(D=[D_1,...,D_n]\), decide if the application of F to the set of observations characterized by M and D has types that are semantically compatible. If so, we say that M is semantically summarizable by F across D, and denote it as  and then semantic correctness of summarizability is ensured.
and then semantic correctness of summarizability is ensured.
Back to Example 1.1, if the commitment measure is categorised as summarizable across country and year following one of the approaches in [9, 11, 15], then one can use their proposed methods to decide if the query is meaningful or not. Importantly, this can be only done in traditional BI because multidimensional elements are known before analysis and they can be categorized in advance according to the expertise of DW designers, thus limiting users to meaningful queries. However, in self-service BI, multidimensional elements coming from external sources are unknown beforehand, and are uncategorised.
3 Related Work
An in-depth analysis of summarizability problems and a taxonomy of reasons why summarizability may not hold is presented by Horner and Song [6]. They distinguish schema problems (e.g., disjointness and completeness) from data problems (e.g., inconsistencies and imprecision) and computational problems (e.g., type compatibility in the sense of [11]), give typical examples for each problematic case, and suggest guidelines for their management. A survey on summarizability issues and solutions is in [13]. Categorisation of measures is the main approach for ensuring semantic correctness of summarizability. The most recent categorization is proposed by Niemi et al. [15]. They consider measures and categorize them, depending on their nature, into tally, semi-tally, reckoning, snapshot and conversion factor. Also, they propose an algorithm to decide summarizability according to this novel categorization. Main pitfall of these approaches is that they define a fixed categorization for measures in order to ensure semantic correctness of summarization queries. This is useful in traditional BI scenarios based only on querying internal and well-known data, but is has limitations in self-service BI scenarios that query unforeseen data from heterogeneous domains (see simplified example on Table 1).
Several efforts have advanced in the direction of realising self-service BI on the Web of Data based on Linked Data Cubes and the QB vocabulary. Kämpgen et al. [8] propose a mapping from OLAP operations to SPARQL based on RDF Data Cube. They define every multidimensional element but they do not automatically deal with summarizability problems and they manually create a specific measure for each possible aggregation function. Höffner [7] defines Question-Answering (in the sense of natural language questions) on top of Linked Data Cubes.
Varga et al. [14] propose a series of steps to automate the enrichment of QB data sets with specific QB4OLAP semantics; being the most important, the definition of aggregate functions and the detection of new concepts in the dimension hierarchy construction. They state that not every aggregate function can be applied to a measure and give a valid result. Therefore, techniques to automate the association between measures and aggregate functions should be provided. To do so, they create a mapping of measures to aggregate functions called MAggMap. However, they assume that the user must explicitly provide the MAggMap mapping since they state that the large variety of measure and aggregate function types makes the compatibility check a tedious task that can hardly be fully automated.
Nebot and Berlanga [14] consider semantic correctness of summarization in multidimensional queries on LOD in the context of exploring the potential analysis of LOD datasets. They propose a statistical framework to automatically discover candidate multidimensional patterns hidden in LOD. They consider different kind of aggregation semantics than the previous literature: (i) applicable to data that can be added together; (ii) applicable to data that can be used for average calculations; and (iii) applicable to data that is constant, i.e., it can only be counted. However, they assume the existence of a function that gives for each dimension type returns the compatible aggregation functions which should be manually established by a designer or an expert of the domain.
4 Detecting Semantic Correctness of Summarizability
Our proposal focuses on leveraging the information on query logs about aggregations made by decision makers, to provide them with hints on the summarizability of their multidimensional queries based on what others have done on their data. Figure 2 gives an overview of the framework. The flow of the framework is as follows:
-
1.
A decision maker wants to execute a multidimensional query on a data cube without measure categorisation available (e.g. on a self-service BI scenario). Before issuing the query to the cube, the decision maker asks a Summarizability Hint Module (SHM) to get a hint on summarizability of the query.
-
2.
A Summarizability Knowledge Base (SUM-KB) is previously constructed by extracting from query logs how others have used multidimensional queries that ensure summarizability on different cubes and knowledge bases.
-
3.
The SHM takes the query Q and the knowledge from SUM-KB and produces a hint about the summarizability of Q (i.e., summarizability awareness).
-
4.
If the decision maker accepts the hint, the query is executed on his/her data cube and this decision of considering that Q ensures summarizability is added to SUM-KB.

Overview of framework for detecting semantic correctness of summarizability
To realize this scenario, we need to solve three problems, namely (i) how to describe semantic correctness of summarizability, (ii) how to extract semantic correctness knowledge from query logs, and (iii) how to compute a hint from said information. The first problem is solved by extending the QB4OLAP vocabulary to consider summarizability (we refer reader to Sect. 5 for further details), while the two latter problems are formalized as follows.
Definition 2 (Extraction of multidimensional elements (EME))
Given a multidimensional query string Q, extract the aggregation function F, the measure M and the dimensions D it uses. We say that Q summarizes M by F across D, and denote it as  .
.
Section 6 proposes an algorithm to solve EME for SPARQL queries. Besides the multidimensional elements of queries, the hint process can benefit of having available metadata about their context or provenance, e.g., who executed it, on which dataset, etc. We formalise this as a Summarizability statement.
Definition 3 (Summarizability statement)
Let  be the EME of a query Q and C a set containing the context or provenance of Q. We call the tuple
be the EME of a query Q and C a set containing the context or provenance of Q. We call the tuple  a summarizability statement.
a summarizability statement.
In layman terms, a summarizability statement encodes the fact that someone or something issued a multidimensional query with M, F and D and therefore considered it summarizable. In Sect. 5 we provide an extension of the QB4OLAP vocabulary that allows us to encode summarizability statements in RDF. Finally, we formalize the problem of providing a summarizability hint:
Definition 4 (Summarizability Hint)
Given a set S of summarizability statements and an instance of the semantic correctness of summarizability denoted as \(M \xrightarrow {F} D\) (cf. Sect. 2), return one of the following three outputs:
-
1.
\(M \xrightarrow {F} D\) is hinted by the statements in S
-
2.
\(M \xrightarrow {F} D\) is not hinted by S
-
3.
The knowledge in S is inconclusive to hint summarizability.
5 QB4OLAP Extension for Constructing SUM-KB
We chose to extend QB4OLAP [4] to encode summarizability statements because it already considers aggregation functions, measures and dimensions. We want to express the following knowledge (recall 3): The Measure M has been summarized by function F across dimensions \(D_1,...,D_n\) in context C. Figure 3 shows a diagram describing our extension (we only show the classes from QB4OLAP linked to the classes and properties defined by us). We encode the n-ary relationship between a measure and the aggregation function, dimensions and context on which it was summarized by means of the Summarizability Statement (SS) class and three properties: has_summarizability_statement that relates a qb:MeasureProperty with a SS; across_dimension that relates a SS with a rdfs:Class and by_aggregation that relates a SS with a qb4o:AggregationFunction. We chose to relate SSs to rdfs:Class instead of qb:DimensionProperty because knowledge bases that are not data cubes or data cubes not in QB format usually regard dimensions as concepts or classes instead of properties. QB provides the mean to link a qb:DimensionProperty to the concept and/or class it represents through the qb:concept and rdfs:Range properties, therefore, a hint to a query on RDF Data Cube could be provided by examining the summarizability statements in SUM-KB refer to the same or similar classes or concepts. If available, context information can be linked to summarizability statements and be used as input for the hinting process. Figure 3 shows the sample statement linked to a prov:agent through prov:wasAttributedTo property of PROV ontology [10].

Extension to QB4OLAP to encode summarizability statements
6 EME for SPARQL Queries
An algorithm to solve the EME (Extraction of Multidimensional Elements) problem (cf. Definition 2) for SPARQL queries has been developed. For queries executed on data cubes modelled with the QB vocabulary, e.g., Example 1.1, properties used are typed as qb:DimensionProperty or qb:MeasureProperty, making EME straightforward. Algorithm 1 shows EME for the class of queries on QB. This class is characterized as multidimensional queries centered around a variable of type qb:Observation.


However, for queries made on Knowledge Bases that are not QB data cubes, there is no explicit link to dimensions and measures. Therefore, we need to define an algorithm to perform EME. Our Algorithm 2 is divided in three main steps. We will illustrate it with the query depicted in Example 1.2.
-
1.
Extract the aggregation functions and their aggregation variables. In the example, there are three aggregation functions: max, min and avg, all of them with ?runtime as aggregation variable.
-
2.
For each aggregation function, locate the Basic Graph Pattern (BGP) that contains the aggregation variable as object. We call this the measure BGP of the query. In our example, the measure BGP is ?movies dbo:runtime ?runtime. The predicate of this pattern is the Measure type of the query. In our example dbo:runtime.
-
3.
To extract the dimensions there are two cases:
-
(a)
If the query has a Group By clause, the GroupBy variables indicate the dimensions. To get their type, we check for each one if the query has a BGP explicitly stating their rdf:type. This is not the case in Example 1.2. Note that if the query had included the BGP ?movie rdf:type schema:Movie, the algorithm would add schema:Movie as a dimension to the summarizability statement. If there is not such a BGP, we add as dimensions the rdfs:domain of the predicates of the BGPs having the group variable as subject, and the rdfs:range of the predicates of the BGPs having the group variable as subject (as in our running example). The algorithm identifies both BGPs in the query as containing the ?movie variable and dereferences the predicates dbo:runtime and dbo:starring to get their domains. Both properties have as domain dbo:Work.
-
(b)
Else, if there is no GroupBy clause, we take the variable that appears as subject in the measure BGP and apply the same procedure that we do to GroupBy variables: check if the rdf:type is explicit in the query, and if not, get the domain and ranges of the predicates involving the variable.
-
(a)
Complexity of Algorithm 2 is \(O(numF \times numBGP)\) where numF is the number of aggregation functions and numB the number of Basic Graph Patterns.

From the EME and the context/provenance metadata of the query, it is straightforward to produce RDF summarizability statements following the extension to QB4OLAP described in Sect. 5. The following excerpt shows it for Example 1.2 for the Max aggregation function:

A simple way to provide a solution to the summarizability hinting problem (cf. Definition 4) is to ask the SUM-KB if a query using the same multidimensional elements exists. For example, given a query with F = qb4o:Min, M = dbo:runtime and D = dbo:Work, the following ASK query on SUM-KB returns TRUE if there is a summarizability statement using the same combination, and FALSE otherwise:

7 Conclusion and Future Work
The capability of (automatically) incorporating external data for supporting decision making processes gives rise to a novel BI scenario labelled as Self-Service BI [1]. Within this scenario decision makers are likely to make meaningless queries that lead to summarizability problems. To overcome these problems, we propose a framework that contain (i) a Summarizability Hint Module (SHM) that allows decision makers to be aware on the potential summarizability problems of multidimensional queries; and (ii) a Summarizability Knowledge Base (SUM-KB) constructed by extracting multidimensional elements (EME), from multidimensional query logs, that contain information about semantic correctness of summarization queries. To proof-concept our framework, we generated a first version of SUM-KB from the DBpedia logs of the USEWOD 2016 research dataset [12] by filtering the queries that use aggregation functions (8946 queries out of 35124962). We applied Algorithm 2Footnote 5 to the remaining queries. Only in 0.5% of the queries the extraction was successful. Results suggest that the log of a public endpoint where many people come to learn SPARQL and the percentage of queries using aggregation is not significant. Therefore, although using the USEWOD 2016 dataset shows the feasibility of our approach works, as future work, we plan to extend our experimentation to be conducted on query logs from other endpoints (where more multidimensional queries are executed). Also, the algorithm that extracts multidimensional elements (EME) will be extended for considering a larger class of SPARQL queries.
References
Abelló, A., Darmont, J., Etcheverry, L., Golfarelli, M., Mazón, J.N., Naumann, F., Pedersen, T., Rizzi, S.B., Trujillo, J., Vassiliadis, P., Vossen, G.: Fusion cubes: towards self-service Business Intelligence. Int. J. Data Warehous. Min. 9(2), 66–88 (2013)
Abello, A., Romero, O., Pedersen, T.B., Berlanga, R., Nebot, V., Aramburu, M.J., Simitsis, A.: Using semantic web technologies for exploratory OLAP: a survey. IEEE Trans. Knowl. Data Eng. 27(2), 571–588 (2015)
Cyganiak, R., Reynolds, D., Tennison, J.: The RDF data cube vocabulary. Technical report, W3C (2014). https://www.w3.org/TR/vocab-data-cube/
Etcheverry, L., Vaisman, A., Zimányi, E.: Modeling and Querying Data Warehouses on the Semantic Web Using QB4OLAP. In: Bellatreche, L., Mohania, M.K. (eds.) DaWaK 2014. LNCS, vol. 8646, pp. 45–56. Springer, Cham (2014). doi:10.1007/978-3-319-10160-6_5
Golfarelli, M., Rizzi, S.: Data Warehouse Design: Modern Principles and Methodologies. McGraw-Hill Inc., New York (2009)
Höffner, K., Lehmann, J., Usbeck, R.: CubeQA - question answering on RDF data cubes. In: International Semantic Web Conference (ISWC) (2016)
Horner, J., Song, I.-Y.: A Taxonomy of Inaccurate Summaries and Their Management in OLAP Systems. In: Delcambre, L., Kop, C., Mayr, H.C., Mylopoulos, J., Pastor, O. (eds.) ER 2005. LNCS, vol. 3716, pp. 433–448. Springer, Heidelberg (2005). doi:10.1007/11568322_28
Kämpgen, B., O’Riain, S., Harth, A.: Interacting with statistical linked data via OLAP operations. In: Simperl, E., Norton, B., Mladenic, D., Della Valle, E., Fundulaki, I., Passant, A., Troncy, R. (eds.) ESWC 2012. LNCS, vol. 7540, pp. 87–101. Springer, Heidelberg (2015). doi:10.1007/978-3-662-46641-4_7
Kimball, R., Ross, M.: The Kimball Group Reader: Relentlessly Practical Tools for Data Warehousing and Business Intelligence. Wiley, Indianapolis (2010)
Lebo, T., Sahoo, S., McGuinness, D.: PROV-O: the PROV ontology. Technical report, W3C (2013). https://www.w3.org/TR/prov-o
Lenz, H.J., Shoshani, A.: Summarizability in OLAP and statistical data bases. In: Proceedings of the Ninth International Conference on Scientific and Statistical Database Management, pp. 132–143. IEEE Computer Society,., January 1997
Luczak-Roesch, M., Aljaloud, S., Berendt, B., Hollink, L.: Usewod 2016 research dataset. doi:10.5258/SOTON/385344
Mazón, J.N., Lechtenbörger, J., Trujillo, J.: A survey on summarizability issues in multidimensional modeling. Data Knowl. Eng. 68(12), 1452–1469 (2009)
Nebot, V., Berlanga, R.: Statistically-driven generation of multidimensional analytical schemas from linked data. Knowl. Based Syst. 110, 15–29 (2016)
Niemi, T., Niinimäki, M., Thanisch, P., Nummenmaa, J.: Detecting summarizability in OLAP. Data Knowl. Eng. 89, 1–20 (2014)
Pedersen, T.B.: Managing Complex Multidimensional Data. In: Aufaure, M.-A., Zimányi, E. (eds.) eBISS 2012. LNBIP, vol. 138, pp. 1–28. Springer, Heidelberg (2013). doi:10.1007/978-3-642-36318-4_1
Rafanelli, M., Bezenchek, A., Tininini, L.: The aggregate data problem: a system for their definition and management. ACM Sigmod Rec. 25(4), 8–13 (1996)
Varga, J., Etcheverry, L., Vaisman, A.A., Romero, O., Pedersen, T.B., Thomsen, C.: Qb2olap: Enabling olap on statistical linked open data. In: 32nd International Conference on Data Engineering (ICDE), pp. 1346–1349. IEEE (2016)
Acknowledgments
Jose-Norberto Mazón is funded by grant number JC2015-00284 under “José Castillejo” research program from Spanish Government (Ministerio de Educación, Cultura y Deporte en el marco del Programa Estatal de Promoción del Talento y su Empleabilidad en I+D+i, Subprograma Estatal de Movilidad, del Plan Estatal de Investigación Científica y Técnica y de Innovación 2013–2016). This work is also funded by research project TIN2016-78103-C2-2-R from Spanish Government (Ministerio de Economía, Industria y Competitividad).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Ibáñez, LD., Mazón, JN., Simperl, E. (2017). Towards Semantic Assessment of Summarizability in Self-service Business Intelligence. In: Kirikova, M., et al. New Trends in Databases and Information Systems. ADBIS 2017. Communications in Computer and Information Science, vol 767. Springer, Cham. https://doi.org/10.1007/978-3-319-67162-8_18
Download citation
DOI: https://doi.org/10.1007/978-3-319-67162-8_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-67161-1
Online ISBN: 978-3-319-67162-8
eBook Packages: Computer ScienceComputer Science (R0)