
Abstract
Language processing of Sanskrit presents various challenges in the field of computational linguistics. Prosodical, orthographic and inflectional complexities encountered in Sanskrit texts makes it difficult to apply linguistic analysis methods relevant for western European languages. The inadequacy of contemporary computational approaches in the analysis of Sanskrit language is vivdly apparent. In this exposition, we focus on the challenge of learning syntactic and semantic similarities in a rich Sanskrit literature. We present a simple yet effective approach of representing Sanskrit words in a continuous vector space. We utilise word embeddings in similarity, compositionality and visualization tasks to test its efficacy. Experiments show that our method produces interpretable vector offsets exhibiting shared relationships.
This is a preview of subscription content, log in via an institution.
Buying options
Tax calculation will be finalised at checkout
Purchases are for personal use only
Learn about institutional subscriptionsNotes
- 1.
A word represented as dense vector.
- 2.
- 3.
Period symbol in Sanskrit.
- 4.
Sandhi splitting.
- 5.
Sanskrit word for synonym. For example-
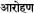 (ArohaNa) can refer to words such as mount, climb, ride, depending upon the context.
(ArohaNa) can refer to words such as mount, climb, ride, depending upon the context. - 6.
- 7.
Although, we also applied Skip Gram model with same settings, the resultant word vectors were not of adequate quality.
- 8.
- 9.
From here on we will use TOPn to refer n closest similar words.
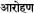 (ArohaNa) can refer to words such as mount, climb, ride, depending upon the context.
(ArohaNa) can refer to words such as mount, climb, ride, depending upon the context.References
Begum, R., Husain, S., Dhwaj, A., Sharma, D.M., Bai, L., Sangal, R.: Dependency annotation scheme for Indian languages. In: IJCNLP, pp. 721–726 (2008)
Bengio, Y., Ducharme, R., Vincent, P., Jauvin, C.: A neural probabilistic language model. J. Mach. Learn. Res. 3(Feb), 1137–1155 (2003)
Bharati, A., Chaitanya, V., Sangal, R., Ramakrishnamacharyulu, K.: Natural Language Processing: A Paninian Perspective. Prentice Hall of India Pvt. Ltd., New Delhi (1995)
Chowdhury, G.G.: Natural language processing. Ann. Rev. Inf. Sci. Technol. 37(1), 51–89 (2003)
Donoho, D.L., et al.: High-dimensional data analysis: the curses and blessings of dimensionality. AMS Math Challenges Lect. 1, 32 (2000)
Elman, J.L.: Finding structure in time. Cogn. Sci. 14(2), 179–211 (1990)
Goldberg, Y., Levy, O.: word2vec explained: deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv preprint arXiv:1402.3722 (2014)
Goyal, P., Huet, G.P., Kulkarni, A.P., Scharf, P.M., Bunker, R.: A distributed platform for Sanskrit processing. In: COLING, pp. 1011–1028 (2012)
Hellwig, O.: Detecting sentence boundaries in Sanskrit texts. In: Proceedings of COLING (2016)
Hellwig, O.: Improving the morphological analysis of classical Sanskrit. WSSANLP 2016, 142 (2016)
Huet, G.: Towards computational processing of sanskrit. In: International Conference on Natural Language Processing (ICON). Citeseer (2003)
Jain, A.K.: Data clustering: 50 years beyond k-means. Pattern Recogn. Lett. 31(8), 651–666 (2010)
Kak, S.C.: The paninian approach to natural language processing. Int. J. Approx. Reason. 1(1), 117–130 (1987)
Kashyap, L., Joshi, S.R., Bhattacharyya, P.: Insights on Hindi Wordnet coming from the IndoWordNet. In: Dash, N.S. et al. (eds.) The WordNet in Indian Languages, pp. 19–44. Springer, Heidelberg (2017)
Kerschen, G., Golinval, J.C.: Feature extraction using auto-associative neural networks. Smart Mater. Struct. 13(1), 211 (2003)
Krishna, A., Santra, B., Satuluri, P., Bandaru, S.P., Faldu, B., Singh, Y., Goyal, P.: Word segmentation in Sanskrit using path constrained random walks. In: Proceedings of COLING (2016)
Krishna, A., Satuluri, P., Sharma, S., Kumar, A., Goyal, P.: Compound type identification in sanskrit: what roles do the corpus and grammar play? WSSANLP 2016, 1 (2016)
van der Maaten, L., Hinton, G.: Visualizing data using t-SNE. J. Mach. Learn. Res. 9(Nov), 2579–2605 (2008)
Manning, C.D., Schütze, H., et al.: Foundations of Statistical Natural Language Processing, vol. 999. MIT Press, Cambridge (1999)
Mikolov, T., Kopecky, J., Burget, L., Glembek, O., et al.: Neural network based language models for highly inflective languages. In: IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2009, pp. 4725–4728. IEEE (2009)
Mikolov, T., Sutskever, I., Chen, K., Corrado, G.S., Dean, J.: Distributed representations of words and phrases and their compositionality. In: Advances in Neural Information Processing Systems, pp. 3111–3119 (2013)
Mikolov, T., Yih, W.T., Zweig, G.: Linguistic regularities in continuous space word representations. In: Hlt-naacl, vol. 13, pp. 746–751 (2013)
Mishra, A.: Modelling the grammatical circle of the pāṇinian system of Sanskrit grammar. In: Kulkarni, A., Huet, G. (eds.) ISCLS 2009. LNCS, vol. 5406, pp. 40–55. Springer, Heidelberg (2008). doi:10.1007/978-3-540-93885-9_4
Nandi, D., Pati, D., Rao, K.S.: Implicit processing of LP residual for language identification. Comput. Speech Lang. 41, 68–87 (2017)
Pandey, R.K., Jha, G.N.: Error analysis of sahit-a statistical Sanskrit-Hindi translator. Procedia Comput. Sci. 96, 495–501 (2016)
Staal, J.: Sanskrit philosophy of language. In: History of Linguistic Thought and Contemporary Linguistics, pp. 102–136 (1976)
Van Der Maaten, L.: Accelerating t-SNE using tree-based algorithms. J. Mach. Learn. Res. 15(1), 3221–3245 (2014)
Žalik, K.R.: An efficient k-means clustering algorithm. Pattern Recogn. Lett. 29(9), 1385–1391 (2008)
Zass, R., Shashua, A.: Nonnegative sparse PCA. Adv. Neural Inf. Process. Syst. 19, 1561 (2007)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Sharma, I., Anand, S., Goyal, R., Misra, S. (2017). Representing Contexual Relations with Sanskrit Word Embeddings. In: Gervasi, O., et al. Computational Science and Its Applications – ICCSA 2017. ICCSA 2017. Lecture Notes in Computer Science(), vol 10409. Springer, Cham. https://doi.org/10.1007/978-3-319-62407-5_18
Download citation
DOI: https://doi.org/10.1007/978-3-319-62407-5_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-62406-8
Online ISBN: 978-3-319-62407-5
eBook Packages: Computer ScienceComputer Science (R0)