
Abstract
Computational fluid dynamics (CFD) is a valuable tool for studying vascular diseases, but requires long computational time. To alleviate this issue, we propose a statistical framework to predict the aneurysmal wall shear stress patterns directly from the aneurysm shape. A database of 38 complex intracranial aneurysm shapes is used to generate aneurysm morphologies and CFD simulations. The shapes and wall shear stresses are then converted to clouds of hybrid points containing both types of information. These are subsequently used to train a joint statistical model implementing a mixture of principal component analyzers. Given a new aneurysmal shape, the trained joint model is firstly collapsed to a shape only model and used to initialize the missing shear stress values. The estimated hybrid point set is further refined by projection to the joint model space. We demonstrate that our predicted patterns can achieve significant similarities to the CFD-based results.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others

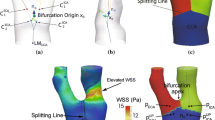
1 Introduction
We address the problem of estimating wall shear stress (WSS) on the surface of patient-specific image-based models of vascular aneurysms. Such estimates are clinically relevant as the endothelial cell response to WSS variations is one of the driving factors in the inflammatory process that leads to aneurysm growth and rupture. Boussel et al. [1], for example, have reported a correlation between aneurysm growth and areas of low time-averaged WSS. However, WSS in small vessels is difficult to be estimated accurately from flow imaging, so that it is often evaluated indirectly through computational fluid dynamics (CFD) simulations.
CFD simulations can be very time-consuming, especially in the context of rapid clinical decision making. Thus there is a need to develop methods that predict WSS directly from image-based models of aneurysms, preferably without relying on costly CFD simulations. One way to do this is by applying machine learning algorithms to build statistical models. This has been previously proposed e.g. by Schiavazzi et al. [5] to learn the relation between inlet/outlet flow and pressure in vascular flows. In contrast, statistical models for aneurysms are not found in the literature, possibly due to the heterogeneity of shapes and the consequent problems in establishing point correspondences.
To successfully predict WSS based only on the morphology of the aneurysm, we hypothesize that we deal with geometry-driven flow. This means that the time-averaged flow (and consequently the time-averaged WSS) is determined mainly by the morphology of the vasculature, and that other factors such as the mean input flow and the blood viscosity only contribute negligible fluctuation terms. Cebral et al. [2] performed a sensitivity analysis of various hemodynamic parameters in intracranial aneurysms (IAs), and showed that the greatest impact on the computed flow fields was indeed due to the morphology.
We propose a framework to predict the time-averaged WSS (TAWSS) on the surface of patient-specific saccular IAs. A joint statistical model (JSM) is trained by a hybrid dataset of IA shapes and CFD-predicted aneurysmal TAWSS. We apply the method of Gooya et al. [4] for joint clustering and principal component analysis for building statistical models. However, the published method does not provide a mechanism to predict missing values from partially observed data. We further extend it by collapsing the JSM to a shape only model, obtaining initial TAWSS values, and further refining the result by projecting it to the JSM space.
The JSM is trained using a database of 38 patient-specific IA morphologies plus 114 TAWSS patterns (three different flow scenarios for each IA morphology). The optimal model is first selected by maximizing the model evidence, and used to predict the TAWSS pattern given the IA morphology of the test aneurysm. To the best of our knowledge, this represents the first development of a statistical model for complex IA shapes that also provides predictions of WSS. While the focus here is on the TAWSS, the method is general and can also predict flow quantities in other cases where the geometry-driven flow assumption holds.
2 Methods
2.1 Vascular Modeling and Pre-processing of Shapes
A cohort of 38 IA cases are selected from the @neurIST database. Surface models of the parent vessels, the neck surface, and the aneurysm sac have been previously reconstructed using the @neurIST processing toolchain as described by Villa-Uriol et al. in [7]. In all these cases, the IA is located at the sylvian bifurcation of the middle cerebral artery (MbifA-type), which is the most prevalent location for IAs. For each vascular model, the inlet branches are truncated at the beginning of the internal carotid artery (ICA) cavernous segment and extruded by an entry length of \(5 \times \) the inlet diameter to allow for fully developed flow. Outlet branches are automatically clipped 20 mm after their proximal bifurcation. Branches shorter than 20 mm are extruded before truncation. The processed vascular surface models are then used for CFD simulation of blood flow as described in the next section.
2.2 Flow Simulation and Post-processing of TAWSS
For each surface model, a volumetric mesh of unstructured tetrahedrons with a maximum side length of 0.2 mm is generated in ANSYS ICEM v16.2 (Ansys Inc., Canonsburg, PA, USA). Three boundary layers of prismatic elements with edge size of 0.1 mm are used to provide convergence of WSS-related quantities. Blood is considered incompressible and Newtonian with density of 1066 kg/m\(^3\) and dynamic viscosity of 0.0035 Pa\(\cdot \)s. Arterial distensibility is not considered.
Time-varying inlet boundary conditions are prescribed at the ICA. To account for intra-subject flow variability on the aneurysmal TAWSS, we perform multiple flow simulations with different inflow boundary conditions for each case. A Gaussian process -model (GPM) is used to generate multiple inflow waveforms over the physiological range of variability at the ICA. This GPM is trained on subject-specific data from the study of Ford et al. [3], describing the statistical variance of 14 fiducial landmarks on the waveform. To simulate the high, moderate, and low flow conditions, we select three representative waveforms from the GPM generated samples and use them as inlet boundary conditions for flow simulations. A Poiseuille profile is imposed at all times of the inlet, and zero pressure at the outlets.
The unsteady Navier-Stokes equations are solved in ANSYS CFX v16.2 (Ansys Inc., Canonsburg, PA, USA) using a finite-volume method. Mesh convergence tests are performed on WSS, pressure, and flow velocity at several points in the computational domain. Unsteady simulations are run for 3 heartbeats until a periodic solution with stationary mean pressure is achieved. A total of \(38 \times 3 = 114\) flow simulations are performed. Thereafter, the WSS vector field \(\varvec{\tau }_w(x,t)\) on the surface is reconstructed and TAWSS is computed as:
The area of interest for building the statistical model contains only the IA aneurysm sac. This choice was made to reduce the shape complexity due to variations of the branch vessels. For each of the 114 simulated cases, aneurysm sacs along with the TAWSS data are extracted from the complete vascular model and semi-automatically aligned by Procrustes registration according to their neck surfaces. Joint aneurysm sac and TAWSS field data sets are then decimated to point sets of around 600 points, so that the statistical model could be trained in a reasonable amount of time (< 30 mins).
2.3 Construction of Hybrid Point Sets
Our combined 4-D data vectors mix both spatial (coordinates (x, y, z) of the points) ans flow components (TAWSS in units of Pa). The relative magnitudes of the different components thus need to be carefully selected to avoid biasing the joint model towards either pure shape or pure TAWSS approximations. As initial scaling, the Euclidean distance (d) of each point in the point sets from the global centroid of point sets is computed and the maximum, \(d_\text {max}\), is used to scale the spatial coordinates as \((\widetilde{x},\widetilde{y},\widetilde{z}) = (x,y,z)/d_\text {max}\). TAWSS values are scaled to fall between [0,1] by dividing them with the peak TAWSS value computed across all the vectors in the training set. To open up a possibility to investigate the effect of relative weight of shape and TAWSS in the JSM, we introduce a weighting factor (\(\alpha \)). Thus, for each case (\(k = 1, \ldots , 114\)) the 4D point set is, \(\mathcal{X}_k(\alpha ) = [ \tilde{\mathcal{Y}}_k,\alpha \tilde{\mathcal{F}}_k ]\), where \(\tilde{\mathcal{Y}}_k\) is the shape vector and \(\tilde{\mathcal{F}}_k\) is the TAWSS vector. Note that as there is no point-to-point correspondence between different shapes.
2.4 Joint Statistical Flow-and-Shape Model Construction
Footnote 1Let \(\mathcal {X}_k=\{\mathrm {\mathbf {x}}_{kn}\}^{N_k,\,\,K}_{n=1,k=1}\) denote the kth point set, where \(\mathrm {\mathbf {x}}_{kn}\) is a \(D=4\) dimensional vector containing spatial and TAWSS coordinates of the nth landmark. Our statistical model can be explained by considering a hierarchy of two interacting mixture models. In D dimensions, points in \(\mathcal {X}_k\) are assumed to be samples from a Gaussian Mixture Model (GMM) having M components. Furthermore, by consistently concatenating the coordinates of those components, \(\mathcal {X}_k\) can be represented as an MD dimensional vector. These are assumed to be samples from a mixture of J probabilistic principal component analyzers (PPCA) [6]. Clustering and linear component analysis for \(\mathcal {X}_k\) takes place in this high-dimensional space. The jth PPCA is an MD dimensional Gaussian specified by the mean vector \(\bar{\varvec{\mu }}_{j}\), and the covariance matrix given by \(\mathrm {\mathbf {W}}_{j}\mathrm {\mathbf {W}}_{j}^T+\beta ^{-1}\) I. Here, \({\mathrm {\mathbf {W}}_{j}}\) is an \({MD\times L}\) dimensional matrix, whose columns encode the variation modes in the cluster j. Let \(\mathrm {\mathbf {v}}_{k}\) be an L dimensional vector and define \(\varvec{{\mu }}_{jk}=\mathrm {\mathbf {W}}_{j}\mathrm {\mathbf {v}}_{k}+\bar{\varvec{\mu }}_{j}\), a re-sampled representation of \(\mathcal {X}_k\) in the space spanned by principal components of the jth cluster. Meanwhile, if we partition \(\varvec{{\mu }}_{jk}\) into a series of M subsequent vectors and denote each as \(\varvec{{\mu }}^{(m)}_{jk}\), we obtain the means of the corresponding GMM.
To specify point correspondences, let \(\mathcal {Z}_k=\{\mathrm {\mathbf {z}}_{kn}\}^{N_k}_{n=1}\), and \(\mathrm {\mathbf {z}}_{kn}\in \{0,1\}^M\). The latter is a vector of zeros except for its arbitrary mth component, where \(z_{knm}=1\), indicating that \(\mathrm {\mathbf {x}}_{kn}\) is a sample from the D-dimensional Gaussian m. Moreover, let \(\mathrm {\mathbf {t}}_{k}\in \{0,1\}^J\), whose component j being one, (\(t_{kj}=1\)), indicates that \(\mathcal {X}_k\) belongs to cluster j. We define
Finally, we impose prior multinomial distributions on \(\mathbb {Z}=\{\mathcal {Z}_k\}\) and \(\mathbb {T}=\{\mathrm {\mathbf {t}}_{k}\}\) variables, normal distributions on \(\mathbb {W}=\{\mathrm {\mathbf {W}}_{j}\}\) and \(\mathbb {V}=\{\mathrm {\mathbf {v}}_{k}\}\) variables, and assume conditional independence (see [4] for further details).
To train the joint flow-shape model, we consider estimating the posterior probability of \(p(\varvec{\theta }|\mathbb {X}, M,L, J)\), where \(\mathbb {X}=\{\mathcal {X}_k\}\) and \(\varvec{{\theta }}=\{\mathbb {Z},\mathbb {T},\mathrm {\mathbb {W}},\mathbb {V}\}\). Since this is not analytically tractable, an approximate posterior is sought by maximizing a lower bound (LB) on the \(p(\mathbb {X}|M,L, J)\) (also known as model evidence). This is achieved by assuming a factorized form of posteriors, following the Variational Bayesian (VB) principal. On the convergence, the approximated posteriors are computed, hence expectations (denoted by \(\langle \cdot \rangle \)) of latent variables with regard to these variational posteriors become available. For a new test point set \(\mathcal {X}_r\), we can then compute the model projected point set using the definition of the expectation: \(\langle \hat{\mathrm {\mathbf {x}}}_{rn}\rangle =\int \hat{\mathrm {\mathbf {x}}}_{rn}p(\hat{\mathrm {\mathbf {x}}}_{rn}|\mathcal {X}_r,\mathbb {X})d\hat{\mathrm {\mathbf {x}}}_{rn}\). The latter can be shown to lead into the following result.
To predict TAWSS values from a shape, we first collapse the trained joint model to a shape-only model, by discarding flow related rows from the \(\mathrm {\mathbf {W}}_{j}\) matrices and \(\bar{\varvec{\mu }}_{j}\) vectors. Using this collapsed model, we then perform VB iterations and obtain the initial posteriors for the corresponding \(\mathrm {\mathbf {t}}_{r}\), \(\mathcal {Z}_r\) and \(\mathrm {\mathbf {v}}_{r}\) variables. Following this, we retrieve \(\langle \mathrm {\mathbf {W}}_{j}\rangle \) and \(\bar{\varvec{\mu }}_{j}\) from the joint model and set: \(\langle \varvec{{\mu }}_{jr}\rangle =\langle \mathrm {\mathbf {W}}_{j}\rangle \langle \mathrm {\mathbf {v}}_{r}\rangle +\bar{\varvec{\mu }}_{j}\). Subsequently, we use (3) to estimate initial TAWSS values. These estimates are then further refined by performing VB iterations (using the joint model), updating \(\mathrm {\mathbf {t}}_{r}\), \(\mathcal {Z}_r\) and \(\mathrm {\mathbf {v}}_{r}\), and interlacing imputations from (3). We observed that a convergence is achieved within 10 iterations (< 5 mins).

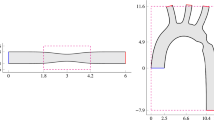
Lower bound of model evidence used for optimising the number of clusters J when \(L = 1\) (left), and the number of modes of variation per cluster L when \(J = 1\) (right). Results shown for different M, the number of sampling points in each cluster.
3 Results
3.1 Model Selection and Validation
The lower bound of the model evidence, \(p( \mathbb {X} \, \vert \, M, L, J)\), was used as a criterion to select optimal numbers of: 4-dimensional Gaussians (M), PPCA clusters (J), and modes of variations (L) in each cluster. A nine-fold cross validation was then performed using 36 IA shapes and flows to assess the generality and specificity of the model. The scaling parameter \(\alpha \), representing the relative weight of shape and TAWSS information in each point set, was then chosen to minimize the generalization and specificity errors. It was observed that the specificity and generalization errors was minimized for the default choice of scaling, i.e. \(\alpha = 1\). These parameters were used for the flow prediction test.
Figure 1 shows the variation of model evidence with respect to the model parameters (J, L, and M). For each \(1 \le J \le 40\) and \(1 \le L \le 20\), we repeated the training for 10 rounds of initializations. The mean and standard deviation of the model evidences obtained are reported. As shown in Fig. 1, maximal model evidence was observed for \(J = 23\), \(L = 1\), and \(M = 100\).
Figure 2 shows the mean shape and the first (and only) mode of variation for the two most populated clusters (the largest cluster having 12 point sets, and the second largest cluster containing 9 point sets). It can be seen that the IA size is the leading mode of the first cluster. However, in the second cluster, the leading mode of variation acts mainly to reorient the TAWSS pattern while the aneurysm shape remains similar. This demonstrates that the modes identified in the model training capture both flow and shape variabilities.

Mean and first mode of variation for the two most populated clusters. The mode of the first cluster (top row) represents mainly the IA size, while the mode of the second cluster (bottom row) represents mainly changes in TAWSS patterns.
3.2 TAWSS Prediction from Shape
To evaluate the ability of the JSM to predict TAWSS for a given test shape, we performed leave-one-out cross-validations. Since CFD model inputs have been shown to only affect the TAWSS magnitude and not the distribution of TAWSS on the aneurysm sac [8], Pearson correlation test was used to perform a statistical point-by-point comparison between the model predicted TAWSS and that obtained from the full CFD simulation. Among a total of 38, the following correlation coefficients were found: \(\rho \ge \) 0.6 for 18 cases, \(0.4 \le \rho \le 0.6\) for 13 cases, and \( \rho \le 0.4\) for the rest. It was observed that IAs with worst correlation coefficients fell into clusters with only one aneurysm shape in them. This revealed that the unsuccessful WSS prediction cases were associated with what appeared to be outlier shapes from the training data set; mainly complex multi-bleb aneurysm shapes. Figure 3 shows the model predicted TAWSS compared with the ground truth CFD solutions for the four best and worst cases. For each aneurysm, we report correlation coefficient \(\rho \) and the most probable cluster size (MPCS). The latter refers to the size of the cluster that appeared most similar to the test case. It can be seen that the IA with the worst \(\rho \) value (bottom row) fell into a cluster with size of three. While others with stronger predictions fell into more populated clusters containing at least 9 point sets in the training data.

Leave-one-out cross validation test for TAWSS estimation. Shown are the four best cases and the worst case (in terms of Pearson’s \(\rho \)). The JSM accurately predicts flow impingement regions (case 1) and absence of flow (case 2). Case 5 is a complex outlier shape that does not resemble any of the other IA shapes used for training. All correlations significant to \(p<0.001\) except case 5, \(p = 0.05\).
4 Discussion
We have presented the first statistical model for complex saccular IAs that also predicts TAWSS patterns. The JSM was trained using a database of 38 patient-specific IA geometries and corresponding TAWSS values obtained from CFD simulations. A mixture PPCA model with 23 clusters and one mode of variation in each provided the best fit in terms of model evidence. Only the morphology and TAWSS on the aneurysmal sac were used for training, yet the TAWSS included implicitly information about the configuration of the host vessels. This enabled estimations of TAWSS on the IA wall based on the IA shape alone. Observation of the modes of variation of the largest clusters confirmed that the modes contained information on the variability of both TAWSS and shape.
The large inter-subject variability of IA shapes and their parent vessel configurations means that a sufficiently representative set of training data needs to be acquired. Even when choosing the most populous type of IA (MbifA-type) from the most comprehensive imaging database available to us, we only had 38 patient cases for training. To further study the prediction power of the proposed method, a larger cohort of synthetic aneurysms could however be generated and analyzed as a future work. As a result, the leave-one-out flow prediction test revealed that some IA shapes in the dataset were outlier shapes in which the TAWSS could not be well approximated. These outlier shapes included IAs with multiple daughter aneurysms and/or unusual positioning of the IA with respect to the vasculature. They could be flagged for further CFD analysis based on the size of the cluster in the training data that they were most likely to be part of.
We used IAs as an example of heterogeneous datasets with large variability in both flow patterns and shapes. Building the shape model is challenging since there is no straightforward method for establishing point correspondences between heterogeneous shapes. In the proposed method point correspondences are not required. Furthermore, the use of the PPCA mixture model allows outliers to be automatically separated into their own clusters. This is an improvement to single cluster PPCA models, which are known to be sensitive to outliers. The method presented here is therefore general and applicable to a number of other flow prediction scenarios in the presence of complex shape variations.
Notes
- 1.
The details of statistical model has been given in [4]. A brief overview is provided here for the sake of completeness.
References
Boussel, L., Rayz, V., McCulloch, C., Martin, A., Acevedo-Bolton, G., Lawton, M., Higashida, R., Smith, W.S., Young, W.L., Saloner, D.: Aneurysm growth occurs at region of low wall shear stress patient-specific correlation of hemodynamics and growth in a longitudinal study. Stroke 39(11), 2997–3002 (2008)
Cebral, J.R., Castro, M.A., Appanaboyina, S., Putman, C.M., Millan, D., Frangi, A.F.: Efficient pipeline for image-based patient-specific analysis of cerebral aneurysm hemodynamics: technique and sensitivity. IEEE Trans. Med. Imaging 24(4), 457–467 (2005)
Ford, M.D., Alperin, N., Lee, S.H., Holdsworth, D.W., Steinman, D.A.: Characterization of volumetric flow rate waveforms in the normal internal carotid and vertebral arteries. Physiol. Meas. 26(4), 477 (2005)
Gooya, A., Lekadir, K., Alba, X., Swift, A.J., Wild, J.M., Frangi, A.F.: Joint clustering and component analysis of correspondenceless point sets: application to cardiac statistical modeling. In: Ourselin, S., Alexander, D.C., Westin, C.-F., Cardoso, M.J. (eds.) IPMI 2015. LNCS, vol. 9123, pp. 98–109. Springer, Heidelberg (2015)
Schiavazzi, D., Hsia, T., Marsden, A.: On a sparse pressure-flow rate condensation of rigid circulation models. J. Biomech. 49(11), 2174–2186 (2015)
Tipping, M.E., Bishop, C.M.: Mixtures of probabilistic principal component analyzers. Neural Comput. 11(2), 443–482 (1999)
Villa-Uriol, M., Berti, G., Hose, D., Marzo, A., Chiarini, A., Penrose, J., Pozo, J., Schmidt, J., Singh, P., Lycett, R., et al.: @ neurist complex information processing toolchain for the integrated management of cerebral aneurysms. Interface Focus 1(3), 308–319 (2011). rsfs20100033
Xiang, J., Siddiqui, A., Meng, H.: The effect of inlet waveforms on computational hemodynamics of patient-specific intracranial aneurysms. J. Biomech. 47(16), 3882–3890 (2014)
Acknowledgements
This project was partly supported by the Marie Curie Individual Fellowship (625745, A. Gooya). The aneurysm dataset has been provided by the European integrated project @neurIST (IST-027703).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing AG
About this paper
Cite this paper
Sarrami-Foroushani, A., Lassila, T., Pozo, J.M., Gooya, A., Frangi, A.F. (2016). Direct Estimation of Wall Shear Stress from Aneurysmal Morphology: A Statistical Approach. In: Ourselin, S., Joskowicz, L., Sabuncu, M.R., Unal, G., Wells, W. (eds) Medical Image Computing and Computer-Assisted Intervention - MICCAI 2016. MICCAI 2016. Lecture Notes in Computer Science(), vol 9902. Springer, Cham. https://doi.org/10.1007/978-3-319-46726-9_24
Download citation
DOI: https://doi.org/10.1007/978-3-319-46726-9_24
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-46725-2
Online ISBN: 978-3-319-46726-9
eBook Packages: Computer ScienceComputer Science (R0)