
Abstract
Within the cognitive neuroscience of language, the left anterior temporal lobe (LATL) is one of the most consistent loci for semantic effects; yet its precise role in semantic processing remains unclear. Here we focus on a literature showing that the LATL is modulated by semantic composition even in the simplest of cases, suggesting that it has a central role in the construction of complex meaning. We show that while the LATL’s combinatory contribution generalizes across several linguistic factors, such as composition type and word order , it is also robustly modulated by conceptual factors such as the specificity of the composing words. These findings suggest that the LATL’s role in composition is at the conceptual as opposed to the syntactic or logico-semantic level, making formal semantic theories of composition less obviously useful for guiding future research on the LATL. For an alternative theoretical foundation, this chapter seeks to connect LATL research to psychological models of conceptual combination, which potentially offer a more fruitful space of hypotheses to constrain our understanding of the computations housed in the LATL. We conclude that, though currently available data on the LATL do not rule out relation-based models , they are most consistent with schema-based models of conceptual combination, with the LATL potentially representing the site of concept schema activation and modification.
You have full access to this open access chapter, Download chapter PDF
Similar content being viewed by others

1 Introduction
The ability to build complex concepts from simple parts is fundamental to human language. Thus a central part of the cognitive neuroscience of language is to develop a model of where, when and how this type of composition occurs. Neuroimaging experiments have shown that sentence processing engages a large network of primarily left-lateralized, interconnected regions (Binder et al. 2009; Jefferies 2013). One of these regions in particular, the left anterior temporal lobe (LATL), appears to be directly implicated in the basic process of combining words into phrases, such as the combination of nouns with adjectival modifiers (red boat) or verbal predicates (eats meat) (Bemis and Pylkkänen 2011, 2013a; Pylkkänen et al. 2014; Westerlund et al. 2015; Westerlund and Pylkkänen 2014). In order to develop and test hypotheses about combinatory responses in the LATL, recent research has tested representational distinctions arising both from linguistic theory and neuropsychological studies of patients with temporal lobe damage. This work has revealed that LATL responses generalize across various word classes (Westerlund et al. 2015), but are sensitive to the conceptual nature of the combining words. For example, the conceptual specificity of the composing items robustly modulates the combinatory responses in the LATL (Westerlund and Pylkkänen 2014; Zhang and Pylkkänen 2015) and composition such as numeral quantification (e.g., two boats), which arguably does not add any conceptual features to a noun, does not elicit LATL effects at all (Del Prato and Pylkkänen 2014; Blanco-Elorrieta and Pylkkänen 2016). Thus the LATL appears mostly sensitive to the composition of elements whose meanings are in some sense clearly conceptual, as opposed to composition in a more general sense. In other words, the presence of semantic composition alone is not predictive of combinatory effects in the LATL but rather the semantic composition needs to fit a certain a conceptual profile. Given this, the psychological literature on conceptual combination is a potentially a useful cognitive basis for studying the LATL, a connection we explore in this article.
A large psychological literature has carefully investigated the way that meaning is constructed at the conceptual level and developed models of possible combinatory mechanisms (see Murphy 2002 for discussion). Therefore, these models could be useful for generating predictions about the LATL’s combinatory role. In this chapter, we outline two major models of conceptual combination, ‘schema-based’ models and ‘relation-based’ models and discuss how these models may be able to constrain the hypothesis space regarding the role of the LATL in composition.
2 The LATL as a Central Combinatory Region
The LATL’s anatomical location makes it an excellent candidate for a central combinatory region. It is well connected to primary sensory and motor areas, along with their related association cortices (Catani and De Schotten 2008; Gloor 1997), is close to the medial temporal lobe, which supports memory processes, and is functionally connected to several critical language regions, including the left inferior temporal gyrus and the middle temporal gyrus (Hurley et al. 2014).
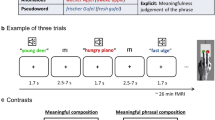
Several neuroimaging experiments have implicated the LATL in sentence processing above the word level. It is consistently engaged by contrasts between structured, meaningful sentences and word lists or jabberwocky sentences (Bottini et al. 1994; Brennan et al. 2010; Brennan and Pylkkänen 2012; Crinion et al. 2003; Friederici et al. 2000, 2003; Humphries et al. 2001, 2005, 2006, 2007; Mazoyer et al. 1993; Pallier et al. 2011; Rogalsky and Hickok 2009; Scott et al. 2000; Stowe et al. 1998; Vandenberghe et al. 2002; Xu et al. 2005). Most critically for its putative status as a combinatory region, a series of magnetoencephalography (MEG) experiments has shown the LATL to be the region most reliably engaged by the composition of basic adjective-noun phrases (Bemis and Pylkkänen 2011, 2013b; Del Prato and Pylkkänen 2014; Pylkkänen et al. 2014; Westerlund and Pylkkänen 2014). The LATL shows consistent differences in neural activity, peaking at around 250 ms, between adjective-noun phrases (e.g. red boat) and the same nouns in isolation (preceded by an unpronounceable consonant string, e.g. xqk boat) (Bemis and Pylkkänen 2011). Importantly, there is no equivalent increase in activity when nouns are presented in a list (e.g. cup, boat) rather than in a phrase, suggesting that the LATL is specifically engaged by the composition of words into a coherent phrase, rather than by a simple increase in the amount of lexical information present.
Of course, composition is not limited to the combination of adjectives and nouns, but extends across all word classes: verbs and adverbs, verbs and their objects, prepositions and their arguments, to name but a few. Within linguistics, at least one prominent model of semantic composition outlines two broad types of composition: the satisfaction of a predicate’s argument position ( argument saturation) , and the optional modification of a predicate (modification) (Heim and Kratzer 1998). Argument saturation represents a core process of semantic composition. Several word classes, such as verbs, prepositions, and determiners, require arguments in order to exist in well-formed expressions. For example, in the phrase ‘eat meat’, the verb ‘eat’ takes the direct object ‘meat’ as its internal argument. Composing the verb with its argument saturates its argument requirement, allowing it to be interpreted. While argument saturation is crucial to the construction of well-formed sentences, language also contains optional elements that serve to enrich the meaning of a well-formed expression. For example, though ‘I ate meat’ is a perfectly interpretable sentence, the meaning conveyed is greatly changed when meat is modified with an adjective such as ‘spoiled’. This type of optional composition is typically described as modification.
Westerlund et al. (2015) investigated whether LATL combinatory responses generalize across these two composition types by presenting words in either modification or argument saturation contexts (black sweater and eats meat). Both types of composition elicited larger responses in the LATL compared to the same second words presented in isolation. In both cases, the effects peaked at ~250 ms. Furthermore, similar results were found in Arabic, a language with post-nominal adjectives (e.g. sweater black). These results provide evidence that the LATL plays a general role in composition, independent of composition type, language, or word order .
The LATL has also been implicated in the combination of simpler concepts to create more complex concepts at the single-word level (e.g. boy can be represented by the concepts young and male) (Baron and Osherson 2011; Baron et al. 2010), which suggests that the LATL’s role in composition may be at the conceptual level, rather than at the level of semantic composition as traditionally conceived of in linguistics. Specifically, most linguistic theories of semantic composition would not consider the construction of a complex single word concept out of its primary features to be composition in the same sense as the composition of words into phrases (i.e., the semantic complexity of boy would not in most formal semantic theories correspond to structural complexity that required combinatory steps).
Relatedly, neuropsychological investigations of patients with damage to the LATL have shown that their sentence comprehension and production remain mostly intact, particularly if semantic demands are kept low (Cotelli et al. 2007; Gorno-Tempini et al. 2004; Grossman et al. 2005; Hodges et al. 1992; Kapur et al. 1994; Kho et al. 2008; Noppeney et al. 2005; Wilson et al. 2012). Instead, damage to the LATL leads to a disorder called semantic dementia (SD), in which patients suffer a severe, amodal, memory loss for concepts that manifests across a variety of tasks, including picture naming, word-picture matching, delayed-copy picture drawing, and categorization (Gainotti 2006, 2007, 2011; Garrard and Carroll 2006; Garrard and Hodges 2000; Hodges et al. 1992, 1995; Mummery et al. 1999, 2000; Patterson et al. 2006; Rogers et al. 2004; Snowden et al. 1989). One well-documented aspect of the pattern of conceptual memory loss in SD is that more specific concepts are disproportionally affected by LATL degradation. Patients with SD use progressively more general labels and lose the ability to distinguish similar concepts, mistaking, for example, a zebra for a horse.
Westerlund and Pylkkänen (2014) investigated the relationship between conceptual specificity and composition effects in the LATL, with the goal of characterizing whether these two variables modulate the same LATL activity. The conceptual specificity of the noun was varied in adjective-noun phrases (e.g. blue canoe vs. blue boat) with results showing that combinatorial responses in the LATL at ~250 ms were sensitive to the specificity of the noun, with less specific nouns (blue boat) eliciting greater combinatory responses in the LATL than more specific nouns (blue canoe). For a fuller assessment of the position-by-position interplay between single word specificity and composition, a follow-up experiment manipulated the conceptual specificity of both the modifier and head in noun-noun compounds (e.g. tomato vs. vegetable, soup vs. dish) (Zhang and Pylkkänen 2015). More specific modifiers (tomato) elicited the greatest responses in the LATL when composed with a less specific head (dish). In both of these studies, the effects of single word specificity were subtle or even completely absent when composition was not at play, such as in the head word position when no modifier was present (boat vs. canoe) or in the modifier position when the head word had not yet been seen (vegetable _ vs. tomato _). In contrast, the effect of specificity on composition was robust. Thus these data suggest that at least this LATL-localized MEG activity, occurring at ~250 ms, is most strongly driven by the composition of concepts and not by access to already stored representations .
In sum, these combined results show that although LATL composition effects generalize across composition types and word order (Westerlund et al. 2015), they can be significantly diminished if the composition does not result in a substantial boost in the conceptual specificity of the head word: modifying an already specific noun (blue canoe; Westerlund and Pylkkänen 2014) does not elicit a strong combinatory response perhaps because the noun is already quite specific and modifying a noun with a very general modifier also fails to engage the LATL measurably (vegetable dish; Zhang and Pylkkänen 2015). Westerlund and Pylkkänen (2014) argued that these results suggest that the LATL’s role in composition might be directly related to its role in semantic memory .
The pattern of semantic memory loss in the LATL has led researchers to hypothesize that it acts as a ‘semantic hub’ (Lambon Ralph et al. 2010; Patterson et al. 2007; Rogers et al. 2004; Rogers and McClelland 2004; Rogers and Patterson 2007), and Westerlund and Pylkkänen (2014) suggested that the semantic hub model might be extended to account for the LATL’s involvement in semantic composition. The semantic hub model assumes that concepts are represented as sets of features (for example, a dog is brown, has eyes, and barks), and that these features are represented in a distributed manner across the brain in modality-specific areas (color and shape in visual areas, sound in auditory areas, etc.). However, these distributed features alone are not sufficient to account for the abstract amodal representations that humans have of concepts. Though elephants and mice share very little in common visually, we categorize them both as animals based on other overlapping features. Rogers and colleagues argue that these categorization abilities require the existence of a hub, located in the LATL, which stores amodal representations of concepts by coordinating the distributed features. Because more specific concepts share several overlapping features (e.g. all poodles have curly hair, four legs, and floppy ears), it is more difficult to distinguish their representations, which leaves them more vulnerable to damage as the LATL deteriorates. In other words, when presented with two poodles, as opposed to a poodle and an elephant, the hub must work harder to identify the few distinguishing features of each poodle (say, a few inches difference in size) than to identify one of the many differences between poodles and elephants (color, size, sound, location, etc.). Note that the hub model is most plausibly a model of concrete concepts, unlikely to suffice as a general account of the semantic space which obviously includes concepts and combinations such as original idea, lacking any obvious distributed modal features (for discussion, see e.g., Shallice and Cooper 2013).
Proponents of the semantic hub model argue that the pattern of amodal semantic memory loss in SD points to the LATL as the most likely candidate for a semantic hub. However, this model has been criticized on the grounds that the pathology of SD is not always neatly contained in the ATLs (Hodges and Patterson 2007; Brambati et al. 2009), which can make it difficult to assert that the ATLs are the locus of the critical damage (Simmons et al. 2010). Furthermore, in the intact brain, the LATL is not consistently activated across all tasks that require conceptual processing (Simmons et al. 2010). However, this latter fact may be due in part to technical challenges in imaging the ATLs, related to their proximity to the nasal cavities (see Visser et al. 2010 for discussion). The presence of LATL effects in the MEG experiments listed above, which do not suffer from similar imaging challenges, lend some support to this interpretation.
Critics of the semantic hub model have also pointed to the ATL’s engagement in social and emotional processing (Olson et al. 2007; Zahn et al. 2007) and theory of mind tasks (Olson et al. 2007), as well as in the recognition of famous and familiar people (Damasio et al. 2004; Gorno-Tempini et al. 1998; Sergent and Signoret 1992) to argue that the ATL’s role is specific to the social domain (Simmons et al. 2010). Yet other competing models of the LATL propose that LATL plays a role in recognizing unique items, such as familiar people and places (Damasio et al. 1996; Grabowski et al. 2001; Gainotti et al. 2003; Gainotti 2007; Ross and Olson 2012); or that that semantic information is simply grouped by semantic categories, organized along an anterior-posterior gradient across the temporal lobes (Chao et al. 1999; Martin and Chao 2001).
It is of course possible that the LATL plays multiple roles in conceptual processing. Though we discuss the LATL as a single unified region for the purposes of simplicity, the LATL in fact has several anatomical and functional subdivisions (Fan et al. 2014; Rogalsky and Hickok 2009; Sanjuán et al. 2014; Visser et al. 2012; Visser and Lambon Ralph 2011). Therefore, it is difficult to determine whether these models represent competing or complementary interpretations of LATL activity. We believe the semantic hub model to be the simplest model that can reconcile results from SD with results from the sentence processing literature. In fact, when a noun is modified by an adjective , the outcome is a modified conceptual representation, and Westerlund and Pylkkänen (2014) suggested that the semantic hub might also be involved in the construction of that modified representation . This might then account for the observed interaction within the LATL between conceptual specificity and combinatory responses. However, this can only be a rudimentary starting point for characterizing the precise contribution of the LATL, as the semantic hub theories offer no mechanistic model of how complex concepts are composed. Since the richest body of work on this topic can be found under the term “conceptual combination” within cognitive psychology, we turn next to these models in order to evaluate extant LATL data in light of predictions arising from this work.
3 Theories of Conceptual Combination
Within psychology, theories of conceptual combination have focused almost exclusively on the modification of nouns, either by adjectives (e.g. red apple) or by other nouns (e.g. city dog). In modification, the concept being modified is the ‘head’, while the other is the ‘modifier’. Psychological models for how concepts are combined fall into two general camps: ‘schema-based’ models and ‘relation-based’ models. Schema-based models propose that interpretation arises from the features of the individual constituents (Cohen and Murphy 1984; Hampton 1987, 1997 ; Murphy 1988; Rumelhart 1980; Smith et al. 1988; Wisniewski 1997), whereas relation-based models focus on how interpretation arises from the general relationship between constituents (Downing 1977; Gagné 2001; Gagné and Shoben 1997, 2002; Gleitman and Gleitman 1970; Levi 1978).
3.1 Schema-Based Models
Schema-based models start with the assumption that concepts contain sets of features organized into a ‘schema’ (Cohen and Murphy 1984; Rumelhart 1980). Rather than a disorganized list of features (is red, is sweet, is round, etc.), features within a schema are organized into a set of dimensions that are important to that concept. For example, the concept apple might have dimensions for color, shape, and taste, amongst others, but not, say, for speed. Within each dimension, features are weighted according to how typical they are for the concept. In the color dimension, apple might have the possible features green, red and brown as features, and red would be weighted higher than brown.
Within this framework, conceptual combination involves the modification of the head’s schema by a feature of the modifier. Smith et al. (1988) laid out a prominent version of this model, in which each dimension is weighted by how ‘diagnostic’ it is for a concept; in other words, how useful the dimension is for distinguishing it from similar concepts. For example, the taste dimension is useful for distinguishing an apple from other small, round objects, as well as from other fruit. When two concepts are composed, the modifier’s feature is placed into a particular dimension in the head’s schema. In red apple, for example, the feature red is placed into apple’s color dimension. The process of modifying a dimension also makes that dimension more diagnostic for the concept. This captures the intuitive fact that knowing that a concept is red is even more important for identifying a red apple than an apple.
While useful, this model struggles to account for instances of modification in which the modifier is more complex than a simple adjective like red. Murphy (1988) provides the adjective corporate as an example. The dimension that corporate modifies in a composed phrase is dependent on the head noun: a corporate car is one owned by the company (modifying the ownership dimension), a corporate lawyer is one who works for the company (modifying the employment dimension), and corporate stationery has the company’s logo on it (modifying a visual dimension). Furthermore, there can be complex interactions between the various dimensions of a concept when it is modified (Medin and Shoben 1988; Murphy 2002)—for example, the modifier brown does not just modify the color dimension of apple, but also affects our idea of its taste (unpleasant) and texture (mushy).
Murphy (1988, 1990) proposed that these complications can be accounted for by adding world knowledge to the model. Comprehenders can then draw upon their existing knowledge of cars, lawyers and stationery when deciding what dimension is likely to be modified by corporate. Furthermore, after the appropriate dimension has been identified and modified, world knowledge can be used to make further inferences about the concept (Murphy 1990). For example, a comprehender might realize that a brown apple is probably rotten, and use this knowledge to draw conclusions about its likely taste and smell. One possible mechanism for this process is ‘extensional feedback’ (Hampton 1987 )—essentially, particular instances of a composed concept can be retrieved from memory, and those memories can be used to refine the representation of the concept. For example, after reading brown apple, you might remember the last brown apple you had the misfortune of biting into, and you can incorporate aspects of that memory (the bad smell, the soft mush, etc.) into your representation of the concept.
3.2 Relation-Based Models
The central insight behind relation-based models of conceptual combination is the fact that concepts are often combined according to certain patterns. In the phrases glass bottle, pea soup, and leather purse, the modifiers and heads are in a similar relationship; in all three cases, the head is ‘made of’ the modifier. Relation-based models propose that comprehenders make use of these statistical regularities in their language to constrain the process of composition. For example, when a comprehender reads the phrase glass bottle, she can recognize an instance of ‘made of’ relationship, and therefore immediately understand that a glass bottle is a bottle ‘made of’ glass without needing to access the specific features of the particular concepts.
The most prominent relational model of conceptual combination is the RICE (Relational Interpretation Competitive Evaluation) model (Spalding et al. 2010), previously the CARIN (Competition Among Relations in Nominals) model (Gagné and Shoben 1997). This model argues that there is a fixed set of ‘primitive’ relations into which all combinations can be classified (Downing 1977; Levi 1978), and that comprehenders store distributional information about the types of relations in which the words of their language tend to occur. The process of combining concepts therefore consists of retrieving the appropriate relationship between the modifier and head and linking the concepts according to that relation. As an example, the noun mountain, when used as a modifier, occurs much more often in a location relation (e.g. mountain cloud) than in an about relation (e.g. mountain magazine). Gagné and Shoben (1997) showed that participants were quicker at judging the sensicality of phrases in which modifiers were in a more frequent relation to the head (i.e. mountain cloud was easier to interpret than mountain magazine).
Several researchers have argued that the assumption that there is a constrained set of relational ‘primitives’ that are stored separately in the mental lexicon is not necessary for a relation-based model. Using Wordnet (Seco et al. 2004), Devereux and Costello (2005) examined the semantic similarity of the constituent words for all the phrases used in Gagné (2001), and concluded that semantically similar words tend to be used in similar kinds of relations. For instance, gas and propane are lexically very similar, and also tended to be used in combinations with similar kinds of relations (gas crisis, propane shortage). Maguire et al. (2010) confirmed that the type of relations in which constituents tend to occur can be predicted by the semantic nature of the constituents, in a study of all noun-noun combinations in the British National Corpus. Using WordNet, they classified all the constituents in the corpus into 25 different high-level semantic categories, such as ‘substance’, ‘artifact’, or ‘emotion’, and found a strong relationship between the semantic categories of the constituents in the combinations and their relations. They argued that distributional information based on the semantics of the constituents can guide the construction of a relation between them without necessitating the assumption of a separately stored relation.
Importantly, there is evidence that people are sensitive to these category-level statistical patterns. Maguire et al. (2010) showed that participants were able to evaluate a combination like chocolate taste just as quickly as a combination like chocolate rabbit, even though only chocolate rabbit conforms to the highest relation frequency for chocolate (‘made of’). The RICE model would instead have predicted that chocolate rabbit would be interpreted more rapidly, as it is the phrase with the more frequent relation for chocolate. The authors suggested that this contradictory result arose from the fact that substance-attribute combinations like chocolate taste most frequently occur in the ‘has’ relation, which can make up for the specific preference that chocolate has for a ‘made of’ relation like chocolate rabbit.
3.3 Summary
In sum, schema-based models and relation-based models each address different aspects of the composition process. Schema-based models focus on the internal conceptual structure of constituents, and on how this internal structure is modified when the concepts are combined. Relation-based models focus on statistical regularities in how concepts tend to compose, and argue that this information guides the composition process. Importantly, these models are not necessarily mutually exclusive. Maguire et al. (2010) suggest that statistical information could serve a similar function to world knowledge within the schema modification process, by identifying candidate dimensions for modification based on previously encountered similar examples. They provide the example of stone squirrel. If a comprehender matches the phrase to the common combination pattern ‘substance-object’, and knows that this combination is most often used in a ‘made of’ relation, he can then avoid retrieving irrelevant features such as is alive or eats nuts, and instead be guided towards form features like has a tail and has four legs.
4 Processing Predictions of Schema and Relation-Based Models
4.1 Storage and Retrieval
The most important assumption of schema-based models of conceptual combination is that concepts are represented as a collection of features organized into structured schemas. This assumption is also the basis of the semantic hub model of the LATL, in which features are organized in modality specific areas, representing dimensions, and the hub serves to organize all the relevant dimensions into a schema.
Composing concepts requires the selection of the relevant feature of the modifier, as well as the corresponding dimension of the head; therefore, schema-based models also assume that composition first requires the retrieval of the feature representations of both constituent concepts. According to the semantic hub model , these feature representations are mediated in the LATL. Together, these models predict that the LATL is involved in retrieving the feature schema for the modifier and head noun, and that this process is the necessary first stage of conceptual combination.
Relation-based models argue that language users store statistical information about the distribution of concepts in their language across relation types. Maguire et al. (2010) suggest that the relevant distributional information about composed phrases is at the level of general semantic categories, such as plant-plant (e.g. flower bud) and substance-substance (e.g. wax paste), rather than at the level of individual words. Under this type of account, one might then expect certain neural responses to encode combinations of category-level information. However, as regards the LATL, Westerlund and Pylkkänen (2014) and Zhang and Pylkkänen (2015) have shown that LATL combinatorial responses are sensitive to the specificity of the nouns being composed, even when the nouns are in the same general semantic category (for example, blue canoe and blue boat might each be categorized as ‘attribute-object’). Therefore, category-level information alone does not appear to be driving LATL responses, though these results of course do not directly rule out relation-based models. Determining whether the frequency of a given combination affects combinatory responses in the LATL would be a more direct test of the predictions of relation-based models. Furthermore, as proposed by Maguire et al. (2010), it is possible that statistical information is accessed prior to the composition response measured in the LATL, and used to guide feature selection.
More generally, if distributional information does guide the retrieval of features in the LATL, we would expect different representations to be retrieved for the same word, depending on the type of phrase it is presented in. Indeed, there is behavioral evidence that the features that are retrieved for a concept are context-specific (Barclay et al. 1974; Barsalou 1982; Tabossi and Johnson-Laird 1980). For example, Tabossi and Johnson-Laird (1980) presented the same word within two different contexts that each emphasized a different feature of the concept.
-
(1)
The goldsmith cut the glass with the diamond
-
(2)
The mirror dispersed the light from the diamond
Participants were faster at verifying the truth of the subsequent sentences diamonds are hard or diamonds are brilliant when these were compatible with the feature emphasized by the context. However, there is as of yet no specific evidence that distributional information of the kind posited by Maguire et al. (2010) constrains feature selection in the LATL.
In sum, schema models, which assume that a concept’s feature schema is retrieved prior to composition, have direct theoretical overlap with semantic hub models of the LATL. The idea that distributional information might direct feature retrieval is open to further investigation.
4.2 Composition
4.2.1 What Is the Combinatory Process?
After the features and/or relations of the constituent concepts have been retrieved, a composed concept is created. A composed concept is not simply the knowledge that, for example, cooked pasta is pasta that has been cooked. Above and beyond the features of the constituents, composed concepts have features that are true of the combined representation but not of the individual constituents, or ‘emergent features’. For example, comprehenders know that cooked pasta is soft even though pasta itself could be hard. Thus composition can also result in the ‘deletion’ of features. Understanding how, when, and even whether comprehenders arrive at a complete composed representation is crucial to understanding the combinatory process.
In schema-based models, the core process underlying combination involves the selection of a relevant feature of the modifier and the related dimension of the head. Thus, these models predict that it will be more difficult to select the appropriate features for constituents with more complex internal representations , and that such phrases will therefore be more difficult to compose. There is behavioral evidence that this is in fact the case. Participants were slower to understand novel phrases with noun or non-predicating adjectives modifiers (such as prostitute committee) than novel phrases with predicating adjectives (such as edible food) (Murphy 1990). The speed of interpretation was also affected by the typicality and abstractness of the modifier (inedible food was interpreted more slowly than edible food) (Murphy 1990; van Jaarsveld and Drašković 2003; Xu and Ran 2011). If the LATL is involved in the process of composing concepts, rather than in simply retrieving the relevant representations, we might expect to see greater LATL activity for more complex modifiers. This is consistent with the results of Zhang and Pylkkänen (2015), in which composing more specific modifiers, with more features, elicited greater LATL activity on the head noun.
It is less clear how to reconcile this prediction with results from Westerlund and Pylkkänen (2014) showing that less specific heads elicit greater LATL combinatory responses. Less specific concepts have fewer features and therefore a less complex internal representation; however, it may be more difficult to select the appropriate dimension to modify in a more general concept . For instance, what is a brown animal? If it’s a mammal, this might be an animal with the feature brown in the color-of-fur dimension. Alternatively, it might be color-of-scales if it’s a fish, or color-of-feathers if it’s a bird. A noun denoting a general category of concepts, comprising multiple disparate subcategories of concepts, may not have a single readily accessible dimension that can be modified, in which case it might be more difficult to compose. Of course, this hypothesis makes the prediction that combinatory responses will vary depending on the modifier; a modifier that targets a feature at the more general level might be easier to compose with a more general head (e.g. dead animal).
Schema-based models also assume that a combined concept will inherit most of the features of its constituents. Other than the dimension(s) being modified, the features of the head noun should remain stable in the resulting representation . For example, the representation of a red apple should still have the features of apple (i.e. is sweet, is a fruit, grows on a tree, etc.). Connolly, Fodor , Gleitman, and Gleitman (Gainotti 2007) argue, however, that the feature inheritance assumption is incompatible with a phenomenon they term the ‘modification effect’—the fact that properties that are believed to be true of a concept are judged to be less true of a modified concept. As a typical example, people rate baby ducks have webbed feet as less true than ducks have webbed feet, despite the fact that webbed feet should be inherited from duck into the composed phrase (Connolly et al. 2007). The modification effect also holds for non-word modifiers, which have no semantic content (e.g. brinn bottles are cylindrical) (Gagné and Spalding, 2011).
Spalding and Gagné (2014) also provide intriguing evidence for a ‘reverse modification effect’ , in which noun properties that are evaluated as false (e.g. candles have teeth) are judged as less false when the noun is modified (e.g. purple candles have teeth). Participants appear to be both less comfortable attributing a true property (having webbed feet) and more comfortable attributing false properties (having teeth) to modified nouns.
Gagné and Spalding (2014) argue that the modification and reverse modification effects are more compatible with relation-based models than schema-based models. In the RICE model, they propose that the initial output of the composition process is an underspecified representation, which they term a ‘relational gist’, limited to the relation between the two constituent concepts . A comprehender’s first-pass understanding of a composed concept might thus correspond roughly to the idea that ‘a mountain cloud is a cloud located in the mountains’, or that ‘a corporate car is a car used by a corporation’ (Gagné and Spalding 2014; Spalding and Gagné 2014). In other words, they argue that no features are inherited during the first stage of the composition process. Any further information about the composed concept, such as the fact that mountain clouds are white, fluffy, and block out the sun, is accessed if and only if the context necessitates further interpretation.
The intuition that combined concepts are initially underspecified, and are only fully fleshed out if the context requires it is similar to a prominent model of sentence processing in psycholinguistics, in which comprehenders construct representations that are ‘good enough’ for the task of understanding the meaning of the sentence but do not reflect a complete syntactic and semantic analysis of the sentence (Ferreira et al. 2001, 2002; Ferreira and Patson 2007). However, this idea is not as incompatible with schema-based models as Spalding and Gagné suggest. It is somewhat implausible to assume that every feature of a concept is retrieved and active during the process of composition: in composing the constituents baby and duck, for example, a comprehender would have to activate every single feature that he or she knows about ducks, including the fact that they have eyes, a heart and lungs, lay eggs, breathe, etc. Instead, context and world knowledge can limit feature retrieval. Therefore, if one assumes that in the absence of a supporting context the specific feature having webbed feet is not part of the initial combined concept of baby duck, schema modification models do not strictly conflict with modification and reverse modification effects . Instead , these effects might arise out of a post hoc pragmatic reasoning process which assumes that a speaker is providing exactly the necessary information and no more, leading participants to assume that the modifier plays an important contrastive role in the phrase (Gagné and Spalding 2014; Grice 1975; Hampton et al. 2011; Jönsson and Hampton 2012).
In sum, modification and reverse modification effects themselves are potentially compatible with either model of composition. Instead, the major difference between both models lies in whether the activation of conceptual features is necessary in order for composition to occur. Schema-based models posit that conceptual features are the elements being composed, whereas relation-based models assume that a ‘good-enough’ relational gist, lacking specific featural information, is the initial output of the combinatory process.
The fact that the complexity of a modifier’s schema affects composition in the LATL is therefore most compatible with the predictions of schema models. In the absence of a context requiring the retrieval of specific features, the relational gist hypothesis does not straightforwardly predict that the conceptual specificity of the constituents would affect LATL responses. Schema-based models further predict that combinatory processes will be disrupted by damage to the LATL; for example, it should be very difficult to comprehend a phrase in which the modifier addresses a dimension of a more specific concept , since that concept’s representation will be degraded. On the other hand, if distributional information can be used to construct a relational gist without accessing a concept’s features, patients with SD should not struggle to comprehend composed phrases. In this case, we might expect these ‘gist’ representations to reflect category-level generalizations, with patients constructing similar interpretations of, for example, red apple and red cherry. To the best of our knowledge, patient studies have not yet provided evidence about patients’ combinatory abilities that is fine-grained enough to allow us to verify these predictions.
4.2.2 Timing of Composition
Both schema-based and relation-based models are compatible with the existence of a first-pass, shallow composition process, followed by a more elaborative stage. According to schema-based models, the first stage of the combinatory process involves the retrieval of concept features followed by an elaboration stage aided by world knowledge ; therefore, combinatory activity in the LATL, peaking at 250 ms, could provide an estimate of the timing of this first stage of feature retrieval. On the other hand, the first stage of composition in the RICE model is the construction of a relational gist, and concept features are only accessed, if necessary, in a second stage. Therefore, the most straightforward way to reconcile this model with current evidence about the LATL’s combinatory responses is to either assume that combinatory activity in the LATL represents a second processing stage after a relational gist has been constructed, or that LATL activity is tangential to the composition process.
Furthermore, because the first stage of composition in the RICE model does not involve the retrieval of conceptual features, this makes the prediction that features that are irrelevant to the combined concept will never be activated at any stage of processing. Several behavioral experiments have been conducted to address this prediction by investigating the accessibility of emergent and deleted features at various points during composition. Early evidence suggested that phrasal features were actually accessible faster or at the same time as the features of the individual constituents (Gagné and Murphy 1996; Glucksberg and Estes 2000; Hampton and Springer 1989; Potter and Faulconer 1979). For example, Springer and Murphy (1992) found that subjects were faster at evaluating the truth of a sentence like boiled celery is crispy than boiled celery is green. At first glance, these results are compatible with the predictions of the RICE model .
However, these early experiments measured relatively slow response times (around one second), and therefore may have primarily reflected late-stage reasoning processes. When McElree et al. (2006) used a speed-accuracy tradeoff task to examine the online accessibility of noun and phrasal features, they showed that noun features (water pistols have triggers) were verified more accurately than emergent features (water pistols are harmless) at early stages of processing. Importantly, subjects were also slower to reject deleted features (water pistols are dangerous), suggesting that irrelevant noun features are retrieved during the combinatory process. Furthermore, Swinney et al. (2007) used a cross-modal priming task to confirm that deleted features (peeled banana-yellow) are primed during composition, and more quickly than emergent features (peeled banana-white).
These results suggest that irrelevant noun features (e.g. bananas are yellow) are in fact activated during composition, contradicting the predictions of relation-based models . Furthermore, phrasal features (e.g. peeled bananas are white) emerged relatively rapidly, in the absence of explicit pragmatic demands. This suggests that at least some phrasal features are an automatic outcome of the composition process, though they emerge after noun features have been retrieved.
In sum, behavioral and neurophysiological evidence suggest that constituent features are retrieved very rapidly, at or before 250 ms after the onset of composing word. This is followed by the retrieval of features of the composed phrase, a process that may still be ongoing at around 600 ms (Molinaro et al. 2012). Therefore, current evidence supports a two-stage model of conceptual combination. First, at least some of the features of both constituents are activated. This feature activation may be guided by an existing context, and might also be guided by statistical information about the semantic category of the constituents. Then, the modifier’s feature modifies the representation of the head concept , leading to the emergence of new phrasal features and the suppression of irrelevant noun features. This can be followed by a further stage of explicit reasoning processes, possibly only to the extent that this is necessary in the comprehension context (Hampton 1987 ; Murphy 1988, 1990). Of course, composed phrases are often encountered in the context of a phrase or paragraph, in which case contextual information may be available prior to the start of the composition process.
Though further investigation is necessary to determine precisely how phrasal features are retrieved, and how contextual and world knowledge information guide retrieval, the fact that irrelevant features are retrieved during the composition process is more compatible with schema-based models than with relation-based models, though it remains unclear whether these irrelevant features are retrieved in the LATL.
5 Conclusions and Future Directions
In this chapter, we have laid out the general predictions and assumptions of schema and relation-based models of conceptual combination. Schema-based models argue that composition involves the activation of a both constituents’ feature schemata and the modification of the head’s schema by a feature of the modifier, whereas relation-based models focus on the importance of distributional information in guiding the interpretation of a composed concept.
The fact that LATL combinatory responses take place mostly on the head, after both feature representations can be accessed, and are sensitive to the conceptual specificity of the composing constituents provides preliminary evidence more compatible with the predictions of schema-based models than with the predictions of relation-based models. Schema-based models can be combined with the semantic hub model to predict that the LATL is the locus of feature retrieval and of schema modification , though it is likely that this latter process involves an interplay between the LATL and other higher-order regions, such as the LIFG (Thompson-Schill et al. 1997, 1999) and possibly the angular gyrus (Molinaro et al. 2015; Price et al. 2015), particularly if world knowledge and contextual information can be used to guide the composition process.
Furthermore, schema-based models make the following testable predictions about the LATL as the neural center of composition: (i) that the specific features activated for the composed constituents should vary to some degree depending on the surrounding context and possibly on distributional information about the constituents, (ii) that the difficulty of integrating the modifier’s feature into the head’s schema will affect the amplitude or timing of combinatory responses, (iii) that supporting contextual information should mitigate these effects, and (iv) that phrasal features will be retrieved later in composition. Equipped with these predictions, we can now guide our investigation of the LATL in order to construct a detailed model of its combinatory role and its relationships to other language regions. Of course, we do not have enough evidence to rule out relation-based models entirely, and therefore should further investigate the role of distributional information on LATL responses.
In this review, we have focused exclusively on theories of modification, restricted to the composition of adjective-noun and noun-noun phrases. In light of evidence that the LATL shows similar combinatory responses across composition types (Westerlund et al. 2015), it is important to determine whether we can extend current psychological models of composition to include other composition types.
While this challenge is beyond the scope of this chapter, we do note that Bornkessel-Schlesewsky and Schlesewsky (2013) have advanced a general compositional model in which all words have an ‘actor-event schema’, which focuses on actors and actions. For example, an actor-event schema for paint might include the typical actor (humans) as well as the typical actions performed around it. This idea is similar in intent to an idea put forth by Wisniewski (1997) that concept schemas should include ‘scenarios’ corresponding to verbs describing actions or events relevant to the concept. These schemata are then composed in much that same manner as modified phrases, with the head’s schema being altered by the information it is composed with. For example, in a phrase like the doctor paints, the actor dimension would be filled with the subject doctor. Bornkessel-Schlesewsky and Schlesewsky (2013) propose that these general schemas are combined in the LATL, and therefore provide a possible first step towards investigating the composition of other types of concepts than simply adjectives and nouns .
References
Barclay, J. R., Bransford, J. D., Franks, J. J., McCarrell, N. S., & Nitsch, K. (1974). Comprehension and semantic flexibility. Journal of Verbal Learning and Verbal Behavior, 13(4), 471–481.
Baron, S. G., & Osherson, D. (2011). Evidence for conceptual combination in the left anterior temporal lobe. NeuroImage, 55, 1847–1852.
Baron, S. G., Thompson-Schill, S. L., Weber, M., & Osherson, D. (2010). An early stage of conceptual combination: Superimposition of constituent concepts in left anterolateral temporal lobe. Cognitive Neuroscience, 1(1), 44–51.
Barsalou, L. W. (1982). Context-independent and context-dependent information in concepts. Memory & Cognition, 10(1), 82–93.
Bemis, D. K., & Pylkkänen, L. (2011). Simple composition: A magnetoencephalography investigation into the comprehension of minimal linguistic phrases. The Journal of Neuroscience, 31(8), 2801.
Bemis, D. K., & Pylkkänen, L. (2013a). Basic linguistic composition recruits the left anterior temporal lobe and left angular gyrus during both listening and reading. Cerebral Cortex, 23(8), 1859–1873. doi:10.1093/cercor/bhs170.
Bemis, D. K., & Pylkkänen, L. (2013b). Combination across domains: An MEG investigation into the relationship between mathematical, pictorial, and linguistic processing. Frontiers in psychology, 3.
Binder, J. R., Desai, R. H., Graves, W. W., & Conant, L. L. (2009). Where is the semantic system? A critical review and meta-analysis of 120 functional neuroimaging studies. (1460–2199 (Electronic)).
Blanco-Elorrieta, E., & Pylkkänen, L. (2016). Composition of complex numbers: Delineating the computational role of the left anterior temporal lobe. NeuroImage, 124, 194–203.
Bornkessel-Schlesewsky, I., & Schlesewsky, M. (2013). Reconciling time, space and function: A new dorsal–ventral stream model of sentence comprehension. Brain and Language, 125(1), 60–76.
Bottini, G., Corcoran, R., Sterzi, R., Paulesu, E., Schenone, P., Scarpa, P., et al. (1994). The role of the right hemisphere in the interpretation of figurative aspects of language: A positron emission tomography activation study. Brain, 117(6), 1241.
Brambati, S., Rankin, K., Narvid, J., Seeley, W., Dean, D., Rosen, H., et al. (2009). Atrophy progression in semantic dementia with asymmetric temporal involvement: A tensor-based morphometry study. Neurobiology of Aging, 30(1), 103–111.
Brennan, J., Nir, Y., Hasson, U., Malach, R., Heeger, D. J., & Pylkkänen, L. (2010). Syntactic structure building in the anterior temporal lobe during natural story listening. Brain and Language.
Brennan, J., & Pylkkänen, L. (2012). The time-course and spatial distribution of brain activity associated with sentence processing. NeuroImage, 60(2), 1139–1148. doi:10.1016/j.neuroimage.2012.01.030.
Catani, M., & De Schotten, M. T. (2008). A diffusion tensor imaging tractography atlas for virtual in vivo dissections. Cortex, 44(8), 1105–1132.
Chao, L. L., Haxby, J. V., & Martin, A. (1999). Attribute-based neural substrates in temporal cortex for perceiving and knowing about objects. Nature Neuroscience, 2(10), 913–919.
Cohen, B., & Murphy, G. L. (1984). Models of concepts. Cognitive Science, 8(1), 27–58.
Connolly, A. C., Fodor, J. A., Gleitman, L. R., & Gleitman, H. (2007). Why stereotypes don’t even make good defaults. Cognition, 103(1), 1–22.
Cotelli, M., Borroni, B., Manenti, R., Ginex, V., Calabria, M., Moro, A., et al. (2007). Universal grammar in the frontotemporal dementia spectrum: Evidence of a selective disorder in the corticobasal degeneration syndrome. Neuropsychologia, 45(13), 3015–3023.
Crinion, J. T., Lambon Ralph, M. A., Warburton, E. A., Howard, D., & Wise, R. J. (2003). Temporal lobe regions engaged during normal speech comprehension. Brain, 126(5), 1193–1201.
Damasio, H., Grabowski, T. J., Tranel, D., Hichwa, R. D., & Damasio, A. R. (1996). A neural basis for lexical retrieval. Nature, 380(6574), 499–505.
Damasio, H., Tranel, D., Grabowski, T., Adolphs, R., & Damasio, A. (2004). Neural systems behind word and concept retrieval. Cognition, 92(1–2), 179–229. doi:10.1016/j.cognition.2002.07.001.
Del Prato, P., & Pylkkänen, L. (2014). MEG evidence for conceptual combination but not numeral quantification in the left anterior temporal lobe during language production. Language Sciences, 5, 524.
Devereux, B., & Costello, F. (2005). Investigating the relations used in conceptual combination. Artificial Intelligence Review, 24(3), 489–515.
Downing, P. (1977). On the creation and use of English compound nouns. Language, 810–842.
Fan, L., Wang, J., Zhang, Y., Han, W., Yu, C., & Jiang, T. (2014). Connectivity-based parcellation of the human temporal pole using diffusion tensor imaging. Cerebral Cortex, 24, 3365–3378. doi:10.1093/cercor/bht196.
Ferreira, F., Bailey, K. G., & Ferraro, V. (2002). Good-enough representations in language comprehension. Current Directions in Psychological Science, 11(1), 11–15.
Ferreira, F., Christianson, K., & Hollingworth, A. (2001). Misinterpretations of garden-path sentences: Implications for models of sentence processing and reanalysis. Journal of Psycholinguistic Research, 30(1), 3–20.
Ferreira, F., & Patson, N. D. (2007). The ‘good enough’ approach to language comprehension. Language and Linguistics Compass, 1(1–2), 71–83.
Friederici, A. D., Meyer, M., & Von Cramon, D. Y. (2000). Auditory language comprehension: An event-related fMRI study on the processing of syntactic and lexical information. Brain and Language, 74(2), 289–300.
Friederici, A. D., Rüschemeyer, S. A., Hahne, A., & Fiebach, C. J. (2003). The role of left inferior frontal and superior temporal cortex in sentence comprehension: Localizing syntactic and semantic processes. Cerebral Cortex, 13(2), 170–177.
Gagné, C. L. (2001). Relation and lexical priming during the interpretation of noun–noun combinations. Journal of Experimental Psychology: Learning, Memory, and Cognition, 27(1), 236.
Gagné, C. L., & Murphy, G. L. (1996). Influence of discourse context on feature availability in conceptual combination. Discourse Processes, 22(1), 79–101.
Gagné, C. L., & Shoben, E. J. (1997). Influence of thematic relations on the comprehension of modifier–noun combinations. Journal of Experimental Psychology: Learning, Memory, and Cognition, 23(1), 71.
Gagné, C. L., & Shoben, E. J. (2002). Priming relations in ambiguous noun-noun combinations. Memory & Cognition, 30(4), 637–646.
Gagné, C. L., & Spalding, T. L. (2011). Inferential processing and meta-knowledge as the bases for property inclusion in combined concepts. Journal of Memory and Language, 65(2), 176–192.
Gagné, C. L., & Spalding, T. L. (2014). Subcategorisation, not uncertainty, drives the modification effect.
Gainotti, G., Barbier, A., & Marra, C. (2003). Slowly progressive defect in recognition of familiar people in a patient with right anterior temporal atrophy. Brain, 126(4), 792.
Gainotti, G. (2006). Anatomical functional and cognitive determinants of semantic memory disorders. Neuroscience and Biobehavioral Reviews, 30(5), 577–594.
Gainotti, G. (2007). Different patterns of famous people recognition disorders in patients with right and left anterior temporal lesions: A systematic review. Neuropsychologia, 45(8), 1591–1607.
Gainotti, G. (2011). The format of conceptual representations disrupted in semantic dementia: A position paper. Cortex, 48(5), 521–529.
Garrard, P., & Carroll, E. (2006). Lost in semantic space: A multi-modal, non-verbal assessment of feature knowledge in semantic dementia. Brain, 129(5), 1152–1163.
Garrard, P., & Hodges, J. (2000). Semantic dementia: Clinical, radiological and pathological perspectives. Journal of Neurology, 247(6), 409–422.
Gleitman, L. R., & Gleitman, H. (1970). Phrase and paraphrase: Some innovative uses of language. New York: Norton.
Gloor, P. (1997). The temporal lobe and limbic system. USA: Oxford University Press.
Glucksberg, S., & Estes, A. (2000). Feature accessibility in conceptual combination: Effects of context-induced relevance. Psychonomic Bulletin & Review, 7(3), 510–515.
Gorno-Tempini, M. L., Rankin, K. P., Woolley, J. D., Rosen, H. J., Phengrasamy, L., & Miller, B. L. (2004). Cognitive and behavioral profile in a case of right anterior temporal lobe neurodegeneration. Cortex, 40(4–5), 631–644.
Gorno-Tempini, M. L., Price, C., Josephs, O., Vandenberghe, R., Cappa, S., Kapur, N., et al. (1998). The neural systems sustaining face and proper name processing. Brain, 121(11), 2103–2118.
Grabowski, T. J., Damasio, H., Tranel, D., Ponto, L. L. B., Hichwa, R. D., & Damasio, A. R. (2001). A role for left temporal pole in the retrieval of words for unique entities. Human Brain Mapping, 13(4), 199–212.
Grice, H. P. (1975). Logic and conversation. In P. Cole & J. L. Morgan (Eds.), Syntax and semantics (Vol. 3: Speech acts, pp. 41–58). New York: Academic Press.
Grossman, M., Rhee, J., & Moore, P. (2005). Sentence processing in frontotemporal dementia. Cortex, 41(6), 764–777.
Hampton, J. A. (1987). Inheritance of attributes in natural concept conjunctions. Memory & Cognition, 15(1), 55–71.
Hampton, J. A. (1997). Conceptual combination. In K. Lamberts & D. Shanks (Eds.), Knowledge, concepts, and categories (pp. 133–159). Cambridge, MA: MIT Press.
Hampton, J. A., Passanisi, A., & Jönsson, M. L. (2011). The modifier effect and property mutability. Journal of Memory and Language, 64(3), 233–248.
Hampton, J. A., & Springer, K. (1989). Long speeches are boring: Verifying properties of conjunctive concepts. Paper presented at the 30th meeting of the Psychonomic Society, Atlanta.
Heim, I., & Kratzer, A. (1998). Semantics in generative grammar (Vol. 13). Wiley-Blackwell.
Hodges, J. R., Graham, N., & Patterson, K. (1995). Charting the progression in semantic dementia: Implications for the organization of semantic memory. Semantic Knowledge and Semantic Representations, 3(3–4), 463–495.
Hodges, J. R., Patterson, K., Oxbury, S., & Funnell, E. (1992). Progressive fluent aphasia with temporal lobe atrophy. Brain, 115(6), 1783–1806.
Hodges, J. R., & Patterson, K. (2007). Semantic dementia: A unique clinicopathological syndrome. The Lancet Neurology, 6(11), 1004–1014.
Humphries, C., Binder, J. R., Medler, D. A., & Liebenthal, E. (2006). Syntactic and semantic modulation of neural activity during auditory sentence comprehension. Journal of Cognitive Neuroscience, 18(4), 665–679.
Humphries, C., Binder, J. R., Medler, D. A., & Liebenthal, E. (2007). Time course of semantic processes during sentence comprehension: An fMRI study. NeuroImage, 36(3), 924–932. doi:10.1016/j.neuroimage.2007.03.059.
Humphries, C., Love, T., Swinney, D., & Hickok, G. (2005). Response of anterior temporal cortex to syntactic and prosodic manipulations during sentence processing. Human Brain Mapping, 26(2), 128–138.
Humphries, C., Willard, K., Buchsbaum, B., & Hickok, G. (2001). Role of anterior temporal cortex in auditory sentence comprehension: An fMRI study. NeuroReport, 12(8), 1749.
Hurley, R. S., Bonakdarpour, B., Wang, X., & Mesulam, M.-M. (2014). Asymmetric connectivity between the anterior temporal lobe and the language network.
Jefferies, E. (2013). The neural basis of semantic cognition: Converging evidence from neuropsychology, neuroimaging and TMS. Cortex, 49(3), 611–625.
Jönsson, M. L., & Hampton, J. A. (2012). The modifier effect in within-category induction: Default inheritance in complex noun phrases. Language and Cognitive Processes, 27(1), 90–116.
Kapur, N., Barker, S., Burrows, E., Ellison, D., Brice, J., Illis, L., et al. (1994). Herpes simplex encephalitis: Long term magnetic resonance imaging and neuropsychological profile. Journal of Neurology, Neurosurgery and Psychiatry, 57(11), 1334–1342.
Kho, K. H., Indefrey, P., Hagoort, P., Van Veelen, C., Van Rijen, P., & Ramsey, N. (2008). Unimpaired sentence comprehension after anterior temporal cortex resection. Neuropsychologia, 46(4), 1170–1178.
Lambon Ralph, M. A., Sage, K., Jones, R. W., & Mayberry, E. J. (2010). Coherent concepts are computed in the anterior temporal lobes. Proceedings of the National Academy of Sciences, 107(6), 2717.
Levi, J. N. (1978). The syntax and semantics of complex nominals. New York: Academic Press.
Maguire, P., Maguire, R., & Cater, A. W. S. (2010a). The influence of interactional semantic patterns on the interpretation of noun–noun compounds. Journal of Experimental Psychology: Learning, Memory, and Cognition, 36(2), 288.
Maguire, P., Wisniewski, E. J., & Storms, G. (2010b). A corpus study of semantic patterns in compounding. Corpus Linguistics and Linguistic Theory, 6(1), 49–73.
Martin, A., & Chao, L. L. (2001). Semantic memory and the brain: Structure and processes. Current Opinion in Neurobiology, 11(2), 194–201.
Mazoyer, B. M., Tzourio, N., Frak, V., Syrota, A., Murayama, N., Levrier, O., et al. (1993). The cortical representation of speech. Journal of Cognitive Neuroscience, 5(4), 467–479.
McElree, B., Murphy, G. L., & Ochoa, T. (2006). Time course of retrieving conceptual information: A speed-accuracy trade-off study. Psychonomic Bulletin & Review, 13(5), 848–853.
Medin, D. L., & Shoben, E. J. (1988). Context and structure in conceptual combination. Cognitive Psychology, 20(2), 158–190.
Molinaro, N., Carreiras, M., & Duñabeitia, J. A. (2012). Semantic combinatorial processing of non-anomalous expressions. NeuroImage, 59(4), 3488–3501.
Molinaro, N., Paz-Alonso, P. M., Duñabeitia, J. A., & Carreiras, M. (2015). Combinatorial semantics strengthens angular-anterior temporal coupling. Cortex.
Mummery, C., Patterson, K., Price, C., Ashburner, J., Frackowiak, R., & Hodges, J. R. (2000). A voxel-based morphometry study of semantic dementia: Relationship between temporal lobe atrophy and semantic memory. Annals of Neurology, 47(1), 36–45.
Mummery, C., Patterson, K., Wise, R., Vandenbergh, R., Price, C., & Hodges, J. (1999). Disrupted temporal lobe connections in semantic dementia. Brain, 122(1), 61.
Murphy, G. L. (1988). Comprehending complex concepts. Cognitive Science, 12(4), 529–562.
Murphy, G. L. (1990). Noun phrase interpretation and conceptual combination. Journal of Memory and Language, 29(3), 259–288.
Murphy, G. L. (2002). The big book of concepts. The MIT Press.
Noppeney, U., Price, C. J., Duncan, J. S., & Koepp, M. J. (2005). Reading skills after left anterior temporal lobe resection: An fMRI study. Brain, 128(6), 1377–1385.
Olson, I. R., Plotzker, A., & Ezzyat, Y. (2007). The enigmatic temporal pole: A review of findings on social and emotional processing. Brain, 130(7), 1718–1731.
Pallier, C., Devauchelle, A. D., & Dehaene, S. (2011). Cortical representation of the constituent structure of sentences. Proceedings of the National Academy of Sciences, 108(6), 2522.
Patterson, K., Lambon Ralph, M. A., Jefferies, E., Woollams, A., Jones, R., Hodges, J. R., et al. (2006). “Presemantic” cognition in semantic dementia: Six deficits in search of an explanation. Journal of Cognitive Neuroscience, 18(2), 169–183.
Patterson, K., Nestor, P. J., & Rogers, T. T. (2007). Where do you know what you know? The representation of semantic knowledge in the human brain. Nature Reviews Neuroscience, 8(12), 976–987.
Potter, M. C., & Faulconer, B. A. (1979). Understanding noun phrases. Journal of Verbal Learning and Verbal Behavior, 18(5), 509–521.
Price, A. R., Bonner, M. F., Peelle, J. E., & Grossman, M. (2015). Converging evidence for the neuroanatomic basis of combinatorial semantics in the angular gyrus. The Journal of Neuroscience, 35(7), 3276–3284.
Pylkkänen, L., Bemis, D. K., & Blanco Elorrieta, E. (2014). Building phrases in language production: An MEG study of simple composition. Cognition, 133(2), 371–384.
Rogalsky, C., & Hickok, G. (2009). Selective attention to semantic and syntactic features modulates sentence processing networks in anterior temporal cortex. Cerebral Cortex, 19(4), 786.
Rogers, T. T., Lambon Ralph, M. A., Garrard, P., Bozeat, S., McClelland, J. L., Hodges, J. R., et al. (2004). Structure and deterioration of semantic memory: A neuropsychological and computational investigation. Psychological Review, 111(1), 205.
Rogers, T. T., & McClelland, J. L. (2004). Semantic cognition: A parallel distributed processing approach. MIT press.
Rogers, T. T., & Patterson, K. (2007). Object categorization: Reversals and explanations of the basic-level advantage. Journal of Experimental Psychology: General, 136(3), 451.
Ross, L. A., & Olson, I. R. (2012). What’s unique about unique entities? An fMRI investigation of the semantics of famous faces and landmarks. Cerebral Cortex, 22(9), 2005–2015.
Rumelhart, D. (1980). Schemata: The building blocks of cognition. In R. J. Spiro, B. C. Bruce, & W. F. Brewer (Eds.), Theoretical issues in reading comprehension. HIllsdale, NJ: Erlbaum.
Sanjuán, A., Hope, T. M., Jones, Ō. P., Prejawa, S., Oberhuber, M., Guerin, J., Price, C. J. (2014). Dissociating the semantic function of two neighbouring subregions in the left lateral anterior temporal lobe. Neuropsychologia.
Scott, S. K., Blank, C. C., Rosen, S., & Wise, R. J. (2000). Identification of a pathway for intelligible speech in the left temporal lobe. Brain, 123(12), 2400–2406.
Seco, N., Veale, T., & Hayes, J. (2004). An intrinsic information content metric for semantic similarity in WordNet. Paper presented at the ECAI.
Shallice, T., & Cooper, R. P. (2013). Is there a semantic system for abstract words? Frontiers in Human Neuroscience, 7, 175. http://doi.org/10.3389/fnhum.2013.00175.
Sergent, J., & Signoret, J. L. (1992). Functional and anatomical decomposition of face processing: Evidence from prosopagnosia and PET study of normal subjects. Philosophical Transactions of the Royal Society London: Series B, Biological Sciences, 335, 55–62.
Simmons, W. K., Reddish, M., Bellgowan, P. S. F., & Martin, A. (2010). The selectivity and functional connectivity of the anterior temporal lobes. Cerebral Cortex, 20(4), 813–825. doi:10.1093/cercor/bhp149.
Smith, E. E., Osherson, D. N., Rips, L. J., & Keane, M. (1988). Combining prototypes: A selective modification model. Cognitive Science, 12(4), 485–527. doi:10.1207/s15516709cog1204_1.
Snowden, J. S., Goulding, P., & Neary, D. (1989). Semantic dementia: A form of circumscribed cerebral atrophy. Behavioural Neurology.
Spalding, T. L., & Gagné, C. L. (2014). Property attribution in combined concepts.
Spalding, T. L., Gagné, C. L., Mullaly, A. C., & Ji, H. (2010). Relation-based interpretation of noun-noun phrases: A new theoretical approach. Linguistische Berichte Sonderheft, 17, 283–315.
Springer, K., & Murphy, G. L. (1992). Feature availability in conceptual combination. Psychological Science, 3(2), 111–117.
Stowe, L. A., Broere, C. A. J., Paans, A. M. J., Wijers, A. A., Mulder, G., Vaalburg, W., et al. (1998). Localizing components of a complex task: Sentence processing and working memory. NeuroReport, 9(13), 2995.
Swinney, D., Love, T., Walenski, M., & Smith, E. E. (2007). Conceptual combination during sentence comprehension evidence for compositional processes. Psychological Science, 18(5), 397–400.
Tabossi, P., & Johnson-Laird, P. (1980). Linguistic context and the priming of semantic information. The Quarterly Journal of Experimental Psychology, 32(4), 595–603.
Thompson-Schill, S. L., D’Esposito, M., & Kan, I. P. (1999). Effects of repetition and competition on activity in left prefrontal cortex during word generation. Neuron, 23(3), 513–522.
Thompson-Schill, S. L., D’Esposito, M., Aguirre, G. K., & Farah, M. J. (1997). Role of left inferior prefrontal cortex in retrieval of semantic knowledge: A reevaluation. Proceedings of the National Academy of Sciences, 94(26), 14792–14797.
van Jaarsveld, H., & Drašković, I. (2003). Effects of collocational restrictions in the interpretation of adjective-noun combinations. Language and Cognitive Processes, 18(1), 47–60.
Vandenberghe, R., Nobre, A., & Price, C. (2002). The response of left temporal cortex to sentences. Journal of Cognitive Neuroscience, 14(4), 550–560.
Visser, M., Jefferies, E., & Lambon Ralph, M. A. (2010). Semantic processing in the anterior temporal lobes: A meta-analysis of the functional neuroimaging literature. Journal of Cognitive Neuroscience, 22(6), 1083–1094.
Visser, M., & Lambon Ralph, M. A. (2011). Differential contributions of bilateral ventral anterior temporal lobe and left anterior superior temporal gyrus to semantic processes. Journal of Cognitive Neuroscience, 23(10), 3121–3131.
Visser, M., Jefferies, E., Embleton, K. V., & Lambon Ralph, M. A. (2012). Both the middle temporal gyrus and the ventral anterior temporal area are crucial for multimodal semantic processing: Distortion-corrected fMRI evidence for a double gradient of information convergence in the temporal lobes. Journal of Cognitive Neuroscience, 24(8), 1766–1778.
Westerlund, M., Kastner, I., Al Kaabi, M., & Pylkkänen, L. (2015). The LATL as locus of composition: MEG evidence from English and Arabic. Brain and Language, 141, 124–134.
Westerlund, M., & Pylkkänen, L. (2014). The role of the left anterior temporal lobe in semantic composition vs. semantic memory. Neuropsychologia, 57, 59–70.
Wilson, S. M., Galantucci, S., Tartaglia, M. C., & Gorno-Tempini, M. L. (2012). The neural basis of syntactic deficits in primary progressive aphasia. Brain and Language, 122(3), 190–198.
Wisniewski, E. J. (1997). When concepts combine. Psychonomic Bulletin & Review, 4(2), 167–183.
Xu, J., Kemeny, S., Park, G., Frattali, C., & Braun, A. (2005). Language in context: Emergent features of word, sentence, and narrative comprehension. NeuroImage, 25(3), 1002–1015.
Xu, X., & Ran, B. (2011). Familarity, abstractness, and the interpretive strategies of noun-noun combinations. Cognitive Sciences, 5, 125–138.
Zahn, R., Moll, J., Krueger, F., Huey, E. D., Garrido, G., & Grafman, J. (2007). Social concepts are represented in the superior anterior temporal cortex. Proceedings of the National Academy of Sciences, 104(15), 6430–6435.
Zhang, L., & Pylkkänen, L. (2015). The interplay of composition and concept specificity in the left anterior temporal lobe: An MEG study. NeuroImage, 111, 228–240.
Acknowledgements
The writing of this chapter and the work reviewed in it were supported by the National Science and Engineering Research Council of Canada (M.W.), the Fonds de recherche du Québec- Nature et technologies (M.W.), the National Science Foundation Grants BCS-0545186 and BCS-1221723 (L.P.) and grant G1001 from the NYUAD Institute, New York University Abu Dhabi (L.P.).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Open Access This chapter is licensed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license and indicate if changes were made.
The images or other third party material in this chapter are included in the chapter’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the chapter’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder.
Copyright information
© 2017 The Author(s)
About this chapter
Cite this chapter
Westerlund, M., Pylkkänen, L. (2017). How Does the Left Anterior Temporal Lobe Contribute to Conceptual Combination? Interdisciplinary Perspectives. In: Hampton, J., Winter, Y. (eds) Compositionality and Concepts in Linguistics and Psychology. Language, Cognition, and Mind, vol 3. Springer, Cham. https://doi.org/10.1007/978-3-319-45977-6_11
Download citation
DOI: https://doi.org/10.1007/978-3-319-45977-6_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-45975-2
Online ISBN: 978-3-319-45977-6
eBook Packages: Social SciencesSocial Sciences (R0)