
Abstract
In this work, an Artificial Neural Network (ANN) is developed to improve the performance of Space Vector Modulation (SVM) based Direct Torque Controlled (DTC) Induction Motor (IM) drive. The ANN control algorithm based on Scaled Conjugate Gradient (SCG) method is developed. The algorithm is tested on MATLAB Simulink platform. Results show smooth steady state operation as well as fast and dynamic transient performance. This is due to the SCG training algorithm of ANN which has the benchmarked performance against the standard Back-propagation (BP) algorithm. BP uses gradient descent optimization theory which has user selected parameters; learning rate and momentum constant. The network is trained offline and has fixed parameters. This leads to extra control effort and demands for online tuning of the parameters. SCG algorithm tunes these parameters with the use of second order approximation. Additionally, it takes less learning iterations and hence results in faster learning. Robustness to parameter variations and disturbances is the basic advantage of ANN, thus effectively controlling inherently non linear IM.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
The Direct Torque Control (DTC) [1] and Space Vector Modulated-Direct Torque Control (SVM-DTC) [2, 3] are the latest research technologies for the VSI fed cage IMs. Both, being the special cases of vector control, have the fast and dynamic transient responses. The former has PWM-free operation and involves no coordinate transformation but 20–30 % steady state torque ripple; whereas the later has SVM based PWM, with coordinate transformation but less torque ripple upto 5–7 %. The research in SVM-DTC controlled IM drives is further advanced with respect to -
-
Sensorless operation [4].
-
Generation of reference stator voltage control vectors [5].
-
Stator resistance compensation at low speeds [6].
Modern control techniques like Sliding Mode Control (SMC) and intelligent control [7, 8] are used to address the three issues mentioned above. Performances of various methods are compared [9] for control vector generation.
Out of the methods reported, PI has known demerits. An approach proposed in [10] gives excellent torque response and also very low torque distortions in static state, but has complex fuzzy structure. The chattering behavior of SVM can be eliminated by using ANN [11]. Apart from variety of techniques in DTC, SVM-DTC techniques based on neuro-fuzzy logic are also discussed and compared with the conventional motor control schemes [12]. Intelligent control has benefits of model-free control and hence it is robust [13]. With these advancements in intelligent control techniques, ANN is not restricted to be used as separate controller. Rather, it can be combined with other techniques to enhance the performance of the drive as in [14], where Field Oriented Control (FOC) and DTC [15] are combined to make a hybrid network and both the schemes FOC and DTC are mapped using two different ANNs. In [16], ANN is reported in control voltage vector loop. It can be seen that the ripple in torque with ANN-DTC control is very less as compared to conventional DTC at the same operating conditions [17]. In case of ANN based control, Resilient Backpropogation (RBP) and Levenberg-Marquardt (LM) [18] algorithms are very popular.
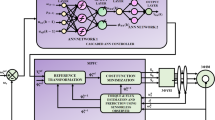
This paper presents another approach for training the ANN for the Space Vector Modulated- Direct Torque Control (SVM-DTC) based induction motor drive. The training algorithm used is Scaled Conjugate Gradient (SCG). The basic idea in this algorithm is to combine the model-trust region approach (used in the Levenberg-Marquardt algorithm), with the conjugate gradient approach [19] (Fig. 1).

ANN based SVM-DTC Scheme
2 Artificial Neural Network
Artificial Neural Networks (ANNs) have capability of recognizing the non-linear functions of their inputs. They can represent a non-linear system to the nearest possible approximation. Hence, in non-linear systems, which are difficult to control, the performance of conventional PI controller, in conditions like change in loads, disturbance and uncertainties can be improved by ANN [13].
Basically, it consist of neurons to represent inputs and outputs variables as well as intermediate layers which are interconnected via weights. The performance of ANNs depend upon the type of algorithm used, the number of neurons in the hidden layer, learning rate and the type of member function implied.
Various performance determining factors of ANNs are:
-
Mean Square Error (MSE)
-
Number of epochs
-
Training Time
-
Validation checks
-
Gradient
2.1 Resilient Backpropagation (RBP) Algorithm
Resilient Backpropagation (RBP) is most suitable for pattern recognition problems. It utilizes the sign of derivative for the direction of weight update; that is, the magnitude of the derivative does not affect the weight-updating process. This eliminates the harmful effects of the magnitude of derivatives.
It generally converges much faster than other algorithms. In MATLAB, ‘trainrp’ function is used to train network by RBP algorithm.
The use of constant step size and involvement of a momentum term makes RBP less robust and more parameter dependent.
2.2 Scaled Conjugate Gradient (SCG) Algorithm
The scaled conjugate gradient (SCG) algorithm, developed by Moller [Moll93], is based on conjugate directions, but this algorithm does not perform a line search at each iteration unlike other conjugate gradient algorithms which require a line search at each iteration making the system computationally expensive. SCG was designed to avoid the time-consuming line search.
‘trainscg’ in MATLAB is a network training function that updates weight and bias values according to the scaled conjugate gradient method. It can train any network as long as its weight, net input, and transfer functions have derivative functions. In SCG algorithm, the step size is a function of quadratic approximation of the error function which makes it more robust and independent of user defined parameters.
The step size is estimating using different approach. The second order term is calculated as,
where, \(\lambda _{k}\) is a scalar and is adjusted each time according to the sign of \(\delta _{k}\).
The step size,
where, \(\bar{w}\) is weight vector in space \(R^{n}\),
\(E(\bar{w})\) is the global error function,
\({E}'(\bar{w})\) is the gradient of error,
\({E}'_{qw}(\bar{y_{1}})\) is the quadratic approximation of error function,
\(\bar{p}_{1},\bar{p}_{2}....\bar{p}_{k}\) be the set of non-zero weight vectors.
\(\lambda _{k}\) is to be updated such that,
If \(\varDelta _{k}>0.75\), then \(\lambda _{k}\) = \(\lambda _{k}/4\)
If \(\varDelta _{k}<0.25\), then \(\lambda _{k}\) = \(\lambda _{k}+\frac{\delta _{k}(1-\varDelta _{k})}{{\bar{\left| p_{k}\right| ^{2}}}}\)
where, \(\varDelta _{k}\) is comparison parameter and is given by,
Initially the values are set as, \(0<\sigma \le 10^{-4}\), \(0<\lambda _{l} \le 10^{-6}\) and \(\bar{\lambda _{l}}=0\).
Training stops when any of these conditions occurs:
-
The maximum number of epochs is reached.
-
The maximum amount of time is exceeded.
-
Performance is minimized to the goal.
-
The performance gradient falls below min-grad.
-
Validation performance has increased more than max-fail times since the last time it decreased (when using validation)[20].
3 Simulation Results
A three phase induction motor with frequency = 50 Hz and power rating 3.5 kW is used. The various machine parameters are given as,
-
Stator resistance (rs) = 7.83 \(\varOmega \)
-
Rotor resistance (rr) = 7.55 \(\varOmega \)
-
Stator inductance (Ls) = 0.4751 H
-
Rotor inductance (Lr) = 0.4751 H
-
Mutual inductance (Lm) = 0.4535 H
-
No. of Poles (P) = 4
-
Inertia (J) = 0.013 kg-\(m^{2}\)
Torque of 12 Nm is applied at 0.5 s. A comparison has been done between the two algorithms Resilient Backpropogation (RBP) and Scaled Conjugate Gradient (SCG) method.
SCG has been tried for various cases. Each time the conditions were varied and results are verified (Table 1).

Performance Plot for the two algorithms
-
Case I The reference speed is kept to be zero.
-
Case II A sinusoidal disturbance of amplitude 0.001 and high frequency is added in the torque and flux errors.
-
Case III The stator resistance is increased to 150 % .
-
Case IV The reference speed is kept to be 100 rad/s.
-
Case V Speed is constant and torque is changed to zero at 0.7 s.
-
Case VI Torque is constant and speed is changed from 100 rad/s to 50 rad/s at 0.8 s.
Results have been shown as a comparison between the two.

Full load torque condition for Case I

Speed for the conditions referred in Case I

Stator input current for both algorithms in Case I

Flux Circle for the two algorithms
4 Observations
It is seen from Fig. 2 that the number of epochs required for least mean square error (MSE) is 280 for RBP while only 36 for SCG. Also, it is clear from Case I that total harmonic distortion (THD) is more in case of RBP than that of SCG. Figures 4 and 5 show that there exists undershoot in both speed and current graphs for RBP unlike SCG which has smooth transients. The steady state error in case of speed, current and torque is less in case of SCG as depicted by Figs. 14, 15 and 16.

Current transients for Case II

Current transients for Case III

Stator input current for both the algorithms in Case IV

Full load torque condition for Case IV

Speed for the conditions referred in Case IV

Torque developed in Case V

Speed for the conditions referred in Case V

Stator input current for both the algorithms in Case V

Torque developed in Case VI

Speed for the conditions referred in Case VI

Stator input current for both the algorithms in Case VI

Selected stator current in Case I for both algorithms

Total harmonic distortion (THD) for RBP

Total harmonic distortion (THD) for SCG
5 Conclusion
Both the algorithms provide fast initial convergence. But, the calculations and training methods are different in both of them. Results show that the proposed controller gives better results than RBP. When the torque is applied, SCG gives more smooth transients with less peak overshoot and undershoot in case of current and speed. That is, the control effort required in SCG is comparatively less than that of RBP. Also, the total harmonic distortion and steady state errors in torque and speed appear to be less in case of SCG as compared to RBP. Though the computational efforts are more in SCG algorithm, it achieves faster learning as against RBP algorithm due to the absence of line search optimization. It is observed that the epochs for SCG are around 36 for best performance while that of RBP, they are found to be around 280 which proves the superiority of the algorithm.
This scheme can be implemented on hardware using dSPACE which produces pulses to feed Voltage Source Inverter (VSI) which in turn runs the motor. The scope of this scheme is not limited to only ANN, rather, it can be used in hybrid with some other algorithm and also with Genetic Algorithm (GA) to improve the transient response.
References
Takahashi, I., Ohmori, Y.: High-performance direct torque control of an induction motor. IEEE Trans. Ind. Appl. 25(2), 257–264 (1989)
Habetler, T.G., Profumo, F., Pastorelli, M., Tolbert, L.M.: Direct torque control of induction machines using space vector modulation. IEEE Trans. Ind. Appl. 28(5), 1045–1053 (1992)
Kang, J.-K., Sul, S.-K.: New direct torque control of induction motor for minimum torque ripple and constant switching frequency. IEEE Trans. Ind. Appl. 35(5), 1076–1082 (1999)
Lascu, C., Boldea, I., Blaabjerg, F.: A modified direct torque control for induction motor sensorless drive. IEEE Trans. Ind. Appl. 36(1), 122–130 (2000)
Lascu, C., Boldea, I.: Variable-structure direct torque control-a class of fast and robust controllers for induction machine drives. IEEE Trans. Ind. Appl. 51, 785–792 (2004)
Husain, I., Cabrera, L.A., Elbuluk, M.E.: Tuning the stator resistance of induction motors using artificial neural network. IEEE Trans. Power Electron. 12(5), 779–787 (1997)
Park, D., Kandel, A., Langholz, G.: Genetic-based new fuzzy reasoning models with application to fuzzy control. IEEE Trans. Syst. Man Cybern. 24(1), 39–47 (1994)
Grabowski, P.Z., Kazmierkowski, M.P., Bose, B.K., Blaabjerg, F.: A simple direct-torque neuro-fuzzy control of PWM-inverter-fed induction motor drive. IEEE Trans. Ind. Electron. 47(4), 863–870 (2000)
Jadhav, S.V., Srikanth, J., Chaudhari, B.N.: Intelligent controllers applied to SVM-DTC based induction motor drives: a comparative study. In: 2010 Joint International Conference on Power Electronics, Drives and Energy Systems (PEDES) & 2010 Power India, pp. 1–8 (2010)
Mir, S.A., Zinger, D.S., Elbuluk, M.E.: Fuzzy controller for inverter fed induction machines. IEEE Trans. Ind. Appl. 30(1), 78–84 (1994)
Pinto, J.O.P., et al.: A neural-network-based space-vector PWM controller for voltage-fed inverter induction motor drive. IEEE Trans. Ind. Appl. 36(6), 1628–1636 (2000)
Buja, G.S., Kazmierkowski, M.P.: Direct torque control of PWM inverter-fed AC motors-a survey. IEEE Trans. Ind. Electron. 51(4), 744–757 (2004)
Lai, Y.-S., Chen, J.-H.: A new approach to direct torque control of induction motor drives for constant inverter switching frequency and torque ripple reduction. IEEE Trans. Energy Convers. 16(3), 220–227 (2001)
Sakarung, P., Chatratana, S.: Neural network mapping of hybrid FOC-DTC induction motordrive. In: 2004 IEEE Region 10 Conference on TENCON 2004, vol. 500, pp. 467–470. IEEE (2004)
Kazmierkowski, M.P.: Control strategies for PWM rectifier/inverter-fed induction motors. In: Proceedings of the 2000 IEEE International Symposium on Industrial Electronics (ISIE 2000), vol. 1. IEEE (2000)
Jadhav, S.V., Kirankumar, J., Chaudhari, B.N.: ANN based intelligent control of induction motor drive with space vector modulated DTC. In: 2012 IEEE International Conference on Power Electronics, Drives and Energy Systems (PEDES), pp. 1–6 (2012)
Kumar, D., Thakur, I., Gupta, K.: Direct torque control for induction motor using intelligent artificial neural network technique. Int. J. Emerg. Trends Technol. Comput. Sci. (IJETTCS) 3(4), 44–50 (2014)
Gottapu, K., Prashanth, Y., Mahesh, P., Sumith, Y., et al.: Simulation of DTC IM based on PI & artificial neural network technique. Simulation 2(7) (2013)
Møller, M.F.: A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw. 6(4), 525–533 (1993)
MATLAB
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 IFIP International Federation for Information Processing
About this paper
Cite this paper
Babani, L., Jadhav, S., Chaudhari, B. (2016). Scaled Conjugate Gradient Based Adaptive ANN Control for SVM-DTC Induction Motor Drive. In: Iliadis, L., Maglogiannis, I. (eds) Artificial Intelligence Applications and Innovations. AIAI 2016. IFIP Advances in Information and Communication Technology, vol 475. Springer, Cham. https://doi.org/10.1007/978-3-319-44944-9_33
Download citation
DOI: https://doi.org/10.1007/978-3-319-44944-9_33
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-44943-2
Online ISBN: 978-3-319-44944-9
eBook Packages: Computer ScienceComputer Science (R0)