
Abstract
Traditional development methodologies that separate software design from application deployment have been replaced by approaches such as continuous delivery or DevOps, according to which deployment issues should be taken into account already at the early stages of development. This calls for the definition of new modeling and specification languages. In this paper we show how deployment can be added as a first-class citizen in the object-oriented modeling language ABS. We follow a declarative approach: programmers specify deployment constraints and a solver synthesizes ABS classes exposing methods like deploy (resp. undeploy) that executes (resp. cancels) configuration actions changing the current deployment towards a new one satisfying the programmer’s desiderata. Differently from previous works, this novel approach allows for the specification of incremental modifications, thus supporting the declarative modeling of elastic applications.
Supported by the EU projects FP7-610582 Envisage: Engineering Virtualized Services (http://www.envisage-project.eu) and H2020-644298 HyVar: Scalable Hybrid Variability for Distributed, Evolving Software Systems (http://www.hyvar-project.eu).
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Software applications deployed and executed on cloud computing infrastructures should flexibly adapt by dynamically acquiring or releasing computing resources. This is necessary to properly deliver to the final users the expected services at the expected level of quality, maintaining an optimized usage of the computing resources. For this reason, modern software systems call for novel engineering approaches that anticipate the possibility to reason about deployment already at the early stages of development.
Modeling languages like TOSCA [21], CloudML [16], and CloudMF [13] have been proposed to specify the deployment of software artifacts, but they are mainly intended to express deployment of already developed software. An integration of deployment in software modeling is still far from being obtained in the current practices. To cover this gap, in this paper we address the problem of extending the ABS (Abstract Behavioural Specification) language [2] with linguistic constructs and mechanisms to properly specify deployment. Following [9] our approach is declarative: the programmer specifies deployment constraints and a solver computes actual deployments satisfying such constraints. In previous work [10] we presented an external engine able to synthesize ABS code specifying the initial static deployment; in this paper we fully integrate this approach in the ABS language allowing for the declarative specification of the incremental upscale/downscale of the modeled application depending, e.g., on the monitored workload or the current level of resource usage.
ABS is an object-oriented modeling language with a formally defined and executable semantics. It includes a rich tool-chain supporting different kinds of analysis (like, e.g., logic-based modular verification [11], deadlock detection [15], and cost analysis [3]). Executable code can be automatically obtained from ABS specifications by means of code generation. ABS has been mainly used to model systems based on asynchronously communicating concurrent objects, distributed over Deployment Components corresponding to containers offering to objects the resources they need to properly run. For our purposes, we adopted ABS because it allows the modeling of computing resources and it has a real-time semantics reflecting the way in which objects consume resources. This makes ABS particularly suited for modeling and reasoning about deployment.
Our initial proposal for the declarative modeling of deployment into ABS [10] was based on three main pillars: (i) classes are enriched with annotations that indicate functional dependencies of objects of those classes as well as the resources they require, (ii) a separate high-level language for the declarative specification of the deployment, (iii) an engine that, based on the annotations and the programmer’s requirements, computes a fully specified deployment that minimizes the total cost of the system. The computed deployment is expressed in ABS and can be manually included in a main block.
The work in [10] had two main limitations: (i) there was no way to express incremental deployment decisions like, e.g., the need to upscale or downscale the modeled system at run-time and (ii) there was no real integration of the code synthesized by the engine in the corresponding ABS specification. In this paper we address these limitations by promoting the notion of deployment as a first-class citizen of the language. During a pre-processing phase, the new tool SmartDepl generates classes exposing the methods deploy and undeploy to upscale and downscale the system. The deployment requirements can now also reuse already deployed objects just specifying which existing objects could be used, and how they should be connected with new objects to be freshly deployed. This has been the fundamental step forward that allowed us to support incremental modification of the current deployment. Moreover, other relevant contributions of this paper are (i) a more natural high-level language for the specification of requirements that now supports universal and existential quantifiers, and (ii) the usage of the delta modules and the variability modeling features of the ABS framework [7] to automatically and safely inject the deployment instructions into the existing ABS code.
Our ABS extension and the realization of the corresponding SmartDepl tool have been driven by Fredhopper Cloud Services, an industrial case-study of the European FP7 Envisage project. The Fredhopper Cloud Services offer search and targeting facilities on a large product database to e-Commerce companies. Depending on the specific profile of an e-Commerce company Fredhopper has to decide the most appropriate customized deployment of the service. Currently, such decisions are taken manually by an operation team which decides customized, hopefully optimal, service configurations taking into account the tension among several aspects like the level of replications of critical parts of the service to ensure high availability. The operators manually perform the operations to scale up or down the system and this usually causes the over-provision of resources for guaranteeing the proper management of requests during a usage peak. With our extension of ABS, we have been able to realize a new modeling of the Fredhopper Cloud Services in which both the initial deployment and the subsequent up- and down-scale is expected to be executed automatically. This new model is a first fundamental step towards a new more efficient and elastic deployment management of the Fredhopper Cloud Services.
Structure of the paper. Section 2 describes the Fredhopper Cloud Services case-study. Section 3 reports the ABS deployment annotations that we already defined in [10]. Section 4 presents the new high-level language for the specification of deployment requirements while Sect. 5 discusses the corresponding solver. Finally, the application of our technique to the Fredhopper Cloud Services use-case is reported in Sect. 6. Section 7 discusses the related literature while in Sect. 8 we draw some concluding remarks.
2 The Fredhopper Cloud Services
Fredhopper provides the Fredhopper Cloud Services to offer search and targeting facilities on a large product database to e-Commerce companies as services (SaaS) over the cloud computing infrastructure (IaaS). The Fredhopper Cloud Services drives over 350 global retailers with more than 16 billion in online sales every year. A customer (service consumer) of Fredhopper is a web shop, and an end-user is a visitor of the web shop.
The services offered by Fredhopper are exposed at endpoints. In practice, these services are implemented to be RESTful and accept connections over HTTP. Software services are deployed as service instances. Each instance offers the same service and is exposed via Load Balancer endpoints that distribute requests over the service instances.
The number of requests can vary greatly over time, and typically depends on several factors. For instance, the time of the day in the time zone where most of the end-users are plays an important role (typical lows in demand are observed between 2 am and 5 am). Figure 1 shows a real-world graph for a single day (with data up to 18:00) plotting the number of queries per second (y-axis, ranging from 0–25 qps, the horizontal dotted lines are drawn at 5, 10, 15 and 20 qps) over the time of the day (x-axis, starting at midnight, the vertical dotted lines indicate multiples of 2 h). The 2 am–5 am low is clearly visible.

Number of queries per second (in green the query processing time). (Color figure online)
Peaks typically occur during promotions of the shop or around Christmas. To ensure a high quality of service, web shops negotiate an aggressive Service Level Agreement (SLA) with Fredhopper. QoS attributes of interest include query latency (response time) and throughput (queries per second). For example, based on the negotiated SLA with a customer, services must maintain 100 queries per seconds with less than 200 ms of response time over 99.5 % of the service uptime, and 99.9 % with less than 500 ms.
Previous work reported in [10] aimed to compute an optimal initial deployment configuration (using the size of the product catalogue, number of expected visitors and cost of the required virtual machines). The computation was based on an already available model of the Fredhopper Cloud Services written in the ABS language. In this paper we address the problem of maintaining a high quality of service after this initial set-up by taking dynamic factors into account, such as fluctuating user-demand and unexpectedly failing virtual machines.
The solution that we propose is based on a tool named SmartDepl that, when integrated in the ABS model of the Fredhopper Cloud Services, enables the modeling of automatic upscaling or downscaling. When the decision to scale up or down is made, SmartDepl indicates how to automatically evolve the deployment configuration. This is not a trivial task: the desired deployment configuration should satisfy various requirements, and those can trigger the need to instantiate multiple service instances that furthermore require proper configuring to ensure they function correctly.
The requirements can originate from both business decisions or technical reasons. For instance, for security reasons, services that operate on sensitive customer data should not be deployed on machines shared by multiple customers. Below we list some of these requirements.
-
To increase fault-tolerance, we aim to spread virtual machines across geographical locations. Amazon allows specifying the desired region (a geographical area) and availability zone (a geographical location in a region) for a virtual machine. Fault tolerance is then increased by balancing the number of machines between different availability zones. Thus, when scaling, the number of machines should be adjusted in all zones simultaneously. Effectively this means that with two zones, we scale up or down with an even number of machines.
-
Each instance of a Query service is in one of two modes: ‘live’ mode to serve queries, or ‘staging’ mode to serve as an indexer (i.e., to publish updates to the product catalogue). There always should be at least one instance of Query service in staging mode.
-
The network throughput and latency between the PlatformService and indexer is important. Since the infrastructure provider gives better performance for traffic between instances in the same zone, we require the indexer and PlatformService to be in the same zone.
-
Installing an instance of the QueryService requires the presence of an instance of the DeploymentService on the same virtual machine.
-
For performance reasons and fault tolerance, load balancers require a dedicated machine without other services co-located on the same virtual machine.
3 Annotated ABS
The ABS language is designed to develop executable models. It targets distributed and concurrent systems by means of concurrent object groups and asynchronous method calls. Here, we will recap just the specific linguistic features of ABS to support the modeling of the deployment; for more details we refer the interested reader to the ABS project website [2] and [10] for the cost annotations.
The basic element to capture the deployment in ABS is the Deployment Component (DC), which is a container for objects/services that, intuitively, may model a virtual machine running those objects/services. ABS comes with a rich API that allows the programmer to model a cloud provider of deployment components.

In the ABS code above, the cloud provider “Amazon” is modeled as the object  of type
of type  . The fact that “Amazon” can provide a virtual machine of type “c3” is modeled by calling
. The fact that “Amazon” can provide a virtual machine of type “c3” is modeled by calling  in Line 2. With this instruction we also specify that c3 virtual machines cost 0,210 cents per hour, provide 7.5 GB of RAM and 4 cores. In Line 5 an instance of “c3” is launched and the corresponding deployment component is saved in the variable
in Line 2. With this instruction we also specify that c3 virtual machines cost 0,210 cents per hour, provide 7.5 GB of RAM and 4 cores. In Line 5 an instance of “c3” is launched and the corresponding deployment component is saved in the variable  . Finally, in Line 6, a new object of type
. Finally, in Line 6, a new object of type  (implementing interface
(implementing interface  ) is created and deployed on the deployment component
) is created and deployed on the deployment component  .
.
ABS supports declaring interface hierarchies and defining classes implementing them.

In the excerpt of ABS above, the  service is declared as an interface that extends
service is declared as an interface that extends  , and the class
, and the class  is an implementation of this interface. Notice that the initialization parameters required at object instantiation are indicated as parameters in the corresponding class definition.
is an implementation of this interface. Notice that the initialization parameters required at object instantiation are indicated as parameters in the corresponding class definition.
Classes can be annotated with the cost and requirements of an object of that class.

The above two annotations, to be included before the declaration of the class  in the above ABS code, describe two possible deployment scenarios for objects of that class. The first annotation models the deployment of a Query Service in staging mode, the second one models the deployment in live mode. A Query Service in staging mode requires 2 cores and 7 GB of RAM. In live mode, 1 core and 3 GB of RAM suffices. Creating a Query Service object requires the instantiation of its two initialization parameters
in the above ABS code, describe two possible deployment scenarios for objects of that class. The first annotation models the deployment of a Query Service in staging mode, the second one models the deployment in live mode. A Query Service in staging mode requires 2 cores and 7 GB of RAM. In live mode, 1 core and 3 GB of RAM suffices. Creating a Query Service object requires the instantiation of its two initialization parameters  and
and  . The second parameter should be instantiated with
. The second parameter should be instantiated with  or
or  depending on the deployment scenario. The first parameter is required (keyword
depending on the deployment scenario. The first parameter is required (keyword  in the annotation): this means that the Query Service requires a reference to an object of type
in the annotation): this means that the Query Service requires a reference to an object of type  passed via the
passed via the  initialization parameter.
initialization parameter.
4 The Declarative Requirement Language DRL
Computing a deployment configuration requires taking into account the expectations of the ABS programmer. For example, in the Fredhopper Cloud Services , one initial goal is to deploy with reasonable cost a given number of Query Services and a Platform Service, possibly located on different machines to improve fault tolerance, and later on to upscale (or subsequently downscale) the system according to the monitored traffic. Each desiderata can be expressed with a corresponding expression in Declarative Requirement Language (DRL): a new language for stating constraints a configuration to be computed should satisfy.
As shown in Table 1, that reports an excerpt of the DRL grammar,Footnote 1 a desiderata is a (possibly quantified) Boolean formula  obtained by using the usual logical connectives over comparisons between arithmetic expressions. An atomic arithmetic expression is an integer (Line 6), a sum statement (Line 8) or an identifier for the number of deployed objects (Line 9). The number of objects to deploy using a given scenario is defined by its class name and the scenario name enclosed in square brackets (Line 12). For example, the below formula requires deploying at least one object of class
obtained by using the usual logical connectives over comparisons between arithmetic expressions. An atomic arithmetic expression is an integer (Line 6), a sum statement (Line 8) or an identifier for the number of deployed objects (Line 9). The number of objects to deploy using a given scenario is defined by its class name and the scenario name enclosed in square brackets (Line 12). For example, the below formula requires deploying at least one object of class  in staging mode.
in staging mode.

The square brackets are optional (Line 12 - first option) for objects with only one default deployment scenario. Regular expressions ( in Line 12) can match objects deployed using different scenarios. The number of deployed objects can be prefixed by a deployment component identifier to denote just the number of objects defined within that specific deployment component. As an example, the deployment of only one object of class
in Line 12) can match objects deployed using different scenarios. The number of deployed objects can be prefixed by a deployment component identifier to denote just the number of objects defined within that specific deployment component. As an example, the deployment of only one object of class  on the first and second instance of a “c3” virtual machine can be enforced as follows.
on the first and second instance of a “c3” virtual machine can be enforced as follows.

Here the 0 and 1 numbers between the square brackets represent respectively the first and second virtual machine of type “c3”. To shorten the notation, the  can be omitted (Line 9).Footnote 2
can be omitted (Line 9).Footnote 2
It is possible to use also quantifiers and sum expressions to capture more concisely some of the desired properties. Variables are identifiers prefixed with a question mark. As specified in Line 13, variables in quantifiers and sums can range over all the objects ( ), all the deployment components (
), all the deployment components ( ), or just all the virtual machines matching a given regular expression (
), or just all the virtual machines matching a given regular expression ( ). In this way it is possible to express more elaborate constraints such as the co-location or distribution of objects, or limit the amount of objects deployed on a given DC.Footnote 3 As an example, the constraint enforcing that every Query Service has a Deployment Service installed on its virtual machine is as follows.
). In this way it is possible to express more elaborate constraints such as the co-location or distribution of objects, or limit the amount of objects deployed on a given DC.Footnote 3 As an example, the constraint enforcing that every Query Service has a Deployment Service installed on its virtual machine is as follows.

Here impl stands for logical implication. The regular expression  allows us to match with both deployment modalities for the Query Service (
allows us to match with both deployment modalities for the Query Service ( and
and  ). Finally, specifying that the load balancer must be installed on a dedicated virtual machine (without other Service instances) can be done as follows.
). Finally, specifying that the load balancer must be installed on a dedicated virtual machine (without other Service instances) can be done as follows.

5 Deployment Engine
SmartDepl is the tool that we have implemented to realize automatic deployment. The key idea of SmartDepl is to allow the user on the one hand to declaratively specify the desired deployments and, on the other hand, to develop its program abstracting from concrete deployment decisions. More concretely, deployment requirements are specified as program annotations. SmartDepl processes each of these annotations and generates for each of them a new class that specifies the deployment steps to reach the desired target. Then this class can be used to trigger the execution of the deployment, and to undo it in case the system needs to downscale.
As an example, imagine that an initial deployment of the Fredhopper Cloud Services has been already obtained and that, based on a monitor decision, the user wants to add a Query Service instance in live mode. The annotation that describes this requirement is the JSON object defined in Table 2.Footnote 4
In Line 1, the keyword  specifies that the name of the class with the deployment code, to be synthesized by SmartDepl, is
specifies that the name of the class with the deployment code, to be synthesized by SmartDepl, is  . As we will see later, this class exposes methods to be invoked to actually execute deployment actions that modifies the current deployment according to the requirements in the deployment annotation. The second line contains the declarative specification of the desired configuration in DRL. Deploying a new instance of the Query Service may involve other relevant objects from the surrounding environment, such as the
. As we will see later, this class exposes methods to be invoked to actually execute deployment actions that modifies the current deployment according to the requirements in the deployment annotation. The second line contains the declarative specification of the desired configuration in DRL. Deploying a new instance of the Query Service may involve other relevant objects from the surrounding environment, such as the  or a
or a  . Which objects are relevant may come from business, security or performance reasons, thus in general it may be undesirable to select or create automatically a Service instance of the right type. SmartDepl is flexible in this regard: the user supplies the appropriate ones. By using the keyword
. Which objects are relevant may come from business, security or performance reasons, thus in general it may be undesirable to select or create automatically a Service instance of the right type. SmartDepl is flexible in this regard: the user supplies the appropriate ones. By using the keyword  , Lines 3–18 list the appropriate objects. Since these object are already available, they need not be deployed again. The names of these objects are specified with the keyword
, Lines 3–18 list the appropriate objects. Since these object are already available, they need not be deployed again. The names of these objects are specified with the keyword  (Lines 3, 9, 14), the provided interfaces with the keyword
(Lines 3, 9, 14), the provided interfaces with the keyword  (Lines 5–6, 11, 16) with the amount of services that can use it (keyword
(Lines 5–6, 11, 16) with the amount of services that can use it (keyword  in Lines 7, 12, 17 — in this case a \(-1\) value means that the object can be used by an unbounded number of other objects), and the object interface with keyword
in Lines 7, 12, 17 — in this case a \(-1\) value means that the object can be used by an unbounded number of other objects), and the object interface with keyword  (Lines 8, 13, 18). Finally, with the keyword
(Lines 8, 13, 18). Finally, with the keyword  , the user specifies if there are existing deployment components with free resources that can be used to deploy new objects. In this case, for fault tolerance reasons the user wants to deploy the Query Service in a new machine and therefore the
, the user specifies if there are existing deployment components with free resources that can be used to deploy new objects. In this case, for fault tolerance reasons the user wants to deploy the Query Service in a new machine and therefore the  is empty (Line 19).
is empty (Line 19).
Once the annotation is given, the user may freely use this class. For instance, the below ABS code scales the system up or down based on a monitor decision.

Every time an upscale is needed, an object of class  (the name associated with the annotation previously discussed) is created. The idea is to store the references to these deployment objects in a list called
(the name associated with the annotation previously discussed) is created. The idea is to store the references to these deployment objects in a list called  . We now discuss the initialization parameters for such objects. The first parameter is the cloud provider, as defined for instance in Sect. 3. The next parameters are the objects already available for the deployment that do not need to be re-deployed. These are given according to the order they are defined in the annotation in Table 2. The generated class implements the
. We now discuss the initialization parameters for such objects. The first parameter is the cloud provider, as defined for instance in Sect. 3. The next parameters are the objects already available for the deployment that do not need to be re-deployed. These are given according to the order they are defined in the annotation in Table 2. The generated class implements the  with: (i) a
with: (i) a  method to realise the deployment of the desired configuration, (ii) an
method to realise the deployment of the desired configuration, (ii) an  method to undo the deployment gracefully by removing the virtual machine created with the
method to undo the deployment gracefully by removing the virtual machine created with the  method, (iii) getter methods to retrieve the list of new objects and deployment components created by running the
method, (iii) getter methods to retrieve the list of new objects and deployment components created by running the  method (e.g., a call
method (e.g., a call  retrieves the list of all the Query Services created by
retrieves the list of all the Query Services created by  ). The actual addition of the Query Service is performed in Line 5 with the call of the
). The actual addition of the Query Service is performed in Line 5 with the call of the  method. If the monitor decides to downscale (Line 7), the last deployment solution is retrieved (Line 8), and the corresponding deployment actions are reverted by calling the
method. If the monitor decides to downscale (Line 7), the last deployment solution is retrieved (Line 8), and the corresponding deployment actions are reverted by calling the  method.Footnote 5
method.Footnote 5
Technically, SmartDepl is written in Python (\(\sim \)1k lines of code) and relies on Zephyrus2, a configuration optimizer that given the user desiderata and a universe of components, computes the optimal configuration satisfying the user needs.Footnote 6 The cost annotations (see Sect. 3) are used to compute a configuration that satisfies the constraints, minimizes the cost of the deployment components that need to be created and, in case of ties, minimizes the number of created objects. The user is notified if no configuration exists that satisfies the desiderata. Once a configuration is obtained, SmartDepl uses topological sorting to take into account all the object dependencies and computes the sequence of deployment instructions to realise the desirable configuration. SmartDepl exploits Delta Modeling [7] to generate the code of the classes and methods to inject into the interface. SmartDepl also notifies the user when it is unable to generate a sequence of deployment actions due to mutual dependencies between the objects.Footnote 7
As an example the  code generated by SmartDepl for the annotation defined in Table 2 is the following.
code generated by SmartDepl for the annotation defined in Table 2 is the following.

At Line 3, a new deployment component  is created. In Lines 4–5 an object of class
is created. In Lines 4–5 an object of class  is created, since every Query Service requires a corresponding Deployment Service (it is one of the required parameters, cf. Sect. 3) to be deployed before the Query Service. In Lines 8–9 the desired object of class
is created, since every Query Service requires a corresponding Deployment Service (it is one of the required parameters, cf. Sect. 3) to be deployed before the Query Service. In Lines 8–9 the desired object of class  is created. Both objects are deployed on
is created. Both objects are deployed on  .
.
Even though for the sake of the presentation this is just a simple example, it is immediately possible to notice that SmartDepl alleviates the user from the burden of the deployment decisions. Indeed, she can specify the desired configuration without worrying about the dependencies of the various objects and their distributed placement for obtaining the cheapest possible solution.

SmartDepl execution within the ABS toolchain IDE.
SmartDepl is open source, available at https://github.com/jacopoMauro/abs_deployer/tree/smart_deployer and to increase its portability it can be installed also by using the Docker container technology [12]. As illustrated in Fig. 2, SmartDepl has also been integrated into the ABS toolchain,Footnote 8 an IDE for a collection of tools for writing, inspecting, checking, and analyzing ABS programs developed within the Envisage European project.
6 Application to the Fredhopper Use Case
In this section we report on the modeling with SmartDepl of the concrete deployment requirements of the Fredhopper Cloud Services, previously introduced in Sect. 2. We decided to apply our techniques to the Fredhopper Cloud Services use case because it was already modeled in ABS, and thanks to extensive profiling of the in-production system, the cost of its services are known.
SmartDepl was used twice: to synthesize the initial static deployment of the entire framework and to add (and later remove) instances of the Query Service if the system needs to scale. Since the Fredhopper Cloud Services uses Amazon EC2 Instance Types, we used two types of deployment components corresponding to the “xlarge” and “2xlarge” instances of the Compute Optimized instances (version 3)Footnote 9 of Amazon. For fault tolerance and stability, Fredhopper Cloud Services uses instances in multiple regions in Amazon (regions are geographically separate areas, so even if there is a force majeure in one region, other regions may be unaffected). We model the instance types in different regions as follows: “c3_xlarge_eu”, “c3_xlarge_us”, “c3_2xlarge_eu”, “c3_2xlarge_us” (“eu” refers to a European region, “us” is an American region).
The static deployment of the Fredhopper Cloud Services requires deploying a Load Balancer, a Platform Service, a Service Provider and 2 Query Services with at least one in staging mode. This is expressed as follows.

For the correct functioning of the system, a Query Service requires a Deployment Service installed on the same machine. This constraint is expressed as shown in Sect. 4. The requirement that a Service Provider is present on every machine containing a Platform Service is expressed by:

Not all services can be freely installed on an arbitrary virtual machine. To increase resilience, we require that the Load Balancer, the Query/Deployment Services, and the Platform Service/Service Provider are never co-located on the same virtual machine. The end of Sect. 4 shows how this is expressed.
To handle catastrophic failures, the Fredhopper Cloud Services aim to balance the Query Services between the regions (see Sect. 2). This is enforced by constraining the number of the Query Services in the different data centers to be equal. In DRL this is expressed with regular expressions as follows.

As described in Sect. 4, for performance reasons, the Query Service in Staging mode should be located in the zone of the Platform Service, since Amazon connects instances in the same region with low-latency links. For the European data-center this is expressed by:


Example of automatic objects allocation to deployment components.
From this specification SmartDepl computes the initial configuration in Fig. 3, which minimizes the total costs per interval. It deploys the Load Balancer, Platform Service and one staging Query Service on three “2xlarge” instances in Europe, and deploys a live Query service on an “xlarge” instance in US.
After this initial deployment, the Cloud engineers of Fredhopper Cloud Services rely on feedback provided by monitors to decide if more Query Services in live mode are needed. Figures 4 and 5 show some of the main metrics for a single customer used to determine the scaling. The timescale in the figures is 1 day, but this can be adjusted to see trends over longer periods, or zoom in on a short period. The figures show that the number of queries served per second (qps, first graph of Fig. 4) is relatively high and the requests (Fig. 4, second graph) are fairly low, so requests are not queuing. Furthermore the CPU usage (Fig. 4, third graph) and memory consumption with small swap space used (Fig. 5, second and third graphs) look healthy. Hence, no scaling is needed.

Metrics graphed over a single day for a customer (a).

Metrics graphed over a single day for a customer (b).
If we would have needed to scale up, two Query Service instances are added: one in an EU region, and one in an US region for balancing across regions. In contrast, if there is unnecessary overcapacity, the most recent ones can be shut down. Since the Cloud operations team currently manually decides to scale, and Fredhopper has very aggressive SLAs, the team is typically conservative with downscaling, leading to potential over-spending. The ability of SmartDepl to deploy in the programming language (ABS) itself allows to leverage the extensive tool-supported analyses available for ABS [3, 11, 15, 25]. For example, by using monitors to track the quality of services, SmartDepl allows to reason on a rigorous basis on the scaling decisions and their impact on the SLA agreed with the customers.
Furthermore, while the operations team currently use ad-hoc scripts to configure newly added or removed service instances, and these scripts are specific to the infrastructure provider, SmartDepl automatically generates code that accomplishes this (for example, see Table 2). SmartDepl is flexible in the sense that it is infrastructure independent, allowing to seamlessly switch between different infrastructure providers: virtual machines are launched and terminated through a generic Cloud API offered by ABS for managing virtual resources. Executable code is automatically generated from ABS for any of the infrastructures for which an implementation of the Cloud API exists (e.g., Amazon, Docker, OpenStack).
To automatically generate the scaling deployment configuration, SmartDepl uses all the previous specifications, except that now instead of requiring a Platform Service and a Load Balancer we simply require two Query services in live mode. In this case, as expected after the deployment of the initial framework, the best solution is to deploy one Query Service in Europe and one in US using “xlarge” instances. The ABS model used with all the annotations and specifications and an example of generated code is available at https://github.com/jacopoMauro/abs_deployer/blob/smart_deployer/test/.
7 Related Work
Many management tools for bottom-up deployment exist, e.g., CFEngine [6], Puppet [19], MCollective [23], and Chef [22]. Such tools allow for the declaration of components, by indicating how they should be installed on a given machine, together with their configuration files, but they are not able to automatically decide where components should be deployed and how to interconnect them for an optimal resource allocation. The alternative holistic approach allows modeling the entire application and derives the deployment plan top-down. In this context, one prominent work is represented by the TOSCA (Topology and Orchestration Specification for Cloud Applications) standard [21]. Following a similar philosophy, we can mention Terraform [17], JCloudScale [26], Apache Brooklyn [4], and tools supporting the Cloud Application Management for Platforms protocol [20]. A first attempt to combine the holistic and bottom-up approaches is reported in [5]: a global deployment plan expressed in TOSCA is checked for correctness against local specifications of the deployment lifecycle of the single components.
Similarly to our approach, ConfSolve [18] and Engage [14] use a solver to plan deployment starting from the local requirements of components, but these approaches were not incorporated in fully-fledged specification languages (including also behavioral descriptions as in our case with ABS).
8 Conclusions
We presented an extension of the ABS specification language that supports modeling deployment in a declarative manner: the programmer specifies deployment constraints, and a solver synthesizes ABS classes with methods that execute deployment actions to reach an optimal deployment configuration that satisfies the constraints. Our approach, which is inspired by [9] and significantly improves our initial work [10], can be easily applied to any other object-oriented language that offers primitives for the acquisition and release of computing resources.
As a future work we plan to investigate the possibility to invoke at run time the external deployment engine. In this way, it could be possible to dynamic re-define the deployment constraints by means of a dynamic tuning of the engine. Nevertheless, dynamically computing the deployment steps may require additional elements such as the support of new reflection primitives to get a snapshot of the running application, and possibly the use of sub-optimal solutions when computing the optimal configuration takes too much time.
Notes
- 1.
The complete grammar defined using the ANTLR compiler generator is available at https://github.com/jacopoMauro/abs_deployer/blob/smart_deployer/decl_spec_lang/DeclSpecLanguage.g4.
- 2.
We assume that every deployment desiderata expressed in DRL deals with only a bounded number of deployment components (the bound is a configuration parameter for SmartDepl). Notice that this does not mean that the total number of deployment components in an application is bound, as the deployment can be repeated an unbounded number of times.
- 3.
DRL improves on the specification language presented in [10] because the addition of the quantifiers and sums allow to write the desiderata more concise and naturally.
- 4.
To facilitate the interoperability between ABS and SmartDepl we have adopted a JSON syntax for the deployment annotations. For the interested reader the formal specification of the JSON annotations is defined in https://github.com/jacopoMauro/abs_deployer/blob/smart_deployer/spec/smart_deploy_annotation_schema.json.
- 5.
Since ABS does not have an explicit operation to force the removal of objects the
 procedure just removes the references to these objects leaving the garbage collector to actually remove them. The deployment components created by the
procedure just removes the references to these objects leaving the garbage collector to actually remove them. The deployment components created by the 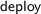 methods are removed instead using an explicit kill primitive provided by ABS.
methods are removed instead using an explicit kill primitive provided by ABS. - 6.
SmartDepl uses Zephyrus2 (freely available at https://bitbucket.org/jacopomauro/zephyrus2.git) since it allows the use of a new expressive language and because it relies on MiniSearch [24], a new efficient and flexible framework for planning the search strategies. Zephyrus2 is a completely new re-engineering of the previous Zephyrus solver [8, 9].
- 7.
This occurs when the creation of an object requires the execution of a complex protocol, such as what happens for the boostrapping of Linux distributions [1].
- 8.
- 9.
 procedure just removes the references to these objects leaving the garbage collector to actually remove them. The deployment components created by the
procedure just removes the references to these objects leaving the garbage collector to actually remove them. The deployment components created by the 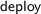 methods are removed instead using an explicit kill primitive provided by ABS.
methods are removed instead using an explicit kill primitive provided by ABS.References
Abate, P., Johannes, S.: Bootstrapping software distributions. In: CBSE 2013 (2013)
Abstract behavioral specification language. http://www.abs-models.com/
Albert, E., Arenas, P., Flores-Montoya, A., Genaim, S., Gómez-Zamalloa, M., Martin-Martin, E., Puebla, G., Román-Díez, G.: SACO: static analyzer for concurrent objects. In: ETAPS (2014)
Apache Software Foundation: Apache Brooklyn. https://brooklyn.incubator.apache.org/
Brogi, A., Canciani, A., Soldani, J.: Modelling and analysing cloud application. In: Dustdar, S., Leymann, F., Villari, M. (eds.) ESOCC 2015. LNCS, vol. 9306, pp. 19–33. Springer, Heidelberg (2015)
Burgess, M.: A site configuration engine. Comput. Syst. 8(2), 309–337 (1995)
Clarke, D., Muschevici, R., Proença, J., Schaefer, I., Schlatte, R.: Variability modelling in the ABS language. In: Aichernig, B.K., de Boer, F.S., Bonsangue, M.M. (eds.) FMCO 2010. LNCS, vol. 6957, pp. 204–224. Springer, Heidelberg (2011)
Cosmo, R.D., Lienhardt, M., Mauro, J., Zacchiroli, S., Zavattaro, G., Zwolakowski, J.: Automatic application deployment in the cloud: from practice to theory and back. In: CONCUR (2015)
Cosmo, R.D., Lienhardt, M., Treinen, R., Zacchiroli, S., Zwolakowski, J., Eiche, A., Agahi, A.: Automated synthesis and deployment of cloud applications. In: ASE (2014)
de Gouw, S., Lienhardt, M., Mauro, J., Nobakht, B., Zavattaro, G.: On the integrationof automatic deployment into the ABS modeling language. In: Dustdar, S., Leymann, F., Villari, M. (eds.) ESOCC 2015. LNCS, vol. 9306, pp. 49–64. Springer, Heidelberg (2015)
Din, C.C., Bubel, R., Hähnle, R.: KeY-ABS: a deductive verification tool for the concurrent modelling language ABS. In: CADE (2015)
Docker Inc.: Docker. https://www.docker.com/
Ferry, N., Chauvel, F., Rossini, A., Morin, B., Solberg, A.: Managing multi-cloud systems with CloudMF. In: NordiCloud (2013)
Fischer, J., Majumdar, R., Esmaeilsabzali, S.: Engage: a deployment management system. In: PLDI (2012)
Giachino, E., Laneve, C., Lienhardt, M.: A framework for deadlock detection in core ABS. CoRR (2015)
Gonçalves, G.E., Endo, P.T., Santos, M.A., Sadok, D., Kelner, J., Melander, B., Mångs, J.: CloudML: an integrated language for resource, service and request description for D-Clouds. In: CloudCom (2011)
HashiCorp: Terraform. https://terraform.io/
Hewson, J.A., Anderson, P., Gordon, A.D.: A declarative approach to automated configuration. In: LISA (2012)
Kanies, L.: Puppet: next-generation configuration management. ;login: the USENIX magazine (1) (2006)
OASIS: Cloud Application Management for Platforms. http://docs.oasis-open.org/camp/camp-spec/v1.1/camp-spec-v1.1.html
OASIS: Topology and Orchestration Specification for Cloud Applications (TOSCA) Version 1.0. http://docs.oasis-open.org/tosca/TOSCA/v1.0/cs01/TOSCA-v1.0-cs01.html
Opscode: Chef. http://www.opscode.com/chef/
Puppet Labs: Marionette collective. http://docs.puppetlabs.com/mcollective/
Rendl, A., Guns, T., Stuckey, P.J., Tack, G.: MiniSearch: a solver-independent meta-search language for MiniZinc. In: CP (2015)
Wong, P.Y.H., Bubel, R., de Boer, F.S., Gómez-Zamalloa, M., de Gouw, S., Hähnle, R., Meinke, K., Sindhu, M.A.: Testing abstract behavioral specifications. STTT 17(1), 107–119 (2015)
Zabolotnyi, R., Leitner, P., Hummer, W., Dustdar, S.: JCloudScale: closing the gap between IaaS and PaaS. ACM Trans. Internet Technol. 15(3), 10 (2015)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 IFIP International Federation for Information Processing
About this paper
Cite this paper
de Gouw, S., Mauro, J., Nobakht, B., Zavattaro, G. (2016). Declarative Elasticity in ABS. In: Aiello, M., Johnsen, E., Dustdar, S., Georgievski, I. (eds) Service-Oriented and Cloud Computing. ESOCC 2016. Lecture Notes in Computer Science(), vol 9846. Springer, Cham. https://doi.org/10.1007/978-3-319-44482-6_8
Download citation
DOI: https://doi.org/10.1007/978-3-319-44482-6_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-44481-9
Online ISBN: 978-3-319-44482-6
eBook Packages: Computer ScienceComputer Science (R0)