
Abstract
Estimating the centroid of a set of time series under time warp is a major topic for many temporal data mining applications, as summarization a set of time series, prototype extraction or clustering. The task is challenging as the estimation of centroid of time series faces the problem of multiple temporal alignments. This work compares the major progressive and iterative centroid estimation methods, under the dynamic time warping, which currently is the most relevant similarity measure in this context.
Similar content being viewed by others


Keywords
1 Introduction
Time series centroid estimation is a major issue for many temporal data analysis and mining applications. Estimating the centroid of a set of time series under time warp however faces the tricky multiple temporal alignment problem [1–4]. Temporal warping alignment of time series has been an active research topic in many scientific disciplines. To estimate the centroid of two time series under temporal metrics, as the dynamic time warping [5–7], one standard way is to embed the time series into a new Euclidean space defined by their temporal warping alignment. In this space, the centroid can be estimated as the average of the linked elements. The problem becomes more complex where the number of time series is more than two, as one needs to determine a multiple alignment that links simultaneously all the time series on their commonly shared elements.
A first manner to determine a multiple alignment is to search, by dynamic programming, the optimal path within an N-dimensional grid that crosses the N time series. The complexity of this approach nevertheless prevents its use, as it constitutes an NP-complete problem with a complexity of \(O(T^N)\) that increases exponentially with the number of time series N and the time series length T. A second way, that characterizes progressive approaches, is based on combining progressively pairs of time series centroids to estimate the global centroid. Such progressive approaches may suffer from the error propagation problem through the set of pairwise centroid combinations. The third approach is iterative. It works similarly to the progressive approach but reduces the error propagation by repeatedly refining the centroid and realigning it to the initial time series.
The main contribution of this work is to present some major progressive and iterative approaches for time series centroid estimation, prior to present their characteristics. It also reviews an extensive comparison between the approaches through public real and synthetic datasets. To the best of our knowledge, such a comparison has never been conducted before.
The remainder of the paper is organized as follows: In the next section, different related progressive and iterative approaches are presented. Section 3 presents the experiments conducted for comparison purposes and discuss the results obtained. Lastly, Sect. 4 concludes the paper.
2 Progressive and Iterative Approaches
The progressive and iterative approaches for time series centroid estimation are mainly derived from the multiple sequence alignment methods to address the challenging problem of aligning more than two time series [8–11]. To estimate the centroid of more than two time series, several heuristic approaches have been proposed. Here, we review some major progressive and iterative approaches for time series averaging under the dynamic time warping.
2.1 Progressive Approaches
NonLinear Alignment and Averaging Filters (NLAAF). In the past decades, many averaging methods have been introduced, but only a few of them have been adapted to time series averaging, clustering and mining. For instance, Gupta et al. [12], proposed a time series averaging method based on a tournament scheme, called “NonLinear Alignment and Averaging Filters (nlaaf)”. First, pairs of time series are selected randomly, and then aligned according to the dynamic time warping. That way, (N / 2) averaged sequences are created. The same process is iterated on the centroids estimated, until one sequence is obtained as a global centroid. In this approach, the averaging method between two time series is applied (\(N-1\)) times, as illustrated in Fig. 1, where \(\mathbf c (\mathbf x _i,\mathbf x _j)\) refers to the estimated centroid of time series \(\mathbf x _i\) and \(\mathbf x _j\).

Centroid estimation by random pairwise centroid combination.
In nlaaf, each element of a centroid is computed as the mean of each linked elements in the dtw alignment. The main drawback of nlaaf approach lies in the growth of its resulting length, because each use of averaging method can almost double the length of the average sequence. As classical datasets comprise hundreds of time series, with each one including hundreds of data points, simply storing the resulting average may be impossible. This length problem is moreover worsened by the complexity of dtw, that grows bi-linearly with the lengths of the sequences. That is why nlaaf is generally used in conjunction with a process reducing the length of the average, unfortunately leading to information loss and unsatisfactory approximation. Additionally, the average strongly depends on the random selection of sequences and different choices lead to different results.
Prioritized Shape Averaging (PSA). To avoid the bias induced by random selection, Niennattrakul et al. among others [8, 16, 17] proposed a framework of shape averaging called “Prioritized Shape Averaging (psa)” based on hierarchical clustering. The pairwise time series centering is guided by the dendrogram obtained through hierarchical clustering strategy.
The psa uses hierarchical clustering as a way to identify priorities between time series. In particular, to estimate a global centroid, the set is first clustered using the agglomerative clustering to get a hierarchical relationship among the whole time series. The simple or complete linkage is considered in general to fasten the dendrogram build, where almost the average linkage or centroids are the best-performed methods. Subsequently, the pairwise time series centroids are combined respectively to their clustering order in the dendrogram. Each parent node is averaged in a bottom-up manner using a weighted dtw averaging. Therefore, the most similar time series are averaged first. Note that the weight of an averaged sequence is calculated from the number of time series upon which the averaged sequence is formed. Initially, all time series have the same weight of one.

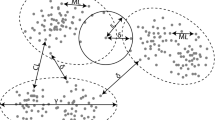
Example of six time series sequence averaging using psa
Figure 2 describes an example of averaging six sample time series using psa. According to the dendrogram, first the time series \(\mathbf x _2\) and \(\mathbf x _3\) are averaged. The average sequence denoted by \(\mathbf c (\mathbf x _2,\mathbf x _3)\), has the weight of two. The intermediate centroid \(\mathbf c (\mathbf x _1, \mathbf c (\mathbf x _2,\mathbf x _3))\) is then computed by averaging the time series \(\mathbf x _1\) and the average sequence \(\mathbf c (\mathbf x _2,\mathbf x _3)\). The intermediate centroid \(\mathbf c (\mathbf x _1, \mathbf c (\mathbf x _2,\mathbf x _3))\) will have the weight of three, since the time series sequences \(\mathbf x _1\) and \(\mathbf c (\mathbf x _2,\mathbf x _3)\) have weight of one and two, respectively. The process goes on till one obtains a global centroid.
Although this hierarchical averaging method aims to remove the bias induced by random selection, growth length of the average sequence remains a problem. Furthermore, local averaging strategies like nlaaf or psa may let an initial approximation error propagate throughout the averaging process. If averaging process has to be repeated (e.g., during k-means iterations), the effects may dramatically alter the quality of the result. This is why a global approach is desirable, where time series would be averaged all together, with no sensitivity to their order of consideration.
Cross-Word Reference Template (CWRT). A direct manner to estimate the centroid is proposed in Abdulla et al. [1], where a dynamic time warping between each time series and a reference one, generally the time series medoid, is first performed. Each time series is then described in the representation space defined by the reference medoid by resampling, stretching and shortening operations, as in Fig. 3. Finally the global centroid is computed by averaging the time-aligned time series across each point. The method is called “Cross-Words Reference Template (cwrt)”.

Centroid estimation based on a reference time series. The dtw is performed between \(\mathbf x _1\), \(\mathbf x _2\) and the reference time series \(\mathbf x _3\) (left). \(\mathbf x _1\) and \(\mathbf x _2\) are embedded in the space defined by \(\mathbf x _3\) (right) where the centroid is estimated, and ‘avg’ is the standard mean function.
The global estimated centroid has the same length as the medoid, and the result does not depend on the order in which time series are processed.
2.2 Iterative Approaches
Dtw Barycenter Averaging (DBA). Petitjean et al. [3] proposed a global averaging method, called “Dtw Barycenter Averaging (dba)”. The method consists in iteratively refining an initially average sequence, in order to minimize its distance to the set of time series. The aim is to minimize the sum of squared dtw distances from the average sequence to the set of time series. Technically, dba works in two steps for each refinement. First, computing dtw between each time series and the temporary average sequence, and secondly, updating each element of the average sequence with the barycenter of the elements aligned to it during the first step. In a nutshell, the dba under temporal warping is a global approach that can average a set of time series all together. The global estimated centroid has the same length as the initial average sequence, and like cwrt, the result is not depending on the order in which time series are processed. However the time complexity of dba is smaller than nlaaf and psa [3], but the time complexity problem remains.
Weighted DTW Averaging (WDTW). To circumvent the tricky multiple temporal alignments and the above mentioned limitations, we proposed a tractable and fast centroid estimation that captures both global and local temporal features under weighted time warp measures [20]. It formalizes the multiple time series averaging problem as an optimization problem and propose a solution yielding a local optimum.
For that, we propose to estimate both the time series centroid c and the weight vector w that measures the representativeness of the centroid’s regions. In addition, we introduce a weighted warping function \(f(w_t)\) that guides the learned alignments according to the importance of the centroid elements to capture the shared global and local temporal features.
Let X = \({\{\mathbf{x }_1, \mathbf{x }_2,\ldots , \mathbf{x }_{N}\}}\) be a set of time series, and wdtw the weighted dissimilarity between \(\mathbf x _i\) and the weighted centroid (c,w). The averaging problem, as formalized in [20], is defined as:
with
where \(f: (0,1] \rightarrow \mathbb {R^+}\) is a non-increasing function (e.g. \(f(w_t)= w_t^{-\alpha } \)) and \(\varphi : \mathbb {R} \times \mathbb {R} \rightarrow \mathbb {R^+}\) is a positive, real-valued, dissimilarity function. The cost function C computes the sum of the weighted dissimilarities \(\varphi \) between \(\mathbf x \) and (\(\mathbf c ,\mathbf w \)) through the alignment \(\varvec{\pi }\). When the weights are uniform (or f is a constant function) and when \(\varphi \) is the Euclidean distance, corresponds to the well known Dynamic Time Warping (dtw) [5, 7].
The problem given above, can be solved by computing the partial derivatives of Lagrangian with respect to c to 0 and solving for c, and with respect to w to 0 and solving for w, described more in details in [20].
Let us summarize the main characteristics of the above approaches. In both nlaaf and psa, the length of the global centroid increases with the number of time series to average, inducing an increase of the space and time complexity that is particularly critical under the dtw. The length of the centroids estimated by cwrt, dba and wdtw averaging is however the same as the reference time series length. Furthermore, all the progressive approaches as well as dba method are heuristic, with no guarantee of optimality. Even, if the provided approximations are accurate for globally similar time series, they are in general poor for time series that share local characteristics with distinctive global behaviors. In this view, wdtw is a tractable fast and accurate averaging method that captures both global and local temporal features, as shown in [20].
3 Experimental Study
The experiments are conducted to compare the above approaches on classes of time series composing various datasets. The datasets can be divided into two categories. The first one is composed of time series that have similar global behavior within the classes, where the time series of the second category may have distinct global behavior, while sharing local characteristics [19]. For the comparison, the induced inertia reduction rate and the required run time are evaluated as well as the qualitative comparison of the centroids obtained by a visualization. In the following, we first describe the datasets used, then specify the validation process and discuss the obtained results.
3.1 Data Description
The experiments are first carried out on four well known public datasets cbf, cc, digits and character traj. [14, 15]. These data define a favorable case for the averaging task as time series behave similarly within the classes, as illustrated in Fig. 4.

The time series behaviors with the classes “Funnel”, “Cyclic”, “6” and “b” of the datasets cbf, cc, digits and character traj., respectively
We then consider more complex datasets: bme Footnote 1, umd (see Footnote 1) [19], spiral [4], noised spiral (see Footnote 1) and consseason [14]. They are composed of time series that behave differently within the same classes while sharing several local characteristics.
bme includes two challenging classes begin and end (Fig. 5-left), which characterized by a small bell arising at the initial and final period respectively. The overall behavior may be different depending on whether the large bell is pointing upward or downward. umd introduces more complexity with the classes up and down (Fig. 5-right) characterized by a small bell that may occur at different time stamps.

The time series behaviors with the classes “Begin” and “End” of the dataset bme (left), “Up” and “Down” of the dataset umd (right)
The spiral data, proposed in [18], consists of 3-D spatio-temporal time series (2-D spatial and 1-D temporal) generated from latent time series:
where the canonical time series \(\mathbf Z \in \mathbb {R}^{2*l}\) is a curve in two dimensions (x, y). \(\mathbf U _i \in \mathbb {R}^{2*2}\) and \(\mathbf b _i \in \mathbb {R}^2\) are randomly generated projection matrix and translation vector respectively. The binary matrix \(\mathbf M _i \in \{0,1\}^{l*n_i} \) is generated by randomly choosing \(n_i \le l \) columns from \(\mathbf I _l\) for temporal distortion. The spatial dimension \(\mathbf e _i \in \mathbb {R}^{n_i}\) is generated with zero-mean Gaussian noise. The latent time series \(\mathbf Z \) and three generated time series are visualized in Fig. 6.

Latent curve Z and three induced instances \(X_1, X_2, X_3\) without noise (left), and with noise \(e_i\) (right) - spiral dataset
spiral2 extends spiral data to more challenging time series that are highly noisy and globally behave differently while sharing a three dimensional latent time series that may appear randomly at different time stamps. The latent time series \(\mathbf Z \) and three generated time series are visualized in Fig. 7.

Latent curve Z and 3 induced instances \(X_1, X_2, X_3\) sharing local characteristics for the spiral2 dataset
Finally, consseason data provides the electric power consumption recorded in a personal home over almost one year. consseason is composed of time series distributed in two season classes (Warm and Cold) depending on whether the power consumption is recorded during the warm (from April to September) or cold (from October to March) season. Note that the electric power consumption profiles differ markedly within classes.
Table 1 indicates for each data set: the number of classes it includes (nb. class), the number of instances (nb. ts.), the number of attributes (nb. att.), the time series length (ts. length) and the global or local nature of similarity within the classes (type).
3.2 Validation Process
The five mentioned methods nlaaf, psa, cwrt, dba and wdtw described in Sect. 2 are compared together. The performances of these approaches are evaluated through the centroid estimation of each class of the above described datasets. Particularly, the efficiency of each approach is measured through: (a) the reduction rate of the inertia criterion; the initial inertia being evaluated around the time series medoid that minimizes the distances to the rest of time series and (b) the space and time complexity. The results reported hereafter are averages of 10 repetitions of the corresponding algorithms. Finally for all reported results, the one which is significantly different from the rest (two-sided t-test at 5 \(\%\) risk) is indicated in bold.
Inertia Reduction Rate. Time series averaging approaches are used to estimate centroid of the time series classes described above, then the inertia w.r.t. the centroids is measured. Lower is the inertia higher representative is the extracted centroid. Table 2, gives the obtained inertia reduction rates (irr), averaged per dataset, as:
where \(\mathbf x _1,...,\mathbf x _N\) are the set of time series, D is the distance metric, \(\mathbf c \) is the determined centroid and \(\mathbf m \) the initial medoid. The alternative of a centroid is a medoid. Medoid is a time series in a set that minimizes sum of the distances to all other time series within the same set. Note that, we use the medoid in the criteria defined above to make the results comparable. In the case, we compare the obtained centroid of each method with a specific time series in the set (i.e. medoid) as its alternative one. Table 2 shows that the wdtw provides the highest irr for the most datasets, followed by dba and psa. Notice that, the results presented by psa is obtained through the centroid linkage, which outperformed the other linkage (e.g. simple linkage, complete linkage), mostly. Some negative rates observed indicate an inertia increase.
Time and Space Complexity. In Table 3 the studied approaches are compared w.r.t their space and time complexity. Are reported the length of the extracted centroid (length), the time consumption in seconds (time) and for the iterative methods the request number of iterations (iter nb.). The results, averaged per dataset, reveal almost wdtw the faster method, followd by dba, and psa the slowest one. The cwrt approach is not comparable to the rest of the methods as it performs directly an euclidean distance on the time series once the initial dtw matrix evaluated. Remark that for nlaaf and psa the centroid lengths are very large making these approaches unusable for large time series, while the centroid lengths for the remaining methods are equal to the length of the initial medoid. The higher time consumptions observed for nlaaf and psa are mainly explained by the progressive increase of the centroid length during the pairwise combination process.
3.3 Discussion
From Table 2, we can see that wdtw lead to the highest inertia reduction rates for almost all datasets, where the best scores (significantly different) indicated in bold. As expected, the dba method that iteratively optimizes an inertia criterion, in general, reaches higher values than the non-iterative methods (nlaaf, psa and cwrt). Finally, cwrt has the lowest inertia reduction rates. The negative rates observed for cwrt indicate an inertia increase.
From Table 3, the results reveal wdtw the fastest method and the psa the slowest one. For nlaaf and psa the estimated centroids have a drastically large dimension (i.e. a length around \(10^4\)) making these approaches unusable for large time series datasets. The nlaaf and psa methods are highly time consuming, largely because of the progressive increase of the centroid length during the pairwise combination process. The centroid lengths for the remaining methods are equal to the length of the initial medoid (Table 3). Finally, psa appears greatly slower than nlaaf; this is due to the hierarchical clustering on the whole time series.
We finally visualize here some of the centroids obtained by the different methods to compare their shape to the one of the time series they represent. Figures 8, 9, 10, 11 and 12 display the centroids obtained by the mentioned methods for the class “funnel” of cbf, “cyclic” of data set cc, the spiral1, “begin” of bme and “down” of data set umd, respectively. As one can note, for global datasets, almost all approaches succeed in obtainging centroids more or less similar to the initial time series. However, we observe generally less representative centroids for nlaaf and psa, with a drastically large centroid’s length of about \(10^4\) elements vs. \(10^2\) for the other methods. For the more complex (e.g. spiral), Fig. 10 shows the ability of the dba method, in obtainging centroids more or less similar to the initial time series, but one should circumvent the noise problem. Finally, as shown in the figures, the wdtw provide the most representative centroid for all datasets. For complex dataset, one can see the ability of the wdtw to circumvent the noise problem and to reveal the locally shared signature.

cbf-“funnel” centroids: (a) ground through, (b) nlaaf, (c) psa, (d) cwrt, (e) dba, (f) wdtw

cc-“cyclic” centroids: (a) ground through, (b) nlaaf, (c) psa, (d) cwrt, (e) dba, (f) wdtw

spiral-1 centroids: (a) ground through, (b) nlaaf, (c) psa, (d) cwrt, (e) dba, (f) wdtw

bme-“begin” centroids: (a) ground through, (b) nlaaf, (c) psa, (d) cwrt, (e) dba, (f) wdtw

umd-“down” centroids: (a) ground through, (b) nlaaf, (c) psa, (d) cwrt, (e) dba, (f) wdtw
4 Conclusion
The dtw is among the most frequently used metrics for time series in several domains as signal processing, temporal data analysis and mining or machine learning. However, for time series clustering, approaches are generally limited to k-medoid to circumvent time series averaging under dynamic time warping and tricky multiple temporal alignments. The present study compares the major progressive and iterative time series averaging methods under the dynamic time warping. The experimental validation is based on standard datasets in which time series share similar behaviors within classes, as well as on more complex datasets. They are multidimensional, noisy and share only local characteristics. Both the quantitative evaluation, based on an inertia criterion (i.e. irr), time and space complexity, and the qualitative one (consisting in the visualization of the centroids obtained by different methods) show the effectiveness of wdtw method to provide fastly accurate time series averaging for standard and complex datasets. The centroids obtained through wdtw are more representative of the set than the centroids obtained by the other methods, and the time requirements are lower than the rest. Following wdtw approach, the dba, the second best method that iteratively optimizes an inertia criterion, reaches higher values than the non iterative methods (nlaaf, psa and cwrt).
Notes
References
Abdulla, W.H., Chow, D., Sin, G.: Cross-words reference template for DTW-based speech recognition systems. In: Proceedings of TENCON, vol. 2, pp. 1576–1579 (2003)
Hautamaki, V., Nykanen, P., Franti, P.: Time-series clustering by approximate prototypes. In: 19th International Conference on Pattern Recognition (2008)
Petitjean, F., Ketterlin, A., Gançarski, P.: A global averaging method for dynamic time warping, with applications to clustering. Pattern Recogn. 44, 678–693 (2011)
Zhou, F., De la Torre, F.: Generalized time warping for multi-modal alignment of human motion. In: Computer Vision and Pattern Recognition (CVPR), pp. 1282–1289. IEEE (2012)
Kruskall, J.B., Liberman, M.: The symmetric time warping algorithm: from continuous to discrete. Time Warps Journal. Addison-Wesley (1983)
Sakoe, H., Chiba, S.: Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech, Signal Process. 26, 43–49 (1978)
Sankoff, D., Kruskal, J.B.: Time Warps, String Edits, and Macromolecules: The Theory and Practice of Sequence Comparison. Cambridge University Press, Addison-Wesley, Reading (1983)
Thompson, J.D., Higgins, D.G., Gibson, T.J.: CLUSTAL W: improving the sensitivity of progressive multiple sequence alignment through sequence weighting, position-specific gap penalties and weight matrix choice. J. Comput. Biol. 22(22), 4673–4680 (1994)
Notredame, C., Higgins, D.-G., Heringa, J.: T-Coffee: a novel method for fast and accurate multiple sequence alignment. J. Mol. Biol. - J MOL BIOL 302(1), 205–217 (2000)
Sze, S.-H., Lu, Y., Yang, Q.: A polynomial time solvable formulation of multiple sequence alignment. J. Comput. Biol. 13(2), 309–319 (2006)
Carrillo, H., Lipman, D.: The multiple sequence alignment problem in biology. SIAM J. Appl. Math. 48, 1073–1082 (1988). Society for Industrial and Applied Mathematics, Philadelphia, PA, USA
Gupta, L., Molfese, D., Tammana, R., Simos, P.: Nonlinear alignment and averaging for estimating the evoked potential. IEEE Trans. Biomed. Eng. 43(4), 348–356 (1996)
Soheily-Khah, S., Douzal-Chouakria, A., Gaussier, E.: Progressive and iterative approaches for time series averaging. In: ECML-PKDD (Advanced Analytics and Learning on Temporal Data) (2015)
UCI Machine Learning Repository. http://archive.ics.uci.edu/ml/
UCR Time Series Classification Archive. http://www.cs.ucr.edu/~eamonn/
Niennattrakul, N., Ratanamahatana, C.: On clustering multimedia time series data using K-means and dynamic time warping. In: International onference on IEEE Multimedia and Ubiquitous Engineering, MUE 2007, pp. 733–738 (2007)
Niennattrakul, N., Ratanamahatana, C.: Shape averaging under time warping. In: ECTI-CON 6th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology. IEEE, vol. 2, pp. 626–629, May 2009
Zhou, F., De la Torre, F.: Canonical time warping for alignment of human behavior. Adv. Neural Inf. Process. Syst. 22, 2286–2294 (2009)
Frambourg, C., Douzal-Chouakria, A., Gaussier, E.: Learning multiple temporal matching for time series classification. In: Tucker, A., Höppner, F., Siebes, A., Swift, S. (eds.) IDA 2013. LNCS, vol. 8207, pp. 198–209. Springer, Heidelberg (2013)
Soheily-Khah, S., Douzal-Chouakria, A., Gaussier, E.: Generalized \(k\)-means-based clustering for temporal data under weighted and kernel time warp. J. Pattern Recogn. Lett. 75, 63–69 (2016). doi:10.1016/j.patrec.2016.03.007
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Soheily-Khah, S., Douzal-Chouakria, A., Gaussier, E. (2016). A Comparison of Progressive and Iterative Centroid Estimation Approaches Under Time Warp. In: Douzal-Chouakria, A., Vilar, J., Marteau, PF. (eds) Advanced Analysis and Learning on Temporal Data. AALTD 2015. Lecture Notes in Computer Science(), vol 9785. Springer, Cham. https://doi.org/10.1007/978-3-319-44412-3_10
Download citation
DOI: https://doi.org/10.1007/978-3-319-44412-3_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-44411-6
Online ISBN: 978-3-319-44412-3
eBook Packages: Computer ScienceComputer Science (R0)