
Abstract
The authors have previously shown that, by using shadow media that transforms the color and shapes of shadows to transform the relationship between individuals and shadow media, a variety of bodily expressions is created from individual performers. In this study, we attempted to support co-creative expressions by transforming the relationships between performers and shadow media space. Specifically, we developed shadow media utilizing point clouds (dappled shadows) and made it possible to freely alter the light source position of shadow media. In addition, we implemented a shadow media system that displays a shadow agent moving according to the movements of a group of performers (a virtual light source robot) on a stage, and used its position as a light source. As a result, we found that the expression space of performers expanded in comparison with existing shadow media systems. This result shows the possibility that this system supports the emergence of co-creative expressions.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
Focusing on shadows, which are inseparable from the body, the authors have researched a shadow media system to support the emergence of bodily expressions. This system allows displaying artificial shadows with modified colors or shapes (shadow media) from one’s feet. We’ve shown that, by creating gaps between the body and shadow, a variety of bodily expressions can be created from an individual 1–3]. On the other hand, in terms of co-creative expressions in which multiple people create expressions together using their bodies, the positioning of performers on stage – that is, the relationship between performers and the expression space –plays an important role [4]. Thus, if we are able to modify the relationship between performers and the shadow media space in bodily expressions by groups of performers using shadow media, there is a possibility that we could support the emergence of co-creative expressions. As a first step in realizing this research, in this study, we focused on changing the size and direction of all shadow media according to the light source position of shadow media, we tried to freely control of the three-dimensional position of a shadow media light source. In addition, we developed a movable shadow agent (virtual light source robot) that uses the light source position of the shadow media as its own position. Then, we aimed to support the emergence of co-creative expressions by displaying that shadow on the stage along with the shadow media of the group of performers.
Real-time 3D processing of body images is necessary to control the light source positions of shadow media for multiple people. In relation to this, the authors have previously developed a shadow media system (3D shadow media system, Fig. 1 (a)) that utilizes a 3D virtual space and skeleton data (3D models of people) [4]. As a result, this allowed for freely controlling the posture and movement of shadow media individually for each part, and controlling the position of a virtual light source for the shadow media. However, in the existing system, attempting high-resolution contours of shadow media led to a massive increase in 3D model data for people, making it difficult to perform real-time 3D processing for the shadow media of multiple people.

3D shadow media and point cloud shadow media
On the other hand, in CG research, in recent years high-speed 3D image processing has been implemented without sacrificing accuracy by using point cloud data [5, 6]. In this study, the authors propose and develop a new shadow media system using a 3D virtual space and point cloud data. The main feature of this system is the ability to position point clouds for human bodies and virtual light sources in a 3D virtual space, then use the shadows created from the point clouds generated by these light sources as shadow media. In other words, this system speeds up image processing by processing 3D shadow media without constructing 3D models of people composed of multiple surfaces (Fig. 1).
Due to the fact that expressing shadow media using point clouds creates blank space (“yohaku” in Japanese) in the shadow media, this opens the possibility of evoking the creation of a variety of images from these blank spaces. Moreover, it is possible that if these blank spaces (point cloud density) are modified by shadow media depth position, this will create thickness in shadow media which has heretofore been seen as flat, enhancing the feeling of depth and solidity of the shadow media.
Below, in this paper, we explain the details of the point cloud shadow media (dappled shadows) using point cloud data and the virtual light source robot. As we also attempted to support co-creative expressions using this system, we also report on those results.
2 Point Cloud Shadow Media (Dappled Shadows)
2.1 Dappled Shadow Generation Method
In this study, we developed a system composed of the following four-step process using Unity (Unity Technologies) to generate point cloud shadow media (Fig. 2). These processes are performed in advance by constructing a 3D virtual space that recreates the real space within Unity.

Process of generation of point cloud shadow media
-
(1)
Obtaining point cloud data of the body image
A depth image (512 × 424 pixels) captured by Kinect v2 (Microsoft) was used to obtaining point cloud data of the body image. By removing all objects in the image other than the person, such as the floor, walls, and screen, we obtaining the point cloud data for only people in the shadow media space.
-
(2)
Drawing point cloud data
We generate a body image by positioning 3D objects at each point in the point data within the virtual space. It is possible to alter object size, shape and the distribution pattern when drawing the point cloud data.
-
(a)
Object size
Object size can be set arbitrarily. However, shadow media may not be displayed when the size is small. In this study, the object size was set to above 5.0 mm.
-
(b)
Object shape
Object shapes can be selected from cubes, regular tetrahedrons, spheres, rectangular plates, or two of these plates arranged in a cross pattern (Fig. 3).
Fig. 3. 
Object shape
-
(c)
Object distribution pattern
In this study, we allowed changing the object distribution pattern by reducing the point cloud density of the objects composing the body image (the amount of data in the point cloud data) according to one of the following four methods (Fig. 4).
Fig. 4. 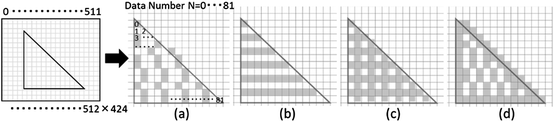
Object distribution pattern: (a) Constant, (b) Border, (c) Lattice, (d) Contour enhancement
-
(a)


Figure 4(a) shows point cloud data composing a body image culled uniformly at fixed intervals (point cloud density D[point/Voxel]). Below, we refer to this object distribution pattern as “constant.” Figure 4(b) shows the object displayed with point cloud data displayed only for points positioned at N Interval_l × i (N Interval_l and i are positive integers) rows in the depth image (424 rows × 512 columns). This distribution pattern is referred to as “border.” Figure 4(c) shows the object displayed with point cloud data displayed only for points positioned at N Interval_r × i (N Interval_r and i are positive integers) rows or N Interval_c × i (N Interval_c and i are positive integers) columns in the depth image. This distribution is referred to as “lattice.” Figure 4(d) shows the result of performing contour detection on the point cloud data and displaying all objects at points on the contour. Contour detection is performed by comparing the distance of points in the depth direction among data number i and four points positioned above, below and to the left and right (data number i − 512, i + 512, i − 1, i + 1). Specifically, if even one of these four points has a distance of above 0.5 m in the depth direction, the point for data number i is determined to be a contour point. In this study, by performing this type of contour processing on the dappled shadow, we implemented high-resolution expression of shadow media contours. Drawing methods for objects other than those at contour points (points within the contour) were selected from the constant, border and lattice methods described above.
-
(3)
Generating shadow media (dappled shadows)
Multiple object shadows created from point light sources (virtual light sources) set in the 3D virtual space and multiple objects (body image point cloud data) distributed in process (2) were shown on a screen or floor in the virtual space.
-
(4)
Projecting shadow media in real space
The shadow image of body image point cloud data generated in process (3) was displayed at the feet of participants in the real space using a projector. Below, we call this shadow media “dappled shadow.” In this study, even when shadow media for three people simultaneously existed within the media space, we were able to display shadow media (dappled shadows) for all people at 30 fps. An example of the dappled shadow generated in this study is shown in Fig. 5.
Fig. 5. 
Projecting dappled shadow

2.2 Dappled Shadow Features
Next, we examined the features and function of the dappled shadows developed in this study as shadow media. Specifically, we focused on dappled shadow point cloud density D and whether or not contours were enhanced, and checked for differences between the dappled shadow and the shadow generated by the projector in the real space (real shadow) The parameters for the three types of dappled shadows used in this experiment are given below.
-
Basic dappled shadow; size: 10 mm, shape: cube, distribution pattern: constant (D = 5[point/Voxel]), no contour enhancement.
-
Dappled shadow with contour enhancement; size: 10 mm, shape: cube, distribution pattern: constant (D = 5[point/Voxel]), contour enhancement.
-
Culled dappled shadow; size: 10 mm, shape: cube, distribution pattern: constant (D = 10[point/Voxel]), no contour enhancement.
In this experiment, we asked participants to move freely within the space for the first 30 s with the dappled shadow (or real shadow) displayed from their feet. Then, they were asked to perform bodily expressions through the dappled shadow for 60 s.
Figure 6 shows a view of the experiment. Participants commented that the basic dappled shadow “felt strong” and “felt solid and round.” Regarding the dappled shadow with contour enhancement, participants commented that “it felt solid,” “it felt more like me than myself,” and “I felt like shadow could speak to me.” Regarding the culled dappled shadow, participants commented that “it did not feel as solid as the other dappled shadows” and “it feels like flowers or snow.” When we compared real shadows to the dappled shadows, participants commented that the dappled shadow “felt like it stimulated me internally,” “felt like it drew out expressions from me,” and that “it allowed for natural expressions.” Particularly, participants commented that the dappled shadow with contour enhancement “felt the most like my own shadow of the four shadow media, including the real shadow.”

Experiment of the features and function of dappled shadows with one person: (a) Real shadow, (b) Basic dappled shadow, (c) Dappled shadow with contour enhancement, (d) Culled dappled shadow.
This suggests that the dappled shadows developed in this study have an existence even stronger than real shadows, and that they possess even greater image emergence ability and expression emergence ability than the shadow media previously developed [1]. The authors believe that, this is caused by the enhancement of the ontological connection between one’s body and shadow by the incompleteness of the media formed by blank spaces, because the dappled shadows are formed from point clouds.
3 Virtual Light Source Robot
3.1 Virtual Light Source Robot Positional Control Method
The virtual light source robot is composed of a cylindrical main body (0.30 m diameter × 0.50 m height) and a virtual light source positioned on top of it (Fig. 7). In this study, we allow changing the light source position of shadow media for the group of performers by moving this robot in the 3D virtual space. Also, in this study, we displayed the shadow of this robot as well as the shadow media (dappled shadows) of the group of performers in the real space (Fig. 8).

Virtual light source robot

Movement and the presentation of the virtual light source robot
In this study, as a starting point for researching support for the emergence of co-creative expression through transforming the relationship between performers and the shadow media space, we designed the following three operating modes for the virtual light source robot (Fig. 9).

Operating modes for the virtual light robot
-
(1)
Random mode
In random mode, the virtual light source robot is moved irrespective of the movements of the group of performers that exist within the shadow media space (Fig. 9(a)). In particular, the planar movement direction and its update interval for the virtual robot are set randomly within ranges of 0 to 360° and 3.0 to 10 s, respectively.
-
(2)
Center of gravity origin symmetry mode
In center of gravity origin symmetry mode, the virtual light source robot is moved according to the collective movements of the performers. Specifically, we calculate the position of the center of gravity for the standing positions of the group of performers, then move the virtual light source robot to a position symmetrical to that position with respect to the origin (Fig. 9(b)). The origin is the center point of the shadow media space. A Laser Range Finder (LMS100, SICK) was used to measure the standing positions of the performers.
-
(3)
Circumscribed mode
Due to the fact that the center of gravity position for the group of performers and virtual light source robot generally matches the origin, movement of detail including virtual light source robot is small in center of gravity origin symmetry mode. Circumscribed mode aims to shift the overall center of gravity position through the collective movements of the performers. To accomplish this, the virtual light source robot is moved in smallest enclosing circle enclosing the group of performers (Fig. 9(c)). The angular velocity of the circular movement is determined by the velocity of the center of gravity position for the standing positions of the group of performers.
3.2 Co-creative Expression Space Expandability
-
(1)
Experiment with one person
Using the shadow media system using the virtual light source robot and dappled shadows described above, we first examined whether or not it could support the emergence of bodily expressions in the case of a single performer. The participant in this experiment was an adult male who is a beginner at bodily expressions. In this experiment, we directed the participant to perform bodily expressions freely for 60 s in a shadow media space measuring 6.0 m × 5.0 m × 2.8 m. We used the dappled shadow with contour enhancement as the shadow media, which was assessed as “feeling the most like my own shadow” in the experiment in Sect. 2.2. We set the following four conditions for the virtual light source robot. For condition 3, we used the position of the participant as the center of gravity position. In condition 4, the virtual light source robot was moved in a circular motion along a circle with a radius of 0.5 m centered on the position of the participant.
-
Condition 1: immobile (fixed light source)
-
Condition 2: random mode
-
Condition 3: center of gravity origin symmetry mode
-
Condition 4: circumscribed mode
-
Figure 10 illustrates this experiment. We received comments from the participant indicating that, in comparison with condition 1, in condition 2, “I often looked back without regard to the shadow media.” In condition 3, the participant commented that “I could express while turning in various directions and being conscious of my own position.” Moreover, in condition 4, the participant commented that “I moved my point of view in various directions and my movements became larger,” and “I felt that I was being moved by my shadow.” In addition, participant movement locus in the experiment (Fig. 11) showed that, particularly in condition 4, the movement range of the participant expanded in the depth direction with respect to the screen surface in comparison with condition 1. These results show that modifying the light source position of shadow media using a virtual light source robot can expand the expression space of performers.

Experiment of virtual light robot with one person: (a) Immobile, (b) Random mode, (c) Center of gravity origin symmetry mode, (d) Circumscribed mode, (e) Sequence photographs of expression in circumscribed mode.

Data position measurement: (a) Immobile, (b) Random mode, (c) Center of gravity origin symmetry mode, (d) Circumscribed mode. (Color figure online)
-
(2)
Experiment with multiple people (two people)
Next, we examined whether the shadow media system using a virtual light source robot and dappled shadows could support the emergence of bodily expressions for multiple people (two people). In this experiment, we directed participants to perform hand contact improvisation [7] in which they put their hands together and create improvisational, bodily expressions with their hands for 60 s. The conditions for the experiment were identical to those given in the experiment with one participant described above.
This experiment is shown in Fig. 12. Movement locus of the two participants in the experiment (Fig. 13) shows that, in conditions 2–4, the moving range is expanded in comparison with condition 1. Moreover, Fig. 14, which shows the frequency distribution for distance between the two participants, shows that in comparison with condition 1, in conditions 2–4 there were more instances of distances above 2 m. These results suggest that, in case with the existence of the virtual light source robot, the two participants used a wide space to perform bodily expressions.

Experiment of virtual light robot with two people: (a) Immobile, (b) Random mode, (c) Center of gravity origin symmetry mode, (d) Circumscribed mode, (e) Sequence photographs of expression in circumscribed mode.

Data position measurement: (a) Immobile, (b) Random mode, (c) Center of gravity origin symmetry mode, (d) Circumscribed mode. (Color figure online)

Frequency distribution for interpersonal distance: (a) Immobile, (b) Random mode, (c) Center of gravity origin symmetry mode, (d) Circumscribed mode
In addition, we received comments in conditions 2–4 such as “I wanted to touch the robot,” “I wanted to chase the robot,” and “I felt like I was creating an expression together with my partner and the robot.” These comments suggest that the performers felt the existence and movement of the robot through its shadow, and that its movement facilitated the bodily expressions of the performers. Interestingly, in the experiment with two participants, we received the following comment from a participant: “the dappled shadows were different from previous shadow media in that, even when the shadow media were overlapped, we could distinguish the anteroposterior relationship between the two, making it easier to create expressions.” This feature is not seen in other shadow media.
4 Summary
In this study, we considered the possibility that we could support the emergence of co-creative expressions by modifying the relationship between performers and shadow media space. Thus, we developed a system to control the three-dimensional position of a virtual light source for shadow media. In order to achieve this, we designed and developed a shadow media system using point clouds. We were able to create dappled shadows with a higher sense of solidity and high-resolution contours in comparison with existing shadow media. Moreover, we constructed a system that displays the shadow of a virtual light source robot that sets the light source for the shadow media along with the shadow media of the performers. We implemented moving the position of this robot (a virtual light source) according to the movements of the group of performers. Performing bodily expressions using these systems demonstrated that the expression space of the performers was expanded in comparison with existing shadow media systems. These results suggest that it is possible to support the emergence of co-creative expressions through the virtual light source robot.
References
Miwa, Y.: Co-creative expressions and communicability support. J. Soc. Instrum. Control Eng. 51(11), 1016–1022 (2012)
Miwa, Y., Ishibiki, C.: Shadow communication: system for embodied interaction with remote partners. In: Proceeding of CSCW 2004, pp. 467–476 (2004)
Miwa, Y., Itai, S., Watanabeand, T., Nishi, H.: Shadow awareness: enhancing theater space through the mutual projection of images on a connective slit-screen. Leonardo J. Int. Soc. Arts Sci. Technol. 44(4), 325–333 (2011). (SIGGRAPH 2011 Art paper)
Kajita, Y., Takahashi, T., Miwa, Y., Itai, S.: Designing the embodied shadow media using virtual three-dimensional space. In: Yamamoto, S., de Oliveira, N.P. (eds.) HIMI 2015. LNCS, vol. 9173, pp. 610–621. Springer, Heidelberg (2015). doi:10.1007/978-3-319-20618-9_60
Aitor, A., Marton, Z., Tombari, F., Wohlkinger, W., Potthast, C., Zeisl, B., Rusu, R., Gedikli, S., Vincze, M.: Point cloud library. IEEE Robot. Autom. Mag. 19, 80–91 (2012)
Mitra, N.J., Nguyen, A.: Esting surface normal in noisy point cloud data. In: Proceedings of the Nineteenth Annual Symposium on Computational Geometry, pp. 322–328 (2003)
Watanabe, T., Miwa, Y.: Duality of embodiment and support for co-creation in hand contact improvisation. J. Adv. Mech. Des. Syst. Manuf. 6(7), 1307–1319 (2012)
Acknowledgments
This study received support from a JSPS Grant-in-Aid for Scientific Research (B) (Principal investigator: Yoshiyuki Miwa, No. 26280131) and the support of the “Principal of emergence for empathetic “Ba” and its applicability to communication technology” project at the RISE Waseda University. Graduate students Yusuke Kajita, Kento Yamaguchi, Ibuki Mizuno, Takemi Watanuk, Takahiro Sugano et al. assisted with system development and experiment execution. The authors wish to express their gratitude here.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Hayashi, M., Miwa, Y., Itai, S., Nishi, H., Yamakawa, Y. (2016). Creation of Shadow Media Using Point Cloud and Design of Co-creative Expression Space. In: Yamamoto, S. (eds) Human Interface and the Management of Information: Applications and Services. HIMI 2016. Lecture Notes in Computer Science(), vol 9735. Springer, Cham. https://doi.org/10.1007/978-3-319-40397-7_25
Download citation
DOI: https://doi.org/10.1007/978-3-319-40397-7_25
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-40396-0
Online ISBN: 978-3-319-40397-7
eBook Packages: Computer ScienceComputer Science (R0)