
Abstract
In this paper, we introduce a fully automatic approach to construct action datasets from noisy Web video search results. The idea is based on combining cluster structure analysis and density-based outlier detection. For a specific action concept, first, we download its Web top search videos and segment them into video shots. We then organize these shots into subsets using density-based hierarchy clustering. For each set, we rank its shots by their outlier degrees which are determined as their isolatedness with respect to their surroundings. Finally, we collect upper ranked shots as training data for the action concept. We demonstrate that with action models trained by our data, we can obtain promising precision rates in the task of action classification while offering the advantage of a fully automatic, scalable learning. Experiment results on UCF11, a challenging action dataset, show the effectiveness of our method.
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
High quality datasets play important roles in computer vision and pattern recognition tasks. With sufficient and high quality training data, most pattern recognition methods have achieved promising results. As data sources, most recently released datasets exploit Web data which are extremely numerous and easy to obtain. However, since Web data are generated and uploaded by general users, data corresponding to the concept of interest account for only a small proportion among retrieved results. Therefore, constructing high quality datasets with Web data requires extensive human effort of manual annotation. In case of constructing action datasets, in general, we need annotators to localize relevant video parts (shots) of the pre-defined actions in video sources by watching the whole of them carefully. Since the task is too exhausted, even largest action datasets cover not more than 101 concepts with only several thousands of video shots. This situation has given rise to the need for constructing action datasets with less human effort.
Previous work which aim to automatically obtain action shots of specific action concepts from noisy data [1–3] generally require textual information provided together with videos such as movie script [1] or metadata (tags) [2, 3]. Laptev et al. [1, 4, 5] proposed methods to automatically associate movie scripts with actions and obtain video shots in movie representing particular classes of human actions. Their methods actually can help reduce human effort on construction of realistic action database. However, targeted videos are only the movies with available scripts and trainable actions are limited to only actions appeared in movies. On the other hand, our proposed system can be applied to extract data for various types of actions which are distributed over much more immense video source.
As an approach which also targets on more various actions and use broader data sources, Nga et al. [2, 6, 7] proposed to collect video shots corresponding to any kind of action concept using Web videos. They conducted experiments for more than 100 action concepts and obtained promising results. Their work is the most related work to ours and treated as our baseline in this paper. According to their methods, before video downloading, videos are ranked based on usage frequencies of tags. Videos which have tags with high co-occurrence frequencies are considered as relevant videos. Therefore, their approach cannot make use of videos without associated tags. In this work, we propose an approach which also exploits videos without tags. As visual features, we extract temporal features using a ConvNet trained on UCF-101 dataset [8] following a recent state-of-the-art approach for action recognition [9].
In action recognition, in almost cases, a primary action is considered as a target in both training videos and test videos. Even with only one action, the task is still challenging due to variability of human actions. The actions can look different when they are seen from different views or operated by different people. They even can be manipulated in many disparate ways. Thus, to obtain good recognition performance, training data should capture actions in many different conditions. In other words, a high quality action database should reflect as much as possible the diversity of the concept. However, previous approaches for automatic construction of action database do not cope with concept diversity. Especially, our baseline [6] applies VisualRank [10] which is originally an image ranking method with a visual feature based similarity matrix to rank shots. Shots sharing the most visual characteristics with others are ranked to the top and selected as relevant shots. Therefore, this method tends to obtain only visually similar shots. In this paper, we propose to group related shots into clusters before shot ranking by a hierarchy clustering method [11]. Different clusters while sharing some appearance characteristics still hold unique aspects of the concept. Consequently, our obtained shots are much more diverse than shots obtained by the baseline [6]. According to our experiment results, the more diverse the training data are, the better recognition performance we can achieve.
After obtaining clusters, we rank instances in each cluster by outlier factor [12]. Outliers are instances deviating from the major distribution of the data. In other words, outliers belong to sparse regions while relevant instances lie in dense regions. The most densely linked instances from each cluster are ranked to the top and then used as training data for the concept. As action concepts, we experiment on those used in YouTube (also called as UCF11) dataset [13]. Furthermore, we train action models with our automatically collected data and test them on the test data of these datasets. We performed action classification by a popular supervised framework with the intention of comparing classification performance using manually constructed dataset and the dataset collected automatically by our proposed approach. Experiment results show that even though our data are not qualified as “clean” data as standard training data (manually collected data), classification rates are promising and show potential for development of approaches for automatic construction of action databases. Our work is inspired by [14] which uses density analysis of Web images for automatic image dataset construction.
Our contributions can be summarized as follows: (1) We propose a simple yet effective and feasible approach for fully automatic construction of action datasets; (2) We address intra-class variations within a concept resulting in multiple groups of shots; (3) We validate our automatically constructed datasets on standard datasets to show the potential of automatic construction for action datasets. To the best of our knowledge, we are the first to do that.
Remainder of this paper is constructed as follows. We first introduce some more related work for dataset construction and action recognition in Sect. 2. In Sect. 3 we describe our proposed approach. We then report the results of our experiments in Sect. 4 and finally, conclude this work in Sect. 5.
2 Related Work
We discuss here several related work on two topics: dataset construction and action recognition.
Dataset Construction: Many recent work have tackled the problem of building qualified training datasets automatically from data retrieved by Web search engines but most of them have been applied only on images [14–17]. Collins et al. [15] presented a framework for incrementally learning object categories from Web image search results. Given a set of seed images a non-parametric latent topic model is applied to categorize collected Web image. Schoroff et al. [16] proposed to first filter out the abstract images (e.g., drawings, cartoons) and then use text and metadata surrounding the images to re-rank the images searched in Google. Chen et al. [14] proposed NEIL (Never Ending Image Learner) which is a program using a semi-supervised learning algorithm that jointly discovers common sense relationships and labels instances of the given visual categories. NEIL learns multiple sub-model automatically for each concept. As an approach which also alleviates the multi-modal problem of concepts, [17] divides seed images into multiple groups and trains classifiers on each group separately. Images obtained from different groups usually capture some different looks of the concept.
As for automatic construction of action datasets using unconstrained videos, there are very few approaches as we introduced in the previous section. Moreover, these approaches require textual information associated with videos [1, 2]. Adrian et al. [3] proposed a method to learn automatically concept detectors from YouTube videos for any kind of concepts including objects, actions and events. Their method also requires textual description of the target concept provided by YouTube users. Furthermore, each concept must be manually assigned a canonical YouTube category and low-quality videos are eliminated to improve the quality of downloaded material. In this work, we propose a fully automatic approach for action dataset building which exploits only visual features of raw videos retrieved from video sharing sites. Our approach neither needs additional information nor manual annotation.
Action Recognition: Most action recognition methods followed the standard framework of pattern recognition. First, a sufficiently large corpus of training data is collected, in which the concept labels are generally obtained through expensive human annotation. Next, concept classifiers are learned from the training data. Finally, the classifiers are used to detect the presence of the actions in the test data. We also adopt this standard framework in action recognition task, except that instead of using provided training data, we use our automatically collected data to train concept classifiers.
As popular video presentation, successful hand-crafted features such as HOG, HOF or MBH extracted along dense trajectories [18] have been adopted and developed in many work recently [19, 20]. These features are generally encoded by Bag-of-Visual-Words or Fisher Vectors. In very recent years, followed by their success in image recognition field, deep learning Convolutional Neural Networks (CNNs) have received great attention and obtained promising results in action recognition [9, 21, 22]. Following this trend, we also train a temporal CNN using a method proposed in [9] and use this model to extract features from video shots.
3 Approach
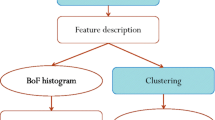
In this work, we present an approach which autonomously extracts from noisy Web videos relevant video shots for given action concepts. Our approach consists of three steps: shot collection, shot clustering and shot selection. See Fig. 1 for the illustration of our proposed framework. In shot collection, we download videos of the concepts and segment them to shots. These shots are then organized into subsets by hierarchical clustering [11]. Finally, relevant shots are ranked by outlier factors [12] and selected from each of all clusters using a simple selection strategy. In the followings, we explain in detail each step.

Framework of our approach for automatic construction of action shot datasets which consists of three steps: shot collection, shot clustering and shot ranking.
3.1 Shot Collection
We first prepare keywords for given action concepts. The concepts can be defined in any form: either “verb” (such as “dive”) or “verb+non-verb” (such as “throw+hammer”, “cut+in+kitchen”) or “non-verb” (such as “pole vault”). In case verb included in the keyword, we search for its videos in both forms: “verb” and “verb-ing” (such as “diving”, “throwing+hammer”). We filter out videos belonging to “entertainment”, “music”, “movies”, “film” and “games” categories during searching since these categories generally contain extremely long videos. Top search results are downloaded and segmented into video shots using color histogram. RGB histograms of every frame are computed and then segmentation points are put between frames whose histogram intersection is larger than a predefined constant. Each shot represents one single scene. For each concept, we download around 100–200 videos and obtain around 700–2000 shots.
3.2 Shot Clustering
With shots obtained after above step, we group related shots into clusters before shot ranking and selection. This step helps deal with concept diversity. With web data retrieved for a given concept, there will also be common characteristics shared among subsets of data. Therefore, rather than hard clustering data into a specific number of subsets as some approaches which also aim to deal with intra-class variations in concepts [17, 23], we use hierarchy clustering which allows different clusters to share the same instances. We adopt OPTICS (“Ordering Points To Identify the Clustering Structure”) [11] to find clusters. Rather than the popular Mean Shift, OPTICS is prefer due to its computational efficiency. The hierarchical structure of the clusters can be obtained based on the density of the data distributed around their points. Follows are our brief introduction of this clustering algorithm. For the detail, please refer to [11].
The basic idea of a density-based clustering algorithm is that for each object of a cluster the neighborhood of a given radius has to contain at least a given minimum number of objects (MinPts). Clusters are formally defined as maximal sets of density-connected objects. We introduce here some important definitions while briefly reviewing OPTICS algorithm.
Let p be an object from a dataset D, k be a positive integer and d be a distance metric, then (Fig. 2):

k-distance and reachability distance (k = 4)
Definition 1: \(k-\mathrm{dist}(p)\), the k-distance of p, is defined as the distance d(p, o) between p and object \(o \in D\) satisfying: 1. at least k objects \(q \in D\) having \(d(p,q) \le d(p,o)\), and 2. at most (k-1) objects \(q \in D\) having \(d(p,q) < d(p,o).\)
Definition 2: \(N_{k-\mathrm{dist}(p)}(p) = \{ q | q \in D, d(p,q) \le k-\mathrm{dist}(p)\}\) denotes the k-distance neighborhood of p.
Definition 3: \(reach-\mathrm{dist}_{k}(p,o) = max({k-\mathrm{dist}(o),d(p,o)})\) represents reachability distance of an object p with respect to object o.
The OPTICS-algorithm computes a “walk” through the data, and calculates for each object the smallest reachability-distance with respect to an object considered before it in the walk. A low reachability-distance indicates an object with a cluster, and a high reachability-distance indicates a noise object or a jump from one cluster to another cluster. Each cluster should hold different characteristics of the concept. The differences are caused by variations of conditions which videos taken under (viewpoints, scenes, illumination and so on) or diversity in meaning of the concept itself.
3.3 Shot Selection
For each obtained cluster, we assign outlier factor for each shot based on outlying property relative to its surrounding space. Differently from shot clustering step, in this step surrounding space of a shot is limited within in its own cluster. We use calculation method of LOF (Local Outlier Factor) proposed in [12]. There are numerous methods of outlier detection which have been proposed so far in the literature [24]. Among those, LOF is one of the most efficient and easy-to-implement. Especially, it makes use of computation during clustering (\(k-\mathrm{dist}, N_{k-\mathrm{dist}}\)). Therefore, we chose it to simplify the calculation process. Actually, the combination of OPTICS and LOF is quite natural and has been employed in some previous work [25]. LOF of a point p is formally defined as follows.
LOF of an object is calculated as the average ratio of its MinPts-dist and that of its neighbors within MinPts-dist. A large MinPts-dist corresponds to a sparse region since the distance to the nearest MinPts neighbors is large. In the contrast, a small MinPts-dist means that the density is high. In each cluster, shots are ranked according to LOF. Shots with low LOF degrees are considered as relevant shots and brought to the top of the cluster. MinPts is the most important parameter for finding clusters and calculating LOF. Larger MinPts means more clusters. Optimized value of MinPts varies on the concept. In our experiments, we try several values and report the one with the best performance on average.

We propose a simple shot selection strategy which can guarantee that shots are selected from all clusters. Let \(N_s\) be number of shots we want to collect for a concept and \(N_c\) be number of clusters we obtained. Since some shots are shared among some clusters, simply selecting top \(N_s/N_c\) shots from each cluster obtains less than \(N_s\) shots. Our selection strategy tries to keep selecting shots from clusters which are still available until number of selected shots reaches \(N_s\) or no available clusters left. An “available cluster” must have more shots than twice of its maximal number of shots to be selected. This definition of available cluster is inspired by experimental results in the baseline [6] which show that only shots ranked among top-half should be considered as relevant shots. Selection order for clusters is determined by the mean LOF of their shots. Our selection strategy is summarized in Algorithm 1.
In Algorithm 1, \(N_t\) and \(N_m\) represent the total number of selected shots and the maximal number of shots can be selected from each cluster, respectively. \(\mathbb {C} = \{C(c)| c = 1:N_c\}\) is the group of obtained clusters. Each cluster C(c) has following fields: C(c).is means index of start-to-select shot, C(c).ns means the number of shots to select from C(c), C(c).ts is the total number of shots in C(c) and C(c).av represent the availability of C(c). If C(c) is available, \(C(c).av = 1\), otherwise \(C(c).av = 0\). Collection of shots in C(c) is denoted as C(c).S. Since shots are ranked as mentioned above, C(c).S[1] is supposed to be the most relevant shot and C(c).S[C(c).ts] should be the least relevant one in cluster C(c). \(\mathbb {S}\) is the collection of selected shots.
4 Experiments and Results
4.1 Experimental Setup
We conduct two experiments: dataset construction and action recognition to validate the efficiency of our method. For dataset construction, we use 11 actions defined in UCF YouTube Action (UCF11) dataset [13]: “basketball shooting”, “biking/cycling”, “diving”, “golf swinging”, “horse riding”, “soccer juggling”, “swinging”, “tennis swinging”, “trampoline jumping”, “volleyball spiking”, and “walking with a dog”. Note that in this experiment, we do not use videos of that dataset. Our videos are automatically collected from Web source (YouTube) as described in Sect. 3.2. As for action recognition experiment, we use videos of that dataset which contains a total of 1168 videos. The dataset is challenging due to large variations in camera motion, object appearance and pose, object scale, viewpoint, cluttered background and illumination conditions. We train three SVM multi-class classifiers: one based on our collected data, one based on data retrieved by the baseline [2] and one based on standard training data. Finally, we use these classifiers to perform action recognition on the standard test data.

Average precisions by the proposed method in different cases of n when \(N = 100\).

Average precisions by the proposed approach and the baseline in different cases of N.
Our baseline is our most related work [2]. According to this method, first videos are ranked based on usage frequencies of tags. Shots are collected from videos which have tags with high co-occurrence frequencies. Next shots are ranked using VisualRank [10] which is a ranking method with a visual feature based similarity matrix. Since it became hard to obtain tag information, we could not perform tag co-occurrence based video ranking step as proposed in the baseline. Here we use our method of shot collection and apply their idea of using VisualRank to shot ranking to compare with our proposed method of shot selection which composed of diversity based shot clustering and LOF based shot ranking. We show that our method can obtain higher precision rate for most of experimented actions and importantly, our results look more diverse than those by the baseline in all cases.
As distance metric, we use Rank-order distance [26] which has been demonstrated as a better density measurement than commonly used Euclidean distance [17]. We train a temporal ConvNet using UCF101 dataset [13] (split 1) following the approach proposed in [9] except that we insert a normalization layer between pool2 layer and conv3 layer. Using this modified network architecture, we obtained slightly better performance than the original one: 82.1 % versus 81.2 % [9] on UCF101 (split 1). We use 2048 dimensional full7 features extracted using the trained temporal ConvNet. MinPts is set as T / n where T is total number of shots for a concept obtained after shot collection step (Sect. 3.1) and n is a constant. Ten values of n are experimented: 10, 20,..., 100.

Results of diversity evaluation. As opposed to the baseline, our approach retrieved more diverse shots from various videos. This explains for significant improvements in recognition performance (Fig. 6).

Results of action recognition with automatically obtained training data. As shown in this figure, action model trained with shots obtained by the proposed method achieved better recognition rates in all cases of N.
4.2 Dataset Construction
In this experiment, we want to validate the quality of automatically constructed dataset regarding precision and diversity. Precision rate is calculated as percentage of relevant shots among top N shots following our baseline [2]. Three values of N are taken into consideration: 30, 50, 100. We evaluate relevance of upper ranked shots manually.
First we examine the effect of parameter settings on the performance of our proposed approach. Figure 3 shows average precision rates in different cases of n with \(N = 100\). According to our empirical results, \(n = 50\) obtained best performance. All results related to our proposed method that we report from here on refer to the case of \(n = 50\). Figure 4 compares average precision rates in different cases of N between the proposed approach and the baseline. As shown in this figure, the proposed approach outperformed the baseline in all cases of N, especially when \(N \ge 50\). In all of our results, “Proposed” means our approach and “Baseline” corresponds to VisualRank based shot ranking with our shot collection. Precision for all actions when \(N = 100\) are shown in Table 1.
As shown in Table 1, for most of the actions, more relevant shots could be ranked to the top using our method. In many cases, top ranked shots by the baseline are although relevant to the concept but actually look similar to each other (See Fig. 7 for some example results). Even though average precision is not significantly improved, shots retrieved by our proposed method look much more diverse as shown in the followings.
Regarding evaluation for diversity of ranking results, we use evaluation method as described in [7]. Diversity score of a ranking result is defined as the ratio of the number of identical videos in its top ranked N video shots to N. This definition is based on the fact that shots from the same video tend to look similar. The results of diversity evaluation are summarized in Fig. 5. As shown in Fig. 5, overall, the diversity score was significantly enhanced by using the proposed method. Figure 7 shows some examples of relevant shots among top 15 shots obtained by our method and the baseline.

Relevant shots among top 15 shots retrieved by our proposed method and the baseline for “golf_swing” and “horse_riding”. As seen here, shots by the baseline tend to look similar while shots by our method are taken from various view points against different background.
4.3 Action Recognition
In this experiment, we validate performance of our automatically collected training data for the task of recognition on standard test data. To evaluate recognition performance, we follow the original setup [13] using leave one out cross validation for a pre-defined set of 25 folds. Average accuracy over all classes is reported as performance measure. We use top ranked N shots to train action classifiers. Similar to the previous experiment, three values of N are taken into consideration: 30, 50 and 100.
Figure 6 shows recognition accuracy rates by the proposed approach and the baseline in all cases of N. As shown in this figure, we obtained significant precision gain compared to the baseline. The recognition precision was boosted from approximately 35 % to 44 % in case of \(N = 100\). This can be explained mostly by the improvements regarding diversity in the results (Sect. 4.2). Since many shots obtained by the baseline look similar, the information we can gain from them is much less than that from shots retrieved by our proposed approach. These results verified the fact that a high quality action database should reflect as well as possible the diversity of the concepts. The precision rate is further improved as more top-ranked shots are used to train.
In case of using standard training data, the average recognition rate was 81.5 %. This result is comparable to other approaches on the same dataset [18, 27]. [27] with probabilistic fusion of multiple motion descriptors and scene context descriptors achieved 73.2 %. Especially, the state-of-the-art motion hand-crafted features (dense trajectory based MBH) [18] achieved 80.6 %. To the best of our knowledge, there are no reports with CNN features on this dataset for us to compare.
5 Conclusions
In this paper, we proposed a fully automatic approach for action dataset construction with noisy Web videos. Our approach aims to solve the problem of limitation in quantity of training data for the task of action recognition. In our experiments, we first constructed a database for 11 actions in UCF11 dataset using YouTube videos with our proposed approach. We then employed this database to train action classifiers and applied them to classify standard test data of UCF11. Even though collected training data by it is still far from “clean data” as standard training data, it offers the advantage of a fully automatic, scalable learning and shows the potential for development of approaches for automatic construction of action databases.
References
Laptev, I., Marszalek, M., Schmid, C., Rozenfeld, B.: Learning realistic human actions from movies. In: Proceedings of IEEE Computer Vision and Pattern Recognition (2008)
Do, H.N., Yanai, K.: Automatic extraction of relevant video shots of specific actions exploiting Web data. Comput. Vis. Image Underst. 118, 2–15 (2014)
Adrian, U., Christian, S., Markus, K., Thomas, M.B.: Learning automatic concept detectors from online video. Comput. Vis. Image Underst. 114, 429–438 (2010)
Marszalek, M., Laptev, I., Schmid, C.: Actions in context. In: Proceedings of IEEE International Conference on Computer Vision (2009)
Duchenne, O., Laptev, I., Sivic, J., Bach, F., Ponce, J.: Automatic annotation of human actions in video. In: Proceedings of IEEE Computer Vision and Pattern Recognition, pp. 1491–1498 (2009)
Do, H.N., Yanai, K.: Automatic construction of an action video shot database using web videos. In: Proceedings of IEEE International Conference on Computer Vision, pp. 527–534 (2011)
Do, H.N., Yanai, K.: VisualTextualRank: an extension of visualrank to large-scale video shot extraction exploiting tag co-occurrence. IEICE Trans. Inf. Syst. e98–D, 166–172 (2015)
Khurram, S., Amir, R.Z., Mubarak, S.: UCF101: A Dataset of 101 Human Actions Classes from Videos in the Wild. CoRR abs/1212.0402 (2012)
Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recognition in videos. In: Proceedings of Advances in Neural Information Processing Systems, pp. 568–576 (2014)
Jing, Y., Baluja, S.: VisualRank: applying pagerank to large-scale image search. IEEE Trans. Pattern Anal. Mach. Intell. 30, 1870–1890 (2008)
Mihael, A., Markus, M.B., Hans-Peter, K., Jorg, S.: OPTICS: ordering points to identify the clustering structure. In: Proceedings of the ACM SIGMOD International Conference on Management of Data, pp. 49–60 (1999)
Chiu, A.L.M., Fu, A.C.: Enhancements on local outlier detection. In: Proceedings of IEEE Database Engineering and Applications Symposium, pp. 298–307 (2003)
Jingen, L., Jiebo, L., Shah, M.: Recognizing realistic actions from videos. In: Proceedings of IEEE Computer Vision and Pattern Recognition, pp. 1996–2003 (2009)
Chen, X., Abhinav, S., Abhinav, G.: Neil: extracting visual knowledge from web data. In: Proceedings of IEEE International Conference on Computer Vision (2013)
Collins, B., Deng, J., Li, K., Fei-Fei, L.: Towards scalable dataset construction: an active learning approach. In: Forsyth, D., Torr, P., Zisserman, A. (eds.) ECCV 2008, Part I. LNCS, vol. 5302, pp. 86–98. Springer, Heidelberg (2008)
Schroff, F., Criminisi, A., Zisserman, A.: Harvesting image databases from the web. IEEE Trans. Pattern Anal. Mach. Intell. 33, 754–766 (2011)
Xia, Y., Cao, X., Wen, F., Sun, J.: Well begun is half done: generating high-quality seeds for automatic image dataset construction from web. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014, Part IV. LNCS, vol. 8692, pp. 387–400. Springer, Heidelberg (2014)
Wang, H., Schmid, C.: Action recognition with improved trajectories. In: Proceedings of IEEE International Conference on Computer Vision, pp. 3551–3558 (2013)
Oneata, D., Verbeek, J., Schmid, C.: Action and event recognition with fisher vectors on a compact feature set. In: Proceedings of IEEE International Conference on Computer Vision, pp. 1817–1824 (2013)
Peng, X., Zou, C., Qiao, Y., Peng, Q.: Action recognition with stacked fisher vectors. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014, Part V. LNCS, vol. 8693, pp. 581–595. Springer, Heidelberg (2014)
Jeff, D., Lisa, A.H., Sergio, G., Marcus, R., Subhashini, V., Kate, S., Trevor, D.: Long-term Recurrent Convolutional Networks for Visual Recognition and Description. CoRR abs/1411.4389 (2014)
Joe, Y.H.N., Matthew, J.H., Sudheendra, V., Oriol, V., Rajat, M., George, T.: Beyond Short Snippets: Deep Networks for Video Classification. CoRR abs/1503.08909 (2015)
Golge, E., Duygulu, P.: ConceptMap: mining noisy web data for concept learning. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014, Part VII. LNCS, vol. 8695, pp. 439–455. Springer, Heidelberg (2014)
Chandola, V., Banerjee, A., Kumar, V.: Anomaly detection: a survey. Proc. ACM Comput. Surv. 41, 15:1–15:58 (2009)
Breunig, M.M., Kriegel, H.-P., Sander, J., Ng, R.T.: OPTICS-OF: identifying local outliers. In: Żytkow, J.M., Rauch, J. (eds.) PKDD 1999. LNCS (LNAI), vol. 1704, pp. 262–270. Springer, Heidelberg (1999)
Chunhui, Z., Fang, W., Jian, S.: A rank-order distance based clustering algorithm for face tagging. In: Proceedings of IEEE Computer Vision and Pattern Recognition, pp. 481–488 (2011)
Reddy, K., Shah, M.: Recognizing 50 human action categories of web videos. Mach. Vis. Appl. 24, 971–981 (2013)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Do, N.H., Yanai, K. (2016). Automatic Construction of Action Datasets Using Web Videos with Density-Based Cluster Analysis and Outlier Detection. In: Bräunl, T., McCane, B., Rivera, M., Yu, X. (eds) Image and Video Technology. PSIVT 2015. Lecture Notes in Computer Science(), vol 9431. Springer, Cham. https://doi.org/10.1007/978-3-319-29451-3_14
Download citation
DOI: https://doi.org/10.1007/978-3-319-29451-3_14
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-29450-6
Online ISBN: 978-3-319-29451-3
eBook Packages: Computer ScienceComputer Science (R0)
