
Abstract
In Cloud computing environments, computing resources are available for users, and they only pay for used resources The most important issues in cloud computing are scheduling and energy consumption which many researchers worked on them. In these systems a scheduling mechanism has two phases: task prioritization and processor selection. Different priorities may cause to different makespan and for each processor which assigned to the task, the energy consumption is different. So a good scheduling algorithm must assign priority to each task and select the best processor for them, in such a way that makespan and energy consumption be minimized. In this paper, we proposed a two phase’s algorithm for scheduling, named TETS, the first phase is task prioritization and the second phase is processor assignment. We use three prioritization methods for prioritize the tasks and produce optimized initial chromosomes and assign the tasks to processors which is an energy-aware model. Simulation results indicate that our algorithm is better than previous algorithms in terms of energy consumption and makespan. It can improve the energy consumption by 20 % and makespan by 4 %.
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction and Backgrounds
Cloud computing provide a new model for IT Services. In such models, scalable and virtual resources are provided through Internet [1]. As you know, cloud computing models need minimal interactions with IT leaders and service providers. As important features of cloud computing, we can refer to: access to resources through the Internet apart from the used devices, easy implementation, resource sharing, easy maintenance, “pay per use” model, network scalability and security [2]. Cloud computing model can provide any services such as: computing resources, web based services, social networks and telecommunication for its users [3]. As you know, the same as other systems, there are several challenges in cloud computing too, the most significant challenge which indicates the quality of provided services are: the price of service production and consequently the prices that user have to pay for using the services, makespan, and energy consumption.
In general, we can decompose large applications into a set of smaller tasks and execute them on multiple processors, in order to reduce the execution time. But these tasks always have some dependencies that represent the precedence constraints; it means that the results of some tasks must be ready before a particular task can be executed. We use DAG graph for represent these tasks and their dependencies. The nodes of a DAG represent the tasks and edges represent the precedence between tasks. Because of the importance of energy consumption, diverse techniques, such as: Circuit techniques, Memory Optimization, Hardware Optimization, Resource Hibernation, Commercial Systems, DVS have been proposed [4, 5]. Among them, DVS can enable processors to adjust voltage supply levels (VSLs) based on the requirements of input jobs aiming to reduce power consumption. In this paper we investigate the scheduling and energy consumption problems. We propose a new and efficient algorithm for task scheduling that takes into account both criteria, the makespan and energy consumption. Our new approach is hybrid of GA algorithm and ECS approach [6] which is an energy conscious method. Simulation results show the superiority of the new approach against the previous approaches.
The remainder of this paper is organized as follows. After presenting some related methods in Sect. 2, the system model includes application, system, energy and scheduling introduced in Sect. 3. The proposed approach and solution presented in Sect. 4. The results of simulation and conclusion are discussed in Sects. 5 and 6, respectively.
2 Related Work
In this section we investigate some state-of-the-art recent works in task scheduling and energy consumption for cloud computing. In [7] a resource allocation framework provided for cloud resources. At first the optimal networked cloud mapping problem is formulated as a mixed integer programming (MIP), and then a heuristic methodology is proposed for mapping of resource requests onto a shared computing resources. The aim of this method is to reduce the cost of resource mapping and guarantee the QoS for customers. In [8] based on the task ordering and Cloud resource allocation mechanisms, a family of fourteen scheduling heuristics for concurrently executing BoTs in Cloud environments and reallocation mechanisms are proposed. The aim of these schedulers is to increase the efficiency of resources. These proposed methods are combined in an agent-based approach, and able to concurrent and parallel execution of BoTs. TRACON [9] is a novel task and resource allocation control framework which can mitigate the interference effects from concurrent data-intensive applications and can recognize the levels of concurrent I/O operations, so it can greatly improves the overall system performance. In this model when tasks arrived the scheduler generate a number of possible assignment and based on that scheduler makes the scheduling decision and assigns the tasks to different servers. None of the above mentioned methods considered energy consumption. Authors in [6] presented an approach, called ECS, which is an energy-aware scheduling algorithm in order to optimize the makespan and energy consumption and also reduce the heat emission to the environment. This algorithm uses DVS method which enables the processors to adjust their voltage levels according to the requirements of input tasks and select the appropriate processor for task execution. Authors in [10] by exploiting the genetic algorithm, Proposed an efficient task scheduling algorithm. The superiority of their algorithm is related to assign priority to each task and produce optimal initial population. Using the proposed method leads to efficient use of resources and reduce the run time but it does not optimize energy consumption. Reference [3] proposed a parallel bi-objective and energy-aware scheduling for parallel applications. This algorithm is hybrid of genetic algorithm and DVS method. The aim of this method was to reduce the energy consumption and makespan but it generates the initial population randomly which is not good for Precedence-constrained parallel applications. Authors in [11] proposed an approach for energy aware scheduling just for private clouds, the model used the pre-power technique and least-load-first algorithm in order to reduce the response time and load balancing respectively. Authors in [12] presented a near optimal scheduling based on carbon/energy is proposed which works based on the heterogeneity of databases. And besides the energy consumption, reduce the impact of energy consumption on environment but makespan is not optimum in this way.
3 System Model
The cloud computing system considered in this paper consists of a set \( p \) of \( m \) heterogeneous processes that are fully interconnected with a high-speed network. Each processor is Dynamic Voltage Scaling (DVS) enabled; it means that each processor is able to operate with different voltages scales as a set \( v \) which can adjust according to the input task. Since clock frequency transition overheads take a negligible amount of time (about 10–15 μs) [6]. These overheads are not considered in our paper and the inter processor communications are performed with the same speed on all links.
3.1 DAG Computation and Communication Model
We present an application by a Directed Acyclic Graph (DAG), in which the vertices representing tasks (maximum \( n \)) and edges between vertices representing execution precedence between tasks. Such graph is called tasks graph. And for a pair of dependent tasks \( T_{i} \) and \( T_{j} \) if the execution of \( T_{j} \) depends on the output from the execution of \( T_{i} \), then \( T_{i} \) is the predecessor of \( T_{j} \) and \( T_{j} \) is the successor of \( T_{i} \). So \( pred\left( {T_{i} } \right) \) and \( succ(T_{i} ) \) are denoted as the set of predecessor tasks and successor tasks of task \( T_{i} \). Also, there is an entry task and exit task in a DAG. The entry task \( T_{entry} \) is the task of the application without any predecessor, and the exit task \( T_{exit} \) is the final task whit no successor [6, 13]. A weight is associated with each vertex and edge. The vertex weight denoted as \( W_{d} (T_{i} ) \) and it is the amount of time to perform the task \( T_{i} \). And the edge weight denoted as \( C_{d} (T_{i} ,T_{j} ) \), represents the amount of communication between \( T_{i} \) and \( T_{j} \). Each task in a DAG application must be executed on one processor and one voltage. If tasks of one application are assigned to different processors, the communication cost between them cannot be ignored and when tasks are scheduled on the same processor, the communication cost is equal to 0. Besides, we assumed that the precedence relations and the execution precedence is predetermined and won’t change during the scheduling or execution and all processors are available during the processor assignment.
Communication cost between task \( T_{i} \) and \( T_{j} \) is as the edge weight, presented as \( C_{ij} \) and is equal to the amount time needs to data transmission from \( T_{i} \) (which is on the \( p_{k} \)) to \( T_{j} \) (which is on the processor \( p_{l} \)). Only when tasks are assigned to different processors there is communication cost else the communication cost is 0. \( B \) is the system bandwidth and is fixed for all links, so we can consider it as 1 (\( B(p_{k} ,p_{l} ) = 1, \) \( \forall p \in [1,m] \)). Note that, we neglect communication startup cost. Therefore, the communication cost for \( T_{i} \) is calculated as Eq. (1):
The speed at which processor \( p \) executes the task \( T_{i} \) is denoted as \( S(T_{i} ,p_{k} ) \) [10] and the computation cost of task \( T_{i} \) which is running on processor \( p \) is as Eq. (2):
and the average computation cost of task \( T_{i} \) is calculated as Eq. (3):
Figure 1 demonstrates a simple DAG containing 8 tasks and Table 1 shows the processor speed for each tasks and computation costs (\( W \)).

A simple DAG containing 8 tasks (nodes) [10]
To generate efficient initial chromosome we used three prioritization methods (upward rank, downward rank and a combination of upward-downward rank) and based on that the task priorities is shown in Table 1.
Upward rank shows the average remaining cost to finish all tasks. We show the upward rank as \( Rank_{U} (T_{i} ) \) and it is calculated as Eq. (4) [10]:
In which \( T_{j} \) is the set of immediate successors of task \( T_{i} \) and \( \overline{C}(T_{i} ,T_{j} ) \) is the average communication cost between \( T_{i} \) and \( T_{j} \). The upward rank is computed by traveling the task graph starting from exit task \( T_{exit} \) to entry task \( T_{entry} \).
The downward rank as \( Rank_{D} (T_{i} ) \) is calculated as Eq. (5) [10]:
In which \( T_{j} \) is the set of immediate predecessors of task \( T_{i} \). the downward rank is calculated starting from entry task \( T_{entry} \) to exit task \( T_{exit} \).
The combination of upward-downward rank is calculated as Eq. (6):
We assume that a DAG has a topology (see [14]) as the same as the Fig. 1 and there are 3 processors as shown in Table 1. There are 2 numbers for each node, one is the task name (\( T_{x} \)) and the other is the computation cost for each task (see Fig. 1 nodes) which is calculated in Table 1 (see cost columns) (Table 2).
3.2 Energy Model
Our energy model is derived from the power consumption model of CMOS-based microprocessor and cooling systems [6]. The power consumption of CMOS circuit includes static and dynamic powers. Because dynamic power is the most significant factor, we consider only dynamic power. Hence, the power model is defined as
According to Eq. (7), the most significant factors for power consumption are voltage \( v \), clock frequency \( a \), capacitance load \( C \) and activity factor which show the number of switches per clock cycle. Equation (7) clearly indicates that the supply voltage is the dominant factor, which its reduction can be influential for power reduction. Because voltage is directly related to frequency \( v \propto f \) and \( v{ \sim }f \), the relationship between power can be \( P = aCv^{3} \). Therefore, energy consumption for each job on each processor is as
where \( T \) is the average time takes to respond the tasks (\( T_{y} \)). So, we can write
The task scheduling problem in this paper is the process of allocating n tasks to p processors. Each processor is DVS-enabled. The aim of the proposed schedule is to reduce the makespan and energy consumption altogether. Makespan is the finish time of the latest task in graph. The aim of reducing energy consumption is reduce the heat released into the environment.
4 Proposed Approach (TETS)
In this paper we propose a new method named TETS for task scheduling in cloud computing environment which is based on the genetic algorithm and ECS method [6, 15]. TETS starts with three prioritization method. The aim of prioritization methods is to generate optimized initial chromosomes and prevent to random production of chromosomes. In mapping phase ECS tries to assign the tasks to the proper processors in order to minimize the energy and makespan. In TETS after produce a schedule by genetic algorithm, objective function is called and calculates the time and energy consumption for each gene, and then selects the best option for that gene. Thus the second and third components of chromosomes are completed. In the following the details of TETS is explained.
4.1 Chromosome Display
Each solution (chromosome) contains a sequence of N gene. Each gene represents a task, a processor and a voltage as \( T_{i} \), \( p_{j} \), \( v_{j,k} \), respectively. It means that task \( t_{i} \) allocated to processor \( p_{j} \) and voltage \( v_{k} \). Therefore, we have a vector with three rows (\( T_{i} \), \( p_{j} \), \( v_{j,k} \)) as initial generated chromosome. Iterative method of the genetic algorithms help us in order to modify the current chromosome and generate a new modified one according to the presented fitness function which is minimizing the energy besides the cost.
4.2 Fitness Function
The fitness of chromosomes is calculated based on the finish time of each task and needed energy to perform that task, the fitness function is shown in Eq. (10). In which a task is assigned to the first processor and first voltage and then for each voltage the relative superiority (RS) is calculated. If the current RS is better than previous RS, this task is assigned to the current processor and voltage.
where \( E_{c} \) is the current energy, \( E_{p} \) is the previous energy according to (9), \( FT_{c} \) is the current finish time, \( FT_{p} \) is the previous finish time, \( ST_{c} \) is the current start time, \( ST_{p} \) is the previous start time.
4.3 Parent Selection
We use the roulette-wheel selection method to select parents, in this method some chromosomes with higher fitness (for example 20 % of initial population) are copied into the new population, in this way chromosomes with different fitness have a chance to be selected. Then parents will be selected randomly according to the number of crossover we want to do in the next population.
4.4 Crossover Operation
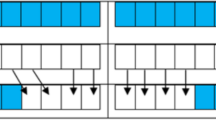
In crossover operation, two chromosomes are selected randomly as parents and two crossover points are selected on parents and divides them into two parts (we use Two-point crossover technique). Everything between the two points is swapped between the parent organisms, rendering two child organisms (Fig. 2).

Crossover operation with two-point (6th and 14th cells) crossover technique
4.5 Mutation Operation
Mutation operation works on the first part (task) of genes. In mutation operator, new chromosomes are generated by exchange two genes of chromosomes with maintain the precedence constraints. At first we select a random point (gene \( T_{i} \)) in chromosome then we find the first successor \( T_{i} \) from the selected point to the end of priority queue (\( T_{j} \)). Then we exchange the Ti with the first predecessor of \( T_{j} \) named \( T_{k} \) [6]. The mutation operator is shown in Fig. 3.

Mutation operation
4.6 Termination Condition
Termination condition is the number of generations. When the number of generations reaches the desired number, the algorithm ends. In this paper, the number of generations is 100. Finally, Fig. 4 shows the algorithm of TETS.

Pseudocode of TETS
5 Simulation Results
The proposed algorithm is simulated in MATLAB. A DAG is represented by a class, whose members include an array of subtasks, a matrix of the speed represents the processor speed to run each subtask, and a matrix of communication cost between pair of subtasks, an array of successors of each subtask, two arrays for input and output degree of subtasks respectively, and array of computational costs of subtasks. TETS is performed on a personal computer with 2.4 GHz and 4 GB RAM. The value of parameters (selected values of mutations are reached by trial and error) is listed in Table 3.
5.1 TETS Evaluation
In this subsection, we test TETS in order to evaluate its convergence and improvements in various tasks and processors. Figure 5a, b show the improvement of TETS according to the number of tasks and the number of processors, respectively. Experiments show that our approach improves on average by increasing the tasks and processors. Figure 5b shows that increasing the processors cause to improve the results of TETS (Fig. 6).

Improvement according to the number of 5a: tasks, and, 5b: processors. a Improvement according to the number of tasks. b Improvement according to the number of processors

5.2 Comparisons
To demonstrate the TETS performance, we compared it against ECS [6] and Hybrid GA [3]. Simulation is done based on the sample data of [10] which contains a set of 8 task which related to each other and arranged in a graph. Considered factors in this paper are makespan and energy consumption. As explained in Sect. 4.2 the fitness function is sum of the time and energy consumption. This function tries minimizing the makespan and energy consumption. To study the performance of the solutions obtained from the comparison of these algorithms we ran them for 100 iteration and for 20, 40, 60, 80 and 120 tasks. The results of executing three algorithms represented in Fig. 5a, b. As demonstrated in Fig. 5a, b by increasing the number of tasks, TETS performs better compared to the ECS and Hybrid GA in terms of makespan and energy consumption. This comparison indicates the improvements over the average of the other two algorithms. Table 4 compares the Pareto solutions of the hybrid approach and the solution of ECS with TETS approach. The comparison is made according to the number of tasks and the number of processors. The third column shows the average number of obtained Pareto solutions. The forth column gives the percentage of Pareto solutions that improves the Hybrid GA solution on the two objectives simultaneously and the last column shows the percentage of Pareto solutions that improves the ECS solution on the two objectives simultaneously. As indicated in the last line of the table, TETS provided 16.76 % solutions on average, and 83.04 % and 19.77 % of the Pareto solutions found by ECS and Hybrid GA respectively on the two objectives simultaneously. In addition, Table 4 shows that when there are more tasks, more Pareto solutions can be found, and the percentage of Pareto solutions dominating the ECS solution and Hybrid GA solution increases. To determine the contribution of TETS, in terms of the values of makespan and energy consumption, we compare the solution provided by ECS and Hybrid GA to only one solution of the Pareto set provided by TETS. And the a comparison is done between solutions.
6 Conclusions
In this paper we investigate the scheduling problem of parallel application with precedence constraints. In most presented methods only makespan was considered and they did not consider energy consumption. So given the importance of makespan and energy consumption, a new method namely TETS, for scheduling was presented which is enable to optimize the makespan and energy consumption. TETS is hybrid of genetic algorithm and ECS method in which genetic algorithm is used for generating chromosomes and ECS is used for assigning processor and voltage to tasks. In addition mutation operation and crossover operation do according to the precedence between tasks so TETS always produce optimized solutions (schedule). Simulation results show that TETS improves on average the results obtained in the literature in energy saving and makespan. Indeed, the energy consumption is reduced by 49 % and the completion time by 14 %.
References
Shojafar, M., Javanmardi, S., Abolfazli, S., Cordeschi, F.: Fuge: a joint meta-heuristic approach to cloud job scheduling algorithm using fuzzy theory and a genetic method. Cluster Comput. 18(2), 829–844 (2015)
Jadeja, Y., Modi, K.: Cloud computing-concepts, architecture and challenges. In: Computing, Electronics and Electrical Technologies (ICCEET), 2012 International Conference on, pp. 877–880. IEEE (2012)
Mezmaz, M., Melab, N., Kessaci, Y., Lee, Y.C., Talbi, E.-G, Zomaya, A.Y., Tuyttens, D.: A parallel bi-objective hybrid metaheuristic for energy-aware scheduling for cloud computing systems. J. Parallel Distribut. Comput. 71(11), 1497–1508 (2011)
Shojafar, M., Cordeschi, N., Amendola, D., Baccarelli, E,: Energy-saving adaptive computing and traffic engineering for real-time-service data centers. In: International Conference on Communications, 2015. ICC’15, pp. 9866–9872. IEEE (2015)
Hajj, H., El-Hajj, W., Dabbagh, M., Arabi, T.R.: An algorithm-centric energy-aware design methodology. Very Large Scale Integr. (VLSI) Syst. IEEE Trans. 22(11), 2431–2435 (2014)
Lee, Y.C., Zomaya, A.Y.: Minimizing energy consumption for precedence-constrained applications using dynamic voltage scaling. In: CCGRID’09, pp. 92–99. IEEE (2009)
Papagianni, C., Leivadeas, A., Papavassiliou, S., Maglaris, V., Cervello-Pastor, C., Monje, A.: On the optimal allocation of virtual resources in cloud computing networks. Comput. IEEE Transa. 62(6), 1060–1071 (2013)
Gutierrez-Garcia, J.O., Sim, K.M.: A family of heuristics for agent-based elastic cloud bag-of-tasks concurrent scheduling. Future Gener. Comput. Syst. 29(7), 1682–1699 (2013)
Chiang, R.C., Huang, H.H.: Tracon: interference-aware scheduling for data-intensive applications in virtualized environments. In: Proceedings of 2011 International Conference for High Performance Computing, Networking, Storage and Analysis, p. 47. ACM (2011)
Xu, Y., Li, K., Hu, J., Li, K.: A genetic algorithm for task scheduling on heterogeneous computing systems using multiple priority queues. Inf. Sci. 270, 255–287 (2014)
Li, J., Peng, J., Lei, Z., Zhang, W.: An energy-efficient scheduling approach based on private clouds. J. Inf. Comput. Sci. 8(4), 716–724 (2011)
Garg, S.K., Yeo, C.S., Anandasivam, A., Buyya, R.: Energy-efficient scheduling of hpc applications in cloud computing environments. arXiv preprint arXiv:0909.1146 (2009)
Shojafar, M., Pooranian, Z., Abawajy, J.H., Meybodi, M.R.: An efficient scheduling method for grid systems based on a hierarchical stochastic petri net. J. Comput. Sci. Eng. 7(1), 44–52 (2013)
Raduca, E., Adrian, P., Raduca, M., Drugarin, C.A., Silviu, D., Rudolf, C.: The algorithm for going through a labyrinth by an autonomous. In: Ingenieria Informatica, pp. 1–4 (2015)
Anghel, C.V., Dorica, S.M., Silviu, D.: Method for programming an autonomous vehicle using pic 16f877 microcontroller. In: Information and Communication Technologies International Conference-ICTIC 2014, vol. 3, pp. 317–320 (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Shojafar, M., Kardgar, M., Hosseinabadi, A.A.R., Shamshirband, S., Abraham, A. (2016). TETS: A Genetic-Based Scheduler in Cloud Computing to Decrease Energy and Makespan. In: Abraham, A., Han, S., Al-Sharhan, S., Liu, H. (eds) Hybrid Intelligent Systems. HIS 2016. Advances in Intelligent Systems and Computing, vol 420. Springer, Cham. https://doi.org/10.1007/978-3-319-27221-4_9
Download citation
DOI: https://doi.org/10.1007/978-3-319-27221-4_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-27220-7
Online ISBN: 978-3-319-27221-4
eBook Packages: EngineeringEngineering (R0)