
Abstract
How to achieve the correct detection result for the infrared small targets is the important and challenging issue in infrared applications. In this paper, a small infrared target detection method based on low-rank representation is proposed, which used the low-rank representation (LRR) to decomposed infrared image to background component and target component, then the detection task could be finished through threshold processing. In different experimental conditions, the results show that our method based on low-rank representation not only has higher detection performance but also reduce the false alarm rate effectively.
Similar content being viewed by others


Keywords
1 Introduction
Infrared small target detection is always one of the key techniques of the infrared guidance system and a hotspot research for military applications. On one hand, the small targets are usually submerged in the background clutter and the heavy noise with low SNR because of the transmitting and scattering of the atmospheric with long observation distance. On the other hand, the targets in images appear as a dim point which make the targets have no obvious feature and texture information useful. therefore, these two factors make the infrared small target detection more difficult [1].
Up to now, the methods of the infrared target detection can be classified into two categories [2]: detection based on single-frame and detection based on sequential frames. Considering the sequential detection methods are processed based on the prior information of the target and background, which would cause the methods cannot reach satisfactory performance because the information are hardly obtained in military application, the single-frame detection algorithms have attracted a lot of attentions of researchers who have proposed various single-frame detection methods which can be divided into three classes: background suppressing methods [3–5], target singularity analysis methods [6, 7], and some method using machine learning theory [8, 9].
Recently, based on the original data is drawn from several low-rank subspaces, low-rank representation(LRR) [10] was proposed for subspace segmentation or recovery, which can decompose the data matrix into the clean matrix described by the self-expressive dictionary with low-rank coefficients and the sparse noise. Considering the underlying structure revealing and background modeling ability of low-rank representation with large errors or outliers, we propose a small infrared target detection method based on low-rank representation in this paper. This method decomposes the infrared image to target component and noise component on the basis of low-rank decomposition and background modeling. So the proposed method have better detection performance compared to the baseline algorithms as the experiments results shown.
2 Low-Rank Representation
Considering the given observation matrix \( X \in R^{m \times n} \) was generated from a low-rank matrix \( X_{0} \in R^{m \times n} \) with some of its entries corrupted by an additive error \( E \in R^{m \times n} \), the original data \( X_{0} \) can be recovered by the following regularized rank minimization problem which is adopted by the established robust principal component analysis (RPCA) method [11]
Where \( \lambda \) is a parameter and \( \left\| \bullet \right\|_{l} \) indicates a certain regularization strategy, such as the squared Frobenius norm \( \left\| \bullet \right\|_{F} \) used for modeling specify the Gaussian disturbance, the \( l_{0} \) norm \( \left\| \bullet \right\|_{0} \) adopted for characterizing the random corruptions, and the \( l_{2,0} \) norm \( \left\| \bullet \right\|_{2,0} \) used to deal with sample specific corruptions and outliers. Based on the RPCA which assumes that the underlying data structure is a single low-rank subspace, the IPI model was proposed to small infrared target detection in [12]. However, considering the data is usually drawn from a union of multiple subspaces in most cases. The formula of low-rank representation is as follows:
where A is a dictionary that linearly spans the union of subspaces. The minimize \( Z^{*} \) indicates the lowest-rank representation of data X with respect to a dictionary A. Apparently, Eq. (2) is a highly non-convex optimization problem, but we can relax it by solving the convex problem:
where \( \left\| \bullet \right\|_{*} \) denotes the nuclear norm of a matrix (i.e., the sum of its singular values).
When \( A = I \), LRR degenerates to RPCA which can be seen as a special case of LRR model, an appropriate A can ensure that the LRR can reveal the true underlying data structure. Usually, the observation data X is chosen to be the dictionary. So, Eq. (3) becomes:
In order to adopt the augmented Lagrange multiplier method to solve the problem, We Introduce one auxiliary variables and convert Eq. (4) to the following equivalent formula:
which equals to solving the following augmented Lagrange function:
Where \( Y{}_{1}^{{}} \) and \( Y{}_{2}^{{}} \) are Lagrange multipliers and μ > 0 is a penalty parameter. By fixing the other variables, the Eq. (6) can be solved with respect to J, Z and E respectively and then updating the multipliers. We can employ the different regular strategies to noise for different applications. The solution steps are following as Algorithm 1 in the case of \( l_{2,1} \) norm:

The step 1 and 2 of the Algorithm 1 which are convex problems both have closed form solutions. The step 1 can be solved by the following lemma:
Lemma 1 [13]:
For the matrix \( Y \in R^{n \times d} \) and \( \mu > 0 \), the problem as following has the only analysis solution.
Its solution can be described by singular value thresholding operator.
\( U \in R^{n \times r} \), \( V \in R^{d \times r} \) and \( \sigma = (\sigma_{1} ,\sigma_{2} ,\sigma_{3} \ldots \sigma_{r} ) \in R^{r \times 1} \) can be achieved by singular value decomposition of matrix Y, \( Y = U\sum V^{T} \) and \( \sum = diag(\sigma ) \).
The step 2 can be solved by lemma 2:
Lemma 2:
Let \( Q = [q_{1} ,q_{2} , \ldots ,q_{i} , \ldots ] \) be a given matrix. If the optimal solution to
is W∗, then the i-th column of W∗ is
3 LRR Based Small Target Detection
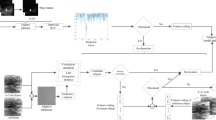
An infrared image can be viewed as a combination of two components such as background, target. The background of the infrared image is transitions slowly which also has the property of non-local self-correlation, and the target is small with respect to the whole image. Thus we consider the background as low-rank matrix and the target as sparse matrix. Meanwhile, the small target is often located in heterogeneous background which causes the background data coming from multi-subspace. Thus, we decompose the original infrared image into two components images by using the LRR model, then the target location is determined by thresholding the target image. The whole method of small target detection based on LRR is depicted as Fig. 1 and the steps of the detection method are as follows:


Diagram of the small detection method based on LRR
-
(1)
Image Data Reconstruction. we need to reconstruct the original image data \( X \in R^{m \times n} \) to the matrix \( \tilde{X} \in R^{{k^{2} \times w}} \) by using a sliding window \( k \times k \), which could increase the similarity of image blocks and reduce the rank of image data, from top and left to down and right with sliding steps s, and each sub-block extracting by the sliding window was vectorized as a column of matrix \( \tilde{X} \), where w is the number of the sub-blocks.
-
(2)
Image Decomposing. By solving Eq. (6), the original infrared image X can be decomposed into background and target by using LRR model with the reconstructed image data \( \tilde{X} \) as input.
-
(3)
Locating the Target. After obtaining the background component AZ, we could locate the target by the following steps: first, we calculate the target component by \( T = \tilde{X} - AZ \). Then, T is inverse transformed to get the real target image \( \tilde{T} \). Because the sliding step is usually less than the size of the window, the same position pixel in the final target image have different values from the adjacent sub-blocks, so we adopt the calculation of \( v = median(x) \), where x is the different values from different sub-blocks having equally location. Finally, the target image \( \tilde{T} \) can be located by threshold processing. If \( \rho M \le \tilde{T}(x,y) \), we see \( (x,y) \) as a target point, where M is the maximum value of \( \tilde{T} \) and \( \rho \) is the threshold.
4 Experiments and Analysis
To evaluate the target detection performance, two groups of experimental are designed: The first group is single target detection experiments, three real images with different background are decomposed and the detection results are obtained directly using the proposed method; The second group of experiments is for the infrared sequences with some synthetic targets. We embed the small synthetic targets, generated from five real targets, into the images chosen from four real sequences. Then the detection performance is quantitatively evaluated by using some objective evaluation criteria such as local SNR, detection probability and false-alarm rate. We also test the conventional single-frame detection methods for comparison such as TDLMS, Top-Hat, Max-Median. In these two groups of experiment, based on the consideration of computational cost, the size of sliding window, sliding step are experimentally determined as 16 × 16 and 8, respectively. The detection threshold are set to 0.7. The penalty parameters \( \lambda = 0.12 \).
4.1 Experiment on Single Target Detection
In this subsection, we apply the proposed detection method to test three infrared images with small dim target against different backgrounds shown as Fig. 2. The first row of Fig. 2 is the original test images and the second row is the three-dimensional mesh surfaces of images. From left to right, the test images are rive-ground background image with size 128 × 128, coast background with size 200 × 256, sea-sky background image with size 200 × 256. The target detection experimental results on these three images by our method are shown in Fig. 3. From this figure, we can see the original infrared image are effectively decomposed into three different components such as the background component image shown in Fig. 3(b) and target component image show in Fig. 3(c). The Fig. 3(d) shows the three-dimensional (3-D) mesh surfaces of the target component image. The results of detection indicate that our method can accomplish the task of target detection effectively not only for the dim point targets but also for the porphyritic target like the target in Fig. 2(c) through separating the target component from other elements.


Infrared images with small dim targets against different backgrounds (a) land background (b) coast background (c) sea sky background


Image decomposition results obtained by proposed algorithm (a) original image (b) background data (c) target component (d) 3-d mesh of target component
4.2 Experiment on Infrared Sequences with Multiple Target
In order to verify the performance of the proposed method more objectively, multi-targets detection experiments on four sequences are done in this subsection. We synthesized the test database by embedding the multi-targets into several background images chosen from four real sequences using the method in [12]. As shown in Fig. 4, we can see that the contrast between target and background is very low in the seq.1 and seq.4, especially in the seq.4 the distant targets almost can not be observed. In the seq.2, there are road and building targets except for tank and aircraft targets with big size. And we compare our method with several typical algorithms, such as Max-Median, Top-Hat, TDLMS.


The representative images for 4 groups of synthetic image (a) seq.1 (b) seq.2 (c) seq.3 (d) seq.4
Figure 5 gives the comparisons between the proposed method and baseline methods. we can see that seq.1 has strong cloud clutter and several targets location are in the clouds and sky junction. From the second row, the proposed method can detect not only four flight targets in the sky but also the tank target on the road correctly and eliminate the road and building effectively, which illustrates our method also has detection ability to the spot target with large pixels. In general, the detection method based on LRR has less clutter and noise residual for different backgrounds compared to the other baseline methods with the target enhanced and more using information preserved at the same time.


The results of different methods (a) the representative images for 4 groups of synthetic image (b) max-median (c) top-hat (d) TDLMS (e) LRR
5 Conclusion and Future Work
Based on the LRR model, we proposed a small target detection method which can transform the detection task into separation process of background and target components by solving the LRR in this paper. The results of two groups of experiments have validated that the proposed method has better detection performance compared to the conventional baseline methods. In the future work, the research attempt is to add the model of target into our method which could make the method have better ability of distinguishing between the target and noise.
Conferences
Zheng, C., Li, H.: Small infrared target detection based on harmonic and sparse matrix decomposition. Opt. Eng. 52(6), 066401 (2013). (1-10)
Gao, C.Q., Zhang, T.Q., et al.: Small infrared target detection using sparse ring representation. IEEE Trans. Aerosp. Electron. Syst. Mag. 27(3), 21–30 (2012)
Zeng, M., Li, J., Peng, Z.: The design of top-hat morphological filter and application to infrared target detection. Infrared Phys. Technol. 48(1), 67–76 (2006)
Wang, P., Tian, J., Gao, C.: Infrared small target detection using directional highpass filters based on LS-SVM. Electron. Lett. 45(3), 156–158 (2009)
Cao, Y., Liu, R.M., Yang, J.: Small target detection using two-dimensional least mean square (TDLMS) filter based on neighborhood analysis. Int. J. Infrared Millim. Waves 29(2), 188–200 (2008)
Zheng, C., Li, H.: Method of infrared target detection based on the characteristic analysis of the local grey level. Infrared Laser Eng. 33(4), 362–365 (2004)
Deshpande, S., et al.: Max-mean and max-median filters for detection of small targets. In Proceedings Signal and Data Processing of Small Targets, vol. 3809, pp. 74–83. SPIE, Denver, CO (1999)
Hu, T., et al.: Infrared small target detection based on saliency and principle component analysis. J. Infrared Millim. Waves 29(4), 303–306 (2010)
Cao, Y., Liu, R., Yang, J.: Infrared small target detection using PPCA. Int. J. Infrared Millim. Waves 29(4), 385–395 (2008)
Liu, G.C., Lin, Z.C., Yu, Y: Robust subspace segmentation by low-rank representation. In: Proceedings of ICML, pp. 663–670 (2010)
Liu, G., Lin, Z., Yan, S., et al.: Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 35(1), 171–184 (2013)
Gao, C.Q., Meng, D.Y., et al.: Infrared patch-image model for small target detection in a single image. IEEE Tans. Image Proc. 22(12), 4996–5009 (2013)
Cai, J.F., Candes, E.J., Shen, Z.W.: A singular value thresholding algorithm for matrix completion. SIAM J. Optim. 20(4), 1956–1982 (2008)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Li, M., He, YJ., Zhang, J. (2015). Small Infrared Target Detection Based on Low-Rank Representation. In: Zhang, YJ. (eds) Image and Graphics. Lecture Notes in Computer Science(), vol 9219. Springer, Cham. https://doi.org/10.1007/978-3-319-21969-1_34
Download citation
DOI: https://doi.org/10.1007/978-3-319-21969-1_34
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-21968-4
Online ISBN: 978-3-319-21969-1
eBook Packages: Computer ScienceComputer Science (R0)
