
Abstract
The development of efficient and scalable cache coherence protocols is a key aspect in the design of manycore chip multiprocessors. In this work, we review a kind of cache coherence protocols that, despite having been already implemented in the 90s for building large-scale commodity multiprocessors, have not been seriously considered in the current context of chip multiprocessors. In particular, we evaluate a directory-based cache coherence protocol that employs distributed simply-linked lists to encode the information about the sharers of the memory blocks. We compare this organization with two protocols that use centralized sharing codes, each one having different directory memory overhead: one of them implementing a non-scalable bit-vector sharing code and the other one implementing a more scalable limited-pointer scheme with a single pointer. Simulation results show that for large-scale chip multiprocessors, the protocol based on distributed linked lists obtains worse performance than the centralized approaches. This is due, principally, to an increase in the contention at the directory controller as a consequence of being blocked for longer time while updating the distributed sharing information.
This work has been supported by the Spanish MINECO, as well as European Commission FEDER funds, under grant “TIN2012-38341-C04-03”.
Chapter PDF
Similar content being viewed by others
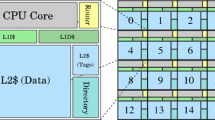
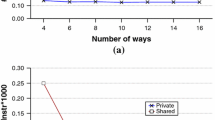
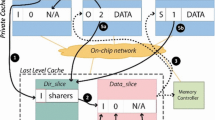
Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Agarwal, N., Krishna, T., Peh, L.S., Jha, N.K.: GARNET: A detailed on-chip network model inside a full-system simulator. In: IEEE Int’l Symp. on Performance Analysis of Systems and Software (ISPASS), pp. 33–42 (April 2009)
Alameldeen, A.R., Wood, D.A.: Variability in architectural simulations of multi-threaded workloads. In: 9th Int’l Symp. on High-Performance Computer Architecture (HPCA), pp. 7–18 (February 2003)
Clark, R., Alnes, K.: An SCI chipset and adapter. In: HotInterconnects Symp. IV, pp. 221–235 (August 1996)
Conway, P., Kalyanasundharam, N., Donley, G., Lepak, K., Hughes, B.: Blade computing with the AMD OpteronTM processor (“Magny Cours”). In: 21st HotChips Symp. (August 2009)
Culler, D.E., Singh, J.P., Gupta, A.: Parallel Computer Architecture: A Hardware/Software Approach. Morgan Kaufmann Publishers, Inc. (1999)
Gustavson, D.B.: The scalable coherent interface and related standards proyects. IEEE Micro 12(1), 10–22 (1992)
Lovett, T., Clapp, R.: STiNG: A cc-NUMA computer system for the commercial marketplace. In: 23rd Int’l Symp. on Computer Architecture (ISCA), pp. 308–317 (June 1996)
Luk, C.K., Cohn, R., Muth, R., Patil, H., Klauser, A., Lowney, G., Wallace, S., Reddi, V.J., Hazelwood, K.: Pin: Building customized program analysis tools with dynamic instrumentation. In: 2005 ACM SIGPLAN Conf. on Programming Language Design and Implementation (PLDI), pp. 190–200 (June 2005)
Martin, M.M.K., Hill, M.D., Sorin, D.: Why on-chip cache coherence is here to stay. Communications of the ACM 55(7), 78–89 (2012)
Martin, M.M., Sorin, D.J., Beckmann, B.M., Marty, M.R., Xu, M., Alameldeen, A.R., Moore, K.E., Hill, M.D., Wood, D.A.: Multifacet’s general execution-driven multiprocessor simulator (GEMS) toolset. Computer Architecture News 33(4), 92–99 (2005)
Monchiero, M., Ahn, J.H., Falcón, A., Ortega, D., Faraboschi, P.: How to simulate 1000 cores. Computer Architecture News 37(2), 10–19 (2009)
Thekkath, R., Singh, A.P., Singh, J.P., John, S., Hennessy, J.L.: An evaluation of a commercial cc-NUMA architecture: The CONVEX Exemplar SPP1200. In: 11th Int’l Parallel Processing Symp. (IPPS), pp. 8–17 (April 1997)
Woo, S.C., Ohara, M., Torrie, E., Singh, J.P., Gupta, A.: The SPLASH-2 programs: Characterization and methodological considerations. In: 22nd Int’l Symp. on Computer Architecture (ISCA), pp. 24–36 (June 1995)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2014 Springer International Publishing Switzerland
About this paper
Cite this paper
Fernández-Pascual, R., Ros, A., Acacio, M.E. (2014). Characterization of a List-Based Directory Cache Coherence Protocol for Manycore CMPs. In: Lopes, L., et al. Euro-Par 2014: Parallel Processing Workshops. Euro-Par 2014. Lecture Notes in Computer Science, vol 8806. Springer, Cham. https://doi.org/10.1007/978-3-319-14313-2_22
Download citation
DOI: https://doi.org/10.1007/978-3-319-14313-2_22
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-14312-5
Online ISBN: 978-3-319-14313-2
eBook Packages: Computer ScienceComputer Science (R0)