
Abstract
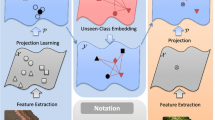
Most existing zero-shot learning approaches exploit transfer learning via an intermediate-level semantic representation such as visual attributes or semantic word vectors. Such a semantic representation is shared between an annotated auxiliary dataset and a target dataset with no annotation. A projection from a low-level feature space to the semantic space is learned from the auxiliary dataset and is applied without adaptation to the target dataset. In this paper we identify an inherent limitation with this approach. That is, due to having disjoint and potentially unrelated classes, the projection functions learned from the auxiliary dataset/domain are biased when applied directly to the target dataset/domain. We call this problem the projection domain shift problem and propose a novel framework, transductive multi-view embedding, to solve it. It is ‘transductive’ in that unlabelled target data points are explored for projection adaptation, and ‘multi-view’ in that both low-level feature (view) and multiple semantic representations (views) are embedded to rectify the projection shift. We demonstrate through extensive experiments that our framework (1) rectifies the projection shift between the auxiliary and target domains, (2) exploits the complementarity of multiple semantic representations, (3) achieves state-of-the-art recognition results on image and video benchmark datasets, and (4) enables novel cross-view annotation tasks.
Chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
References
Akata, Z., Perronnin, F., Harchaoui, Z., Schmid, C.: Label-embedding for attribute-based classification. In: CVPR (2013)
Banerjee, A., Dhillon, I.S., Ghosh, J., Sra, S.: Clustering on the unit hypersphere using von mises-fisher distributions. JMLR (2005)
Biederman, I.: Recognition by components - a theory of human image understanding. Psychological Review (1987)
Blitzer, J., Foster, D.P., Kakade, S.M.: Zero-shot domain adaptation: A multi-view approach (2009)
Brown, P.F., Pietra, V.J.: V.deSouza, P., C.Lai, J., L.Mercer, R.: Class-based n-gram models of natural language. Journal Computational Linguistics (1992)
Farhadi, A., Endres, I., Hoiem, D., Forsyth, D.: Describing objects by their attributes. In: CVPR (2009)
Frome, A., Corrado, G.S., Shlens, J., Bengio, S., Dean, J., Ranzato, M., Mikolov, T.: Devise: A deep visual-semantic embedding model andrea. In: NIPS (2013)
Fu, Y., Hospedales, T.M., Xiang, T., Gong, S.: Attribute learning for understanding unstructured social activity. In: Fitzgibbon, A., Lazebnik, S., Perona, P., Sato, Y., Schmid, C. (eds.) ECCV 2012, Part IV. LNCS, vol. 7575, pp. 530–543. Springer, Heidelberg (2012)
Fu, Y.: Multi-view metric learning for multi-view video summarization (2014), http://arxiv.org/abs/1405.6434
Fu, Y., Guo, Y., Zhu, Y., Liu, F., Song, C., Zhou, Z.H.: Multi-view video summarization. IEEE TMM 12(7), 717–729 (2010)
Fu, Y., Hospedales, T.M., Xiang, T., Gong, S.: Learning multi-modal latent attributes. TPAMI (2013)
Fu, Y., Hospedales, T.M., Xiang, T., Gongy, S., Yao, Y.: Interestingness prediction by robust learning to rank. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014, Part II. LNCS, vol. 8690, pp. 488–503. Springer, Heidelberg (2014)
Gong, Y., Ke, Q., Isard, M., Lazebnik, S.: A multi-view embedding space for modeling internet images, tags, and their semantics. IJCV (2013)
Hardoon, D.R., Szedmak, S., Shawe-Taylor, J.: Canonical correlation analysis; an overview with application to learning methods. In: Neural Computation (2004)
Hospedales, T., Gong, S., Xiang, T.: Learning tags from unsegmented videos of multiple human actions. In: ICDM (2011)
Hwang, S.J., Grauman, K.: Learning the relative importance of objects from tagged images for retrieval and cross-modal search. IJCV (2011)
Hwang, S.J., Sha, F., Grauman, K.: Sharing features between objects and their attributes. In: CVPR (2011)
Lampert, C.H., Nickisch, H., Harmeling, S.: Learning to detect unseen object classes by between-class attribute transfer. In: CVPR (2009)
Lampert, C.H.: Kernel methods in computer vision. Foundations and Trends in Computer Graphics and Vision (2009)
Lampert, C.H., Nickisch, H., Harmeling, S.: Attribute-based classification for zero-shot visual object categorization. IEEE TPAMI (2013)
Liu, J., Kuipers, B., Savarese, S.: Recognizing human actions by attributes. In: CVPR (2011)
van der Maaten, L., Hinton, G.: Visualizing high-dimensional data using t-sne. JMLR (2008)
Mikolov, T., Chen, K., Corrado, G., Dean, J.: Efficient estimation of word representation in vector space. In: Proceedings of Workshop at ICLR (2013)
Mikolov, T., Sutskever, I., Chen, K., Corrado, G., Dean, J.: Distributed representations of words and phrases and their compositionality. In: Proceedings of NIPS (2013)
Palatucci, M., Hinton, G., Pomerleau, D., Mitchell, T.M.: Zero-shot learning with semantic output codes. In: NIPS (2009)
Parikh, D., Grauman, K.: Relative attributes. In: ICCV (2011)
Rohrbach, M., Ebert, S., Schiele, B.: Transfer learning in a transductive setting. In: NIPS (2013)
Rohrbach, M., Stark, M., Schiele, B.: Evaluating knowledge transfer and zero-shot learning in a large-scale setting. In: CVPR (2012)
Rohrbach, M., Stark, M., Szarvas, G., Gurevych, I., Schiele, B.: What helps where–and why semantic relatedness for knowledge transfer. In: CVPR (2010)
Scheirer, W.J., Kumar, N., Belhumeur, P.N., Boult, T.E.: Multi-attribute spaces: Calibration for attribute fusion and similarity search. In: CVPR (2012)
Shi, Z., Yang, Y., Hospedales, T.M., Xiang, T.: Weakly supervised learning of objects, attributes and their associations. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014, Part II. LNCS, vol. 8690, pp. 472–487. Springer, Heidelberg (2014)
Smola, A.J., Kondor, R.: Kernels and regularization on graphs. In: Schölkopf, B., Warmuth, M.K. (eds.) COLT/Kernel 2003. LNCS (LNAI), vol. 2777, pp. 144–158. Springer, Heidelberg (2003)
Socher, R., Fei-Fei, L.: Connecting modalities: Semi-supervised segmentation and annotation of images using unaligned text corpora. In: CVPR (2010)
Socher, R., Ganjoo, M., Sridhar, H., Bastani, O., Manning, C.D., Ng, A.Y.: Zero-shot learning through cross-modal transfer. In: NIPS (2013)
Wang, X., Ji, Q.: A unified probabilistic approach modeling relationships between attributes and objects. In: ICCV (2013)
Wang, Y., Gong, S.: Translating topics to words for image annotation. In: ACM CIKM (2007)
Yu, F.X., Cao, L., Feris, R.S., Smith, J.R., Chang, S.F.: Designing category-level attributes for discriminative visual recognition. In: CVPR (2013)
Zhou, D., Burges, C.J.C.: Spectral clustering and transductive learning with multiple views. In: ICML 2007 (2007)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2014 Springer International Publishing Switzerland
About this paper
Cite this paper
Fu, Y., Hospedales, T.M., Xiang, T., Fu, Z., Gong, S. (2014). Transductive Multi-view Embedding for Zero-Shot Recognition and Annotation. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds) Computer Vision – ECCV 2014. ECCV 2014. Lecture Notes in Computer Science, vol 8690. Springer, Cham. https://doi.org/10.1007/978-3-319-10605-2_38
Download citation
DOI: https://doi.org/10.1007/978-3-319-10605-2_38
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-10604-5
Online ISBN: 978-3-319-10605-2
eBook Packages: Computer ScienceComputer Science (R0)