
Abstract
We propose a model that performs image captioning efficiently based on entity relations, followed by a deep learning-based encoder and decoder model. In order to make image captioning more precise, the proposed model uses Inception-Resnet(version-2) as an encoder and GRU as a decoder. To develop a less expensive and effective image captioning model in accordance with accelerating the training process by reducing the effect of vanishing gradient issues, residual connections are introduced in Inception architecture. Furthermore, the effectiveness of the proposed model has been significantly enhanced by associating the Bahadanu Attention model with GRU. To cut down the computation time and make it a less resource-consuming captioning model, a compact form of the vocabulary of informative words is taken into consideration. The proposed work makes use of the convolution base of the hybrid model to start learning alignment from scratch and learn the correlation among different images and descriptions. The proposed image text generation model is evaluated on Flickr 8k, Flickr 30k, and MSCOCO datasets, and thereby, it produces convincing results on assessments.
Access this chapter
Tax calculation will be finalised at checkout
Purchases are for personal use only
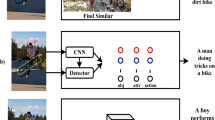
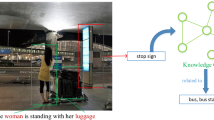
Similar content being viewed by others

References
Al-Malla, M.A., Jafar, A., Ghneim, N.: Image captioning model using attention and object features to mimic human image understanding. J. Big Data 9(1), 1–16 (2022)
Anderson, P., et al.: Bottom-up and top-down attention for image captioning and visual question answering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6077–6086 (2018)
Bahdanau, D., Cho, K., Bengio, Y.: Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014)
Bhatia, Y., Bajpayee, A., Raghuvanshi, D., Mittal, H.: Image captioning using Google’s inception-resnet-v2 and recurrent neural network. In: 2019 Twelfth International Conference on Contemporary Computing (IC3), pp. 1–6. IEEE (2019)
Cho, K., Courville, A., Bengio, Y.: Describing multimedia content using attention-based encoder-decoder networks. IEEE Trans. Multimedia 17(11), 1875–1886 (2015)
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: 2009 IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255. IEEE (2009)
Jyotsna, A., Mary Anita, E.: Enhancing IoT security through deep learning-based intrusion detection. In: Neri, F., Du, K.L., Varadarajan, V., San-Blas, A.A., Jiang, Z. (eds.) CCCE 2023, vol. 1823, pp. 95–105. Springer, Cham (2023). https://doi.org/10.1007/978-3-031-35299-7_8
Khan, R., Islam, M.S., Kanwal, K., Iqbal, M., Hossain, M.I., Ye, Z.: A deep neural framework for image caption generation using GRU-based attention mechanism. arXiv preprint arXiv:2203.01594 (2022)
Li, X., et al.: Oscar: object-semantics aligned pre-training for vision-language tasks. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12375, pp. 121–137. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58577-8_8
Lu, J., Yang, J., Batra, D., Parikh, D.: Neural baby talk. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 7219–7228 (2018)
Song, X., Feng, F., Han, X., Yang, X., Liu, W., Nie, L.: Neural compatibility modeling with attentive knowledge distillation. In: The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, pp. 5–14 (2018)
Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A.: Inception-v4, inception-resnet and the impact of residual connections on learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 31 (2017)
Vedantam, R., Lawrence Zitnick, C., Parikh, D.: Cider: consensus-based image description evaluation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4566–4575 (2015)
Vinyals, O., Toshev, A., Bengio, S., Erhan, D.: Show and tell: a neural image caption generator. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3156–3164 (2015)
Xu, K., et al.: Show, attend and tell: neural image caption generation with visual attention. In: International Conference on Machine Learning, pp. 2048–2057. PMLR (2015)
You, Q., Jin, H., Wang, Z., Fang, C., Luo, J.: Image captioning with semantic attention. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4651–4659 (2016)
Zhou, Y., Wang, M., Liu, D., Hu, Z., Zhang, H.: More grounded image captioning by distilling image-text matching model. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 4777–4786 (2020)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Patra, B., Kisku, D.R. (2023). Precise and Faster Image Description Generation with Limited Resources Using an Improved Hybrid Deep Model. In: Maji, P., Huang, T., Pal, N.R., Chaudhury, S., De, R.K. (eds) Pattern Recognition and Machine Intelligence. PReMI 2023. Lecture Notes in Computer Science, vol 14301. Springer, Cham. https://doi.org/10.1007/978-3-031-45170-6_18
Download citation
DOI: https://doi.org/10.1007/978-3-031-45170-6_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-45169-0
Online ISBN: 978-3-031-45170-6
eBook Packages: Computer ScienceComputer Science (R0)